 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Style Agnostic 3D Reconstruction via Adversarial Style Transfer
Oct 20, 2021
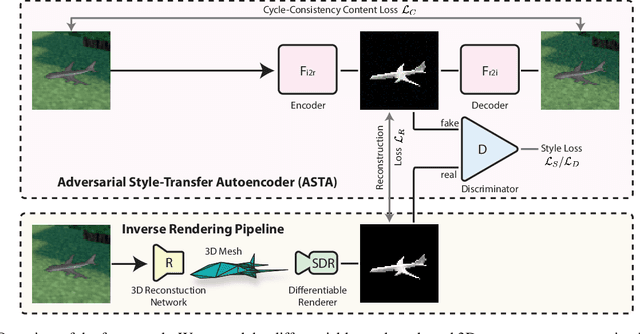
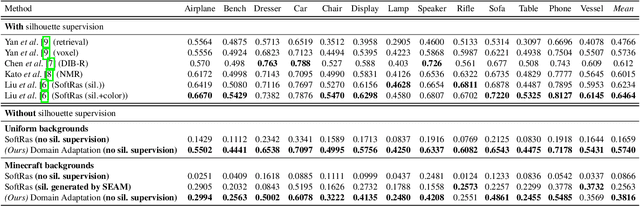
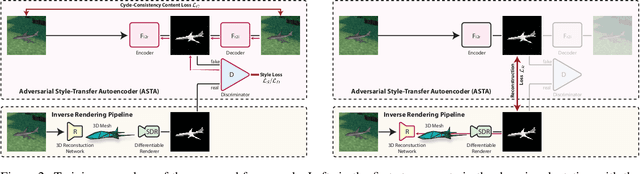

Reconstructing the 3D geometry of an object from an image is a major challenge in computer vision. Recently introduced differentiable renderers can be leveraged to learn the 3D geometry of objects from 2D images, but those approaches require additional supervision to enable the renderer to produce an output that can be compared to the input image. This can be scene information or constraints such as object silhouettes, uniform backgrounds, material, texture, and lighting. In this paper, we propose an approach that enables a differentiable rendering-based learning of 3D objects from images with backgrounds without the need for silhouette supervision. Instead of trying to render an image close to the input, we propose an adversarial style-transfer and domain adaptation pipeline that allows to translate the input image domain to the rendered image domain. This allows us to directly compare between a translated image and the differentiable rendering of a 3D object reconstruction in order to train the 3D object reconstruction network. We show that the approach learns 3D geometry from images with backgrounds and provides a better performance than constrained methods for single-view 3D object reconstruction on this task.
Deep Image Prior for Sparse-sampling Photoacoustic Microscopy
Oct 15, 2020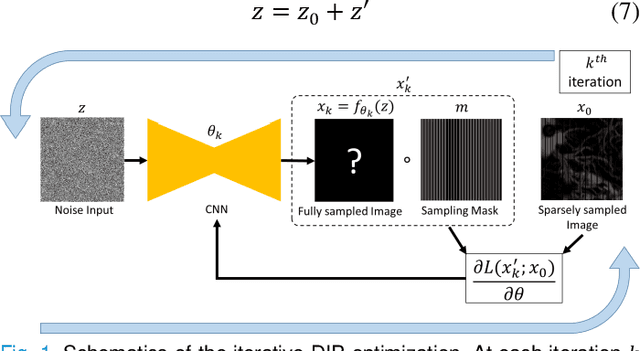
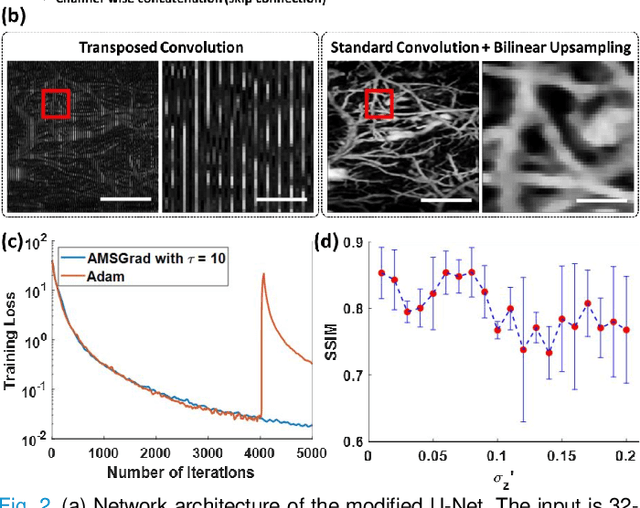
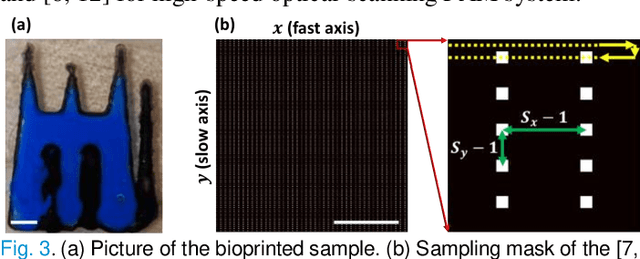
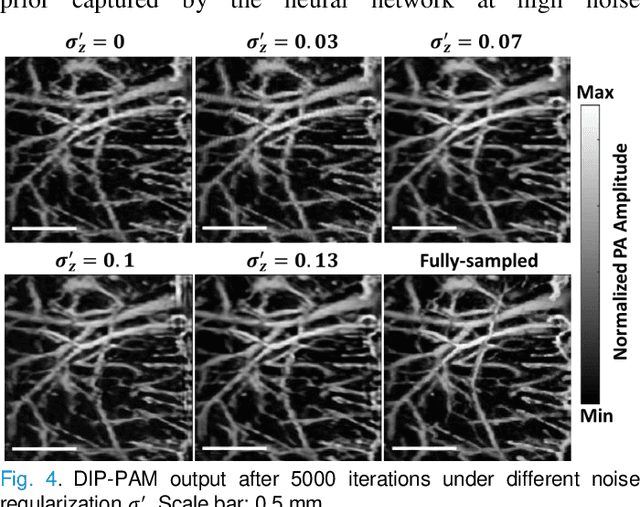
Photoacoustic microscopy (PAM) is an emerging method for imaging both structural and functional information without the need for exogenous contrast agents. However, state-of-the-art PAM faces a tradeoff between imaging speed and spatial sampling density within the same field-of-view (FOV). Limited by the pulsed laser's repetition rate, the imaging speed is inversely proportional to the total number of effective pixels. To cover the same FOV in a shorter amount of time with the same PAM hardware, there is currently no other option than to decrease spatial sampling density (i.e., sparse sampling). Deep learning methods have recently been used to improve sparsely sampled PAM images; however, these methods often require time-consuming pre-training and a large training dataset that has fully sampled, co-registered ground truth. In this paper, we propose using a method known as "deep image prior" to improve the image quality of sparsely sampled PAM images. The network does not need prior learning or fully sampled ground truth, making its implementation more flexible and much quicker. Our results show promising improvement in PA vasculature images with as few as 2% of the effective pixels. Our deep image prior approach produces results that outperform interpolation methods and can be readily translated to other high-speed, sparse-sampling imaging modalities.
Semi-Supervised Hybrid Spine Network for Segmentation of Spine MR Images
Mar 23, 2022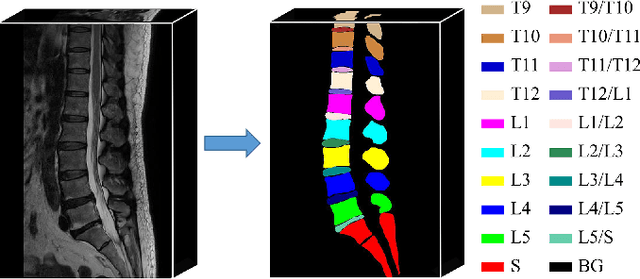
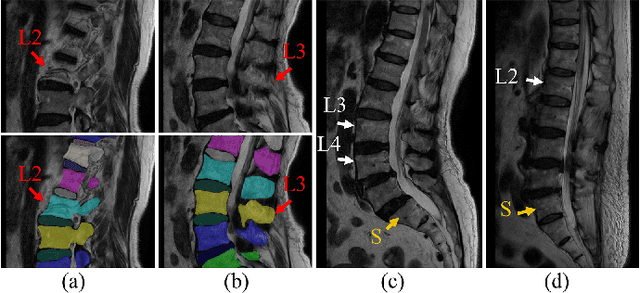
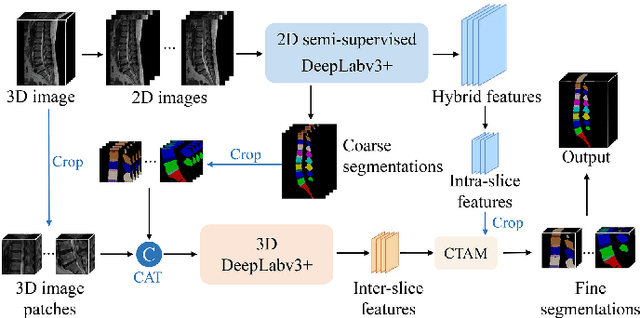
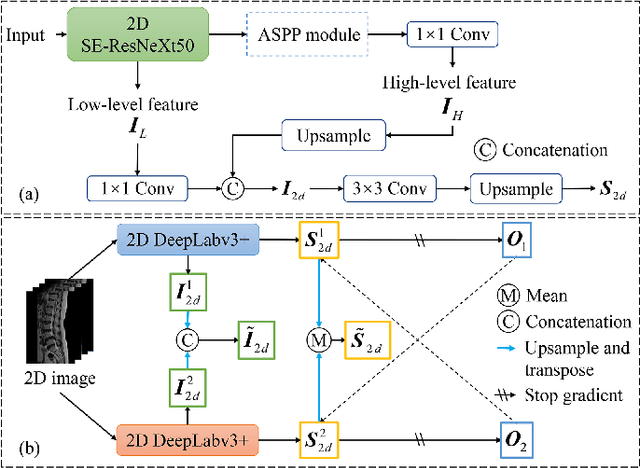
Automatic segmentation of vertebral bodies (VBs) and intervertebral discs (IVDs) in 3D magnetic resonance (MR) images is vital in diagnosing and treating spinal diseases. However, segmenting the VBs and IVDs simultaneously is not trivial. Moreover, problems exist, including blurry segmentation caused by anisotropy resolution, high computational cost, inter-class similarity and intra-class variability, and data imbalances. We proposed a two-stage algorithm, named semi-supervised hybrid spine network (SSHSNet), to address these problems by achieving accurate simultaneous VB and IVD segmentation. In the first stage, we constructed a 2D semi-supervised DeepLabv3+ by using cross pseudo supervision to obtain intra-slice features and coarse segmentation. In the second stage, a 3D full-resolution patch-based DeepLabv3+ was built. This model can be used to extract inter-slice information and combine the coarse segmentation and intra-slice features provided from the first stage. Moreover, a cross tri-attention module was applied to compensate for the loss of inter-slice and intra-slice information separately generated from 2D and 3D networks, thereby improving feature representation ability and achieving satisfactory segmentation results. The proposed SSHSNet was validated on a publicly available spine MR image dataset, and remarkable segmentation performance was achieved. Moreover, results show that the proposed method has great potential in dealing with the data imbalance problem. Based on previous reports, few studies have incorporated a semi-supervised learning strategy with a cross attention mechanism for spine segmentation. Therefore, the proposed method may provide a useful tool for spine segmentation and aid clinically in spinal disease diagnoses and treatments. Codes are publicly available at: https://github.com/Meiyan88/SSHSNet.
Shared Prior Learning of Energy-Based Models for Image Reconstruction
Nov 12, 2020
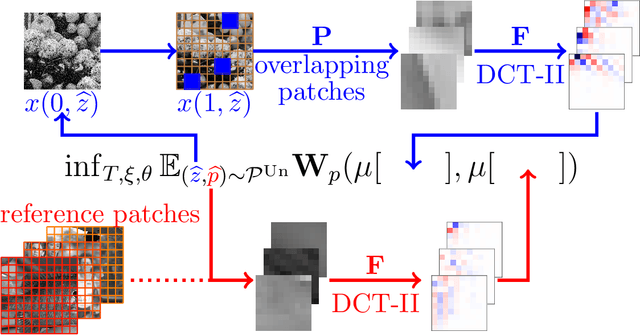
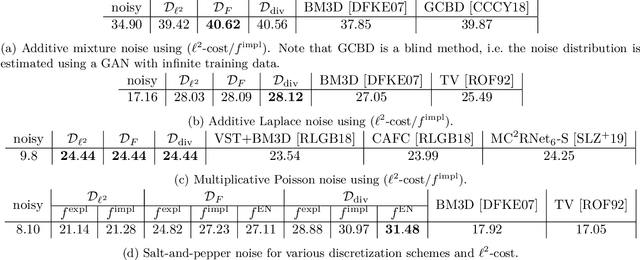
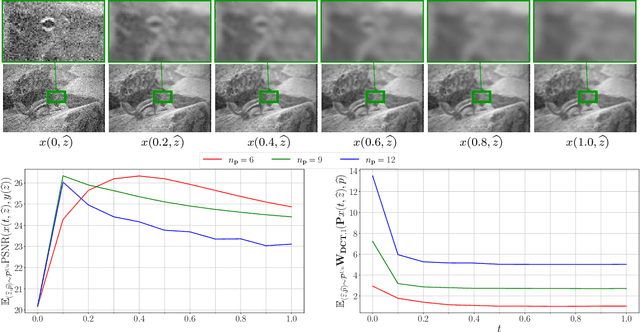
We propose a novel learning-based framework for image reconstruction particularly designed for training without ground truth data, which has three major building blocks: energy-based learning, a patch-based Wasserstein loss functional, and shared prior learning. In energy-based learning, the parameters of an energy functional composed of a learned data fidelity term and a data-driven regularizer are computed in a mean-field optimal control problem. In the absence of ground truth data, we change the loss functional to a patch-based Wasserstein functional, in which local statistics of the output images are compared to uncorrupted reference patches. Finally, in shared prior learning, both aforementioned optimal control problems are optimized simultaneously with shared learned parameters of the regularizer to further enhance unsupervised image reconstruction. We derive several time discretization schemes of the gradient flow and verify their consistency in terms of Mosco convergence. In numerous numerical experiments, we demonstrate that the proposed method generates state-of-the-art results for various image reconstruction applications--even if no ground truth images are available for training.
FMD-cGAN: Fast Motion Deblurring using Conditional Generative Adversarial Networks
Nov 30, 2021
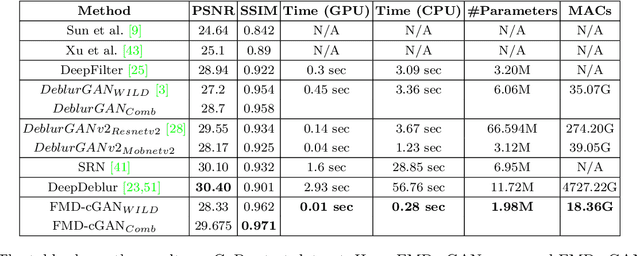


In this paper, we present a Fast Motion Deblurring-Conditional Generative Adversarial Network (FMD-cGAN) that helps in blind motion deblurring of a single image. FMD-cGAN delivers impressive structural similarity and visual appearance after deblurring an image. Like other deep neural network architectures, GANs also suffer from large model size (parameters) and computations. It is not easy to deploy the model on resource constraint devices such as mobile and robotics. With the help of MobileNet based architecture that consists of depthwise separable convolution, we reduce the model size and inference time, without losing the quality of the images. More specifically, we reduce the model size by 3-60x compare to the nearest competitor. The resulting compressed Deblurring cGAN faster than its closest competitors and even qualitative and quantitative results outperform various recently proposed state-of-the-art blind motion deblurring models. We can also use our model for real-time image deblurring tasks. The current experiment on the standard datasets shows the effectiveness of the proposed method.
Hybrid Atlas Building with Deep Registration Priors
Dec 13, 2021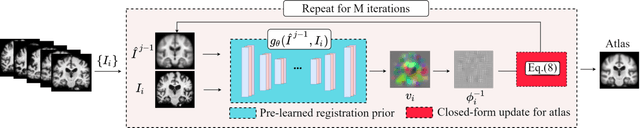
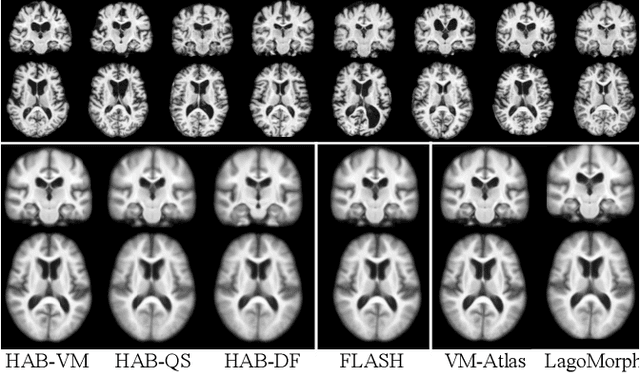
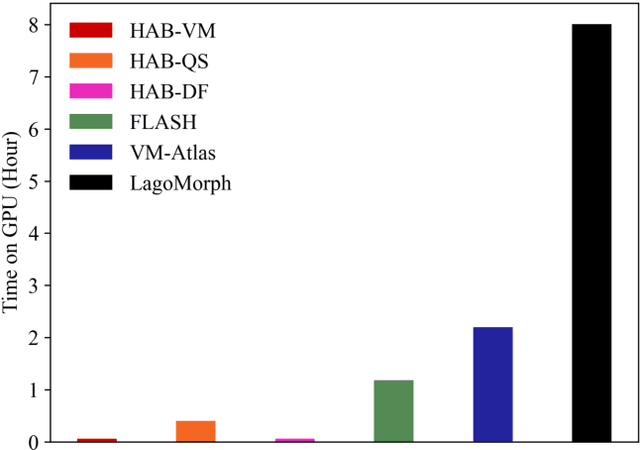
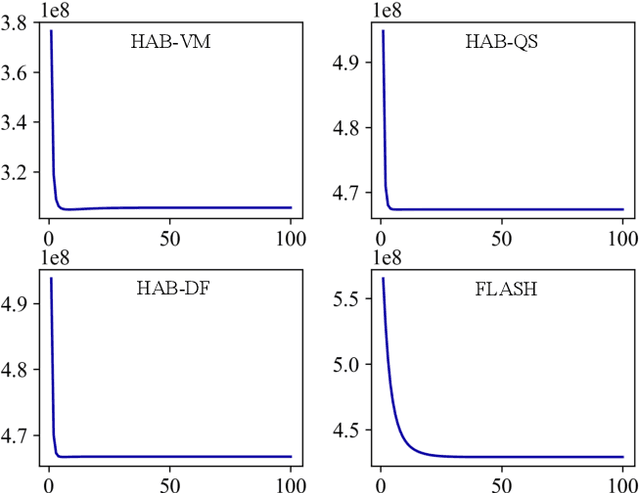
Registration-based atlas building often poses computational challenges in high-dimensional image spaces. In this paper, we introduce a novel hybrid atlas building algorithm that fast estimates atlas from large-scale image datasets with much reduced computational cost. In contrast to previous approaches that iteratively perform registration tasks between an estimated atlas and individual images, we propose to use learned priors of registration from pre-trained neural networks. This newly developed hybrid framework features several advantages of (i) providing an efficient way of atlas building without losing the quality of results, and (ii) offering flexibility in utilizing a wide variety of deep learning based registration methods. We demonstrate the effectiveness of this proposed model on 3D brain magnetic resonance imaging (MRI) scans.
Structural Gaussian Priors for Bayesian CT reconstruction of Subsea Pipes
Mar 02, 2022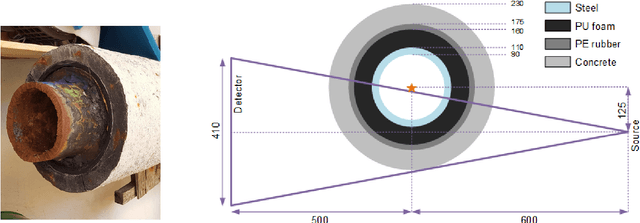
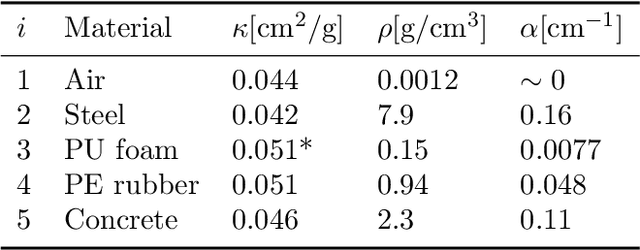
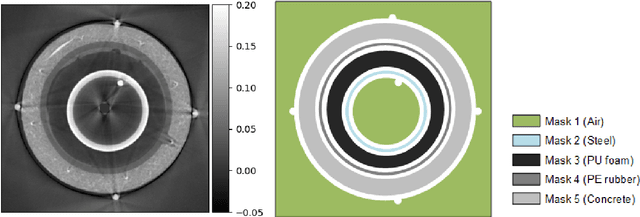
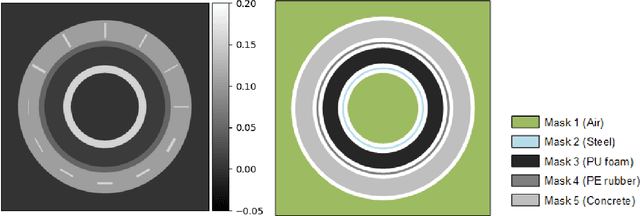
A non-destructive testing (NDT) application of X-ray computed tomography (CT) is inspection of subsea pipes in operation via 2D cross-sectional scans. Data acquisition is time-consuming and costly due to the challenging subsea environment. Reducing the number of projections in a scan can yield time and cost savings, but compromises the reconstruction quality, if conventional reconstruction methods are used. In this work we take a Bayesian approach to CT reconstruction and focus on designing an effective prior to make use of available structural information about the pipe geometry. We propose a new class of structural Gaussian priors to enforce expected material properties in different regions of the reconstructed image based on independent Gaussian priors in combination with global regularity through a Gaussian Markov Random Field (GMRF) prior. Numerical experiments with synthetic and real data show that the proposed structural Gaussian prior can reduce artifacts and enhance contrast in the reconstruction compared to using only a global GMRF prior or no prior at all. We show how the resulting posterior distribution can be efficiently sampled even for large-scale images, which is essential for practical NDT applications.
MSDN: Mutually Semantic Distillation Network for Zero-Shot Learning
Mar 07, 2022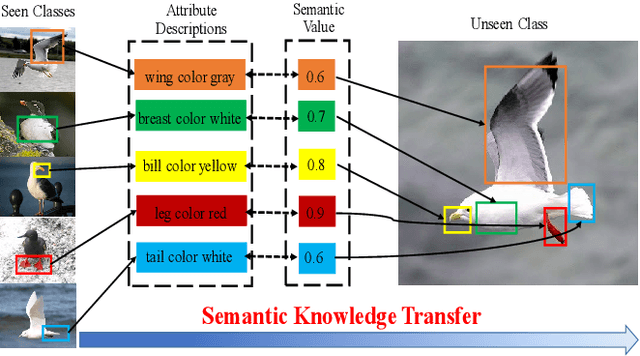
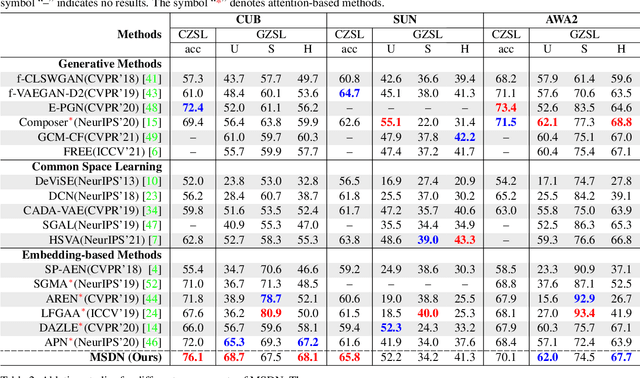

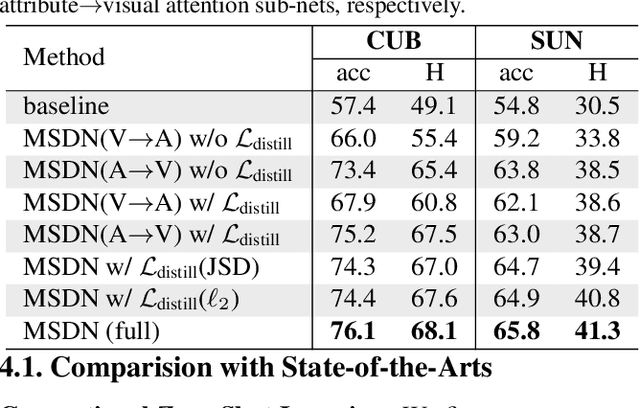
The key challenge of zero-shot learning (ZSL) is how to infer the latent semantic knowledge between visual and attribute features on seen classes, and thus achieving a desirable knowledge transfer to unseen classes. Prior works either simply align the global features of an image with its associated class semantic vector or utilize unidirectional attention to learn the limited latent semantic representations, which could not effectively discover the intrinsic semantic knowledge e.g., attribute semantics) between visual and attribute features. To solve the above dilemma, we propose a Mutually Semantic Distillation Network (MSDN), which progressively distills the intrinsic semantic representations between visual and attribute features for ZSL. MSDN incorporates an attribute$\rightarrow$visual attention sub-net that learns attribute-based visual features, and a visual$\rightarrow$attribute attention sub-net that learns visual-based attribute features. By further introducing a semantic distillation loss, the two mutual attention sub-nets are capable of learning collaboratively and teaching each other throughout the training process. The proposed MSDN yields significant improvements over the strong baselines, leading to new state-of-the-art performances on three popular challenging benchmarks, i.e., CUB, SUN, and AWA2. Our codes have been available at: \url{https://github.com/shiming-chen/MSDN}.
RRL:Regional Rotation Layer in Convolutional Neural Networks
Feb 25, 2022
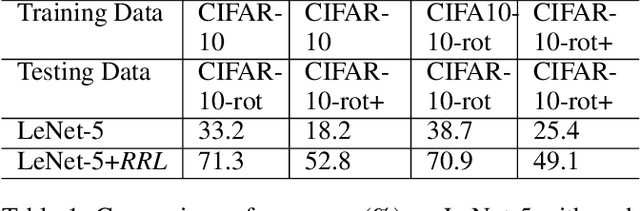
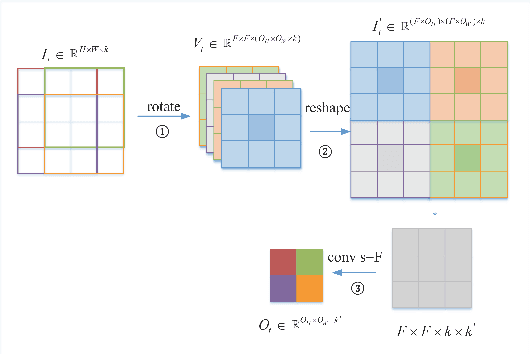
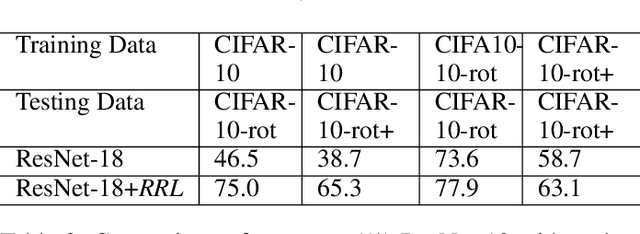
Convolutional Neural Networks (CNNs) perform very well in image classification and object detection in recent years, but even the most advanced models have limited rotation invariance. Known solutions include the enhancement of training data and the increase of rotation invariance by globally merging the rotation equivariant features. These methods either increase the workload of training or increase the number of model parameters. To address this problem, this paper proposes a module that can be inserted into the existing networks, and directly incorporates the rotation invariance into the feature extraction layers of the CNNs. This module does not have learnable parameters and will not increase the complexity of the model. At the same time, only by training the upright data, it can perform well on the rotated testing set. These advantages will be suitable for fields such as biomedicine and astronomy where it is difficult to obtain upright samples or the target has no directionality. Evaluate our module with LeNet-5, ResNet-18 and tiny-yolov3, we get impressive results.
Auto-Encoding Knowledge Graph for Unsupervised Medical Report Generation
Nov 08, 2021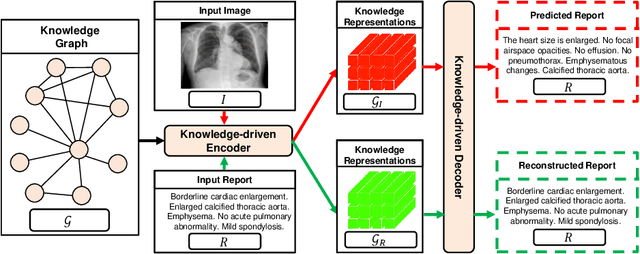
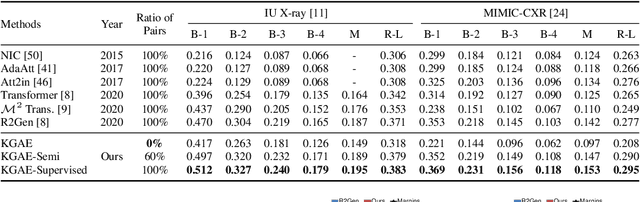
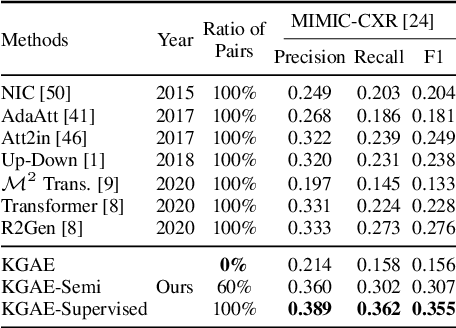

Medical report generation, which aims to automatically generate a long and coherent report of a given medical image, has been receiving growing research interests. Existing approaches mainly adopt a supervised manner and heavily rely on coupled image-report pairs. However, in the medical domain, building a large-scale image-report paired dataset is both time-consuming and expensive. To relax the dependency on paired data, we propose an unsupervised model Knowledge Graph Auto-Encoder (KGAE) which accepts independent sets of images and reports in training. KGAE consists of a pre-constructed knowledge graph, a knowledge-driven encoder and a knowledge-driven decoder. The knowledge graph works as the shared latent space to bridge the visual and textual domains; The knowledge-driven encoder projects medical images and reports to the corresponding coordinates in this latent space and the knowledge-driven decoder generates a medical report given a coordinate in this space. Since the knowledge-driven encoder and decoder can be trained with independent sets of images and reports, KGAE is unsupervised. The experiments show that the unsupervised KGAE generates desirable medical reports without using any image-report training pairs. Moreover, KGAE can also work in both semi-supervised and supervised settings, and accept paired images and reports in training. By further fine-tuning with image-report pairs, KGAE consistently outperforms the current state-of-the-art models on two datasets.