 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Anatomical Data Augmentation via Fluid-based Image Registration
Jul 05, 2020
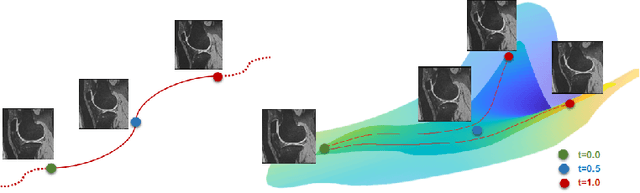
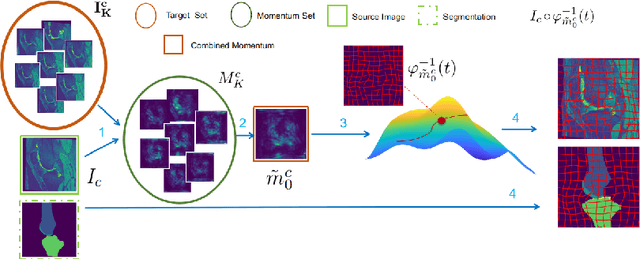
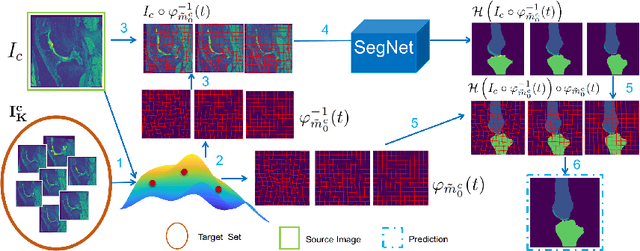
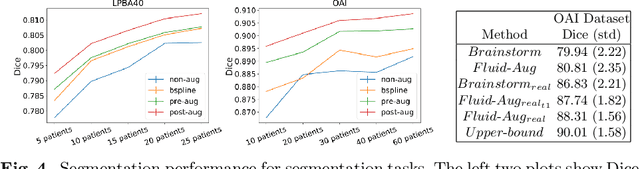
We introduce a fluid-based image augmentation method for medical image analysis. In contrast to existing methods, our framework generates anatomically meaningful images via interpolation from the geodesic subspace underlying given samples. Our approach consists of three steps: 1) given a source image and a set of target images, we construct a geodesic subspace using the Large Deformation Diffeomorphic Metric Mapping (LDDMM) model; 2) we sample transformations from the resulting geodesic subspace; 3) we obtain deformed images and segmentations via interpolation. Experiments on brain (LPBA) and knee (OAI) data illustrate the performance of our approach on two tasks: 1) data augmentation during training and testing for image segmentation; 2) one-shot learning for single atlas image segmentation. We demonstrate that our approach generates anatomically meaningful data and improves performance on these tasks over competing approaches. Code is available at https://github.com/uncbiag/easyreg.
High-Accuracy RGB-D Face Recognition via Segmentation-Aware Face Depth Estimation and Mask-Guided Attention Network
Dec 22, 2021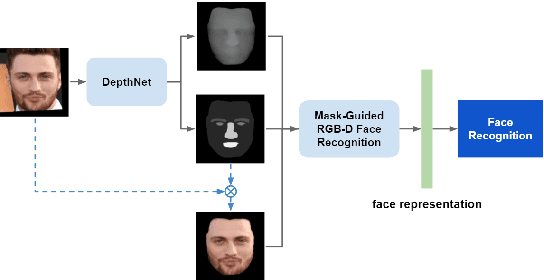
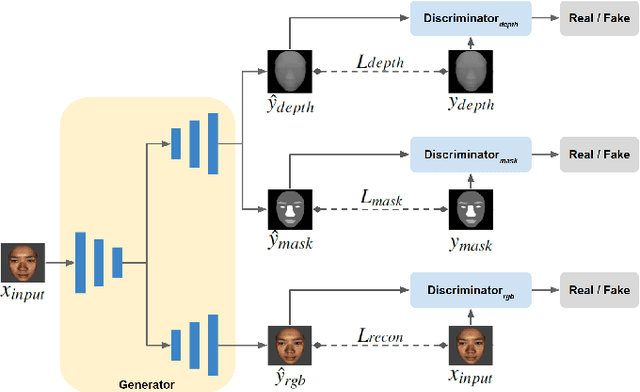
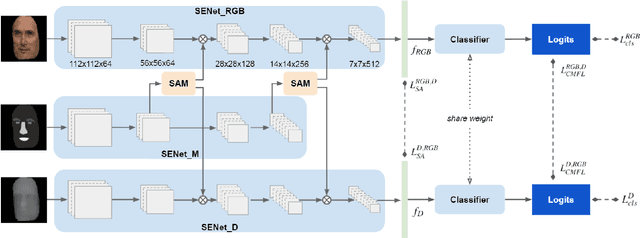

Deep learning approaches have achieved highly accurate face recognition by training the models with very large face image datasets. Unlike the availability of large 2D face image datasets, there is a lack of large 3D face datasets available to the public. Existing public 3D face datasets were usually collected with few subjects, leading to the over-fitting problem. This paper proposes two CNN models to improve the RGB-D face recognition task. The first is a segmentation-aware depth estimation network, called DepthNet, which estimates depth maps from RGB face images by including semantic segmentation information for more accurate face region localization. The other is a novel mask-guided RGB-D face recognition model that contains an RGB recognition branch, a depth map recognition branch, and an auxiliary segmentation mask branch with a spatial attention module. Our DepthNet is used to augment a large 2D face image dataset to a large RGB-D face dataset, which is used for training an accurate RGB-D face recognition model. Furthermore, the proposed mask-guided RGB-D face recognition model can fully exploit the depth map and segmentation mask information and is more robust against pose variation than previous methods. Our experimental results show that DepthNet can produce more reliable depth maps from face images with the segmentation mask. Our mask-guided face recognition model outperforms state-of-the-art methods on several public 3D face datasets.
Wavelet-Based Dual-Branch Network for Image Demoireing
Jul 14, 2020

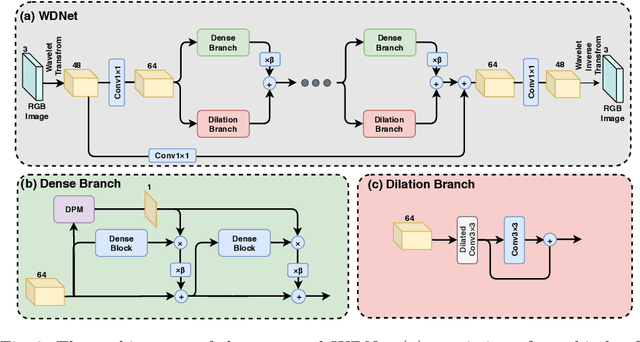

When smartphone cameras are used to take photos of digital screens, usually moire patterns result, severely degrading photo quality. In this paper, we design a wavelet-based dual-branch network (WDNet) with a spatial attention mechanism for image demoireing. Existing image restoration methods working in the RGB domain have difficulty in distinguishing moire patterns from true scene texture. Unlike these methods, our network removes moire patterns in the wavelet domain to separate the frequencies of moire patterns from the image content. The network combines dense convolution modules and dilated convolution modules supporting large receptive fields. Extensive experiments demonstrate the effectiveness of our method, and we further show that WDNet generalizes to removing moire artifacts on non-screen images. Although designed for image demoireing, WDNet has been applied to two other low-levelvision tasks, outperforming state-of-the-art image deraining and derain-drop methods on the Rain100h and Raindrop800 data sets, respectively.
One-bit Supervision for Image Classification
Sep 16, 2020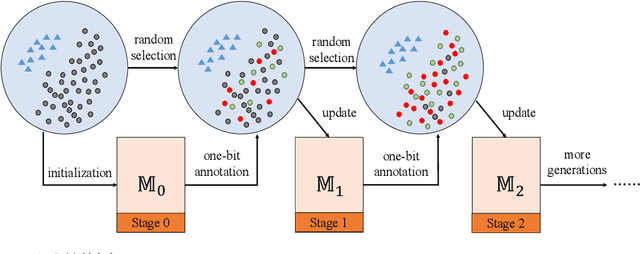

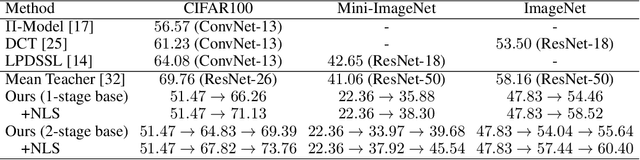
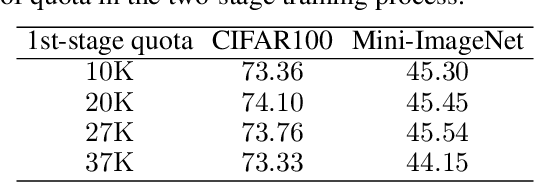
This paper presents one-bit supervision, a novel setting of learning from incomplete annotations, in the scenario of image classification. Instead of training a model upon the accurate label of each sample, our setting requires the model to query with a predicted label of each sample and learn from the answer whether the guess is correct. This provides one bit (yes or no) of information, and more importantly, annotating each sample becomes much easier than finding the accurate label from many candidate classes. There are two keys to training a model upon one-bit supervision: improving the guess accuracy and making use of incorrect guesses. For these purposes, we propose a multi-stage training paradigm which incorporates negative label suppression into an off-the-shelf semi-supervised learning algorithm. In three popular image classification benchmarks, our approach claims higher efficiency in utilizing the limited amount of annotations.
Decamouflage: A Framework to Detect Image-Scaling Attacks on Convolutional Neural Networks
Oct 08, 2020

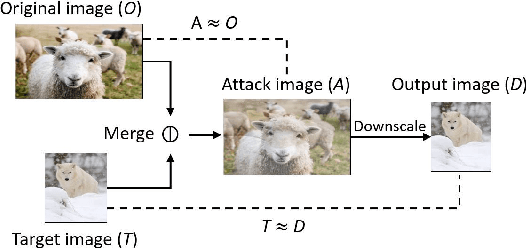

As an essential processing step in computer vision applications, image resizing or scaling, more specifically downsampling, has to be applied before feeding a normally large image into a convolutional neural network (CNN) model because CNN models typically take small fixed-size images as inputs. However, image scaling functions could be adversarially abused to perform a newly revealed attack called image-scaling attack, which can affect a wide range of computer vision applications building upon image-scaling functions. This work presents an image-scaling attack detection framework, termed as Decamouflage. Decamouflage consists of three independent detection methods: (1) rescaling, (2) filtering/pooling, and (3) steganalysis. While each of these three methods is efficient standalone, they can work in an ensemble manner not only to improve the detection accuracy but also to harden potential adaptive attacks. Decamouflage has a pre-determined detection threshold that is generic. More precisely, as we have validated, the threshold determined from one dataset is also applicable to other different datasets. Extensive experiments show that Decamouflage achieves detection accuracy of 99.9\% and 99.8\% in the white-box (with the knowledge of attack algorithms) and the black-box (without the knowledge of attack algorithms) settings, respectively. To corroborate the efficiency of Decamouflage, we have also measured its run-time overhead on a personal PC with an i5 CPU and found that Decamouflage can detect image-scaling attacks in milliseconds. Overall, Decamouflage can accurately detect image scaling attacks in both white-box and black-box settings with acceptable run-time overhead.
On the Effectiveness of Adversarial Training against Backdoor Attacks
Feb 22, 2022

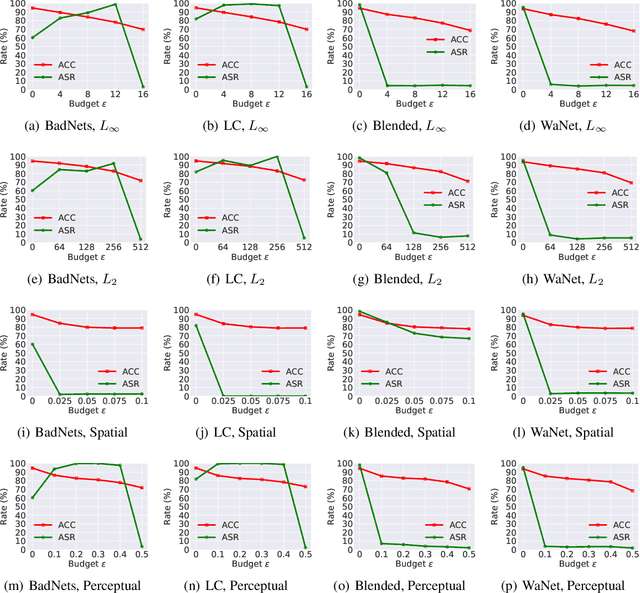
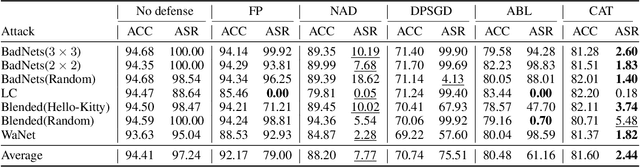
DNNs' demand for massive data forces practitioners to collect data from the Internet without careful check due to the unacceptable cost, which brings potential risks of backdoor attacks. A backdoored model always predicts a target class in the presence of a predefined trigger pattern, which can be easily realized via poisoning a small amount of data. In general, adversarial training is believed to defend against backdoor attacks since it helps models to keep their prediction unchanged even if we perturb the input image (as long as within a feasible range). Unfortunately, few previous studies succeed in doing so. To explore whether adversarial training could defend against backdoor attacks or not, we conduct extensive experiments across different threat models and perturbation budgets, and find the threat model in adversarial training matters. For instance, adversarial training with spatial adversarial examples provides notable robustness against commonly-used patch-based backdoor attacks. We further propose a hybrid strategy which provides satisfactory robustness across different backdoor attacks.
Grounded Situation Recognition with Transformers
Nov 19, 2021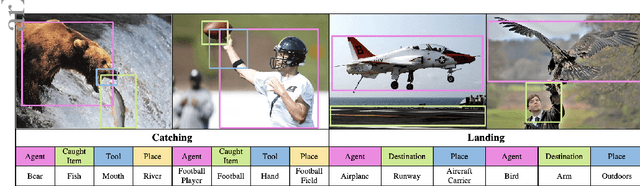
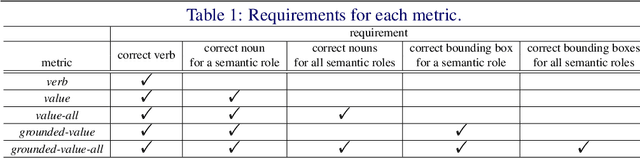
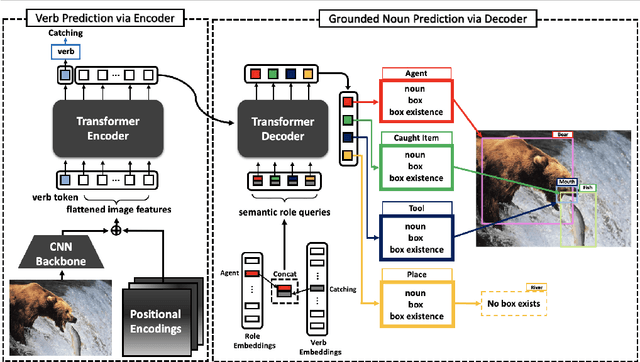
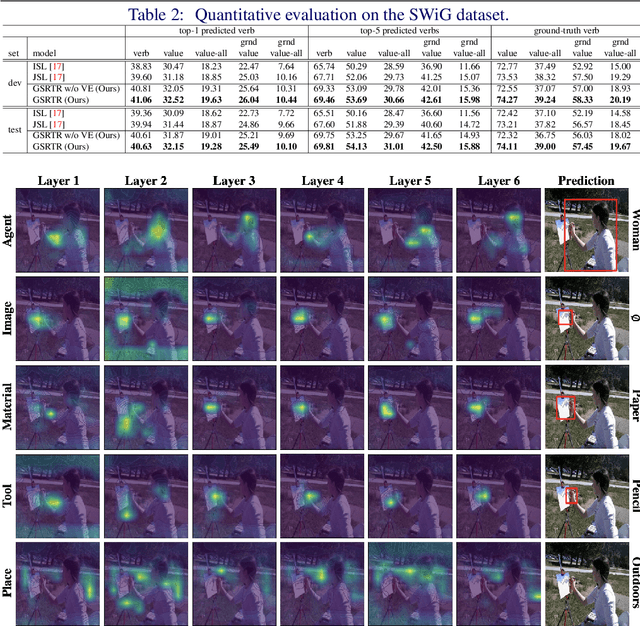
Grounded Situation Recognition (GSR) is the task that not only classifies a salient action (verb), but also predicts entities (nouns) associated with semantic roles and their locations in the given image. Inspired by the remarkable success of Transformers in vision tasks, we propose a GSR model based on a Transformer encoder-decoder architecture. The attention mechanism of our model enables accurate verb classification by capturing high-level semantic feature of an image effectively, and allows the model to flexibly deal with the complicated and image-dependent relations between entities for improved noun classification and localization. Our model is the first Transformer architecture for GSR, and achieves the state of the art in every evaluation metric on the SWiG benchmark. Our code is available at https://github.com/jhcho99/gsrtr .
Benchmarking Test-Time Unsupervised Deep Neural Network Adaptation on Edge Devices
Mar 21, 2022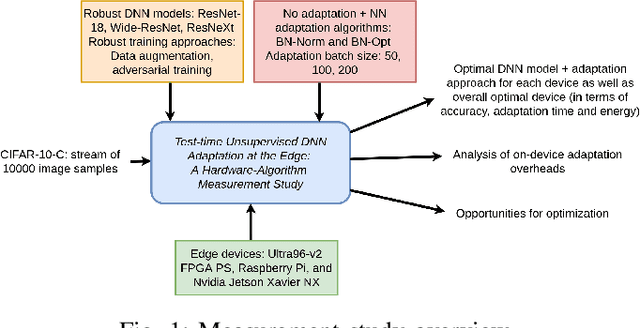
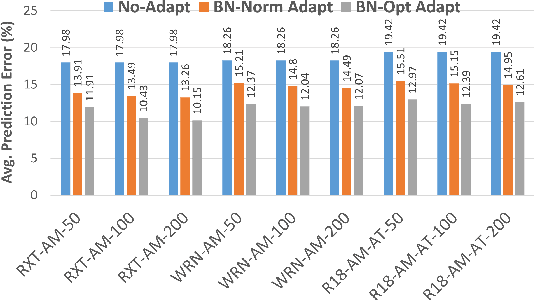
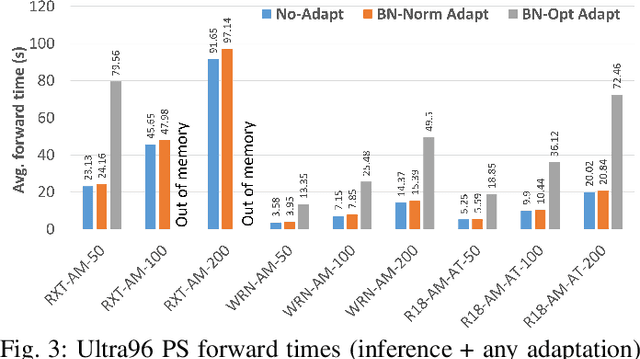
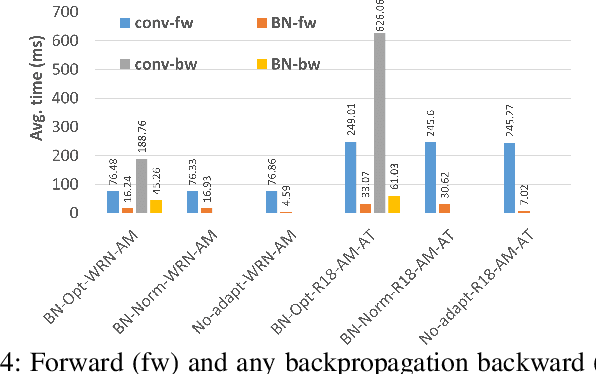
The prediction accuracy of the deep neural networks (DNNs) after deployment at the edge can suffer with time due to shifts in the distribution of the new data. To improve robustness of DNNs, they must be able to update themselves to enhance their prediction accuracy. This adaptation at the resource-constrained edge is challenging as: (i) new labeled data may not be present; (ii) adaptation needs to be on device as connections to cloud may not be available; and (iii) the process must not only be fast but also memory- and energy-efficient. Recently, lightweight prediction-time unsupervised DNN adaptation techniques have been introduced that improve prediction accuracy of the models for noisy data by re-tuning the batch normalization (BN) parameters. This paper, for the first time, performs a comprehensive measurement study of such techniques to quantify their performance and energy on various edge devices as well as find bottlenecks and propose optimization opportunities. In particular, this study considers CIFAR-10-C image classification dataset with corruptions, three robust DNNs (ResNeXt, Wide-ResNet, ResNet-18), two BN adaptation algorithms (one that updates normalization statistics and the other that also optimizes transformation parameters), and three edge devices (FPGA, Raspberry-Pi, and Nvidia Xavier NX). We find that the approach that only updates the normalization parameters with Wide-ResNet, running on Xavier GPU, to be overall effective in terms of balancing multiple cost metrics. However, the adaptation overhead can still be significant (around 213 ms). The results strongly motivate the need for algorithm-hardware co-design for efficient on-device DNN adaptation.
Concatenated Attention Neural Network for Image Restoration
Jun 19, 2020
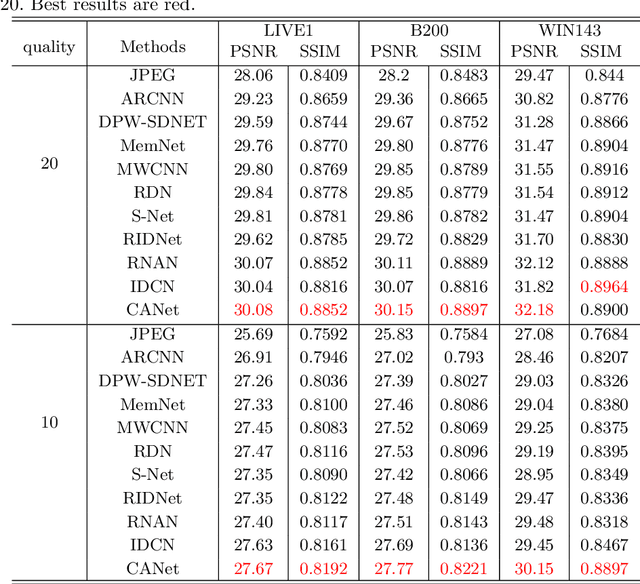
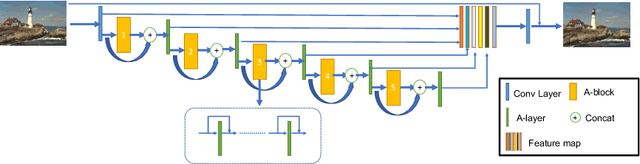
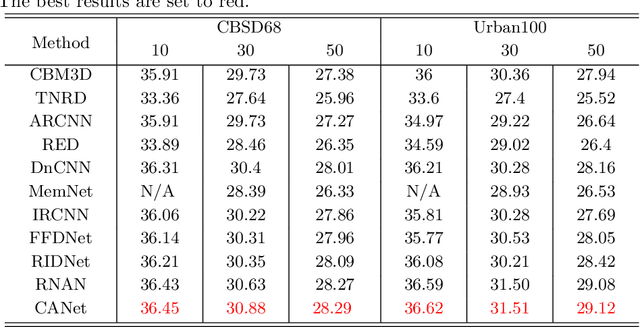
In this paper, we present a general framework for low-level vision tasks including image compression artifacts reduction and image denoising. Under this framework, a novel concatenated attention neural network (CANet) is specifically designed for image restoration. The main contributions of this paper are as follows: First, by applying concise but effective concatenation and feature selection mechanism, we establish a novel connection mechanism which connect different modules in the modules stacking network. Second, both pixel-wise and channel-wise attention mechanisms are used in each module convolution layer, which promotes further extraction of more essential information in images. Lastly, we demonstrate that CANet achieves better results than previous state-of-the-art approaches with sufficient experiments in compression artifacts removing and image denoising.
Label conditioned segmentation
Mar 17, 2022



Semantic segmentation is an important task in computer vision that is often tackled with convolutional neural networks (CNNs). A CNN learns to produce pixel-level predictions through training on pairs of images and their corresponding ground-truth segmentation labels. For segmentation tasks with multiple classes, the standard approach is to use a network that computes a multi-channel probabilistic segmentation map, with each channel representing one class. In applications where the image grid size (e.g., when it is a 3D volume) and/or the number of labels is relatively large, the standard (baseline) approach can become prohibitively expensive for our computational resources. In this paper, we propose a simple yet effective method to address this challenge. In our approach, the segmentation network produces a single-channel output, while being conditioned on a single class label, which determines the output class of the network. Our method, called label conditioned segmentation (LCS), can be used to segment images with a very large number of classes, which might be infeasible for the baseline approach. We also demonstrate in the experiments that label conditioning can improve the accuracy of a given backbone architecture, likely, thanks to its parameter efficiency. Finally, as we show in our results, an LCS model can produce previously unseen fine-grained labels during inference time, when only coarse labels were available during training. We provide all of our code here: https://github.com/tym002/Label-conditioned-segmentation