 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NeuroGen: activation optimized image synthesis for discovery neuroscience
May 15, 2021
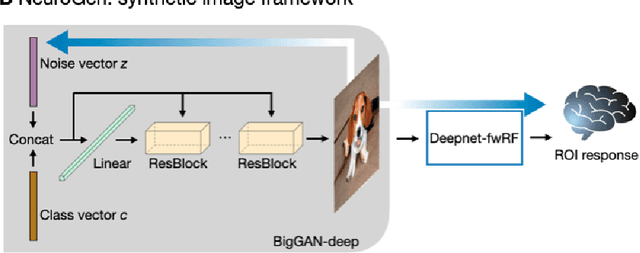
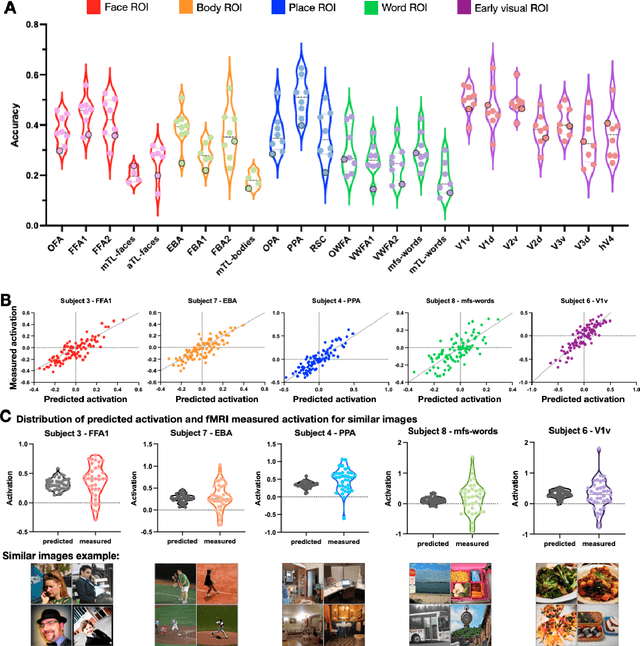

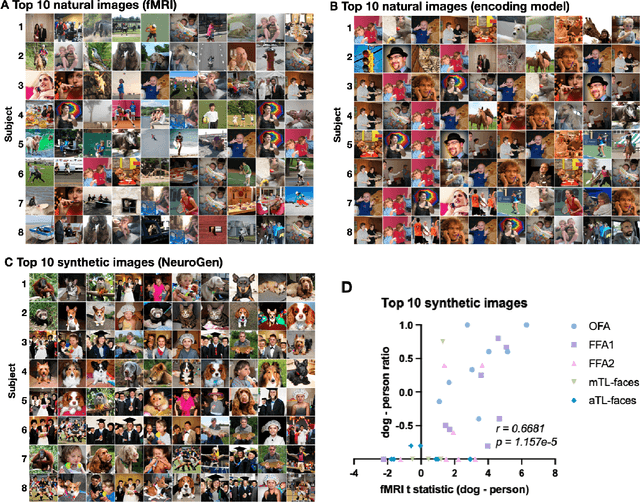
Functional MRI (fMRI) is a powerful technique that has allowed us to characterize visual cortex responses to stimuli, yet such experiments are by nature constructed based on a priori hypotheses, limited to the set of images presented to the individual while they are in the scanner, are subject to noise in the observed brain responses, and may vary widely across individuals. In this work, we propose a novel computational strategy, which we call NeuroGen, to overcome these limitations and develop a powerful tool for human vision neuroscience discovery. NeuroGen combines an fMRI-trained neural encoding model of human vision with a deep generative network to synthesize images predicted to achieve a target pattern of macro-scale brain activation. We demonstrate that the reduction of noise that the encoding model provides, coupled with the generative network's ability to produce images of high fidelity, results in a robust discovery architecture for visual neuroscience. By using only a small number of synthetic images created by NeuroGen, we demonstrate that we can detect and amplify differences in regional and individual human brain response patterns to visual stimuli. We then verify that these discoveries are reflected in the several thousand observed image responses measured with fMRI. We further demonstrate that NeuroGen can create synthetic images predicted to achieve regional response patterns not achievable by the best-matching natural images. The NeuroGen framework extends the utility of brain encoding models and opens up a new avenue for exploring, and possibly precisely controlling, the human visual system.
SeMask: Semantically Masked Transformers for Semantic Segmentation
Dec 23, 2021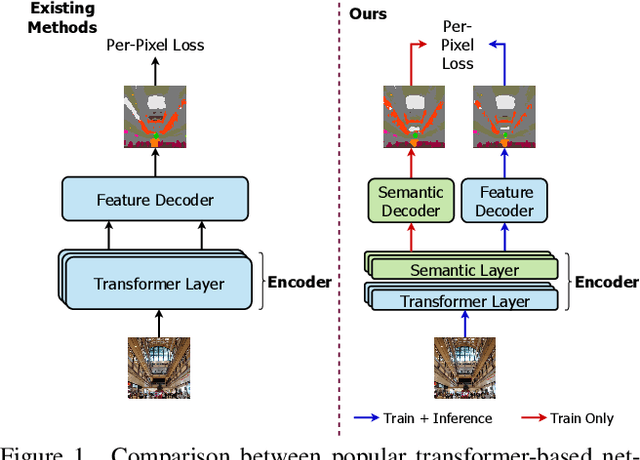
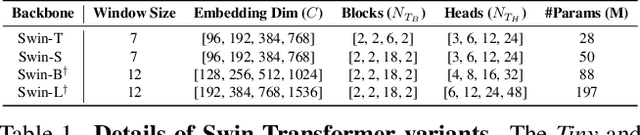
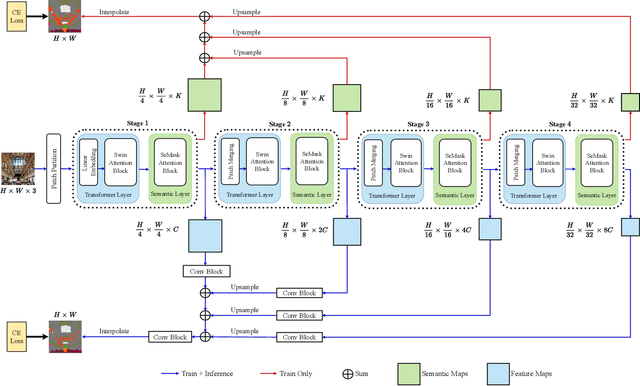
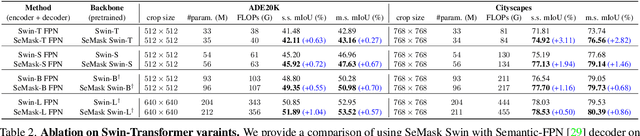
Finetuning a pretrained backbone in the encoder part of an image transformer network has been the traditional approach for the semantic segmentation task. However, such an approach leaves out the semantic context that an image provides during the encoding stage. This paper argues that incorporating semantic information of the image into pretrained hierarchical transformer-based backbones while finetuning improves the performance considerably. To achieve this, we propose SeMask, a simple and effective framework that incorporates semantic information into the encoder with the help of a semantic attention operation. In addition, we use a lightweight semantic decoder during training to provide supervision to the intermediate semantic prior maps at every stage. Our experiments demonstrate that incorporating semantic priors enhances the performance of the established hierarchical encoders with a slight increase in the number of FLOPs. We provide empirical proof by integrating SeMask into each variant of the Swin-Transformer as our encoder paired with different decoders. Our framework achieves a new state-of-the-art of 58.22% mIoU on the ADE20K dataset and improvements of over 3% in the mIoU metric on the Cityscapes dataset. The code and checkpoints are publicly available at https://github.com/Picsart-AI-Research/SeMask-Segmentation .
Learning Graph Regularisation for Guided Super-Resolution
Mar 27, 2022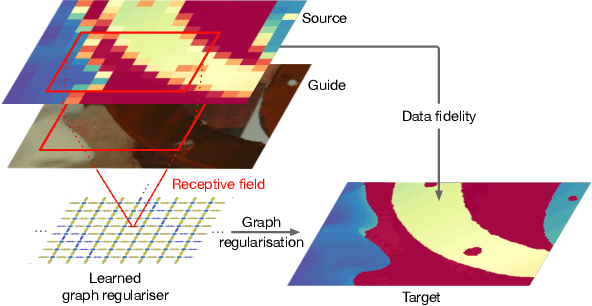
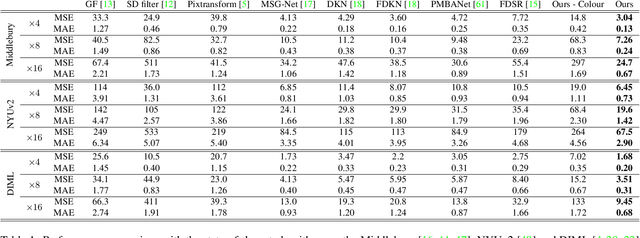

We introduce a novel formulation for guided super-resolution. Its core is a differentiable optimisation layer that operates on a learned affinity graph. The learned graph potentials make it possible to leverage rich contextual information from the guide image, while the explicit graph optimisation within the architecture guarantees rigorous fidelity of the high-resolution target to the low-resolution source. With the decision to employ the source as a constraint rather than only as an input to the prediction, our method differs from state-of-the-art deep architectures for guided super-resolution, which produce targets that, when downsampled, will only approximately reproduce the source. This is not only theoretically appealing, but also produces crisper, more natural-looking images. A key property of our method is that, although the graph connectivity is restricted to the pixel lattice, the associated edge potentials are learned with a deep feature extractor and can encode rich context information over large receptive fields. By taking advantage of the sparse graph connectivity, it becomes possible to propagate gradients through the optimisation layer and learn the edge potentials from data. We extensively evaluate our method on several datasets, and consistently outperform recent baselines in terms of quantitative reconstruction errors, while also delivering visually sharper outputs. Moreover, we demonstrate that our method generalises particularly well to new datasets not seen during training.
Scaling the Wild: Decentralizing Hogwild!-style Shared-memory SGD
Mar 13, 2022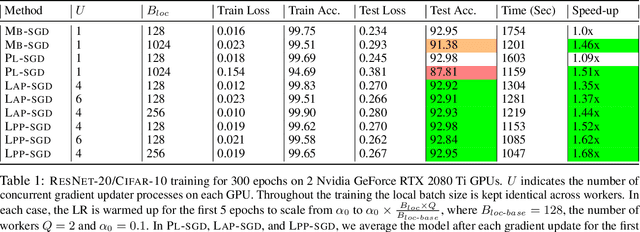
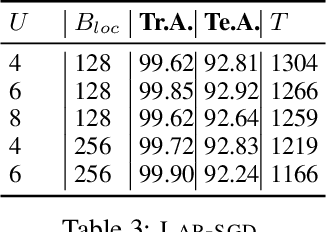
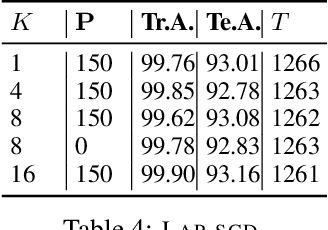
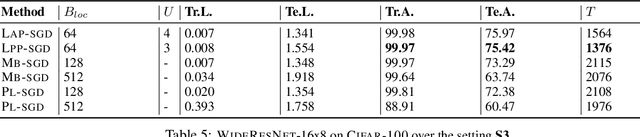
Powered by the simplicity of lock-free asynchrony, Hogwilld! is a go-to approach to parallelize SGD over a shared-memory setting. Despite its popularity and concomitant extensions, such as PASSM+ wherein concurrent processes update a shared model with partitioned gradients, scaling it to decentralized workers has surprisingly been relatively unexplored. To our knowledge, there is no convergence theory of such methods, nor systematic numerical comparisons evaluating speed-up. In this paper, we propose an algorithm incorporating decentralized distributed memory computing architecture with each node running multiprocessing parallel shared-memory SGD itself. Our scheme is based on the following algorithmic tools and features: (a) asynchronous local gradient updates on the shared-memory of workers, (b) partial backpropagation, and (c) non-blocking in-place averaging of the local models. We prove that our method guarantees ergodic convergence rates for non-convex objectives. On the practical side, we show that the proposed method exhibits improved throughput and competitive accuracy for standard image classification benchmarks on the CIFAR-10, CIFAR-100, and Imagenet datasets. Our code is available at https://github.com/bapi/LPP-SGD.
Bayesian Triplet Loss: Uncertainty Quantification in Image Retrieval
Nov 25, 2020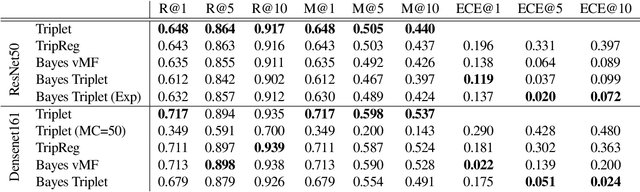
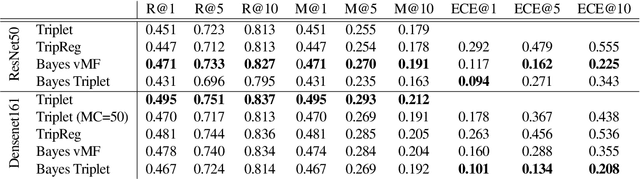
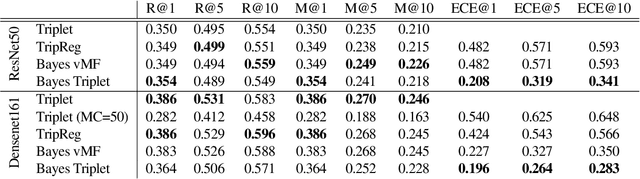
Uncertainty quantification in image retrieval is crucial for downstream decisions, yet it remains a challenging and largely unexplored problem. Current methods for estimating uncertainties are poorly calibrated, computationally expensive, or based on heuristics. We present a new method that views image embeddings as stochastic features rather than deterministic features. Our two main contributions are (1) a likelihood that matches the triplet constraint and that evaluates the probability of an anchor being closer to a positive than a negative; and (2) a prior over the feature space that justifies the conventional l2 normalization. To ensure computational efficiency, we derive a variational approximation of the posterior, called the Bayesian triplet loss, that produces state-of-the-art uncertainty estimates and matches the predictive performance of current state-of-the-art methods.
An unambiguous cloudiness index for nonwovens
Jan 06, 2022
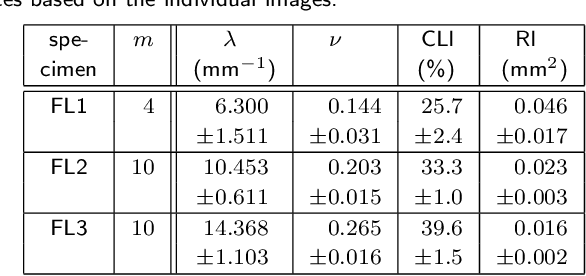
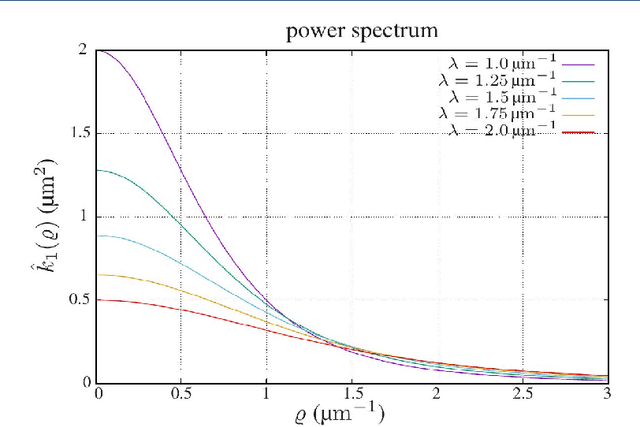
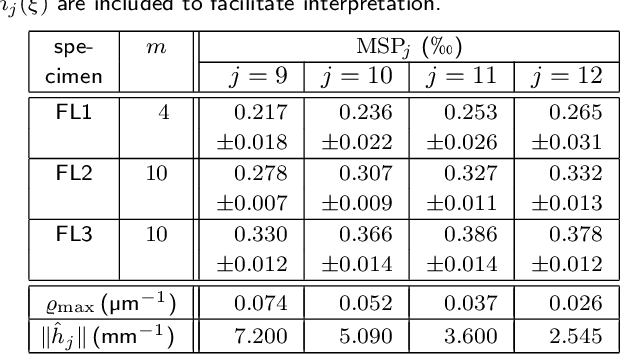
Cloudiness or formation is a concept routinely used in industry to address deviations from homogeneity in nonwovens and papers. Measuring a cloudiness index based on image data is a common task in industrial quality assurance. The two most popular ways of quantifying cloudiness are based on power spectrum or correlation function on the one hand or the Laplacian pyramid on the other hand. Here, we recall the mathematical basis of the first approach comprehensively, derive a cloudiness index, and demonstrate its practical estimation. We prove that the Laplacian pyramid as well as other quantities characterizing cloudiness like the range of interaction and the intensity of small-angle scattering are very closely related to the power spectrum. Finally, we show that the power spectrum is easy to be measured image analytically and carries more information than the alternatives.
CRAFT: Cross-Attentional Flow Transformer for Robust Optical Flow
Mar 31, 2022
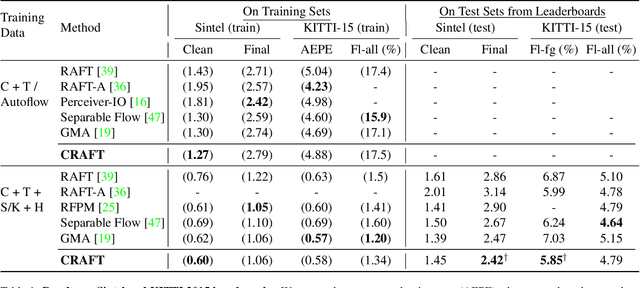
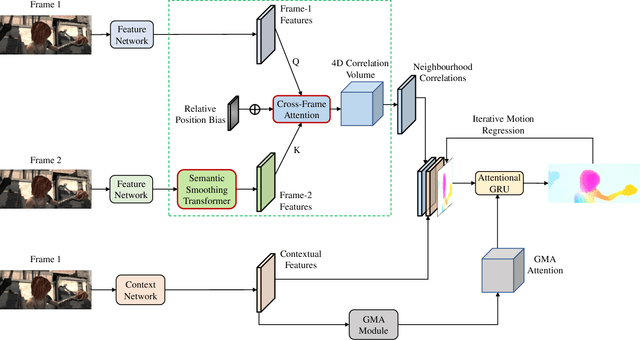
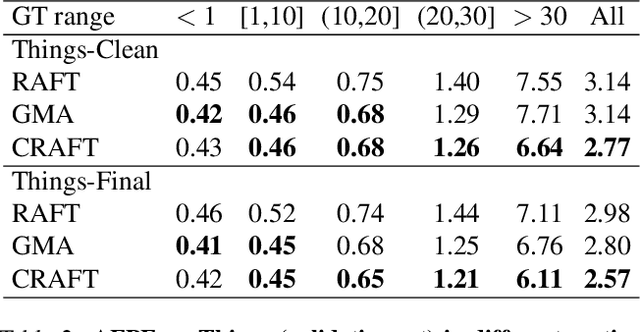
Optical flow estimation aims to find the 2D motion field by identifying corresponding pixels between two images. Despite the tremendous progress of deep learning-based optical flow methods, it remains a challenge to accurately estimate large displacements with motion blur. This is mainly because the correlation volume, the basis of pixel matching, is computed as the dot product of the convolutional features of the two images. The locality of convolutional features makes the computed correlations susceptible to various noises. On large displacements with motion blur, noisy correlations could cause severe errors in the estimated flow. To overcome this challenge, we propose a new architecture "CRoss-Attentional Flow Transformer" (CRAFT), aiming to revitalize the correlation volume computation. In CRAFT, a Semantic Smoothing Transformer layer transforms the features of one frame, making them more global and semantically stable. In addition, the dot-product correlations are replaced with transformer Cross-Frame Attention. This layer filters out feature noises through the Query and Key projections, and computes more accurate correlations. On Sintel (Final) and KITTI (foreground) benchmarks, CRAFT has achieved new state-of-the-art performance. Moreover, to test the robustness of different models on large motions, we designed an image shifting attack that shifts input images to generate large artificial motions. Under this attack, CRAFT performs much more robustly than two representative methods, RAFT and GMA. The code of CRAFT is is available at https://github.com/askerlee/craft.
Aligning Latent and Image Spaces to Connect the Unconnectable
Apr 14, 2021
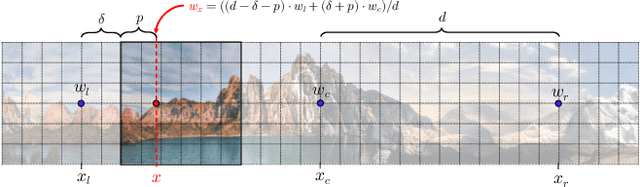

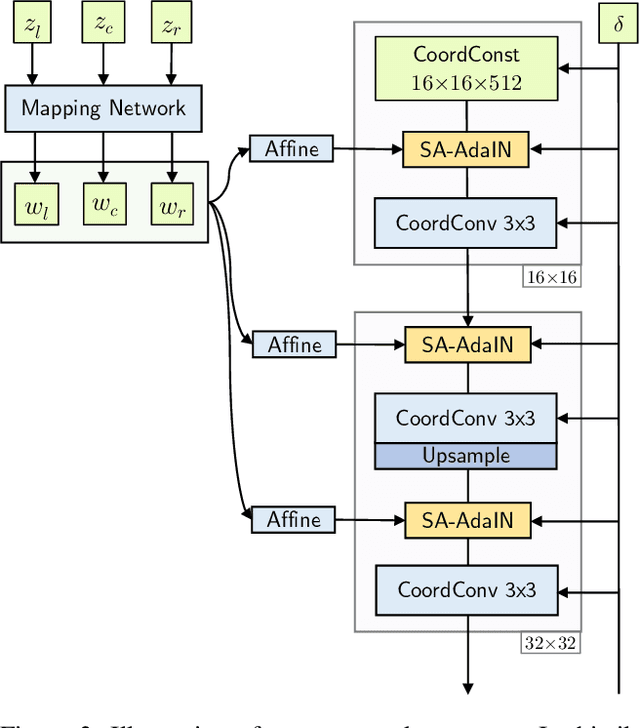
In this work, we develop a method to generate infinite high-resolution images with diverse and complex content. It is based on a perfectly equivariant generator with synchronous interpolations in the image and latent spaces. Latent codes, when sampled, are positioned on the coordinate grid, and each pixel is computed from an interpolation of the nearby style codes. We modify the AdaIN mechanism to work in such a setup and train the generator in an adversarial setting to produce images positioned between any two latent vectors. At test time, this allows for generating complex and diverse infinite images and connecting any two unrelated scenes into a single arbitrarily large panorama. Apart from that, we introduce LHQ: a new dataset of \lhqsize high-resolution nature landscapes. We test the approach on LHQ, LSUN Tower and LSUN Bridge and outperform the baselines by at least 4 times in terms of quality and diversity of the produced infinite images. The project page is located at https://universome.github.io/alis.
VisualCheXbert: Addressing the Discrepancy Between Radiology Report Labels and Image Labels
Feb 23, 2021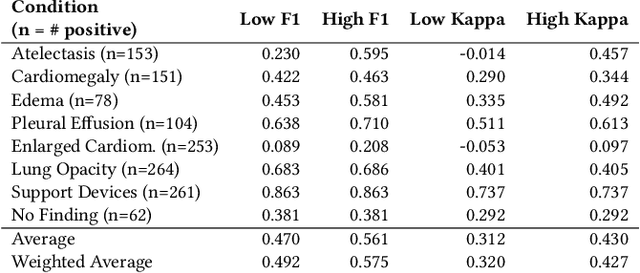
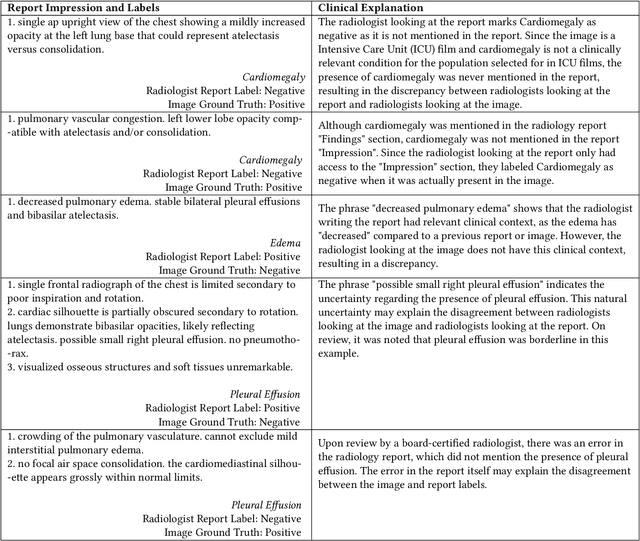
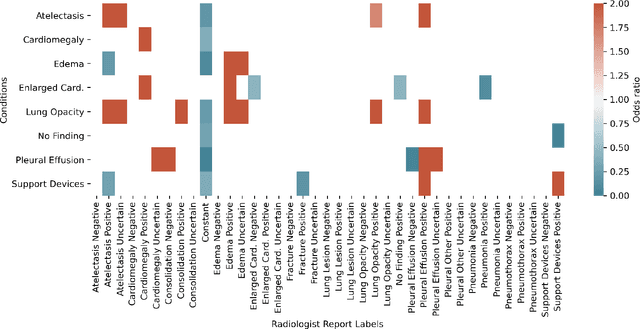
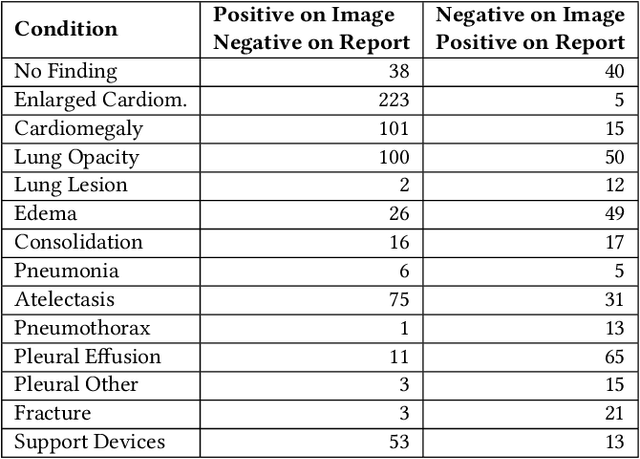
Automatic extraction of medical conditions from free-text radiology reports is critical for supervising computer vision models to interpret medical images. In this work, we show that radiologists labeling reports significantly disagree with radiologists labeling corresponding chest X-ray images, which reduces the quality of report labels as proxies for image labels. We develop and evaluate methods to produce labels from radiology reports that have better agreement with radiologists labeling images. Our best performing method, called VisualCheXbert, uses a biomedically-pretrained BERT model to directly map from a radiology report to the image labels, with a supervisory signal determined by a computer vision model trained to detect medical conditions from chest X-ray images. We find that VisualCheXbert outperforms an approach using an existing radiology report labeler by an average F1 score of 0.14 (95% CI 0.12, 0.17). We also find that VisualCheXbert better agrees with radiologists labeling chest X-ray images than do radiologists labeling the corresponding radiology reports by an average F1 score across several medical conditions of between 0.12 (95% CI 0.09, 0.15) and 0.21 (95% CI 0.18, 0.24).
Piggyback GAN: Efficient Lifelong Learning for Image Conditioned Generation
Apr 24, 2021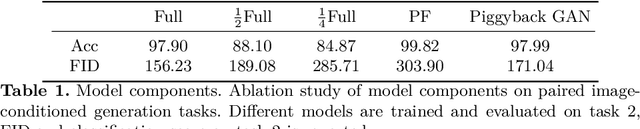
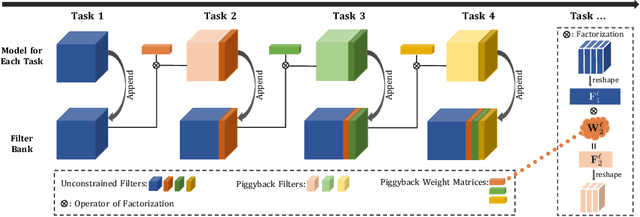
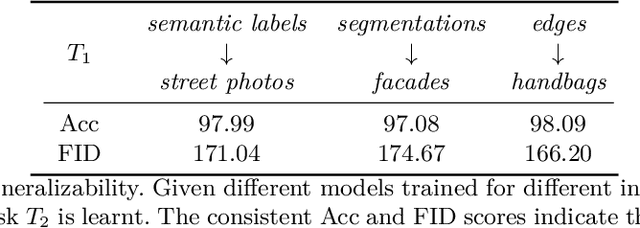
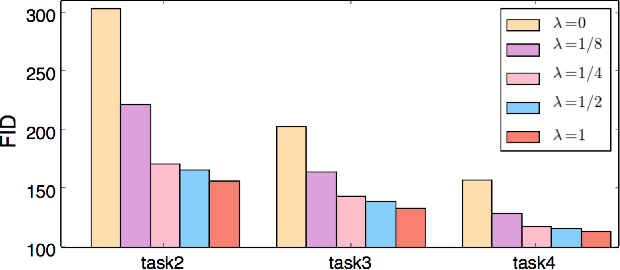
Humans accumulate knowledge in a lifelong fashion. Modern deep neural networks, on the other hand, are susceptible to catastrophic forgetting: when adapted to perform new tasks, they often fail to preserve their performance on previously learned tasks. Given a sequence of tasks, a naive approach addressing catastrophic forgetting is to train a separate standalone model for each task, which scales the total number of parameters drastically without efficiently utilizing previous models. In contrast, we propose a parameter efficient framework, Piggyback GAN, which learns the current task by building a set of convolutional and deconvolutional filters that are factorized into filters of the models trained on previous tasks. For the current task, our model achieves high generation quality on par with a standalone model at a lower number of parameters. For previous tasks, our model can also preserve generation quality since the filters for previous tasks are not altered. We validate Piggyback GAN on various image-conditioned generation tasks across different domains, and provide qualitative and quantitative results to show that the proposed approach can address catastrophic forgetting effectively and efficiently.