 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hyperspectral Mixed Noise Removal via Subspace Representation and Weighted Low-rank Tensor Regularization
Nov 13, 2021
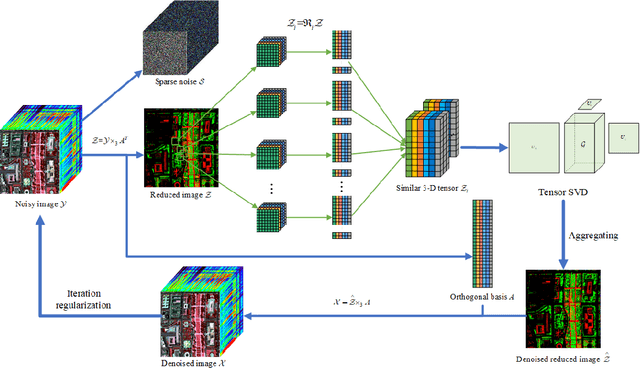


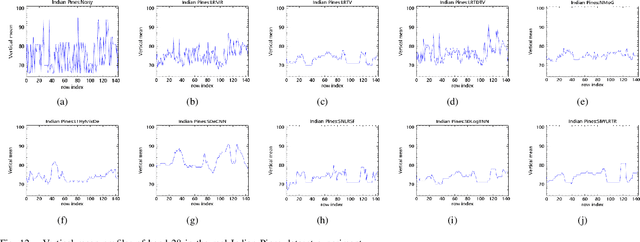
Recently, the low-rank property of different components extracted from the image has been considered in man hyperspectral image denoising methods. However, these methods usually unfold the 3D tensor to 2D matrix or 1D vector to exploit the prior information, such as nonlocal spatial self-similarity (NSS) and global spectral correlation (GSC), which break the intrinsic structure correlation of hyperspectral image (HSI) and thus lead to poor restoration quality. In addition, most of them suffer from heavy computational burden issues due to the involvement of singular value decomposition operation on matrix and tensor in the original high-dimensionality space of HSI. We employ subspace representation and the weighted low-rank tensor regularization (SWLRTR) into the model to remove the mixed noise in the hyperspectral image. Specifically, to employ the GSC among spectral bands, the noisy HSI is projected into a low-dimensional subspace which simplified calculation. After that, a weighted low-rank tensor regularization term is introduced to characterize the priors in the reduced image subspace. Moreover, we design an algorithm based on alternating minimization to solve the nonconvex problem. Experiments on simulated and real datasets demonstrate that the SWLRTR method performs better than other hyperspectral denoising methods quantitatively and visually.
Encoder Fusion Network with Co-Attention Embedding for Referring Image Segmentation
May 05, 2021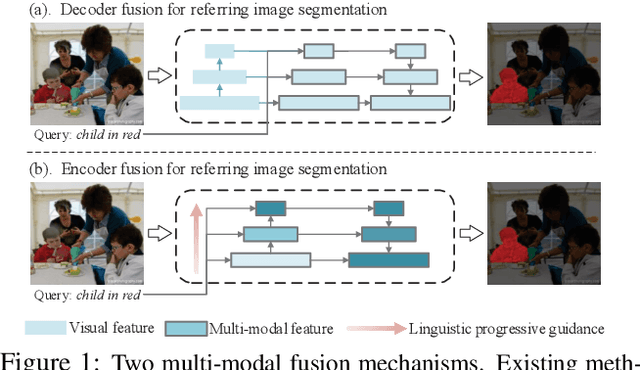
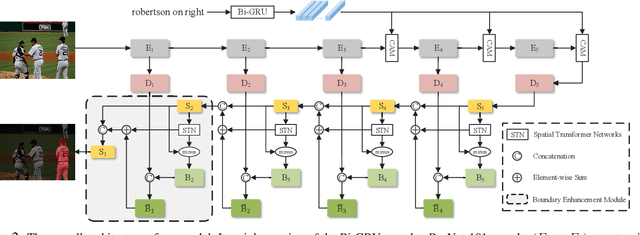
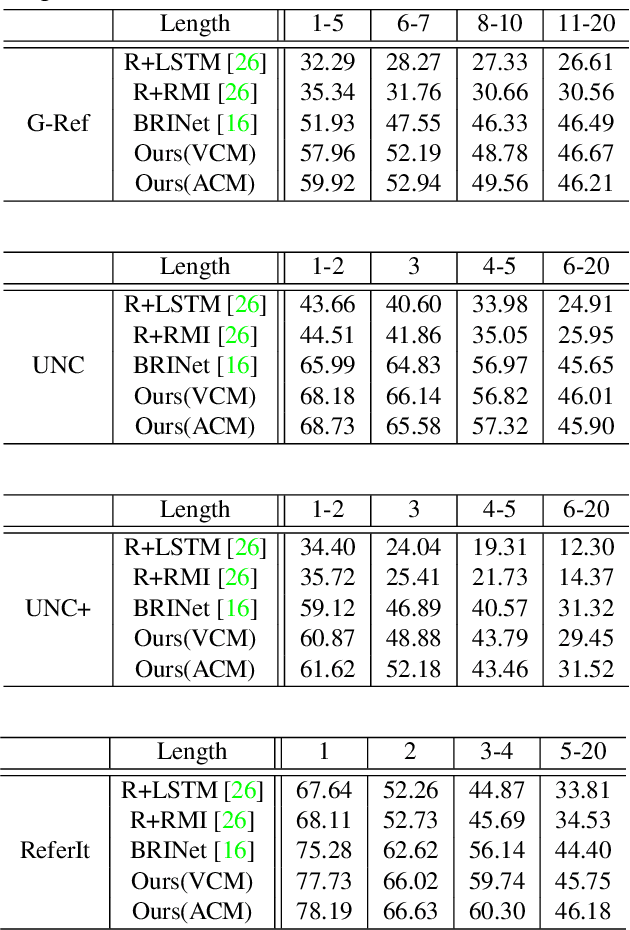
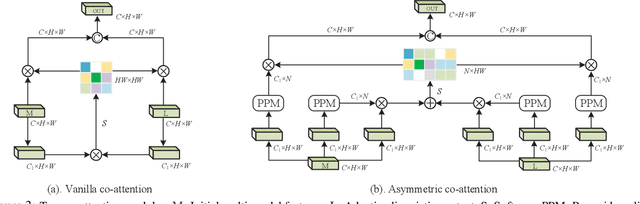
Recently, referring image segmentation has aroused widespread interest. Previous methods perform the multi-modal fusion between language and vision at the decoding side of the network. And, linguistic feature interacts with visual feature of each scale separately, which ignores the continuous guidance of language to multi-scale visual features. In this work, we propose an encoder fusion network (EFN), which transforms the visual encoder into a multi-modal feature learning network, and uses language to refine the multi-modal features progressively. Moreover, a co-attention mechanism is embedded in the EFN to realize the parallel update of multi-modal features, which can promote the consistent of the cross-modal information representation in the semantic space. Finally, we propose a boundary enhancement module (BEM) to make the network pay more attention to the fine structure. The experiment results on four benchmark datasets demonstrate that the proposed approach achieves the state-of-the-art performance under different evaluation metrics without any post-processing.
Weighted Histogram Equalization Using Entropy of Probability Density Function
Nov 22, 2021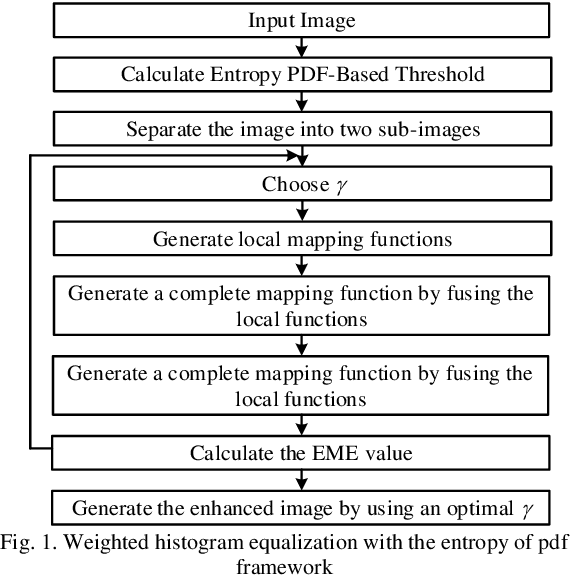
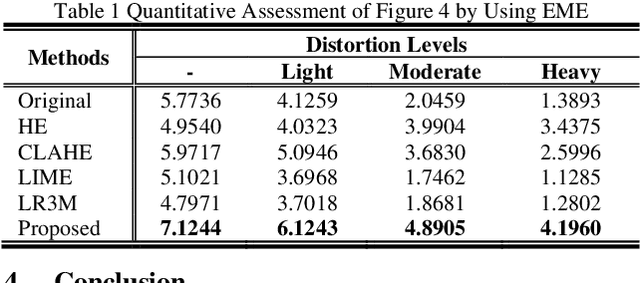
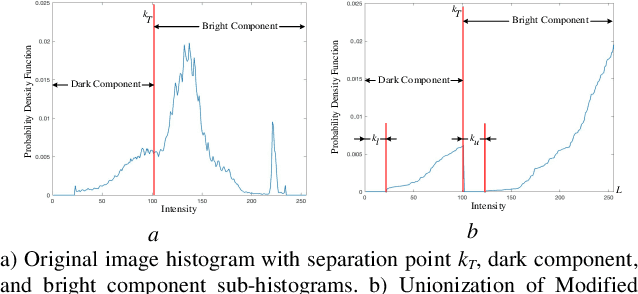

Low-contrast image enhancement is essential for high-quality image display and other visual applications. However, it is a challenging task as the enhancement is expected to increase the visibility of an image while maintaining its naturalness. In this paper, the weighted histogram equalization using the entropy of the probability density function is proposed. The computation of the local mapping functions utilizes the relationship between non-height bin and height bin distributions. Finally, the complete tone mapping function is produced by concatenating local mapping functions. Computer simulation results on the CSIQ dataset demonstrate that the proposed method produces images with higher visibility and visual quality, which outperforms traditional and recently proposed contrast enhancement algorithms methods in qualitative and quantitative metrics.
IAE-Net: Integral Autoencoders for Discretization-Invariant Learning
Mar 10, 2022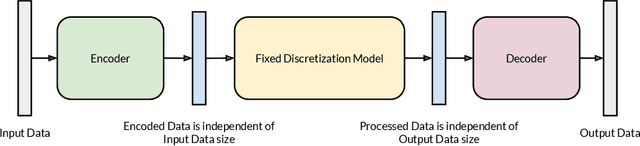

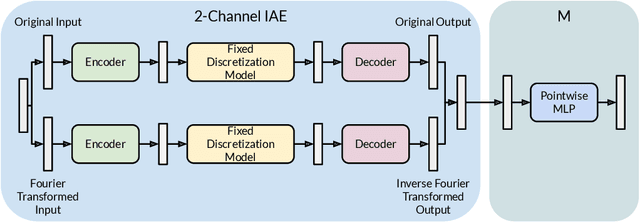

Discretization invariant learning aims at learning in the infinite-dimensional function spaces with the capacity to process heterogeneous discrete representations of functions as inputs and/or outputs of a learning model. This paper proposes a novel deep learning framework based on integral autoencoders (IAE-Net) for discretization invariant learning. The basic building block of IAE-Net consists of an encoder and a decoder as integral transforms with data-driven kernels, and a fully connected neural network between the encoder and decoder. This basic building block is applied in parallel in a wide multi-channel structure, which are repeatedly composed to form a deep and densely connected neural network with skip connections as IAE-Net. IAE-Net is trained with randomized data augmentation that generates training data with heterogeneous structures to facilitate the performance of discretization invariant learning. The proposed IAE-Net is tested with various applications in predictive data science, solving forward and inverse problems in scientific computing, and signal/image processing. Compared with alternatives in the literature, IAE-Net achieves state-of-the-art performance in existing applications and creates a wide range of new applications.
Salt and pepper noise removal method based on stationary Framelet transform with non-convex sparsity regularization
Nov 02, 2021
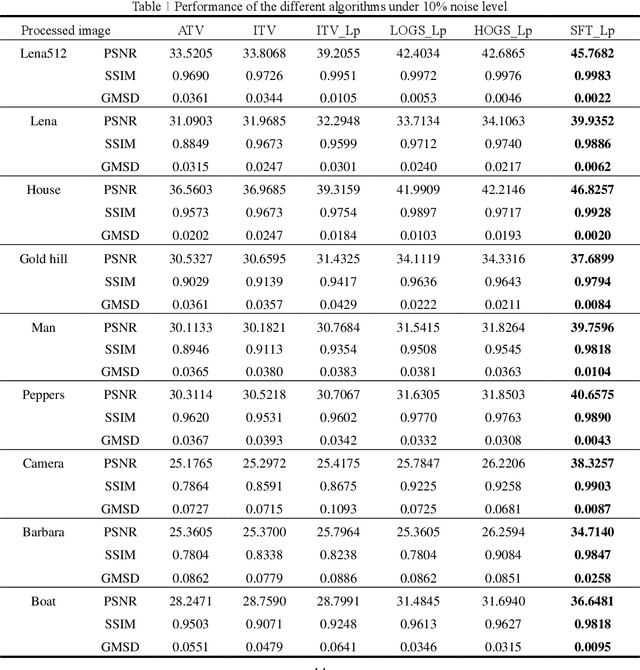
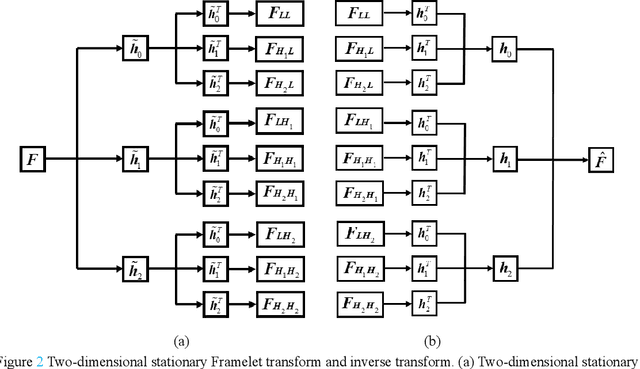
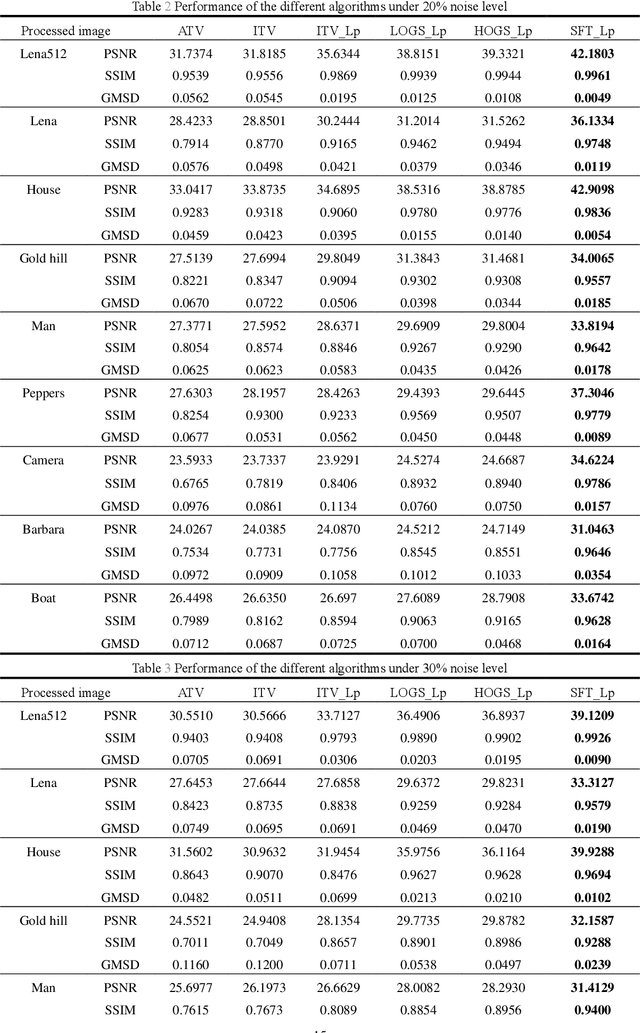
Salt and pepper noise removal is a common inverse problem in image processing. Traditional denoising methods have two limitations. First, noise characteristics are often not described accurately. For example, the noise location information is often ignored and the sparsity of the salt and pepper noise is often described by L1 norm, which cannot illustrate the sparse variables clearly. Second, conventional methods separate the contaminated image into a recovered image and a noise part, thus resulting in recovering an image with unsatisfied smooth parts and detail parts. In this study, we introduce a noise detection strategy to determine the position of the noise, and a non-convex sparsity regularization depicted by Lp quasi-norm is employed to describe the sparsity of the noise, thereby addressing the first limitation. The morphological component analysis framework with stationary Framelet transform is adopted to decompose the processed image into cartoon, texture, and noise parts to resolve the second limitation. Then, the alternating direction method of multipliers (ADMM) is employed to solve the proposed model. Finally, experiments are conducted to verify the proposed method and compare it with some current state-of-the-art denoising methods. The experimental results show that the proposed method can remove salt and pepper noise while preserving the details of the processed image.
Local Gradient Hexa Pattern: A Descriptor for Face Recognition and Retrieval
Jan 03, 2022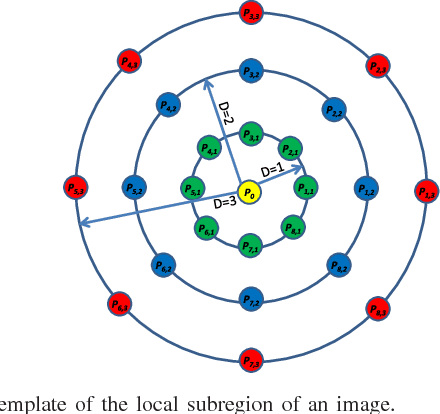
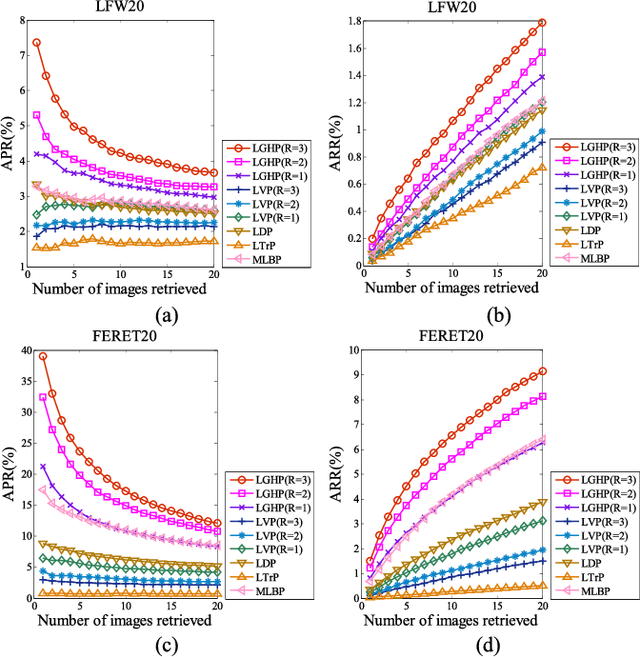
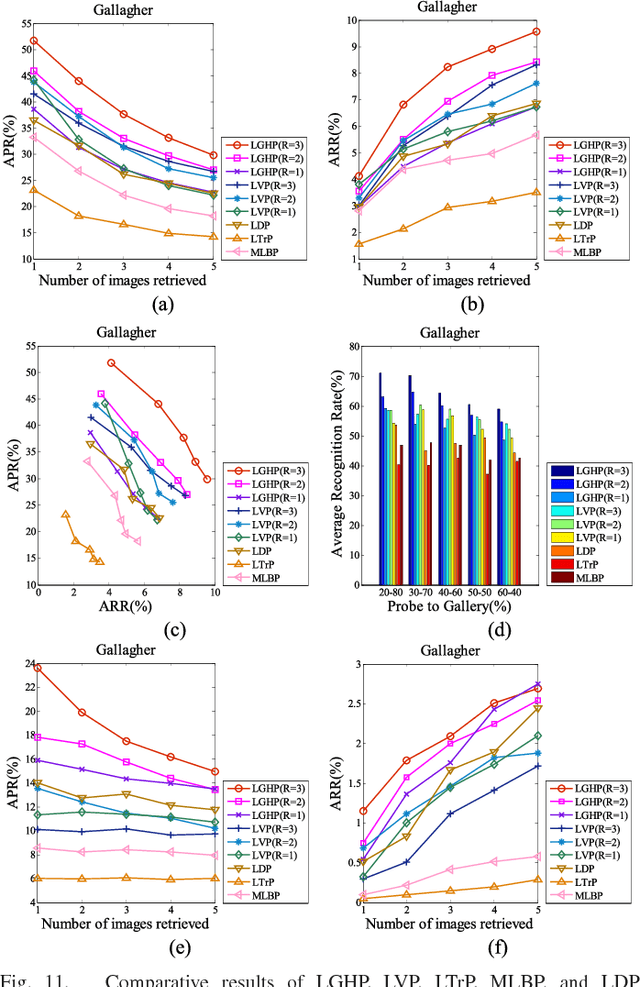
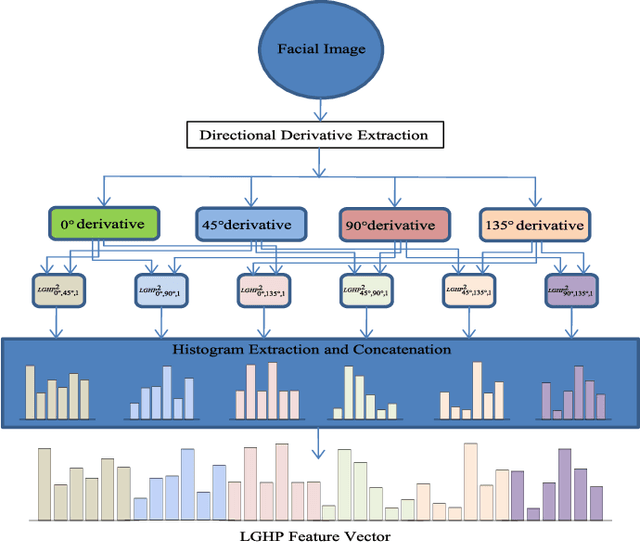
Local descriptors used in face recognition are robust in a sense that these descriptors perform well in varying pose, illumination and lighting conditions. Accuracy of these descriptors depends on the precision of mapping the relationship that exists in the local neighborhood of a facial image into microstructures. In this paper a local gradient hexa pattern (LGHP) is proposed that identifies the relationship amongst the reference pixel and its neighboring pixels at different distances across different derivative directions. Discriminative information exists in the local neighborhood as well as in different derivative directions. Proposed descriptor effectively transforms these relationships into binary micropatterns discriminating interclass facial images with optimal precision. Recognition and retrieval performance of the proposed descriptor has been compared with state-of-the-art descriptors namely LDP and LVP over the most challenging and benchmark facial image databases, i.e. Cropped Extended Yale-B, CMU-PIE, color-FERET, and LFW. The proposed descriptor has better recognition as well as retrieval rates compared to state-of-the-art descriptors.
Developing Imperceptible Adversarial Patches to Camouflage Military Assets From Computer Vision Enabled Technologies
Feb 17, 2022


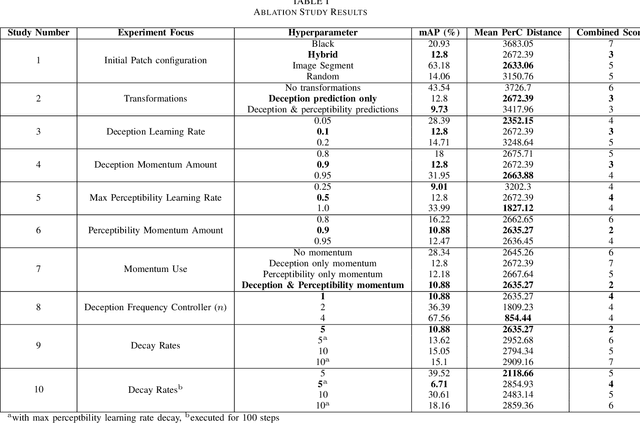
Convolutional neural networks (CNNs) have demonstrated rapid progress and a high level of success in object detection. However, recent evidence has highlighted their vulnerability to adversarial attacks. These attacks are calculated image perturbations or adversarial patches that result in object misclassification or detection suppression. Traditional camouflage methods are impractical when applied to disguise aircraft and other large mobile assets from autonomous detection in intelligence, surveillance and reconnaissance technologies and fifth generation missiles. In this paper we present a unique method that produces imperceptible patches capable of camouflaging large military assets from computer vision-enabled technologies. We developed these patches by maximising object detection loss whilst limiting the patch's colour perceptibility. This work also aims to further the understanding of adversarial examples and their effects on object detection algorithms.
A Quality Index Metric and Method for Online Self-Assessment of Autonomous Vehicles Sensory Perception
Mar 04, 2022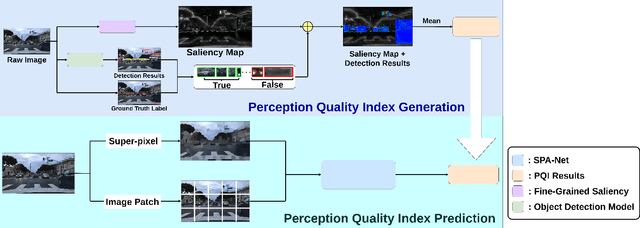

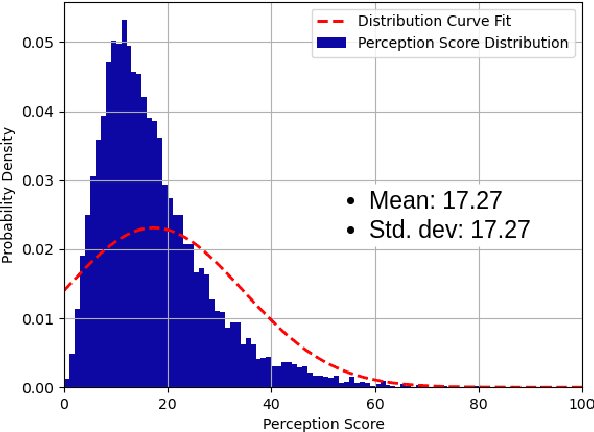
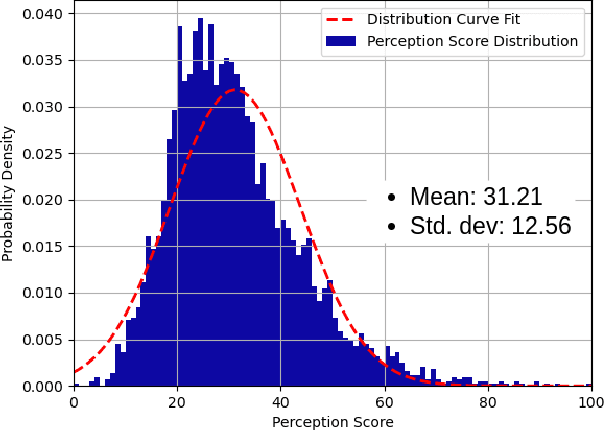
Perception is critical to autonomous driving safety. Camera-based object detection is one of the most important methods for autonomous vehicle perception. Current camera-based object detection solutions for autonomous driving cannot provide feedback on the detection performance for each frame. We propose an evaluation metric, namely the perception quality index (PQI), to assess the camera-based object detection algorithm performance and provide the perception quality feedback frame by frame. The method of the PQI generation is by combining the fine-grained saliency map intensity with the object detection algorithm's output results. Furthermore, we developed a superpixel-based attention network (SPA-NET) to predict the proposed PQI evaluation metric by using raw image pixels and superpixels as input. The proposed evaluation metric and prediction network are tested on three open-source datasets. The proposed evaluation metric can correctly assess the camera-based perception quality under the autonomous driving environment according to the experiment results. The network regression R-square values determine the comparison among models. It is shown that a Perception Quality Index is useful in self-evaluating a cameras visual scene perception.
Online Learning of Reusable Abstract Models for Object Goal Navigation
Mar 04, 2022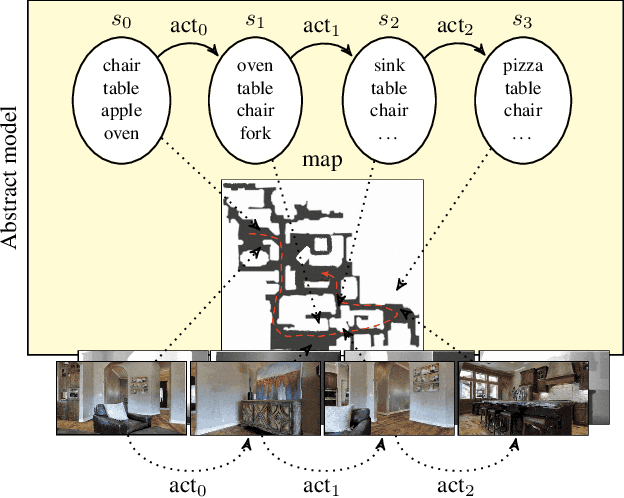
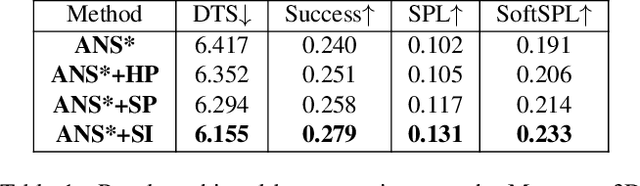
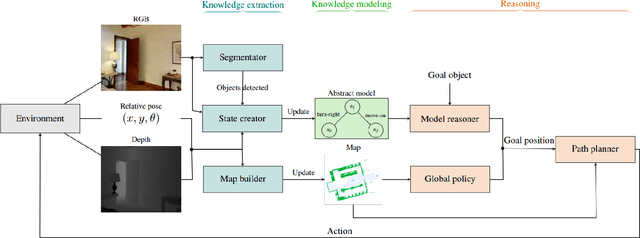
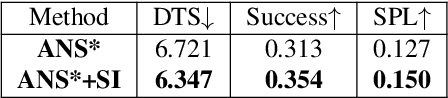
In this paper, we present a novel approach to incrementally learn an Abstract Model of an unknown environment, and show how an agent can reuse the learned model for tackling the Object Goal Navigation task. The Abstract Model is a finite state machine in which each state is an abstraction of a state of the environment, as perceived by the agent in a certain position and orientation. The perceptions are high-dimensional sensory data (e.g., RGB-D images), and the abstraction is reached by exploiting image segmentation and the Taskonomy model bank. The learning of the Abstract Model is accomplished by executing actions, observing the reached state, and updating the Abstract Model with the acquired information. The learned models are memorized by the agent, and they are reused whenever it recognizes to be in an environment that corresponds to the stored model. We investigate the effectiveness of the proposed approach for the Object Goal Navigation task, relying on public benchmarks. Our results show that the reuse of learned Abstract Models can boost performance on Object Goal Navigation.
TransductGAN: a Transductive Adversarial Model for Novelty Detection
Mar 30, 2022


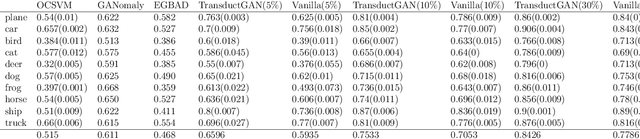
Novelty detection, a widely studied problem in machine learning, is the problem of detecting a novel class of data that has not been previously observed. A common setting for novelty detection is inductive whereby only examples of the negative class are available during training time. Transductive novelty detection on the other hand has only witnessed a recent surge in interest, it not only makes use of the negative class during training but also incorporates the (unlabeled) test set to detect novel examples. Several studies have emerged under the transductive setting umbrella that have demonstrated its advantage over its inductive counterpart. Depending on the assumptions about the data, these methods go by different names (e.g. transductive novelty detection, semi-supervised novelty detection, positive-unlabeled learning, out-of-distribution detection). With the use of generative adversarial networks (GAN), a segment of those studies have adopted a transductive setup in order to learn how to generate examples of the novel class. In this study, we propose TransductGAN, a transductive generative adversarial network that attempts to learn how to generate image examples from both the novel and negative classes by using a mixture of two Gaussians in the latent space. It achieves that by incorporating an adversarial autoencoder with a GAN network, the ability to generate examples of novel data points offers not only a visual representation of novelties, but also overcomes the hurdle faced by many inductive methods of how to tune the model hyperparameters at the decision rule level. Our model has shown superior performance over state-of-the-art inductive and transductive methods. Our study is fully reproducible with the code available publicly.