 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Deep Learning Approach for the Detection of COVID-19 from Chest X-Ray Images using Convolutional Neural Networks
Jan 24, 2022
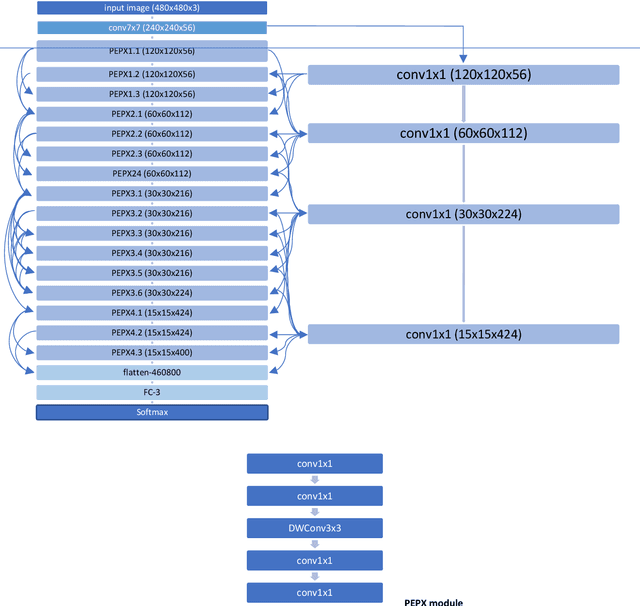
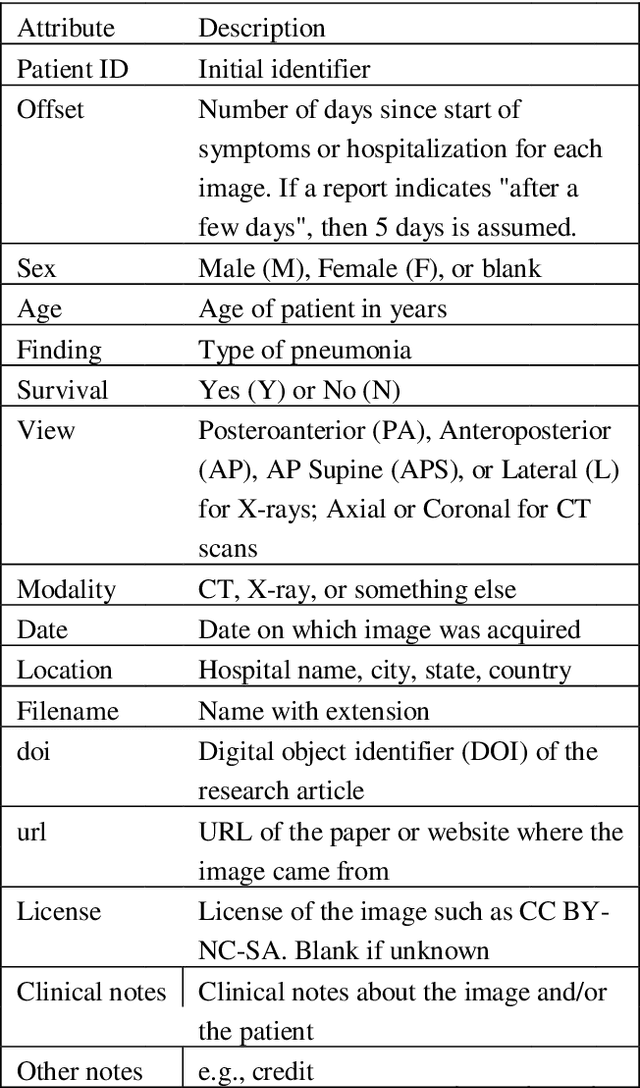
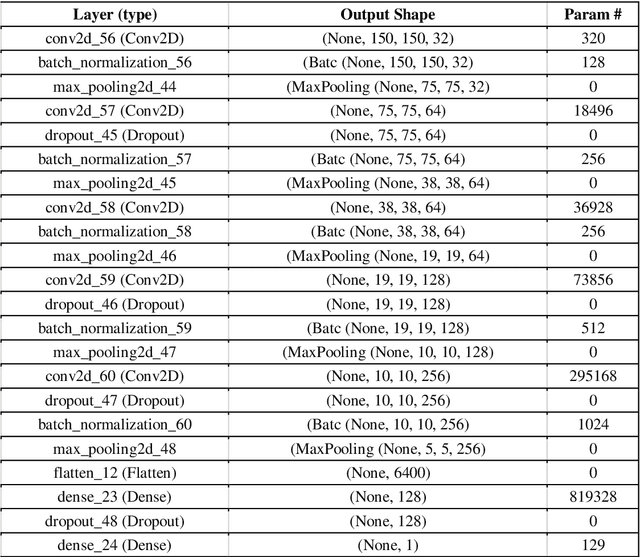
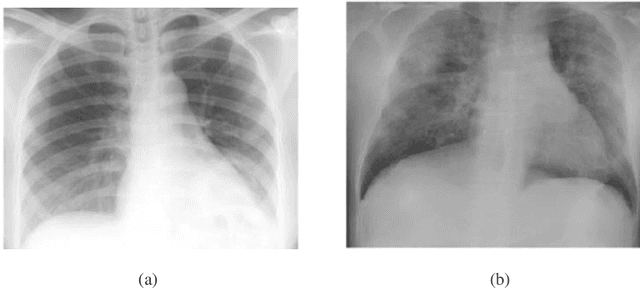
The COVID-19 (coronavirus) is an ongoing pandemic caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). The virus was first identified in mid-December 2019 in the Hubei province of Wuhan, China and by now has spread throughout the planet with more than 75.5 million confirmed cases and more than 1.67 million deaths. With limited number of COVID-19 test kits available in medical facilities, it is important to develop and implement an automatic detection system as an alternative diagnosis option for COVID-19 detection that can used on a commercial scale. Chest X-ray is the first imaging technique that plays an important role in the diagnosis of COVID-19 disease. Computer vision and deep learning techniques can help in determining COVID-19 virus with Chest X-ray Images. Due to the high availability of large-scale annotated image datasets, great success has been achieved using convolutional neural network for image analysis and classification. In this research, we have proposed a deep convolutional neural network trained on five open access datasets with binary output: Normal and Covid. The performance of the model is compared with four pre-trained convolutional neural network-based models (COVID-Net, ResNet18, ResNet and MobileNet-V2) and it has been seen that the proposed model provides better accuracy on the validation set as compared to the other four pre-trained models. This research work provides promising results which can be further improvise and implement on a commercial scale.
Detecting Adversaries, yet Faltering to Noise? Leveraging Conditional Variational AutoEncoders for Adversary Detection in the Presence of Noisy Images
Dec 09, 2021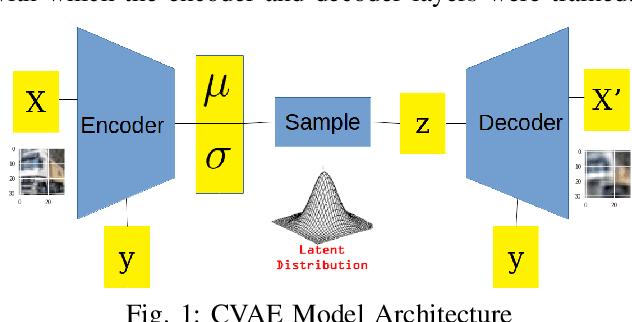
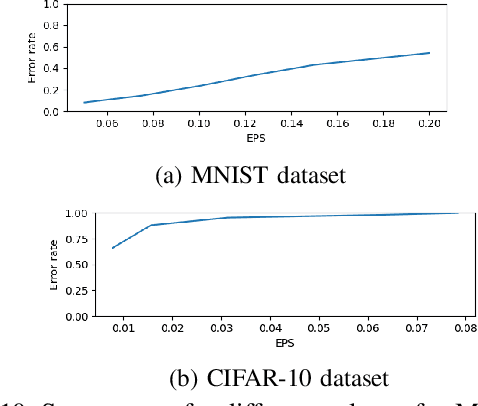
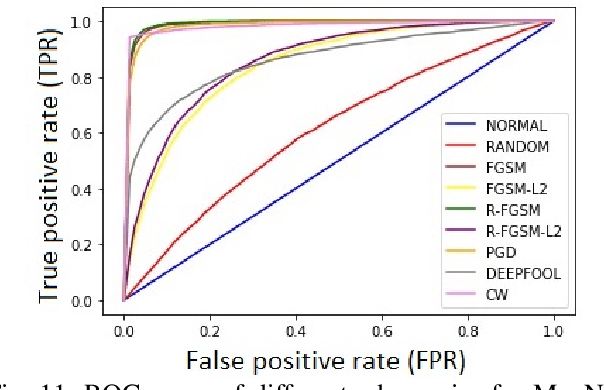
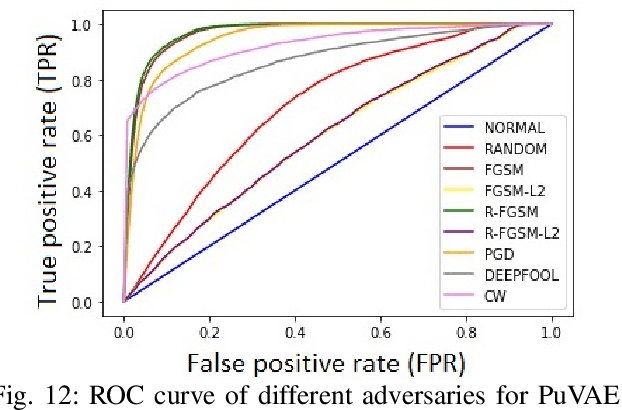
With the rapid advancement and increased use of deep learning models in image identification, security becomes a major concern to their deployment in safety-critical systems. Since the accuracy and robustness of deep learning models are primarily attributed from the purity of the training samples, therefore the deep learning architectures are often susceptible to adversarial attacks. Adversarial attacks are often obtained by making subtle perturbations to normal images, which are mostly imperceptible to humans, but can seriously confuse the state-of-the-art machine learning models. What is so special in the slightest intelligent perturbations or noise additions over normal images that it leads to catastrophic classifications by the deep neural networks? Using statistical hypothesis testing, we find that Conditional Variational AutoEncoders (CVAE) are surprisingly good at detecting imperceptible image perturbations. In this paper, we show how CVAEs can be effectively used to detect adversarial attacks on image classification networks. We demonstrate our results over MNIST, CIFAR-10 dataset and show how our method gives comparable performance to the state-of-the-art methods in detecting adversaries while not getting confused with noisy images, where most of the existing methods falter.
WSEBP: A Novel Width-depth Synchronous Extension-based Basis Pursuit Algorithm for Multi-Layer Convolutional Sparse Coding
Mar 30, 2022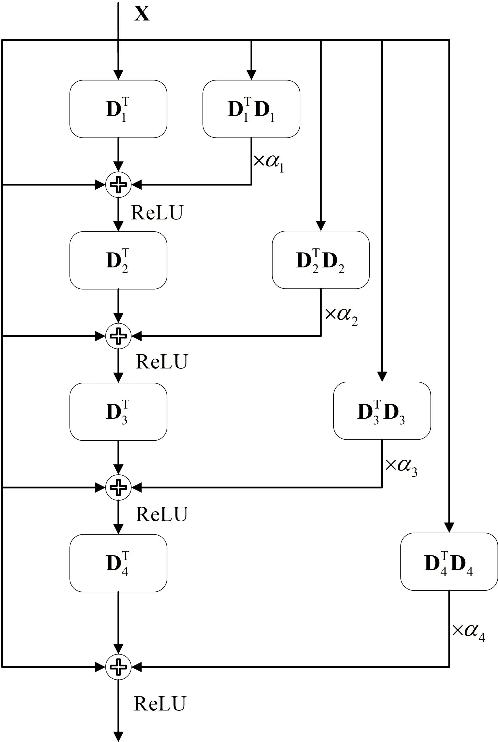
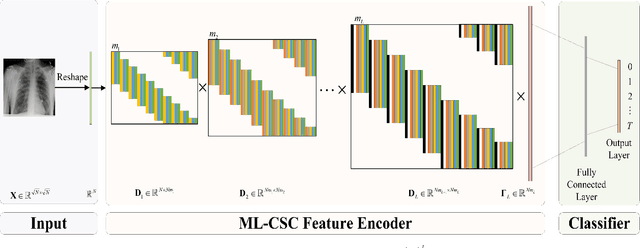
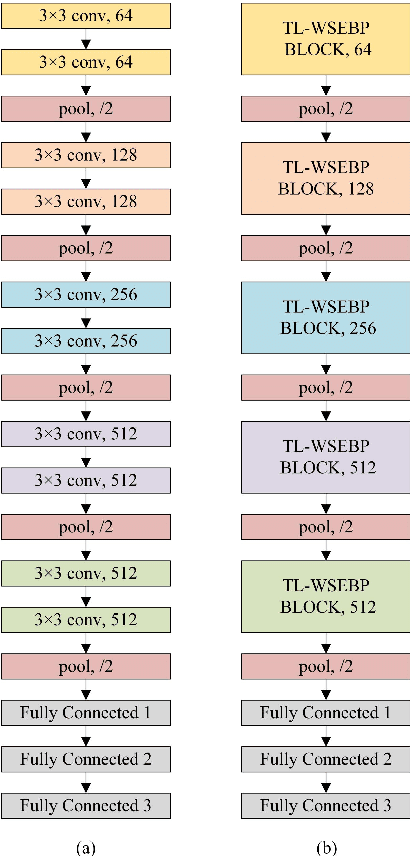
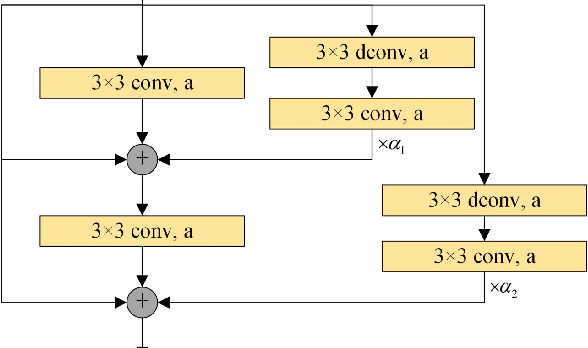
The pursuit algorithms integrated in multi-layer convolutional sparse coding (ML-CSC) can interpret the convolutional neural networks (CNNs). However, many current state-of-art (SOTA) pursuit algorithms require multiple iterations to optimize the solution of ML-CSC, which limits their applications to deeper CNNs due to high computational cost and large number of resources for getting very tiny gain of performance. In this study, we focus on the 0th iteration in pursuit algorithm by introducing an effective initialization strategy for each layer, by which the solution for ML-CSC can be improved. Specifically, we first propose a novel width-depth synchronous extension-based basis pursuit (WSEBP) algorithm which solves the ML-CSC problem without the limitation of the number of iterations compared to the SOTA algorithms and maximizes the performance by an effective initialization in each layer. Then, we propose a simple and unified ML-CSC-based classification network (ML-CSC-Net) which consists of an ML-CSC-based feature encoder and a fully-connected layer to validate the performance of WSEBP on image classification task. The experimental results show that our proposed WSEBP outperforms SOTA algorithms in terms of accuracy and consumption resources. In addition, the WSEBP integrated in CNNs can improve the performance of deeper CNNs and make them interpretable. Finally, taking VGG as an example, we propose WSEBP-VGG13 to enhance the performance of VGG13, which achieves competitive results on four public datasets, i.e., 87.79% vs. 86.83% on Cifar-10 dataset, 58.01% vs. 54.60% on Cifar-100 dataset, 91.52% vs. 89.58% on COVID-19 dataset, and 99.88% vs. 99.78% on Crack dataset, respectively. The results show the effectiveness of the proposed WSEBP, the improved performance of ML-CSC with WSEBP, and interpretation of the CNNs or deeper CNNs.
CoLLIE: Continual Learning of Language Grounding from Language-Image Embeddings
Nov 15, 2021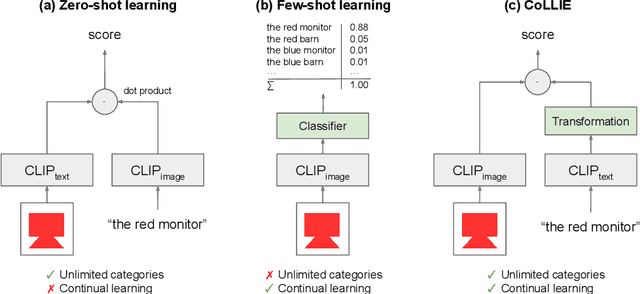
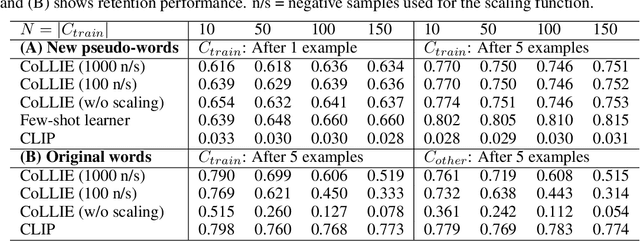
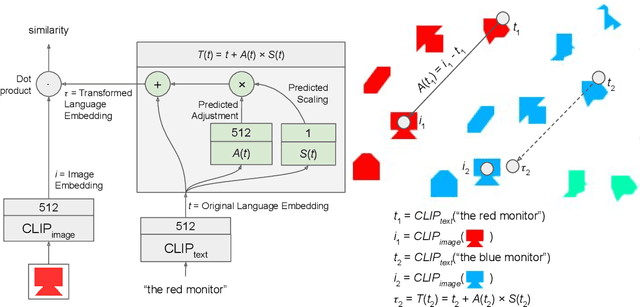
This paper presents CoLLIE: a simple, yet effective model for continual learning of how language is grounded in vision. Given a pre-trained multimodal embedding model, where language and images are projected in the same semantic space (in this case CLIP by OpenAI), CoLLIE learns a transformation function that adjusts the language embeddings when needed to accommodate new language use. Unlike traditional few-shot learning, the model does not just learn new classes and labels, but can also generalize to similar language use. We verify the model's performance on two different tasks of continual learning and show that it can efficiently learn and generalize from only a few examples, with little interference with the model's original zero-shot performance.
A Novel ANN Structure for Image Recognition
Oct 09, 2020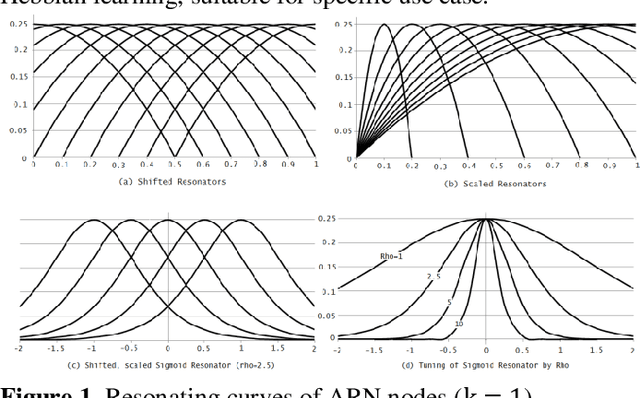
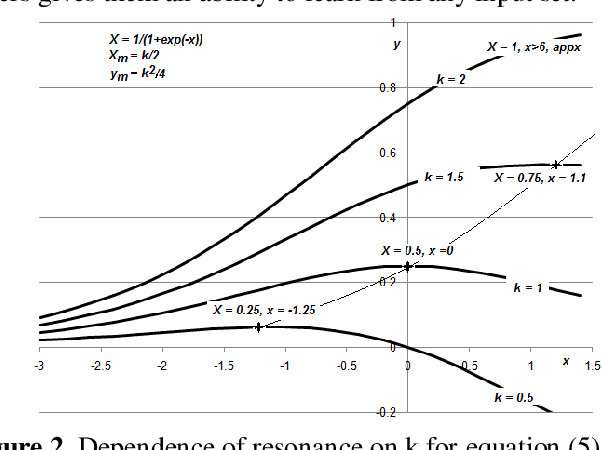
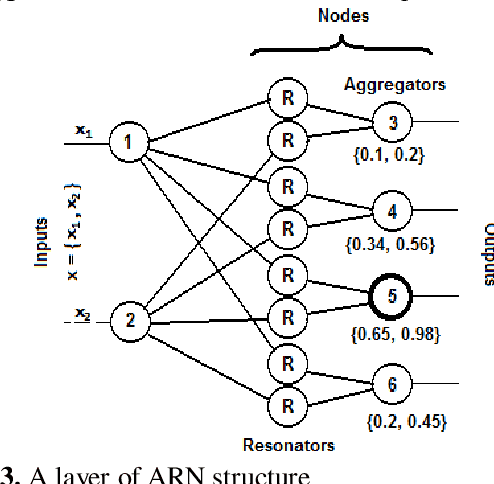
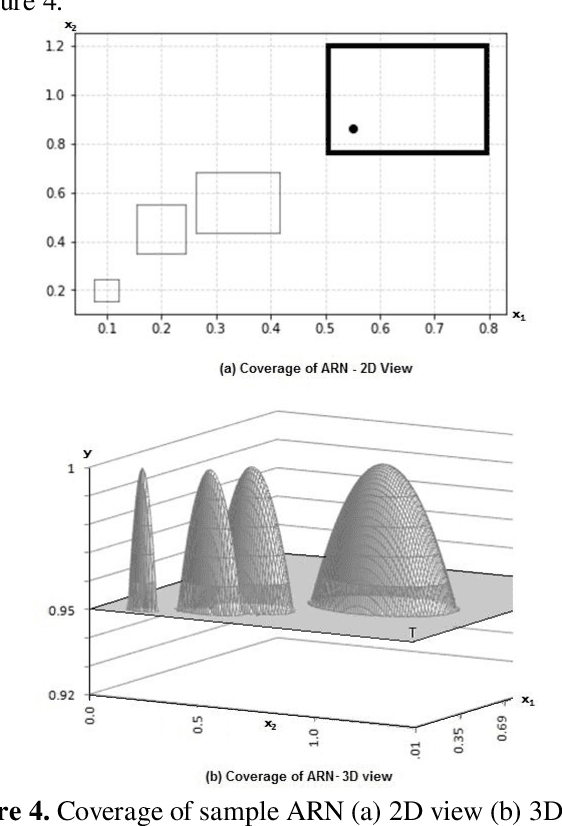
The paper presents Multi-layer Auto Resonance Networks (ARN), a new neural model, for image recognition. Neurons in ARN, called Nodes, latch on to an incoming pattern and resonate when the input is within its 'coverage.' Resonance allows the neuron to be noise tolerant and tunable. Coverage of nodes gives them an ability to approximate the incoming pattern. Its latching characteristics allow it to respond to episodic events without disturbing the existing trained network. These networks are capable of addressing problems in varied fields but have not been sufficiently explored. Implementation of an image classification and identification system using two-layer ARN is discussed in this paper. Recognition accuracy of 94% has been achieved for MNIST dataset with only two layers of neurons and just 50 samples per numeral, making it useful in computing at the edge of cloud infrastructure.
Deepfake Detection for Facial Images with Facemasks
Feb 23, 2022
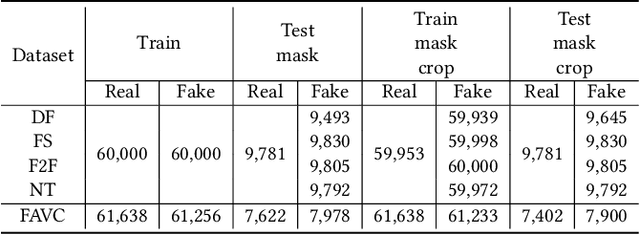
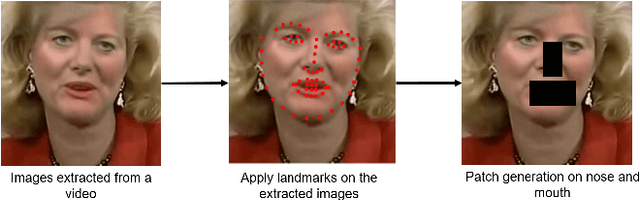
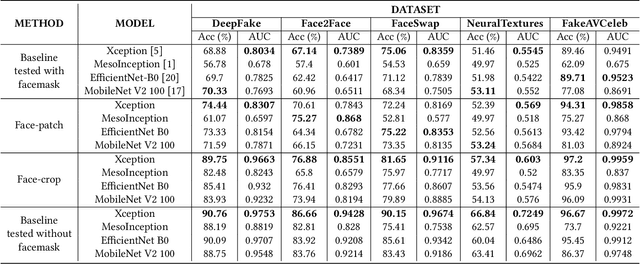
Hyper-realistic face image generation and manipulation have givenrise to numerous unethical social issues, e.g., invasion of privacy,threat of security, and malicious political maneuvering, which re-sulted in the development of recent deepfake detection methodswith the rising demands of deepfake forensics. Proposed deepfakedetection methods to date have shown remarkable detection perfor-mance and robustness. However, none of the suggested deepfakedetection methods assessed the performance of deepfakes withthe facemask during the pandemic crisis after the outbreak of theCovid-19. In this paper, we thoroughly evaluate the performance ofstate-of-the-art deepfake detection models on the deepfakes withthe facemask. Also, we propose two approaches to enhance themasked deepfakes detection:face-patchandface-crop. The experi-mental evaluations on both methods are assessed through the base-line deepfake detection models on the various deepfake datasets.Our extensive experiments show that, among the two methods,face-cropperforms better than theface-patch, and could be a trainmethod for deepfake detection models to detect fake faces withfacemask in real world.
Aesthetics and neural network image representations
Sep 16, 2021



We analyze the spaces of images encoded by generative networks of the BigGAN architecture. We find that generic multiplicative perturbations away from the photo-realistic point often lead to images which appear as "artistic renditions" of the corresponding objects. This demonstrates an emergence of aesthetic properties directly from the structure of the photo-realistic environment coupled with its neural network parametrization. Moreover, modifying a deep semantic part of the neural network encoding leads to the appearance of symbolic visual representations.
BlazeNeo: Blazing fast polyp segmentation and neoplasm detection
Feb 28, 2022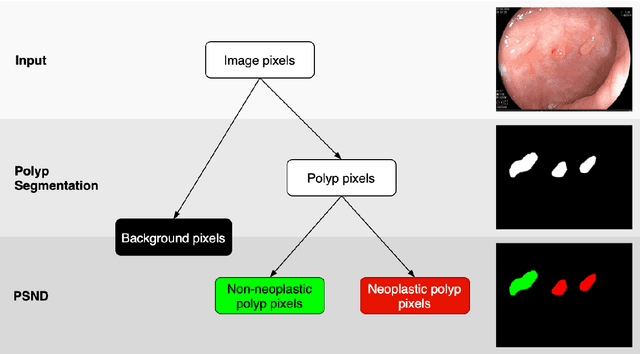

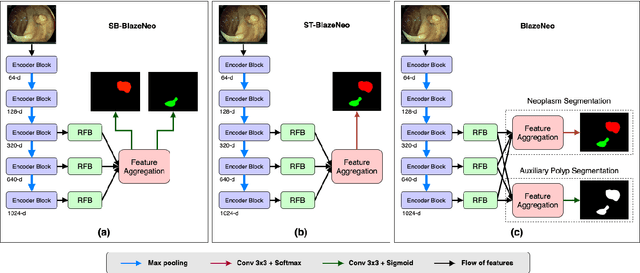
In recent years, computer-aided automatic polyp segmentation and neoplasm detection have been an emerging topic in medical image analysis, providing valuable support to colonoscopy procedures. Attentions have been paid to improving the accuracy of polyp detection and segmentation. However, not much focus has been given to latency and throughput for performing these tasks on dedicated devices, which can be crucial for practical applications. This paper introduces a novel deep neural network architecture called BlazeNeo, for the task of polyp segmentation and neoplasm detection with an emphasis on compactness and speed while maintaining high accuracy. The model leverages the highly efficient HarDNet backbone alongside lightweight Receptive Field Blocks for computational efficiency, and an auxiliary training mechanism to take full advantage of the training data for the segmentation quality. Our experiments on a challenging dataset show that BlazeNeo achieves improvements in latency and model size while maintaining comparable accuracy against state-of-the-art methods. When deploying on the Jetson AGX Xavier edge device in INT8 precision, our BlazeNeo achieves over 155 fps while yielding the best accuracy among all compared methods.
Optimizing High-Dimensional Physics Simulations via Composite Bayesian Optimization
Nov 29, 2021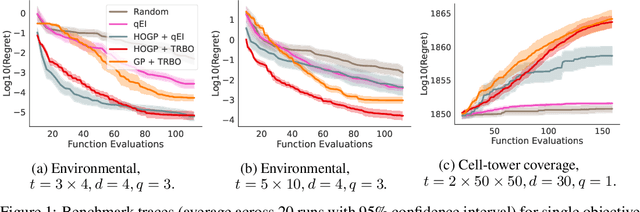
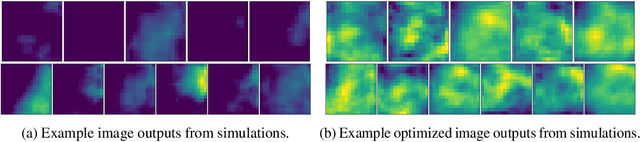
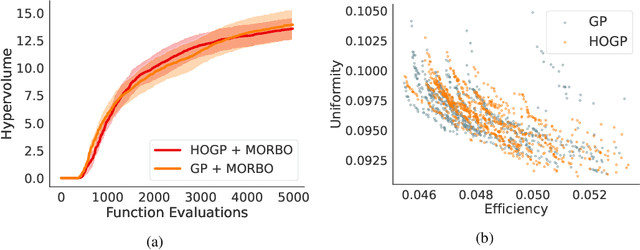
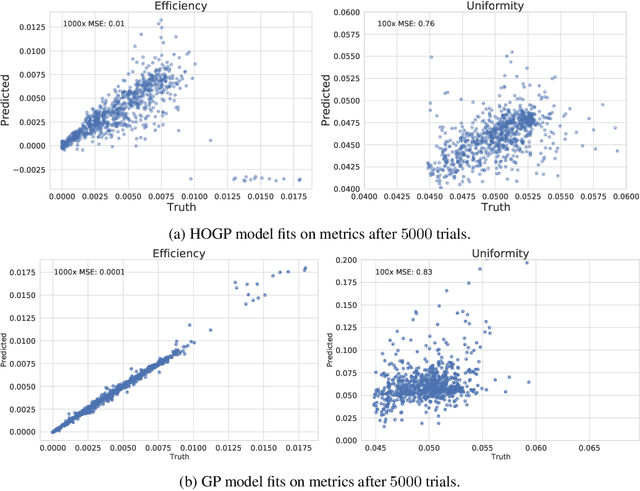
Physical simulation-based optimization is a common task in science and engineering. Many such simulations produce image- or tensor-based outputs where the desired objective is a function of those outputs, and optimization is performed over a high-dimensional parameter space. We develop a Bayesian optimization method leveraging tensor-based Gaussian process surrogates and trust region Bayesian optimization to effectively model the image outputs and to efficiently optimize these types of simulations, including a radio-frequency tower configuration problem and an optical design problem.
Implementation of Convolutional Neural Network Architecture on 3D Multiparametric Magnetic Resonance Imaging for Prostate Cancer Diagnosis
Dec 29, 2021
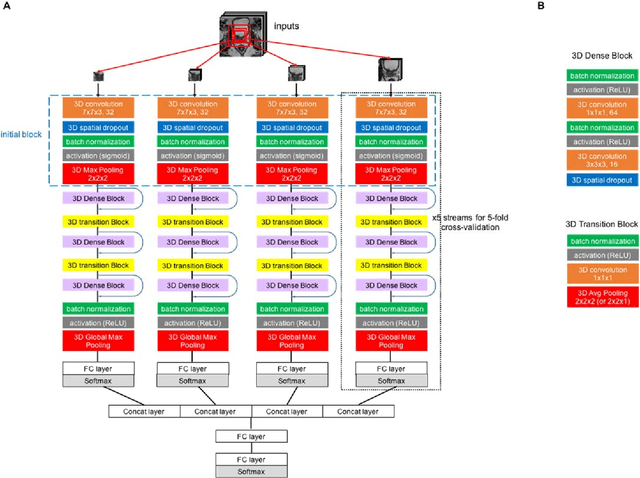
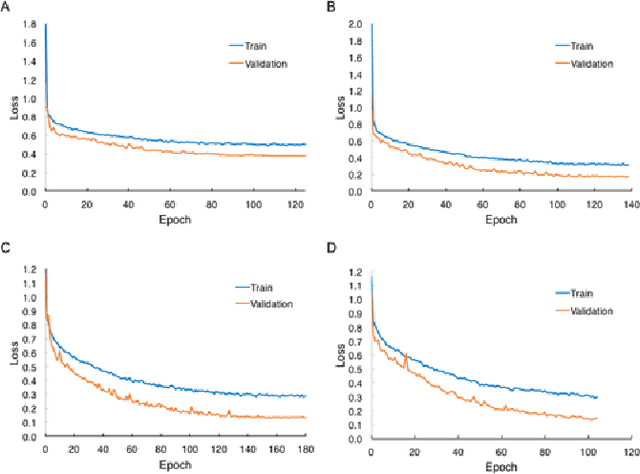
Prostate cancer is one of the most common causes of cancer deaths in men. There is a growing demand for noninvasively and accurately diagnostic methods that facilitate the current standard prostate cancer risk assessment in clinical practice. Still, developing computer-aided classification tools in prostate cancer diagnostics from multiparametric magnetic resonance images continues to be a challenge. In this work, we propose a novel deep learning approach for automatic classification of prostate lesions in the corresponding magnetic resonance images by constructing a two-stage multimodal multi-stream convolutional neural network (CNN)-based architecture framework. Without implementing sophisticated image preprocessing steps or third-party software, our framework achieved the classification performance with the area under a Receiver Operating Characteristic (ROC) curve value of 0.87. The result outperformed most of the submitted methods and shared the highest value reported by the PROSTATEx Challenge organizer. Our proposed CNN-based framework reflects the potential of assisting medical image interpretation in prostate cancer and reducing unnecessary biopsies.