 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Associative Adversarial Learning Based on Selective Attack
Jan 04, 2022
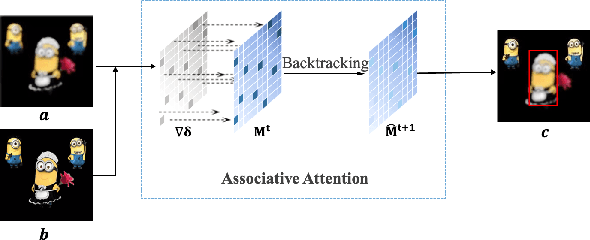
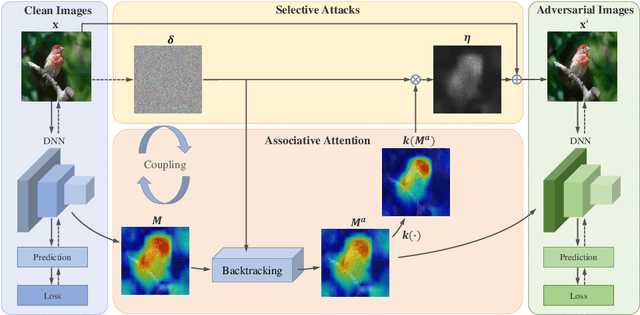
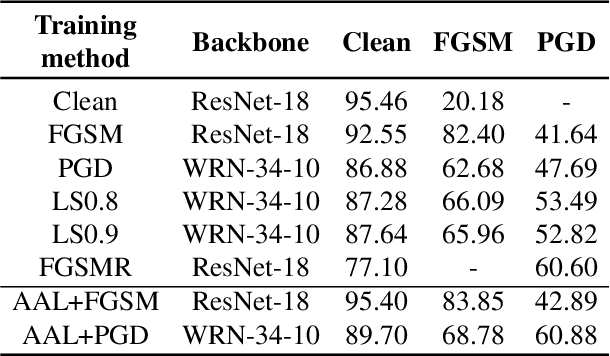
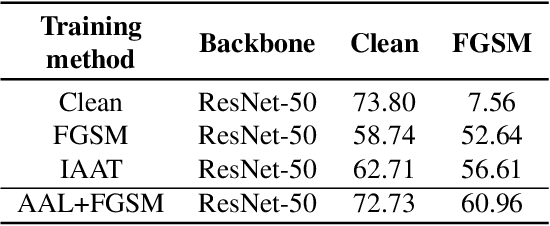
A human's attention can intuitively adapt to corrupted areas of an image by recalling a similar uncorrupted image they have previously seen. This observation motivates us to improve the attention of adversarial images by considering their clean counterparts. To accomplish this, we introduce Associative Adversarial Learning (AAL) into adversarial learning to guide a selective attack. We formulate the intrinsic relationship between attention and attack (perturbation) as a coupling optimization problem to improve their interaction. This leads to an attention backtracking algorithm that can effectively enhance the attention's adversarial robustness. Our method is generic and can be used to address a variety of tasks by simply choosing different kernels for the associative attention that select other regions for a specific attack. Experimental results show that the selective attack improves the model's performance. We show that our method improves the recognition accuracy of adversarial training on ImageNet by 8.32% compared with the baseline. It also increases object detection mAP on PascalVOC by 2.02% and recognition accuracy of few-shot learning on miniImageNet by 1.63%.
Unsupervised Complementary-aware Multi-process Fusion for Visual Place Recognition
Dec 09, 2021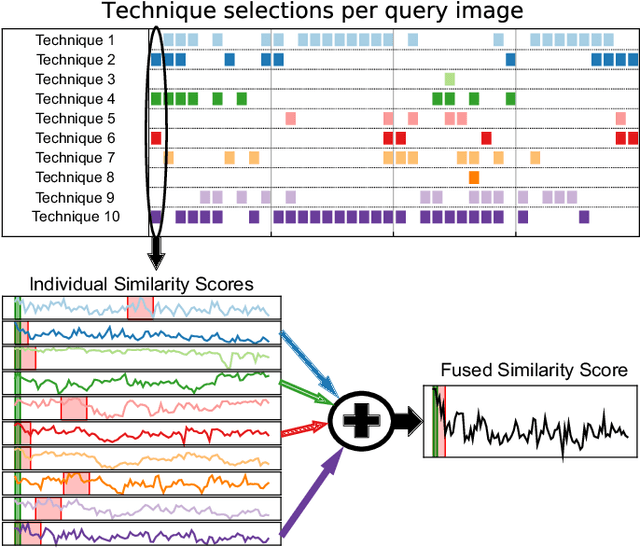
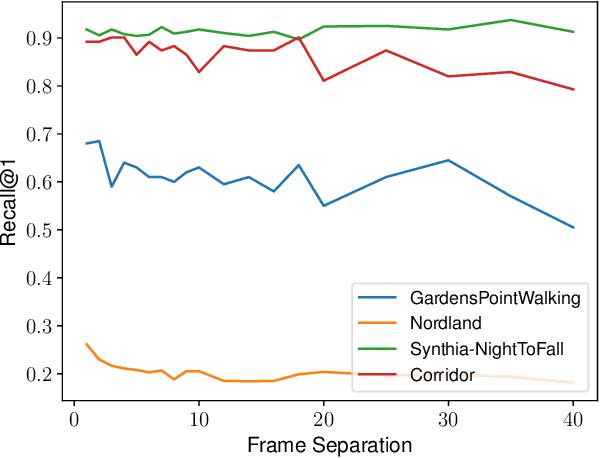
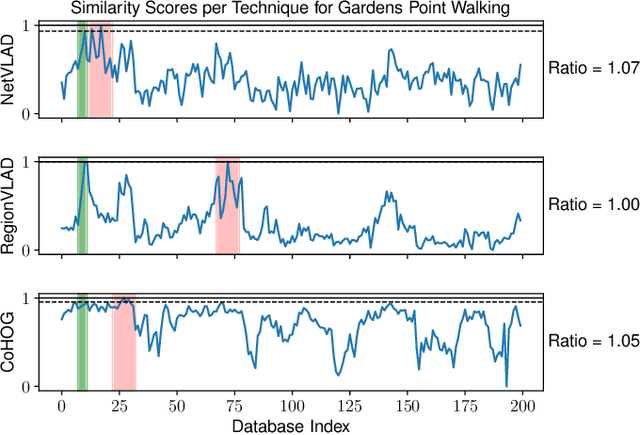
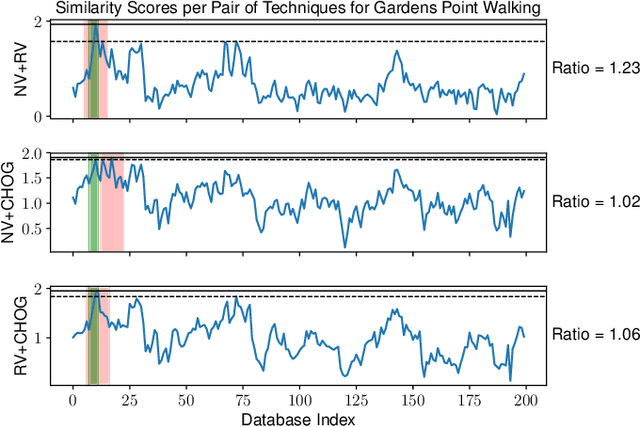
A recent approach to the Visual Place Recognition (VPR) problem has been to fuse the place recognition estimates of multiple complementary VPR techniques simultaneously. However, selecting the optimal set of techniques to use in a specific deployment environment a-priori is a difficult and unresolved challenge. Further, to the best of our knowledge, no method exists which can select a set of techniques on a frame-by-frame basis in response to image-to-image variations. In this work, we propose an unsupervised algorithm that finds the most robust set of VPR techniques to use in the current deployment environment, on a frame-by-frame basis. The selection of techniques is determined by an analysis of the similarity scores between the current query image and the collection of database images and does not require ground-truth information. We demonstrate our approach on a wide variety of datasets and VPR techniques and show that the proposed dynamic multi-process fusion (Dyn-MPF) has superior VPR performance compared to a variety of challenging competitive methods, some of which are given an unfair advantage through access to the ground-truth information.
Conditional Prompt Learning for Vision-Language Models
Mar 10, 2022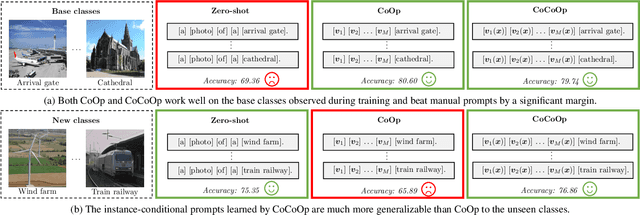
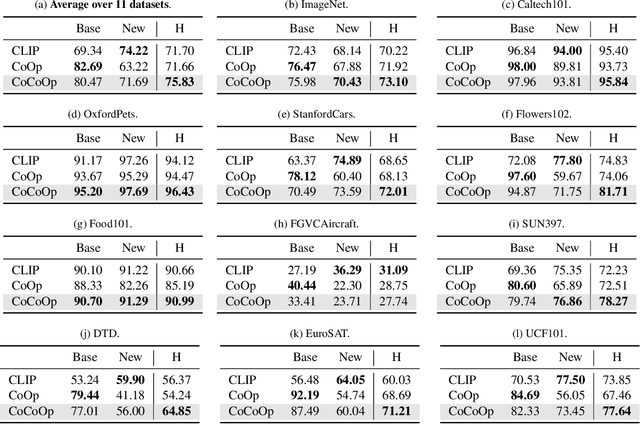
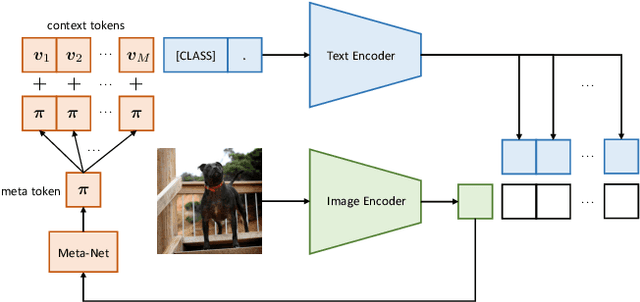
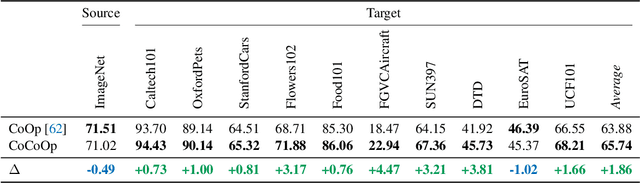
With the rise of powerful pre-trained vision-language models like CLIP, it becomes essential to investigate ways to adapt these models to downstream datasets. A recently proposed method named Context Optimization (CoOp) introduces the concept of prompt learning -- a recent trend in NLP -- to the vision domain for adapting pre-trained vision-language models. Specifically, CoOp turns context words in a prompt into a set of learnable vectors and, with only a few labeled images for learning, can achieve huge improvements over intensively-tuned manual prompts. In our study we identify a critical problem of CoOp: the learned context is not generalizable to wider unseen classes within the same dataset, suggesting that CoOp overfits base classes observed during training. To address the problem, we propose Conditional Context Optimization (CoCoOp), which extends CoOp by further learning a lightweight neural network to generate for each image an input-conditional token (vector). Compared to CoOp's static prompts, our dynamic prompts adapt to each instance and are thus less sensitive to class shift. Extensive experiments show that CoCoOp generalizes much better than CoOp to unseen classes, even showing promising transferability beyond a single dataset; and yields stronger domain generalization performance as well. Code is available at https://github.com/KaiyangZhou/CoOp.
Spatio-temporal Vision Transformer for Super-resolution Microscopy
Feb 28, 2022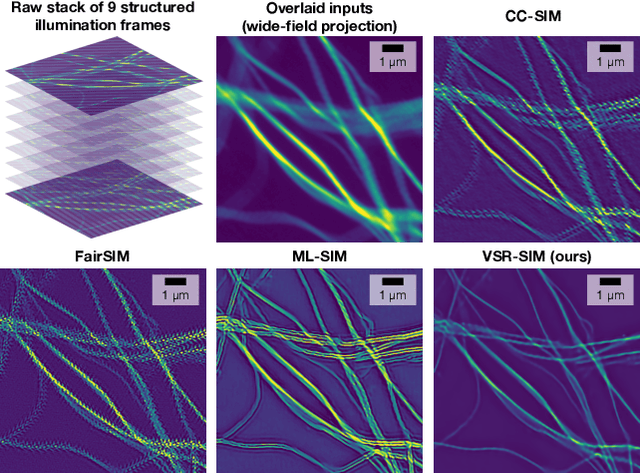
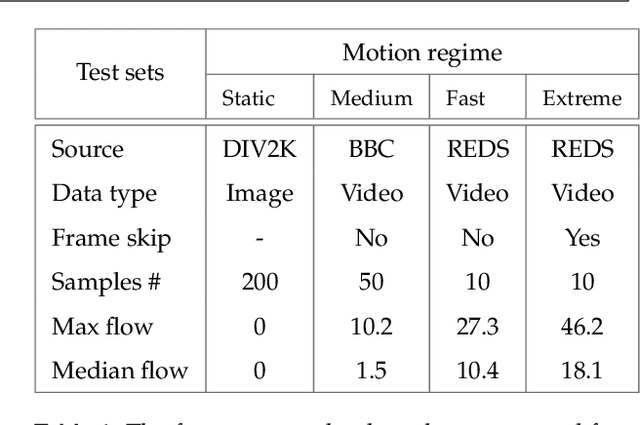
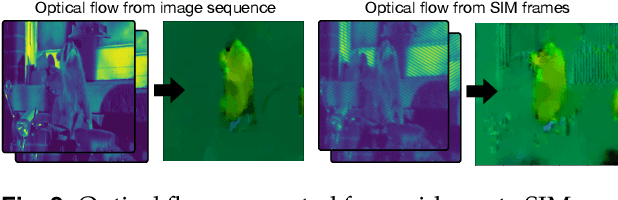
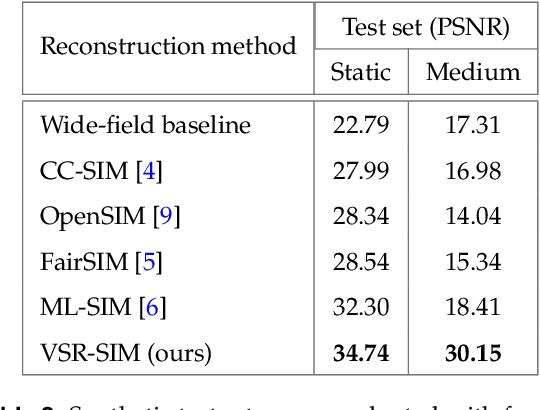
Structured illumination microscopy (SIM) is an optical super-resolution technique that enables live-cell imaging beyond the diffraction limit. Reconstruction of SIM data is prone to artefacts, which becomes problematic when imaging highly dynamic samples because previous methods rely on the assumption that samples are static. We propose a new transformer-based reconstruction method, VSR-SIM, that uses shifted 3-dimensional window multi-head attention in addition to channel attention mechanism to tackle the problem of video super-resolution (VSR) in SIM. The attention mechanisms are found to capture motion in sequences without the need for common motion estimation techniques such as optical flow. We take an approach to training the network that relies solely on simulated data using videos of natural scenery with a model for SIM image formation. We demonstrate a use case enabled by VSR-SIM referred to as rolling SIM imaging, which increases temporal resolution in SIM by a factor of 9. Our method can be applied to any SIM setup enabling precise recordings of dynamic processes in biomedical research with high temporal resolution.
CLIP meets GamePhysics: Towards bug identification in gameplay videos using zero-shot transfer learning
Mar 22, 2022
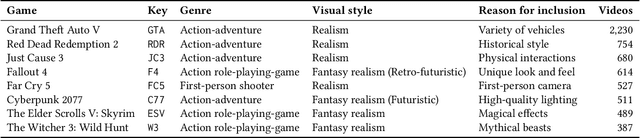

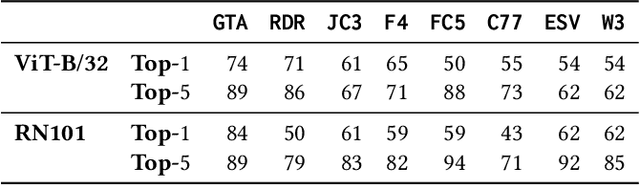
Gameplay videos contain rich information about how players interact with the game and how the game responds. Sharing gameplay videos on social media platforms, such as Reddit, has become a common practice for many players. Often, players will share gameplay videos that showcase video game bugs. Such gameplay videos are software artifacts that can be utilized for game testing, as they provide insight for bug analysis. Although large repositories of gameplay videos exist, parsing and mining them in an effective and structured fashion has still remained a big challenge. In this paper, we propose a search method that accepts any English text query as input to retrieve relevant videos from large repositories of gameplay videos. Our approach does not rely on any external information (such as video metadata); it works solely based on the content of the video. By leveraging the zero-shot transfer capabilities of the Contrastive Language-Image Pre-Training (CLIP) model, our approach does not require any data labeling or training. To evaluate our approach, we present the $\texttt{GamePhysics}$ dataset consisting of 26,954 videos from 1,873 games, that were collected from the GamePhysics section on the Reddit website. Our approach shows promising results in our extensive analysis of simple queries, compound queries, and bug queries, indicating that our approach is useful for object and event detection in gameplay videos. An example application of our approach is as a gameplay video search engine to aid in reproducing video game bugs. Please visit the following link for the code and the data: https://asgaardlab.github.io/CLIPxGamePhysics/
Diagonal Attention and Style-based GAN for Content-Style Disentanglement in Image Generation and Translation
Mar 30, 2021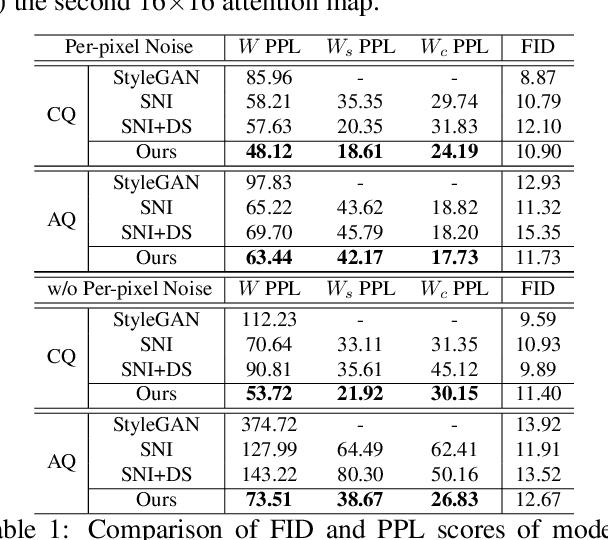
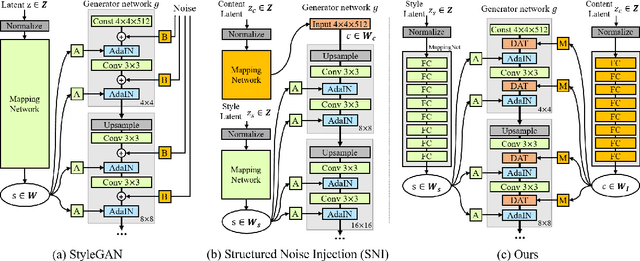
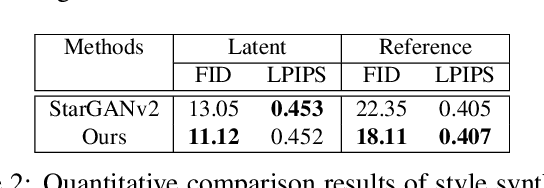
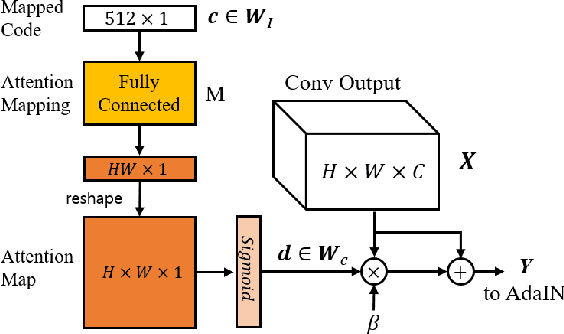
One of the important research topics in image generative models is to disentangle the spatial contents and styles for their separate control. Although StyleGAN can generate content feature vectors from random noises, the resulting spatial content control is primarily intended for minor spatial variations, and the disentanglement of global content and styles is by no means complete. Inspired by a mathematical understanding of normalization and attention, here we present a novel hierarchical adaptive Diagonal spatial ATtention (DAT) layers to separately manipulate the spatial contents from styles in a hierarchical manner. Using DAT and AdaIN, our method enables coarse-to-fine level disentanglement of spatial contents and styles. In addition, our generator can be easily integrated into the GAN inversion framework so that the content and style of translated images from multi-domain image translation tasks can be flexibly controlled. By using various datasets, we confirm that the proposed method not only outperforms the existing models in disentanglement scores, but also provides more flexible control over spatial features in the generated images.
Asymmetric GAN for Unpaired Image-to-image Translation
Dec 25, 2019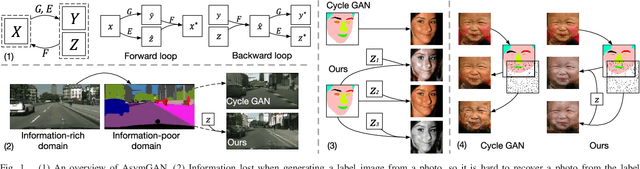
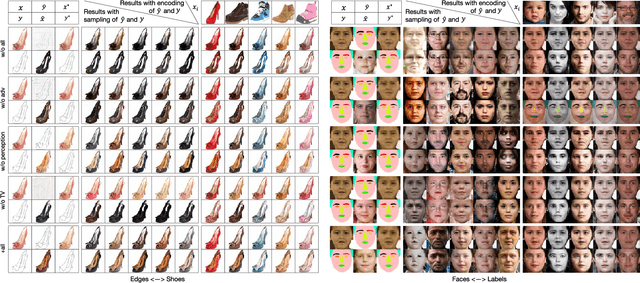


Unpaired image-to-image translation problem aims to model the mapping from one domain to another with unpaired training data. Current works like the well-acknowledged Cycle GAN provide a general solution for any two domains through modeling injective mappings with a symmetric structure. While in situations where two domains are asymmetric in complexity, i.e., the amount of information between two domains is different, these approaches pose problems of poor generation quality, mapping ambiguity, and model sensitivity. To address these issues, we propose Asymmetric GAN (AsymGAN) to adapt the asymmetric domains by introducing an auxiliary variable (aux) to learn the extra information for transferring from the information-poor domain to the information-rich domain, which improves the performance of state-of-the-art approaches in the following ways. First, aux better balances the information between two domains which benefits the quality of generation. Second, the imbalance of information commonly leads to mapping ambiguity, where we are able to model one-to-many mappings by tuning aux, and furthermore, our aux is controllable. Third, the training of Cycle GAN can easily make the generator pair sensitive to small disturbances and variations while our model decouples the ill-conditioned relevance of generators by injecting aux during training. We verify the effectiveness of our proposed method both qualitatively and quantitatively on asymmetric situation, label-photo task, on Cityscapes and Helen datasets, and show many applications of asymmetric image translations. In conclusion, our AsymGAN provides a better solution for unpaired image-to-image translation in asymmetric domains.
* Accepted by IEEE Transactions on Image Processing (TIP) 2019
Recognition Oriented Iris Image Quality Assessment in the Feature Space
Sep 27, 2020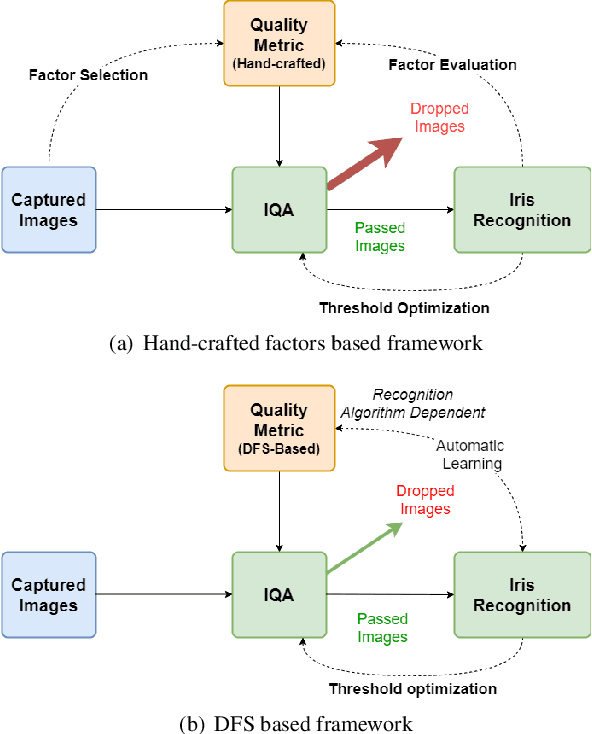
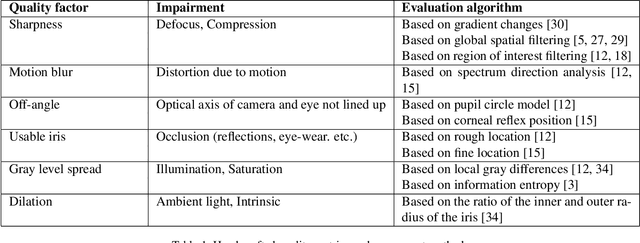
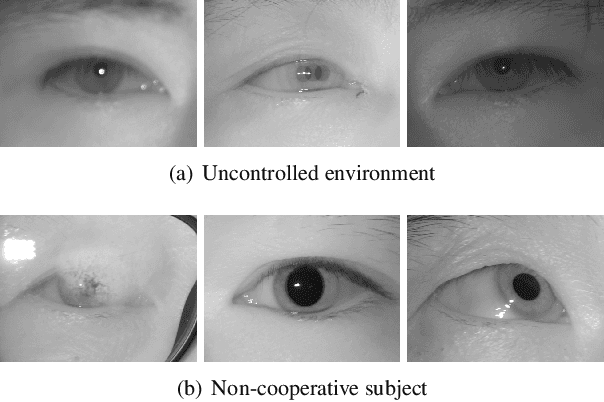
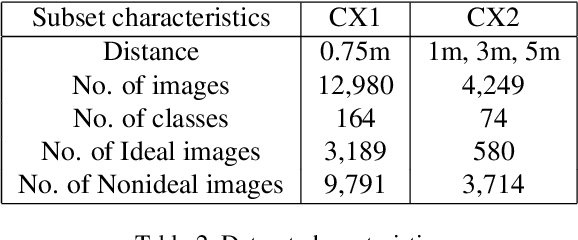
A large portion of iris images captured in real world scenarios are poor quality due to the uncontrolled environment and the non-cooperative subject. To ensure that the recognition algorithm is not affected by low-quality images, traditional hand-crafted factors based methods discard most images, which will cause system timeout and disrupt user experience. In this paper, we propose a recognition-oriented quality metric and assessment method for iris image to deal with the problem. The method regards the iris image embeddings Distance in Feature Space (DFS) as the quality metric and the prediction is based on deep neural networks with the attention mechanism. The quality metric proposed in this paper can significantly improve the performance of the recognition algorithm while reducing the number of images discarded for recognition, which is advantageous over hand-crafted factors based iris quality assessment methods. The relationship between Image Rejection Rate (IRR) and Equal Error Rate (EER) is proposed to evaluate the performance of the quality assessment algorithm under the same image quality distribution and the same recognition algorithm. Compared with hand-crafted factors based methods, the proposed method is a trial to bridge the gap between the image quality assessment and biometric recognition. The code is available at https://github.com/Debatrix/DFSNet.
Indiscriminate Poisoning Attacks on Unsupervised Contrastive Learning
Feb 22, 2022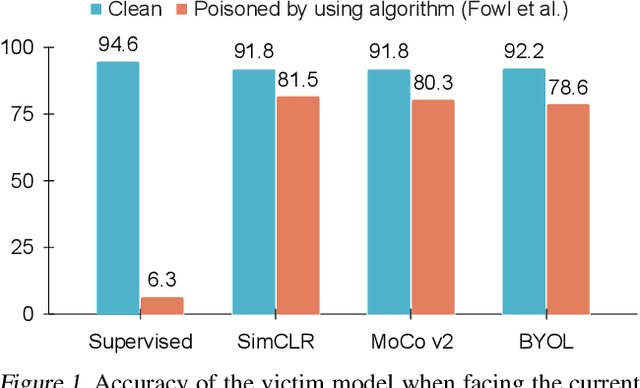
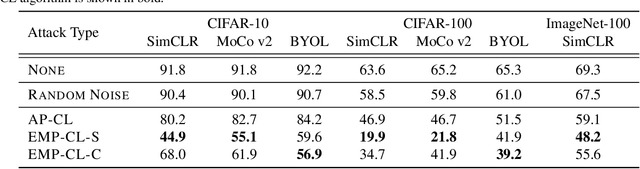
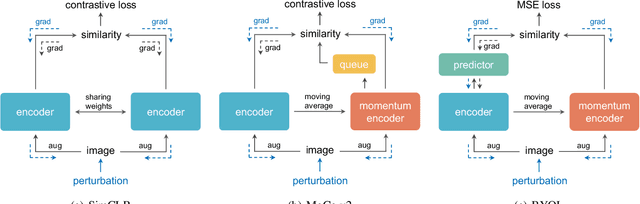
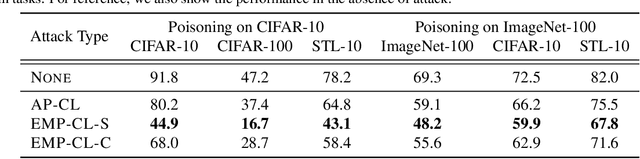
Indiscriminate data poisoning attacks are quite effective against supervised learning. However, not much is known about their impact on unsupervised contrastive learning (CL). This paper is the first to consider indiscriminate data poisoning attacks on contrastive learning, demonstrating the feasibility of such attacks, and their differences from indiscriminate poisoning of supervised learning. We also highlight differences between contrastive learning algorithms, and show that some algorithms (e.g., SimCLR) are more vulnerable than others (e.g., MoCo). We differentiate between two types of data poisoning attacks: sample-wise attacks, which add specific noise to each image, cause the largest drop in accuracy, but do not transfer well across SimCLR, MoCo, and BYOL. In contrast, attacks that use class-wise noise, though cause a smaller drop in accuracy, transfer well across different CL algorithms. Finally, we show that a new data augmentation based on matrix completion can be highly effective in countering data poisoning attacks on unsupervised contrastive learning.
Cross-Region Building Counting in Satellite Imagery using Counting Consistency
Oct 26, 2021
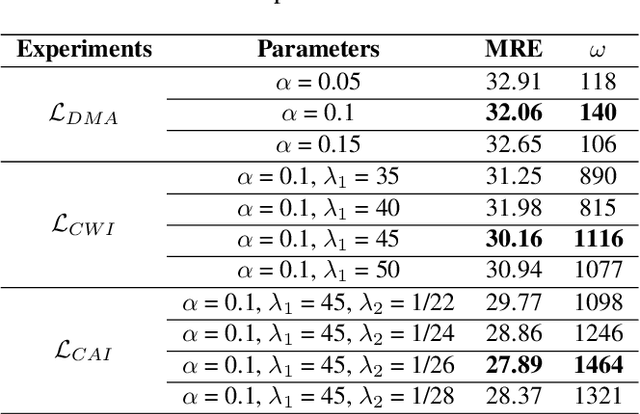
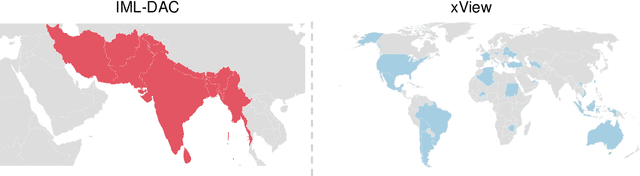
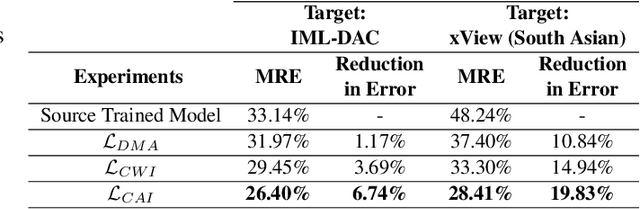
Estimating the number of buildings in any geographical region is a vital component of urban analysis, disaster management, and public policy decision. Deep learning methods for building localization and counting in satellite imagery, can serve as a viable and cheap alternative. However, these algorithms suffer performance degradation when applied to the regions on which they have not been trained. Current large datasets mostly cover the developed regions and collecting such datasets for every region is a costly, time-consuming, and difficult endeavor. In this paper, we propose an unsupervised domain adaptation method for counting buildings where we use a labeled source domain (developed regions) and adapt the trained model on an unlabeled target domain (developing regions). We initially align distribution maps across domains by aligning the output space distribution through adversarial loss. We then exploit counting consistency constraints, within-image count consistency, and across-image count consistency, to decrease the domain shift. Within-image consistency enforces that building count in the whole image should be greater than or equal to count in any of its sub-image. Across-image consistency constraint enforces that if an image contains considerably more buildings than the other image, then their sub-images shall also have the same order. These two constraints encourage the behavior to be consistent across and within the images, regardless of the scale. To evaluate the performance of our proposed approach, we collected and annotated a large-scale dataset consisting of challenging South Asian regions having higher building densities and irregular structures as compared to existing datasets. We perform extensive experiments to verify the efficacy of our approach and report improvements of approximately 7% to 20% over the competitive baseline methods.