 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Quantitative Comparison between Shannon and Tsallis Havrda Charvat Entropies Applied to Cancer Outcome Prediction
Mar 22, 2022
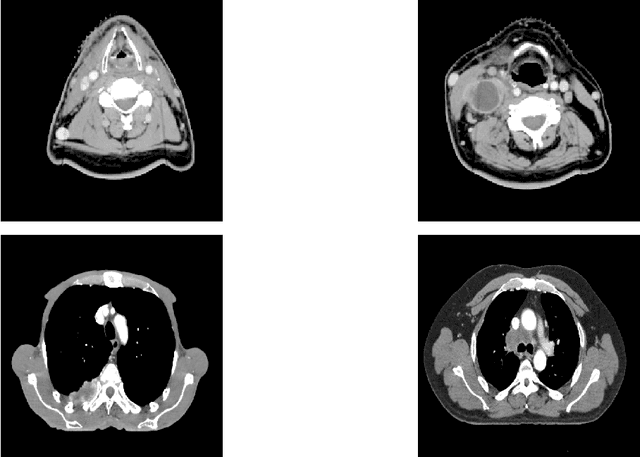
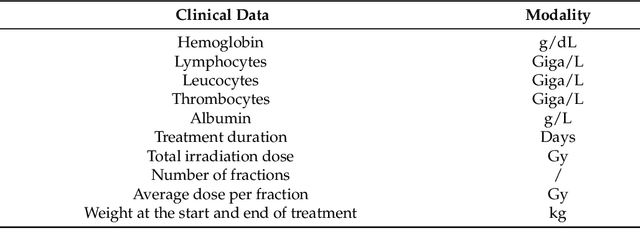
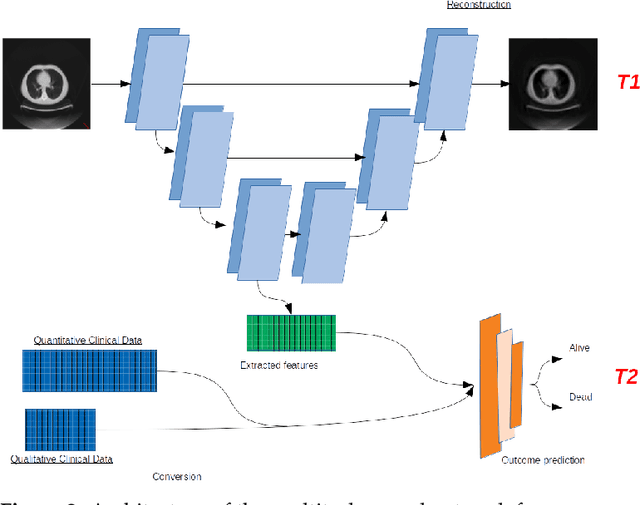

In this paper, we propose to quantitatively compare loss functions based on parameterized Tsallis-Havrda-Charvat entropy and classical Shannon entropy for the training of a deep network in the case of small datasets which are usually encountered in medical applications. Shannon cross-entropy is widely used as a loss function for most neural networks applied to the segmentation, classification and detection of images. Shannon entropy is a particular case of Tsallis-Havrda-Charvat entropy. In this work, we compare these two entropies through a medical application for predicting recurrence in patients with head-neck and lung cancers after treatment. Based on both CT images and patient information, a multitask deep neural network is proposed to perform a recurrence prediction task using cross-entropy as a loss function and an image reconstruction task. Tsallis-Havrda-Charvat cross-entropy is a parameterized cross entropy with the parameter $\alpha$. Shannon entropy is a particular case of Tsallis-Havrda-Charvat entropy for $\alpha$ = 1. The influence of this parameter on the final prediction results is studied. In this paper, the experiments are conducted on two datasets including in total 580 patients, of whom 434 suffered from head-neck cancers and 146 from lung cancers. The results show that Tsallis-Havrda-Charvat entropy can achieve better performance in terms of prediction accuracy with some values of $\alpha$.
* 11 pages, 3 figures
NeILF: Neural Incident Light Field for Physically-based Material Estimation
Mar 18, 2022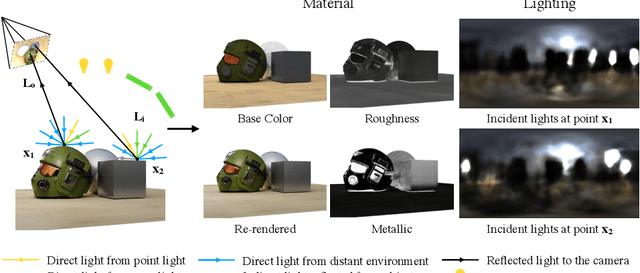
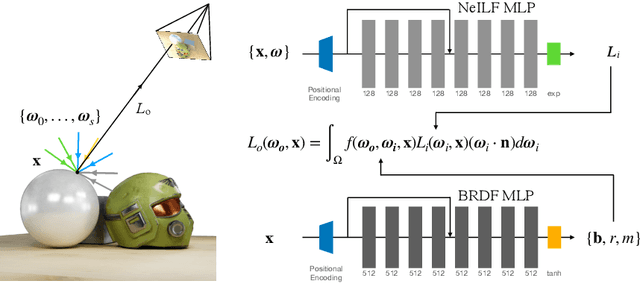

We present a differentiable rendering framework for material and lighting estimation from multi-view images and a reconstructed geometry. In the framework, we represent scene lightings as the Neural Incident Light Field (NeILF) and material properties as the surface BRDF modelled by multi-layer perceptrons. Compared with recent approaches that approximate scene lightings as the 2D environment map, NeILF is a fully 5D light field that is capable of modelling illuminations of any static scenes. In addition, occlusions and indirect lights can be handled naturally by the NeILF representation without requiring multiple bounces of ray tracing, making it possible to estimate material properties even for scenes with complex lightings and geometries. We also propose a smoothness regularization and a Lambertian assumption to reduce the material-lighting ambiguity during the optimization. Our method strictly follows the physically-based rendering equation, and jointly optimizes material and lighting through the differentiable rendering process. We have intensively evaluated the proposed method on our in-house synthetic dataset, the DTU MVS dataset, and real-world BlendedMVS scenes. Our method is able to outperform previous methods by a significant margin in terms of novel view rendering quality, setting a new state-of-the-art for image-based material and lighting estimation.
Unpaired Referring Expression Grounding via Bidirectional Cross-Modal Matching
Jan 18, 2022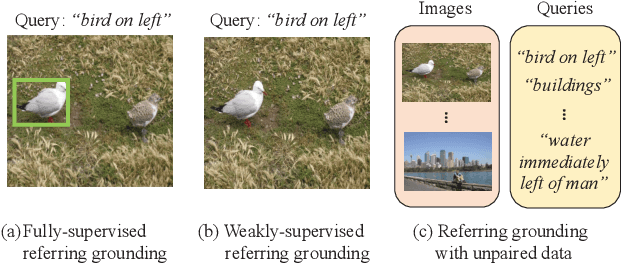
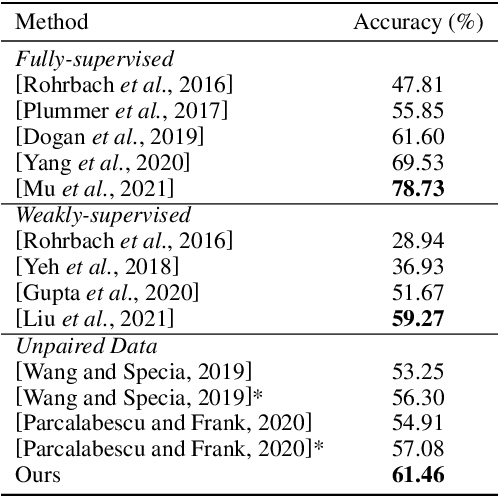
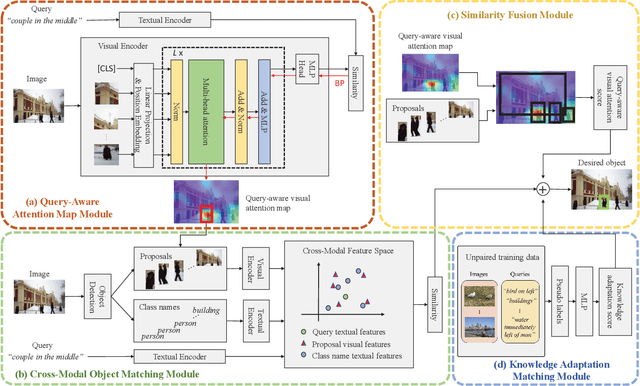
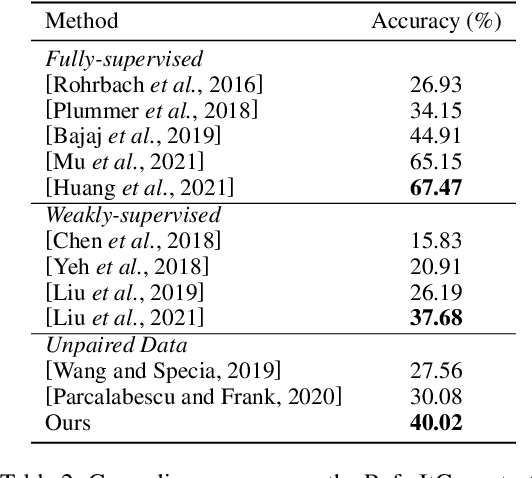
Referring expression grounding is an important and challenging task in computer vision. To avoid the laborious annotation in conventional referring grounding, unpaired referring grounding is introduced, where the training data only contains a number of images and queries without correspondences. The few existing solutions to unpaired referring grounding are still preliminary, due to the challenges of learning image-text matching and lack of the top-down guidance with unpaired data. In this paper, we propose a novel bidirectional cross-modal matching (BiCM) framework to address these challenges. Particularly, we design a query-aware attention map (QAM) module that introduces top-down perspective via generating query-specific visual attention maps. A cross-modal object matching (COM) module is further introduced, which exploits the recently emerged image-text matching pretrained model, CLIP, to predict the target objects from a bottom-up perspective. The top-down and bottom-up predictions are then integrated via a similarity funsion (SF) module. We also propose a knowledge adaptation matching (KAM) module that leverages unpaired training data to adapt pretrained knowledge to the target dataset and task. Experiments show that our framework outperforms previous works by 6.55% and 9.94% on two popular grounding datasets.
Visual Feature Encoding for GNNs on Road Networks
Mar 02, 2022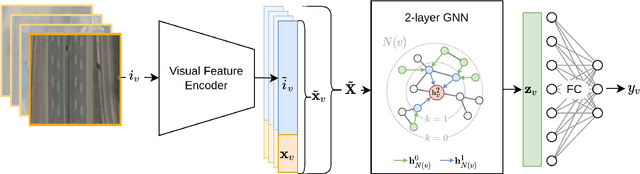
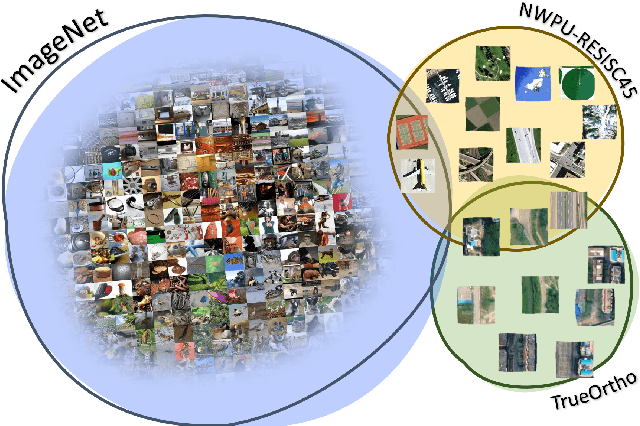
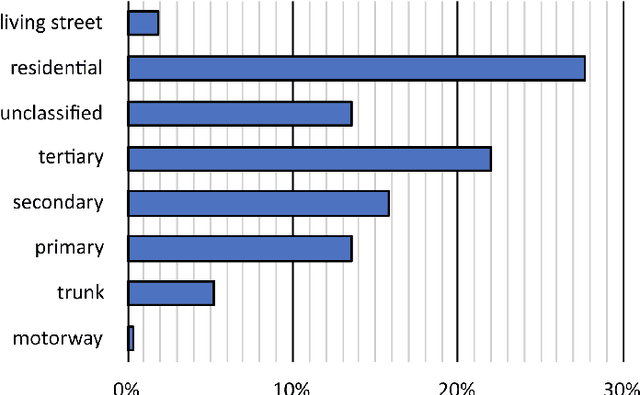
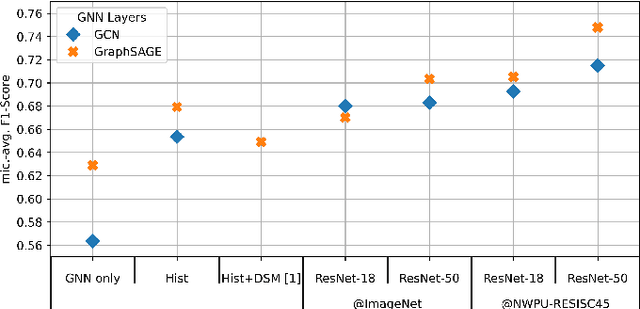
In this work, we present a novel approach to learning an encoding of visual features into graph neural networks with the application on road network data. We propose an architecture that combines state-of-the-art vision backbone networks with graph neural networks. More specifically, we perform a road type classification task on an Open Street Map road network through encoding of satellite imagery using various ResNet architectures. Our architecture further enables fine-tuning and a transfer-learning approach is evaluated by pretraining on the NWPU-RESISC45 image classification dataset for remote sensing and comparing them to purely ImageNet-pretrained ResNet models as visual feature encoders. The results show not only that the visual feature encoders are superior to low-level visual features, but also that the fine-tuning of the visual feature encoder to a general remote sensing dataset such as NWPU-RESISC45 can further improve the performance of a GNN on a machine learning task like road type classification.
Omnidirectional MediA Format (OMAF): Toolbox for Virtual Reality Services
Mar 02, 2022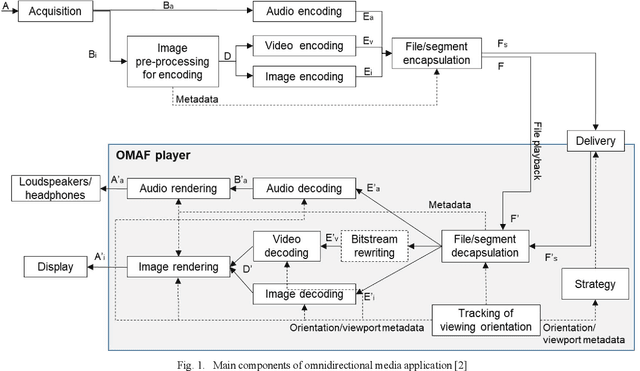
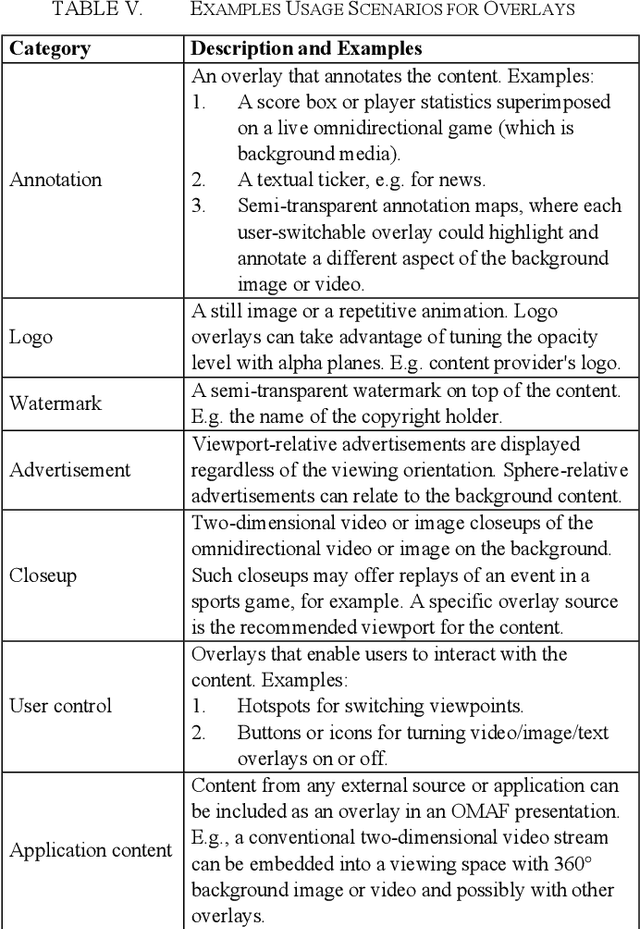
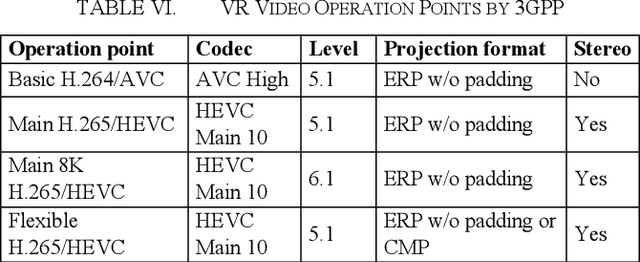
This paper provides an overview of the Omnidirectional Media Format (OMAF) standard, second edition, which has been recently finalized. OMAF specifies the media format for coding, storage, delivery, and rendering of omnidirectional media, including video, audio, images, and timed text. Additionally, OMAF supports multiple viewpoints corresponding to omnidirectional cameras and overlay images or video rendered over the omnidirectional background image or video. Many examples of usage scenarios for multiple viewpoints and overlays are described in the paper. OMAF provides a toolbox of features, which can be selectively used in virtual reality services. Consequently, the paper presents the interoperability points specified in the OMAF standard, which enable signaling which OMAF features are in use or required to be supported in implementations. Finally, the paper summarizes which OMAF interoperability points have been taken into use in virtual reality service specifications by the 3rd Generation Partnership Project (3GPP) and the Virtual Reality Industry Forum (VRIF).
* 7 pages, 1 figure. This document is the accepted version of the paper that has been published in 2021 IEEE Conference on Standards for Communications and Networking (CSCN)
Weakly Supervised Minirhizotron Image Segmentation with MIL-CAM
Jul 30, 2020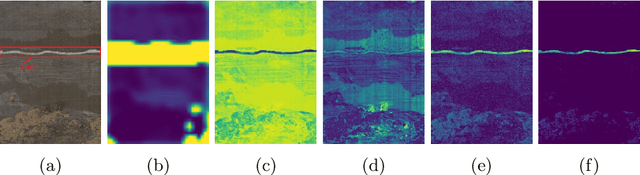
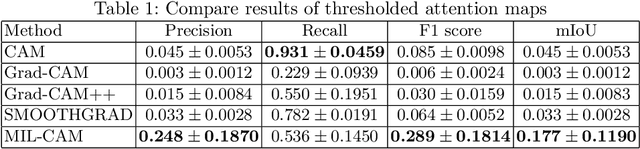
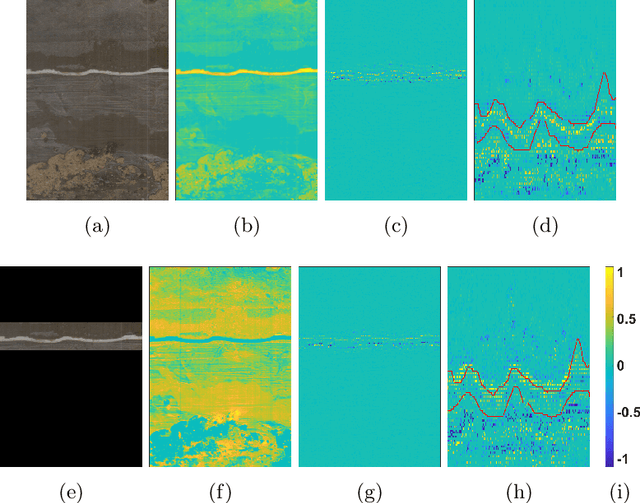
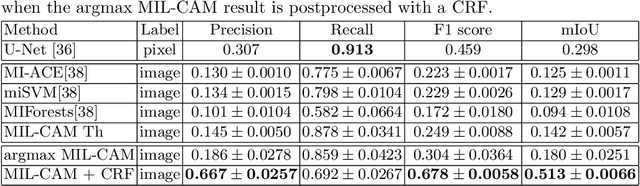
We present a multiple instance learning class activation map (MIL-CAM) approach for pixel-level minirhizotron image segmentation given weak image-level labels. Minirhizotrons are used to image plant roots in situ. Minirhizotron imagery is often composed of soil containing a few long and thin root objects of small diameter. The roots prove to be challenging for existing semantic image segmentation methods to discriminate. In addition to learning from weak labels, our proposed MIL-CAM approach re-weights the root versus soil pixels during analysis for improved performance due to the heavy imbalance between soil and root pixels. The proposed approach outperforms other attention map and multiple instance learning methods for localization of root objects in minirhizotron imagery.
Pyramid Attention Networks for Image Restoration
Apr 28, 2020
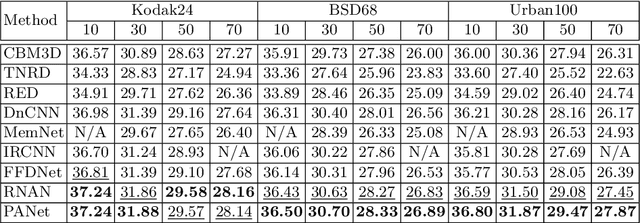
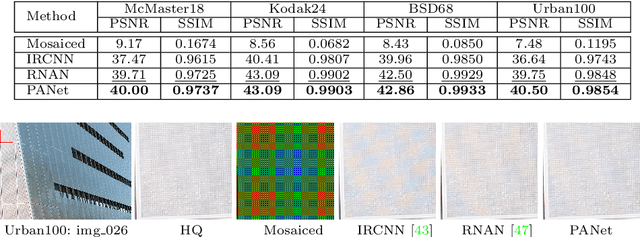
Self-similarity refers to the image prior widely used in image restoration algorithms that small but similar patterns tend to occur at different locations and scales. However, recent advanced deep convolutional neural network based methods for image restoration do not take full advantage of self-similarities by relying on self-attention neural modules that only process information at the same scale. To solve this problem, we present a novel Pyramid Attention module for image restoration, which captures long-range feature correspondences from a multi-scale feature pyramid. Inspired by the fact that corruptions, such as noise or compression artifacts, drop drastically at coarser image scales, our attention module is designed to be able to borrow clean signals from their "clean" correspondences at the coarser levels. The proposed pyramid attention module is a generic building block that can be flexibly integrated into various neural architectures. Its effectiveness is validated through extensive experiments on multiple image restoration tasks: image denoising, demosaicing, compression artifact reduction, and super resolution. Without any bells and whistles, our PANet (pyramid attention module with simple network backbones) can produce state-of-the-art results with superior accuracy and visual quality.
Semantically Grounded Visual Embeddings for Zero-Shot Learning
Jan 03, 2022
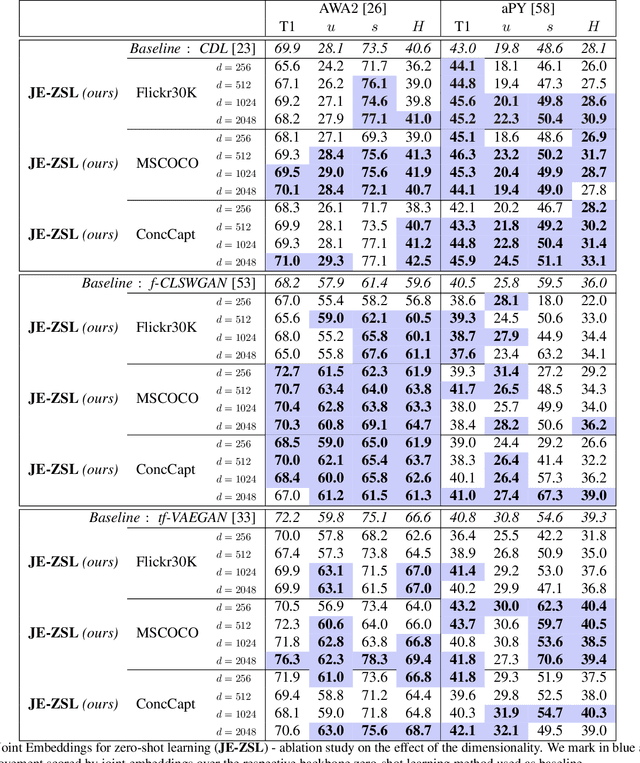
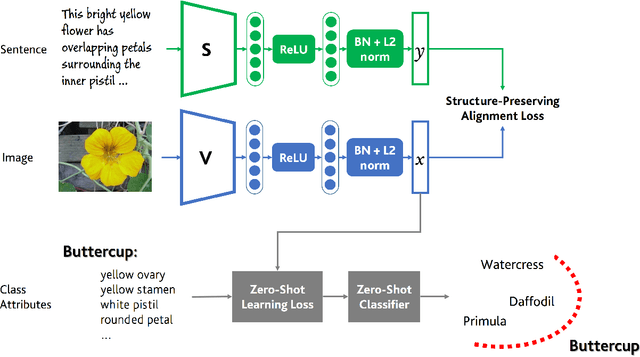
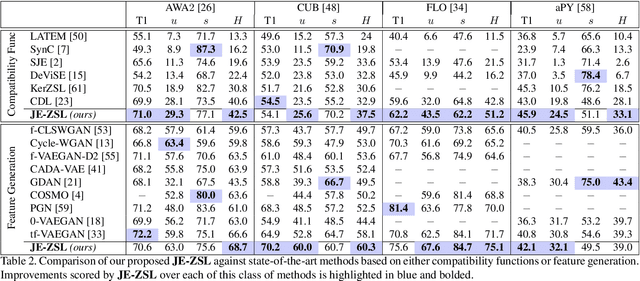
Zero-shot learning methods rely on fixed visual and semantic embeddings, extracted from independent vision and language models, both pre-trained for other large-scale tasks. This is a weakness of current zero-shot learning frameworks as such disjoint embeddings fail to adequately associate visual and textual information to their shared semantic content. Therefore, we propose to learn semantically grounded and enriched visual information by computing a joint image and text model with a two-stream network on a proxy task. To improve this alignment between image and textual representations, provided by attributes, we leverage ancillary captions to provide grounded semantic information. Our method, dubbed joint embeddings for zero-shot learning is evaluated on several benchmark datasets, improving the performance of existing state-of-the-art methods in both standard ($+1.6$\% on aPY, $+2.6\%$ on FLO) and generalized ($+2.1\%$ on AWA$2$, $+2.2\%$ on CUB) zero-shot recognition.
Dynamic imaging using Motion-Compensated SmooThness Regularization on Manifolds (MoCo-SToRM)
Dec 06, 2021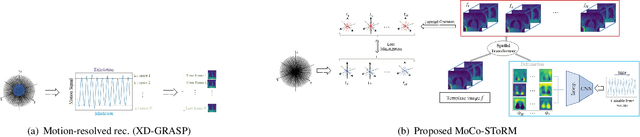
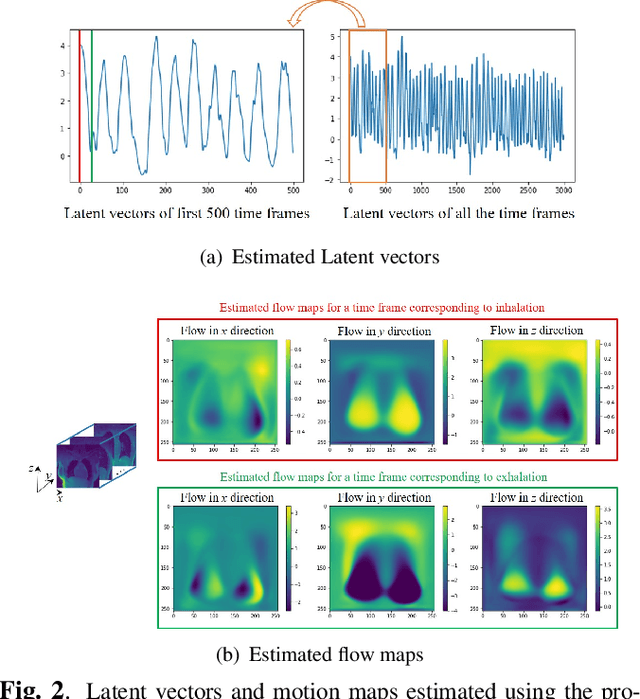
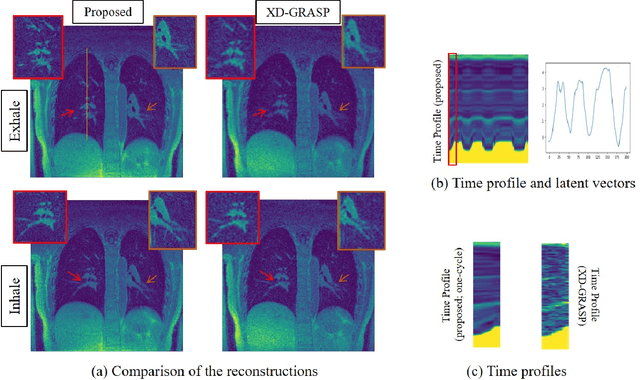
We introduce an unsupervised motion-compensated reconstruction scheme for high-resolution free-breathing pulmonary MRI. We model the image frames in the time series as the deformed version of the 3D template image volume. We assume the deformation maps to be points on a smooth manifold in high-dimensional space. Specifically, we model the deformation map at each time instant as the output of a CNN-based generator that has the same weight for all time-frames, driven by a low-dimensional latent vector. The time series of latent vectors account for the dynamics in the dataset, including respiratory motion and bulk motion. The template image volume, the parameters of the generator, and the latent vectors are learned directly from the k-t space data in an unsupervised fashion. Our experimental results show improved reconstructions compared to state-of-the-art methods, especially in the context of bulk motion during the scans.
AutoAlign: Pixel-Instance Feature Aggregation for Multi-Modal 3D Object Detection
Jan 17, 2022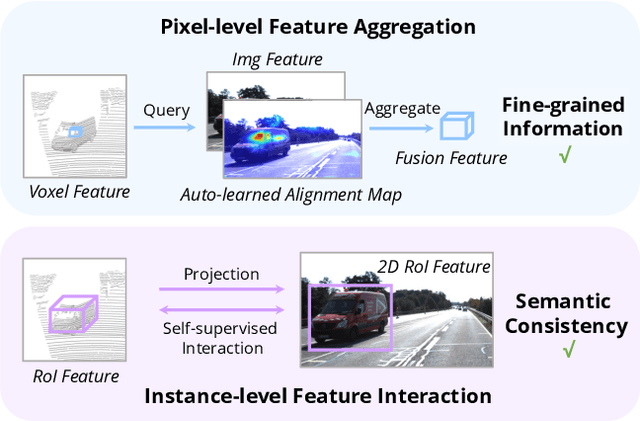
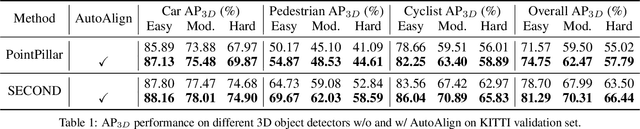
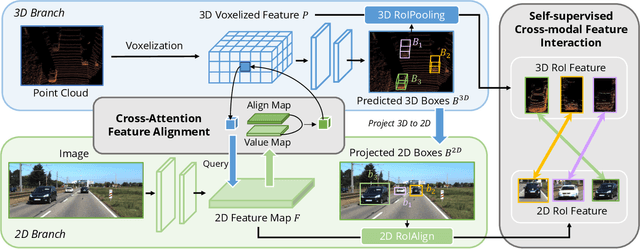

Object detection through either RGB images or the LiDAR point clouds has been extensively explored in autonomous driving. However, it remains challenging to make these two data sources complementary and beneficial to each other. In this paper, we propose \textit{AutoAlign}, an automatic feature fusion strategy for 3D object detection. Instead of establishing deterministic correspondence with camera projection matrix, we model the mapping relationship between the image and point clouds with a learnable alignment map. This map enables our model to automate the alignment of non-homogenous features in a dynamic and data-driven manner. Specifically, a cross-attention feature alignment module is devised to adaptively aggregate \textit{pixel-level} image features for each voxel. To enhance the semantic consistency during feature alignment, we also design a self-supervised cross-modal feature interaction module, through which the model can learn feature aggregation with \textit{instance-level} feature guidance. Extensive experimental results show that our approach can lead to 2.3 mAP and 7.0 mAP improvements on the KITTI and nuScenes datasets, respectively. Notably, our best model reaches 70.9 NDS on the nuScenes testing leaderboard, achieving competitive performance among various state-of-the-arts.