 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Medical Image Segmentation Using Deep Learning: A Survey
Sep 28, 2020
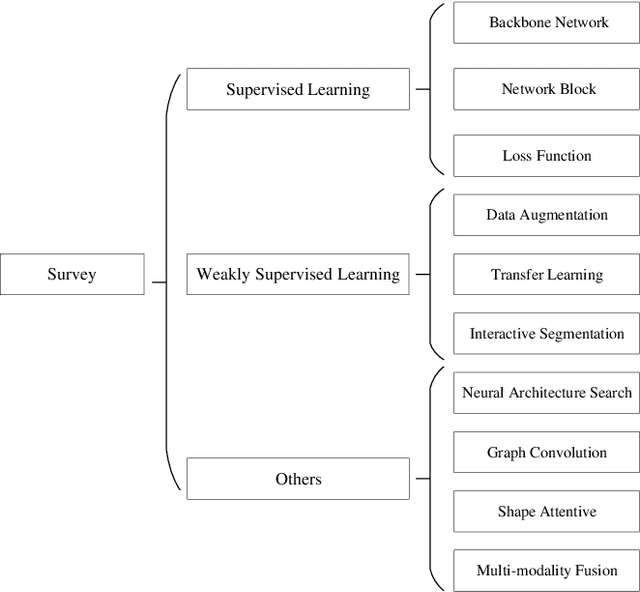
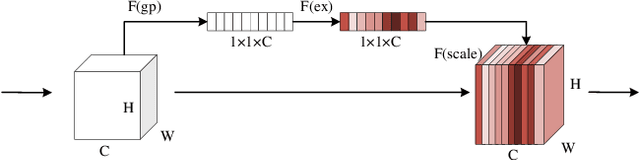
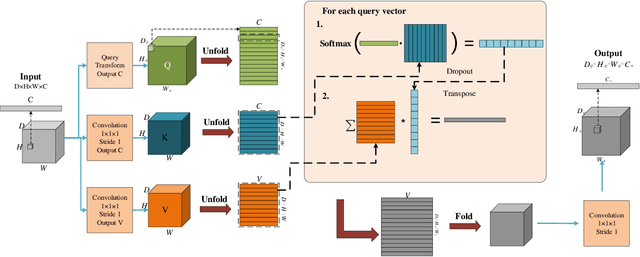
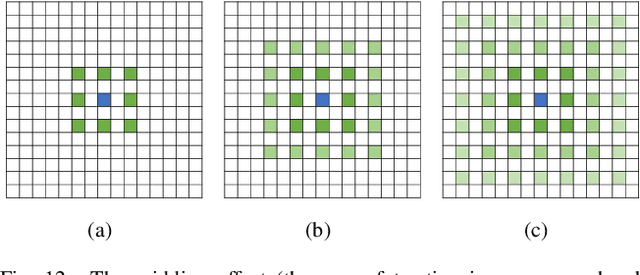
Deep learning has been widely used for medical image segmentation and a large number of papers has been presented recording the success of deep learning in the field. In this paper, we present a comprehensive thematic survey on medical image segmentation using deep learning techniques. This paper makes two original contributions. Firstly, compared to traditional surveys that directly divide literatures of deep learning on medical image segmentation into many groups and introduce literatures in detail for each group, we classify currently popular literatures according to a multi-level structure from coarse to fine. Secondly, this paper focuses on supervised and weakly supervised learning approaches, without including unsupervised approaches since they have been introduced in many old surveys and they are not popular currently. For supervised learning approaches, we analyze literatures in three aspects: the selection of backbone networks, the design of network blocks, and the improvement of loss functions. For weakly supervised learning approaches, we investigate literature according to data augmentation, transfer learning, and interactive segmentation, separately. Compared to existing surveys, this survey classifies the literatures very differently from before and is more convenient for readers to understand the relevant rationale and will guide them to think of appropriate improvements in medical image segmentation based on deep learning approaches.
Learning Occlusion-Aware Coarse-to-Fine Depth Map for Self-supervised Monocular Depth Estimation
Mar 21, 2022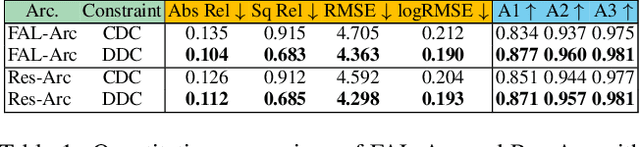
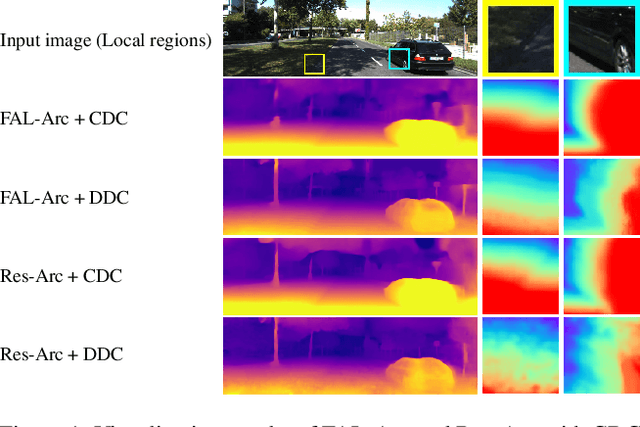
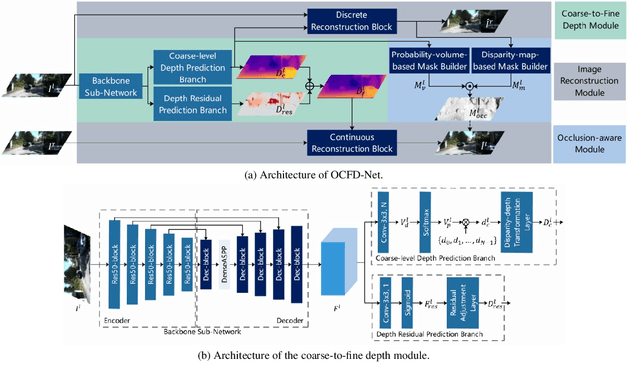
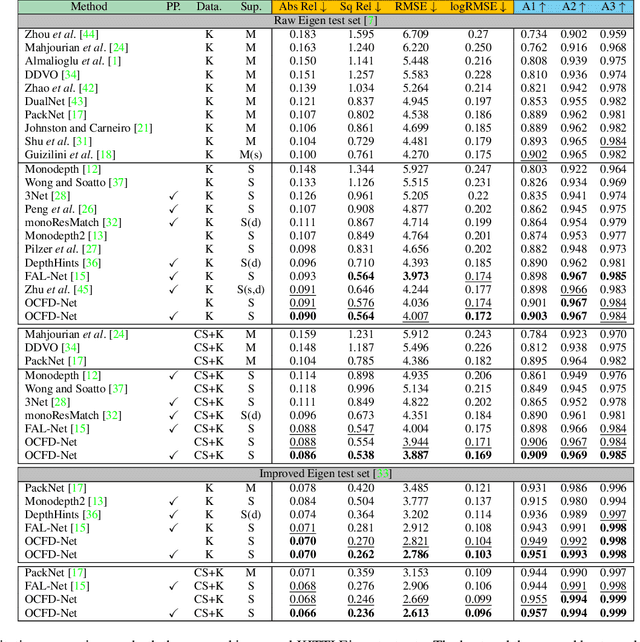
Self-supervised monocular depth estimation, aiming to learn scene depths from single images in a self-supervised manner, has received much attention recently. In spite of recent efforts in this field, how to learn accurate scene depths and alleviate the negative influence of occlusions for self-supervised depth estimation, still remains an open problem. Addressing this problem, we firstly empirically analyze the effects of both the continuous and discrete depth constraints which are widely used in the training process of many existing works. Then inspired by the above empirical analysis, we propose a novel network to learn an Occlusion-aware Coarse-to-Fine Depth map for self-supervised monocular depth estimation, called OCFD-Net. Given an arbitrary training set of stereo image pairs, the proposed OCFD-Net does not only employ a discrete depth constraint for learning a coarse-level depth map, but also employ a continuous depth constraint for learning a scene depth residual, resulting in a fine-level depth map. In addition, an occlusion-aware module is designed under the proposed OCFD-Net, which is able to improve the capability of the learnt fine-level depth map for handling occlusions. Extensive experimental results on the public KITTI and Make3D datasets demonstrate that the proposed method outperforms 20 existing state-of-the-art methods in most cases.
SPICE: Semantic Pseudo-labeling for Image Clustering
Mar 17, 2021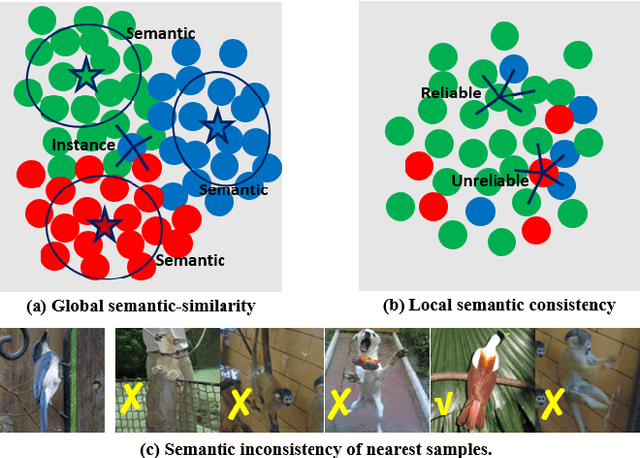
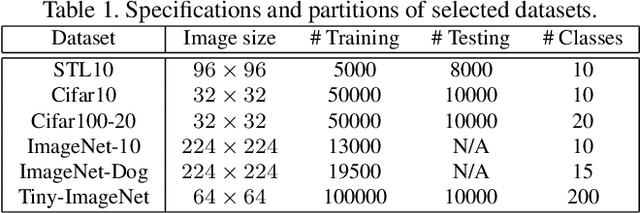
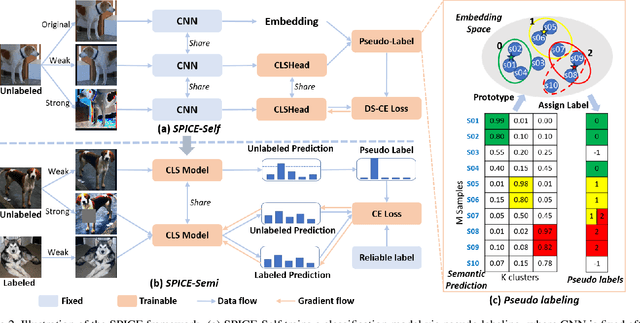
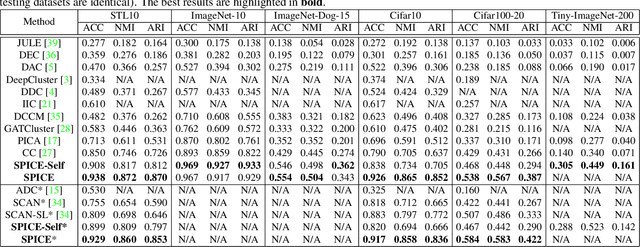
This paper presents SPICE, a Semantic Pseudo-labeling framework for Image ClustEring. Instead of using indirect loss functions required by the recently proposed methods, SPICE generates pseudo-labels via self-learning and directly uses the pseudo-label-based classification loss to train a deep clustering network. The basic idea of SPICE is to synergize the discrepancy among semantic clusters, the similarity among instance samples, and the semantic consistency of local samples in an embedding space to optimize the clustering network in a semantically-driven paradigm. Specifically, a semantic-similarity-based pseudo-labeling algorithm is first proposed to train a clustering network through unsupervised representation learning. Given the initial clustering results, a local semantic consistency principle is used to select a set of reliably labeled samples, and a semi-pseudo-labeling algorithm is adapted for performance boosting. Extensive experiments demonstrate that SPICE clearly outperforms the state-of-the-art methods on six common benchmark datasets including STL10, Cifar10, Cifar100-20, ImageNet-10, ImageNet-Dog, and Tiny-ImageNet. On average, our SPICE method improves the current best results by about 10% in terms of adjusted rand index, normalized mutual information, and clustering accuracy.
GANHopper: Multi-Hop GAN for Unsupervised Image-to-Image Translation
Feb 29, 2020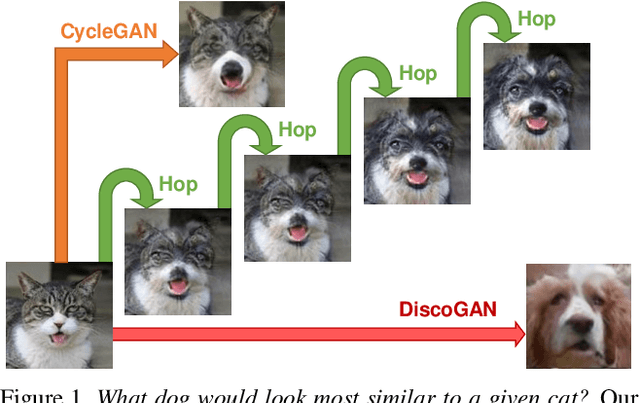
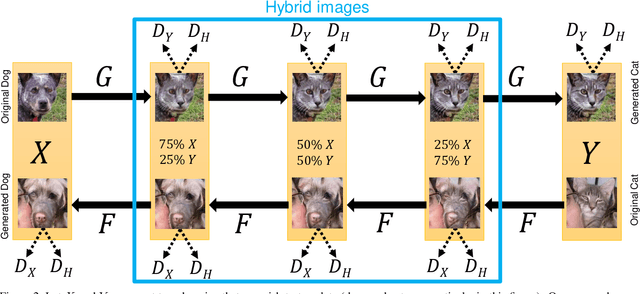
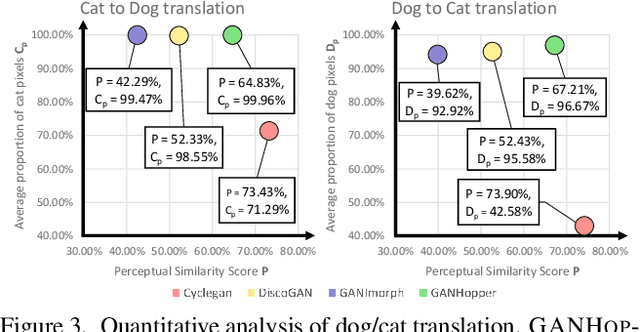
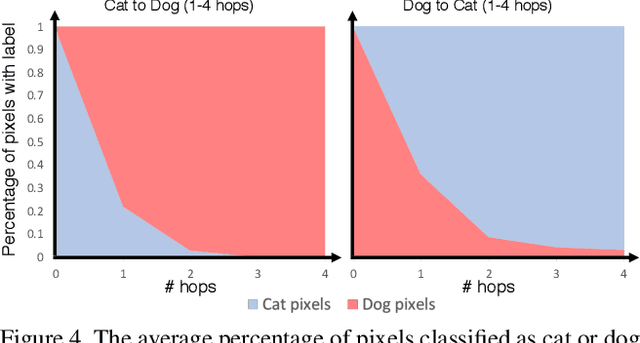
We introduce GANHopper, an unsupervised image-to-image translation network that transforms images gradually between two domains, through multiple hops. Instead of executing translation directly, we steer the translation by requiring the network to produce in-between images which resemble weighted hybrids between images from the two in-put domains. Our network is trained on unpaired images from the two domains only, without any in-between images.All hops are produced using a single generator along each direction. In addition to the standard cycle-consistency and adversarial losses, we introduce a new hybrid discrimina-tor, which is trained to classify the intermediate images produced by the generator as weighted hybrids, with weights based on a predetermined hop count. We also introduce a smoothness term to constrain the magnitude of each hop,further regularizing the translation. Compared to previous methods, GANHopper excels at image translations involving domain-specific image features and geometric variations while also preserving non-domain-specific features such as backgrounds and general color schemes.
Image Anomaly Detection by Aggregating Deep Pyramidal Representations
Nov 12, 2020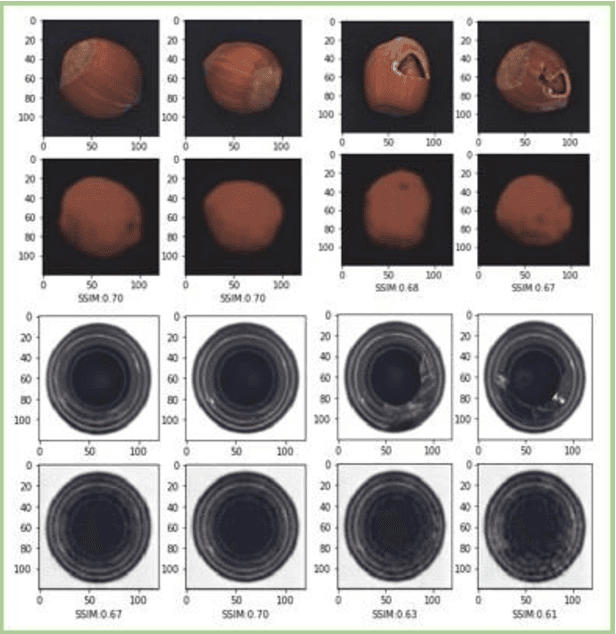
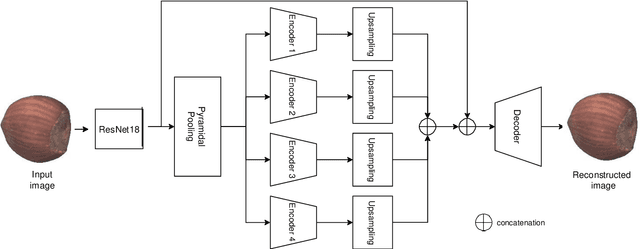
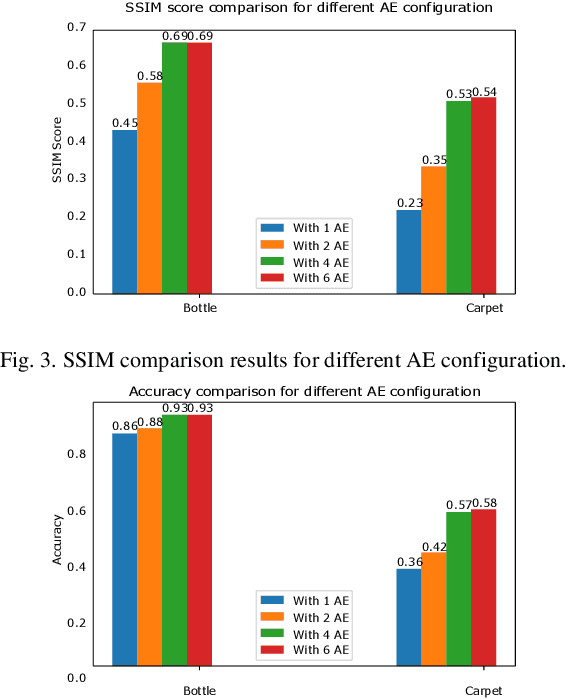
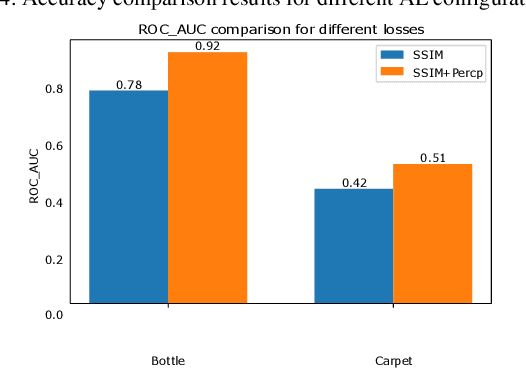
Anomaly detection consists in identifying, within a dataset, those samples that significantly differ from the majority of the data, representing the normal class. It has many practical applications, e.g. ranging from defective product detection in industrial systems to medical imaging. This paper focuses on image anomaly detection using a deep neural network with multiple pyramid levels to analyze the image features at different scales. We propose a network based on encoding-decoding scheme, using a standard convolutional autoencoders, trained on normal data only in order to build a model of normality. Anomalies can be detected by the inability of the network to reconstruct its input. Experimental results show a good accuracy on MNIST, FMNIST and the recent MVTec Anomaly Detection dataset
Ray-transfer functions for camera simulation of 3D scenes with hidden lens design
Feb 23, 2022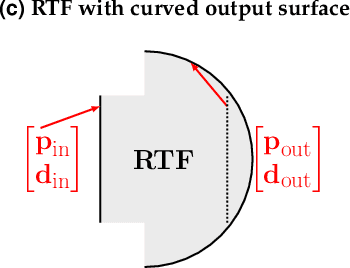

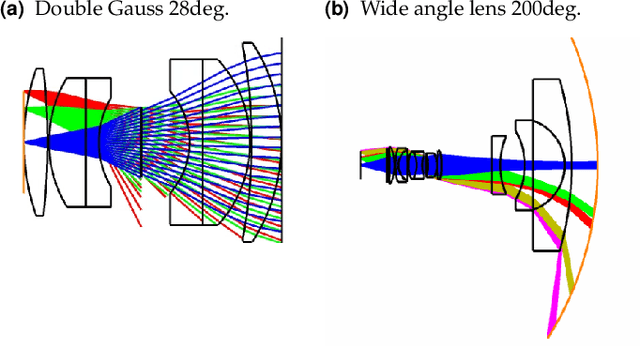
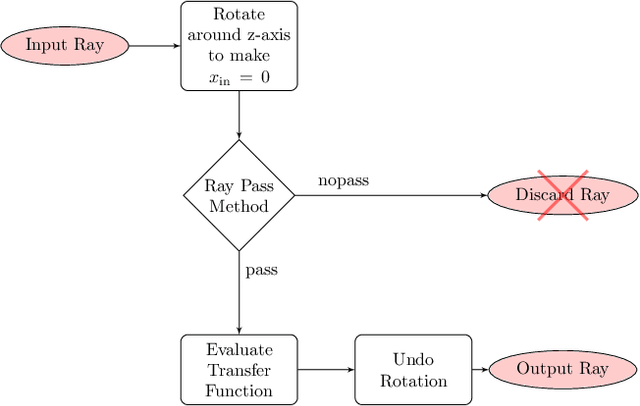
Combining image sensor simulation tools (e.g., ISETCam) with physically based ray tracing (e.g., PBRT) offers possibilities for designing and evaluating novel imaging systems as well as for synthesizing physically accurate, labeled images for machine learning. One practical limitation has been simulating the optics precisely: Lens manufacturers generally prefer to keep lens design confidential. We present a pragmatic solution to this problem using a black box lens model in Zemax; such models provide necessary optical information while preserving the lens designer's intellectual property. First, we describe and provide software to construct a polynomial ray transfer function that characterizes how rays entering the lens at any position and angle subsequently exit the lens. We implement the ray-transfer calculation as a camera model in PBRT and confirm that the PBRT ray-transfer calculations match the Zemax lens calculations for edge spread functions and relative illumination.
Content-based Image Retrieval and the Semantic Gap in the Deep Learning Era
Nov 12, 2020

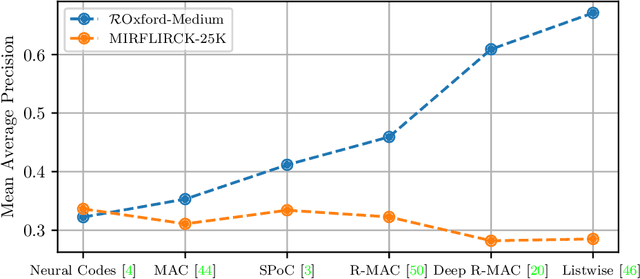
Content-based image retrieval has seen astonishing progress over the past decade, especially for the task of retrieving images of the same object that is depicted in the query image. This scenario is called instance or object retrieval and requires matching fine-grained visual patterns between images. Semantics, however, do not play a crucial role. This brings rise to the question: Do the recent advances in instance retrieval transfer to more generic image retrieval scenarios? To answer this question, we first provide a brief overview of the most relevant milestones of instance retrieval. We then apply them to a semantic image retrieval task and find that they perform inferior to much less sophisticated and more generic methods in a setting that requires image understanding. Following this, we review existing approaches to closing this so-called semantic gap by integrating prior world knowledge. We conclude that the key problem for the further advancement of semantic image retrieval lies in the lack of a standardized task definition and an appropriate benchmark dataset.
FPIC: A Novel Semantic Dataset for Optical PCB Assurance
Feb 17, 2022
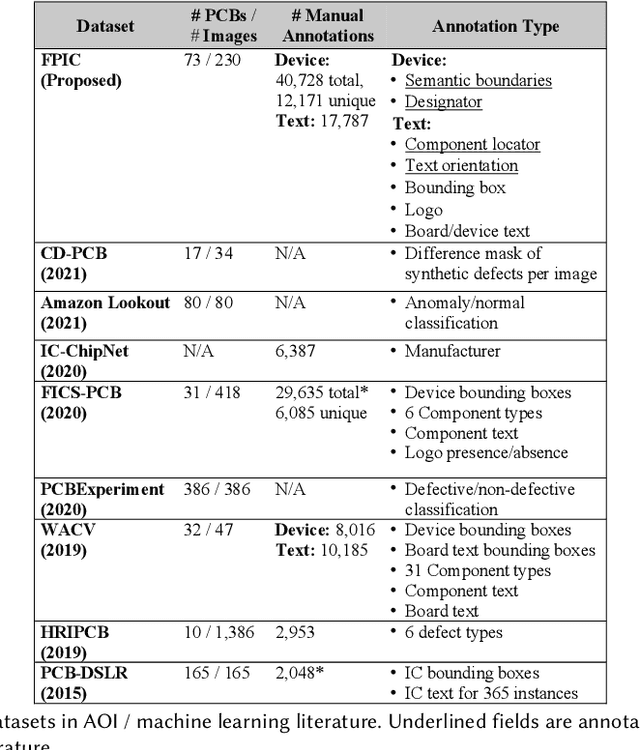
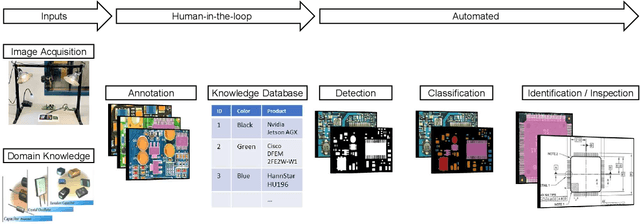
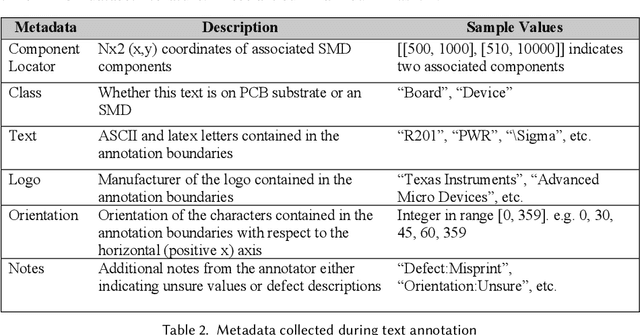
The continued outsourcing of printed circuit board (PCB) fabrication to overseas venues necessitates increased hardware assurance capabilities. Toward this end, several automated optical inspection (AOI) techniques have been proposed in the past exploring various aspects of PCB images acquired using digital cameras. In this work, we review state-of-the-art AOI techniques and observed the strong, rapid trend toward machine learning (ML) solutions. These require significant amounts of labeled ground truth data, which is lacking in the publicly available PCB data space. We propose the FICS PBC Image Collection (FPIC) dataset to address this bottleneck in available large-volume, diverse, semantic annotations. Additionally, this work covers the potential increase in hardware security capabilities and observed methodological distinctions highlighted during data collection.
Adversarially-regularized mixed effects deep learning (ARMED) models for improved interpretability, performance, and generalization on clustered data
Mar 28, 2022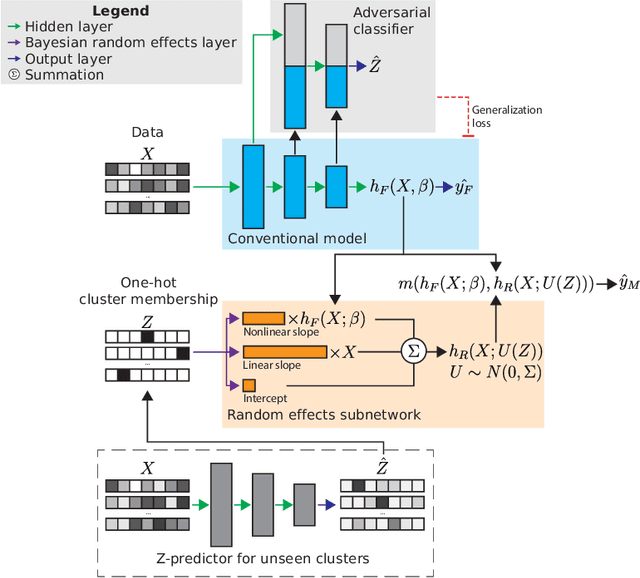
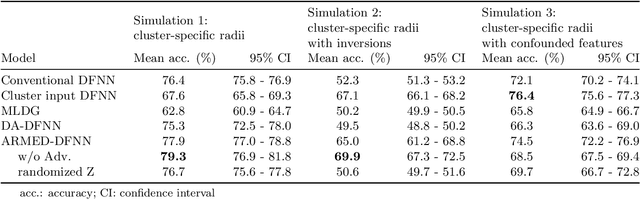
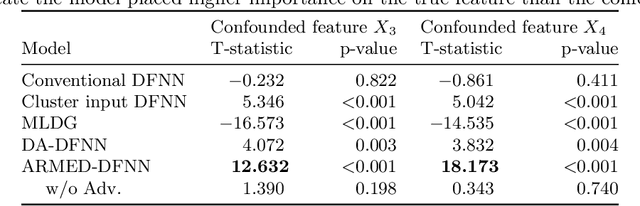
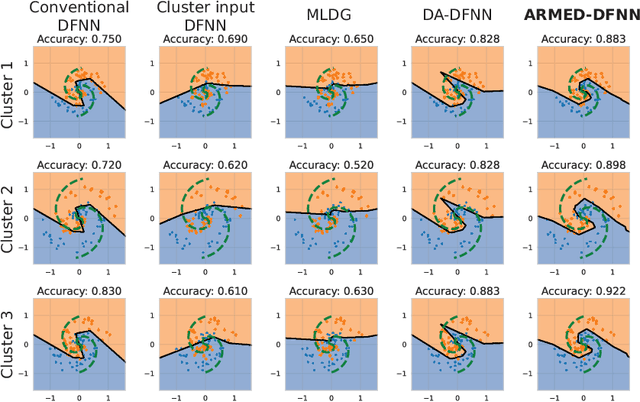
Data in the natural sciences frequently violate assumptions of independence. Such datasets have samples with inherent clustering (eg by study site, subject, experimental batch), leading to spurious associations, poor model fitting, and confounded analyses. While largely unaddressed in deep learning, this problem has been handled in the statistics community through mixed effects models. These models separate cluster-invariant, population-level fixed effects from cluster-specific random effects. We propose a general-purpose framework for Adversarially-Regularized Mixed Effects Deep learning (ARMED) models through three non-intrusive additions to existing neural networks: 1) a domain adversarial classifier constraining the original model to learn only cluster-invariant features, 2) a random effects subnetwork capturing cluster-specific features, and 3) an approach to apply random effects to clusters unseen during training. We apply ARMED to dense feedforward neural networks, convolutional neural networks, and autoencoders on 4 applications including classification of synthesized nonlinear data, dementia prognosis and diagnosis, and live-cell microscopy image analysis. We compare to conventional models, domain adversarial-only models, and the inclusion of cluster membership as an input covariate. ARMED models better distinguish confounded from true associations in synthetic data and emphasize more biologically plausible features in clinical applications. They also quantify inter-cluster variance in clinical data and can visualize batch effects in cell images. Finally, ARMED improves accuracy on data from clusters seen during training (up to 28% vs conventional models) and generalization to unseen clusters (up to 9% vs conventional models). By incorporating powerful mixed effects modeling into deep learning, ARMED increases interpretability, performance, and generalization on clustered data.
A Picture is Worth a Thousand Words: A Unified System for Diverse Captions and Rich Images Generation
Oct 19, 2021

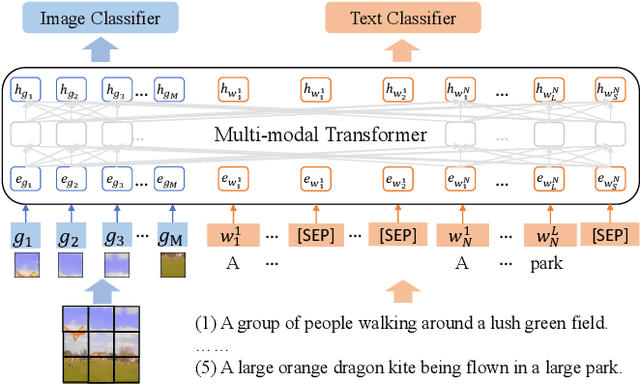
A creative image-and-text generative AI system mimics humans' extraordinary abilities to provide users with diverse and comprehensive caption suggestions, as well as rich image creations. In this work, we demonstrate such an AI creation system to produce both diverse captions and rich images. When users imagine an image and associate it with multiple captions, our system paints a rich image to reflect all captions faithfully. Likewise, when users upload an image, our system depicts it with multiple diverse captions. We propose a unified multi-modal framework to achieve this goal. Specifically, our framework jointly models image-and-text representations with a Transformer network, which supports rich image creation by accepting multiple captions as input. We consider the relations among input captions to encourage diversity in training and adopt a non-autoregressive decoding strategy to enable real-time inference. Based on these, our system supports both diverse captions and rich images generations. Our code is available online.