 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
E-CIR: Event-Enhanced Continuous Intensity Recovery
Mar 03, 2022
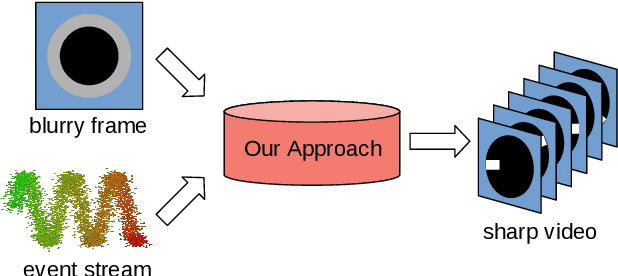
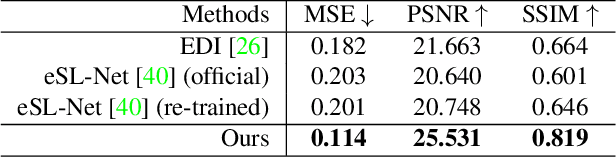
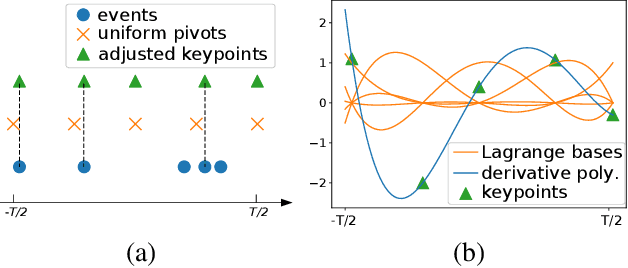

A camera begins to sense light the moment we press the shutter button. During the exposure interval, relative motion between the scene and the camera causes motion blur, a common undesirable visual artifact. This paper presents E-CIR, which converts a blurry image into a sharp video represented as a parametric function from time to intensity. E-CIR leverages events as an auxiliary input. We discuss how to exploit the temporal event structure to construct the parametric bases. We demonstrate how to train a deep learning model to predict the function coefficients. To improve the appearance consistency, we further introduce a refinement module to propagate visual features among consecutive frames. Compared to state-of-the-art event-enhanced deblurring approaches, E-CIR generates smoother and more realistic results. The implementation of E-CIR is available at https://github.com/chensong1995/E-CIR.
Image Synthesis via Semantic Composition
Sep 15, 2021
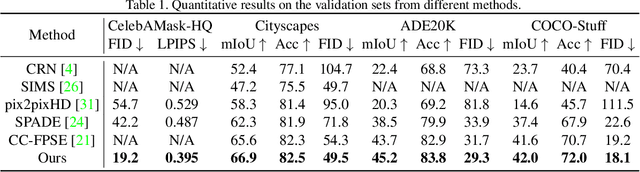
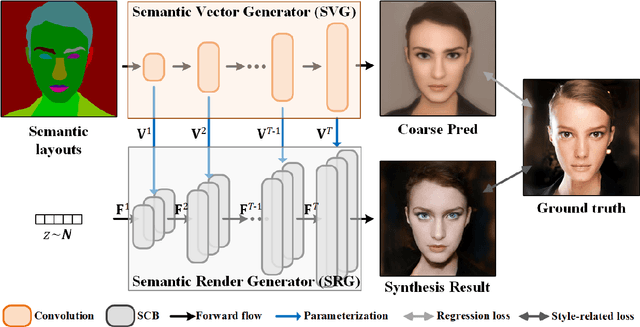
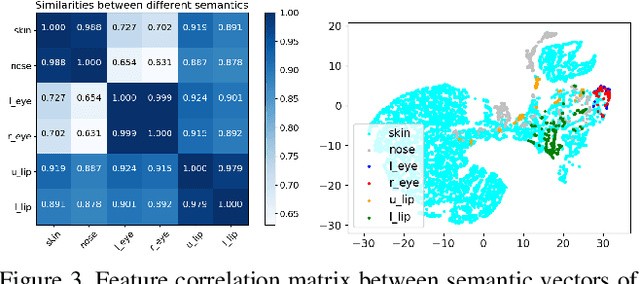
In this paper, we present a novel approach to synthesize realistic images based on their semantic layouts. It hypothesizes that for objects with similar appearance, they share similar representation. Our method establishes dependencies between regions according to their appearance correlation, yielding both spatially variant and associated representations. Conditioning on these features, we propose a dynamic weighted network constructed by spatially conditional computation (with both convolution and normalization). More than preserving semantic distinctions, the given dynamic network strengthens semantic relevance, benefiting global structure and detail synthesis. We demonstrate that our method gives the compelling generation performance qualitatively and quantitatively with extensive experiments on benchmarks.
Towards More Efficient EfficientDets and Low-Light Real-Time Marine Debris Detection
Mar 14, 2022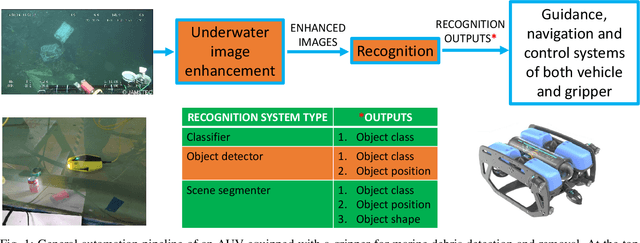
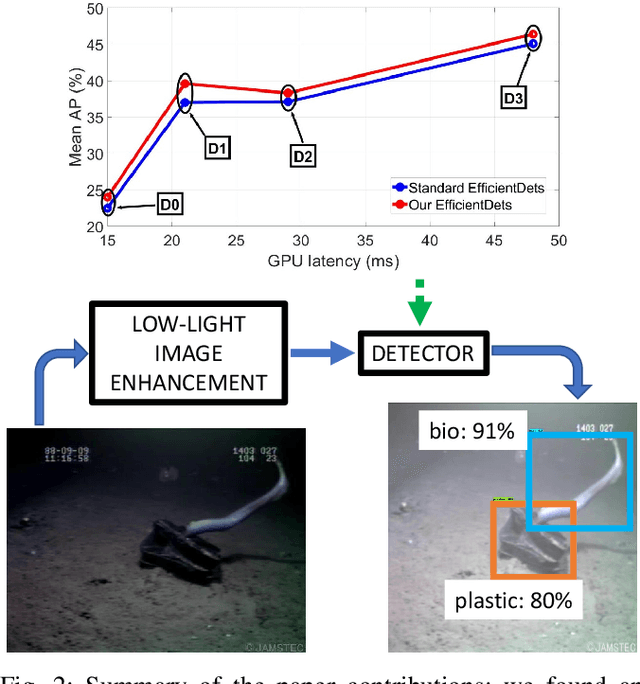
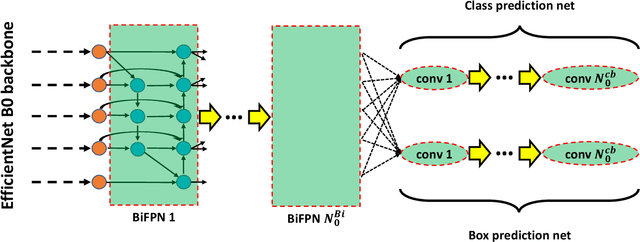

Marine debris is a problem both for the health of marine environments and for the human health since tiny pieces of plastic called "microplastics" resulting from the debris decomposition over the time are entering the food chain at any levels. For marine debris detection and removal, autonomous underwater vehicles (AUVs) are a potential solution. In this letter, we focus on the efficiency of AUV vision for real-time and low-light object detection. First, we improved the efficiency of a class of state-of-the-art object detectors, namely EfficientDets, by 1.5% AP on D0, 2.6% AP on D1, 1.2% AP on D2 and 1.3% AP on D3 without increasing the GPU latency. Subsequently, we created and made publicly available a dataset for the detection of in-water plastic bags and bottles and trained our improved EfficientDets on this and another dataset for marine debris detection. Finally, we investigated how the detector performance is affected by low-light conditions and compared two low-light underwater image enhancement strategies both in terms of accuracy and latency. Source code and dataset are publicly available.
Towards Exemplar-Free Continual Learning in Vision Transformers: an Account of Attention, Functional and Weight Regularization
Mar 28, 2022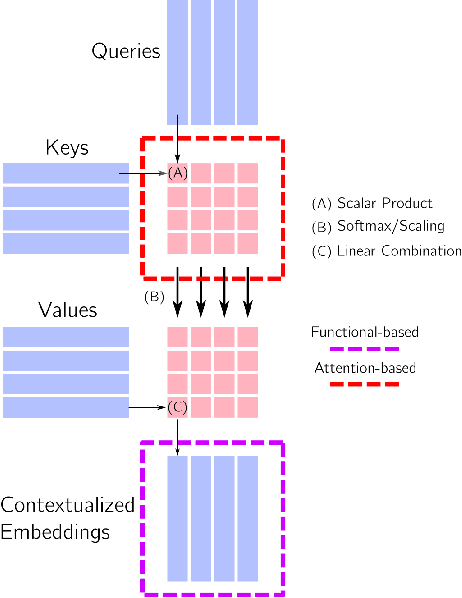
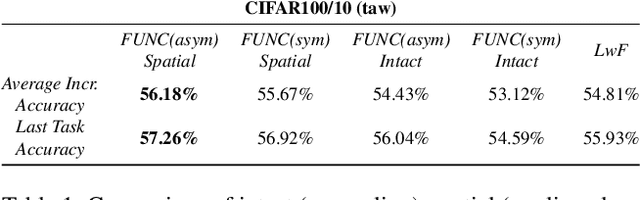
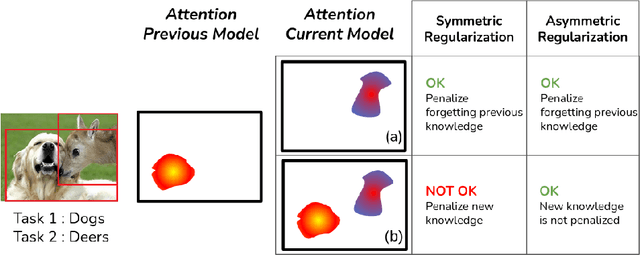
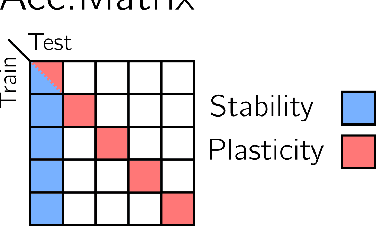
In this paper, we investigate the continual learning of Vision Transformers (ViT) for the challenging exemplar-free scenario, with special focus on how to efficiently distill the knowledge of its crucial self-attention mechanism (SAM). Our work takes an initial step towards a surgical investigation of SAM for designing coherent continual learning methods in ViTs. We first carry out an evaluation of established continual learning regularization techniques. We then examine the effect of regularization when applied to two key enablers of SAM: (a) the contextualized embedding layers, for their ability to capture well-scaled representations with respect to the values, and (b) the prescaled attention maps, for carrying value-independent global contextual information. We depict the perks of each distilling strategy on two image recognition benchmarks (CIFAR100 and ImageNet-32) -- while (a) leads to a better overall accuracy, (b) helps enhance the rigidity by maintaining competitive performances. Furthermore, we identify the limitation imposed by the symmetric nature of regularization losses. To alleviate this, we propose an asymmetric variant and apply it to the pooled output distillation (POD) loss adapted for ViTs. Our experiments confirm that introducing asymmetry to POD boosts its plasticity while retaining stability across (a) and (b). Moreover, we acknowledge low forgetting measures for all the compared methods, indicating that ViTs might be naturally inclined continual learner
Learnability Lock: Authorized Learnability Control Through Adversarial Invertible Transformations
Feb 03, 2022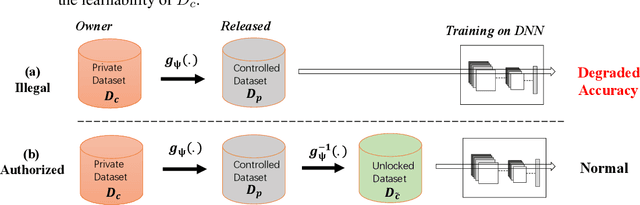

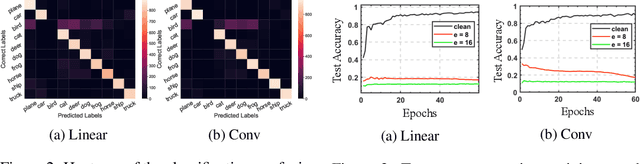
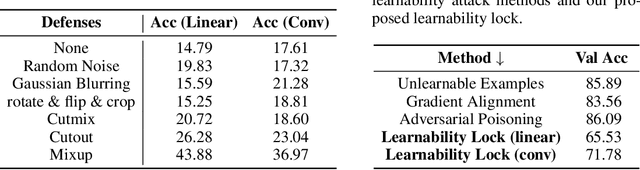
Owing much to the revolution of information technology, the recent progress of deep learning benefits incredibly from the vastly enhanced access to data available in various digital formats. However, in certain scenarios, people may not want their data being used for training commercial models and thus studied how to attack the learnability of deep learning models. Previous works on learnability attack only consider the goal of preventing unauthorized exploitation on the specific dataset but not the process of restoring the learnability for authorized cases. To tackle this issue, this paper introduces and investigates a new concept called "learnability lock" for controlling the model's learnability on a specific dataset with a special key. In particular, we propose adversarial invertible transformation, that can be viewed as a mapping from image to image, to slightly modify data samples so that they become "unlearnable" by machine learning models with negligible loss of visual features. Meanwhile, one can unlock the learnability of the dataset and train models normally using the corresponding key. The proposed learnability lock leverages class-wise perturbation that applies a universal transformation function on data samples of the same label. This ensures that the learnability can be easily restored with a simple inverse transformation while remaining difficult to be detected or reverse-engineered. We empirically demonstrate the success and practicability of our method on visual classification tasks.
Efficient Full Image Interactive Segmentation by Leveraging Within-image Appearance Similarity
Jul 16, 2020
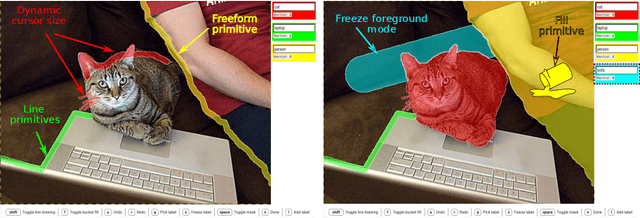

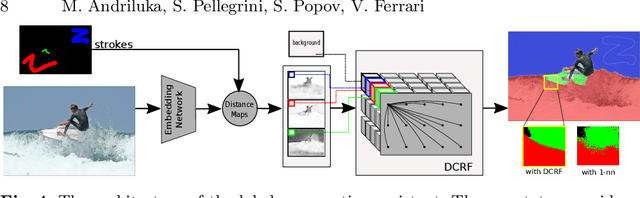
We propose a new approach to interactive full-image semantic segmentation which enables quickly collecting training data for new datasets with previously unseen semantic classes (A demo is available at https://youtu.be/yUk8D5gEX-o). We leverage a key observation: propagation from labeled to unlabeled pixels does not necessarily require class-specific knowledge, but can be done purely based on appearance similarity within an image. We build on this observation and propose an approach capable of jointly propagating pixel labels from multiple classes without having explicit class-specific appearance models. To enable long-range propagation, our approach first globally measures appearance similarity between labeled and unlabeled pixels across the entire image. Then it locally integrates per-pixel measurements which improves the accuracy at boundaries and removes noisy label switches in homogeneous regions. We also design an efficient manual annotation interface that extends the traditional polygon drawing tools with a suite of additional convenient features (and add automatic propagation to it). Experiments with human annotators on the COCO Panoptic Challenge dataset show that the combination of our better manual interface and our novel automatic propagation mechanism leads to reducing annotation time by more than factor of 2x compared to polygon drawing. We also test our method on the ADE-20k and Fashionista datasets without making any dataset-specific adaptation nor retraining our model, demonstrating that it can generalize to new datasets and visual classes.
Real Time Integration Centre of Mass (riCOM) Reconstruction for 4D-STEM
Dec 08, 2021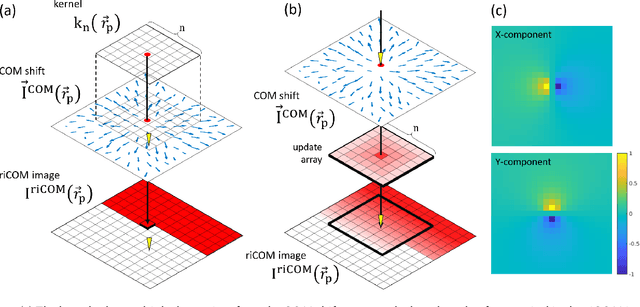
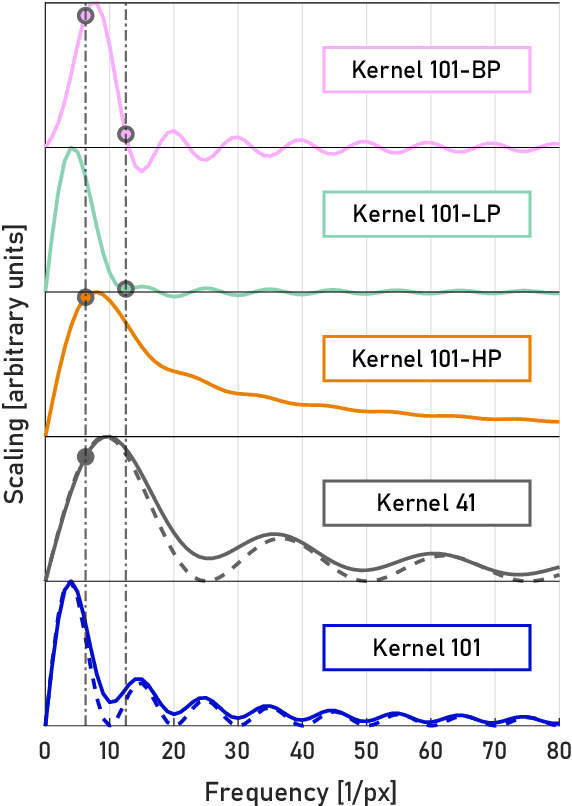
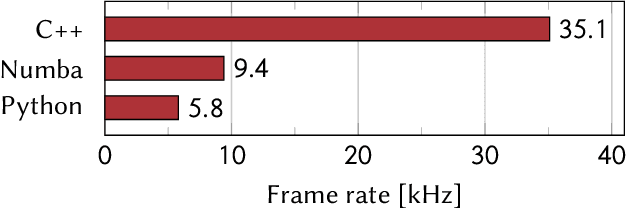
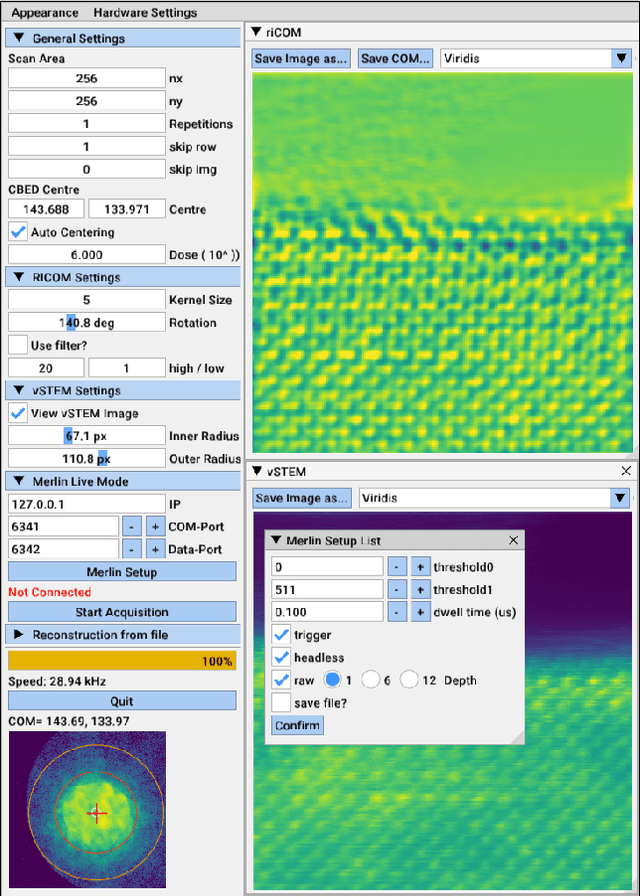
A real-time image reconstruction method for scanning transmission electron microscopy (STEM) is proposed. The method uses the concept of integrated centre of mass (iCOM) and creates a live-updated image based on diffraction patterns collected at each probe position during scanning. It is shown that the method has similar characteristics to the traditional iCOM approach. However, by reformulating the integration method, the reconstruction process can be divided into sub-units, with each unit requiring only information from a single probe position, such that the resulting image can be updated each time a new probe position is visited without storing any intermediate diffraction patterns. As a certain position in the image is only influenced by its surrounding pixels in the immediate vicinity, the image update provides interpretable images being build up while the scanning is being performed. The results show clearer features at higher spatial frequency, such as atomic column positions. It is also demonstrated that common post processing methods, such as a band pass filter, can be directly integrated in the real time processing flow. By comparing with other reconstruction methods, it is shown that the proposed method can produce high quality reconstructions with good noise robustness at extremely low memory and computational requirements. We further present an efficient, interactive open source implementation of the concept, compatible with frame-based, as well as event-based camera/file types. The proposed method provides the attractive feature of immediate feedback that microscope operators have become used to for e.g. conventional HAADF STEM imaging allowing for rapid decision making and fine tuning to obtain the best possible images for beam sensitive samples at the lowest possible dose.
Dynamic and Efficient Gray-Box Hyperparameter Optimization for Deep Learning
Feb 20, 2022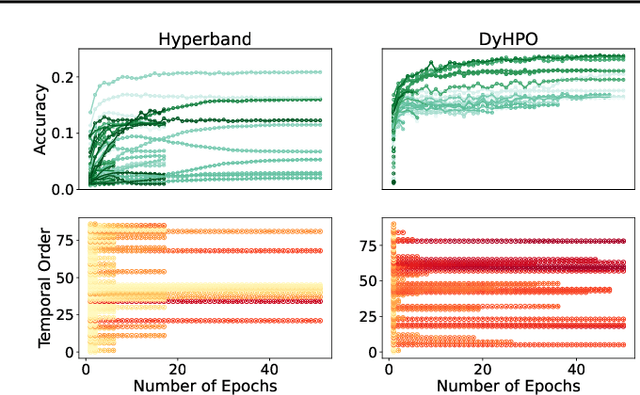
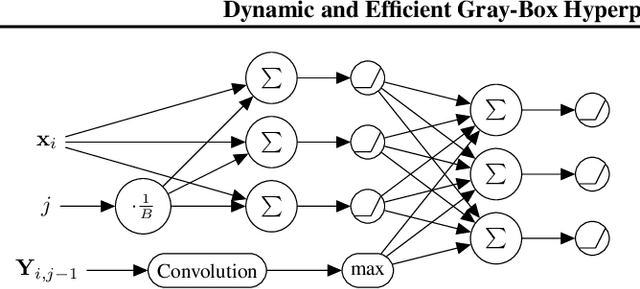
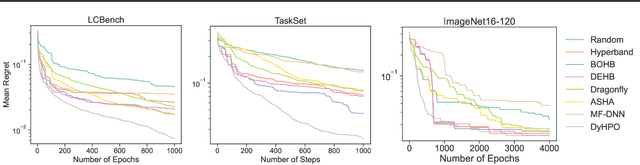
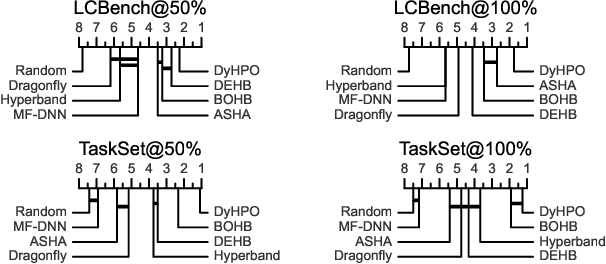
Gray-box hyperparameter optimization techniques have recently emerged as a promising direction for tuning Deep Learning methods. In this work, we introduce DyHPO, a method that learns to dynamically decide which configuration to try next, and for what budget. Our technique is a modification to the classical Bayesian optimization for a gray-box setup. Concretely, we propose a new surrogate for Gaussian Processes that embeds the learning curve dynamics and a new acquisition function that incorporates multi-budget information. We demonstrate the significant superiority of DyHPO against state-of-the-art hyperparameter optimization baselines through large-scale experiments comprising 50 datasets (Tabular, Image, NLP) and diverse neural networks (MLP, CNN/NAS, RNN).
Variable Augmented Network for Invertible MR Coil Compression
Jan 19, 2022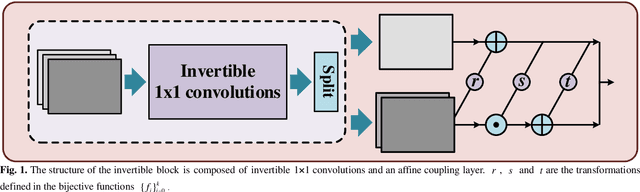
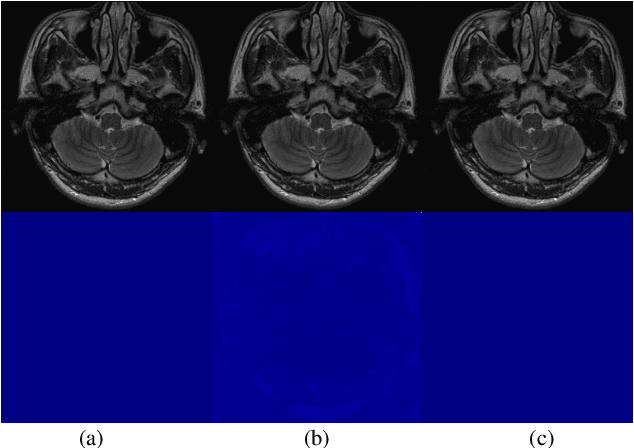
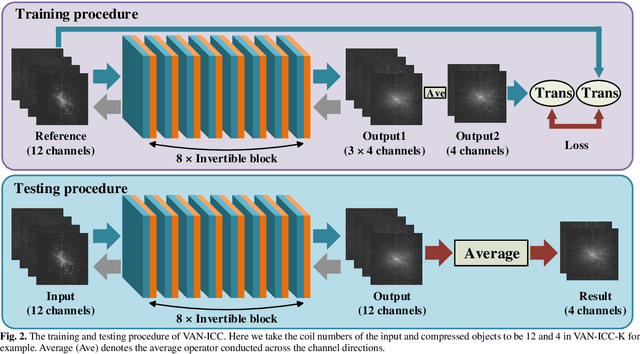
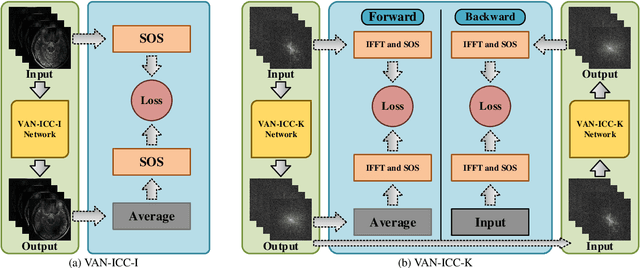
A large number of coils are able to provide enhanced signal-to-noise ratio and improve imaging performance in parallel imaging. As the increasingly grow of coil number, however, it simultaneously aggravates the drawbacks of data storage and reconstruction speed, especially in some iterative reconstructions. Coil compression addresses these issues by generating fewer virtual coils. In this work, a novel variable augmented network for invertible coil compression (VAN-ICC) is presented, which utilizes inherent reversibility of normalizing-flow-based models, for better compression and invertible recovery. VAN-ICC trains invertible network by finding an invertible and bijective function, which can map the original image to the compression image. In the experiments, both fully-sampled images and under-sampled images were used to verify the effectiveness of the model. Extensive quantitative and qualitative evaluations demonstrated that, in comparison with SCC and GCC, VAN-ICC can carry through better compression effect with equal number of virtual coils. Additionally, its performance is not susceptible to different num-ber of virtual coils.
Deep Image Blending
Oct 25, 2019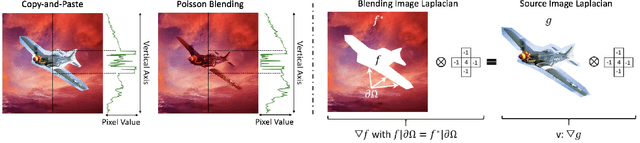
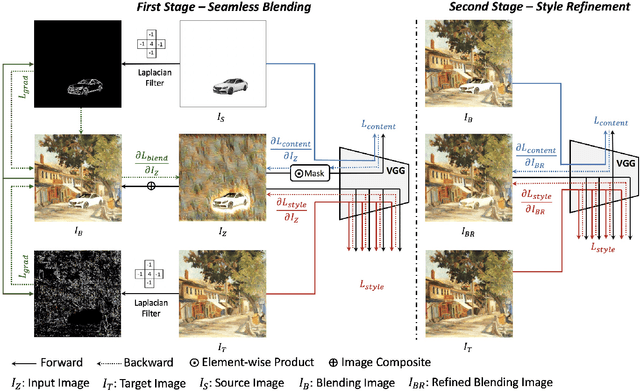


Image composition is an important operation to create visual content. Among image composition tasks, image blending aims to seamlessly blend an object from a source image onto a target image with lightly mask adjustment. A popular approach is Poisson image blending, which enforces the gradient domain smoothness in the composite image. However, this approach only considers the boundary pixels of target image, and thus can not adapt to texture of target image. In addition, the colors of the target image often seep through the original source object too much causing a significant loss of content of the source object. We propose a Poisson blending loss that achieves the same purpose of Poisson image blending. In addition, we jointly optimize the proposed Poisson blending loss as well as the style and content loss computed from a deep network, and reconstruct the blending region by iteratively updating the pixels using the L-BFGS solver. In the blending image, we not only smooth out gradient domain of the blending boundary but also add consistent texture into the blending region. User studies show that our method outperforms strong baselines as well as state-of-the-art approaches when placing objects onto both paintings and real-world images.