 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Positional Encoding Augmented GAN for the Assessment of Wind Flow for Pedestrian Comfort in Urban Areas
Dec 15, 2021
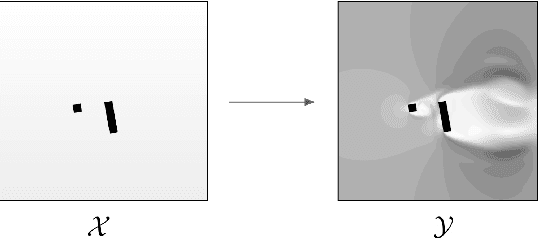
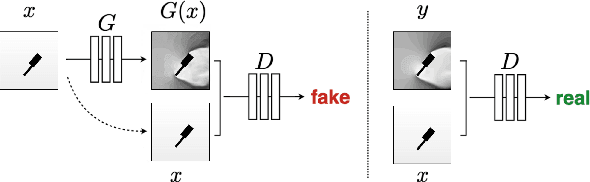

Approximating wind flows using computational fluid dynamics (CFD) methods can be time-consuming. Creating a tool for interactively designing prototypes while observing the wind flow change requires simpler models to simulate faster. Instead of running numerical approximations resulting in detailed calculations, data-driven methods in deep learning might be able to give similar results in a fraction of the time. This work rephrases the problem from computing 3D flow fields using CFD to a 2D image-to-image translation-based problem on the building footprints to predict the flow field at pedestrian height level. We investigate the use of generative adversarial networks (GAN), such as Pix2Pix [1] and CycleGAN [2] representing state-of-the-art for image-to-image translation task in various domains as well as U-Net autoencoder [3]. The models can learn the underlying distribution of a dataset in a data-driven manner, which we argue can help the model learn the underlying Reynolds-averaged Navier-Stokes (RANS) equations from CFD. We experiment on novel simulated datasets on various three-dimensional bluff-shaped buildings with and without height information. Moreover, we present an extensive qualitative and quantitative evaluation of the generated images for a selection of models and compare their performance with the simulations delivered by CFD. We then show that adding positional data to the input can produce more accurate results by proposing a general framework for injecting such information on the different architectures. Furthermore, we show that the models performances improve by applying attention mechanisms and spectral normalization to facilitate stable training.
Translation Consistent Semi-supervised Segmentation for 3D Medical Images
Mar 28, 2022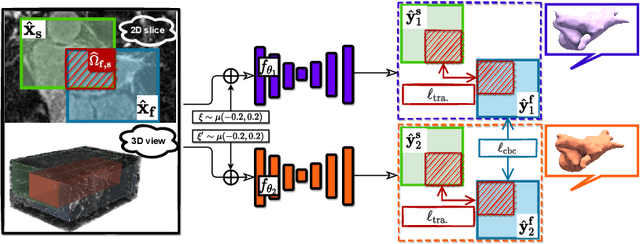
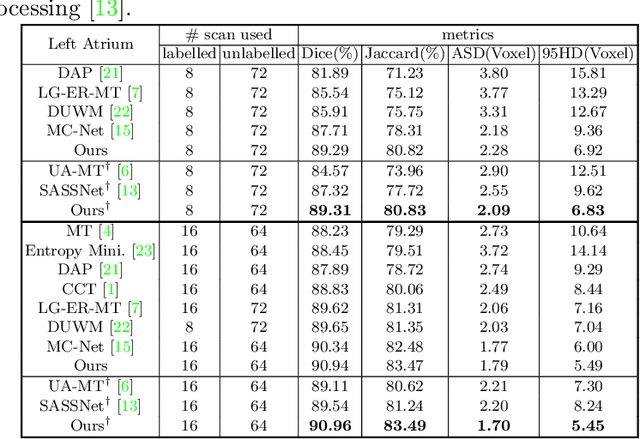
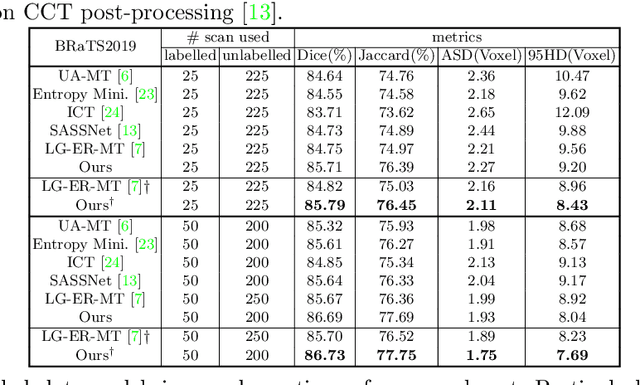
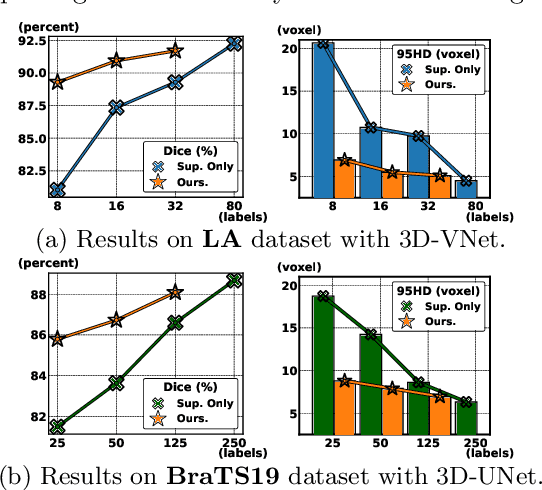
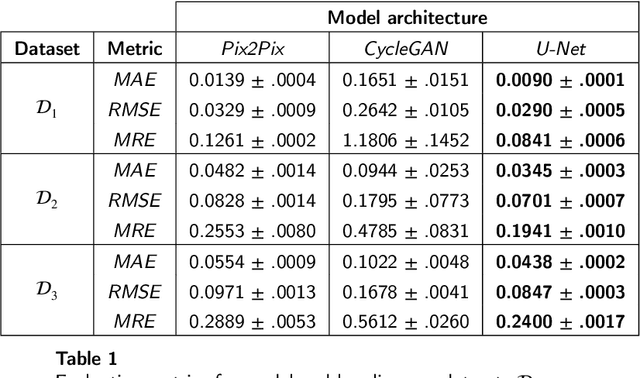
3D medical image segmentation methods have been successful, but their dependence on large amounts of voxel-level annotated data is a disadvantage that needs to be addressed given the high cost to obtain such annotation. Semi-supervised learning (SSL) solve this issue by training models with a large unlabelled and a small labelled dataset. The most successful SSL approaches are based on consistency learning that minimises the distance between model responses obtained from perturbed views of the unlabelled data. These perturbations usually keep the spatial input context between views fairly consistent, which may cause the model to learn segmentation patterns from the spatial input contexts instead of the segmented objects. In this paper, we introduce the Translation Consistent Co-training (TraCoCo) which is a consistency learning SSL method that perturbs the input data views by varying their spatial input context, allowing the model to learn segmentation patterns from visual objects. Furthermore, we propose the replacement of the commonly used mean squared error (MSE) semi-supervised loss by a new Cross-model confident Binary Cross entropy (CBC) loss, which improves training convergence and keeps the robustness to co-training pseudo-labelling mistakes. We also extend CutMix augmentation to 3D SSL to further improve generalisation. Our TraCoCo shows state-of-the-art results for the Left Atrium (LA) and Brain Tumor Segmentation (BRaTS19) datasets with different backbones. Our code is available at https://github.com/yyliu01/TraCoCo.
GANHopper: Multi-Hop GAN for Unsupervised Image-to-Image Translation
Feb 24, 2020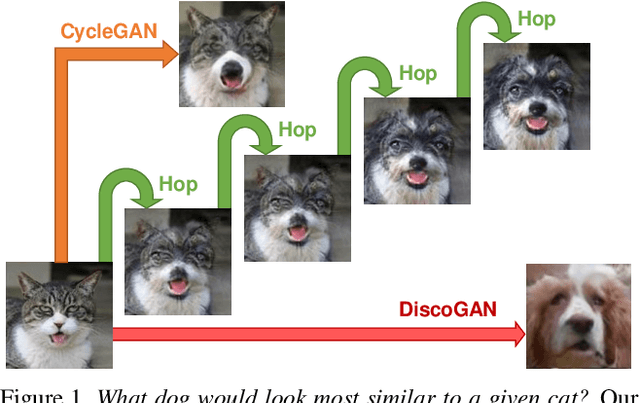
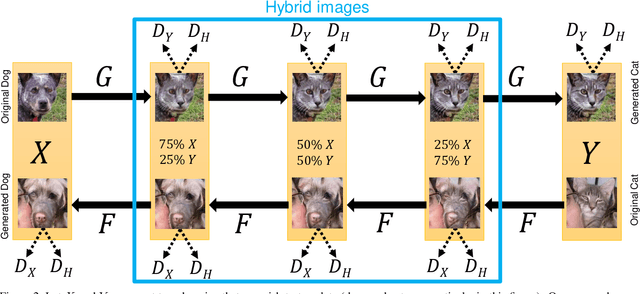
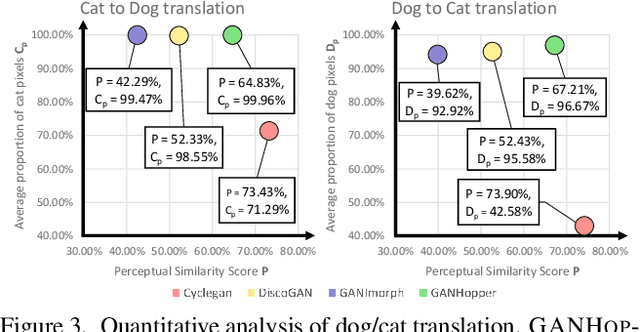
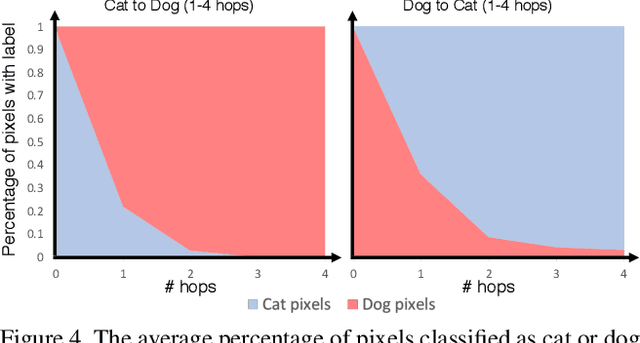
We introduce GANHOPPER, an unsupervised image-to-image translation network that transforms images gradually between two domains, through multiple hops. Instead of executing translation directly, we steer the translation by requiring the network to produce in-between images which resemble weighted hybrids between images from the two in-put domains. Our network is trained on unpaired images from the two domains only, without any in-between images.All hops are produced using a single generator along each direction. In addition to the standard cycle-consistency and adversarial losses, we introduce a new hybrid discrimina-tor, which is trained to classify the intermediate images produced by the generator as weighted hybrids, with weights based on a predetermined hop count. We also introduce a smoothness term to constrain the magnitude of each hop,further regularizing the translation. Compared to previous methods, GANHOPPER excels at image translations involving domain-specific image features and geometric variations while also preserving non-domain-specific features such as backgrounds and general color schemes.
SPICE: Semantic Pseudo-labeling for Image Clustering
Mar 17, 2021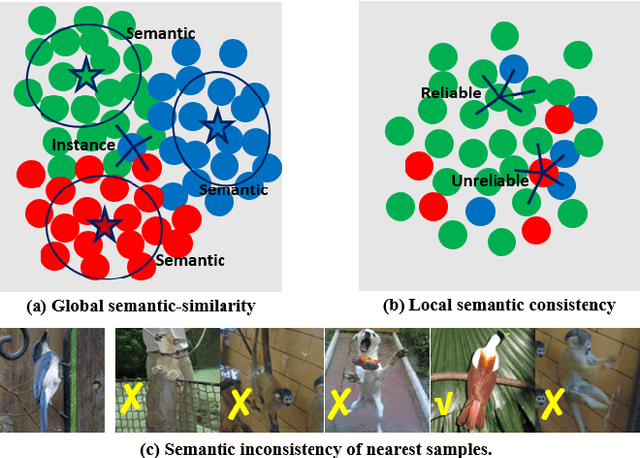
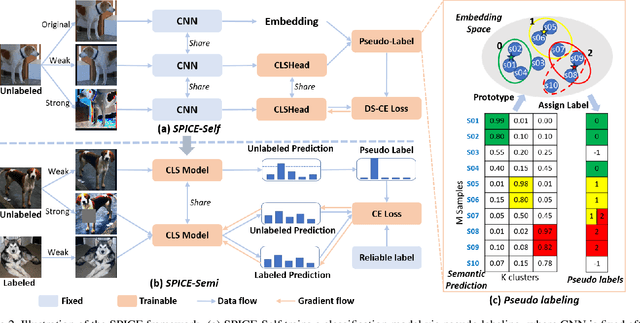
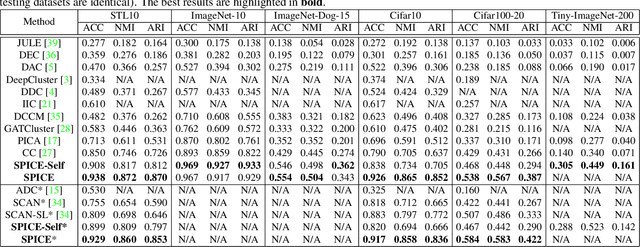
This paper presents SPICE, a Semantic Pseudo-labeling framework for Image ClustEring. Instead of using indirect loss functions required by the recently proposed methods, SPICE generates pseudo-labels via self-learning and directly uses the pseudo-label-based classification loss to train a deep clustering network. The basic idea of SPICE is to synergize the discrepancy among semantic clusters, the similarity among instance samples, and the semantic consistency of local samples in an embedding space to optimize the clustering network in a semantically-driven paradigm. Specifically, a semantic-similarity-based pseudo-labeling algorithm is first proposed to train a clustering network through unsupervised representation learning. Given the initial clustering results, a local semantic consistency principle is used to select a set of reliably labeled samples, and a semi-pseudo-labeling algorithm is adapted for performance boosting. Extensive experiments demonstrate that SPICE clearly outperforms the state-of-the-art methods on six common benchmark datasets including STL10, Cifar10, Cifar100-20, ImageNet-10, ImageNet-Dog, and Tiny-ImageNet. On average, our SPICE method improves the current best results by about 10% in terms of adjusted rand index, normalized mutual information, and clustering accuracy.
A naive method to discover directions in the StyleGAN2 latent space
Mar 19, 2022
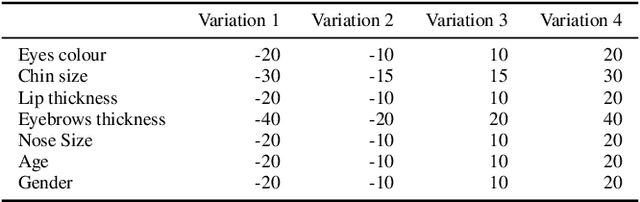

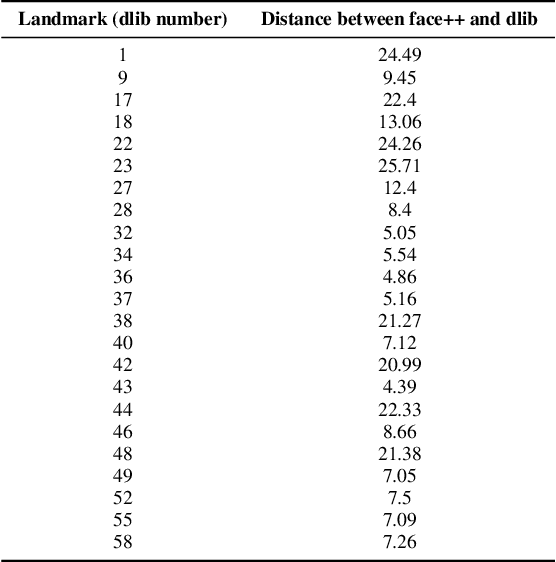
Several research groups have shown that Generative Adversarial Networks (GANs) can generate photo-realistic images in recent years. Using the GANs, a map is created between a latent code and a photo-realistic image. This process can also be reversed: given a photo as input, it is possible to obtain the corresponding latent code. In this paper, we will show how the inversion process can be easily exploited to interpret the latent space and control the output of StyleGAN2, a GAN architecture capable of generating photo-realistic faces. From a biological perspective, facial features such as nose size depend on important genetic factors, and we explore the latent spaces that correspond to such biological features, including masculinity and eye colour. We show the results obtained by applying the proposed method to a set of photos extracted from the CelebA-HQ database. We quantify some of these measures by utilizing two landmarking protocols, and evaluate their robustness through statistical analysis. Finally we correlate these measures with the input parameters used to perturb the latent spaces along those interpretable directions. Our results contribute towards building the groundwork of using such GAN architecture in forensics to generate photo-realistic faces that satisfy certain biological attributes.
Vehicle and License Plate Recognition with Novel Dataset for Toll Collection
Feb 11, 2022

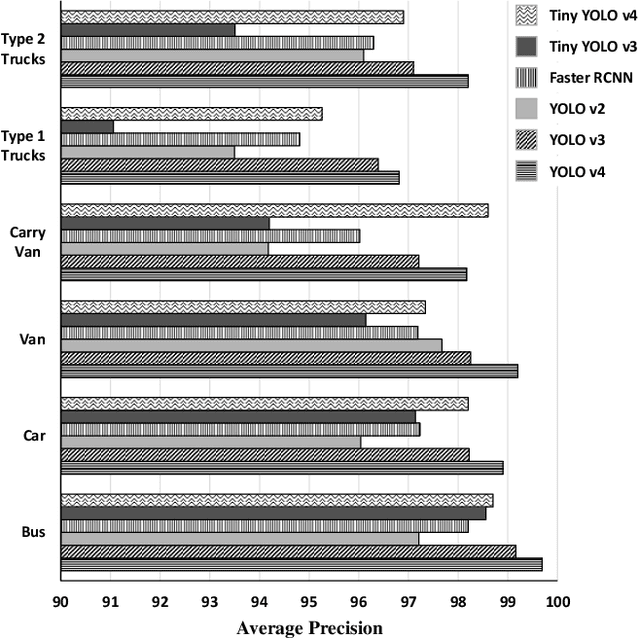

We propose an automatic framework for toll collection, consisting of three steps: vehicle type recognition, license plate localization, and reading. However, each of the three steps becomes non-trivial due to image variations caused by several factors. The traditional vehicle decorations on the front cause variations among vehicles of the same type. These decorations make license plate localization and recognition difficult due to severe background clutter and partial occlusions. Likewise, on most vehicles, specifically trucks, the position of the license plate is not consistent. Lastly, for license plate reading, the variations are induced by non-uniform font styles, sizes, and partially occluded letters and numbers. Our proposed framework takes advantage of both data availability and performance evaluation of the backbone deep learning architectures. We gather a novel dataset, \emph{Diverse Vehicle and License Plates Dataset (DVLPD)}, consisting of 10k images belonging to six vehicle types. Each image is then manually annotated for vehicle type, license plate, and its characters and digits. For each of the three tasks, we evaluate You Only Look Once (YOLO)v2, YOLOv3, YOLOv4, and FasterRCNN. For real-time implementation on a Raspberry Pi, we evaluate the lighter versions of YOLO named Tiny YOLOv3 and Tiny YOLOv4. The best Mean Average Precision (mAP@0.5) of 98.8% for vehicle type recognition, 98.5% for license plate detection, and 98.3% for license plate reading is achieved by YOLOv4, while its lighter version, i.e., Tiny YOLOv4 obtained a mAP of 97.1%, 97.4%, and 93.7% on vehicle type recognition, license plate detection, and license plate reading, respectively. The dataset and the training codes are available at https://github.com/usama-x930/VT-LPR
ViT-FOD: A Vision Transformer based Fine-grained Object Discriminator
Mar 24, 2022



Recently, several Vision Transformer (ViT) based methods have been proposed for Fine-Grained Visual Classification (FGVC).These methods significantly surpass existing CNN-based ones, demonstrating the effectiveness of ViT in FGVC tasks.However, there are some limitations when applying ViT directly to FGVC.First, ViT needs to split images into patches and calculate the attention of every pair, which may result in heavy redundant calculation and unsatisfying performance when handling fine-grained images with complex background and small objects.Second, a standard ViT only utilizes the class token in the final layer for classification, which is not enough to extract comprehensive fine-grained information. To address these issues, we propose a novel ViT based fine-grained object discriminator for FGVC tasks, ViT-FOD for short. Specifically, besides a ViT backbone, it further introduces three novel components, i.e, Attention Patch Combination (APC), Critical Regions Filter (CRF), and Complementary Tokens Integration (CTI). Thereinto, APC pieces informative patches from two images to generate a new image so that the redundant calculation can be reduced. CRF emphasizes tokens corresponding to discriminative regions to generate a new class token for subtle feature learning. To extract comprehensive information, CTI integrates complementary information captured by class tokens in different ViT layers. We conduct comprehensive experiments on widely used datasets and the results demonstrate that ViT-FOD is able to achieve state-of-the-art performance.
End-to-End Human-Gaze-Target Detection with Transformers
Mar 24, 2022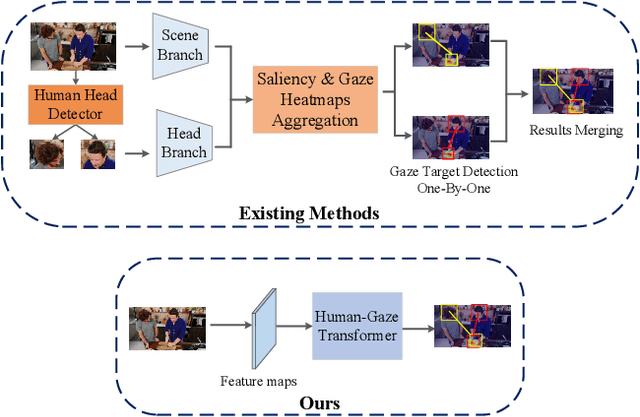
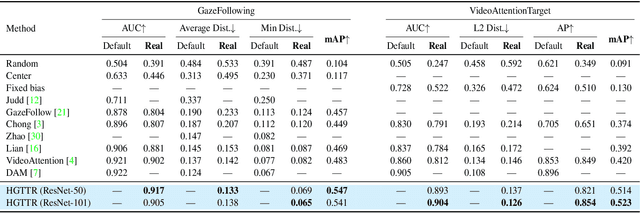
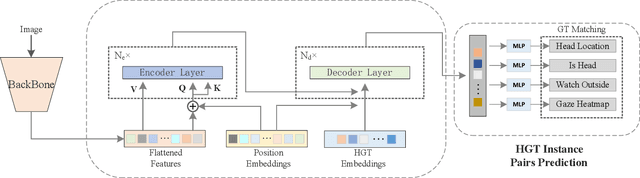
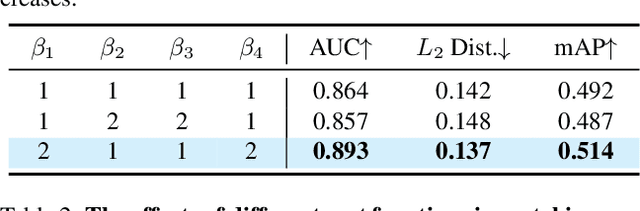
In this paper, we propose an effective and efficient method for Human-Gaze-Target (HGT) detection, i.e., gaze following. Current approaches decouple the HGT detection task into separate branches of salient object detection and human gaze prediction, employing a two-stage framework where human head locations must first be detected and then be fed into the next gaze target prediction sub-network. In contrast, we redefine the HGT detection task as detecting human head locations and their gaze targets, simultaneously. By this way, our method, named Human-Gaze-Target detection TRansformer or HGTTR, streamlines the HGT detection pipeline by eliminating all other additional components. HGTTR reasons about the relations of salient objects and human gaze from the global image context. Moreover, unlike existing two-stage methods that require human head locations as input and can predict only one human's gaze target at a time, HGTTR can directly predict the locations of all people and their gaze targets at one time in an end-to-end manner. The effectiveness and robustness of our proposed method are verified with extensive experiments on the two standard benchmark datasets, GazeFollowing and VideoAttentionTarget. Without bells and whistles, HGTTR outperforms existing state-of-the-art methods by large margins (6.4 mAP gain on GazeFollowing and 10.3 mAP gain on VideoAttentionTarget) with a much simpler architecture.
An implementation of the "Guess who?" game using CLIP
Nov 30, 2021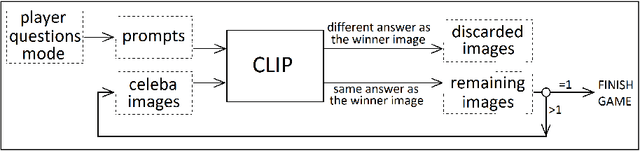
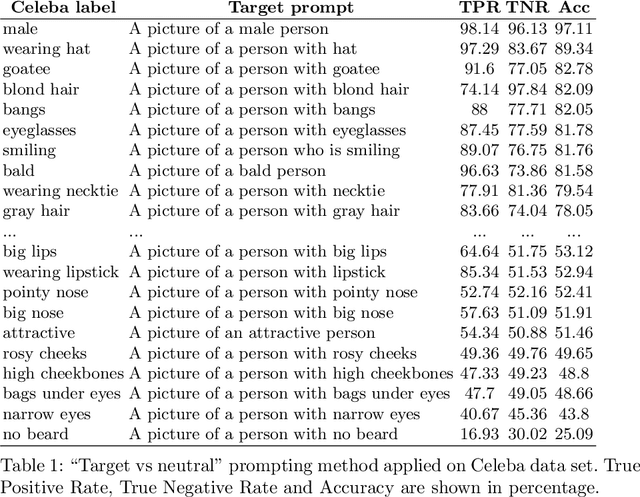
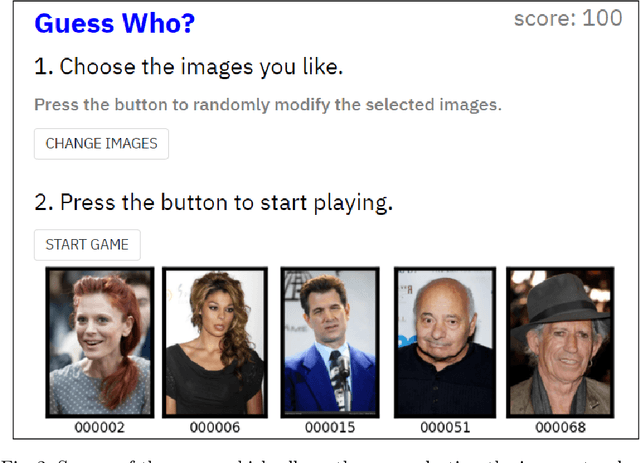
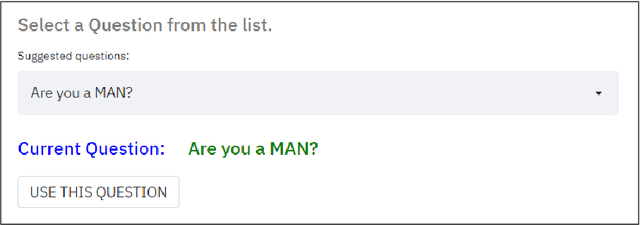
CLIP (Contrastive Language-Image Pretraining) is an efficient method for learning computer vision tasks from natural language supervision that has powered a recent breakthrough in deep learning due to its zero-shot transfer capabilities. By training from image-text pairs available on the internet, the CLIP model transfers non-trivially to most tasks without the need for any data set specific training. In this work, we use CLIP to implement the engine of the popular game "Guess who?", so that the player interacts with the game using natural language prompts and CLIP automatically decides whether an image in the game board fulfills that prompt or not. We study the performance of this approach by benchmarking on different ways of prompting the questions to CLIP, and show the limitations of its zero-shot capabilites.
* Code available at https://github.com/ArnauDIMAI/CLIP-GuessWho
Access Control of Object Detection Models Using Encrypted Feature Maps
Feb 01, 2022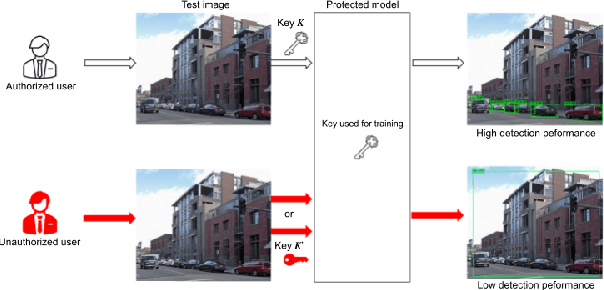
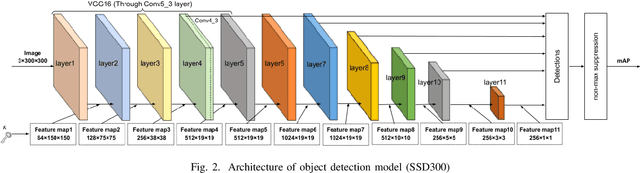
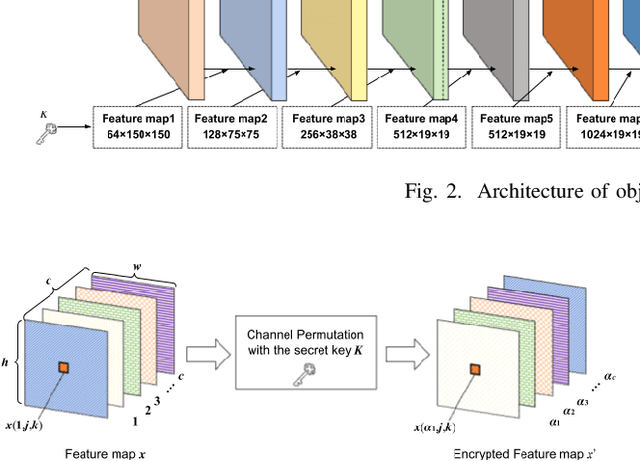

In this paper, we propose an access control method for object detection models. The use of encrypted images or encrypted feature maps has been demonstrated to be effective in access control of models from unauthorized access. However, the effectiveness of the approach has been confirmed in only image classification models and semantic segmentation models, but not in object detection models. In this paper, the use of encrypted feature maps is shown to be effective in access control of object detection models for the first time.