 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Deblur and Rotate Motion-Blurred Faces
Dec 14, 2021
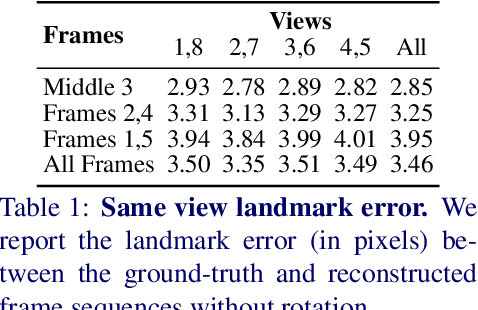
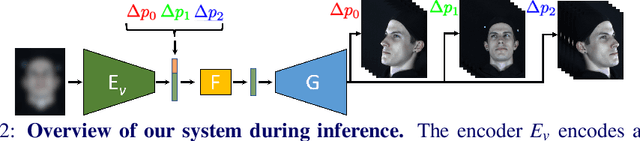
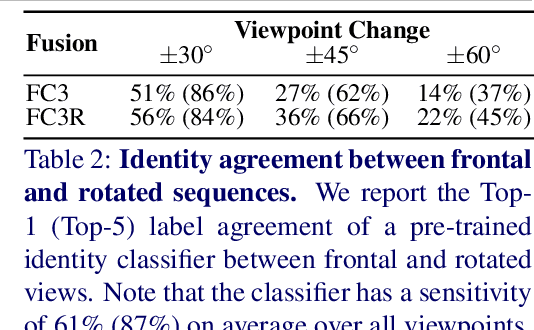
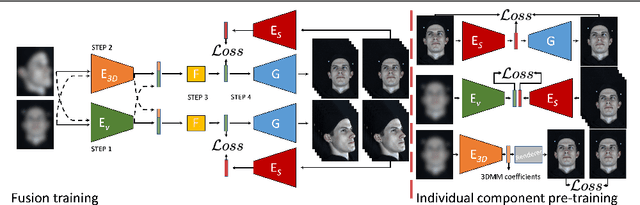
We propose a solution to the novel task of rendering sharp videos from new viewpoints from a single motion-blurred image of a face. Our method handles the complexity of face blur by implicitly learning the geometry and motion of faces through the joint training on three large datasets: FFHQ and 300VW, which are publicly available, and a new Bern Multi-View Face Dataset (BMFD) that we built. The first two datasets provide a large variety of faces and allow our model to generalize better. BMFD instead allows us to introduce multi-view constraints, which are crucial to synthesizing sharp videos from a new camera view. It consists of high frame rate synchronized videos from multiple views of several subjects displaying a wide range of facial expressions. We use the high frame rate videos to simulate realistic motion blur through averaging. Thanks to this dataset, we train a neural network to reconstruct a 3D video representation from a single image and the corresponding face gaze. We then provide a camera viewpoint relative to the estimated gaze and the blurry image as input to an encoder-decoder network to generate a video of sharp frames with a novel camera viewpoint. We demonstrate our approach on test subjects of our multi-view dataset and VIDTIMIT.
Spatial-Spectral Clustering with Anchor Graph for Hyperspectral Image
Apr 24, 2021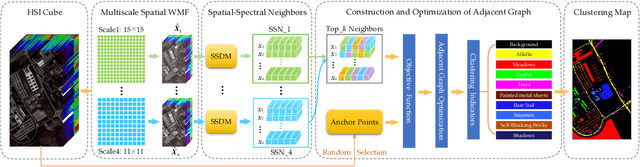
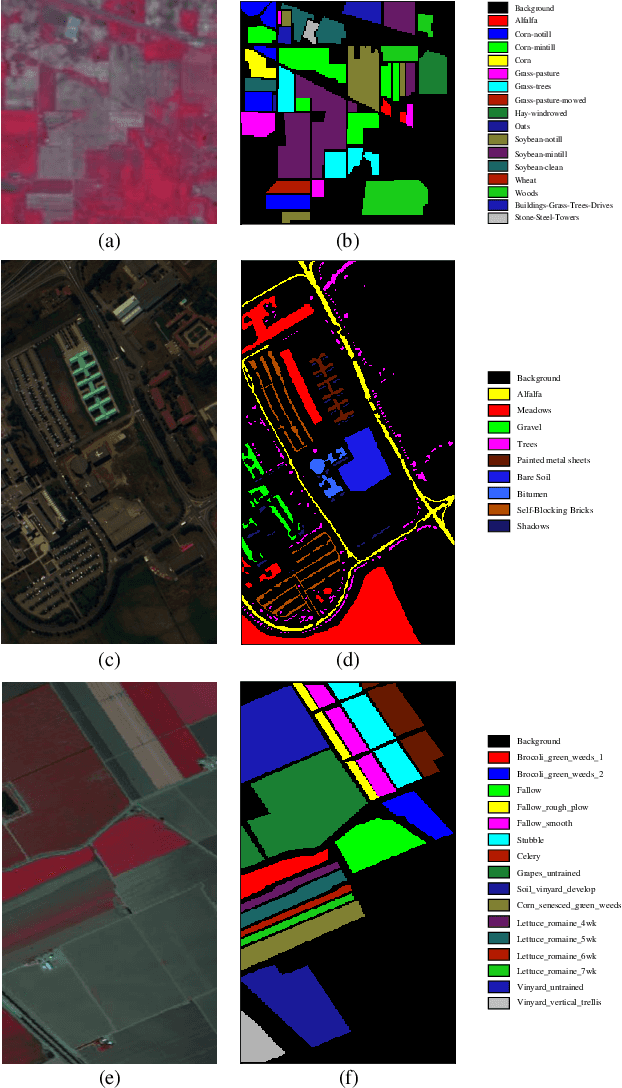
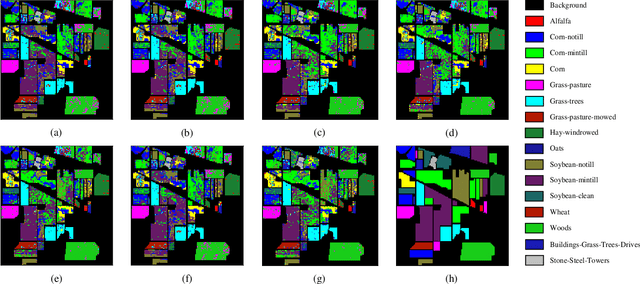
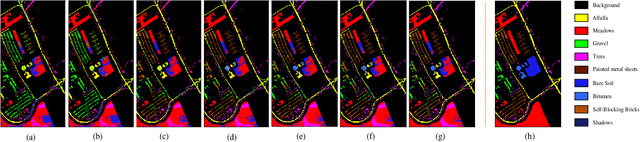
Hyperspectral image (HSI) clustering, which aims at dividing hyperspectral pixels into clusters, has drawn significant attention in practical applications. Recently, many graph-based clustering methods, which construct an adjacent graph to model the data relationship, have shown dominant performance. However, the high dimensionality of HSI data makes it hard to construct the pairwise adjacent graph. Besides, abundant spatial structures are often overlooked during the clustering procedure. In order to better handle the high dimensionality problem and preserve the spatial structures, this paper proposes a novel unsupervised approach called spatial-spectral clustering with anchor graph (SSCAG) for HSI data clustering. The SSCAG has the following contributions: 1) the anchor graph-based strategy is used to construct a tractable large graph for HSI data, which effectively exploits all data points and reduces the computational complexity; 2) a new similarity metric is presented to embed the spatial-spectral information into the combined adjacent graph, which can mine the intrinsic property structure of HSI data; 3) an effective neighbors assignment strategy is adopted in the optimization, which performs the singular value decomposition (SVD) on the adjacent graph to get solutions efficiently. Extensive experiments on three public HSI datasets show that the proposed SSCAG is competitive against the state-of-the-art approaches.
A Preliminary Comparison Between Compressive Sampling and Anisotropic Mesh-based Image Representation
Dec 14, 2020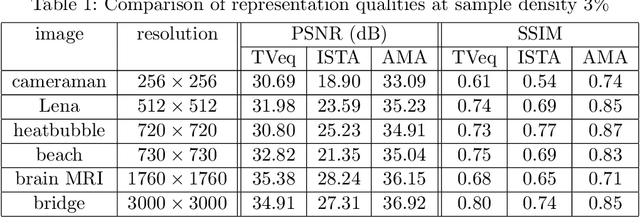
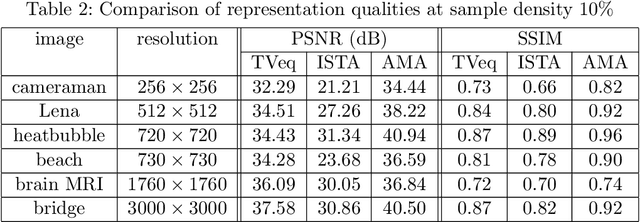

Compressed sensing (CS) has become a popular field in the last two decades to represent and reconstruct a sparse signal with much fewer samples than the signal itself. Although regular images are not sparse on their own, many can be sparsely represented in wavelet transform domain. Therefore, CS has also been widely applied to represent digital images. However, an alternative approach, adaptive sampling such as mesh-based image representation (MbIR), has not attracted as much attention. MbIR works directly on image pixels and represents the image with fewer points using a triangular mesh. In this paper, we perform a preliminary comparison between the CS and a recently developed MbIR method, AMA representation. The results demonstrate that, at the same sample density, AMA representation can provide better reconstruction quality than CS based on the tested algorithms. Further investigation with recent algorithms is needed to perform a thorough comparison.
Semi-Supervised Image Deraining using Gaussian Processes
Sep 25, 2020
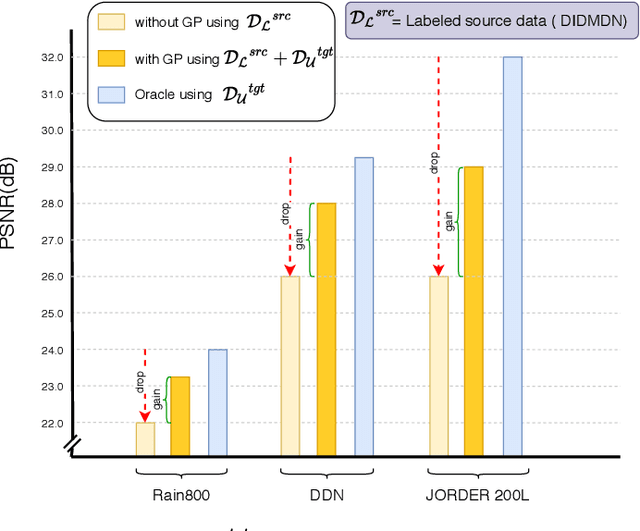

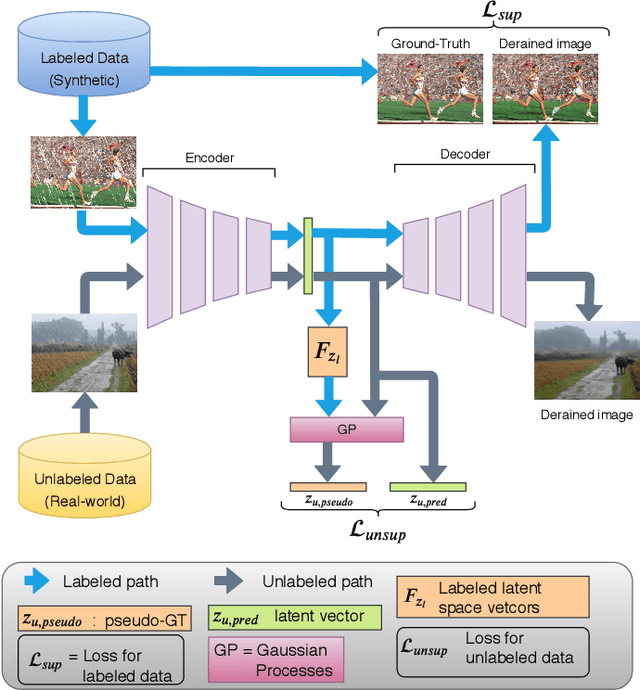
Recent CNN-based methods for image deraining have achieved excellent performance in terms of reconstruction error as well as visual quality. However, these methods are limited in the sense that they can be trained only on fully labeled data. Due to various challenges in obtaining real world fully-labeled image deraining datasets, existing methods are trained only on synthetically generated data and hence, generalize poorly to real-world images. The use of real-world data in training image deraining networks is relatively less explored in the literature. We propose a Gaussian Process-based semi-supervised learning framework which enables the network in learning to derain using synthetic dataset while generalizing better using unlabeled real-world images. More specifically, we model the latent space vectors of unlabeled data using Gaussian Processes, which is then used to compute pseudo-ground-truth for supervising the network on unlabeled data. Through extensive experiments and ablations on several challenging datasets (such as Rain800, Rain200L and DDN-SIRR), we show that the proposed method is able to effectively leverage unlabeled data thereby resulting in significantly better performance as compared to labeled-only training. Additionally, we demonstrate that using unlabeled real-world images in the proposed GP-based framework results
MichiGAN: Multi-Input-Conditioned Hair Image Generation for Portrait Editing
Oct 30, 2020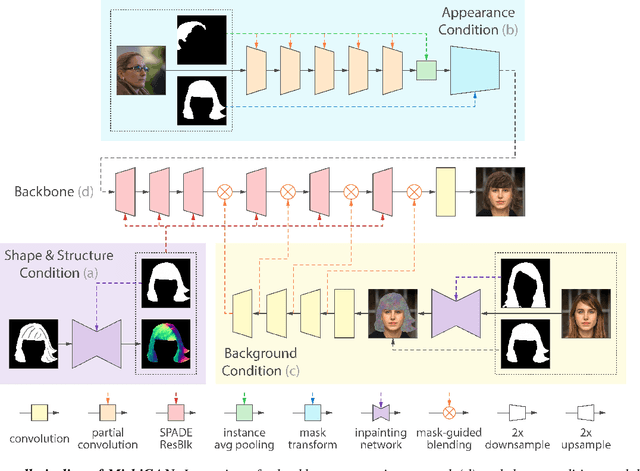
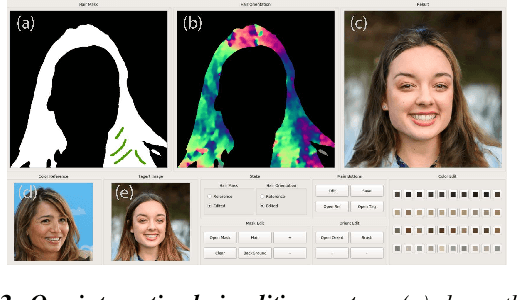
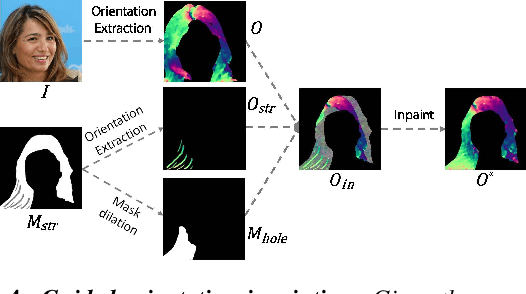

Despite the recent success of face image generation with GANs, conditional hair editing remains challenging due to the under-explored complexity of its geometry and appearance. In this paper, we present MichiGAN (Multi-Input-Conditioned Hair Image GAN), a novel conditional image generation method for interactive portrait hair manipulation. To provide user control over every major hair visual factor, we explicitly disentangle hair into four orthogonal attributes, including shape, structure, appearance, and background. For each of them, we design a corresponding condition module to represent, process, and convert user inputs, and modulate the image generation pipeline in ways that respect the natures of different visual attributes. All these condition modules are integrated with the backbone generator to form the final end-to-end network, which allows fully-conditioned hair generation from multiple user inputs. Upon it, we also build an interactive portrait hair editing system that enables straightforward manipulation of hair by projecting intuitive and high-level user inputs such as painted masks, guiding strokes, or reference photos to well-defined condition representations. Through extensive experiments and evaluations, we demonstrate the superiority of our method regarding both result quality and user controllability. The code is available at https://github.com/tzt101/MichiGAN.
StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation
Dec 03, 2020
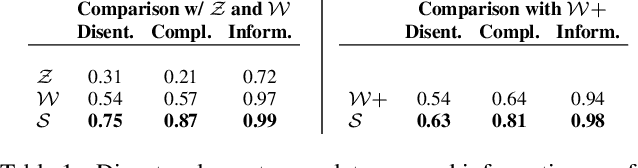
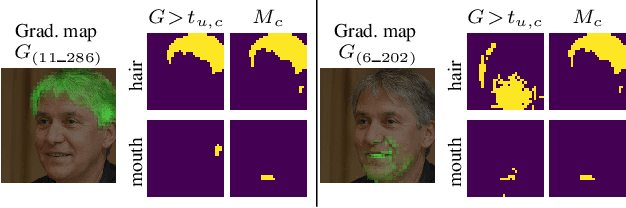
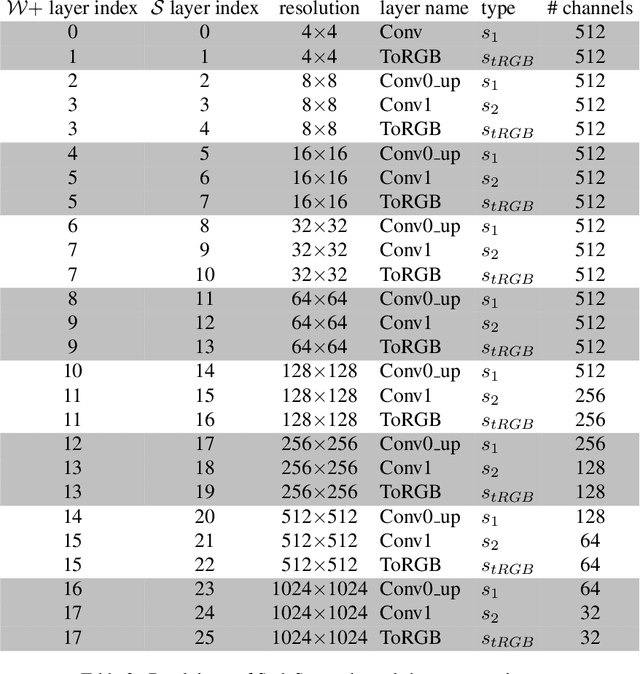
We explore and analyze the latent style space of StyleGAN2, a state-of-the-art architecture for image generation, using models pretrained on several different datasets. We first show that StyleSpace, the space of channel-wise style parameters, is significantly more disentangled than the other intermediate latent spaces explored by previous works. Next, we describe a method for discovering a large collection of style channels, each of which is shown to control a distinct visual attribute in a highly localized and disentangled manner. Third, we propose a simple method for identifying style channels that control a specific attribute, using a pretrained classifier or a small number of example images. Manipulation of visual attributes via these StyleSpace controls is shown to be better disentangled than via those proposed in previous works. To show this, we make use of a newly proposed Attribute Dependency metric. Finally, we demonstrate the applicability of StyleSpace controls to the manipulation of real images. Our findings pave the way to semantically meaningful and well-disentangled image manipulations via simple and intuitive interfaces.
A Deep Learning Approach for the Detection of COVID-19 from Chest X-Ray Images using Convolutional Neural Networks
Jan 24, 2022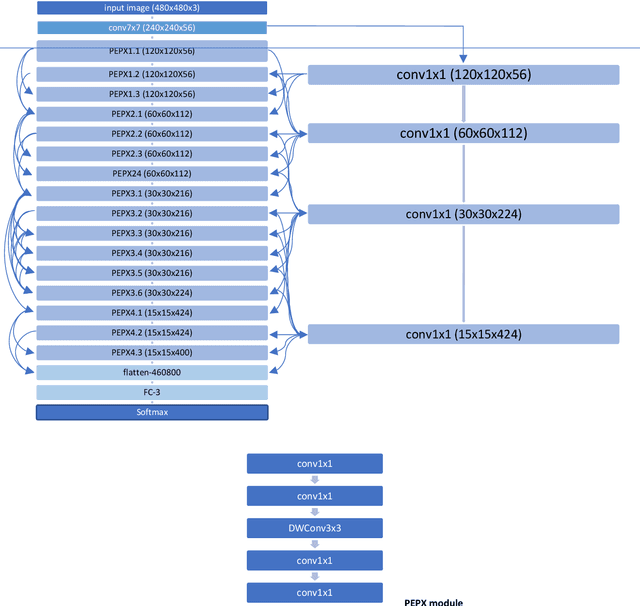
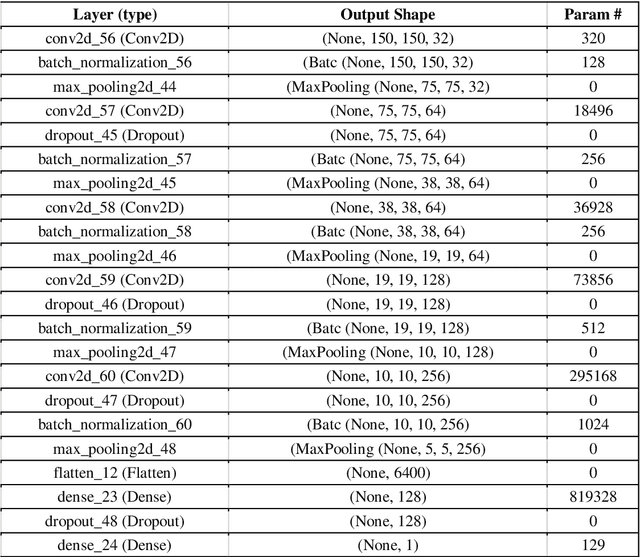
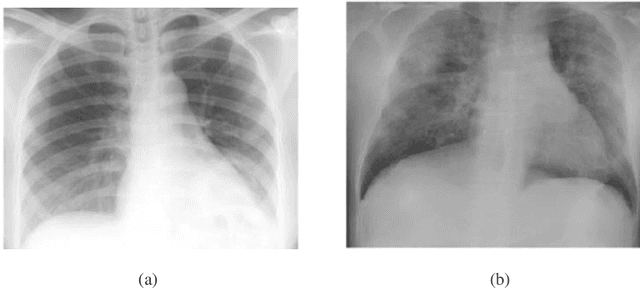
The COVID-19 (coronavirus) is an ongoing pandemic caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). The virus was first identified in mid-December 2019 in the Hubei province of Wuhan, China and by now has spread throughout the planet with more than 75.5 million confirmed cases and more than 1.67 million deaths. With limited number of COVID-19 test kits available in medical facilities, it is important to develop and implement an automatic detection system as an alternative diagnosis option for COVID-19 detection that can used on a commercial scale. Chest X-ray is the first imaging technique that plays an important role in the diagnosis of COVID-19 disease. Computer vision and deep learning techniques can help in determining COVID-19 virus with Chest X-ray Images. Due to the high availability of large-scale annotated image datasets, great success has been achieved using convolutional neural network for image analysis and classification. In this research, we have proposed a deep convolutional neural network trained on five open access datasets with binary output: Normal and Covid. The performance of the model is compared with four pre-trained convolutional neural network-based models (COVID-Net, ResNet18, ResNet and MobileNet-V2) and it has been seen that the proposed model provides better accuracy on the validation set as compared to the other four pre-trained models. This research work provides promising results which can be further improvise and implement on a commercial scale.
Spatio-temporal Vision Transformer for Super-resolution Microscopy
Feb 28, 2022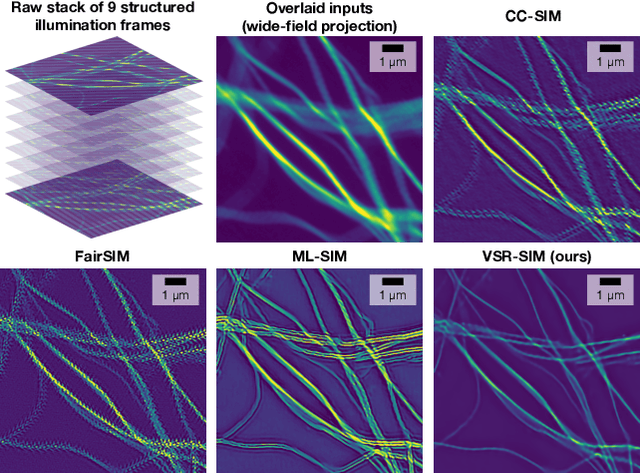
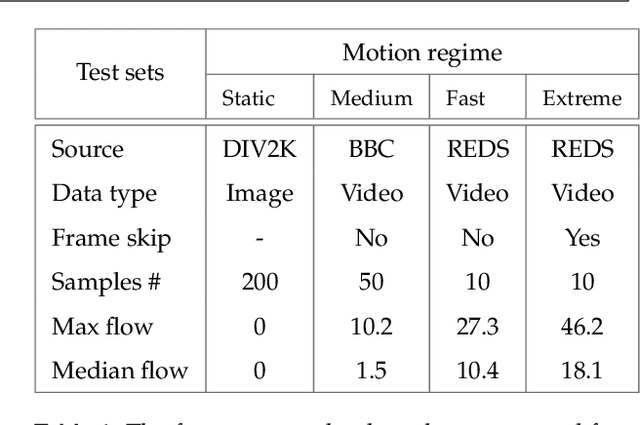
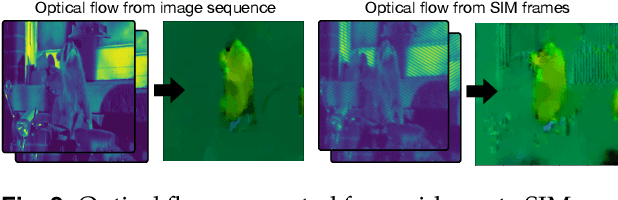
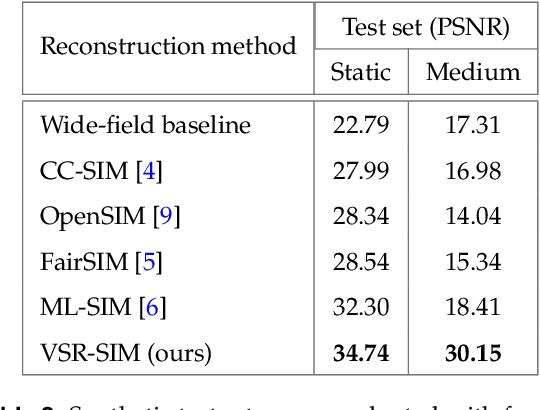
Structured illumination microscopy (SIM) is an optical super-resolution technique that enables live-cell imaging beyond the diffraction limit. Reconstruction of SIM data is prone to artefacts, which becomes problematic when imaging highly dynamic samples because previous methods rely on the assumption that samples are static. We propose a new transformer-based reconstruction method, VSR-SIM, that uses shifted 3-dimensional window multi-head attention in addition to channel attention mechanism to tackle the problem of video super-resolution (VSR) in SIM. The attention mechanisms are found to capture motion in sequences without the need for common motion estimation techniques such as optical flow. We take an approach to training the network that relies solely on simulated data using videos of natural scenery with a model for SIM image formation. We demonstrate a use case enabled by VSR-SIM referred to as rolling SIM imaging, which increases temporal resolution in SIM by a factor of 9. Our method can be applied to any SIM setup enabling precise recordings of dynamic processes in biomedical research with high temporal resolution.
Answer Questions with Right Image Regions: A Visual Attention Regularization Approach
Feb 03, 2021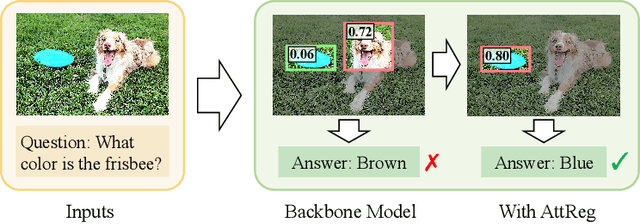
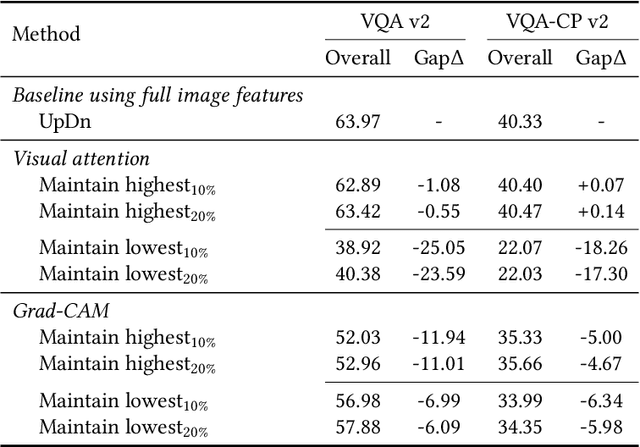
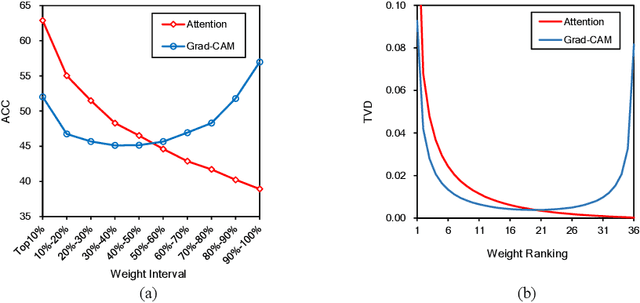
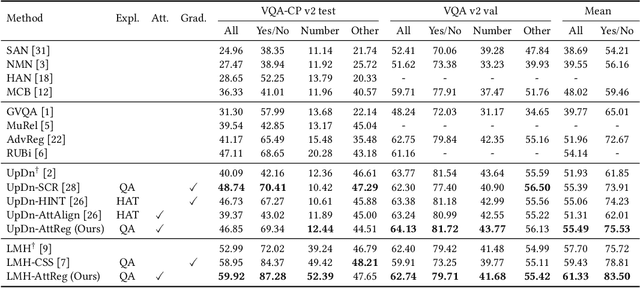
Visual attention in Visual Question Answering (VQA) targets at locating the right image regions regarding the answer prediction. However, recent studies have pointed out that the highlighted image regions from the visual attention are often irrelevant to the given question and answer, leading to model confusion for correct visual reasoning. To tackle this problem, existing methods mostly resort to aligning the visual attention weights with human attentions. Nevertheless, gathering such human data is laborious and expensive, making it burdensome to adapt well-developed models across datasets. To address this issue, in this paper, we devise a novel visual attention regularization approach, namely AttReg, for better visual grounding in VQA. Specifically, AttReg firstly identifies the image regions which are essential for question answering yet unexpectedly ignored (i.e., assigned with low attention weights) by the backbone model. And then a mask-guided learning scheme is leveraged to regularize the visual attention to focus more on these ignored key regions. The proposed method is very flexible and model-agnostic, which can be integrated into most visual attention-based VQA models and require no human attention supervision. Extensive experiments over three benchmark datasets, i.e., VQA-CP v2, VQA-CP v1, and VQA v2, have been conducted to evaluate the effectiveness of AttReg. As a by-product, when incorporating AttReg into the strong baseline LMH, our approach can achieve a new state-of-the-art accuracy of 59.92% with an absolute performance gain of 6.93% on the VQA-CP v2 benchmark dataset. In addition to the effectiveness validation, we recognize that the faithfulness of the visual attention in VQA has not been well explored in literature. In the light of this, we propose to empirically validate such property of visual attention and compare it with the prevalent gradient-based approaches.
Enhanced Transfer Learning Through Medical Imaging and Patient Demographic Data Fusion
Nov 29, 2021
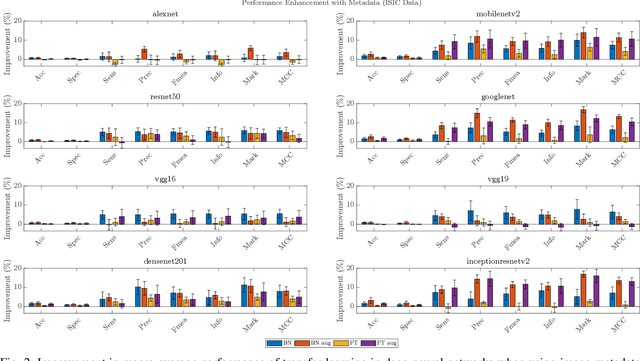
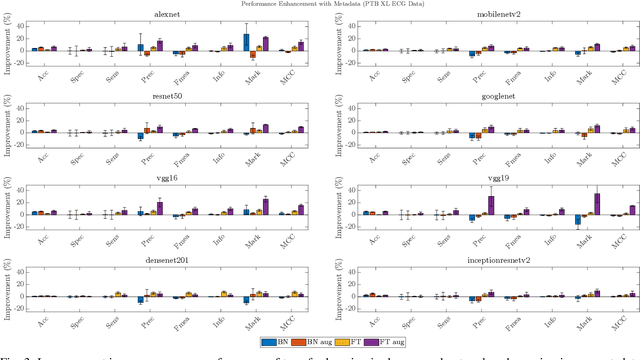
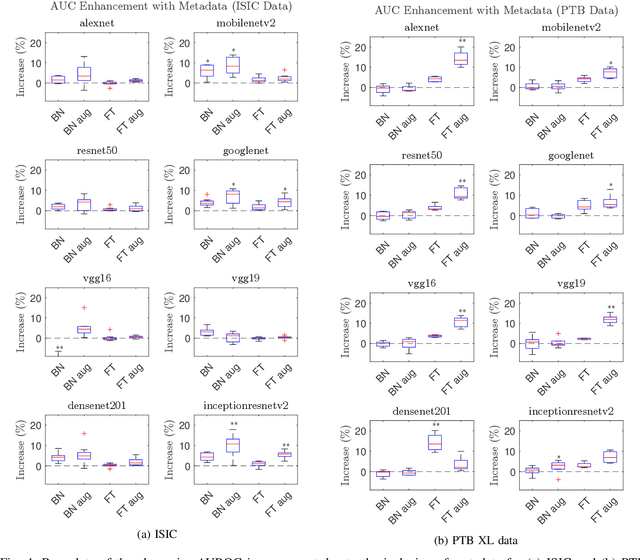
In this work we examine the performance enhancement in classification of medical imaging data when image features are combined with associated non-image data. We compare the performance of eight state-of-the-art deep neural networks in classification tasks when using only image features, compared to when these are combined with patient metadata. We utilise transfer learning with networks pretrained on ImageNet used directly as feature extractors and fine tuned on the target domain. Our experiments show that performance can be significantly enhanced with the inclusion of metadata and use interpretability methods to identify which features lead to these enhancements. Furthermore, our results indicate that the performance enhancement for natural medical imaging (e.g. optical images) benefit most from direct use of pre-trained models, whereas non natural images (e.g. representations of non imaging data) benefit most from fine tuning pre-trained networks. These enhancements come at a negligible additional cost in computation time, and therefore is a practical method for other applications.