 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CLIP meets GamePhysics: Towards bug identification in gameplay videos using zero-shot transfer learning
Mar 22, 2022

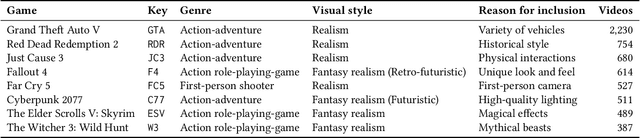

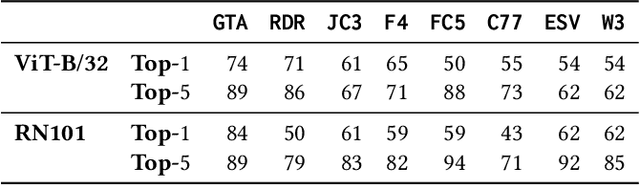
Gameplay videos contain rich information about how players interact with the game and how the game responds. Sharing gameplay videos on social media platforms, such as Reddit, has become a common practice for many players. Often, players will share gameplay videos that showcase video game bugs. Such gameplay videos are software artifacts that can be utilized for game testing, as they provide insight for bug analysis. Although large repositories of gameplay videos exist, parsing and mining them in an effective and structured fashion has still remained a big challenge. In this paper, we propose a search method that accepts any English text query as input to retrieve relevant videos from large repositories of gameplay videos. Our approach does not rely on any external information (such as video metadata); it works solely based on the content of the video. By leveraging the zero-shot transfer capabilities of the Contrastive Language-Image Pre-Training (CLIP) model, our approach does not require any data labeling or training. To evaluate our approach, we present the $\texttt{GamePhysics}$ dataset consisting of 26,954 videos from 1,873 games, that were collected from the GamePhysics section on the Reddit website. Our approach shows promising results in our extensive analysis of simple queries, compound queries, and bug queries, indicating that our approach is useful for object and event detection in gameplay videos. An example application of our approach is as a gameplay video search engine to aid in reproducing video game bugs. Please visit the following link for the code and the data: https://asgaardlab.github.io/CLIPxGamePhysics/
Panoptic-based Image Synthesis
Apr 21, 2020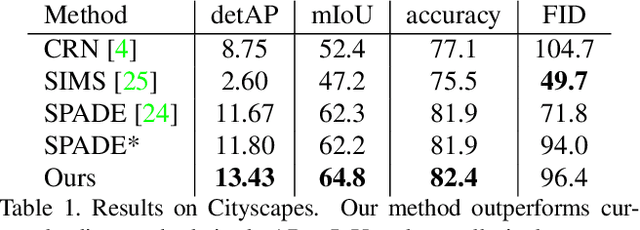
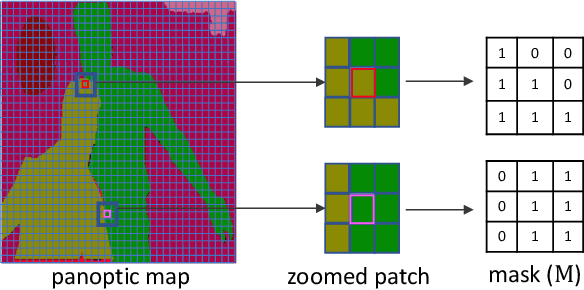
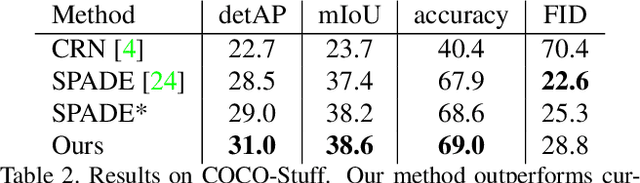
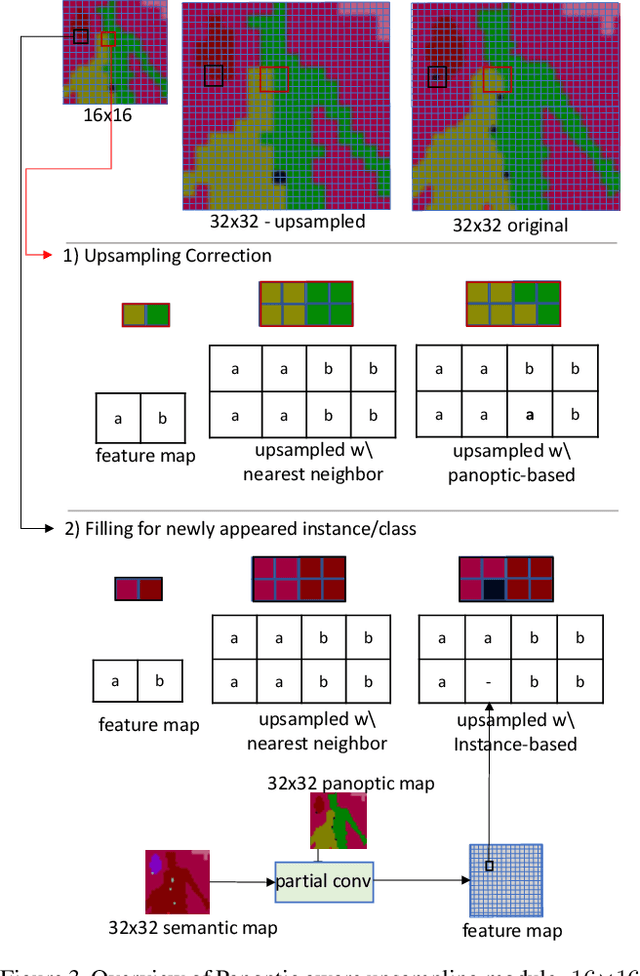
Conditional image synthesis for generating photorealistic images serves various applications for content editing to content generation. Previous conditional image synthesis algorithms mostly rely on semantic maps, and often fail in complex environments where multiple instances occlude each other. We propose a panoptic aware image synthesis network to generate high fidelity and photorealistic images conditioned on panoptic maps which unify semantic and instance information. To achieve this, we efficiently use panoptic maps in convolution and upsampling layers. We show that with the proposed changes to the generator, we can improve on the previous state-of-the-art methods by generating images in complex instance interaction environments in higher fidelity and tiny objects in more details. Furthermore, our proposed method also outperforms the previous state-of-the-art methods in metrics of mean IoU (Intersection over Union), and detAP (Detection Average Precision).
Conditional Prompt Learning for Vision-Language Models
Mar 10, 2022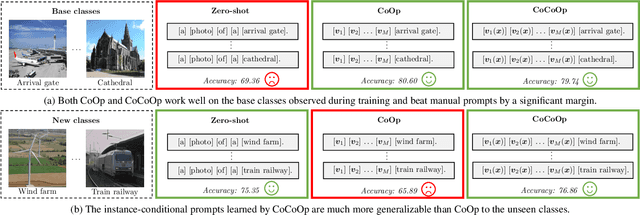
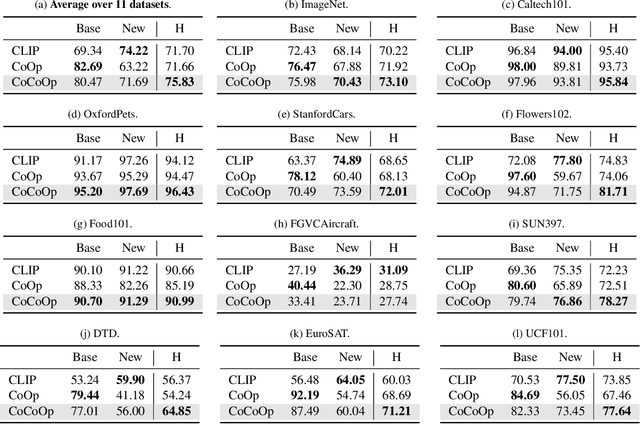
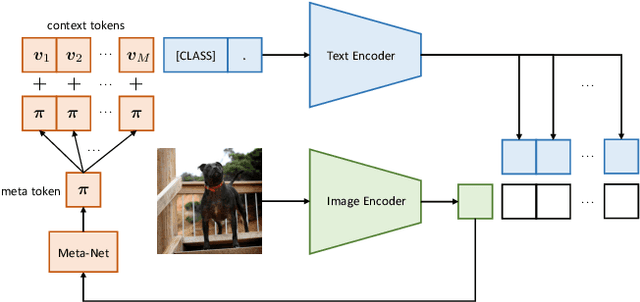
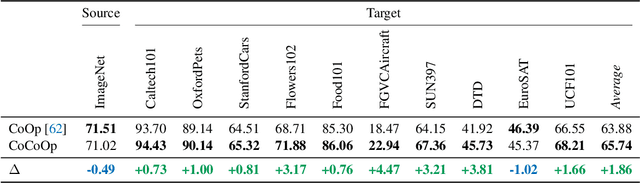
With the rise of powerful pre-trained vision-language models like CLIP, it becomes essential to investigate ways to adapt these models to downstream datasets. A recently proposed method named Context Optimization (CoOp) introduces the concept of prompt learning -- a recent trend in NLP -- to the vision domain for adapting pre-trained vision-language models. Specifically, CoOp turns context words in a prompt into a set of learnable vectors and, with only a few labeled images for learning, can achieve huge improvements over intensively-tuned manual prompts. In our study we identify a critical problem of CoOp: the learned context is not generalizable to wider unseen classes within the same dataset, suggesting that CoOp overfits base classes observed during training. To address the problem, we propose Conditional Context Optimization (CoCoOp), which extends CoOp by further learning a lightweight neural network to generate for each image an input-conditional token (vector). Compared to CoOp's static prompts, our dynamic prompts adapt to each instance and are thus less sensitive to class shift. Extensive experiments show that CoCoOp generalizes much better than CoOp to unseen classes, even showing promising transferability beyond a single dataset; and yields stronger domain generalization performance as well. Code is available at https://github.com/KaiyangZhou/CoOp.
BlazeNeo: Blazing fast polyp segmentation and neoplasm detection
Feb 28, 2022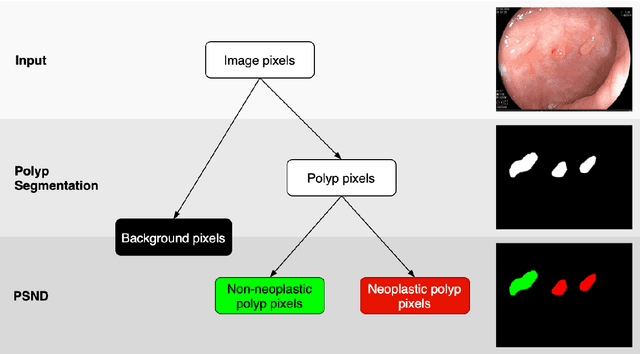

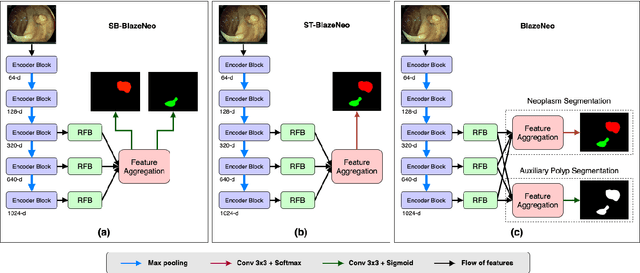
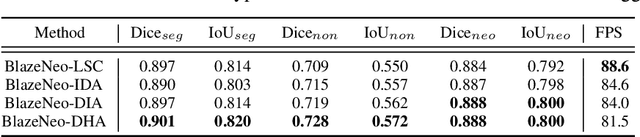
In recent years, computer-aided automatic polyp segmentation and neoplasm detection have been an emerging topic in medical image analysis, providing valuable support to colonoscopy procedures. Attentions have been paid to improving the accuracy of polyp detection and segmentation. However, not much focus has been given to latency and throughput for performing these tasks on dedicated devices, which can be crucial for practical applications. This paper introduces a novel deep neural network architecture called BlazeNeo, for the task of polyp segmentation and neoplasm detection with an emphasis on compactness and speed while maintaining high accuracy. The model leverages the highly efficient HarDNet backbone alongside lightweight Receptive Field Blocks for computational efficiency, and an auxiliary training mechanism to take full advantage of the training data for the segmentation quality. Our experiments on a challenging dataset show that BlazeNeo achieves improvements in latency and model size while maintaining comparable accuracy against state-of-the-art methods. When deploying on the Jetson AGX Xavier edge device in INT8 precision, our BlazeNeo achieves over 155 fps while yielding the best accuracy among all compared methods.
Deepfake Detection for Facial Images with Facemasks
Feb 23, 2022
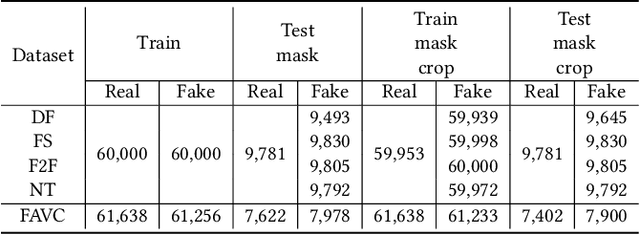
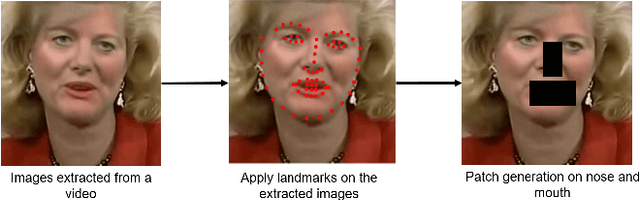
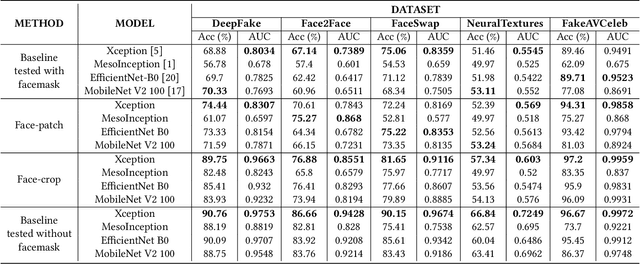
Hyper-realistic face image generation and manipulation have givenrise to numerous unethical social issues, e.g., invasion of privacy,threat of security, and malicious political maneuvering, which re-sulted in the development of recent deepfake detection methodswith the rising demands of deepfake forensics. Proposed deepfakedetection methods to date have shown remarkable detection perfor-mance and robustness. However, none of the suggested deepfakedetection methods assessed the performance of deepfakes withthe facemask during the pandemic crisis after the outbreak of theCovid-19. In this paper, we thoroughly evaluate the performance ofstate-of-the-art deepfake detection models on the deepfakes withthe facemask. Also, we propose two approaches to enhance themasked deepfakes detection:face-patchandface-crop. The experi-mental evaluations on both methods are assessed through the base-line deepfake detection models on the various deepfake datasets.Our extensive experiments show that, among the two methods,face-cropperforms better than theface-patch, and could be a trainmethod for deepfake detection models to detect fake faces withfacemask in real world.
Benchmarking and Comparing Multi-exposure Image Fusion Algorithms
Jul 30, 2020
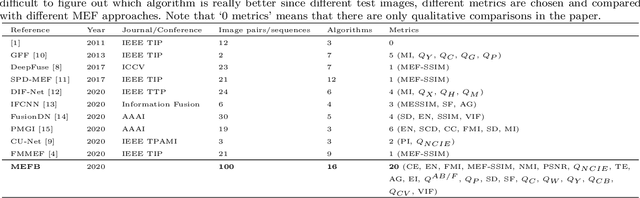

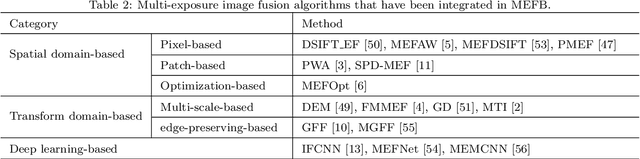
Multi-exposure image fusion (MEF) is an important area in computer vision and has attracted increasing interests in recent years. Apart from conventional algorithms, deep learning techniques have also been applied to multi-exposure image fusion. However, although much efforts have been made on developing MEF algorithms, the lack of benchmark makes it difficult to perform fair and comprehensive performance comparison among MEF algorithms, thus significantly hindering the development of this field. In this paper, we fill this gap by proposing a benchmark for multi-exposure image fusion (MEFB) which consists of a test set of 100 image pairs, a code library of 16 algorithms, 20 evaluation metrics, 1600 fused images and a software toolkit. To the best of our knowledge, this is the first benchmark in the field of multi-exposure image fusion. Extensive experiments have been conducted using MEFB for comprehensive performance evaluation and for identifying effective algorithms. We expect that MEFB will serve as an effective platform for researchers to compare performances and investigate MEF algorithms.
Efficient sign language recognition system and dataset creation method based on deep learning and image processing
Apr 01, 2021

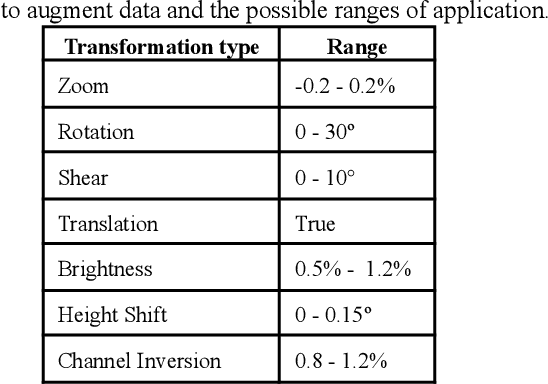
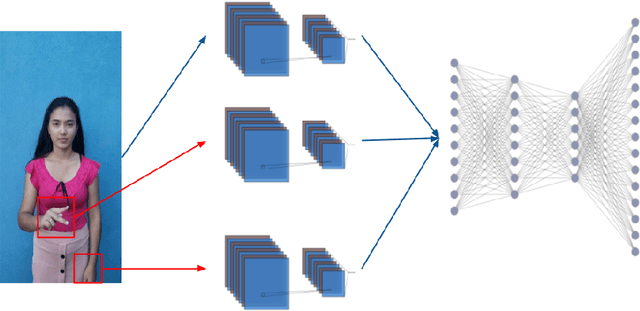
New deep-learning architectures are created every year, achieving state-of-the-art results in image recognition and leading to the belief that, in a few years, complex tasks such as sign language translation will be considerably easier, serving as a communication tool for the hearing-impaired community. On the other hand, these algorithms still need a lot of data to be trained and the dataset creation process is expensive, time-consuming, and slow. Thereby, this work aims to investigate techniques of digital image processing and machine learning that can be used to create a sign language dataset effectively. We argue about data acquisition, such as the frames per second rate to capture or subsample the videos, the background type, preprocessing, and data augmentation, using convolutional neural networks and object detection to create an image classifier and comparing the results based on statistical tests. Different datasets were created to test the hypotheses, containing 14 words used daily and recorded by different smartphones in the RGB color system. We achieved an accuracy of 96.38% on the test set and 81.36% on the validation set containing more challenging conditions, showing that 30 FPS is the best frame rate subsample to train the classifier, geometric transformations work better than intensity transformations, and artificial background creation is not effective to model generalization. These trade-offs should be considered in future work as a cost-benefit guideline between computational cost and accuracy gain when creating a dataset and training a sign recognition model.
Using Out-of-the-Box Frameworks for Unpaired Image Translation and Image Segmentation for the crossMoDA Challenge
Oct 02, 2021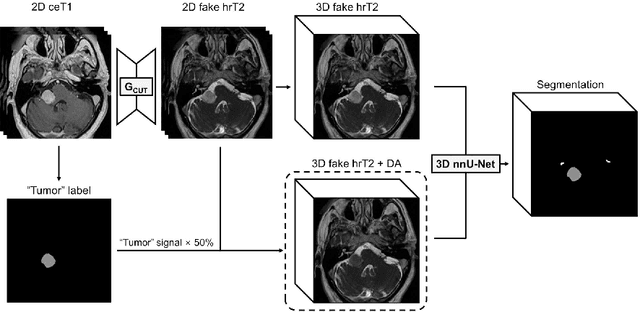
The purpose of this study is to apply and evaluate out-of-the-box deep learning frameworks for the crossMoDA challenge. We use the CUT model for domain adaptation from contrast-enhanced T1 MR to high-resolution T2 MR. As data augmentation, we generated additional images with vestibular schwannomas with lower signal intensity. For the segmentation task, we use the nnU-Net framework. Our final submission achieved a mean Dice score of 0.8299 (0.0465) in the validation phase.
Focal Modulation Networks
Mar 22, 2022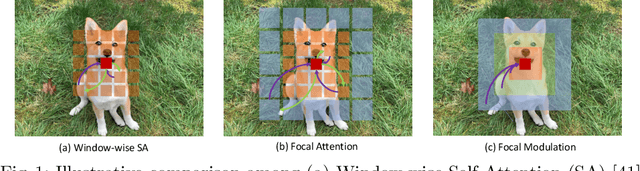
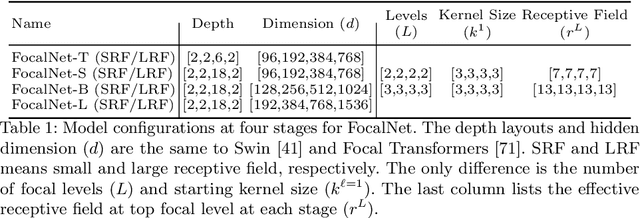
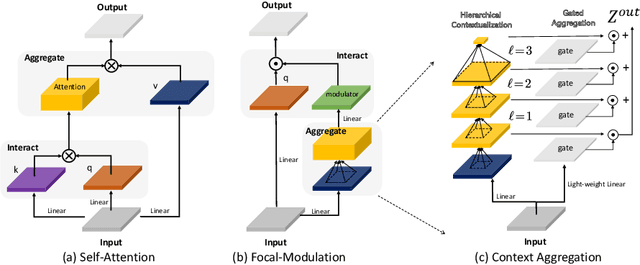
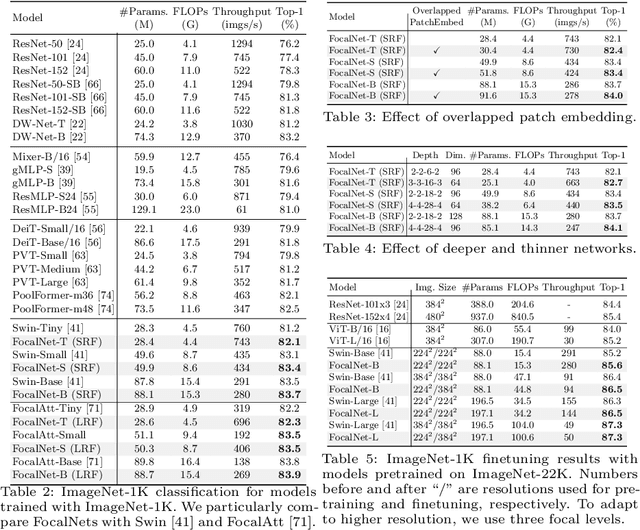
In this work, we propose focal modulation network (FocalNet in short), where self-attention (SA) is completely replaced by a focal modulation module that is more effective and efficient for modeling token interactions. Focal modulation comprises three components: $(i)$ hierarchical contextualization, implemented using a stack of depth-wise convolutional layers, to encode visual contexts from short to long ranges at different granularity levels, $(ii)$ gated aggregation to selectively aggregate context features for each visual token (query) based on its content, and $(iii)$ modulation or element-wise affine transformation to fuse the aggregated features into the query vector. Extensive experiments show that FocalNets outperform the state-of-the-art SA counterparts (e.g., Swin Transformers) with similar time and memory cost on the tasks of image classification, object detection, and semantic segmentation. Specifically, our FocalNets with tiny and base sizes achieve 82.3% and 83.9% top-1 accuracy on ImageNet-1K. After pretrained on ImageNet-22K, it attains 86.5% and 87.3% top-1 accuracy when finetuned with resolution 224$\times$224 and 384$\times$384, respectively. FocalNets exhibit remarkable superiority when transferred to downstream tasks. For object detection with Mask R-CNN, our FocalNet base trained with 1$\times$ already surpasses Swin trained with 3$\times$ schedule (49.0 v.s. 48.5). For semantic segmentation with UperNet, FocalNet base evaluated at single-scale outperforms Swin evaluated at multi-scale (50.5 v.s. 49.7). These results render focal modulation a favorable alternative to SA for effective and efficient visual modeling in real-world applications. Code is available at https://github.com/microsoft/FocalNet.
Spatial-Spectral Clustering with Anchor Graph for Hyperspectral Image
Apr 24, 2021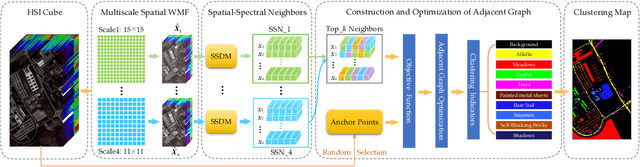
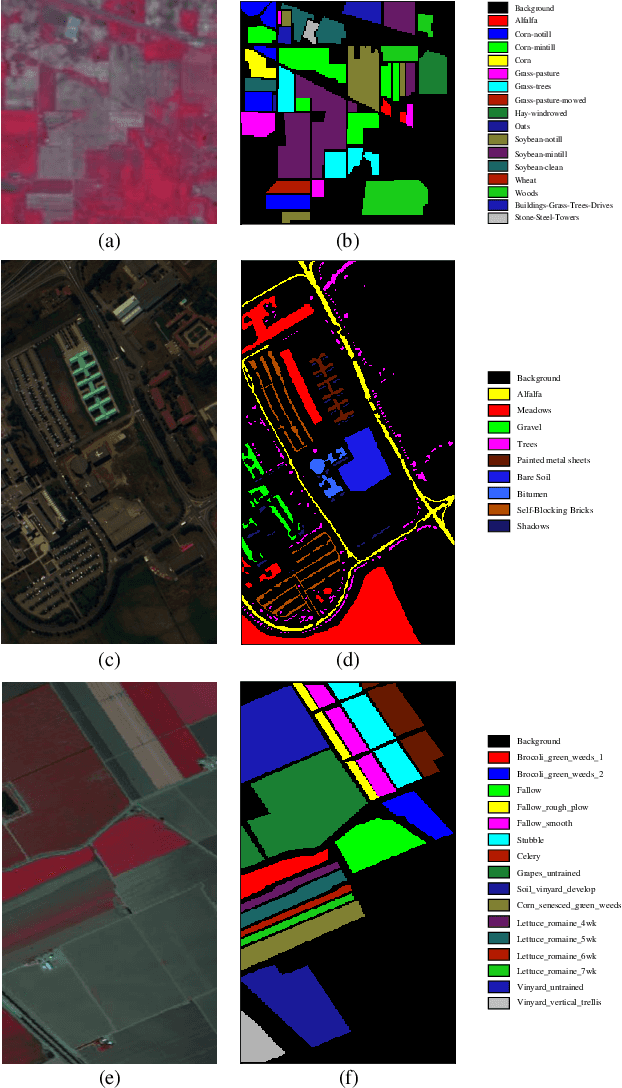
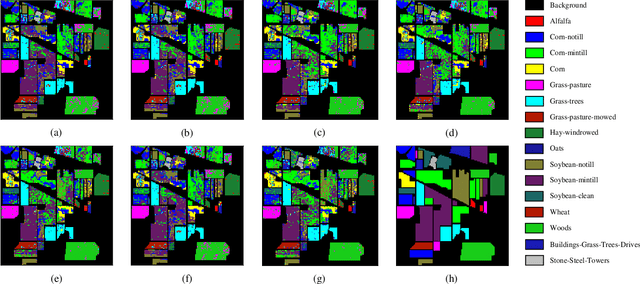
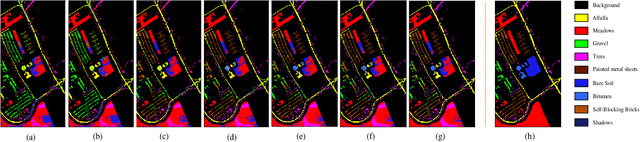
Hyperspectral image (HSI) clustering, which aims at dividing hyperspectral pixels into clusters, has drawn significant attention in practical applications. Recently, many graph-based clustering methods, which construct an adjacent graph to model the data relationship, have shown dominant performance. However, the high dimensionality of HSI data makes it hard to construct the pairwise adjacent graph. Besides, abundant spatial structures are often overlooked during the clustering procedure. In order to better handle the high dimensionality problem and preserve the spatial structures, this paper proposes a novel unsupervised approach called spatial-spectral clustering with anchor graph (SSCAG) for HSI data clustering. The SSCAG has the following contributions: 1) the anchor graph-based strategy is used to construct a tractable large graph for HSI data, which effectively exploits all data points and reduces the computational complexity; 2) a new similarity metric is presented to embed the spatial-spectral information into the combined adjacent graph, which can mine the intrinsic property structure of HSI data; 3) an effective neighbors assignment strategy is adopted in the optimization, which performs the singular value decomposition (SVD) on the adjacent graph to get solutions efficiently. Extensive experiments on three public HSI datasets show that the proposed SSCAG is competitive against the state-of-the-art approaches.