 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spatial-Spectral Clustering with Anchor Graph for Hyperspectral Image
Apr 24, 2021
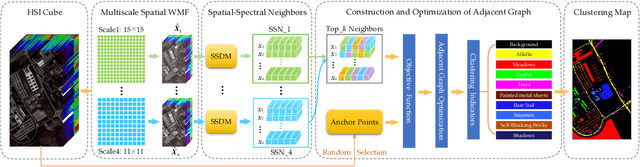
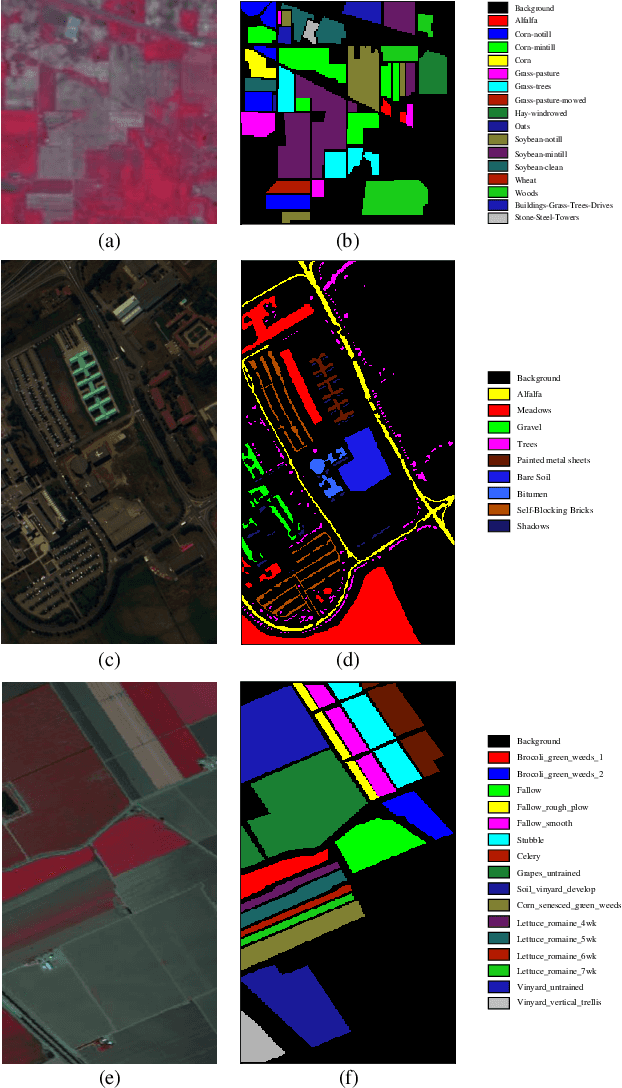
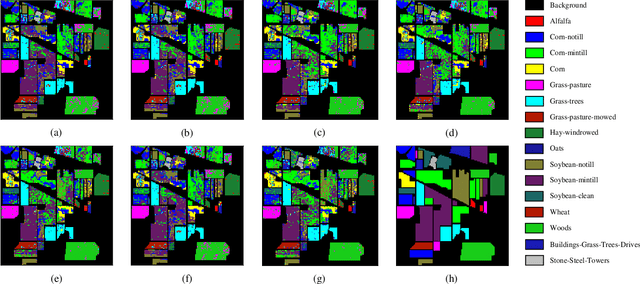
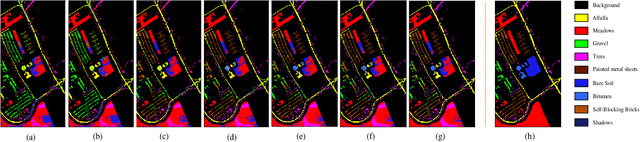
Hyperspectral image (HSI) clustering, which aims at dividing hyperspectral pixels into clusters, has drawn significant attention in practical applications. Recently, many graph-based clustering methods, which construct an adjacent graph to model the data relationship, have shown dominant performance. However, the high dimensionality of HSI data makes it hard to construct the pairwise adjacent graph. Besides, abundant spatial structures are often overlooked during the clustering procedure. In order to better handle the high dimensionality problem and preserve the spatial structures, this paper proposes a novel unsupervised approach called spatial-spectral clustering with anchor graph (SSCAG) for HSI data clustering. The SSCAG has the following contributions: 1) the anchor graph-based strategy is used to construct a tractable large graph for HSI data, which effectively exploits all data points and reduces the computational complexity; 2) a new similarity metric is presented to embed the spatial-spectral information into the combined adjacent graph, which can mine the intrinsic property structure of HSI data; 3) an effective neighbors assignment strategy is adopted in the optimization, which performs the singular value decomposition (SVD) on the adjacent graph to get solutions efficiently. Extensive experiments on three public HSI datasets show that the proposed SSCAG is competitive against the state-of-the-art approaches.
GCNDepth: Self-supervised Monocular Depth Estimation based on Graph Convolutional Network
Dec 13, 2021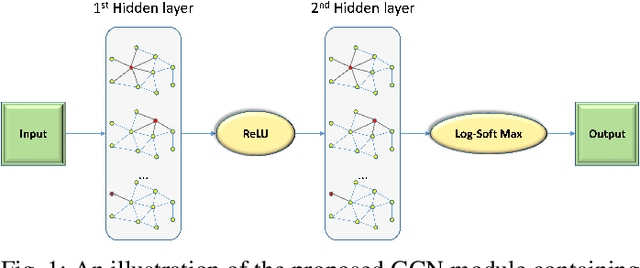
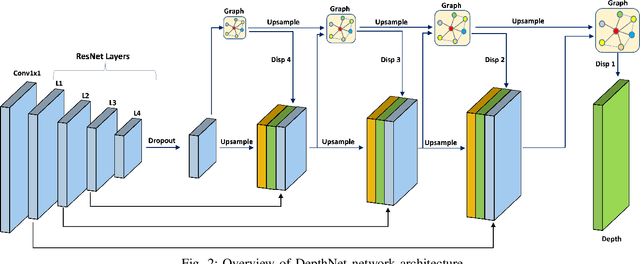

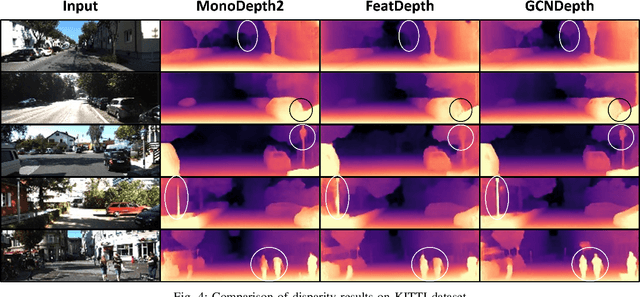
Depth estimation is a challenging task of 3D reconstruction to enhance the accuracy sensing of environment awareness. This work brings a new solution with a set of improvements, which increase the quantitative and qualitative understanding of depth maps compared to existing methods. Recently, a convolutional neural network (CNN) has demonstrated its extraordinary ability in estimating depth maps from monocular videos. However, traditional CNN does not support topological structure and they can work only on regular image regions with determined size and weights. On the other hand, graph convolutional networks (GCN) can handle the convolution on non-Euclidean data and it can be applied to irregular image regions within a topological structure. Therefore, in this work in order to preserve object geometric appearances and distributions, we aim at exploiting GCN for a self-supervised depth estimation model. Our model consists of two parallel auto-encoder networks: the first is an auto-encoder that will depend on ResNet-50 and extract the feature from the input image and on multi-scale GCN to estimate the depth map. In turn, the second network will be used to estimate the ego-motion vector (i.e., 3D pose) between two consecutive frames based on ResNet-18. Both the estimated 3D pose and depth map will be used for constructing a target image. A combination of loss functions related to photometric, projection, and smoothness is used to cope with bad depth prediction and preserve the discontinuities of the objects. In particular, our method provided comparable and promising results with a high prediction accuracy of 89% on the publicly KITTI and Make3D datasets along with a reduction of 40% in the number of trainable parameters compared to the state of the art solutions. The source code is publicly available at https://github.com/ArminMasoumian/GCNDepth.git
Fully Automatic Page Turning on Real Scores
Nov 12, 2021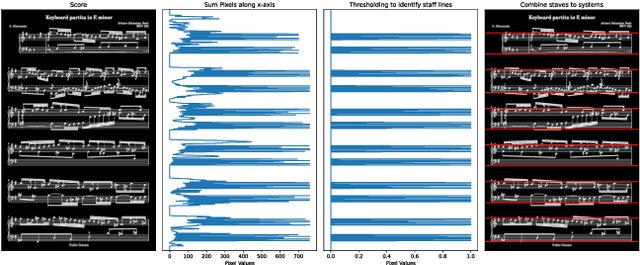

We present a prototype of an automatic page turning system that works directly on real scores, i.e., sheet images, without any symbolic representation. Our system is based on a multi-modal neural network architecture that observes a complete sheet image page as input, listens to an incoming musical performance, and predicts the corresponding position in the image. Using the position estimation of our system, we use a simple heuristic to trigger a page turning event once a certain location within the sheet image is reached. As a proof of concept we further combine our system with an actual machine that will physically turn the page on command.
Deblurring via Stochastic Refinement
Dec 05, 2021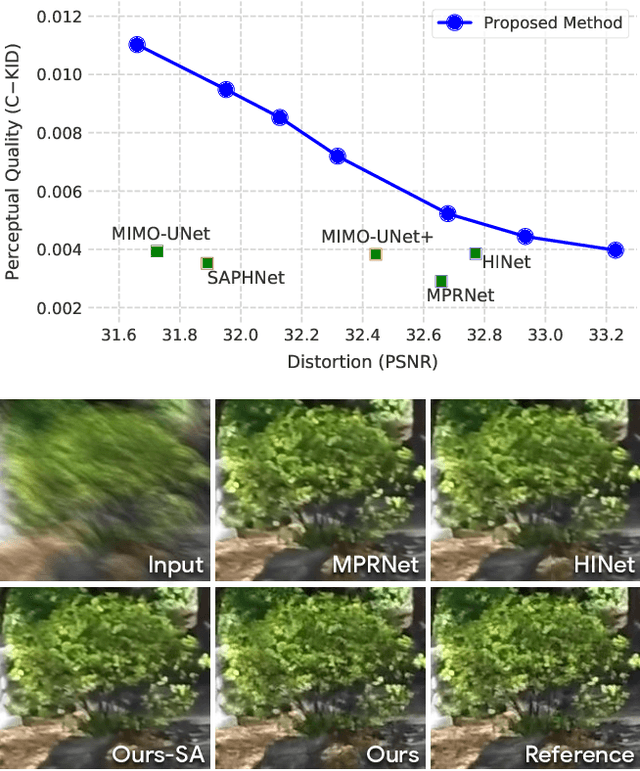
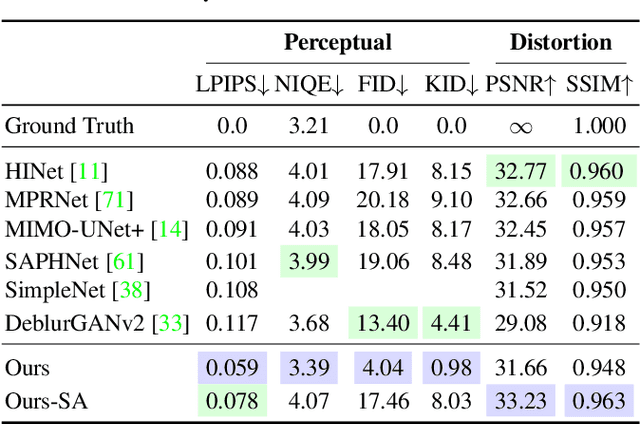
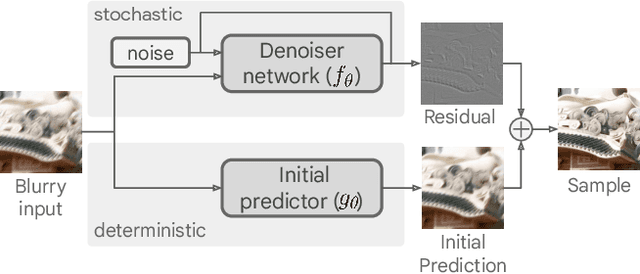

Image deblurring is an ill-posed problem with multiple plausible solutions for a given input image. However, most existing methods produce a deterministic estimate of the clean image and are trained to minimize pixel-level distortion. These metrics are known to be poorly correlated with human perception, and often lead to unrealistic reconstructions. We present an alternative framework for blind deblurring based on conditional diffusion models. Unlike existing techniques, we train a stochastic sampler that refines the output of a deterministic predictor and is capable of producing a diverse set of plausible reconstructions for a given input. This leads to a significant improvement in perceptual quality over existing state-of-the-art methods across multiple standard benchmarks. Our predict-and-refine approach also enables much more efficient sampling compared to typical diffusion models. Combined with a carefully tuned network architecture and inference procedure, our method is competitive in terms of distortion metrics such as PSNR. These results show clear benefits of our diffusion-based method for deblurring and challenge the widely used strategy of producing a single, deterministic reconstruction.
A Deep Learning Approach for the Detection of COVID-19 from Chest X-Ray Images using Convolutional Neural Networks
Jan 24, 2022
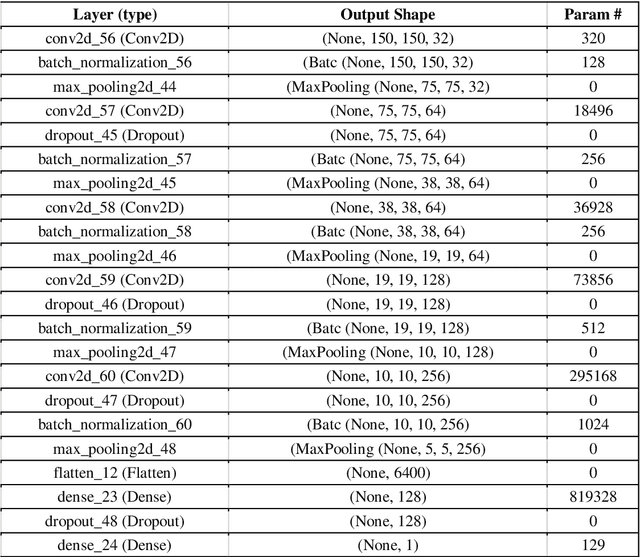
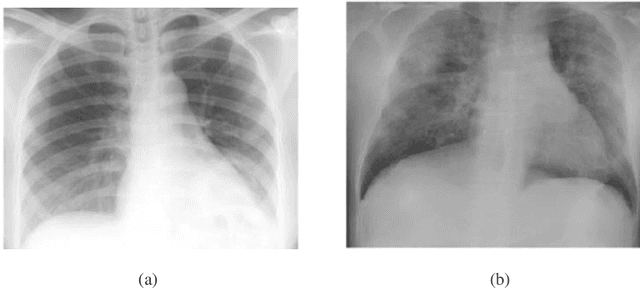
The COVID-19 (coronavirus) is an ongoing pandemic caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). The virus was first identified in mid-December 2019 in the Hubei province of Wuhan, China and by now has spread throughout the planet with more than 75.5 million confirmed cases and more than 1.67 million deaths. With limited number of COVID-19 test kits available in medical facilities, it is important to develop and implement an automatic detection system as an alternative diagnosis option for COVID-19 detection that can used on a commercial scale. Chest X-ray is the first imaging technique that plays an important role in the diagnosis of COVID-19 disease. Computer vision and deep learning techniques can help in determining COVID-19 virus with Chest X-ray Images. Due to the high availability of large-scale annotated image datasets, great success has been achieved using convolutional neural network for image analysis and classification. In this research, we have proposed a deep convolutional neural network trained on five open access datasets with binary output: Normal and Covid. The performance of the model is compared with four pre-trained convolutional neural network-based models (COVID-Net, ResNet18, ResNet and MobileNet-V2) and it has been seen that the proposed model provides better accuracy on the validation set as compared to the other four pre-trained models. This research work provides promising results which can be further improvise and implement on a commercial scale.
CoLLIE: Continual Learning of Language Grounding from Language-Image Embeddings
Nov 15, 2021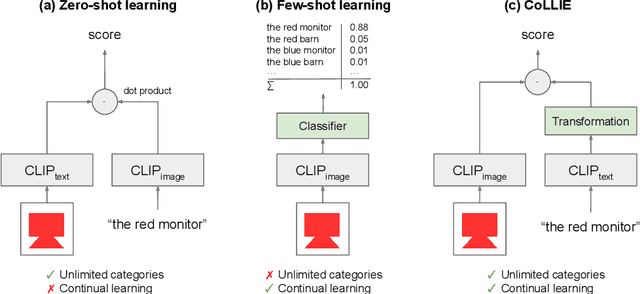
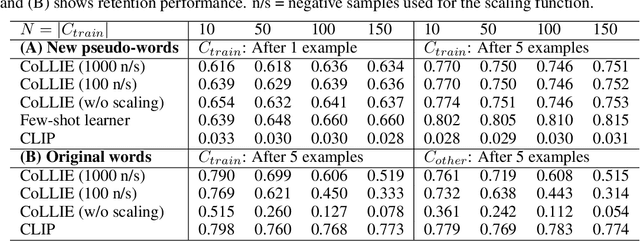
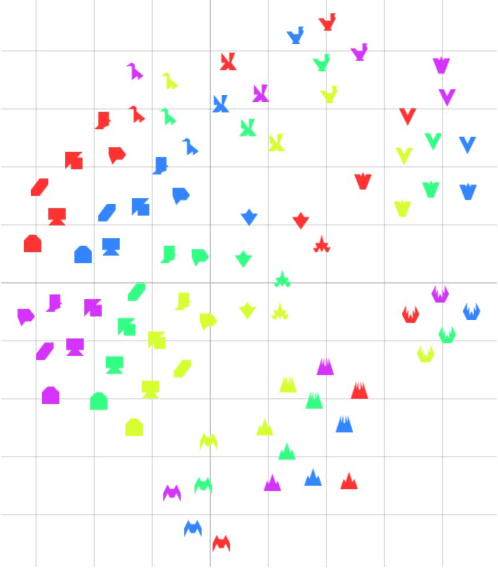
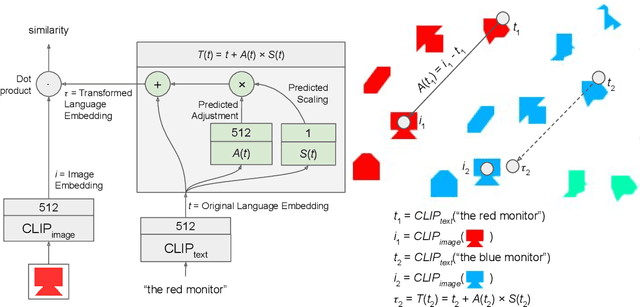
This paper presents CoLLIE: a simple, yet effective model for continual learning of how language is grounded in vision. Given a pre-trained multimodal embedding model, where language and images are projected in the same semantic space (in this case CLIP by OpenAI), CoLLIE learns a transformation function that adjusts the language embeddings when needed to accommodate new language use. Unlike traditional few-shot learning, the model does not just learn new classes and labels, but can also generalize to similar language use. We verify the model's performance on two different tasks of continual learning and show that it can efficiently learn and generalize from only a few examples, with little interference with the model's original zero-shot performance.
Comprehensive evaluation of no-reference image quality assessment algorithms on KADID-10k database
Nov 09, 2020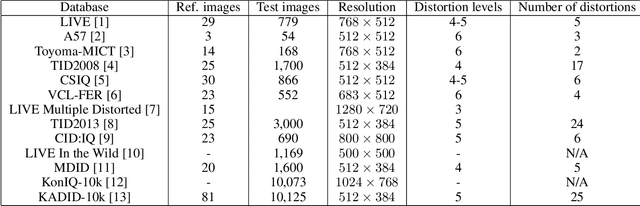
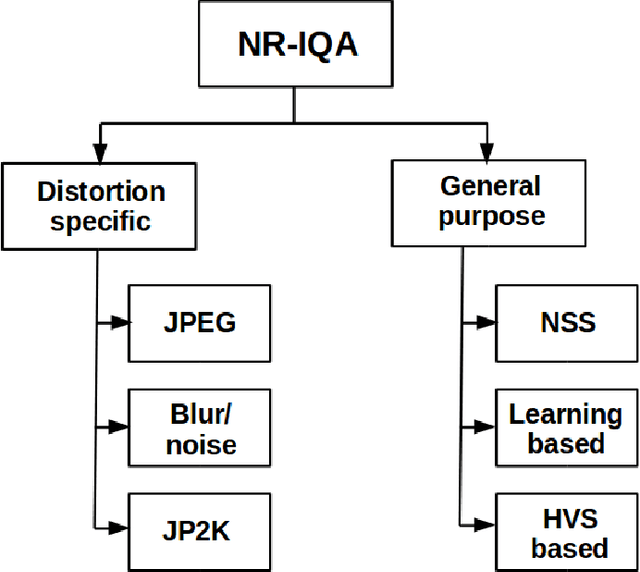

The main goal of objective image quality assessment is to devise computational, mathematical models which are able to predict perceptual image quality consistently with subjective evaluations. The evaluation of objective image quality assessment algorithms is based on experiments conducted on publicly available benchmark databases. In this study, our goal is to give a comprehensive evaluation about no-reference image quality assessment algorithms, whose original source codes are available online, using the recently published KADID-10k database which is one of the largest available benchmark databases. Specifically, average PLCC, SROCC, and KROCC are reported which were measured over 100 random train-test splits. Furthermore, the database was divided into a train (appx. 80\% of images) and a test set (appx. 20% of images) with respect to the reference images. So no semantic content overlap was between these two sets. Our evaluation results may be helpful to obtain a clear understanding about the status of state-of-the-art no-reference image quality assessment methods.
Light Field Image Coding Using VVC standard and View Synthesis based on Dual Discriminator GAN
Mar 06, 2021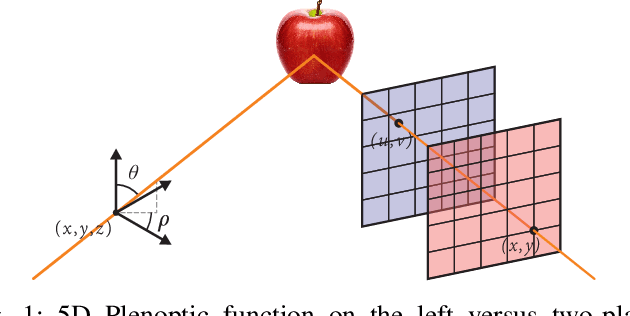
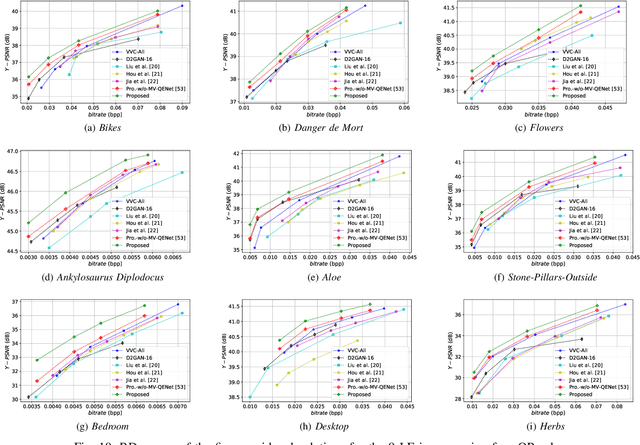
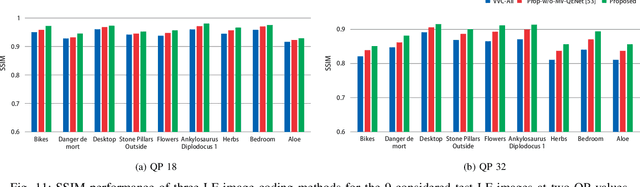

Light field (LF) technology is considered as a promising way for providing a high-quality virtual reality (VR) content. However, such an imaging technology produces a large amount of data requiring efficient LF image compression solutions. In this paper, we propose a LF image coding method based on a view synthesis and view quality enhancement techniques. Instead of transmitting all the LF views, only a sparse set of reference views are encoded and transmitted, while the remaining views are synthesized at the decoder side. The transmitted views are encoded using the versatile video coding (VVC) standard and are used as reference views to synthesize the dropped views. The selection of non-reference dropped views is performed using a rate-distortion optimization based on the VVC temporal scalability. The dropped views are reconstructed using the LF dual discriminator GAN (LF-D2GAN) model. In addition, to ensure that the quality of the views is consistent, at the decoder, a quality enhancement procedure is performed on the reconstructed views allowing smooth navigation across views. Experimental results show that the proposed method provides high coding performance and overcomes the state-of-the-art LF image compression methods by -36.22% in terms of BD-BR and 1.35 dB in BD-PSNR. The web page of this work is available at https://naderbakir79.github.io/LFD2GAN.html.
Rib Suppression in Digital Chest Tomosynthesis
Mar 05, 2022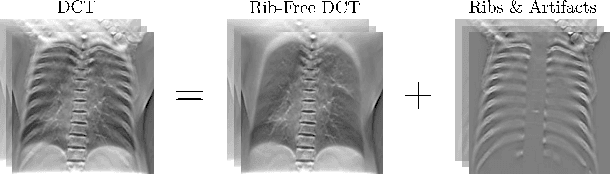
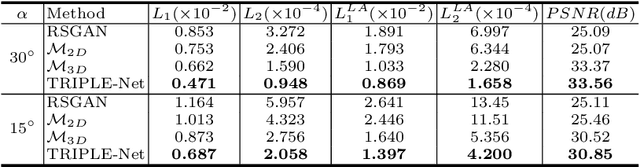
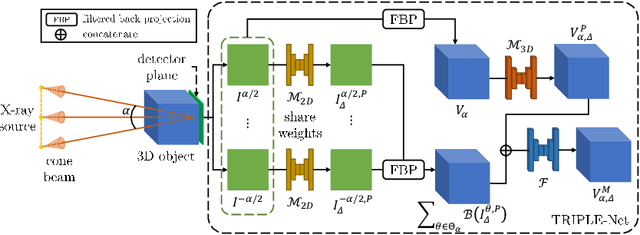
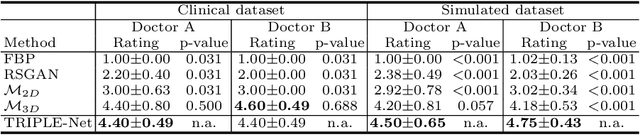
Digital chest tomosynthesis (DCT) is a technique to produce sectional 3D images of a human chest for pulmonary disease screening, with 2D X-ray projections taken within an extremely limited range of angles. However, under the limited angle scenario, DCT contains strong artifacts caused by the presence of ribs, jamming the imaging quality of the lung area. Recently, great progress has been achieved for rib suppression in a single X-ray image, to reveal a clearer lung texture. We firstly extend the rib suppression problem to the 3D case at the software level. We propose a $\textbf{T}$omosynthesis $\textbf{RI}$b Su$\textbf{P}$pression and $\textbf{L}$ung $\textbf{E}$nhancement $\textbf{Net}$work (TRIPLE-Net) to model the 3D rib component and provide a rib-free DCT. TRIPLE-Net takes the advantages from both 2D and 3D domains, which model the ribs in DCT with the exact FBP procedure and 3D depth information, respectively. The experiments on simulated datasets and clinical data have shown the effectiveness of TRIPLE-Net to preserve lung details as well as improve the imaging quality of pulmonary diseases. Finally, an expert user study confirms our findings.
PIINET: A 360-degree Panoramic Image Inpainting Network Using a Cube Map
Oct 30, 2020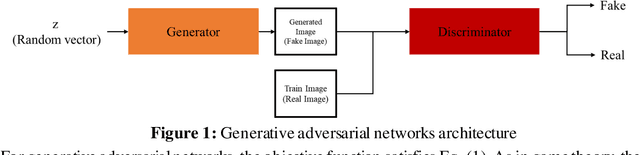

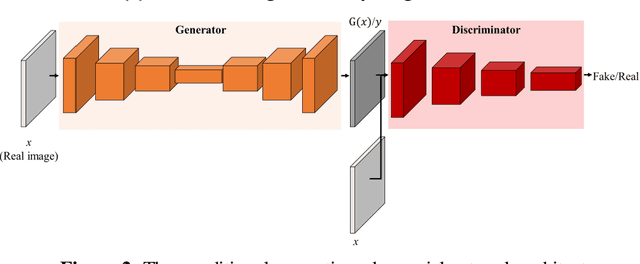

Inpainting has been continuously studied in the field of computer vision. As artificial intelligence technology developed, deep learning technology was introduced in inpainting research, helping to improve performance. Currently, the input target of an inpainting algorithm using deep learning has been studied from a single image to a video. However, deep learning-based inpainting technology for panoramic images has not been actively studied. We propose a 360-degree panoramic image inpainting method using generative adversarial networks (GANs). The proposed network inputs a 360-degree equirectangular format panoramic image converts it into a cube map format, which has relatively little distortion and uses it as a training network. Since the cube map format is used, the correlation of the six sides of the cube map should be considered. Therefore, all faces of the cube map are used as input for the whole discriminative network, and each face of the cube map is used as input for the slice discriminative network to determine the authenticity of the generated image. The proposed network performed qualitatively better than existing single-image inpainting algorithms and baseline algorithms.