 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A unified 3D framework for Organs at Risk Localization and Segmentation for Radiation Therapy Planning
Mar 01, 2022
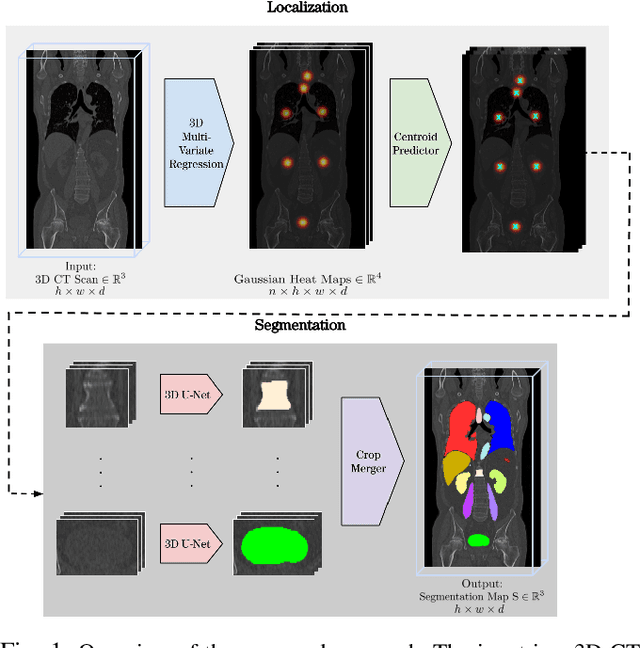
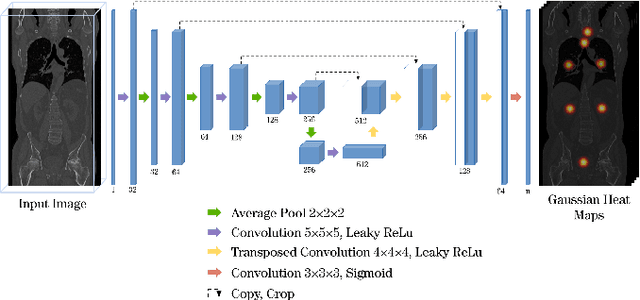
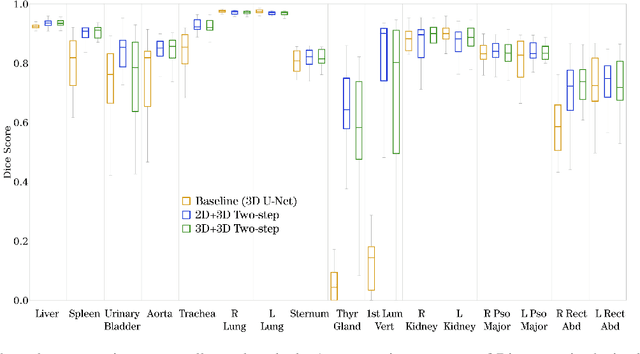
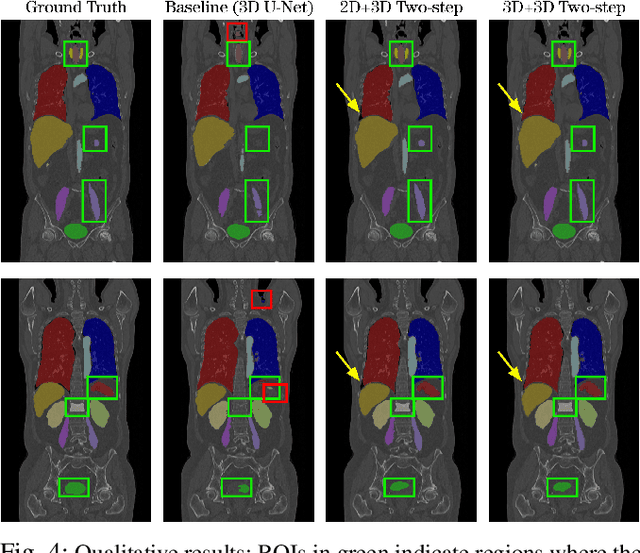
Automatic localization and segmentation of organs-at-risk (OAR) in CT are essential pre-processing steps in medical image analysis tasks, such as radiation therapy planning. For instance, the segmentation of OAR surrounding tumors enables the maximization of radiation to the tumor area without compromising the healthy tissues. However, the current medical workflow requires manual delineation of OAR, which is prone to errors and is annotator-dependent. In this work, we aim to introduce a unified 3D pipeline for OAR localization-segmentation rather than novel localization or segmentation architectures. To the best of our knowledge, our proposed framework fully enables the exploitation of 3D context information inherent in medical imaging. In the first step, a 3D multi-variate regression network predicts organs' centroids and bounding boxes. Secondly, 3D organ-specific segmentation networks are leveraged to generate a multi-organ segmentation map. Our method achieved an overall Dice score of $0.9260\pm 0.18 \%$ on the VISCERAL dataset containing CT scans with varying fields of view and multiple organs.
A Picture is Worth a Thousand Words: A Unified System for Diverse Captions and Rich Images Generation
Oct 19, 2021

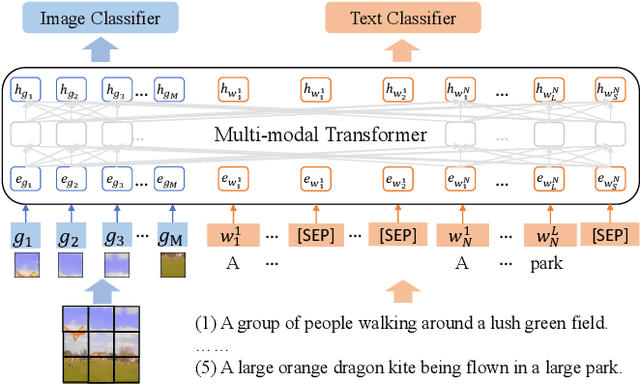
A creative image-and-text generative AI system mimics humans' extraordinary abilities to provide users with diverse and comprehensive caption suggestions, as well as rich image creations. In this work, we demonstrate such an AI creation system to produce both diverse captions and rich images. When users imagine an image and associate it with multiple captions, our system paints a rich image to reflect all captions faithfully. Likewise, when users upload an image, our system depicts it with multiple diverse captions. We propose a unified multi-modal framework to achieve this goal. Specifically, our framework jointly models image-and-text representations with a Transformer network, which supports rich image creation by accepting multiple captions as input. We consider the relations among input captions to encourage diversity in training and adopt a non-autoregressive decoding strategy to enable real-time inference. Based on these, our system supports both diverse captions and rich images generations. Our code is available online.
Robust Contrastive Learning against Noisy Views
Jan 12, 2022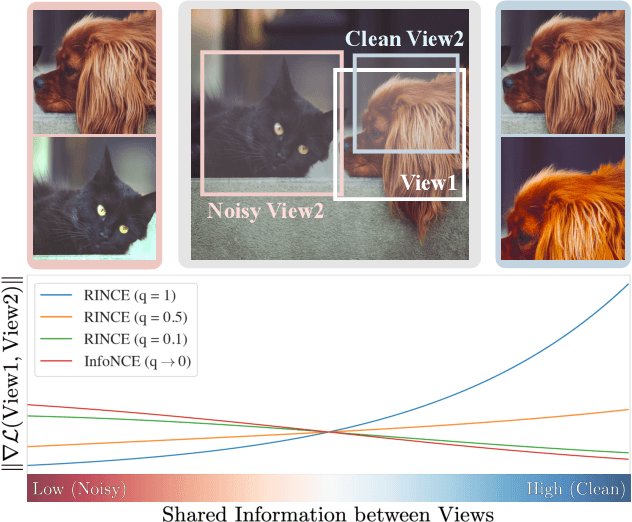
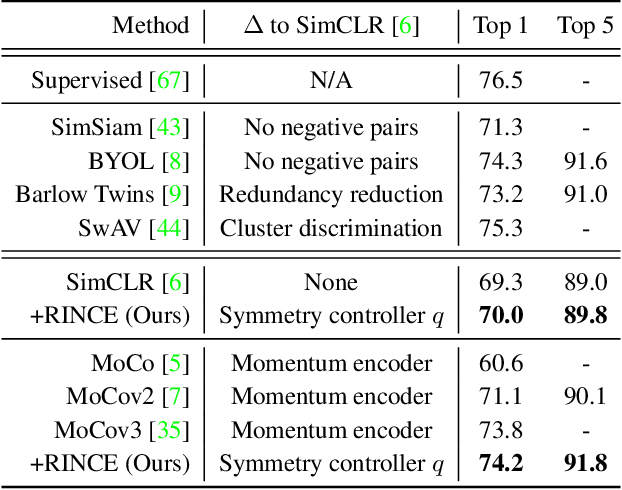

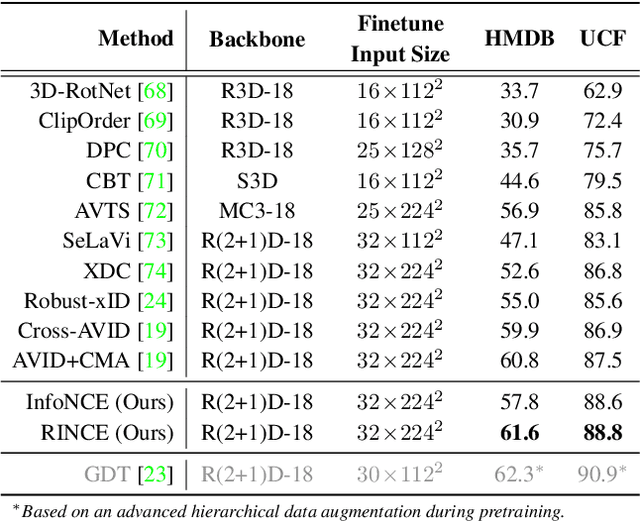
Contrastive learning relies on an assumption that positive pairs contain related views, e.g., patches of an image or co-occurring multimodal signals of a video, that share certain underlying information about an instance. But what if this assumption is violated? The literature suggests that contrastive learning produces suboptimal representations in the presence of noisy views, e.g., false positive pairs with no apparent shared information. In this work, we propose a new contrastive loss function that is robust against noisy views. We provide rigorous theoretical justifications by showing connections to robust symmetric losses for noisy binary classification and by establishing a new contrastive bound for mutual information maximization based on the Wasserstein distance measure. The proposed loss is completely modality-agnostic and a simple drop-in replacement for the InfoNCE loss, which makes it easy to apply to existing contrastive frameworks. We show that our approach provides consistent improvements over the state-of-the-art on image, video, and graph contrastive learning benchmarks that exhibit a variety of real-world noise patterns.
Synthetic Glacier SAR Image Generation from Arbitrary Masks Using Pix2Pix Algorithm
Jan 14, 2021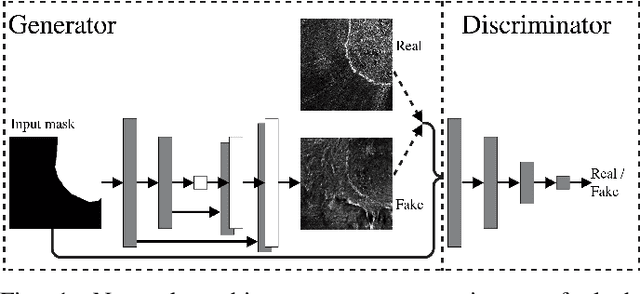
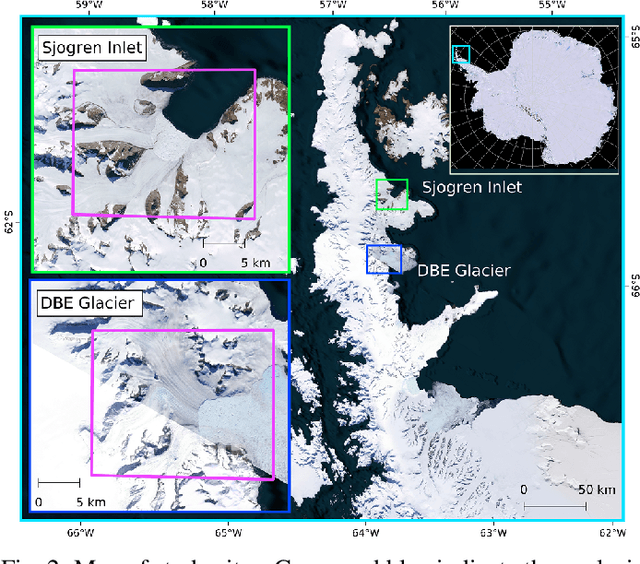
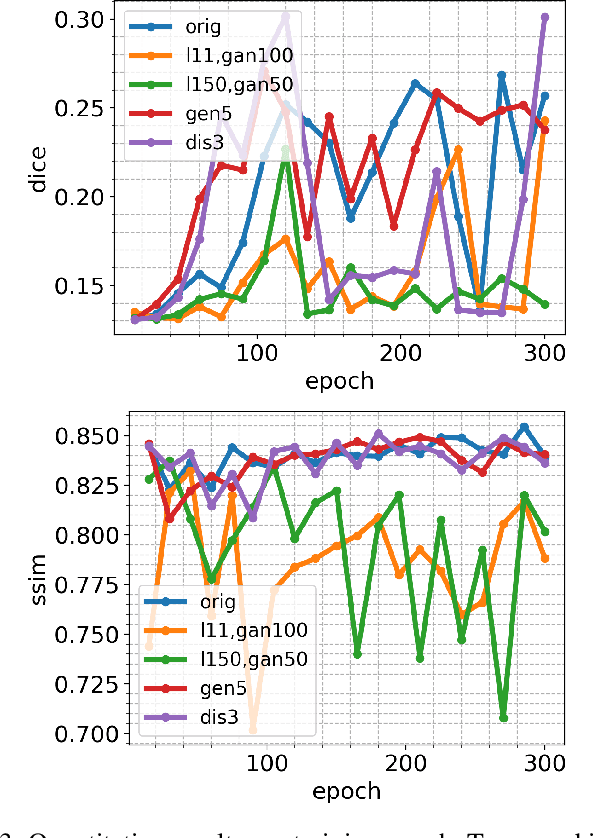

Supervised machine learning requires a large amount of labeled data to achieve proper test results. However, generating accurately labeled segmentation maps on remote sensing imagery, including images from synthetic aperture radar (SAR), is tedious and highly subjective. In this work, we propose to alleviate the issue of limited training data by generating synthetic SAR images with the pix2pix algorithm. This algorithm uses conditional Generative Adversarial Networks (cGANs) to generate an artificial image while preserving the structure of the input. In our case, the input is a segmentation mask, from which a corresponding synthetic SAR image is generated. We present different models, perform a comparative study and demonstrate that this approach synthesizes convincing glaciers in SAR images with promising qualitative and quantitative results.
FaceMap: Towards Unsupervised Face Clustering via Map Equation
Mar 21, 2022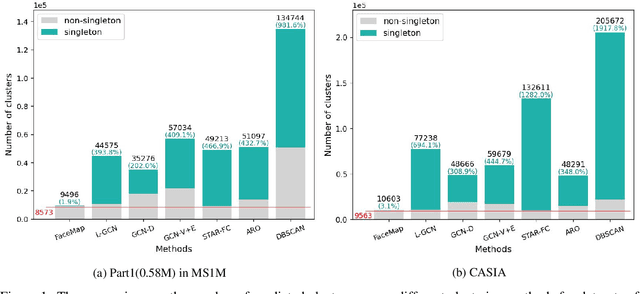
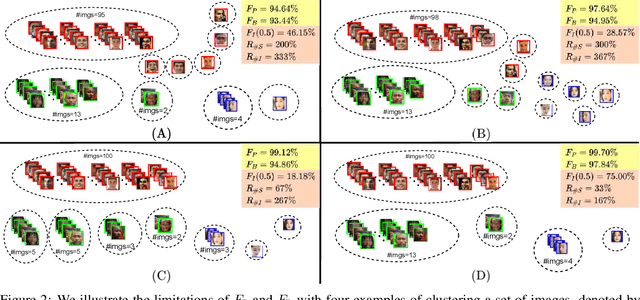

Face clustering is an essential task in computer vision due to the explosion of related applications such as augmented reality or photo album management. The main challenge of this task lies in the imperfectness of similarities among image feature representations. Given an existing feature extraction model, it is still an unresolved problem that how can the inherent characteristics of similarities of unlabelled images be leveraged to improve the clustering performance. Motivated by answering the question, we develop an effective unsupervised method, named as FaceMap, by formulating face clustering as a process of non-overlapping community detection, and minimizing the entropy of information flows on a network of images. The entropy is denoted by the map equation and its minimum represents the least description of paths among images in expectation. Inspired by observations on the ranked transition probabilities in the affinity graph constructed from facial images, we develop an outlier detection strategy to adaptively adjust transition probabilities among images. Experiments with ablation studies demonstrate that FaceMap significantly outperforms existing methods and achieves new state-of-the-arts on three popular large-scale datasets for face clustering, e.g., an absolute improvement of more than $10\%$ and $4\%$ comparing with prior unsupervised and supervised methods respectively in terms of average of Pairwise F-score. Our code is publicly available on github.
Near-field Image Transmission and EVM Measurements in Rich Scattering Environment
Jan 31, 2021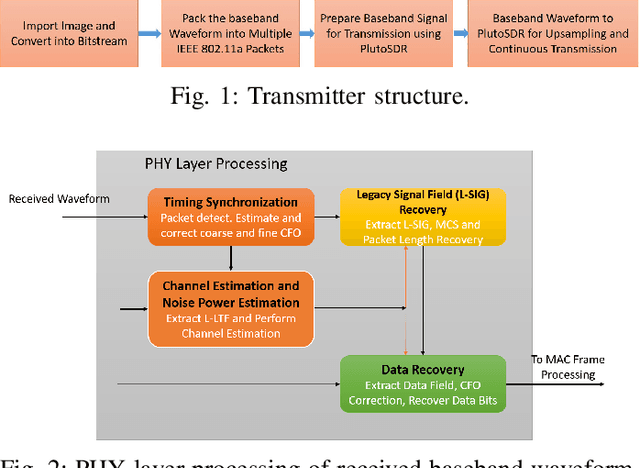
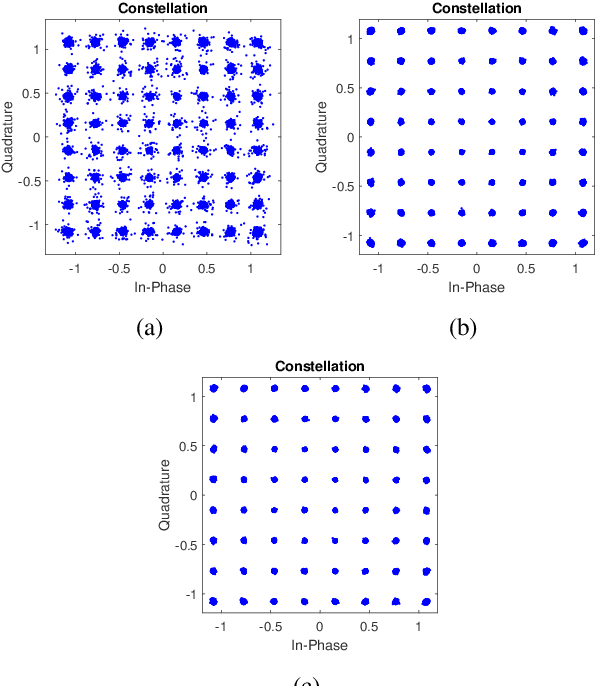
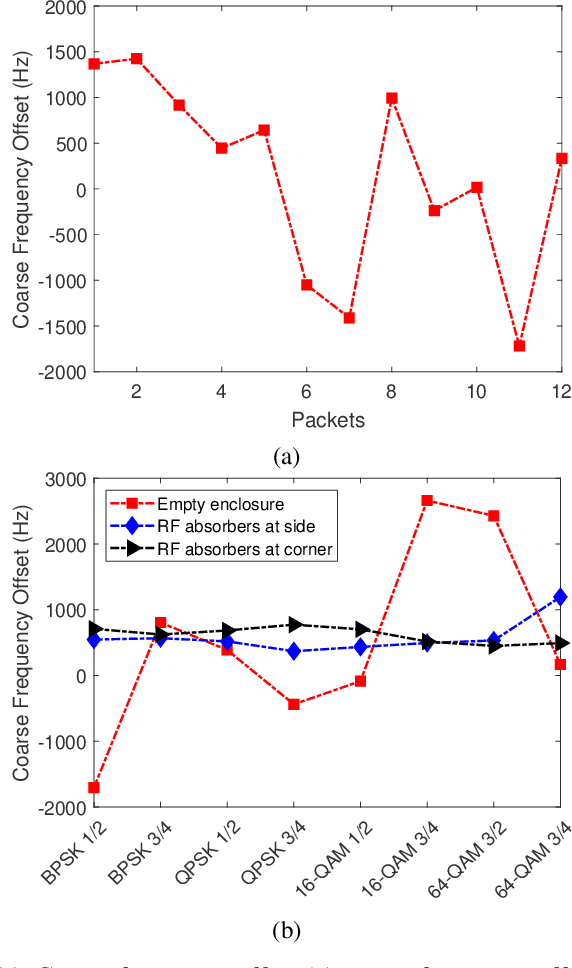
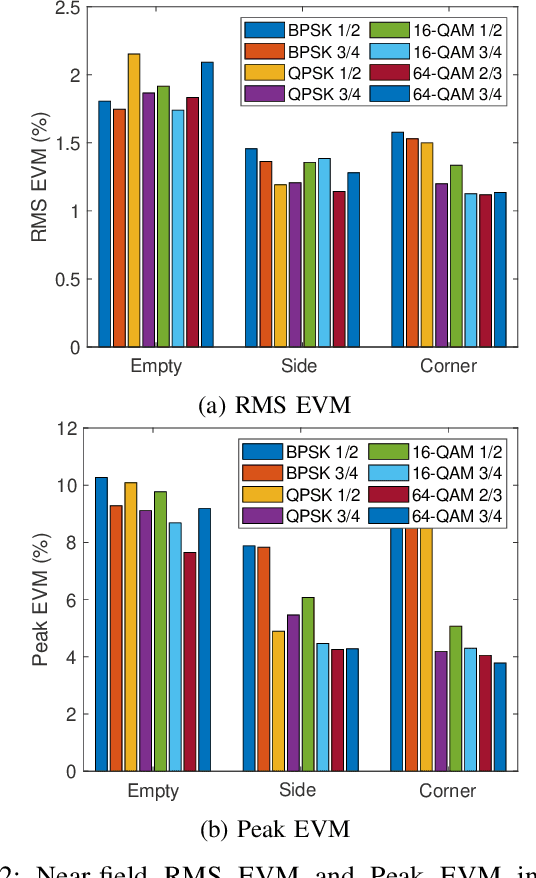
In this work, we present near-field image transmission and error vector magnitude measurement in a rich scattering environment in a metal enclosure. We check the effect of loading metal enclosure on the performance of SDR based near-field communication link. We focus on the key communication receiver parameters to observe the effect of near-field link in presence of rich-scattering and in presence of loading with RF absorber cones. The near-field performance is measured by transmitting wideband OFDM-modulated packets containing image information. Our finding suggests that the performance of OFDM based wideband near-field communication improves when the metal enclosure is loaded with RF absorbers. Near-field EVM improves when the enclosure is loaded with RF absorber cones. Loading of the metal enclosure has the effect of increased coherence bandwidth. Frequency selectivity was observed in an empty enclosure which suggests coherence bandwidth less than the signal bandwidth.
Rethinking Image Deraining via Rain Streaks and Vapors
Aug 03, 2020
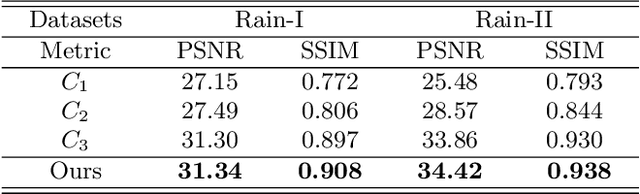
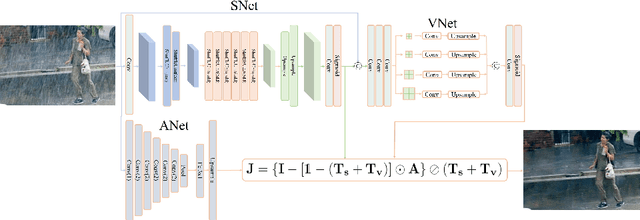

Single image deraining regards an input image as a fusion of a background image, a transmission map, rain streaks, and atmosphere light. While advanced models are proposed for image restoration (i.e., background image generation), they regard rain streaks with the same properties as background rather than transmission medium. As vapors (i.e., rain streaks accumulation or fog-like rain) are conveyed in the transmission map to model the veiling effect, the fusion of rain streaks and vapors do not naturally reflect the rain image formation. In this work, we reformulate rain streaks as transmission medium together with vapors to model rain imaging. We propose an encoder-decoder CNN named as SNet to learn the transmission map of rain streaks. As rain streaks appear with various shapes and directions, we use ShuffleNet units within SNet to capture their anisotropic representations. As vapors are brought by rain streaks, we propose a VNet containing spatial pyramid pooling (SSP) to predict the transmission map of vapors in multi-scales based on that of rain streaks. Meanwhile, we use an encoder CNN named ANet to estimate atmosphere light. The SNet, VNet, and ANet are jointly trained to predict transmission maps and atmosphere light for rain image restoration. Extensive experiments on the benchmark datasets demonstrate the effectiveness of the proposed visual model to predict rain streaks and vapors. The proposed deraining method performs favorably against state-of-the-art deraining approaches.
Gate-Shift-Fuse for Video Action Recognition
Mar 16, 2022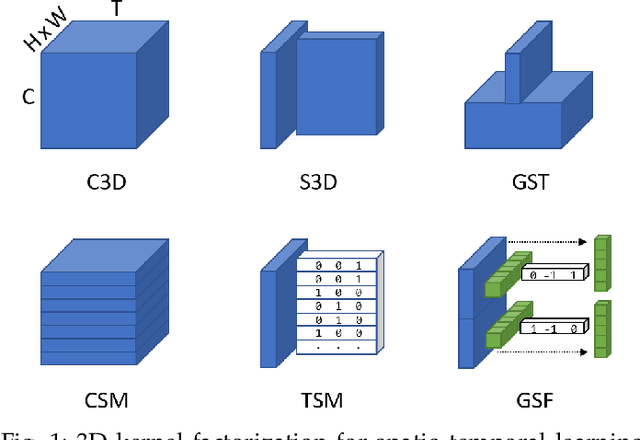
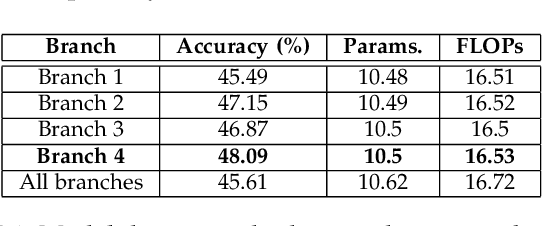
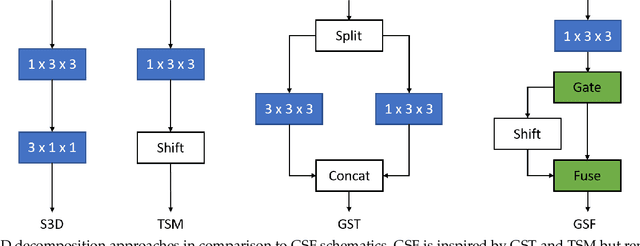
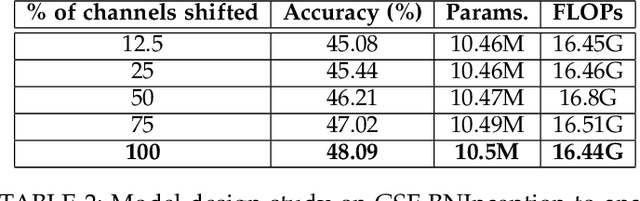
Convolutional Neural Networks are the de facto models for image recognition. However 3D CNNs, the straight forward extension of 2D CNNs for video recognition, have not achieved the same success on standard action recognition benchmarks. One of the main reasons for this reduced performance of 3D CNNs is the increased computational complexity requiring large scale annotated datasets to train them in scale. 3D kernel factorization approaches have been proposed to reduce the complexity of 3D CNNs. Existing kernel factorization approaches follow hand-designed and hard-wired techniques. In this paper we propose Gate-Shift-Fuse (GSF), a novel spatio-temporal feature extraction module which controls interactions in spatio-temporal decomposition and learns to adaptively route features through time and combine them in a data dependent manner. GSF leverages grouped spatial gating to decompose input tensor and channel weighting to fuse the decomposed tensors. GSF can be inserted into existing 2D CNNs to convert them into an efficient and high performing spatio-temporal feature extractor, with negligible parameter and compute overhead. We perform an extensive analysis of GSF using two popular 2D CNN families and achieve state-of-the-art or competitive performance on five standard action recognition benchmarks. Code and models will be made publicly available at https://github.com/swathikirans/GSF.
Boundary Corrected Multi-scale Fusion Network for Real-time Semantic Segmentation
Mar 01, 2022

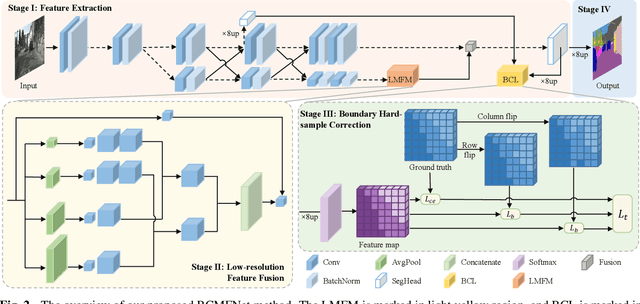
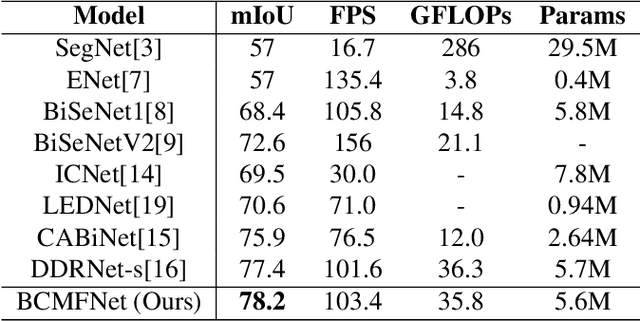
Image semantic segmentation aims at the pixel-level classification of images, which has requirements for both accuracy and speed in practical application. Existing semantic segmentation methods mainly rely on the high-resolution input to achieve high accuracy and do not meet the requirements of inference time. Although some methods focus on high-speed scene parsing with lightweight architectures, they can not fully mine semantic features under low computation with relatively low performance. To realize the real-time and high-precision segmentation, we propose a new method named Boundary Corrected Multi-scale Fusion Network, which uses the designed Low-resolution Multi-scale Fusion Module to extract semantic information. Moreover, to deal with boundary errors caused by low-resolution feature map fusion, we further design an additional Boundary Corrected Loss to constrain overly smooth features. Extensive experiments show that our method achieves a state-of-the-art balance of accuracy and speed for the real-time semantic segmentation.
Semantically Grounded Visual Embeddings for Zero-Shot Learning
Jan 03, 2022
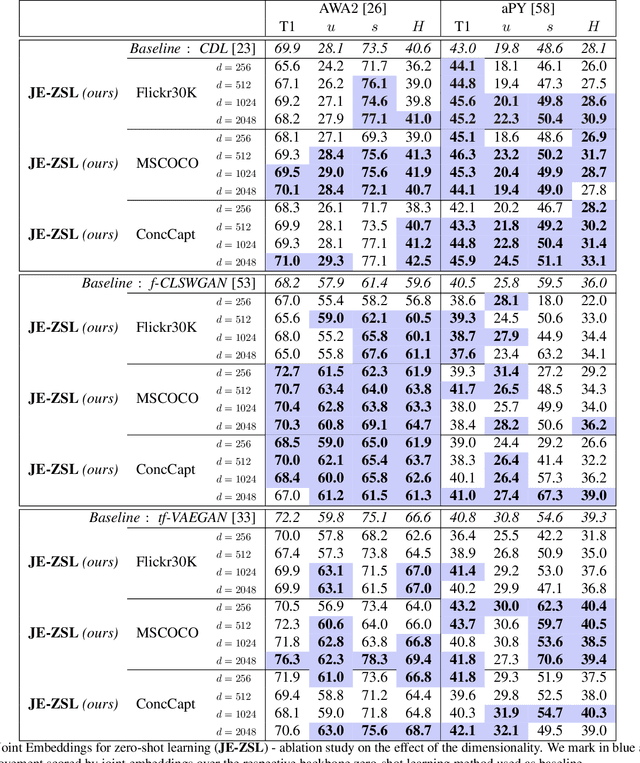
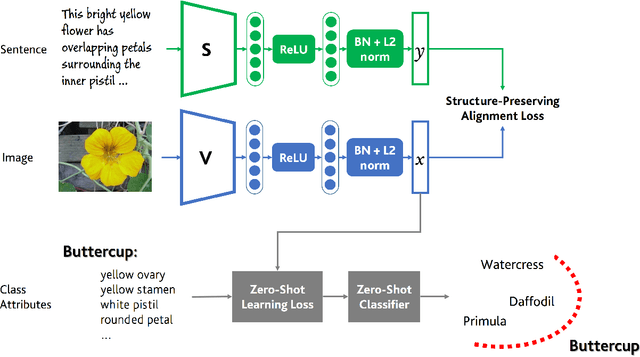
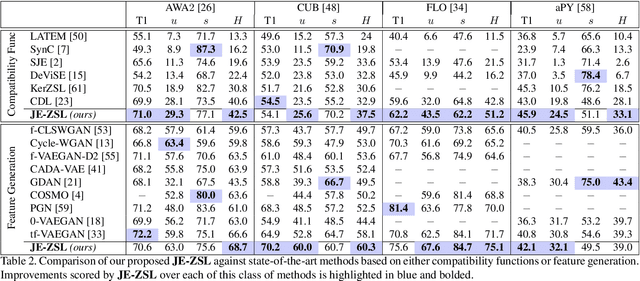
Zero-shot learning methods rely on fixed visual and semantic embeddings, extracted from independent vision and language models, both pre-trained for other large-scale tasks. This is a weakness of current zero-shot learning frameworks as such disjoint embeddings fail to adequately associate visual and textual information to their shared semantic content. Therefore, we propose to learn semantically grounded and enriched visual information by computing a joint image and text model with a two-stream network on a proxy task. To improve this alignment between image and textual representations, provided by attributes, we leverage ancillary captions to provide grounded semantic information. Our method, dubbed joint embeddings for zero-shot learning is evaluated on several benchmark datasets, improving the performance of existing state-of-the-art methods in both standard ($+1.6$\% on aPY, $+2.6\%$ on FLO) and generalized ($+2.1\%$ on AWA$2$, $+2.2\%$ on CUB) zero-shot recognition.