 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Tensor Recovery Based on Tensor Equivalent Minimax-Concave Penalty
Jan 30, 2022
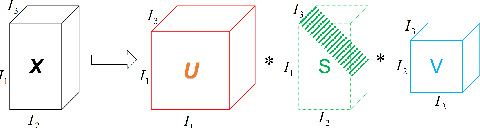

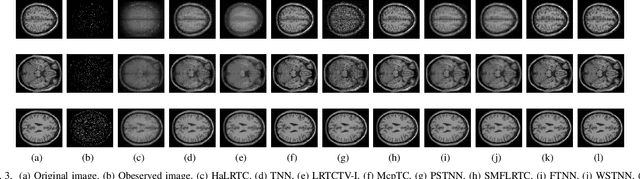

Tensor recovery is an important problem in computer vision and machine learning. It usually uses the convex relaxation of tensor rank and $l_{0}$ norm, i.e., the nuclear norm and $l_{1}$ norm respectively, to solve the problem. It is well known that convex approximations produce biased estimators. In order to overcome this problem, a corresponding non-convex regularizer has been proposed to solve it. Inspired by matrix equivalent Minimax-Concave Penalty (EMCP), we propose and prove theorems of tensor equivalent Minimax-Concave Penalty (TEMCP). The tensor equivalent MCP (TEMCP) as a non-convex regularizer and the equivalent weighted tensor $\gamma$ norm (EWTGN) which can represent the low-rank part are obtained. Both of them can realize weight adaptive. At the same time, we propose two corresponding adaptive models for two classical tensor recovery problems, low-rank tensor completion (LRTC) and tensor robust principal component analysis (TRPCA), and the optimization algorithm is based on alternating direction multiplier (ADMM). This novel iterative adaptive algorithm can produce more accurate tensor recovery effect. For the tensor completion model, multispectral image (MSI), magnetic resonance imaging (MRI) and color video (CV) data sets are considered, while for the tensor robust principal component analysis model, hyperspectral image (HSI) denoising under gaussian noise plus salt and pepper noise is considered. The proposed algorithm is superior to the state-of-arts method, and the algorithm is guaranteed to meet the reduction and convergence through experiments.
MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition
Apr 12, 2021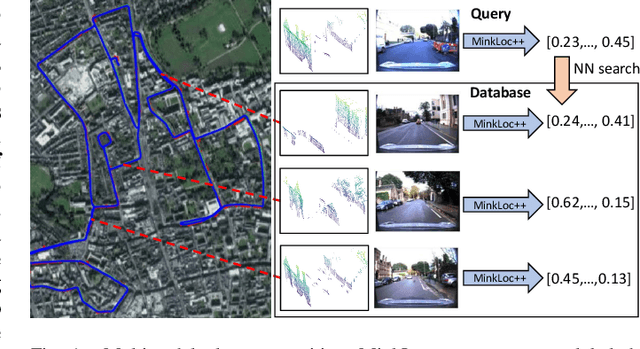
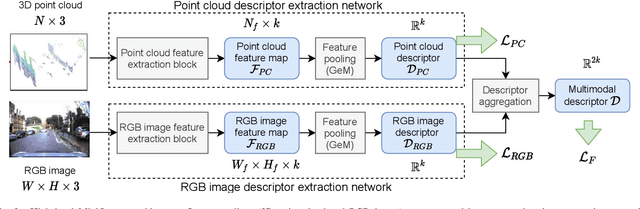
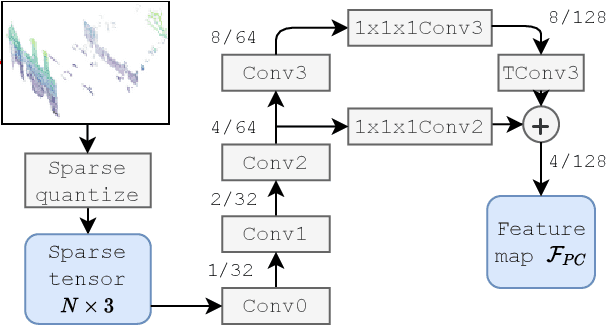

We introduce a discriminative multimodal descriptor based on a pair of sensor readings: a point cloud from a LiDAR and an image from an RGB camera. Our descriptor, named MinkLoc++, can be used for place recognition, re-localization and loop closure purposes in robotics or autonomous vehicles applications. We use late fusion approach, where each modality is processed separately and fused in the final part of the processing pipeline. The proposed method achieves state-of-the-art performance on standard place recognition benchmarks. We also identify dominating modality problem when training a multimodal descriptor. The problem manifests itself when the network focuses on a modality with a larger overfit to the training data. This drives the loss down during the training but leads to suboptimal performance on the evaluation set. In this work we describe how to detect and mitigate such risk when using a deep metric learning approach to train a multimodal neural network. Our code is publicly available on the project website: https://github.com/jac99/MinkLoc3DRGB.
Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing
Mar 11, 2022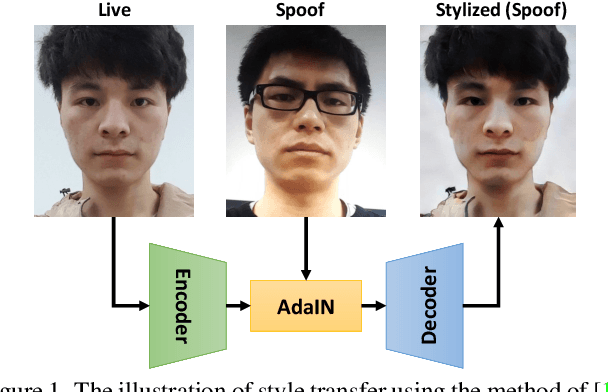
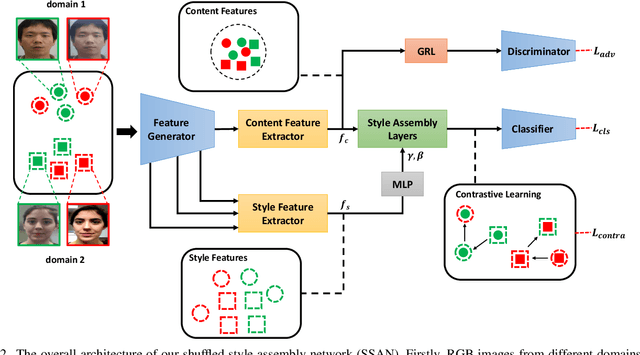
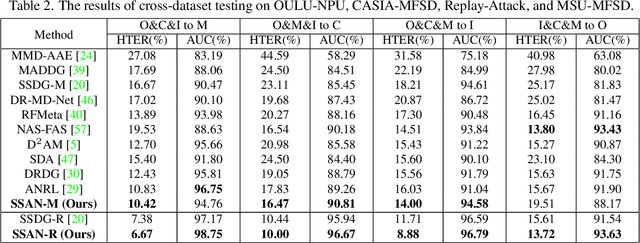
With diverse presentation attacks emerging continually, generalizable face anti-spoofing (FAS) has drawn growing attention. Most existing methods implement domain generalization (DG) on the complete representations. However, different image statistics may have unique properties for the FAS tasks. In this work, we separate the complete representation into content and style ones. A novel Shuffled Style Assembly Network (SSAN) is proposed to extract and reassemble different content and style features for a stylized feature space. Then, to obtain a generalized representation, a contrastive learning strategy is developed to emphasize liveness-related style information while suppress the domain-specific one. Finally, the representations of the correct assemblies are used to distinguish between living and spoofing during the inferring. On the other hand, despite the decent performance, there still exists a gap between academia and industry, due to the difference in data quantity and distribution. Thus, a new large-scale benchmark for FAS is built up to further evaluate the performance of algorithms in reality. Both qualitative and quantitative results on existing and proposed benchmarks demonstrate the effectiveness of our methods. The codes will be available at https://github.com/wangzhuo2019/SSAN.
VT-CLIP: Enhancing Vision-Language Models with Visual-guided Texts
Dec 04, 2021

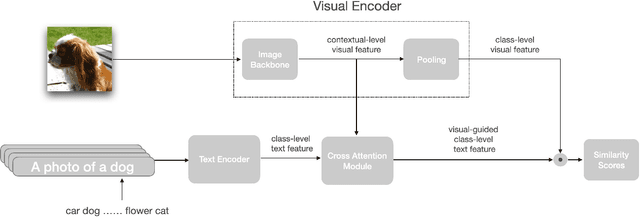
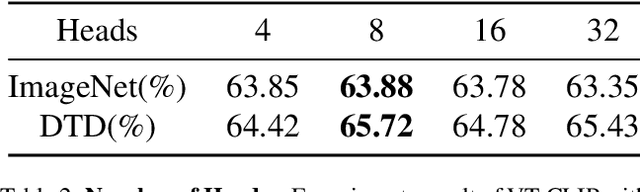
Contrastive Vision-Language Pre-training (CLIP) has drown increasing attention recently for its transferable visual representation learning. Supervised by large-scale image-text pairs, CLIP is able to align paired images and texts and thus conduct zero-shot recognition in open-vocabulary scenarios. However, there exists semantic gap between the specific application and generally pre-trained knowledge, which makes the matching sub-optimal on downstream tasks. In this paper, we propose VT-CLIP to enhance vision-language modeling via visual-guided texts. Specifically, we guide the text feature to adaptively explore informative regions on the image and aggregate the visual feature by cross-attention machanism. In this way, the visual-guided text become more semantically correlated with the image, which greatly benefits the matching process. In few-shot settings, we evaluate our VT-CLIP on 11 well-known classification datasets and experiment extensive ablation studies to demonstrate the effectiveness of VT-CLIP. The code will be released soon.
Towards performant and reliable undersampled MR reconstruction via diffusion model sampling
Mar 11, 2022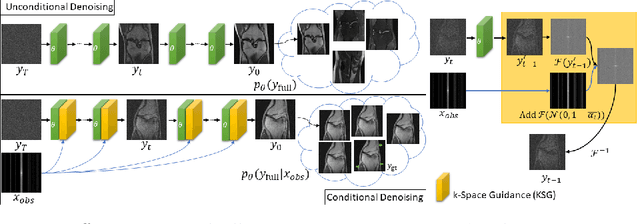
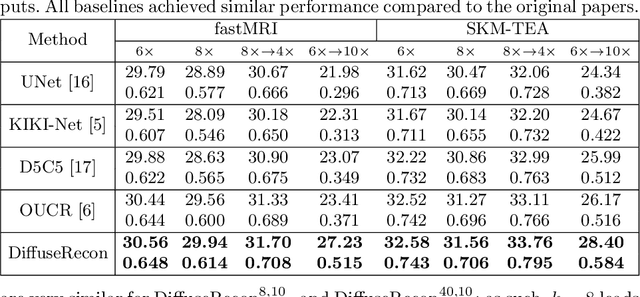
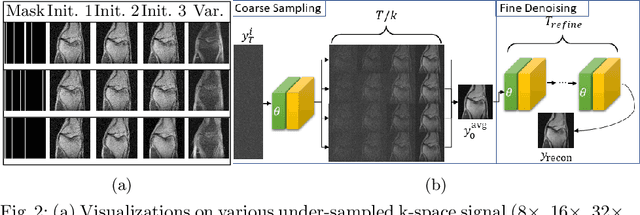
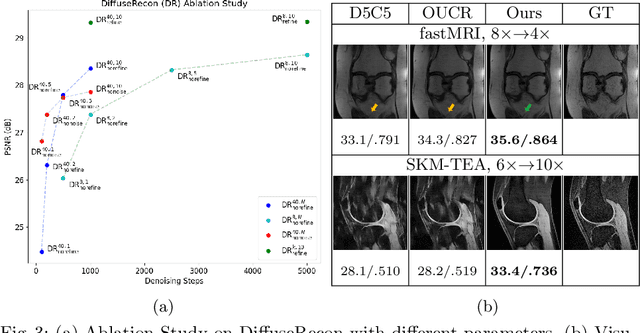
Magnetic Resonance (MR) image reconstruction from under-sampled acquisition promises faster scanning time. To this end, current State-of-The-Art (SoTA) approaches leverage deep neural networks and supervised training to learn a recovery model. While these approaches achieve impressive performances, the learned model can be fragile on unseen degradation, e.g. when given a different acceleration factor. These methods are also generally deterministic and provide a single solution to an ill-posed problem; as such, it can be difficult for practitioners to understand the reliability of the reconstruction. We introduce DiffuseRecon, a novel diffusion model-based MR reconstruction method. DiffuseRecon guides the generation process based on the observed signals and a pre-trained diffusion model, and does not require additional training on specific acceleration factors. DiffuseRecon is stochastic in nature and generates results from a distribution of fully-sampled MR images; as such, it allows us to explicitly visualize different potential reconstruction solutions. Lastly, DiffuseRecon proposes an accelerated, coarse-to-fine Monte-Carlo sampling scheme to approximate the most likely reconstruction candidate. The proposed DiffuseRecon achieves SoTA performances reconstructing from raw acquisition signals in fastMRI and SKM-TEA. Code will be open-sourced at www.github.com/cpeng93/DiffuseRecon.
6-DoF Pose Estimation of Household Objects for Robotic Manipulation: An Accessible Dataset and Benchmark
Mar 11, 2022
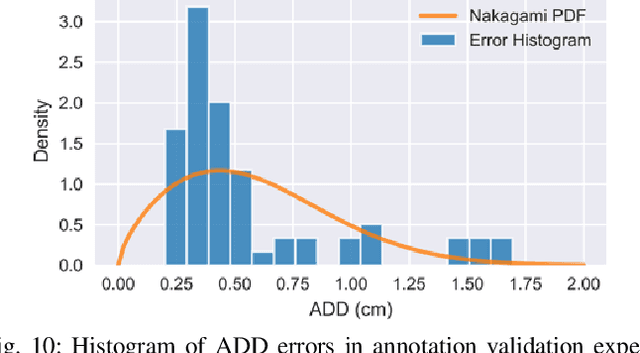
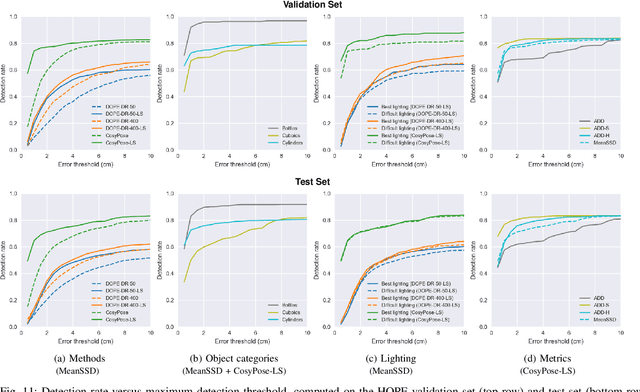
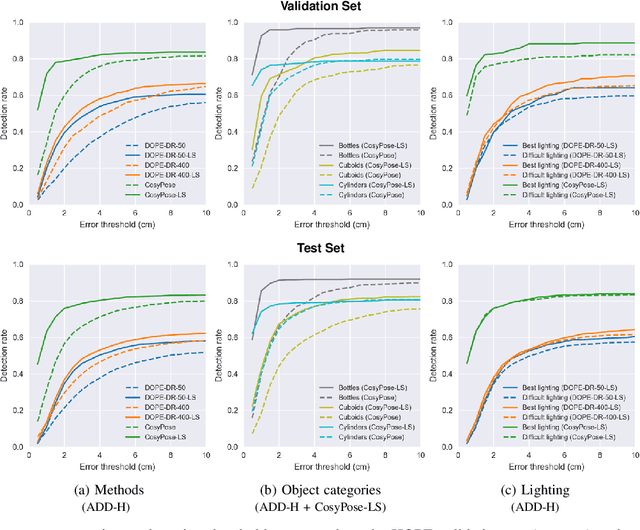
We present a new dataset for 6-DoF pose estimation of known objects, with a focus on robotic manipulation research. We propose a set of toy grocery objects, whose physical instantiations are readily available for purchase and are appropriately sized for robotic grasping and manipulation. We provide 3D scanned textured models of these objects, suitable for generating synthetic training data, as well as RGBD images of the objects in challenging, cluttered scenes exhibiting partial occlusion, extreme lighting variations, multiple instances per image, and a large variety of poses. Using semi-automated RGBD-to-model texture correspondences, the images are annotated with ground truth poses that were verified empirically to be accurate to within a few millimeters. We also propose a new pose evaluation metric called {ADD-H} based upon the Hungarian assignment algorithm that is robust to symmetries in object geometry without requiring their explicit enumeration. We share pre-trained pose estimators for all the toy grocery objects, along with their baseline performance on both validation and test sets. We offer this dataset to the community to help connect the efforts of computer vision researchers with the needs of roboticists.
Machine Learning in Magnetic Resonance Imaging: Image Reconstruction
Dec 09, 2020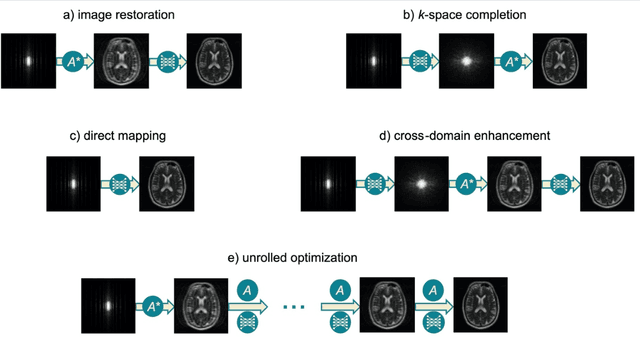
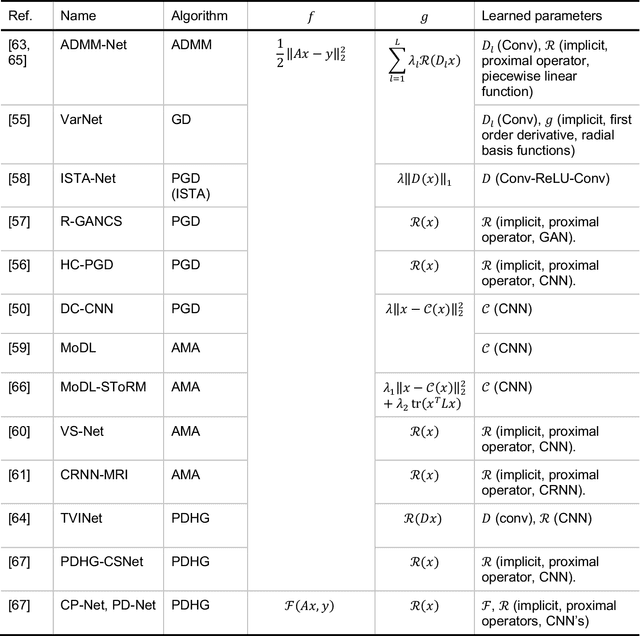
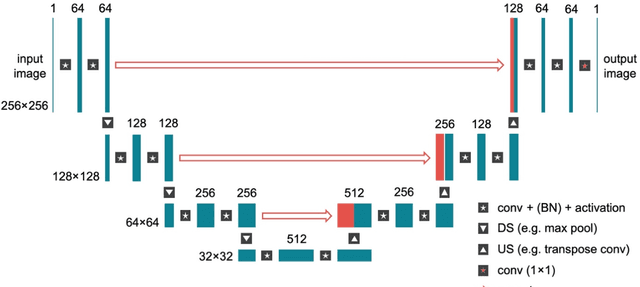
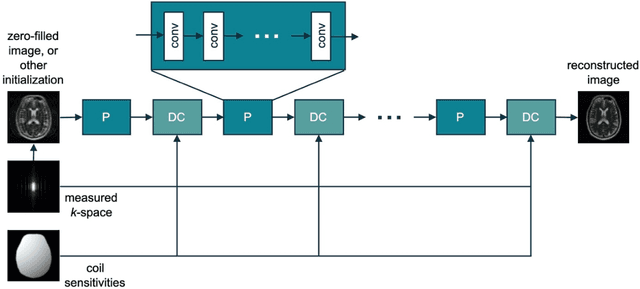
Magnetic Resonance Imaging (MRI) plays a vital role in diagnosis, management and monitoring of many diseases. However, it is an inherently slow imaging technique. Over the last 20 years, parallel imaging, temporal encoding and compressed sensing have enabled substantial speed-ups in the acquisition of MRI data, by accurately recovering missing lines of k-space data. However, clinical uptake of vastly accelerated acquisitions has been limited, in particular in compressed sensing, due to the time-consuming nature of the reconstructions and unnatural looking images. Following the success of machine learning in a wide range of imaging tasks, there has been a recent explosion in the use of machine learning in the field of MRI image reconstruction. A wide range of approaches have been proposed, which can be applied in k-space and/or image-space. Promising results have been demonstrated from a range of methods, enabling natural looking images and rapid computation. In this review article we summarize the current machine learning approaches used in MRI reconstruction, discuss their drawbacks, clinical applications, and current trends.
Invariance Learning in Deep Neural Networks with Differentiable Laplace Approximations
Feb 22, 2022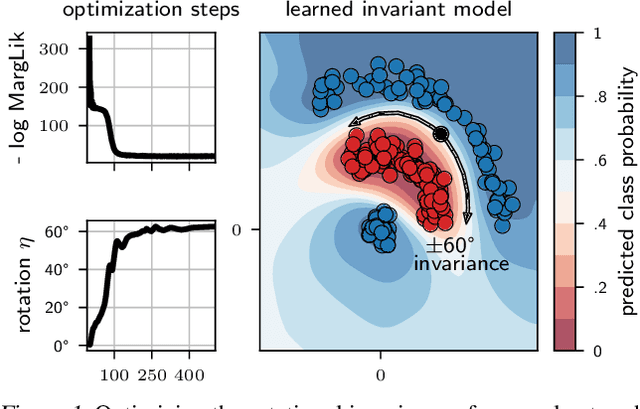
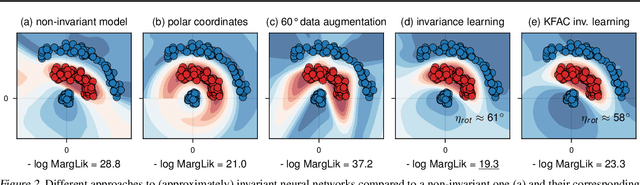

Data augmentation is commonly applied to improve performance of deep learning by enforcing the knowledge that certain transformations on the input preserve the output. Currently, the correct data augmentation is chosen by human effort and costly cross-validation, which makes it cumbersome to apply to new datasets. We develop a convenient gradient-based method for selecting the data augmentation. Our approach relies on phrasing data augmentation as an invariance in the prior distribution and learning it using Bayesian model selection, which has been shown to work in Gaussian processes, but not yet for deep neural networks. We use a differentiable Kronecker-factored Laplace approximation to the marginal likelihood as our objective, which can be optimised without human supervision or validation data. We show that our method can successfully recover invariances present in the data, and that this improves generalisation on image datasets.
One Network Doesn't Rule Them All: Moving Beyond Handcrafted Architectures in Self-Supervised Learning
Mar 15, 2022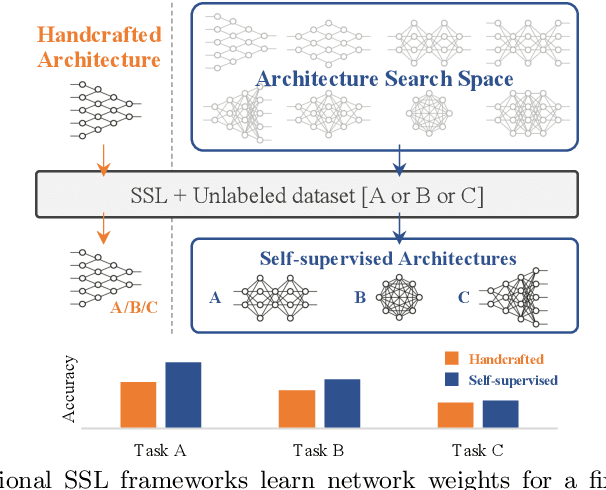
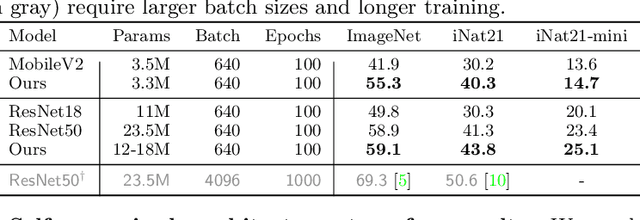
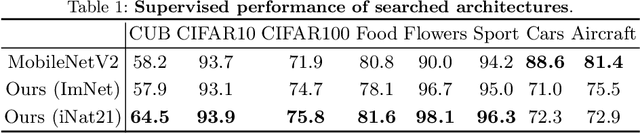
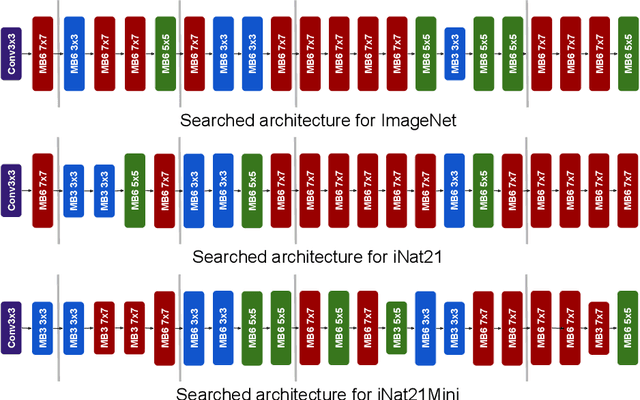
The current literature on self-supervised learning (SSL) focuses on developing learning objectives to train neural networks more effectively on unlabeled data. The typical development process involves taking well-established architectures, e.g., ResNet demonstrated on ImageNet, and using them to evaluate newly developed objectives on downstream scenarios. While convenient, this does not take into account the role of architectures which has been shown to be crucial in the supervised learning literature. In this work, we establish extensive empirical evidence showing that a network architecture plays a significant role in SSL. We conduct a large-scale study with over 100 variants of ResNet and MobileNet architectures and evaluate them across 11 downstream scenarios in the SSL setting. We show that there is no one network that performs consistently well across the scenarios. Based on this, we propose to learn not only network weights but also architecture topologies in the SSL regime. We show that "self-supervised architectures" outperform popular handcrafted architectures (ResNet18 and MobileNetV2) while performing competitively with the larger and computationally heavy ResNet50 on major image classification benchmarks (ImageNet-1K, iNat2021, and more). Our results suggest that it is time to consider moving beyond handcrafted architectures in SSL and start thinking about incorporating architecture search into self-supervised learning objectives.
MeshLeTemp: Leveraging the Learnable Vertex-Vertex Relationship to Generalize Human Pose and Mesh Reconstruction for In-the-Wild Scenes
Feb 15, 2022
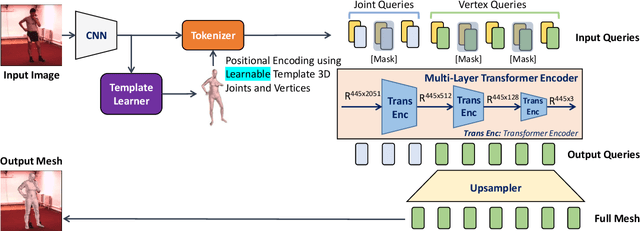
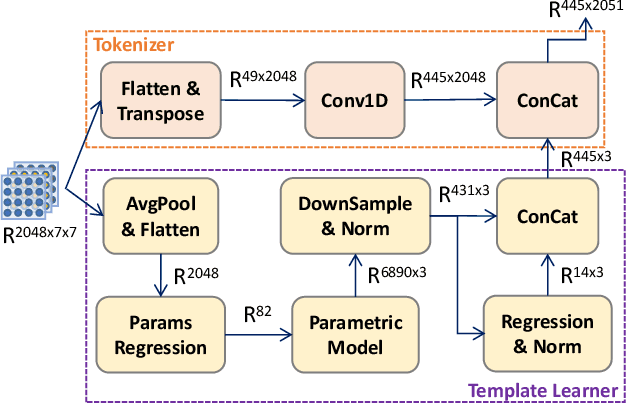

We present MeshLeTemp, a powerful method for 3D human pose and mesh reconstruction from a single image. In terms of human body priors encoding, we propose using a learnable template human mesh instead of a constant template utilized by previous state-of-the-art methods. The proposed learnable template reflects not only vertex-vertex interactions but also the human pose and body shape, being able to adapt to diverse images. We also introduce a strategy to enrich the training data that contains both 2D and 3D annotations. We conduct extensive experiments to show the generalizability of our method and the effectiveness of our data strategy. As one of our ablation studies, we adapt MeshLeTemp to another domain which is 3D hand reconstruction.