 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Choosing an Appropriate Platform and Workflow for Processing Camera Trap Data using Artificial Intelligence
Feb 04, 2022
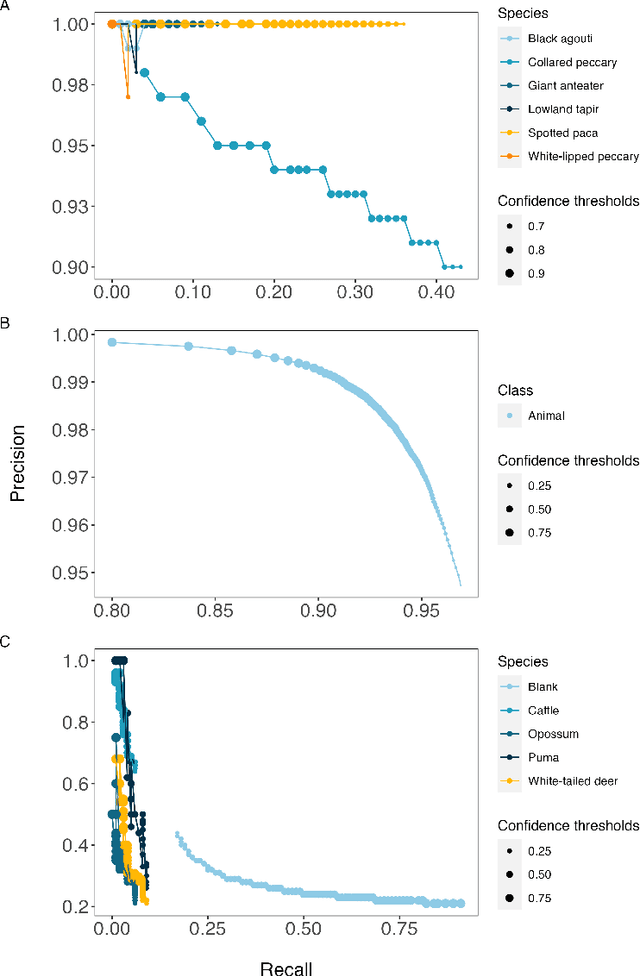

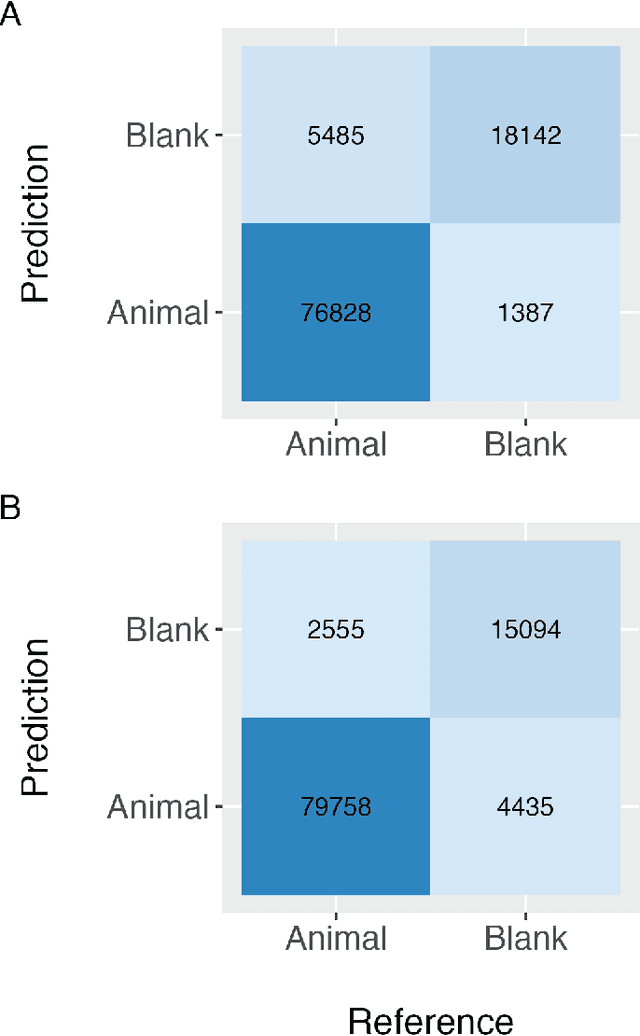
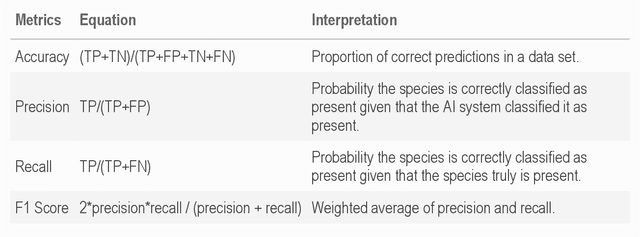
Camera traps have transformed how ecologists study wildlife species distributions, activity patterns, and interspecific interactions. Although camera traps provide a cost-effective method for monitoring species, the time required for data processing can limit survey efficiency. Thus, the potential of Artificial Intelligence (AI), specifically Deep Learning (DL), to process camera-trap data has gained considerable attention. Using DL for these applications involves training algorithms, such as Convolutional Neural Networks (CNNs), to automatically detect objects and classify species. To overcome technical challenges associated with training CNNs, several research communities have recently developed platforms that incorporate DL in easy-to-use interfaces. We review key characteristics of four AI-powered platforms -- Wildlife Insights (WI), MegaDetector (MD), Machine Learning for Wildlife Image Classification (MLWIC2), and Conservation AI -- including data management tools and AI features. We also provide R code in an open-source GitBook, to demonstrate how users can evaluate model performance, and incorporate AI output in semi-automated workflows. We found that species classifications from WI and MLWIC2 generally had low recall values (animals that were present in the images often were not classified to the correct species). Yet, the precision of WI and MLWIC2 classifications for some species was high (i.e., when classifications were made, they were generally accurate). MD, which classifies images using broader categories (e.g., "blank" or "animal"), also performed well. Thus, we conclude that, although species classifiers were not accurate enough to automate image processing, DL could be used to improve efficiencies by accepting classifications with high confidence values for certain species or by filtering images containing blanks.
A unified 3D framework for Organs at Risk Localization and Segmentation for Radiation Therapy Planning
Mar 01, 2022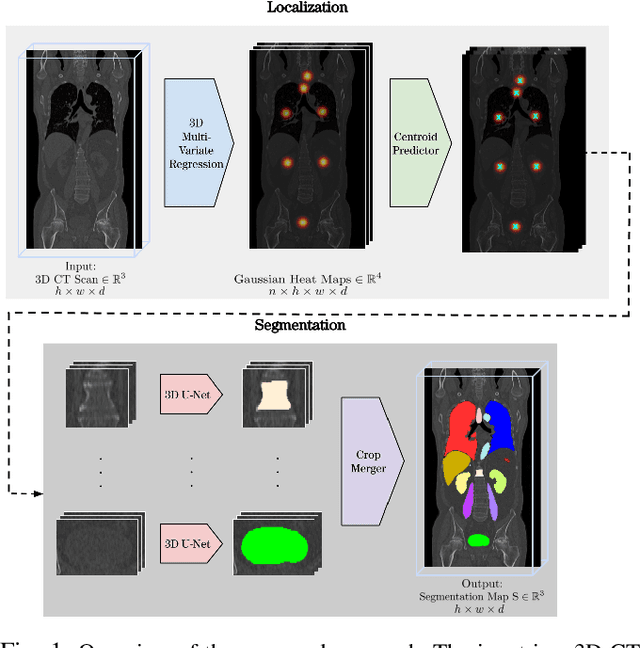
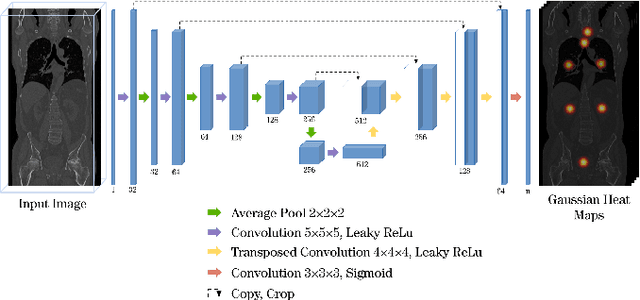
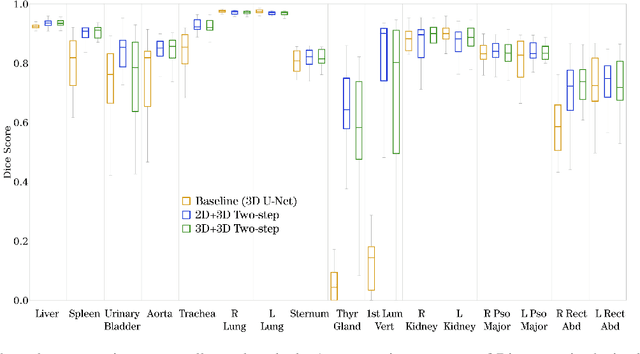
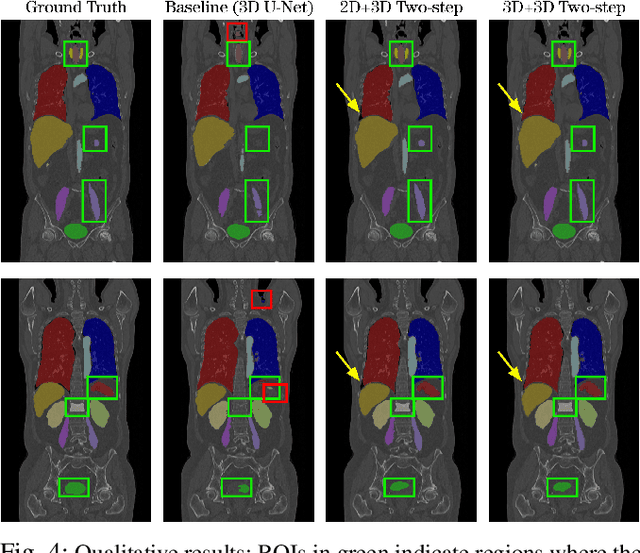
Automatic localization and segmentation of organs-at-risk (OAR) in CT are essential pre-processing steps in medical image analysis tasks, such as radiation therapy planning. For instance, the segmentation of OAR surrounding tumors enables the maximization of radiation to the tumor area without compromising the healthy tissues. However, the current medical workflow requires manual delineation of OAR, which is prone to errors and is annotator-dependent. In this work, we aim to introduce a unified 3D pipeline for OAR localization-segmentation rather than novel localization or segmentation architectures. To the best of our knowledge, our proposed framework fully enables the exploitation of 3D context information inherent in medical imaging. In the first step, a 3D multi-variate regression network predicts organs' centroids and bounding boxes. Secondly, 3D organ-specific segmentation networks are leveraged to generate a multi-organ segmentation map. Our method achieved an overall Dice score of $0.9260\pm 0.18 \%$ on the VISCERAL dataset containing CT scans with varying fields of view and multiple organs.
Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
Feb 17, 2021
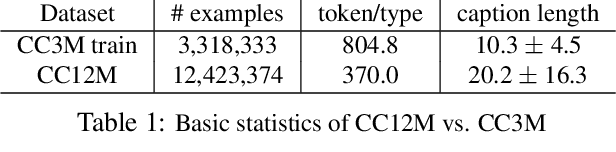

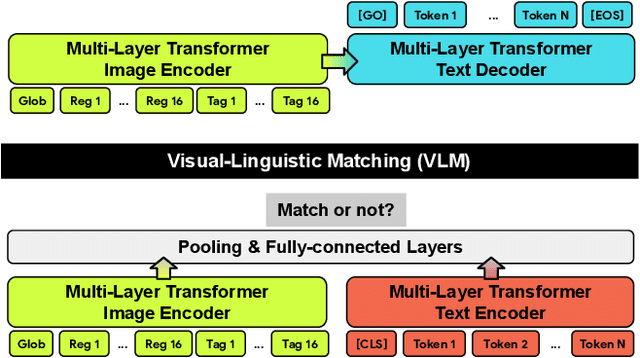
The availability of large-scale image captioning and visual question answering datasets has contributed significantly to recent successes in vision-and-language pre-training. However, these datasets are often collected with overrestrictive requirements, inherited from their original target tasks (e.g., image caption generation), which limit the resulting dataset scale and diversity. We take a step further in pushing the limits of vision-and-language pre-training data by relaxing the data collection pipeline used in Conceptual Captions 3M (CC3M) [Sharma et al. 2018] and introduce the Conceptual 12M (CC12M), a dataset with 12 million image-text pairs specifically meant to be used for vision-and-language pre-training. We perform an analysis of this dataset, as well as benchmark its effectiveness against CC3M on multiple downstream tasks with an emphasis on long-tail visual recognition. The quantitative and qualitative results clearly illustrate the benefit of scaling up pre-training data for vision-and-language tasks, as indicated by the new state-of-the-art results on both the nocaps and Conceptual Captions benchmarks.
Learning Occlusion-Aware Coarse-to-Fine Depth Map for Self-supervised Monocular Depth Estimation
Mar 21, 2022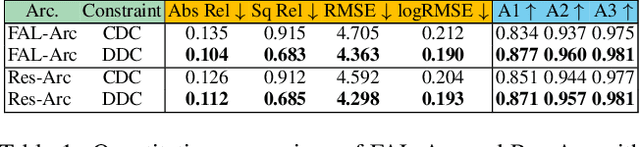
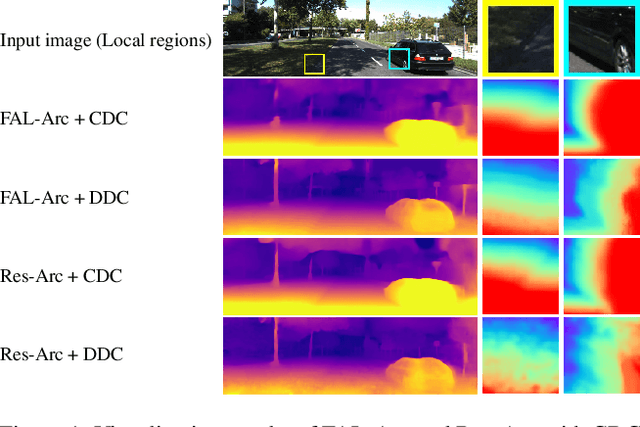
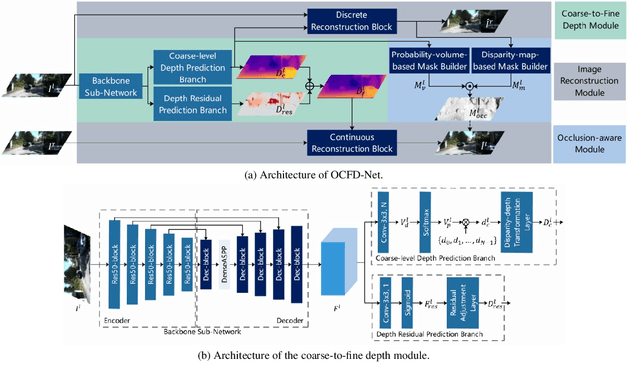
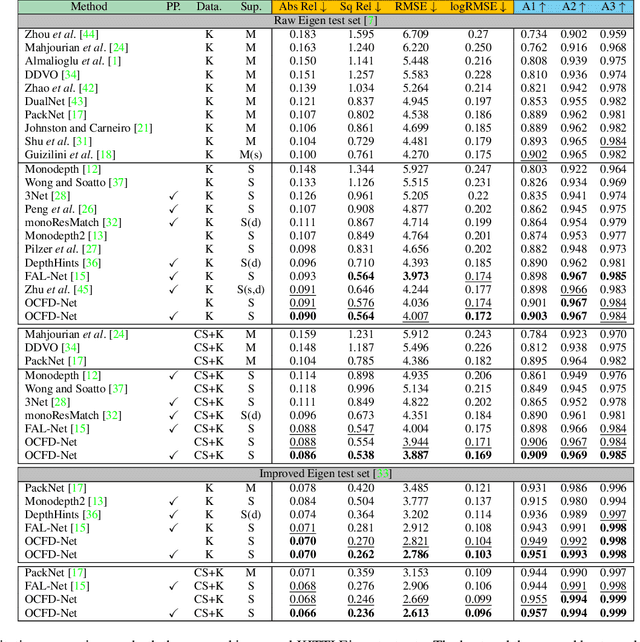
Self-supervised monocular depth estimation, aiming to learn scene depths from single images in a self-supervised manner, has received much attention recently. In spite of recent efforts in this field, how to learn accurate scene depths and alleviate the negative influence of occlusions for self-supervised depth estimation, still remains an open problem. Addressing this problem, we firstly empirically analyze the effects of both the continuous and discrete depth constraints which are widely used in the training process of many existing works. Then inspired by the above empirical analysis, we propose a novel network to learn an Occlusion-aware Coarse-to-Fine Depth map for self-supervised monocular depth estimation, called OCFD-Net. Given an arbitrary training set of stereo image pairs, the proposed OCFD-Net does not only employ a discrete depth constraint for learning a coarse-level depth map, but also employ a continuous depth constraint for learning a scene depth residual, resulting in a fine-level depth map. In addition, an occlusion-aware module is designed under the proposed OCFD-Net, which is able to improve the capability of the learnt fine-level depth map for handling occlusions. Extensive experimental results on the public KITTI and Make3D datasets demonstrate that the proposed method outperforms 20 existing state-of-the-art methods in most cases.
Quality Map Fusion for Adversarial Learning
Oct 24, 2021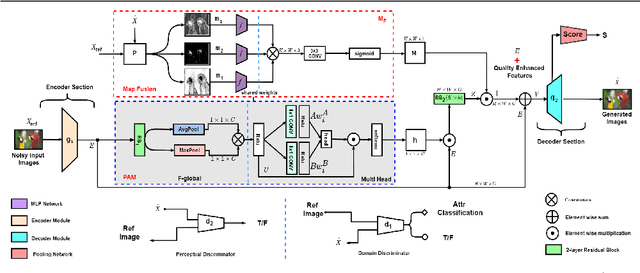
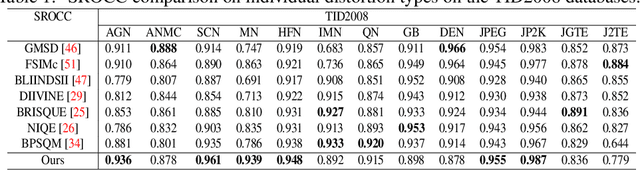
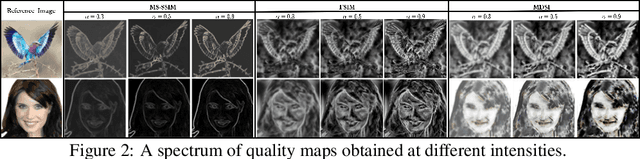
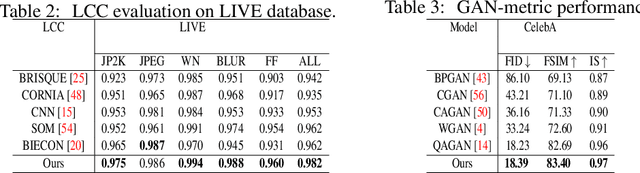
Generative adversarial models that capture salient low-level features which convey visual information in correlation with the human visual system (HVS) still suffer from perceptible image degradations. The inability to convey such highly informative features can be attributed to mode collapse, convergence failure and vanishing gradients. In this paper, we improve image quality adversarially by introducing a novel quality map fusion technique that harnesses image features similar to the HVS and the perceptual properties of a deep convolutional neural network (DCNN). We extend the widely adopted l2 Wasserstein distance metric to other preferable quality norms derived from Banach spaces that capture richer image properties like structure, luminance, contrast and the naturalness of images. We also show that incorporating a perceptual attention mechanism (PAM) that extracts global feature embeddings from the network bottleneck with aggregated perceptual maps derived from standard image quality metrics translate to a better image quality. We also demonstrate impressive performance over other methods.
Boundary Corrected Multi-scale Fusion Network for Real-time Semantic Segmentation
Mar 01, 2022

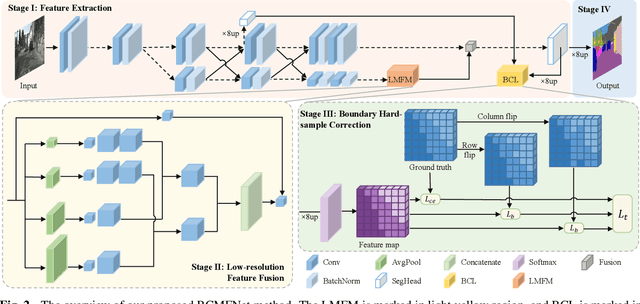
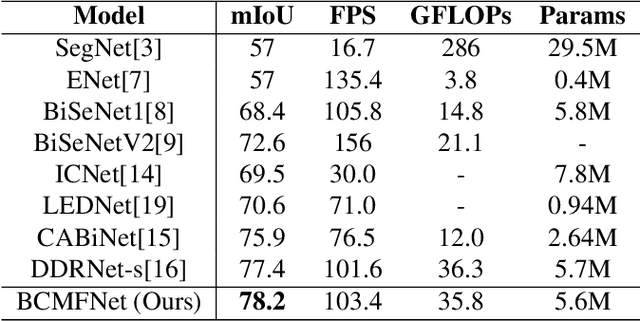
Image semantic segmentation aims at the pixel-level classification of images, which has requirements for both accuracy and speed in practical application. Existing semantic segmentation methods mainly rely on the high-resolution input to achieve high accuracy and do not meet the requirements of inference time. Although some methods focus on high-speed scene parsing with lightweight architectures, they can not fully mine semantic features under low computation with relatively low performance. To realize the real-time and high-precision segmentation, we propose a new method named Boundary Corrected Multi-scale Fusion Network, which uses the designed Low-resolution Multi-scale Fusion Module to extract semantic information. Moreover, to deal with boundary errors caused by low-resolution feature map fusion, we further design an additional Boundary Corrected Loss to constrain overly smooth features. Extensive experiments show that our method achieves a state-of-the-art balance of accuracy and speed for the real-time semantic segmentation.
Ensembling object detectors for image and video data analysis
Feb 09, 2021
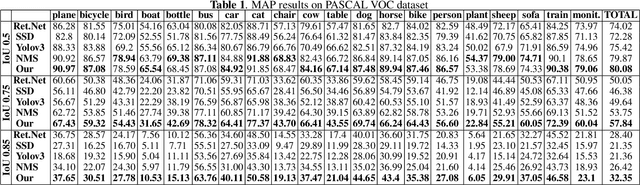

In this paper, we propose a method for ensembling the outputs of multiple object detectors for improving detection performance and precision of bounding boxes on image data. We further extend it to video data by proposing a two-stage tracking-based scheme for detection refinement. The proposed method can be used as a standalone approach for improving object detection performance, or as a part of a framework for faster bounding box annotation in unseen datasets, assuming that the objects of interest are those present in some common public datasets.
COROLLA: An Efficient Multi-Modality Fusion Framework with Supervised Contrastive Learning for Glaucoma Grading
Jan 11, 2022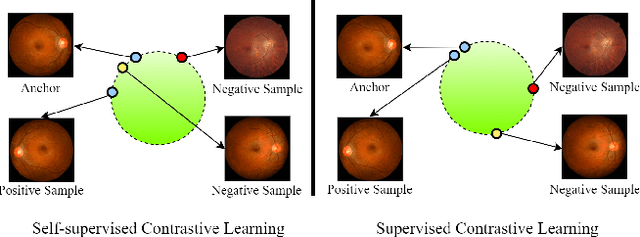
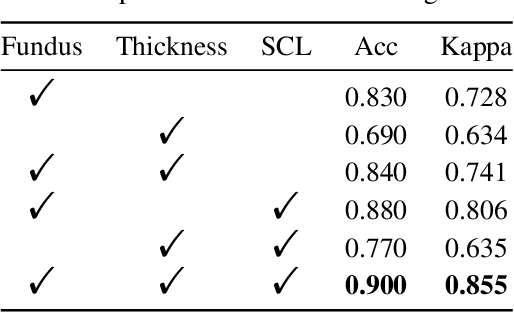
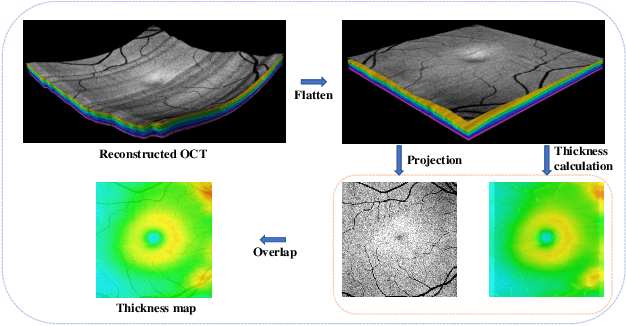
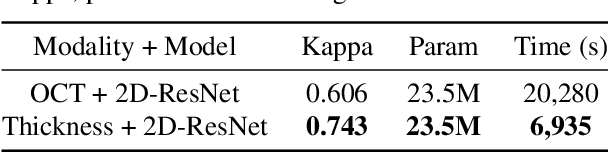
Glaucoma is one of the ophthalmic diseases that may cause blindness, for which early detection and treatment are very important. Fundus images and optical coherence tomography (OCT) images are both widely-used modalities in diagnosing glaucoma. However, existing glaucoma grading approaches mainly utilize a single modality, ignoring the complementary information between fundus and OCT. In this paper, we propose an efficient multi-modality supervised contrastive learning framework, named COROLLA, for glaucoma grading. Through layer segmentation as well as thickness calculation and projection, retinal thickness maps are extracted from the original OCT volumes and used as a replacing modality, resulting in more efficient calculations with less memory usage. Given the high structure and distribution similarities across medical image samples, we employ supervised contrastive learning to increase our models' discriminative power with better convergence. Moreover, feature-level fusion of paired fundus image and thickness map is conducted for enhanced diagnosis accuracy. On the GAMMA dataset, our COROLLA framework achieves overwhelming glaucoma grading performance compared to state-of-the-art methods.
Improving Across-Dataset Brain Tissue Segmentation Using Transformer
Jan 21, 2022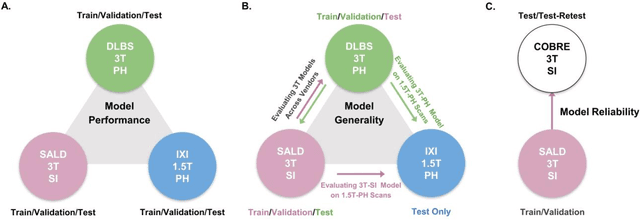
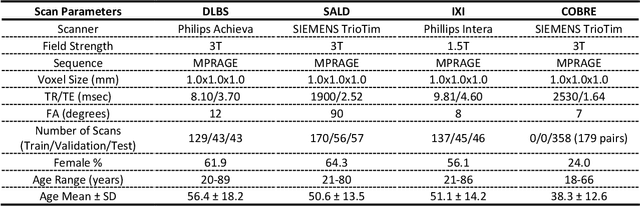
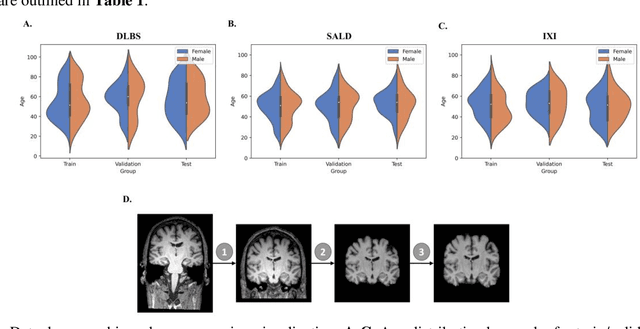
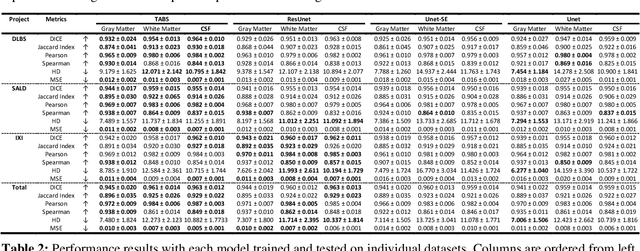
Brain tissue segmentation has demonstrated great utility in quantifying MRI data through Voxel-Based Morphometry and highlighting subtle structural changes associated with various conditions within the brain. However, manual segmentation is highly labor-intensive, and automated approaches have struggled due to properties inherent to MRI acquisition, leaving a great need for an effective segmentation tool. Despite the recent success of deep convolutional neural networks (CNNs) for brain tissue segmentation, many such solutions do not generalize well to new datasets, which is critical for a reliable solution. Transformers have demonstrated success in natural image segmentation and have recently been applied to 3D medical image segmentation tasks due to their ability to capture long-distance relationships in the input where the local receptive fields of CNNs struggle. This study introduces a novel CNN-Transformer hybrid architecture designed for brain tissue segmentation. We validate our model's performance across four multi-site T1w MRI datasets, covering different vendors, field strengths, scan parameters, time points, and neuropsychiatric conditions. In all situations, our model achieved the greatest generality and reliability. Out method is inherently robust and can serve as a valuable tool for brain-related T1w MRI studies. The code for the TABS network is available at: https://github.com/raovish6/TABS.
A deep learning method based on patchwise training for reconstructing temperature field
Jan 26, 2022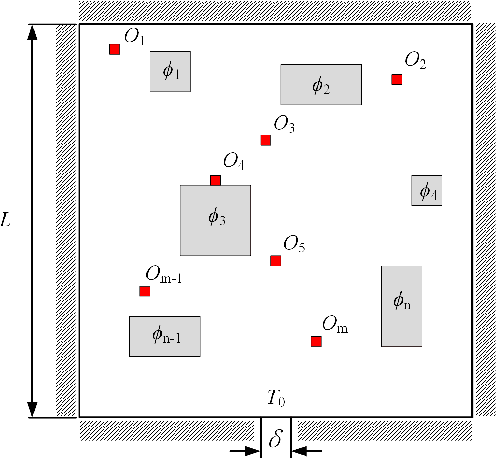
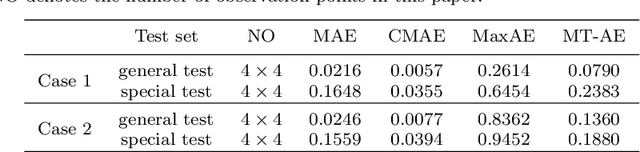
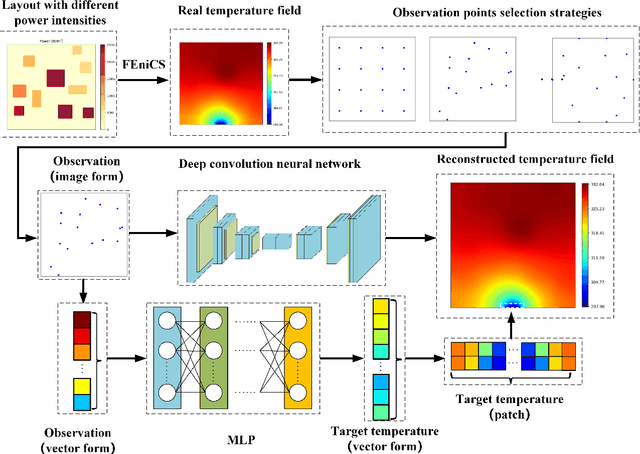

Physical field reconstruction is highly desirable for the measurement and control of engineering systems. The reconstruction of the temperature field from limited observation plays a crucial role in thermal management for electronic equipment. Deep learning has been employed in physical field reconstruction, whereas the accurate estimation for the regions with large gradients is still diffcult. To solve the problem, this work proposes a novel deep learning method based on patchwise training to reconstruct the temperature field of electronic equipment accurately from limited observation. Firstly, the temperature field reconstruction (TFR) problem of the electronic equipment is modeled mathematically and transformed as an image-to-image regression task. Then a patchwise training and inference framework consisting of an adaptive UNet and a shallow multilayer perceptron (MLP) is developed to establish the mapping from the observation to the temperature field. The adaptive UNet is utilized to reconstruct the whole temperature field while the MLP is designed to predict the patches with large temperature gradients. Experiments employing finite element simulation data are conducted to demonstrate the accuracy of the proposed method. Furthermore, the generalization is evaluated by investigating cases under different heat source layouts, different power intensities, and different observation point locations. The maximum absolute errors of the reconstructed temperature field are less than 1K under the patchwise training approach.