 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Screentone-Preserved Manga Retargeting
Mar 07, 2022

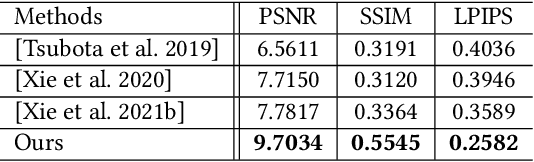
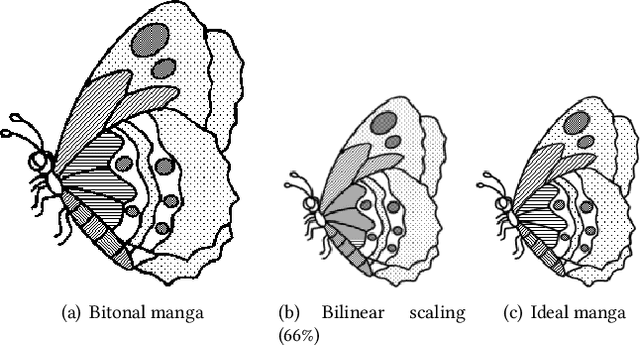
As a popular comic style, manga offers a unique impression by utilizing a rich set of bitonal patterns, or screentones, for illustration. However, screentones can easily be contaminated with visual-unpleasant aliasing and/or blurriness after resampling, which harms its visualization on displays of diverse resolutions. To address this problem, we propose the first manga retargeting method that synthesizes a rescaled manga image while retaining the screentone in each screened region. This is a non-trivial task as accurate region-wise segmentation remains challenging. Fortunately, the rescaled manga shares the same region-wise screentone correspondences with the original manga, which enables us to simplify the screentone synthesis problem as an anchor-based proposals selection and rearrangement problem. Specifically, we design a novel manga sampling strategy to generate aliasing-free screentone proposals, based on hierarchical grid-based anchors that connect the correspondences between the original and the target rescaled manga. Furthermore, a Recurrent Proposal Selection Module (RPSM) is proposed to adaptively integrate these proposals for target screentone synthesis. Besides, to deal with the translation insensitivity nature of screentones, we propose a translation-invariant screentone loss to facilitate the training convergence. Extensive qualitative and quantitative experiments are conducted to verify the effectiveness of our method, and notably compelling results are achieved compared to existing alternative techniques.
Model-Based Reconstruction for Collimated Beam Ultrasound Systems
Feb 20, 2022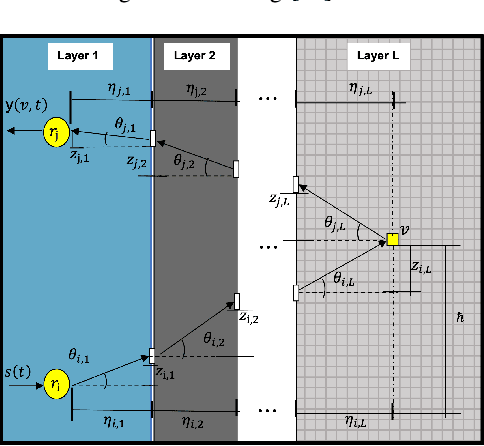
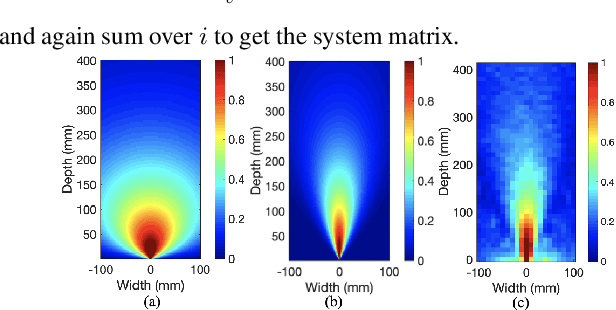
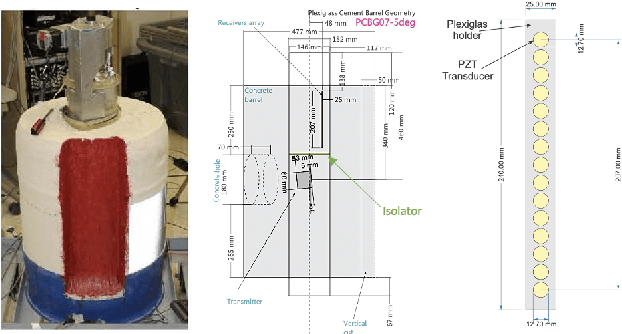
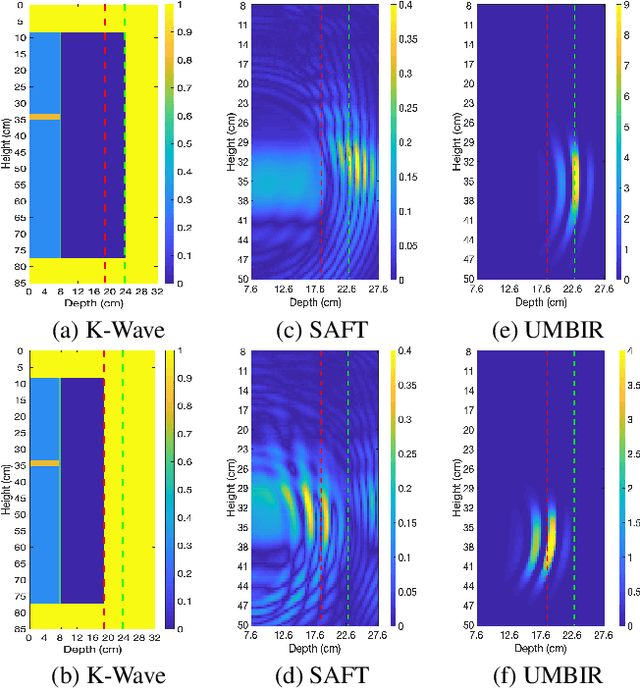
Collimated beam ultrasound systems are a novel technology for imaging inside multi-layered structures such as geothermal wells. Such systems include a transmitter and multiple receivers to capture reflected signals. Common algorithms for ultrasound reconstruction use delay-and-sum (DAS) approaches; these have low computational complexity but produce inaccurate images in the presence of complex structures and specialized geometries such as collimated beams. In this paper, we propose a multi-layer, ultrasonic, model-based iterative reconstruction algorithm designed for collimated beam systems. We introduce a physics-based forward model to accurately account for the propagation of a collimated ultrasonic beam in multi-layer media and describe an efficient implementation using binary search. We model direct arrival signals, detector noise, and a spatially varying image prior, then cast the reconstruction as a maximum a posteriori estimation problem. Using simulated and experimental data we obtain significantly fewer artifacts relative to DAS while running in near real time using commodity compute resources.
How to Fill the Optimum Set? Population Gradient Descent with Harmless Diversity
Feb 16, 2022
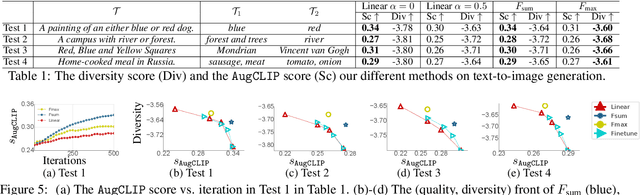
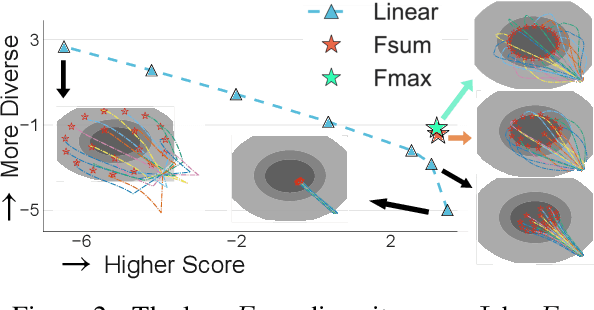

Although traditional optimization methods focus on finding a single optimal solution, most objective functions in modern machine learning problems, especially those in deep learning, often have multiple or infinite numbers of optima. Therefore, it is useful to consider the problem of finding a set of diverse points in the optimum set of an objective function. In this work, we frame this problem as a bi-level optimization problem of maximizing a diversity score inside the optimum set of the main loss function, and solve it with a simple population gradient descent framework that iteratively updates the points to maximize the diversity score in a fashion that does not hurt the optimization of the main loss. We demonstrate that our method can efficiently generate diverse solutions on a variety of applications, including text-to-image generation, text-to-mesh generation, molecular conformation generation and ensemble neural network training.
TerraPN: Unstructured Terrain Navigation using Online Self-Supervised Learning
Mar 11, 2022
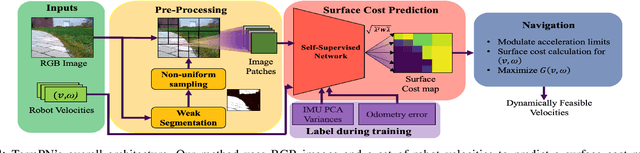
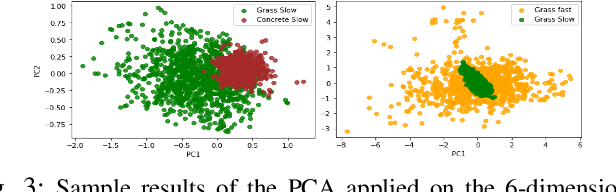
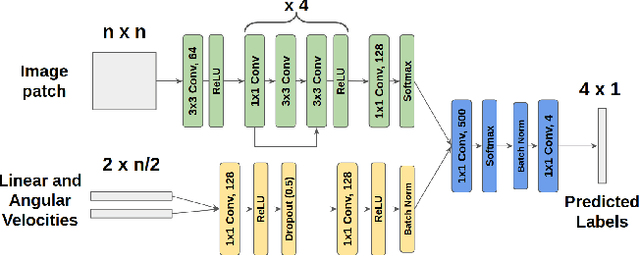
We present TerraPN, a novel method that learns the surface properties (traction, bumpiness, deformability, etc.) of complex outdoor terrains directly from robot-terrain interactions through self-supervised learning, and uses it for autonomous robot navigation. Our method uses RGB images of terrain surfaces and the robot's velocities as inputs, and the IMU vibrations and odometry errors experienced by the robot as labels for self-supervision. Our method computes a surface cost map that differentiates smooth, high-traction surfaces (low navigation costs) from bumpy, slippery, deformable surfaces (high navigation costs). We compute the cost map by non-uniformly sampling patches from the input RGB image by detecting boundaries between surfaces resulting in low inference times (47.27% lower) compared to uniform sampling and existing segmentation methods. We present a novel navigation algorithm that accounts for a surface's cost, computes cost-based acceleration limits for the robot, and dynamically feasible, collision-free trajectories. TerraPN's surface cost prediction can be trained in ~25 minutes for five different surfaces, compared to several hours for previous learning-based segmentation methods. In terms of navigation, our method outperforms previous works in terms of success rates (up to 35.84% higher), vibration cost of the trajectories (up to 21.52% lower), and slowing the robot on bumpy, deformable surfaces (up to 46.76% slower) in different scenarios.
ADVISE: ADaptive Feature Relevance and VISual Explanations for Convolutional Neural Networks
Mar 02, 2022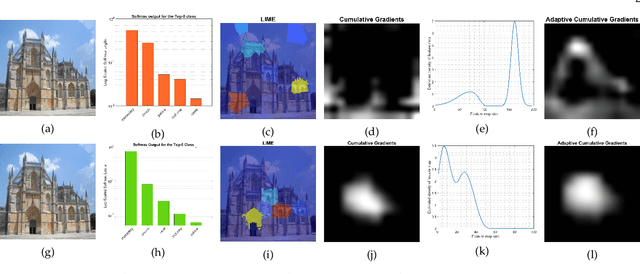
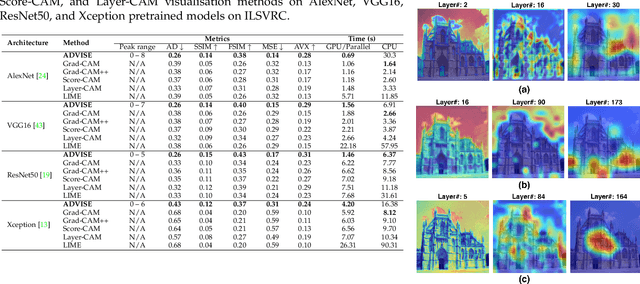
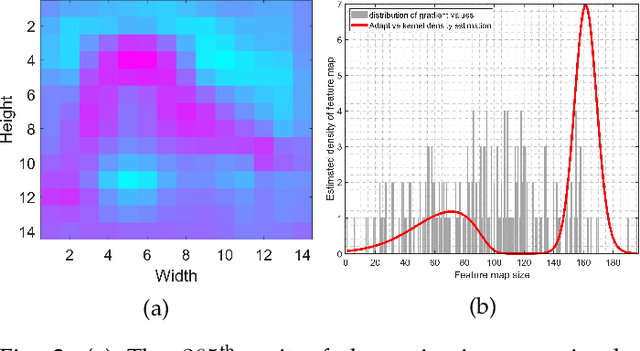
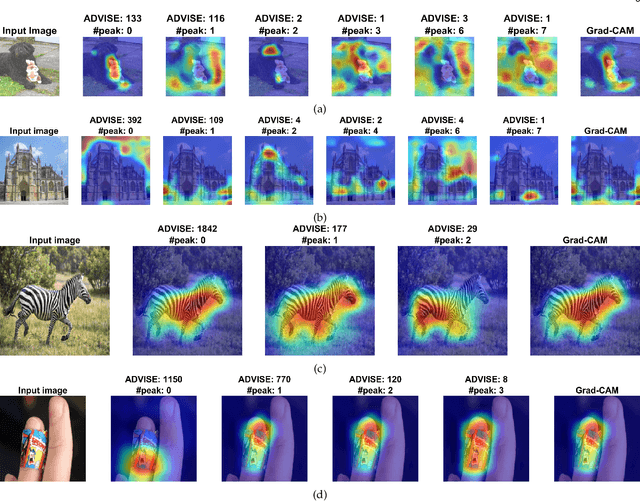
To equip Convolutional Neural Networks (CNNs) with explainability, it is essential to interpret how opaque models take specific decisions, understand what causes the errors, improve the architecture design, and identify unethical biases in the classifiers. This paper introduces ADVISE, a new explainability method that quantifies and leverages the relevance of each unit of the feature map to provide better visual explanations. To this end, we propose using adaptive bandwidth kernel density estimation to assign a relevance score to each unit of the feature map with respect to the predicted class. We also propose an evaluation protocol to quantitatively assess the visual explainability of CNN models. We extensively evaluate our idea in the image classification task using AlexNet, VGG16, ResNet50, and Xception pretrained on ImageNet. We compare ADVISE with the state-of-the-art visual explainable methods and show that the proposed method outperforms competing approaches in quantifying feature-relevance and visual explainability while maintaining competitive time complexity. Our experiments further show that ADVISE fulfils the sensitivity and implementation independence axioms while passing the sanity checks. The implementation is accessible for reproducibility purposes on https://github.com/dehshibi/ADVISE.
Deep Image Prior for Sparse-sampling Photoacoustic Microscopy
Oct 15, 2020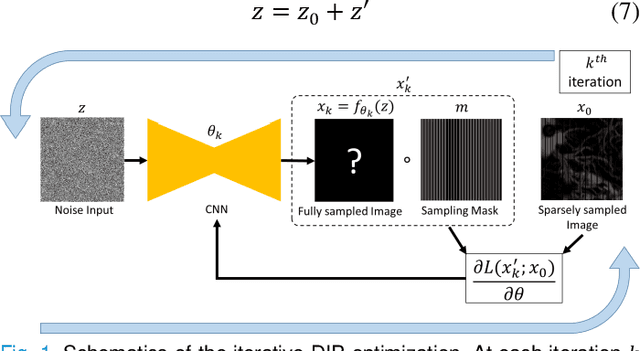
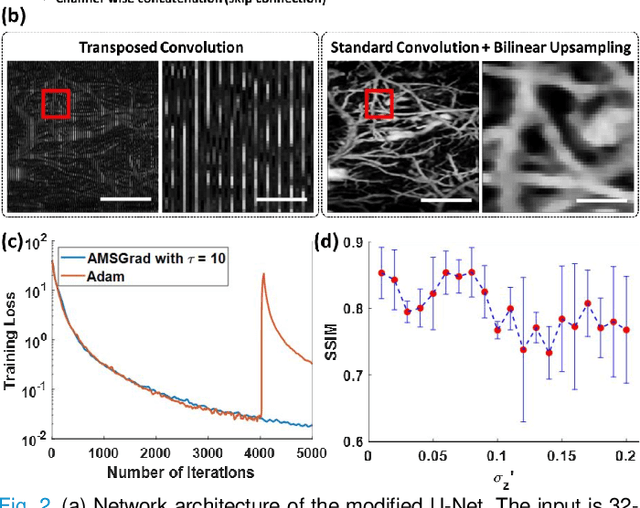
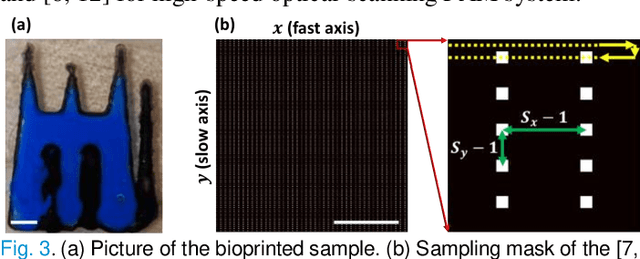
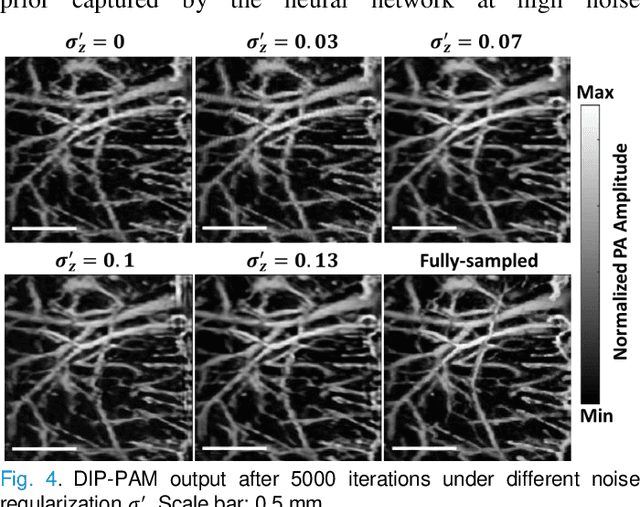
Photoacoustic microscopy (PAM) is an emerging method for imaging both structural and functional information without the need for exogenous contrast agents. However, state-of-the-art PAM faces a tradeoff between imaging speed and spatial sampling density within the same field-of-view (FOV). Limited by the pulsed laser's repetition rate, the imaging speed is inversely proportional to the total number of effective pixels. To cover the same FOV in a shorter amount of time with the same PAM hardware, there is currently no other option than to decrease spatial sampling density (i.e., sparse sampling). Deep learning methods have recently been used to improve sparsely sampled PAM images; however, these methods often require time-consuming pre-training and a large training dataset that has fully sampled, co-registered ground truth. In this paper, we propose using a method known as "deep image prior" to improve the image quality of sparsely sampled PAM images. The network does not need prior learning or fully sampled ground truth, making its implementation more flexible and much quicker. Our results show promising improvement in PA vasculature images with as few as 2% of the effective pixels. Our deep image prior approach produces results that outperform interpolation methods and can be readily translated to other high-speed, sparse-sampling imaging modalities.
Incorporating Texture Information into Dimensionality Reduction for High-Dimensional Images
Mar 02, 2022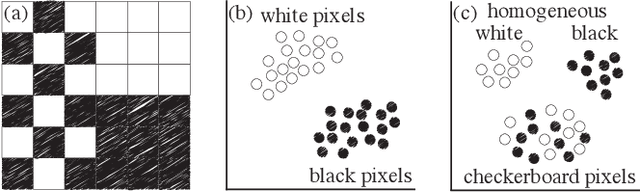
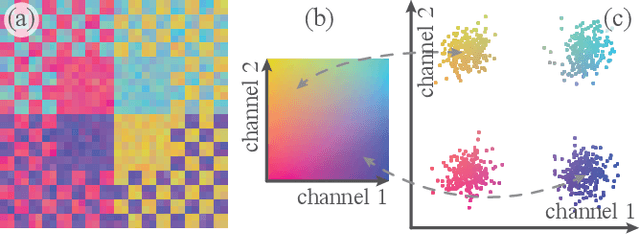
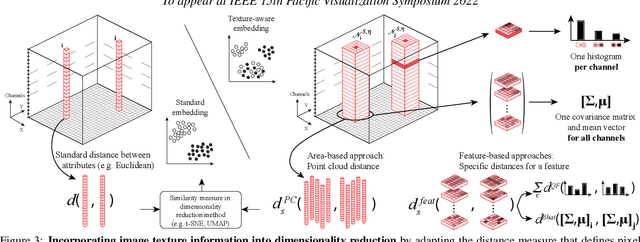
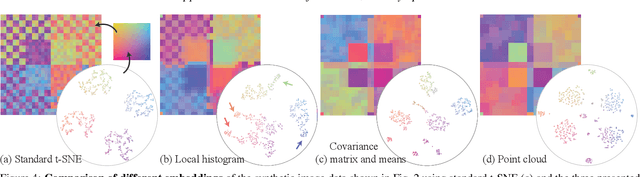
High-dimensional imaging is becoming increasingly relevant in many fields from astronomy and cultural heritage to systems biology. Visual exploration of such high-dimensional data is commonly facilitated by dimensionality reduction. However, common dimensionality reduction methods do not include spatial information present in images, such as local texture features, into the construction of low-dimensional embeddings. Consequently, exploration of such data is typically split into a step focusing on the attribute space followed by a step focusing on spatial information, or vice versa. In this paper, we present a method for incorporating spatial neighborhood information into distance-based dimensionality reduction methods, such as t-Distributed Stochastic Neighbor Embedding (t-SNE). We achieve this by modifying the distance measure between high-dimensional attribute vectors associated with each pixel such that it takes the pixel's spatial neighborhood into account. Based on a classification of different methods for comparing image patches, we explore a number of different approaches. We compare these approaches from a theoretical and experimental point of view. Finally, we illustrate the value of the proposed methods by qualitative and quantitative evaluation on synthetic data and two real-world use cases.
Robust Segmentation of Brain MRI in the Wild with Hierarchical CNNs and no Retraining
Mar 07, 2022


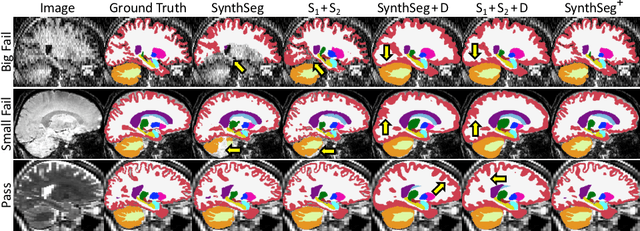
Retrospective analysis of brain MRI scans acquired in the clinic has the potential to enable neuroimaging studies with sample sizes much larger than those found in research datasets. However, analysing such clinical images "in the wild" is challenging, since subjects are scanned with highly variable protocols (MR contrast, resolution, orientation, etc.). Nevertheless, recent advances in convolutional neural networks (CNNs) and domain randomisation for image segmentation, best represented by the publicly available method SynthSeg, may enable morphometry of clinical MRI at scale. In this work, we first evaluate SynthSeg on an uncurated, heterogeneous dataset of more than 10,000 scans acquired at Massachusetts General Hospital. We show that SynthSeg is generally robust, but frequently falters on scans with low signal-to-noise ratio or poor tissue contrast. Next, we propose SynthSeg+, a novel method that greatly mitigates these problems using a hierarchy of conditional segmentation and denoising CNNs. We show that this method is considerably more robust than SynthSeg, while also outperforming cascaded networks and state-of-the-art segmentation denoising methods. Finally, we apply our approach to a proof-of-concept volumetric study of ageing, where it closely replicates atrophy patterns observed in research studies conducted on high-quality, 1mm, T1-weighted scans. The code and trained model are publicly available at https://github.com/BBillot/SynthSeg.
Semi-Supervised Hybrid Spine Network for Segmentation of Spine MR Images
Mar 23, 2022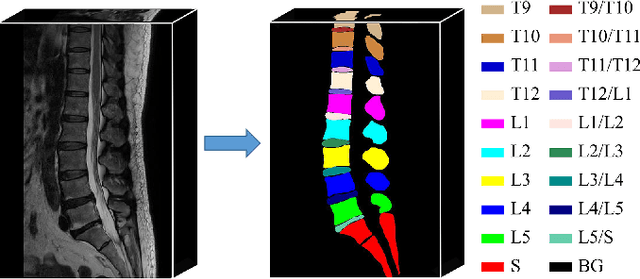
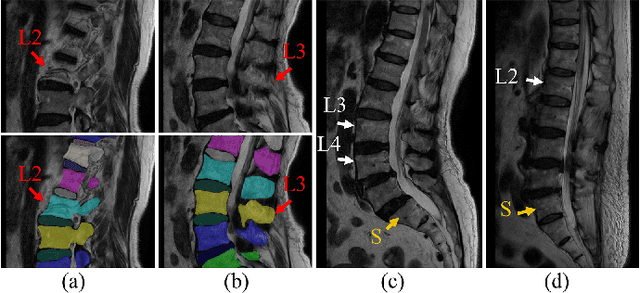
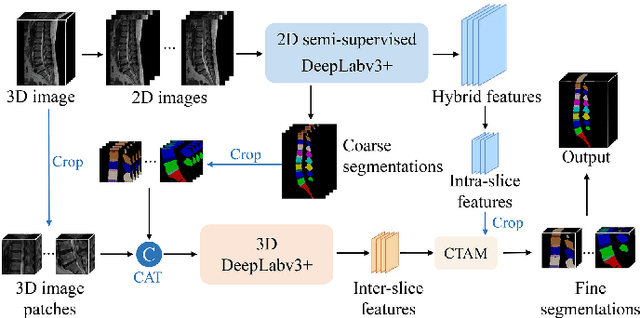
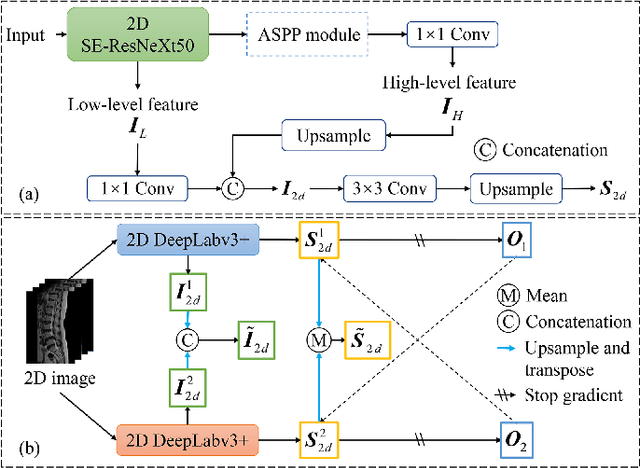
Automatic segmentation of vertebral bodies (VBs) and intervertebral discs (IVDs) in 3D magnetic resonance (MR) images is vital in diagnosing and treating spinal diseases. However, segmenting the VBs and IVDs simultaneously is not trivial. Moreover, problems exist, including blurry segmentation caused by anisotropy resolution, high computational cost, inter-class similarity and intra-class variability, and data imbalances. We proposed a two-stage algorithm, named semi-supervised hybrid spine network (SSHSNet), to address these problems by achieving accurate simultaneous VB and IVD segmentation. In the first stage, we constructed a 2D semi-supervised DeepLabv3+ by using cross pseudo supervision to obtain intra-slice features and coarse segmentation. In the second stage, a 3D full-resolution patch-based DeepLabv3+ was built. This model can be used to extract inter-slice information and combine the coarse segmentation and intra-slice features provided from the first stage. Moreover, a cross tri-attention module was applied to compensate for the loss of inter-slice and intra-slice information separately generated from 2D and 3D networks, thereby improving feature representation ability and achieving satisfactory segmentation results. The proposed SSHSNet was validated on a publicly available spine MR image dataset, and remarkable segmentation performance was achieved. Moreover, results show that the proposed method has great potential in dealing with the data imbalance problem. Based on previous reports, few studies have incorporated a semi-supervised learning strategy with a cross attention mechanism for spine segmentation. Therefore, the proposed method may provide a useful tool for spine segmentation and aid clinically in spinal disease diagnoses and treatments. Codes are publicly available at: https://github.com/Meiyan88/SSHSNet.
Improving Text to Image Generation using Mode-seeking Function
Sep 18, 2020
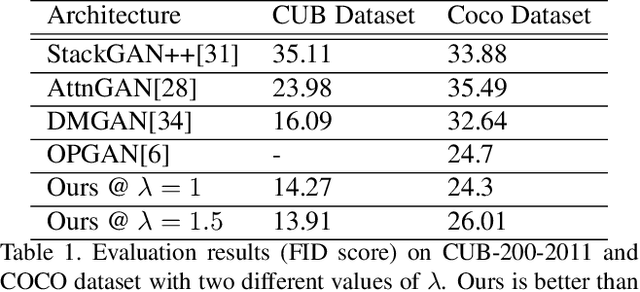


Generative Adversarial Networks (GANs) have long been used to understand the semantic relationship between the text and image. However, there are problems with mode collapsing in the image generation that causes some preferred output modes. Our aim is to improve the training of the network by using a specialized mode-seeking loss function to avoid this issue. In the text to image synthesis, our loss function differentiates two points in latent space for the generation of distinct images. We validate our model on the Caltech Birds (CUB) dataset and the Microsoft COCO dataset by changing the intensity of the loss function during the training. Experimental results demonstrate that our model works very well compared to some state-of-the-art approaches.