 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Empirical Investigation of 3D Anomaly Detection and Segmentation
Mar 10, 2022
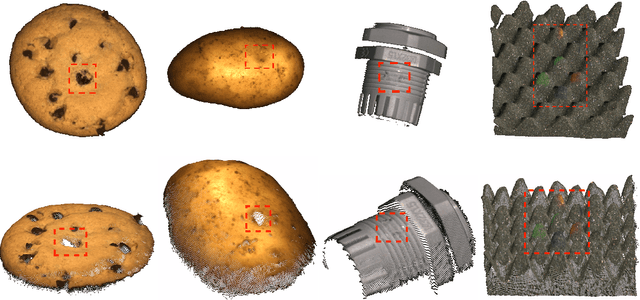

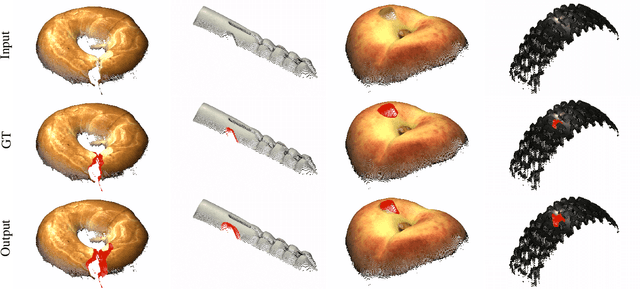
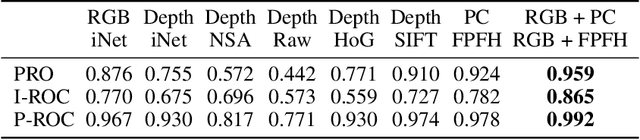
Anomaly detection and segmentation in images has made tremendous progress in recent years while 3D information has often been ignored. The objective of this paper is to further understand the benefit and role of 3D as opposed to color in image anomaly detection. Our study begins by presenting a surprising finding: standard color-only anomaly segmentation methods, when applied to 3D datasets, significantly outperform all current methods. On the other hand, we observe that color-only methods are insufficient for images containing geometric anomalies where shape cannot be unambiguously inferred from 2D. This suggests that better 3D methods are needed. We investigate different representations for 3D anomaly detection and discover that handcrafted orientation-invariant representations are unreasonably effective on this task. We uncover a simple 3D-only method that outperforms all recent approaches while not using deep learning, external pretraining datasets, or color information. As the 3D-only method cannot detect color and texture anomalies, we combine it with 2D color features, granting us the best current results by a large margin (Pixel-wise ROCAUC: 99.2%, PRO: 95.9% on MVTec 3D-AD). We conclude by discussing future challenges for 3D anomaly detection and segmentation.
GANHopper: Multi-Hop GAN for Unsupervised Image-to-Image Translation
Feb 24, 2020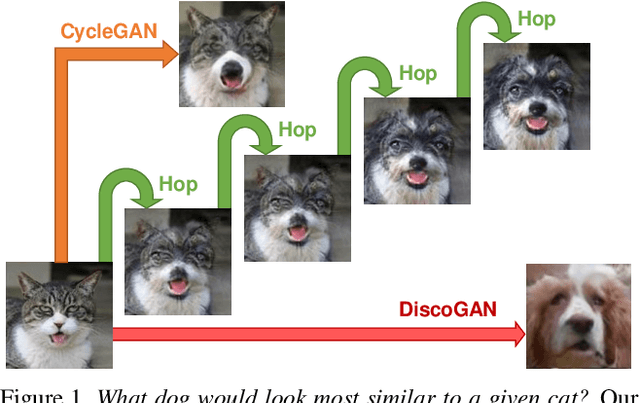
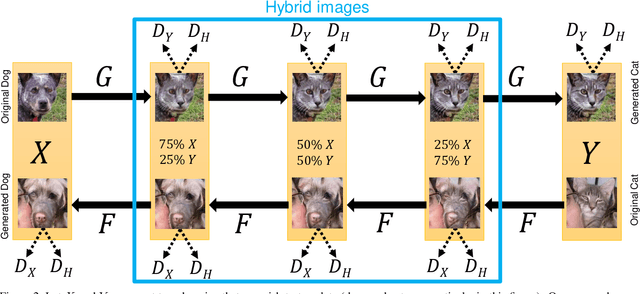
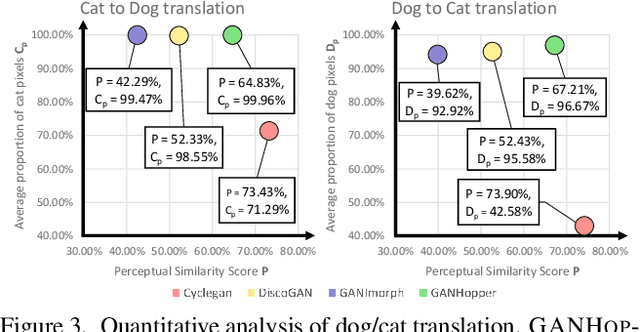
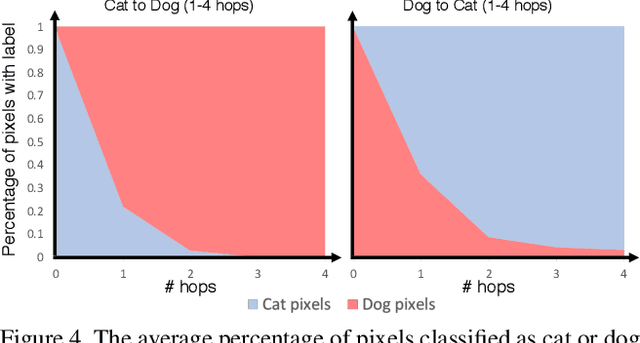
We introduce GANHOPPER, an unsupervised image-to-image translation network that transforms images gradually between two domains, through multiple hops. Instead of executing translation directly, we steer the translation by requiring the network to produce in-between images which resemble weighted hybrids between images from the two in-put domains. Our network is trained on unpaired images from the two domains only, without any in-between images.All hops are produced using a single generator along each direction. In addition to the standard cycle-consistency and adversarial losses, we introduce a new hybrid discrimina-tor, which is trained to classify the intermediate images produced by the generator as weighted hybrids, with weights based on a predetermined hop count. We also introduce a smoothness term to constrain the magnitude of each hop,further regularizing the translation. Compared to previous methods, GANHOPPER excels at image translations involving domain-specific image features and geometric variations while also preserving non-domain-specific features such as backgrounds and general color schemes.
Sphere2Vec: Multi-Scale Representation Learning over a Spherical Surface for Geospatial Predictions
Jan 25, 2022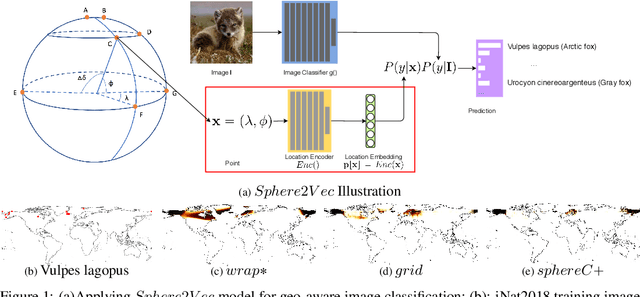
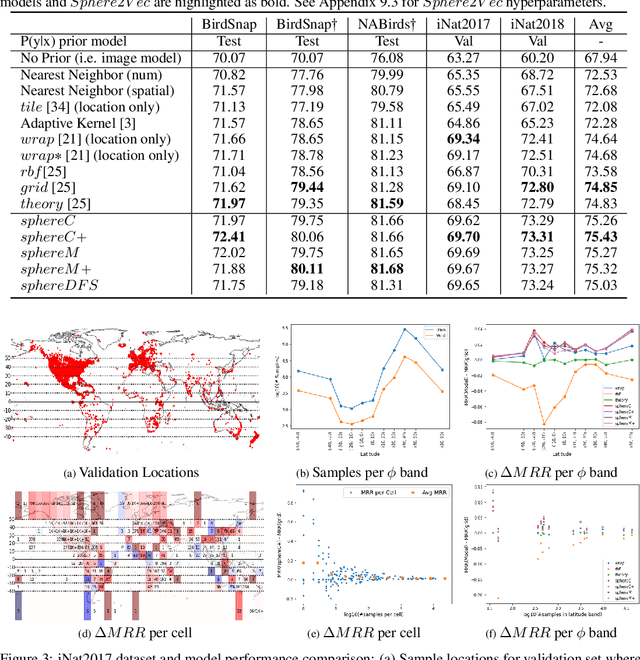

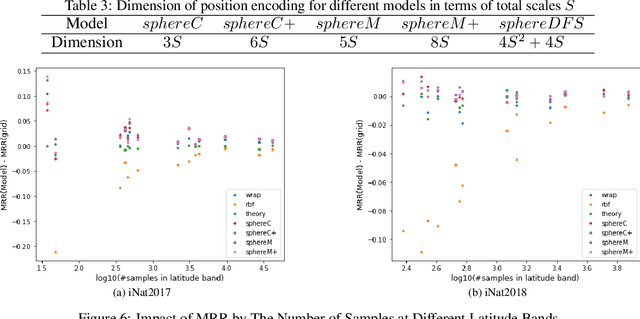
Generating learning-friendly representations for points in a 2D space is a fundamental and long-standing problem in machine learning. Recently, multi-scale encoding schemes (such as Space2Vec) were proposed to directly encode any point in 2D space as a high-dimensional vector, and has been successfully applied to various (geo)spatial prediction tasks. However, a map projection distortion problem rises when applying location encoding models to large-scale real-world GPS coordinate datasets (e.g., species images taken all over the world) - all current location encoding models are designed for encoding points in a 2D (Euclidean) space but not on a spherical surface, e.g., earth surface. To solve this problem, we propose a multi-scale location encoding model called Sphere2V ec which directly encodes point coordinates on a spherical surface while avoiding the mapprojection distortion problem. We provide theoretical proof that the Sphere2Vec encoding preserves the spherical surface distance between any two points. We also developed a unified view of distance-reserving encoding on spheres based on the Double Fourier Sphere (DFS). We apply Sphere2V ec to the geo-aware image classification task. Our analysis shows that Sphere2V ec outperforms other 2D space location encoder models especially on the polar regions and data-sparse areas for image classification tasks because of its nature for spherical surface distance preservation.
Seamless Copy Move Manipulation in Digital Images
Oct 12, 2021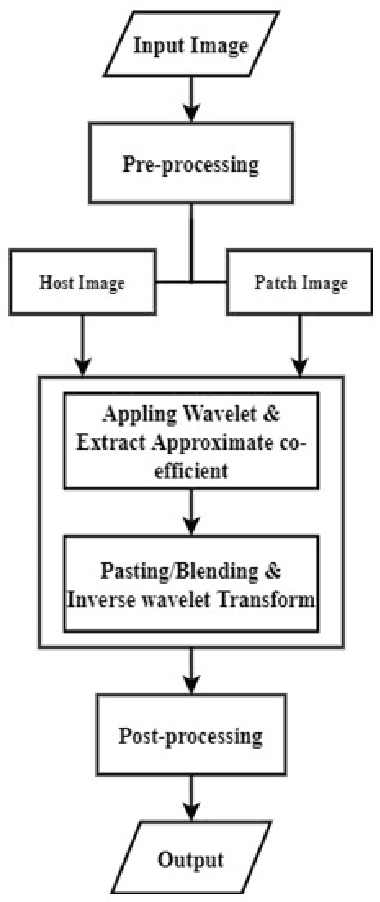
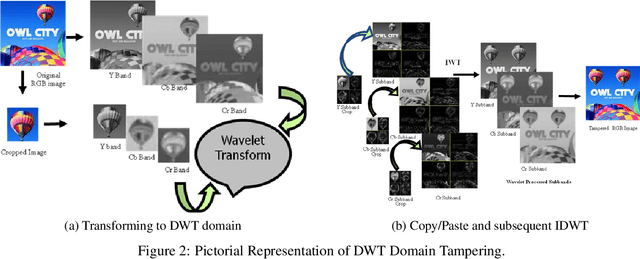


The importance and relevance of digital image forensics has attracted researchers to establish different techniques for creating as well as detecting forgeries. The core category in passive image forgery is copy-move image forgery that affects the originality of image by applying a different transformation. In this paper frequency domain image manipulation method is being presented.The method exploits the localized nature of discrete wavelet transform (DWT) to get hold of the region of the host image to be manipulated. Both the patch and host image are subjected to DWT at the same level $l$ to get $3l + 1$ sub-bands and each sub-band of the patch is pasted to the identified region in the corresponding sub-band of the host image. The resultant manipulated host sub-bands are then subjected to inverse DWT to get the final manipulated host image. The proposed method shows good resistance against detection by two frequency domain forgery detection methods from the literature. The purpose of this research work is to create the forgery and highlight the need to produce forgery detection methods that are robust against the malicious copy-move forgery.
Tensor Recovery Based on Tensor Equivalent Minimax-Concave Penalty
Jan 30, 2022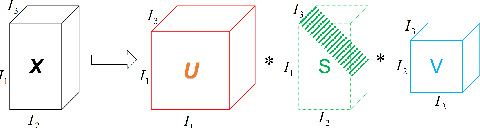

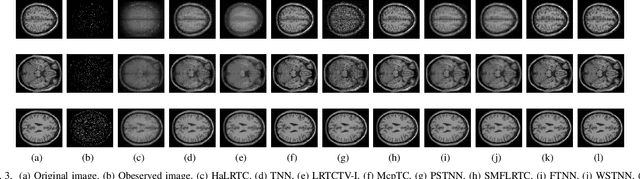

Tensor recovery is an important problem in computer vision and machine learning. It usually uses the convex relaxation of tensor rank and $l_{0}$ norm, i.e., the nuclear norm and $l_{1}$ norm respectively, to solve the problem. It is well known that convex approximations produce biased estimators. In order to overcome this problem, a corresponding non-convex regularizer has been proposed to solve it. Inspired by matrix equivalent Minimax-Concave Penalty (EMCP), we propose and prove theorems of tensor equivalent Minimax-Concave Penalty (TEMCP). The tensor equivalent MCP (TEMCP) as a non-convex regularizer and the equivalent weighted tensor $\gamma$ norm (EWTGN) which can represent the low-rank part are obtained. Both of them can realize weight adaptive. At the same time, we propose two corresponding adaptive models for two classical tensor recovery problems, low-rank tensor completion (LRTC) and tensor robust principal component analysis (TRPCA), and the optimization algorithm is based on alternating direction multiplier (ADMM). This novel iterative adaptive algorithm can produce more accurate tensor recovery effect. For the tensor completion model, multispectral image (MSI), magnetic resonance imaging (MRI) and color video (CV) data sets are considered, while for the tensor robust principal component analysis model, hyperspectral image (HSI) denoising under gaussian noise plus salt and pepper noise is considered. The proposed algorithm is superior to the state-of-arts method, and the algorithm is guaranteed to meet the reduction and convergence through experiments.
Image Retrieval for Structure-from-Motion via Graph Convolutional Network
Sep 17, 2020
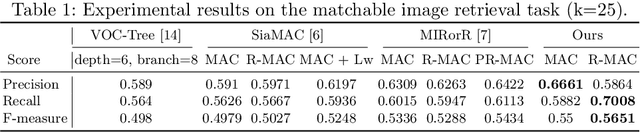

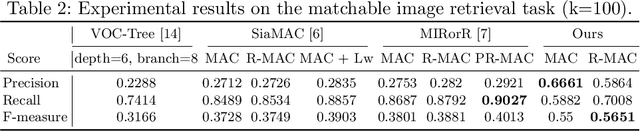
Conventional image retrieval techniques for Structure-from-Motion (SfM) suffer from the limit of effectively recognizing repetitive patterns and cannot guarantee to create just enough match pairs with high precision and high recall. In this paper, we present a novel retrieval method based on Graph Convolutional Network (GCN) to generate accurate pairwise matches without costly redundancy. We formulate image retrieval task as a node binary classification problem in graph data: a node is marked as positive if it shares the scene overlaps with the query image. The key idea is that we find that the local context in feature space around a query image contains rich information about the matchable relation between this image and its neighbors. By constructing a subgraph surrounding the query image as input data, we adopt a learnable GCN to exploit whether nodes in the subgraph have overlapping regions with the query photograph. Experiments demonstrate that our method performs remarkably well on the challenging dataset of highly ambiguous and duplicated scenes. Besides, compared with state-of-the-art matchable retrieval methods, the proposed approach significantly reduces useless attempted matches without sacrificing the accuracy and completeness of reconstruction.
MeshLeTemp: Leveraging the Learnable Vertex-Vertex Relationship to Generalize Human Pose and Mesh Reconstruction for In-the-Wild Scenes
Feb 15, 2022
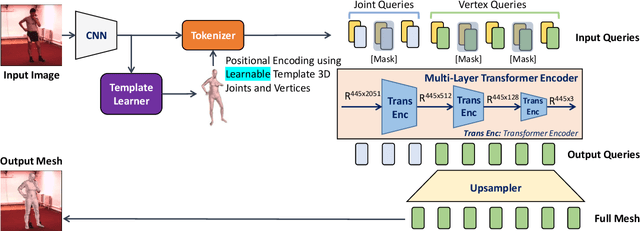
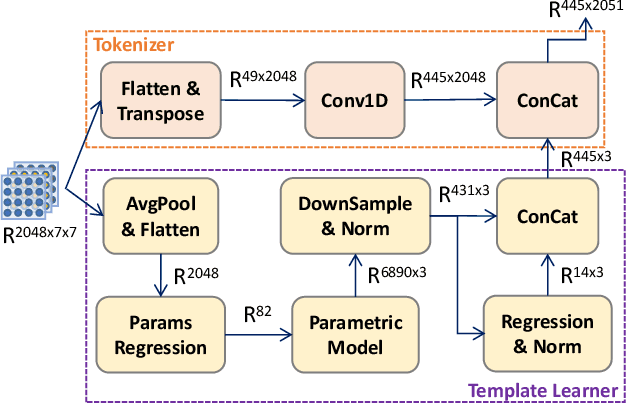

We present MeshLeTemp, a powerful method for 3D human pose and mesh reconstruction from a single image. In terms of human body priors encoding, we propose using a learnable template human mesh instead of a constant template utilized by previous state-of-the-art methods. The proposed learnable template reflects not only vertex-vertex interactions but also the human pose and body shape, being able to adapt to diverse images. We also introduce a strategy to enrich the training data that contains both 2D and 3D annotations. We conduct extensive experiments to show the generalizability of our method and the effectiveness of our data strategy. As one of our ablation studies, we adapt MeshLeTemp to another domain which is 3D hand reconstruction.
MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition
Apr 14, 2021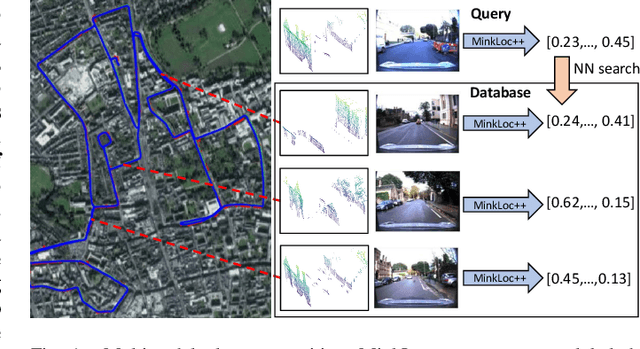
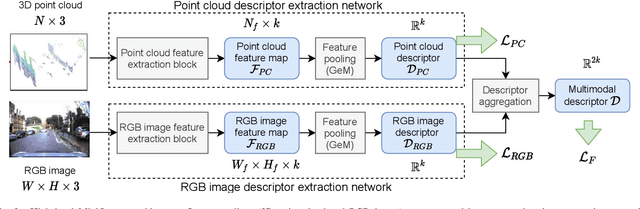
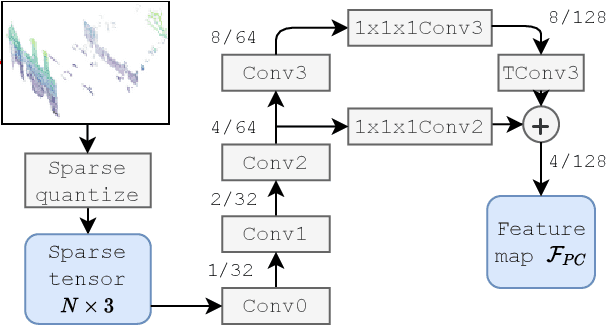

We introduce a discriminative multimodal descriptor based on a pair of sensor readings: a point cloud from a LiDAR and an image from an RGB camera. Our descriptor, named MinkLoc++, can be used for place recognition, re-localization and loop closure purposes in robotics or autonomous vehicles applications. We use late fusion approach, where each modality is processed separately and fused in the final part of the processing pipeline. The proposed method achieves state-of-the-art performance on standard place recognition benchmarks. We also identify dominating modality problem when training a multimodal descriptor. The problem manifests itself when the network focuses on a modality with a larger overfit to the training data. This drives the loss down during the training but leads to suboptimal performance on the evaluation set. In this work we describe how to detect and mitigate such risk when using a deep metric learning approach to train a multimodal neural network. Our code is publicly available on the project website: https://github.com/jac99/MinkLocMultimodal.
Attention Cube Network for Image Restoration
Sep 15, 2020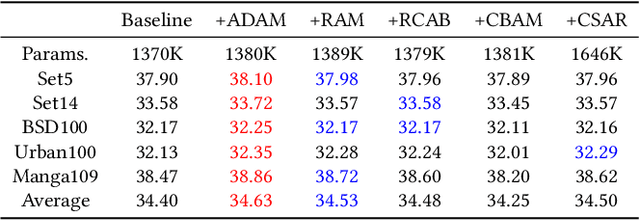
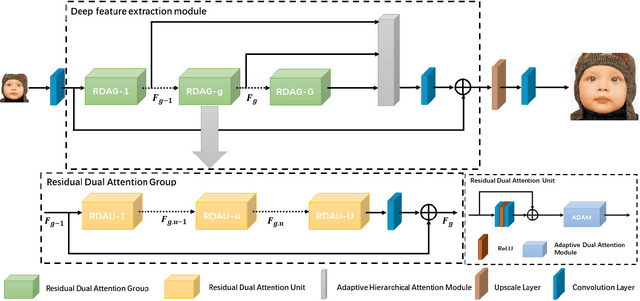
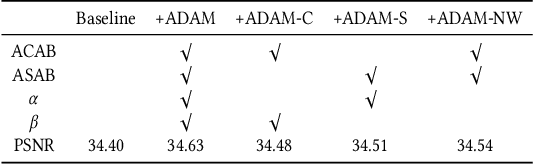
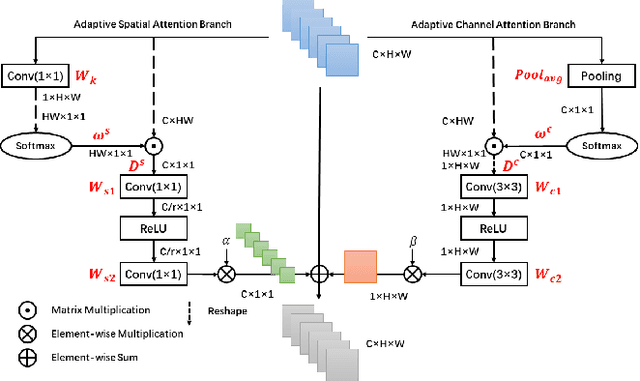
Recently, deep convolutional neural network (CNN) have been widely used in image restoration and obtained great success. However, most of existing methods are limited to local receptive field and equal treatment of different types of information. Besides, existing methods always use a multi-supervised method to aggregate different feature maps, which can not effectively aggregate hierarchical feature information. To address these issues, we propose an attention cube network (A-CubeNet) for image restoration for more powerful feature expression and feature correlation learning. Specifically, we design a novel attention mechanism from three dimensions, namely spatial dimension, channel-wise dimension and hierarchical dimension. The adaptive spatial attention branch (ASAB) and the adaptive channel attention branch (ACAB) constitute the adaptive dual attention module (ADAM), which can capture the long-range spatial and channel-wise contextual information to expand the receptive field and distinguish different types of information for more effective feature representations. Furthermore, the adaptive hierarchical attention module (AHAM) can capture the long-range hierarchical contextual information to flexibly aggregate different feature maps by weights depending on the global context. The ADAM and AHAM cooperate to form an "attention in attention" structure, which means AHAM's inputs are enhanced by ASAB and ACAB. Experiments demonstrate the superiority of our method over state-of-the-art image restoration methods in both quantitative comparison and visual analysis.
Application of DatasetGAN in medical imaging: preliminary studies
Feb 27, 2022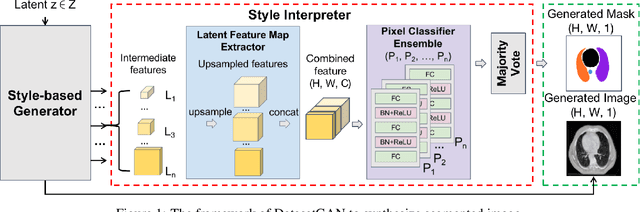

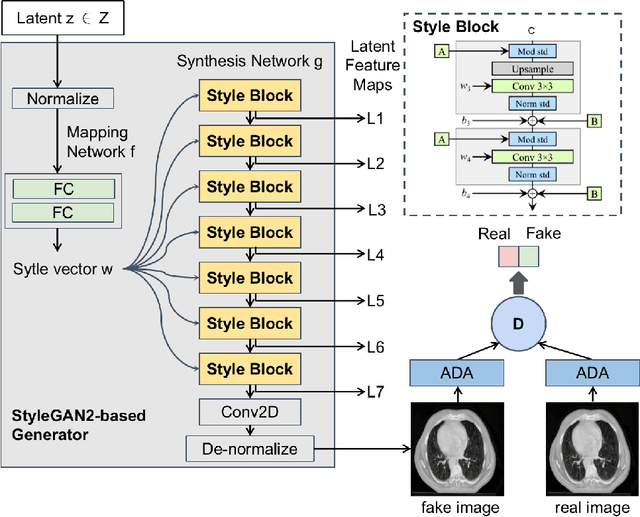

Generative adversarial networks (GANs) have been widely investigated for many potential applications in medical imaging. DatasetGAN is a recently proposed framework based on modern GANs that can synthesize high-quality segmented images while requiring only a small set of annotated training images. The synthesized annotated images could be potentially employed for many medical imaging applications, where images with segmentation information are required. However, to the best of our knowledge, there are no published studies focusing on its applications to medical imaging. In this work, preliminary studies were conducted to investigate the utility of DatasetGAN in medical imaging. Three improvements were proposed to the original DatasetGAN framework, considering the unique characteristics of medical images. The synthesized segmented images by DatasetGAN were visually evaluated. The trained DatasetGAN was further analyzed by evaluating the performance of a pre-defined image segmentation technique, which was trained by the use of the synthesized datasets. The effectiveness, concerns, and potential usage of DatasetGAN were discussed.