 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Rich Recipe Representation as Plan to Support Expressive Multi Modal Queries on Recipe Content and Preparation Process
Mar 31, 2022
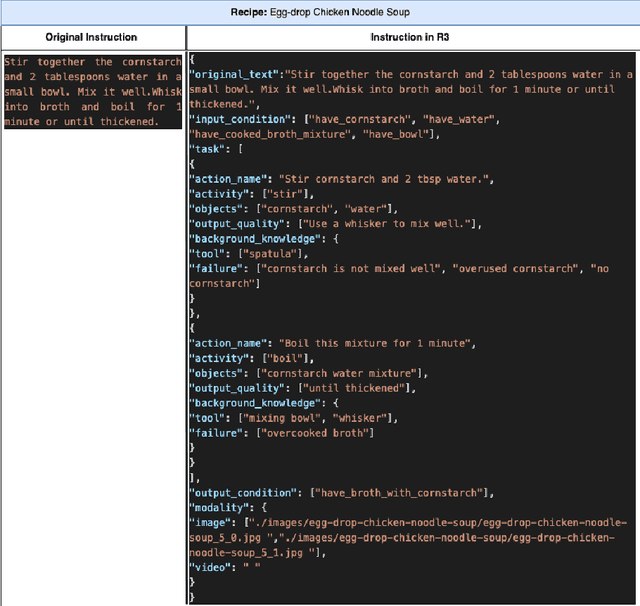
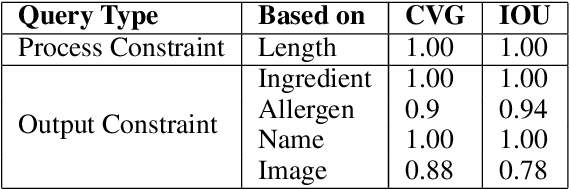
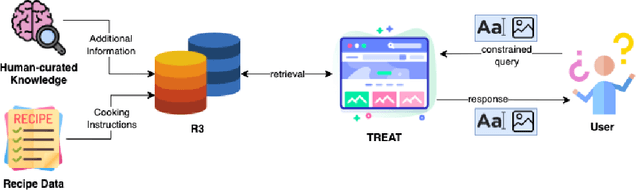
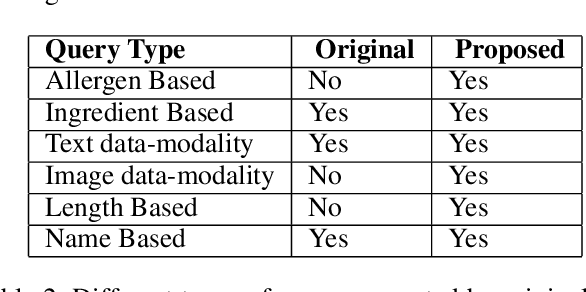
Food is not only a basic human necessity but also a key factor driving a society's health and economic well-being. As a result, the cooking domain is a popular use-case to demonstrate decision-support (AI) capabilities in service of benefits like precision health with tools ranging from information retrieval interfaces to task-oriented chatbots. An AI here should understand concepts in the food domain (e.g., recipes, ingredients), be tolerant to failures encountered while cooking (e.g., browning of butter), handle allergy-based substitutions, and work with multiple data modalities (e.g. text and images). However, the recipes today are handled as textual documents which makes it difficult for machines to read, reason and handle ambiguity. This demands a need for better representation of the recipes, overcoming the ambiguity and sparseness that exists in the current textual documents. In this paper, we discuss the construction of a machine-understandable rich recipe representation (R3), in the form of plans, from the recipes available in natural language. R3 is infused with additional knowledge such as information about allergens and images of ingredients, possible failures and tips for each atomic cooking step. To show the benefits of R3, we also present TREAT, a tool for recipe retrieval which uses R3 to perform multi-modal reasoning on the recipe's content (plan objects - ingredients and cooking tools), food preparation process (plan actions and time), and media type (image, text). R3 leads to improved retrieval efficiency and new capabilities that were hither-to not possible in textual representation.
This Looks Like That, Because ... Explaining Prototypes for Interpretable Image Recognition
Nov 05, 2020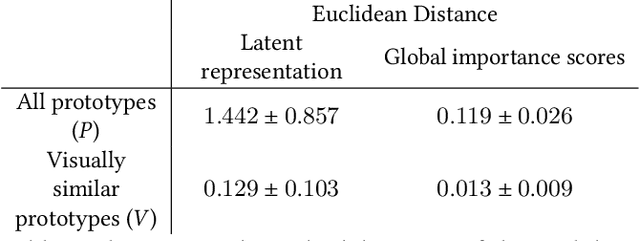


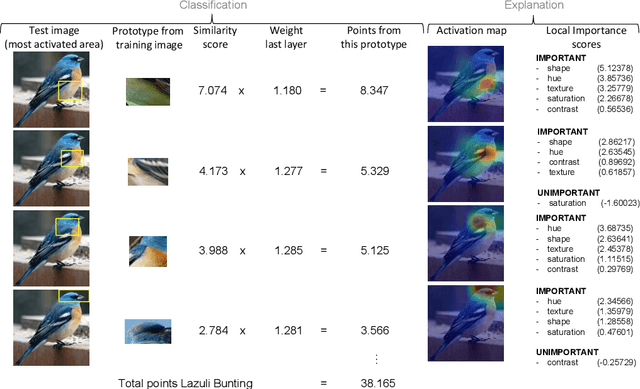
Image recognition with prototypes is considered an interpretable alternative for black box deep learning models. Classification depends on the extent to which a test image "looks like" a prototype. However, perceptual similarity for humans can be different from the similarity learnt by the model. A user is unaware of the underlying classification strategy and does not know which image characteristics (e.g., color or shape) is the dominant characteristic for the decision. We address this ambiguity and argue that prototypes should be explained. Only visualizing prototypes can be insufficient for understanding what a prototype exactly represents, and why a prototype and an image are considered similar. We improve interpretability by automatically enhancing prototypes with extra information about visual characteristics considered important by the model. Specifically, our method quantifies the influence of color hue, shape, texture, contrast and saturation in a prototype. We apply our method to the existing Prototypical Part Network (ProtoPNet) and show that our explanations clarify the meaning of a prototype which might have been interpreted incorrectly otherwise. We also reveal that visually similar prototypes can have the same explanations, indicating redundancy. Because of the generality of our approach, it can improve the interpretability of any similarity-based method for prototypical image recognition.
Exploring Motion Ambiguity and Alignment for High-Quality Video Frame Interpolation
Mar 19, 2022



For video frame interpolation (VFI), existing deep-learning-based approaches strongly rely on the ground-truth (GT) intermediate frames, which sometimes ignore the non-unique nature of motion judging from the given adjacent frames. As a result, these methods tend to produce averaged solutions that are not clear enough. To alleviate this issue, we propose to relax the requirement of reconstructing an intermediate frame as close to the GT as possible. Towards this end, we develop a texture consistency loss (TCL) upon the assumption that the interpolated content should maintain similar structures with their counterparts in the given frames. Predictions satisfying this constraint are encouraged, though they may differ from the pre-defined GT. Without the bells and whistles, our plug-and-play TCL is capable of improving the performance of existing VFI frameworks. On the other hand, previous methods usually adopt the cost volume or correlation map to achieve more accurate image/feature warping. However, the O(N^2) ({N refers to the pixel count}) computational complexity makes it infeasible for high-resolution cases. In this work, we design a simple, efficient (O(N)) yet powerful cross-scale pyramid alignment (CSPA) module, where multi-scale information is highly exploited. Extensive experiments justify the efficiency and effectiveness of the proposed strategy.
Permuted AdaIN: Enhancing the Representation of Local Cues in Image Classifiers
Oct 09, 2020
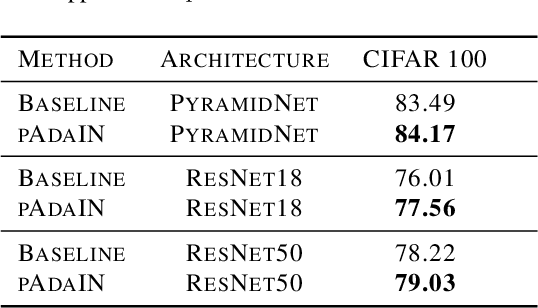
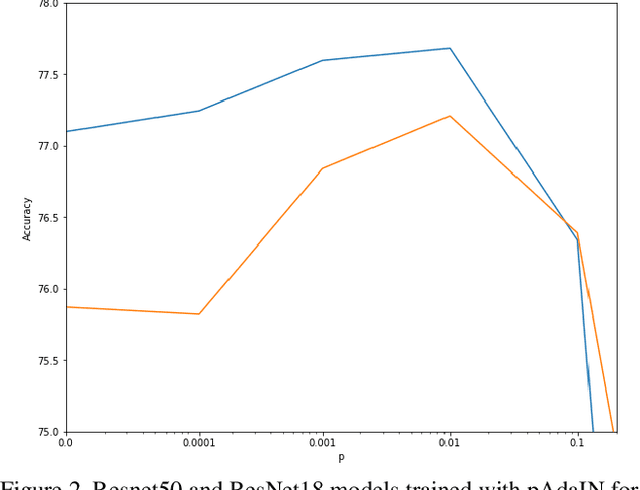
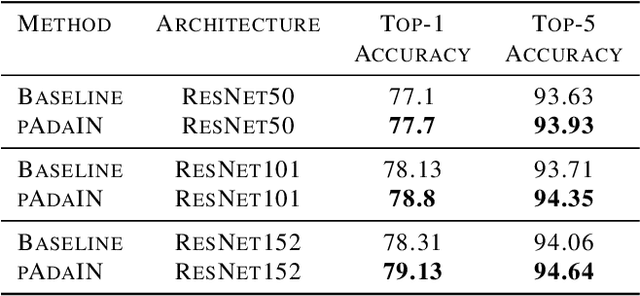
Recent work has shown that convolutional neural network classifiers overly rely on texture at the expense of shape cues, which adversely affects the classifier's performance in shifted domains. In this work, we make a similar but different distinction between local image cues, including shape and texture, and global image statistics. We provide a method that enhances the representation of local cues in the hidden layers of image classifiers. Our method, called Permuted Adaptive Instance Normalization (pAdaIN), samples a random permutation $\pi$ that rearranges the samples in a given batch. Adaptive Instance Normalization (AdaIN) is then applied between the activations of each (non-permuted) sample $i$ and the corresponding activations of the sample $\pi(i)$, thus swapping statistics between the samples of the batch. Since the global image statistics are distorted, this swapping procedure causes the network to rely on the local image cues. By choosing the random permutation with probability $p$ and the identity permutation otherwise, one can control the strength of this effect. With the correct choice of $p$, selected without considering the test data, our method consistently outperforms baseline methods in image classification, as well as in the setting of domain generalization.
TransCAM: Transformer Attention-based CAM Refinement for Weakly Supervised Semantic Segmentation
Mar 14, 2022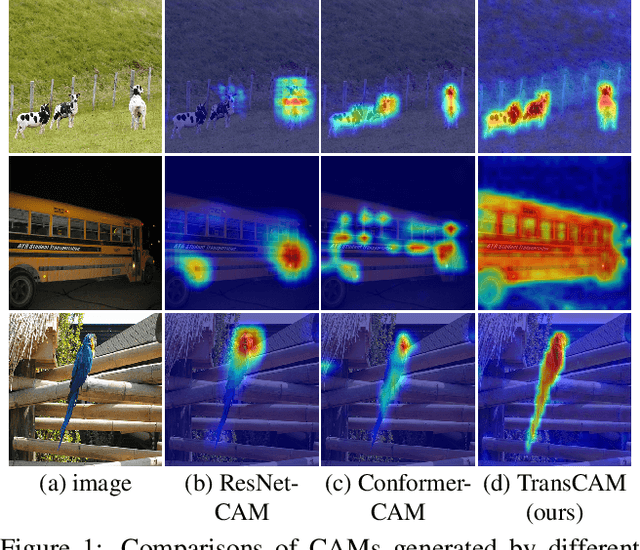

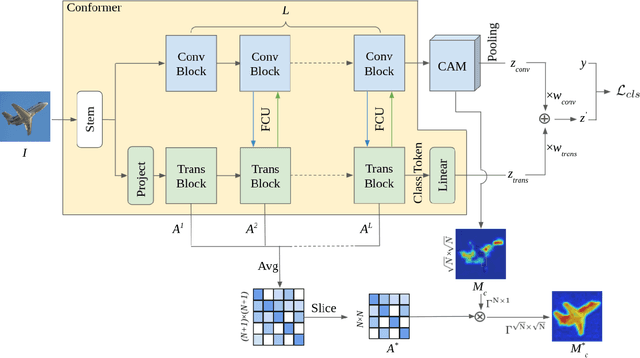

Weakly supervised semantic segmentation (WSSS) with only image-level supervision is a challenging task. Most existing methods exploit Class Activation Maps (CAM) to generate pixel-level pseudo labels for supervised training. However, due to the local receptive field of Convolution Neural Networks (CNN), CAM applied to CNNs often suffers from partial activation -- highlighting the most discriminative part instead of the entire object area. In order to capture both local features and global representations, the Conformer has been proposed to combine a visual transformer branch with a CNN branch. In this paper, we propose TransCAM, a Conformer-based solution to WSSS that explicitly leverages the attention weights from the transformer branch of the Conformer to refine the CAM generated from the CNN branch. TransCAM is motivated by our observation that attention weights from shallow transformer blocks are able to capture low-level spatial feature similarities while attention weights from deep transformer blocks capture high-level semantic context. Despite its simplicity, TransCAM achieves a new state-of-the-art performance of 69.3% and 69.6% on the respective PASCAL VOC 2012 validation and test sets, showing the effectiveness of transformer attention-based refinement of CAM for WSSS.
Refining Self-Supervised Learning in Imaging: Beyond Linear Metric
Feb 25, 2022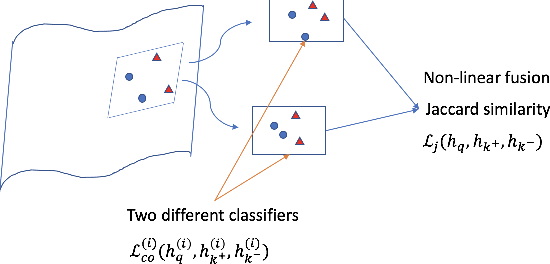
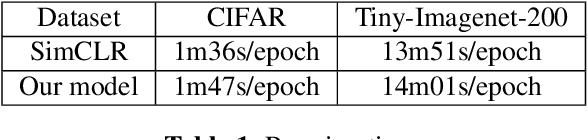
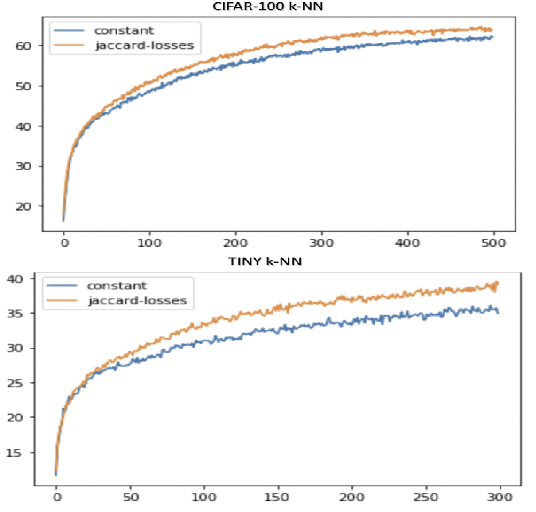
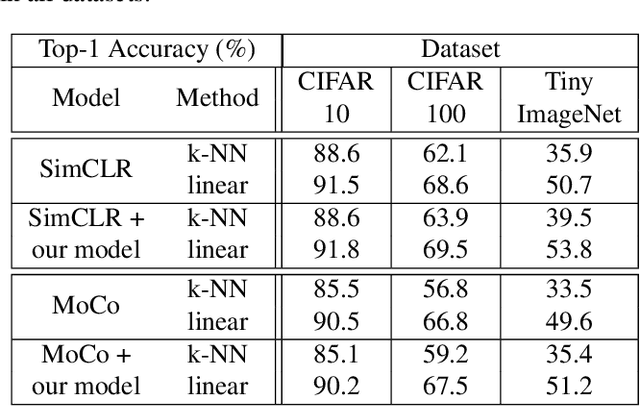
We introduce in this paper a new statistical perspective, exploiting the Jaccard similarity metric, as a measure-based metric to effectively invoke non-linear features in the loss of self-supervised contrastive learning. Specifically, our proposed metric may be interpreted as a dependence measure between two adapted projections learned from the so-called latent representations. This is in contrast to the cosine similarity measure in the conventional contrastive learning model, which accounts for correlation information. To the best of our knowledge, this effectively non-linearly fused information embedded in the Jaccard similarity, is novel to self-supervision learning with promising results. The proposed approach is compared to two state-of-the-art self-supervised contrastive learning methods on three image datasets. We not only demonstrate its amenable applicability in current ML problems, but also its improved performance and training efficiency.
Don't Get Me Wrong: How to apply Deep Visual Interpretations to Time Series
Mar 14, 2022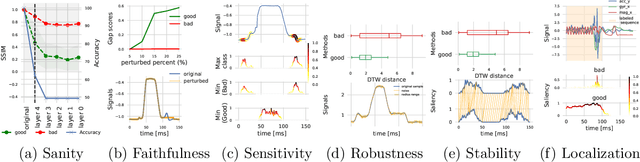
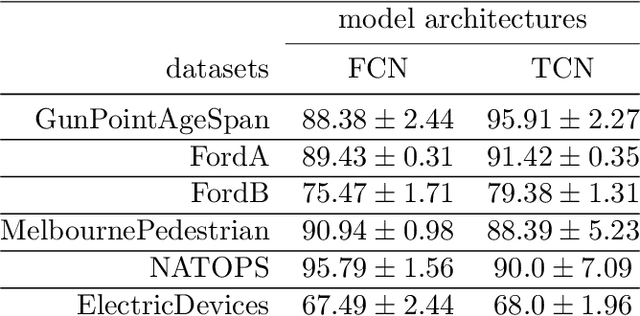
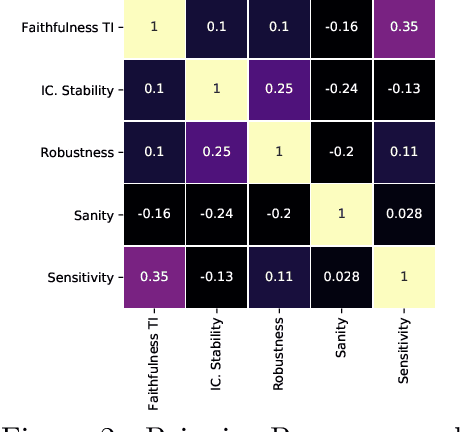
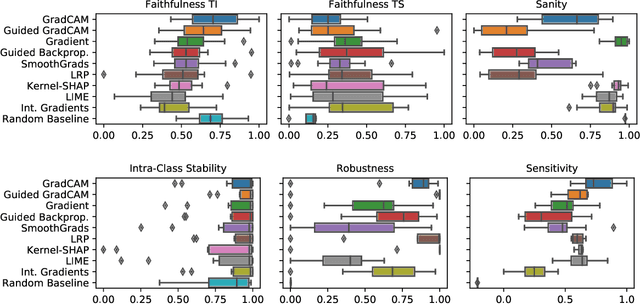
The correct interpretation and understanding of deep learning models is essential in many applications. Explanatory visual interpretation approaches for image and natural language processing allow domain experts to validate and understand almost any deep learning model. However, they fall short when generalizing to arbitrary time series data that is less intuitive and more diverse. Whether a visualization explains the true reasoning or captures the real features is difficult to judge. Hence, instead of blind trust we need an objective evaluation to obtain reliable quality metrics. We propose a framework of six orthogonal metrics for gradient- or perturbation-based post-hoc visual interpretation methods designed for time series classification and segmentation tasks. An experimental study includes popular neural network architectures for time series and nine visual interpretation methods. We evaluate the visual interpretation methods with diverse datasets from the UCR repository and a complex real-world dataset, and study the influence of common regularization techniques during training. We show that none of the methods consistently outperforms any of the others on all metrics while some are ahead at times. Our insights and recommendations allow experts to make informed choices of suitable visualization techniques for the model and task at hand.
Structure-Aware Flow Generation for Human Body Reshaping
Mar 09, 2022
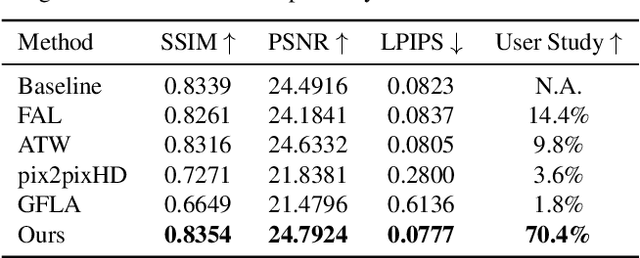
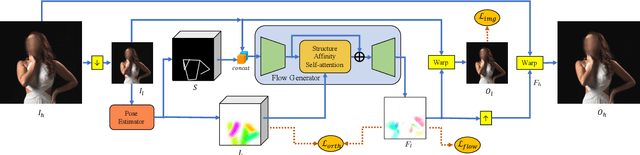
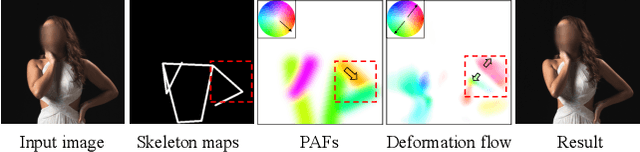
Body reshaping is an important procedure in portrait photo retouching. Due to the complicated structure and multifarious appearance of human bodies, existing methods either fall back on the 3D domain via body morphable model or resort to keypoint-based image deformation, leading to inefficiency and unsatisfied visual quality. In this paper, we address these limitations by formulating an end-to-end flow generation architecture under the guidance of body structural priors, including skeletons and Part Affinity Fields, and achieve unprecedentedly controllable performance under arbitrary poses and garments. A compositional attention mechanism is introduced for capturing both visual perceptual correlations and structural associations of the human body to reinforce the manipulation consistency among related parts. For a comprehensive evaluation, we construct the first large-scale body reshaping dataset, namely BR-5K, which contains 5,000 portrait photos as well as professionally retouched targets. Extensive experiments demonstrate that our approach significantly outperforms existing state-of-the-art methods in terms of visual performance, controllability, and efficiency. The dataset is available at our website: https://github.com/JianqiangRen/BodyReshaping5K.
Image Captioning using Multiple Transformers for Self-Attention Mechanism
Feb 14, 2021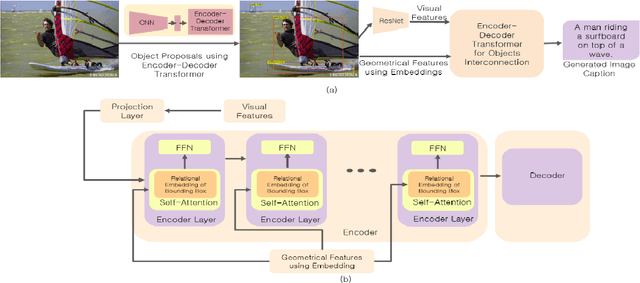
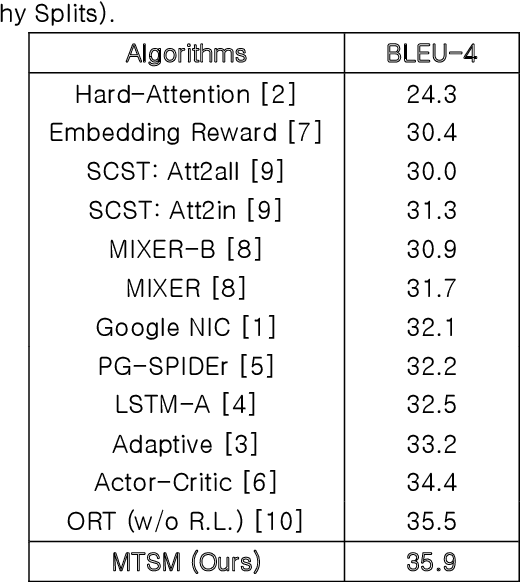
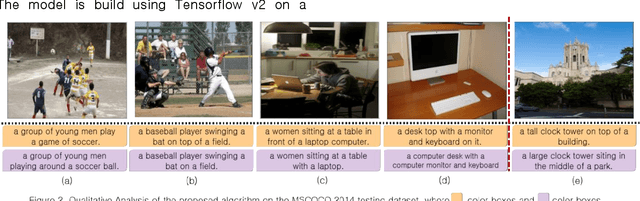

Real-time image captioning, along with adequate precision, is the main challenge of this research field. The present work, Multiple Transformers for Self-Attention Mechanism (MTSM), utilizes multiple transformers to address these problems. The proposed algorithm, MTSM, acquires region proposals using a transformer detector (DETR). Consequently, MTSM achieves the self-attention mechanism by transferring these region proposals and their visual and geometrical features through another transformer and learns the objects' local and global interconnections. The qualitative and quantitative results of the proposed algorithm, MTSM, are shown on the MSCOCO dataset.
Temporal Aggregation for Adaptive RGBT Tracking
Jan 29, 2022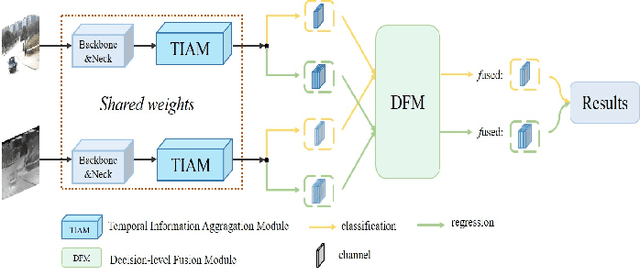
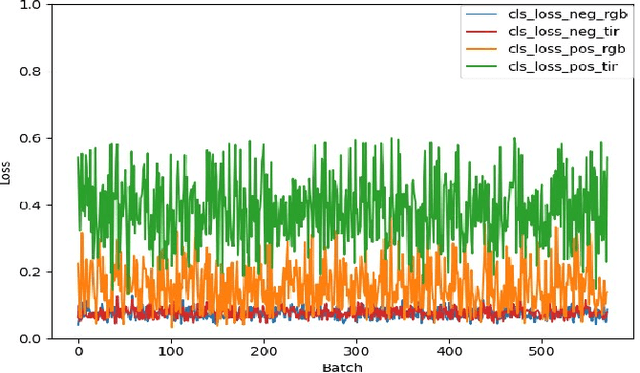
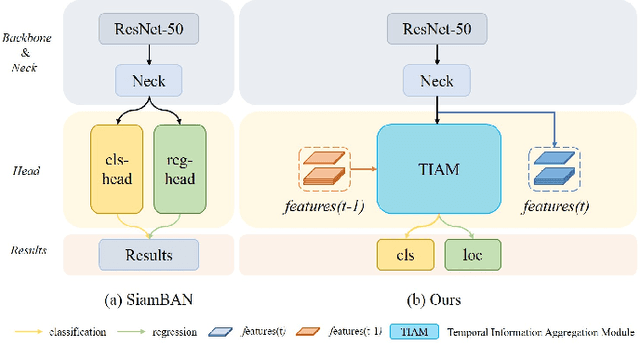
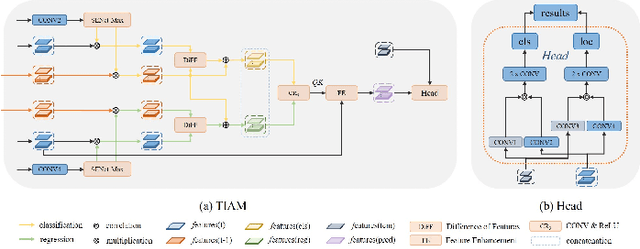
Visual object tracking with RGB and thermal infrared (TIR) spectra available, shorted in RGBT tracking, is a novel and challenging research topic which draws increasing attention nowadays. In this paper, we propose an RGBT tracker which takes spatio-temporal clues into account for robust appearance model learning, and simultaneously, constructs an adaptive fusion sub-network for cross-modal interactions. Unlike most existing RGBT trackers that implement object tracking tasks with only spatial information included, temporal information is further considered in this method. Specifically, different from traditional Siamese trackers, which only obtain one search image during the process of picking up template-search image pairs, an extra search sample adjacent to the original one is selected to predict the temporal transformation, resulting in improved robustness of tracking performance.As for multi-modal tracking, constrained to the limited RGBT datasets, the adaptive fusion sub-network is appended to our method at the decision level to reflect the complementary characteristics contained in two modalities. To design a thermal infrared assisted RGB tracker, the outputs of the classification head from the TIR modality are taken into consideration before the residual connection from the RGB modality. Extensive experimental results on three challenging datasets, i.e. VOT-RGBT2019, GTOT and RGBT210, verify the effectiveness of our method. Code will be shared at \textcolor{blue}{\emph{https://github.com/Zhangyong-Tang/TAAT}}.