 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bag of Visual Words (BoVW) with Deep Features -- Patch Classification Model for Limited Dataset of Breast Tumours
Feb 22, 2022
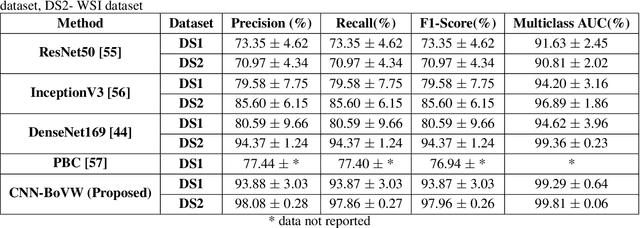
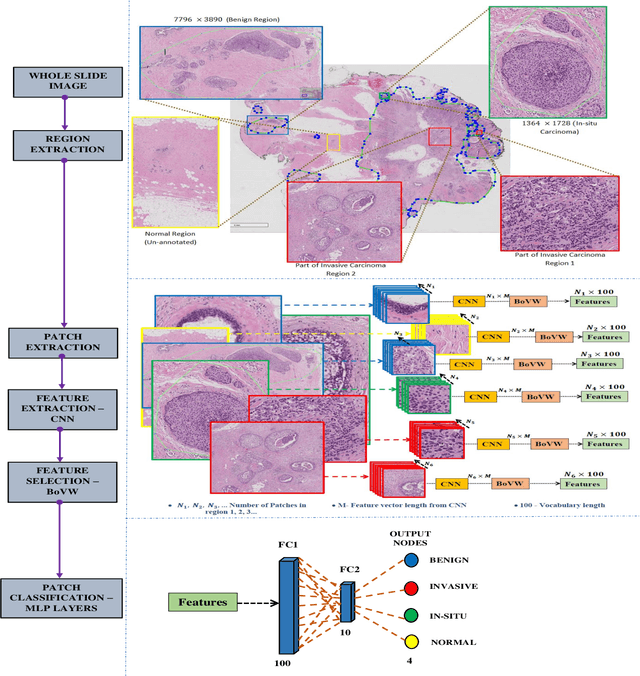
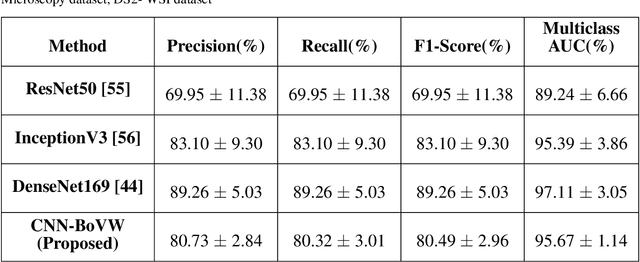
Currently, the computational complexity limits the training of high resolution gigapixel images using Convolutional Neural Networks. Therefore, such images are divided into patches or tiles. Since, these high resolution patches are encoded with discriminative information therefore; CNNs are trained on these patches to perform patch-level predictions. However, the problem with patch-level prediction is that pathologist generally annotates at image-level and not at patch level. Due to this limitation most of the patches may not contain enough class-relevant features. Through this work, we tried to incorporate patch descriptive capability within the deep framework by using Bag of Visual Words (BoVW) as a kind of regularisation to improve generalizability. Using this hypothesis, we aim to build a patch based classifier to discriminate between four classes of breast biopsy image patches (normal, benign, \textit{In situ} carcinoma, invasive carcinoma). The task is to incorporate quality deep features using CNN to describe relevant information in the images while simultaneously discarding irrelevant information using Bag of Visual Words (BoVW). The proposed method passes patches obtained from WSI and microscopy images through pre-trained CNN to extract features. BoVW is used as a feature selector to select most discriminative features among the CNN features. Finally, the selected feature sets are classified as one of the four classes. The hybrid model provides flexibility in terms of choice of pre-trained models for feature extraction. The pipeline is end-to-end since it does not require post processing of patch predictions to select discriminative patches. We compared our observations with state-of-the-art methods like ResNet50, DenseNet169, and InceptionV3 on the BACH-2018 challenge dataset. Our proposed method shows better performance than all the three methods.
Deep Reference Priors: What is the best way to pretrain a model?
Feb 01, 2022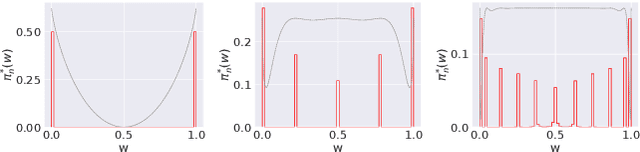
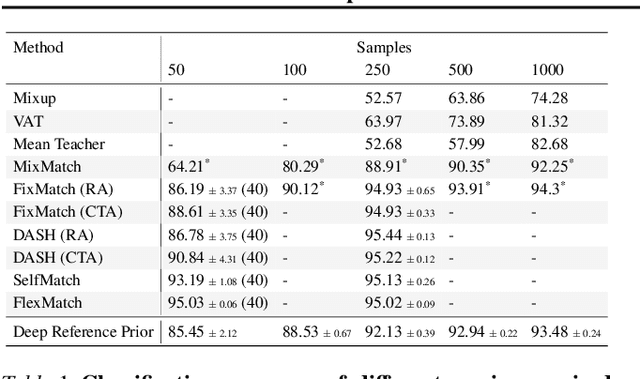
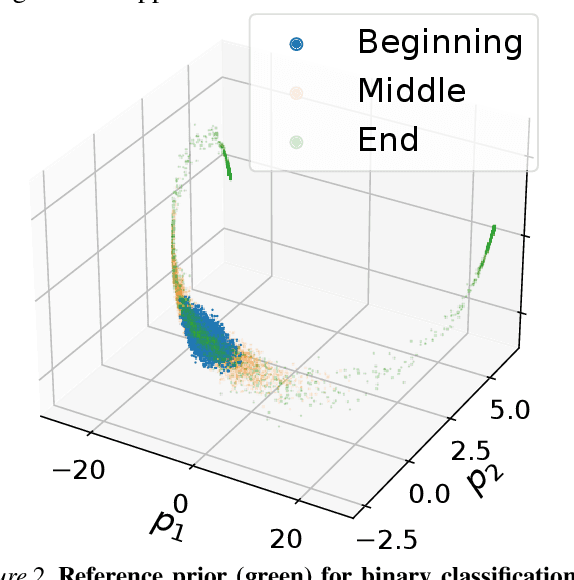
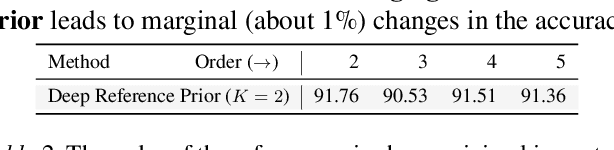
What is the best way to exploit extra data -- be it unlabeled data from the same task, or labeled data from a related task -- to learn a given task? This paper formalizes the question using the theory of reference priors. Reference priors are objective, uninformative Bayesian priors that maximize the mutual information between the task and the weights of the model. Such priors enable the task to maximally affect the Bayesian posterior, e.g., reference priors depend upon the number of samples available for learning the task and for very small sample sizes, the prior puts more probability mass on low-complexity models in the hypothesis space. This paper presents the first demonstration of reference priors for medium-scale deep networks and image-based data. We develop generalizations of reference priors and demonstrate applications to two problems. First, by using unlabeled data to compute the reference prior, we develop new Bayesian semi-supervised learning methods that remain effective even with very few samples per class. Second, by using labeled data from the source task to compute the reference prior, we develop a new pretraining method for transfer learning that allows data from the target task to maximally affect the Bayesian posterior. Empirical validation of these methods is conducted on image classification datasets.
Ten years of image analysis and machine learning competitions in dementia
Dec 15, 2021
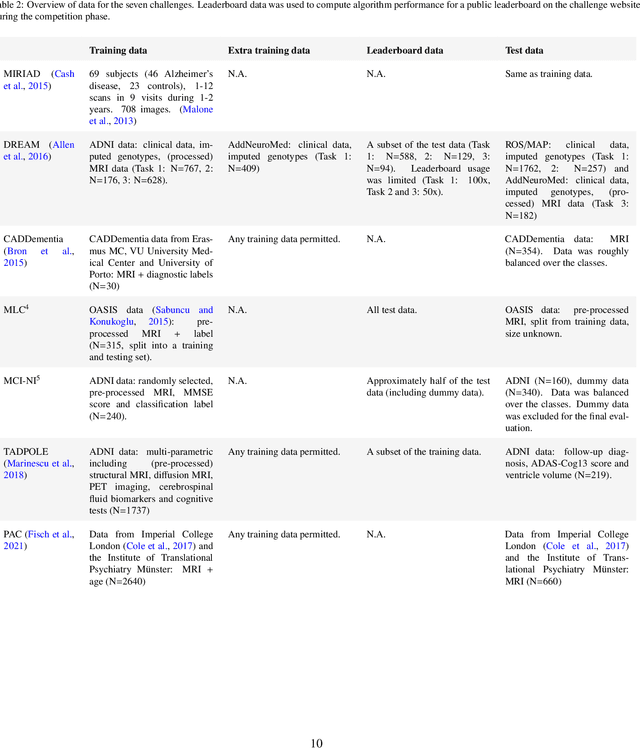
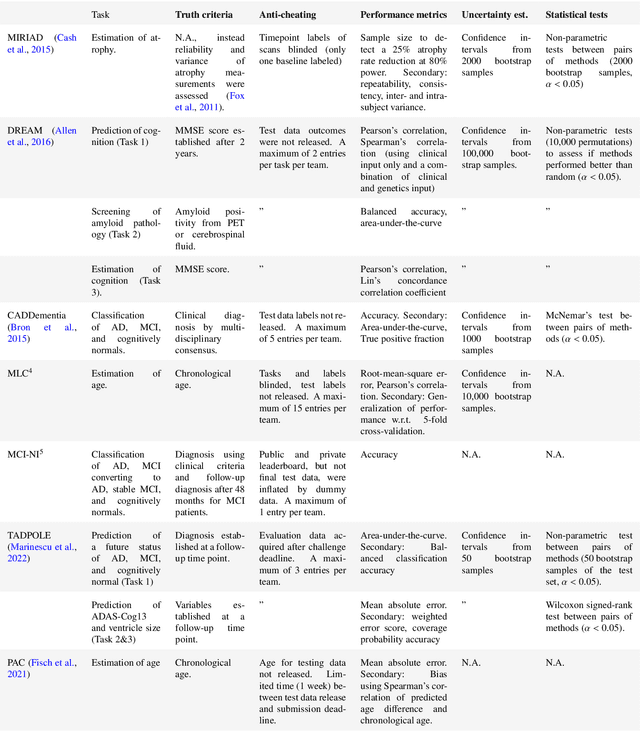
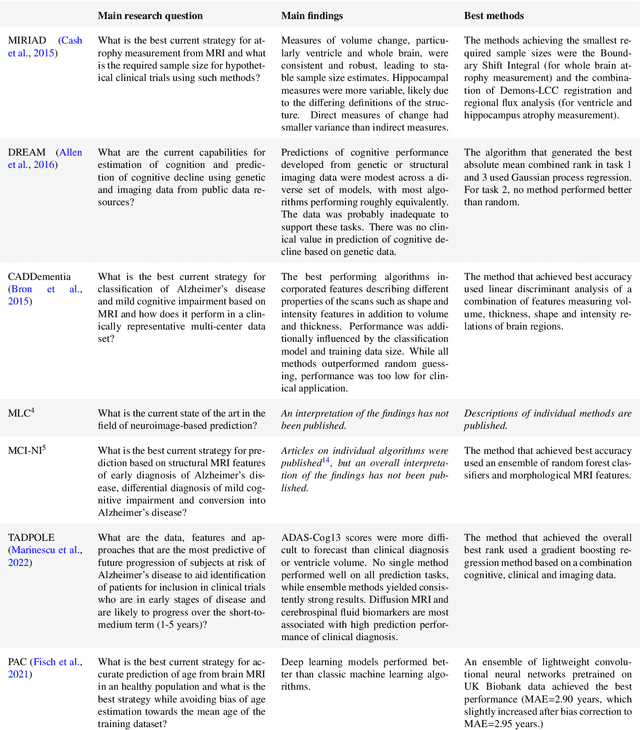
Machine learning methods exploiting multi-parametric biomarkers, especially based on neuroimaging, have huge potential to improve early diagnosis of dementia and to predict which individuals are at-risk of developing dementia. To benchmark algorithms in the field of machine learning and neuroimaging in dementia and assess their potential for use in clinical practice and clinical trials, seven grand challenges have been organized in the last decade: MIRIAD, Alzheimer's Disease Big Data DREAM, CADDementia, Machine Learning Challenge, MCI Neuroimaging, TADPOLE, and the Predictive Analytics Competition. Based on two challenge evaluation frameworks, we analyzed how these grand challenges are complementing each other regarding research questions, datasets, validation approaches, results and impact. The seven grand challenges addressed questions related to screening, diagnosis, prediction and monitoring in (pre-clinical) dementia. There was little overlap in clinical questions, tasks and performance metrics. Whereas this has the advantage of providing insight on a broad range of questions, it also limits the validation of results across challenges. In general, winning algorithms performed rigorous data pre-processing and combined a wide range of input features. Despite high state-of-the-art performances, most of the methods evaluated by the challenges are not clinically used. To increase impact, future challenges could pay more attention to statistical analysis of which factors (i.e., features, models) relate to higher performance, to clinical questions beyond Alzheimer's disease, and to using testing data beyond the Alzheimer's Disease Neuroimaging Initiative. Given the potential and lessons learned in the past ten years, we are excited by the prospects of grand challenges in machine learning and neuroimaging for the next ten years and beyond.
WSSS4LUAD: Grand Challenge on Weakly-supervised Tissue Semantic Segmentation for Lung Adenocarcinoma
Apr 13, 2022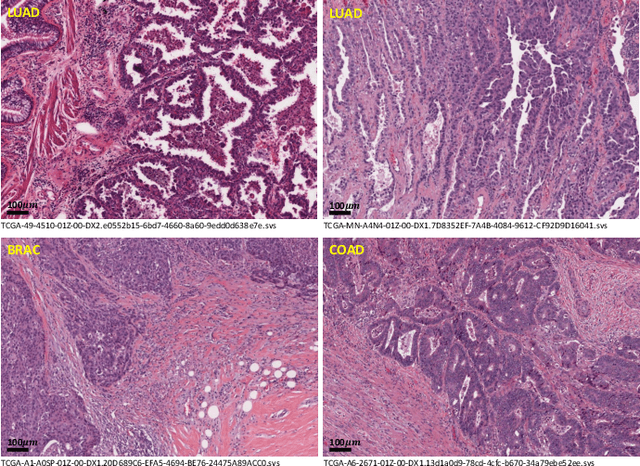
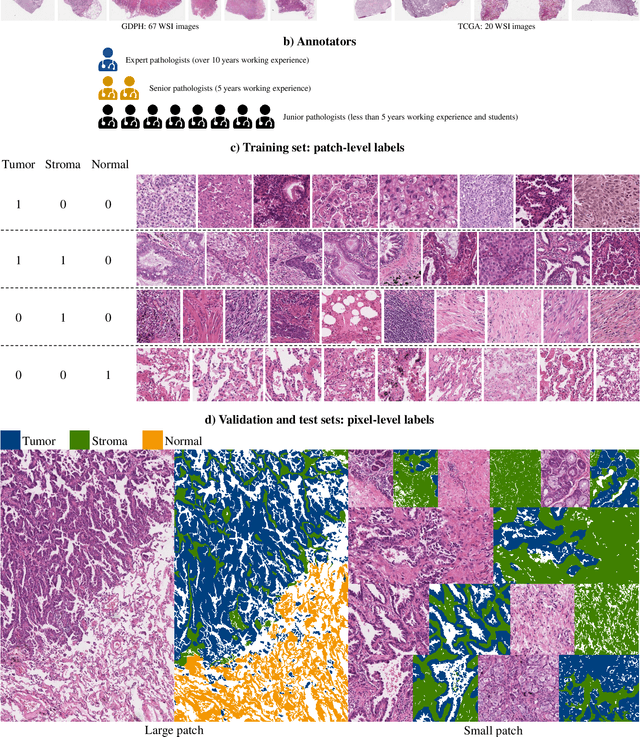
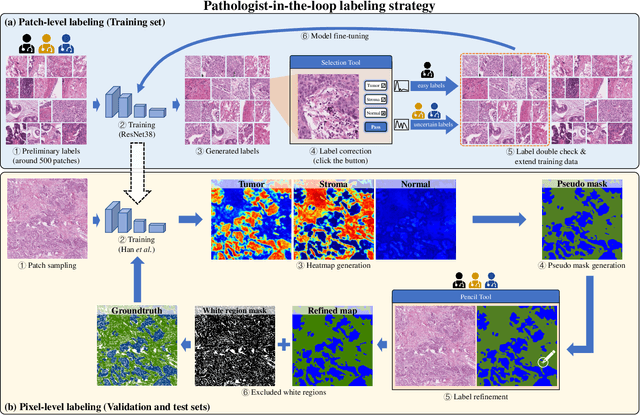
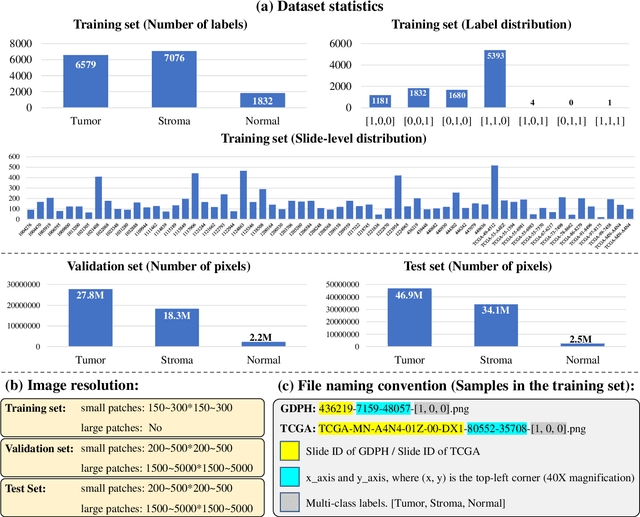
Lung cancer is the leading cause of cancer death worldwide, and adenocarcinoma (LUAD) is the most common subtype. Exploiting the potential value of the histopathology images can promote precision medicine in oncology. Tissue segmentation is the basic upstream task of histopathology image analysis. Existing deep learning models have achieved superior segmentation performance but require sufficient pixel-level annotations, which is time-consuming and expensive. To enrich the label resources of LUAD and to alleviate the annotation efforts, we organize this challenge WSSS4LUAD to call for the outstanding weakly-supervised semantic segmentation techniques for histopathology images of LUAD. Participants have to design the algorithm to segment tumor epithelial, tumor-associated stroma and normal tissue with only patch-level labels. This challenge includes 10,091 patch-level annotations (the training set) and over 130 million labeled pixels (the validation and test sets), from 67 WSIs (47 from GDPH, 20 from TCGA). All the labels were generated by a pathologist-in-the-loop pipeline with the help of AI models and checked by the label review board. Among 532 registrations, 28 teams submitted the results in the test phase with over 1,000 submissions. Finally, the first place team achieved mIoU of 0.8413 (tumor: 0.8389, stroma: 0.7931, normal: 0.8919). According to the technical reports of the top-tier teams, CAM is still the most popular approach in WSSS. Cutmix data augmentation has been widely adopted to generate more reliable samples. With the success of this challenge, we believe that WSSS approaches with patch-level annotations can replace the traditional pixel annotations while reducing the annotation efforts. The entire dataset has been released to encourage more researches on computational pathology in LUAD and more novel WSSS techniques.
HistoKT: Cross Knowledge Transfer in Computational Pathology
Jan 27, 2022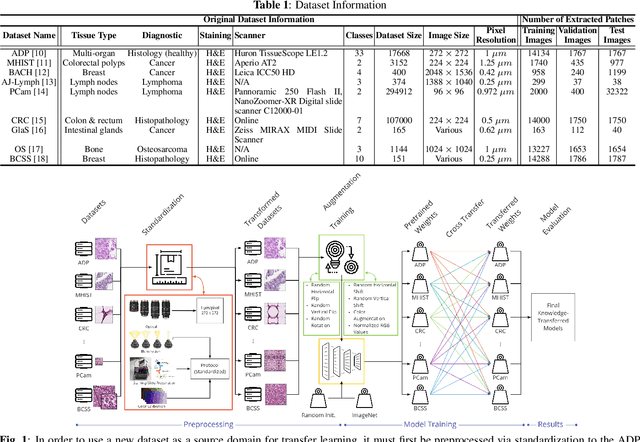
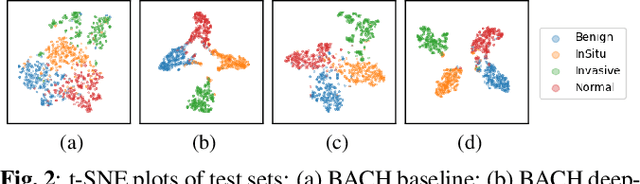
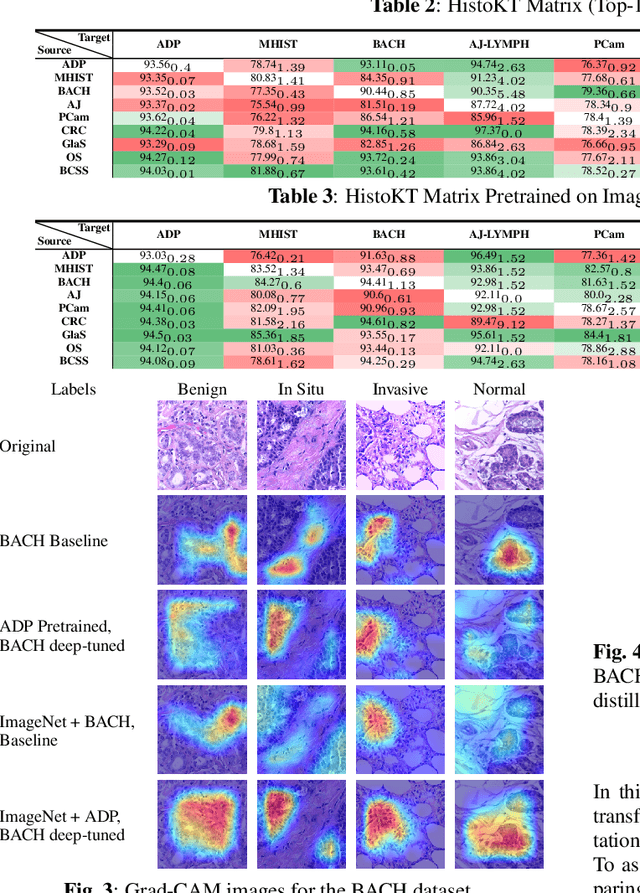
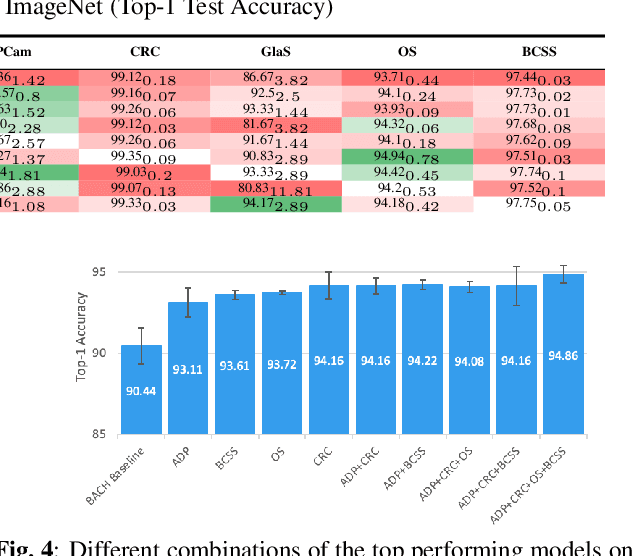
The lack of well-annotated datasets in computational pathology (CPath) obstructs the application of deep learning techniques for classifying medical images. %Since pathologist time is expensive, dataset curation is intrinsically difficult. Many CPath workflows involve transferring learned knowledge between various image domains through transfer learning. Currently, most transfer learning research follows a model-centric approach, tuning network parameters to improve transfer results over few datasets. In this paper, we take a data-centric approach to the transfer learning problem and examine the existence of generalizable knowledge between histopathological datasets. First, we create a standardization workflow for aggregating existing histopathological data. We then measure inter-domain knowledge by training ResNet18 models across multiple histopathological datasets, and cross-transferring between them to determine the quantity and quality of innate shared knowledge. Additionally, we use weight distillation to share knowledge between models without additional training. We find that hard to learn, multi-class datasets benefit most from pretraining, and a two stage learning framework incorporating a large source domain such as ImageNet allows for better utilization of smaller datasets. Furthermore, we find that weight distillation enables models trained on purely histopathological features to outperform models using external natural image data.
Applying Artificial Intelligence for Age Estimation in Digital Forensic Investigations
Jan 09, 2022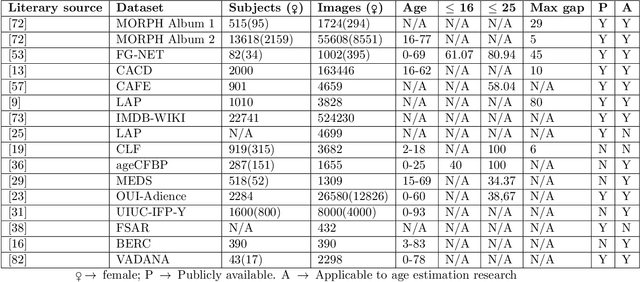
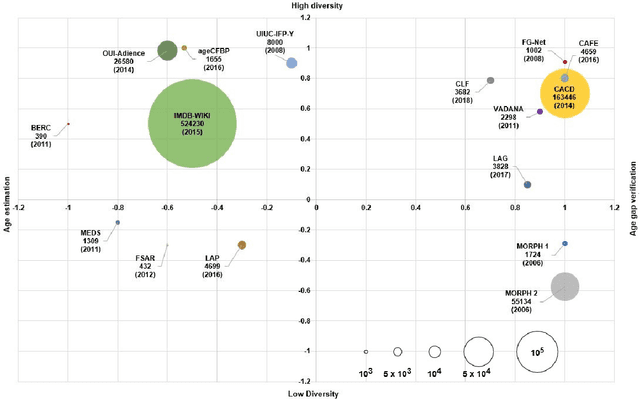

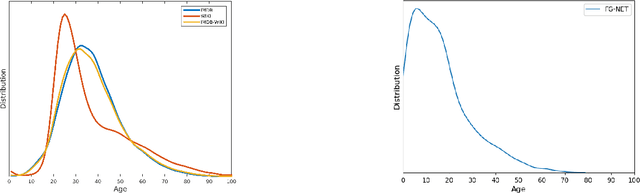
The precise age estimation of child sexual abuse and exploitation (CSAE) victims is one of the most significant digital forensic challenges. Investigators often need to determine the age of victims by looking at images and interpreting the sexual development stages and other human characteristics. The main priority - safeguarding children -- is often negatively impacted by a huge forensic backlog, cognitive bias and the immense psychological stress that this work can entail. This paper evaluates existing facial image datasets and proposes a new dataset tailored to the needs of similar digital forensic research contributions. This small, diverse dataset of 0 to 20-year-old individuals contains 245 images and is merged with 82 unique images from the FG-NET dataset, thus achieving a total of 327 images with high image diversity and low age range density. The new dataset is tested on the Deep EXpectation (DEX) algorithm pre-trained on the IMDB-WIKI dataset. The overall results for young adolescents aged 10 to 15 and older adolescents/adults aged 16 to 20 are very encouraging -- achieving MAEs as low as 1.79, but also suggest that the accuracy for children aged 0 to 10 needs further work. In order to determine the efficacy of the prototype, valuable input of four digital forensic experts, including two forensic investigators, has been taken into account to improve age estimation results. Further research is required to extend datasets both concerning image density and the equal distribution of factors such as gender and racial diversity.
Pose Estimation of Specific Rigid Objects
Dec 30, 2021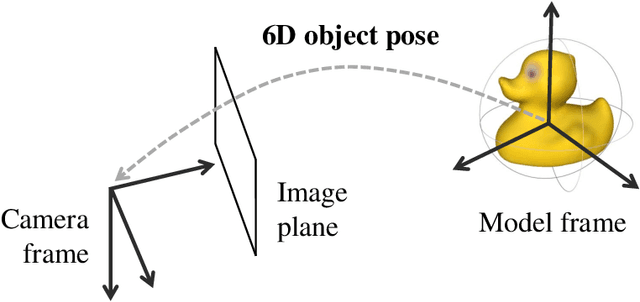
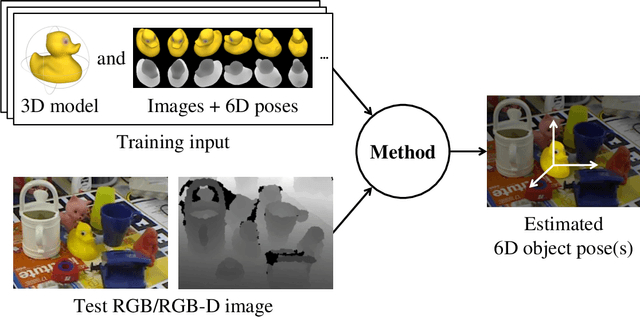
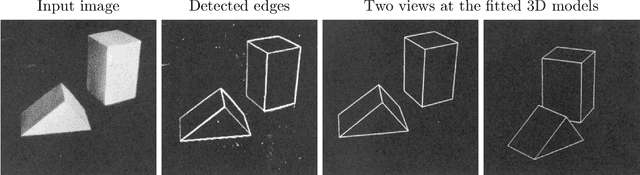
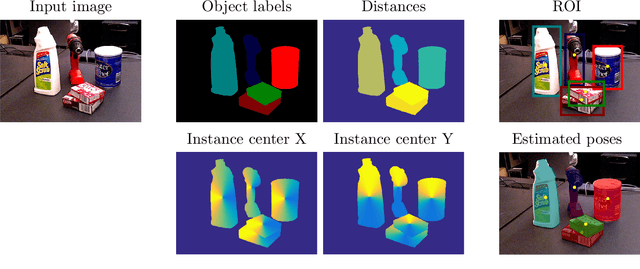
In this thesis, we address the problem of estimating the 6D pose of rigid objects from a single RGB or RGB-D input image, assuming that 3D models of the objects are available. This problem is of great importance to many application fields such as robotic manipulation, augmented reality, and autonomous driving. First, we propose EPOS, a method for 6D object pose estimation from an RGB image. The key idea is to represent an object by compact surface fragments and predict the probability distribution of corresponding fragments at each pixel of the input image by a neural network. Each pixel is linked with a data-dependent number of fragments, which allows systematic handling of symmetries, and the 6D poses are estimated from the links by a RANSAC-based fitting method. EPOS outperformed all RGB and most RGB-D and D methods on several standard datasets. Second, we present HashMatch, an RGB-D method that slides a window over the input image and searches for a match against templates, which are pre-generated by rendering 3D object models in different orientations. The method applies a cascade of evaluation stages to each window location, which avoids exhaustive matching against all templates. Third, we propose ObjectSynth, an approach to synthesize photorealistic images of 3D object models for training methods based on neural networks. The images yield substantial improvements compared to commonly used images of objects rendered on top of random photographs. Fourth, we introduce T-LESS, the first dataset for 6D object pose estimation that includes 3D models and RGB-D images of industry-relevant objects. Fifth, we define BOP, a benchmark that captures the status quo in the field. BOP comprises eleven datasets in a unified format, an evaluation methodology, an online evaluation system, and public challenges held at international workshops organized at the ICCV and ECCV conferences.
Generating Diverse Structure for Image Inpainting With Hierarchical VQ-VAE
Mar 18, 2021
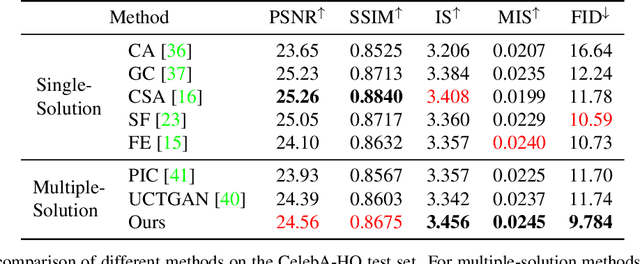
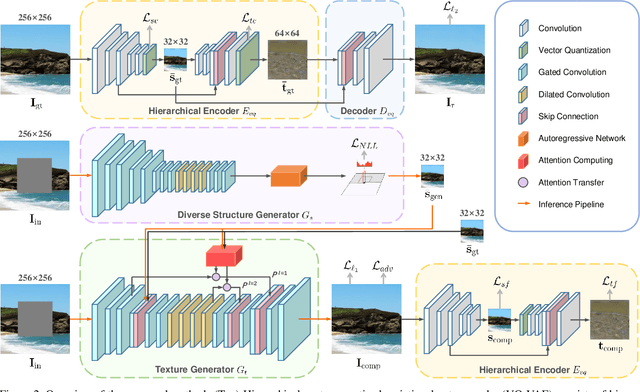
Given an incomplete image without additional constraint, image inpainting natively allows for multiple solutions as long as they appear plausible. Recently, multiplesolution inpainting methods have been proposed and shown the potential of generating diverse results. However, these methods have difficulty in ensuring the quality of each solution, e.g. they produce distorted structure and/or blurry texture. We propose a two-stage model for diverse inpainting, where the first stage generates multiple coarse results each of which has a different structure, and the second stage refines each coarse result separately by augmenting texture. The proposed model is inspired by the hierarchical vector quantized variational auto-encoder (VQ-VAE), whose hierarchical architecture isentangles structural and textural information. In addition, the vector quantization in VQVAE enables autoregressive modeling of the discrete distribution over the structural information. Sampling from the distribution can easily generate diverse and high-quality structures, making up the first stage of our model. In the second stage, we propose a structural attention module inside the texture generation network, where the module utilizes the structural information to capture distant correlations. We further reuse the VQ-VAE to calculate two feature losses, which help improve structure coherence and texture realism, respectively. Experimental results on CelebA-HQ, Places2, and ImageNet datasets show that our method not only enhances the diversity of the inpainting solutions but also improves the visual quality of the generated multiple images. Code and models are available at: https://github.com/USTC-JialunPeng/Diverse-Structure-Inpainting.
Depth estimation of endoscopy using sim-to-real transfer
Dec 27, 2021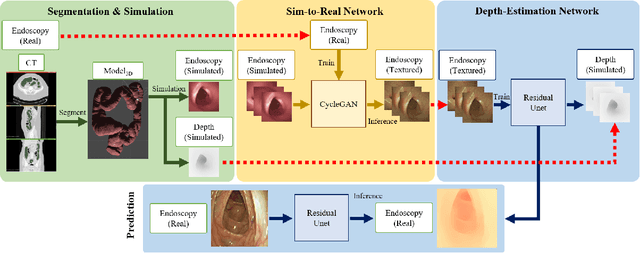
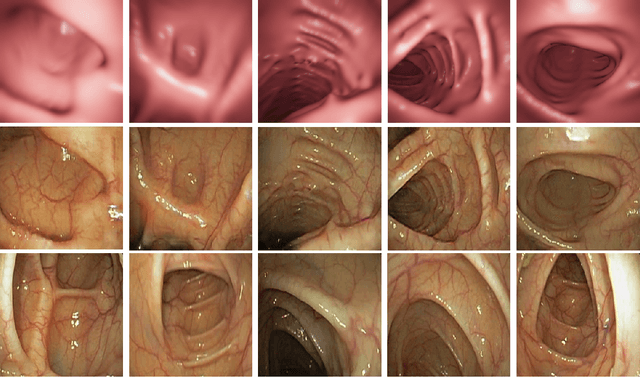
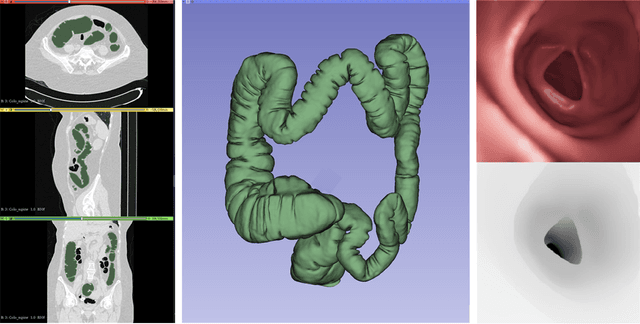

In order to use the navigation system effectively, distance information sensors such as depth sensors are essential. Since depth sensors are difficult to use in endoscopy, many groups propose a method using convolutional neural networks. In this paper, the ground truth of the depth image and the endoscopy image is generated through endoscopy simulation using the colon model segmented by CT colonography. Photo-realistic simulation images can be created using a sim-to-real approach using cycleGAN for endoscopy images. By training the generated dataset, we propose a quantitative endoscopy depth estimation network. The proposed method represents a better-evaluated score than the existing unsupervised training-based results.
The Abduction of Sherlock Holmes: A Dataset for Visual Abductive Reasoning
Feb 10, 2022
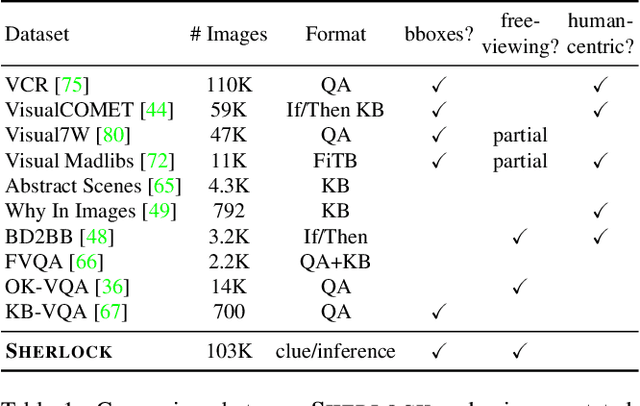

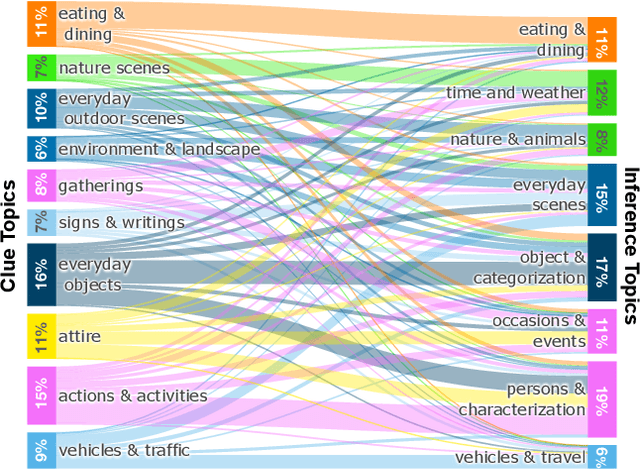
Humans have remarkable capacity to reason abductively and hypothesize about what lies beyond the literal content of an image. By identifying concrete visual clues scattered throughout a scene, we almost can't help but draw probable inferences beyond the literal scene based on our everyday experience and knowledge about the world. For example, if we see a "20 mph" sign alongside a road, we might assume the street sits in a residential area (rather than on a highway), even if no houses are pictured. Can machines perform similar visual reasoning? We present Sherlock, an annotated corpus of 103K images for testing machine capacity for abductive reasoning beyond literal image contents. We adopt a free-viewing paradigm: participants first observe and identify salient clues within images (e.g., objects, actions) and then provide a plausible inference about the scene, given the clue. In total, we collect 363K (clue, inference) pairs, which form a first-of-its-kind abductive visual reasoning dataset. Using our corpus, we test three complementary axes of abductive reasoning. We evaluate the capacity of models to: i) retrieve relevant inferences from a large candidate corpus; ii) localize evidence for inferences via bounding boxes, and iii) compare plausible inferences to match human judgments on a newly-collected diagnostic corpus of 19K Likert-scale judgments. While we find that fine-tuning CLIP-RN50x64 with a multitask objective outperforms strong baselines, significant headroom exists between model performance and human agreement. We provide analysis that points towards future work.