 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Applying adversarial networks to increase the data efficiency and reliability of Self-Driving Cars
Feb 16, 2022
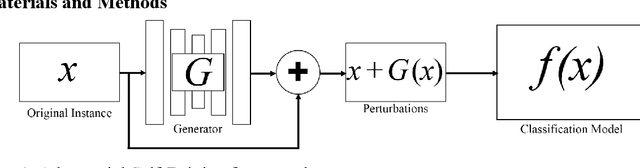

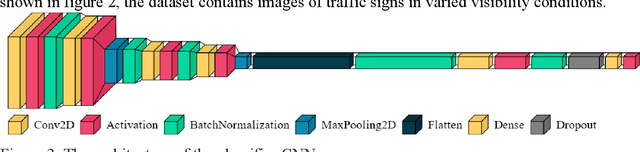
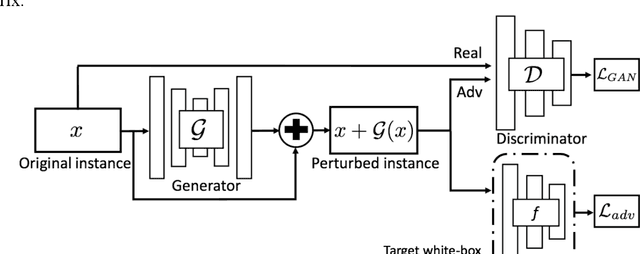
Convolutional Neural Networks (CNNs) are vulnerable to misclassifying images when small perturbations are present. With the increasing prevalence of CNNs in self-driving cars, it is vital to ensure these algorithms are robust to prevent collisions from occurring due to failure in recognizing a situation. In the Adversarial Self-Driving framework, a Generative Adversarial Network (GAN) is implemented to generate realistic perturbations in an image that cause a classifier CNN to misclassify data. This perturbed data is then used to train the classifier CNN further. The Adversarial Self-driving framework is applied to an image classification algorithm to improve the classification accuracy on perturbed images and is later applied to train a self-driving car to drive in a simulation. A small-scale self-driving car is also built to drive around a track and classify signs. The Adversarial Self-driving framework produces perturbed images through learning a dataset, as a result removing the need to train on significant amounts of data. Experiments demonstrate that the Adversarial Self-driving framework identifies situations where CNNs are vulnerable to perturbations and generates new examples of these situations for the CNN to train on. The additional data generated by the Adversarial Self-driving framework provides sufficient data for the CNN to generalize to the environment. Therefore, it is a viable tool to increase the resilience of CNNs to perturbations. Particularly, in the real-world self-driving car, the application of the Adversarial Self-Driving framework resulted in an 18 % increase in accuracy, and the simulated self-driving model had no collisions in 30 minutes of driving.
Context Autoencoder for Self-Supervised Representation Learning
Feb 07, 2022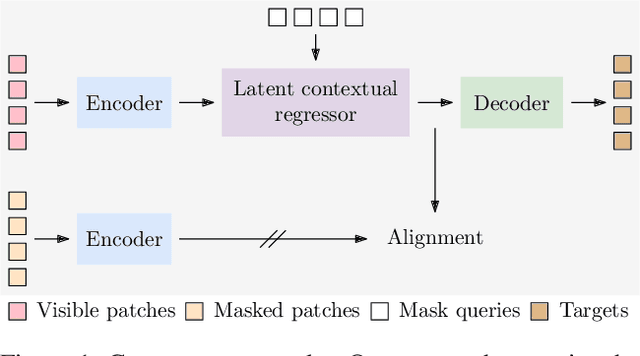
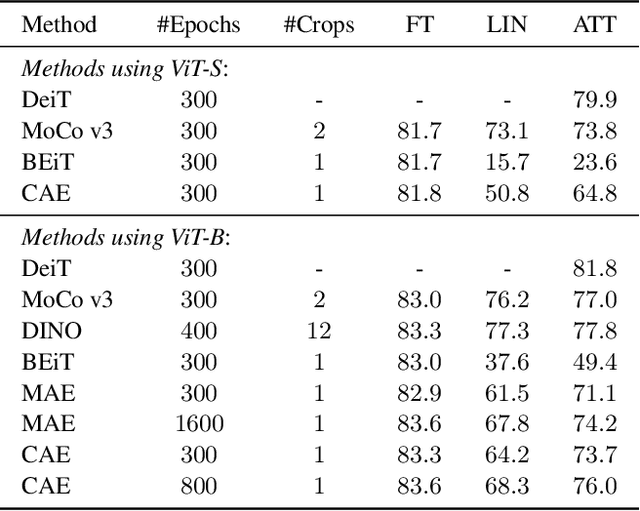


We present a novel masked image modeling (MIM) approach, context autoencoder (CAE), for self-supervised learning. We randomly partition the image into two sets: visible patches and masked patches. The CAE architecture consists of: (i) an encoder that takes visible patches as input and outputs their latent representations, (ii) a latent context regressor that predicts the masked patch representations from the visible patch representations that are not updated in this regressor, (iii) a decoder that takes the estimated masked patch representations as input and makes predictions for the masked patches, and (iv) an alignment module that aligns the masked patch representation estimation with the masked patch representations computed from the encoder. In comparison to previous MIM methods that couple the encoding and decoding roles, e.g., using a single module in BEiT, our approach attempts to~\emph{separate the encoding role (content understanding) from the decoding role (making predictions for masked patches)} using different modules, improving the content understanding capability. In addition, our approach makes predictions from the visible patches to the masked patches in \emph{the latent representation space} that is expected to take on semantics. In addition, we present the explanations about why contrastive pretraining and supervised pretraining perform similarly and why MIM potentially performs better. We demonstrate the effectiveness of our CAE through superior transfer performance in downstream tasks: semantic segmentation, and object detection and instance segmentation.
Temporal Transductive Inference for Few-Shot Video Object Segmentation
Mar 27, 2022
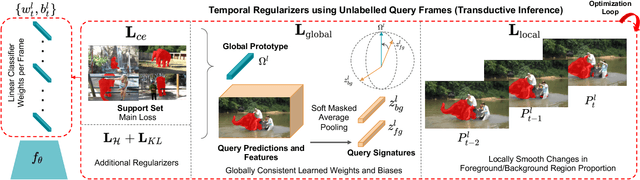
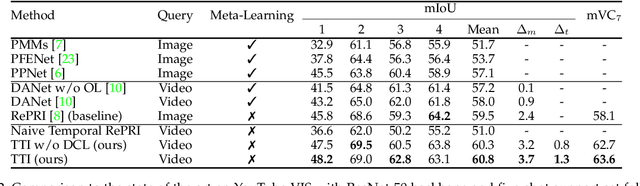
Few-shot video object segmentation (FS-VOS) aims at segmenting video frames using a few labelled examples of classes not seen during initial training. In this paper, we present a simple but effective temporal transductive inference (TTI) approach that leverages temporal consistency in the unlabelled video frames during few-shot inference. Key to our approach is the use of both global and local temporal constraints. The objective of the global constraint is to learn consistent linear classifiers for novel classes across the image sequence, whereas the local constraint enforces the proportion of foreground/background regions in each frame to be coherent across a local temporal window. These constraints act as spatiotemporal regularizers during the transductive inference to increase temporal coherence and reduce overfitting on the few-shot support set. Empirically, our model outperforms state-of-the-art meta-learning approaches in terms of mean intersection over union on YouTube-VIS by 2.8%. In addition, we introduce improved benchmarks that are exhaustively labelled (i.e. all object occurrences are labelled, unlike the currently available), and present a more realistic evaluation paradigm that targets data distribution shift between training and testing sets. Our empirical results and in-depth analysis confirm the added benefits of the proposed spatiotemporal regularizers to improve temporal coherence and overcome certain overfitting scenarios.
Characterizing and Understanding the Behavior of Quantized Models for Reliable Deployment
Apr 08, 2022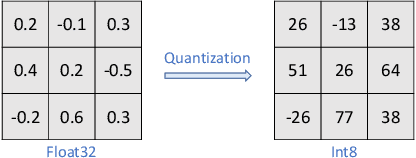
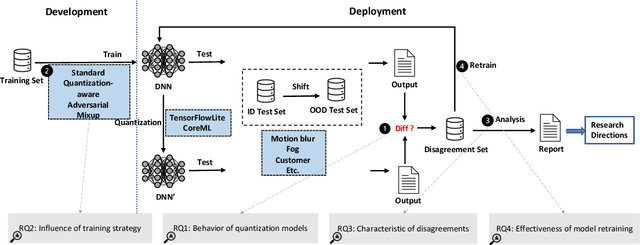
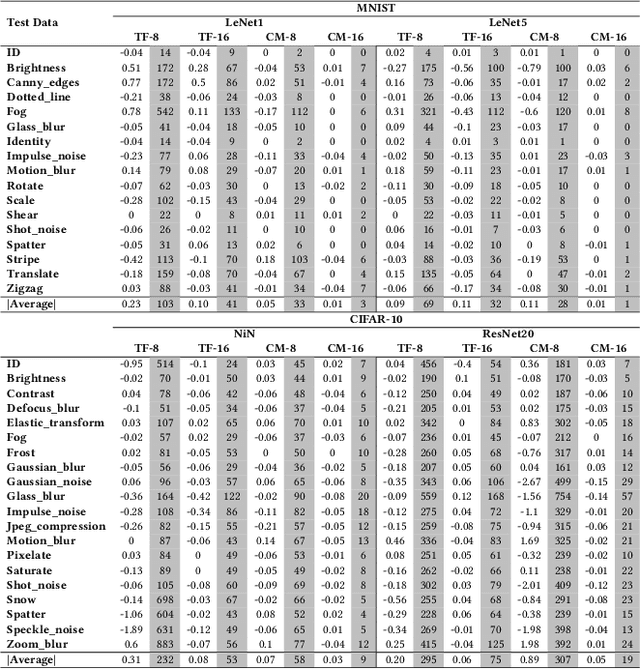
Deep Neural Networks (DNNs) have gained considerable attention in the past decades due to their astounding performance in different applications, such as natural language modeling, self-driving assistance, and source code understanding. With rapid exploration, more and more complex DNN architectures have been proposed along with huge pre-trained model parameters. The common way to use such DNN models in user-friendly devices (e.g., mobile phones) is to perform model compression before deployment. However, recent research has demonstrated that model compression, e.g., model quantization, yields accuracy degradation as well as outputs disagreements when tested on unseen data. Since the unseen data always include distribution shifts and often appear in the wild, the quality and reliability of quantized models are not ensured. In this paper, we conduct a comprehensive study to characterize and help users understand the behaviors of quantized models. Our study considers 4 datasets spanning from image to text, 8 DNN architectures including feed-forward neural networks and recurrent neural networks, and 42 shifted sets with both synthetic and natural distribution shifts. The results reveal that 1) data with distribution shifts happen more disagreements than without. 2) Quantization-aware training can produce more stable models than standard, adversarial, and Mixup training. 3) Disagreements often have closer top-1 and top-2 output probabilities, and $Margin$ is a better indicator than the other uncertainty metrics to distinguish disagreements. 4) Retraining with disagreements has limited efficiency in removing disagreements. We opensource our code and models as a new benchmark for further studying the quantized models.
Guided Deep Decoder: Unsupervised Image Pair Fusion
Jul 23, 2020
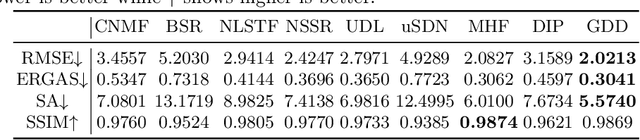
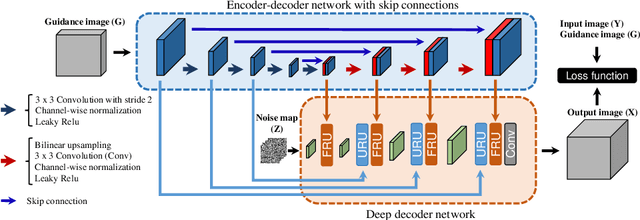
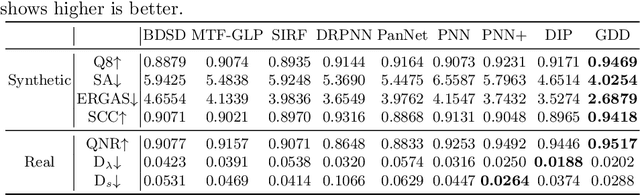
The fusion of input and guidance images that have a tradeoff in their information (e.g., hyperspectral and RGB image fusion or pansharpening) can be interpreted as one general problem. However, previous studies applied a task-specific handcrafted prior and did not address the problems with a unified approach. To address this limitation, in this study, we propose a guided deep decoder network as a general prior. The proposed network is composed of an encoder-decoder network that exploits multi-scale features of a guidance image and a deep decoder network that generates an output image. The two networks are connected by feature refinement units to embed the multi-scale features of the guidance image into the deep decoder network. The proposed network allows the network parameters to be optimized in an unsupervised way without training data. Our results show that the proposed network can achieve state-of-the-art performance in various image fusion problems.
Inertial Sensor Data To Image Encoding For Human Action Recognition
May 28, 2021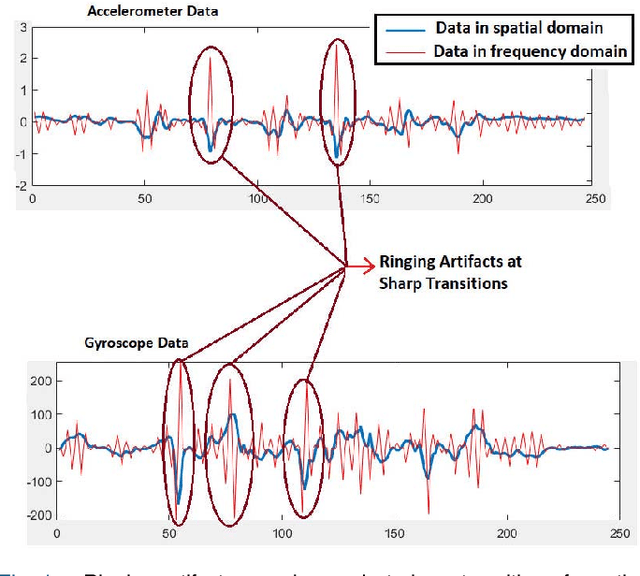
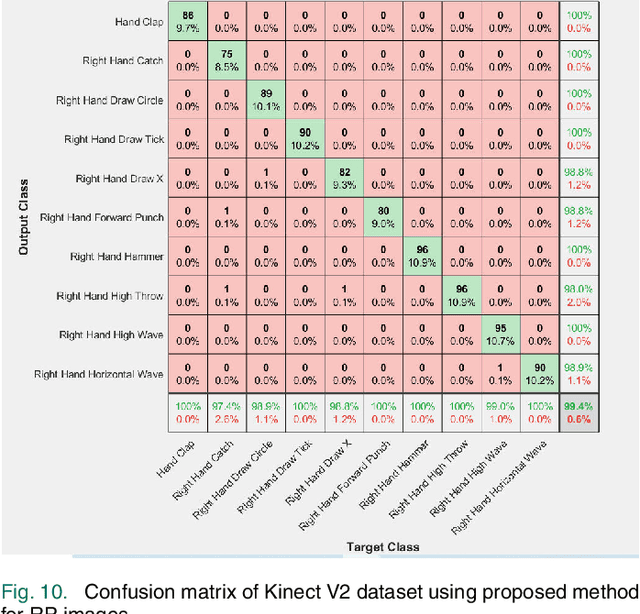
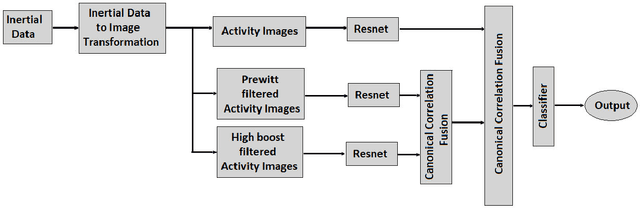

Convolutional Neural Networks (CNNs) are successful deep learning models in the field of computer vision. To get the maximum advantage of CNN model for Human Action Recognition (HAR) using inertial sensor data, in this paper, we use 4 types of spatial domain methods for transforming inertial sensor data to activity images, which are then utilized in a novel fusion framework. These four types of activity images are Signal Images (SI), Gramian Angular Field (GAF) Images, Markov Transition Field (MTF) Images and Recurrence Plot (RP) Images. Furthermore, for creating a multimodal fusion framework and to exploit activity image, we made each type of activity images multimodal by convolving with two spatial domain filters : Prewitt filter and High-boost filter. Resnet-18, a CNN model, is used to learn deep features from multi-modalities. Learned features are extracted from the last pooling layer of each ReNet and then fused by canonical correlation based fusion (CCF) for improving the accuracy of human action recognition. These highly informative features are served as input to a multiclass Support Vector Machine (SVM). Experimental results on three publicly available inertial datasets show the superiority of the proposed method over the current state-of-the-art.
Random Transformation of Image Brightness for Adversarial Attack
Jan 12, 2021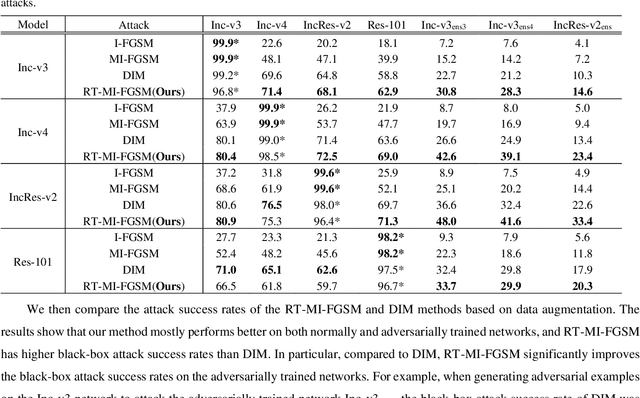
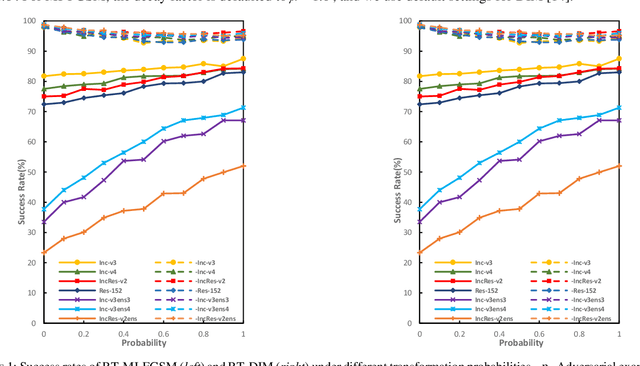
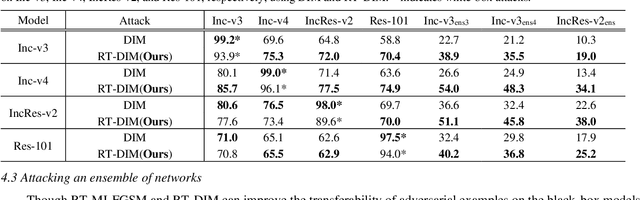
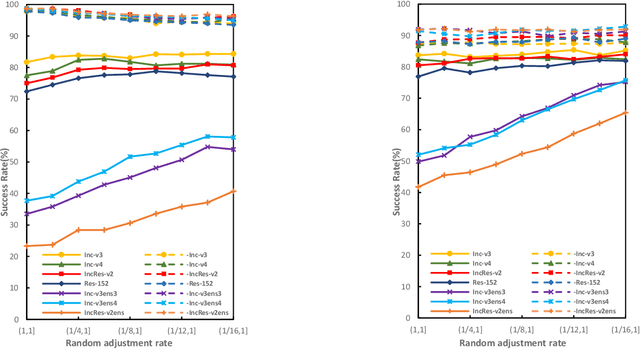
Deep neural networks are vulnerable to adversarial examples, which are crafted by adding small, human-imperceptible perturbations to the original images, but make the model output inaccurate predictions. Before deep neural networks are deployed, adversarial attacks can thus be an important method to evaluate and select robust models in safety-critical applications. However, under the challenging black-box setting, the attack success rate, i.e., the transferability of adversarial examples, still needs to be improved. Based on image augmentation methods, we found that random transformation of image brightness can eliminate overfitting in the generation of adversarial examples and improve their transferability. To this end, we propose an adversarial example generation method based on this phenomenon, which can be integrated with Fast Gradient Sign Method (FGSM)-related methods to build a more robust gradient-based attack and generate adversarial examples with better transferability. Extensive experiments on the ImageNet dataset demonstrate the method's effectiveness. Whether on normally or adversarially trained networks, our method has a higher success rate for black-box attacks than other attack methods based on data augmentation. We hope that this method can help to evaluate and improve the robustness of models.
3D Common Corruptions and Data Augmentation
Mar 02, 2022
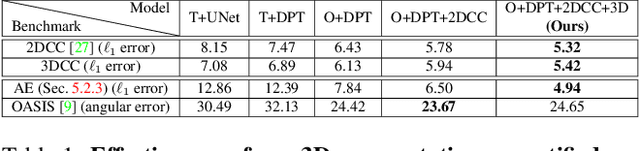

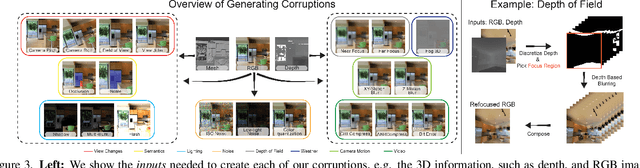
We introduce a set of image transformations that can be used as `corruptions' to evaluate the robustness of models as well as `data augmentation' mechanisms for training neural networks. The primary distinction of the proposed transformations is that, unlike existing approaches such as Common Corruptions, the geometry of the scene is incorporated in the transformations -- thus leading to corruptions that are more likely to occur in the real world. We show these transformations are `efficient' (can be computed on-the-fly), `extendable' (can be applied on most datasets of real images), expose vulnerability of existing models, and can effectively make models more robust when employed as `3D data augmentation' mechanisms. Our evaluations performed on several tasks and datasets suggest incorporating 3D information into robustness benchmarking and training opens up a promising direction for robustness research.
DiffuseVAE: Efficient, Controllable and High-Fidelity Generation from Low-Dimensional Latents
Jan 02, 2022
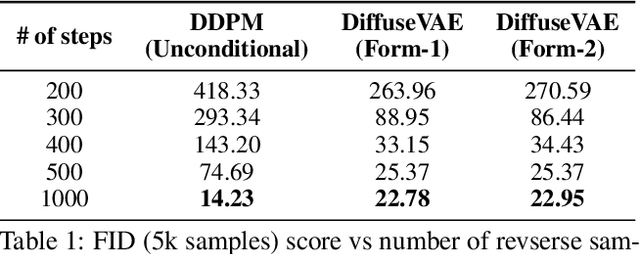
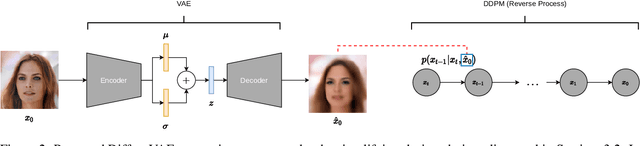
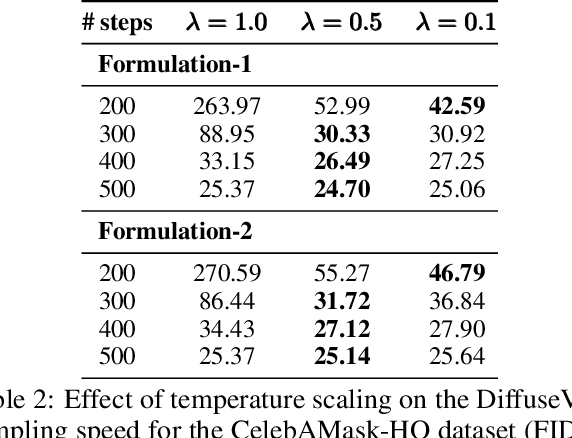
Diffusion Probabilistic models have been shown to generate state-of-the-art results on several competitive image synthesis benchmarks but lack a low-dimensional, interpretable latent space, and are slow at generation. On the other hand, Variational Autoencoders (VAEs) typically have access to a low-dimensional latent space but exhibit poor sample quality. Despite recent advances, VAEs usually require high-dimensional hierarchies of the latent codes to generate high-quality samples. We present DiffuseVAE, a novel generative framework that integrates VAE within a diffusion model framework, and leverage this to design a novel conditional parameterization for diffusion models. We show that the resulting model can improve upon the unconditional diffusion model in terms of sampling efficiency while also equipping diffusion models with the low-dimensional VAE inferred latent code. Furthermore, we show that the proposed model can generate high-resolution samples and exhibits synthesis quality comparable to state-of-the-art models on standard benchmarks. Lastly, we show that the proposed method can be used for controllable image synthesis and also exhibits out-of-the-box capabilities for downstream tasks like image super-resolution and denoising. For reproducibility, our source code is publicly available at \url{https://github.com/kpandey008/DiffuseVAE}.
Generalized Image Reconstruction over T-Algebra
Jan 20, 2021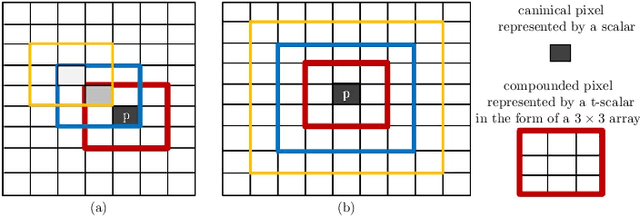
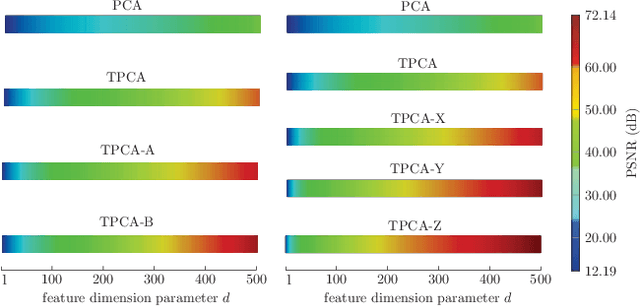
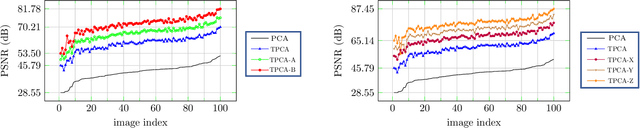
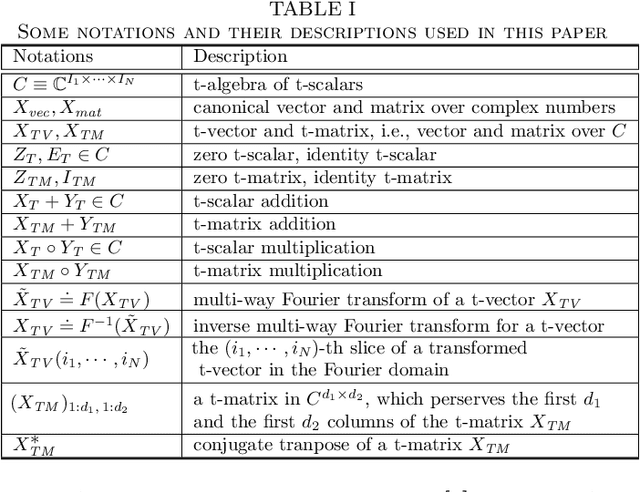
Principal Component Analysis (PCA) is well known for its capability of dimension reduction and data compression. However, when using PCA for compressing/reconstructing images, images need to be recast to vectors. The vectorization of images makes some correlation constraints of neighboring pixels and spatial information lost. To deal with the drawbacks of the vectorizations adopted by PCA, we used small neighborhoods of each pixel to form compounded pixels and use a tensorial version of PCA, called TPCA (Tensorial Principal Component Analysis), to compress and reconstruct a compounded image of compounded pixels. Our experiments on public data show that TPCA compares favorably with PCA in compressing and reconstructing images. We also show in our experiments that the performance of TPCA increases when the order of compounded pixels increases.