 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarial Patterns: Building Robust Android Malware Classifiers
Mar 04, 2022
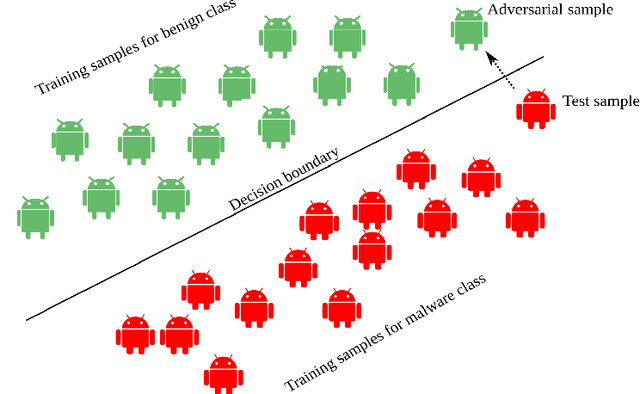

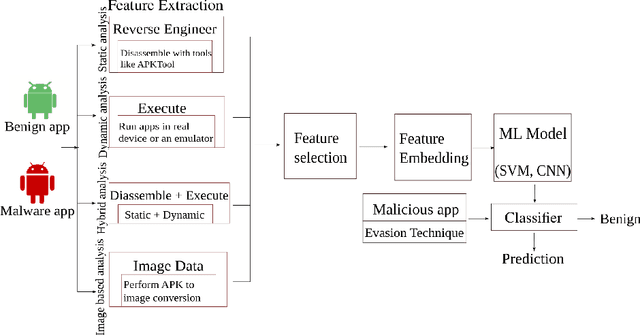
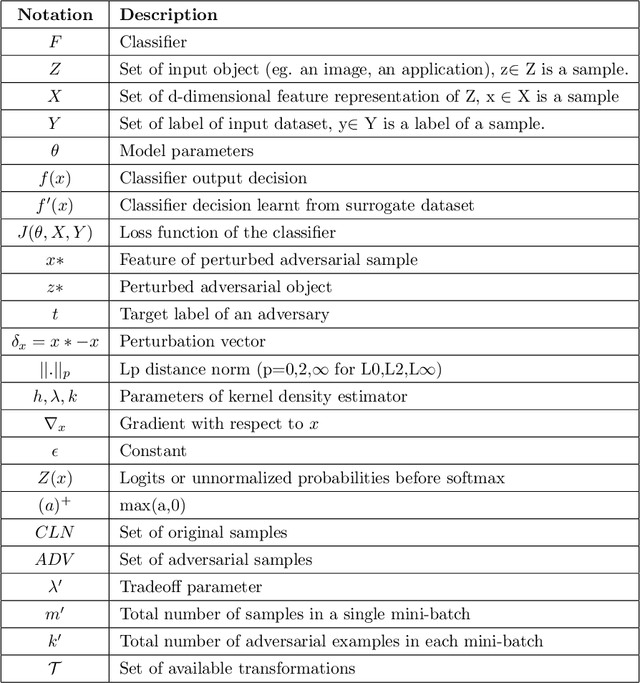
Deep learning-based classifiers have substantially improved recognition of malware samples. However, these classifiers can be vulnerable to adversarial input perturbations. Any vulnerability in malware classifiers poses significant threats to the platforms they defend. Therefore, to create stronger defense models against malware, we must understand the patterns in input perturbations caused by an adversary. This survey paper presents a comprehensive study on adversarial machine learning for android malware classifiers. We first present an extensive background in building a machine learning classifier for android malware, covering both image-based and text-based feature extraction approaches. Then, we examine the pattern and advancements in the state-of-the-art research in evasion attacks and defenses. Finally, we present guidelines for designing robust malware classifiers and enlist research directions for the future.
PhysGNN: A Physics-Driven Graph Neural Network Based Model for Predicting Soft Tissue Deformation in Image-Guided Neurosurgery
Sep 09, 2021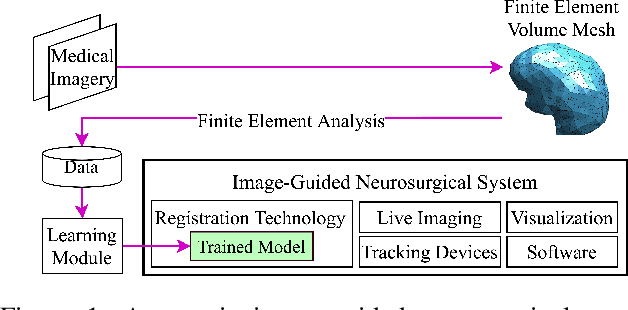



Correctly capturing intraoperative brain shift in image-guided neurosurgical procedures is a critical task for aligning preoperative data with intraoperative geometry, ensuring effective surgical navigation and optimal surgical precision. While the finite element method (FEM) is a proven technique to effectively approximate soft tissue deformation through biomechanical formulations, their degree of success boils down to a trade-off between accuracy and speed. To circumvent this problem, the most recent works in this domain have proposed leveraging data-driven models obtained by training various machine learning algorithms, e.g. random forests, artificial neural networks (ANNs), with the results of finite element analysis (FEA) to speed up tissue deformation approximations by prediction. These methods, however, do not account for the structure of the finite element (FE) mesh during training that provides information on node connectivities as well as the distance between them, which can aid with approximating tissue deformation based on the proximity of force load points with the rest of the mesh nodes. Therefore, this work proposes a novel framework, PhysGNN, a data-driven model that approximates the solution of FEA by leveraging graph neural networks (GNNs), which are capable of accounting for the mesh structural information and inductive learning over unstructured grids and complex topological structures. Empirically, we demonstrate that the proposed architecture, PhysGNN, promises accurate and fast soft tissue deformation approximations while remaining computationally feasible, suitable for neurosurgical settings.
SwapMix: Diagnosing and Regularizing the Over-Reliance on Visual Context in Visual Question Answering
Apr 05, 2022

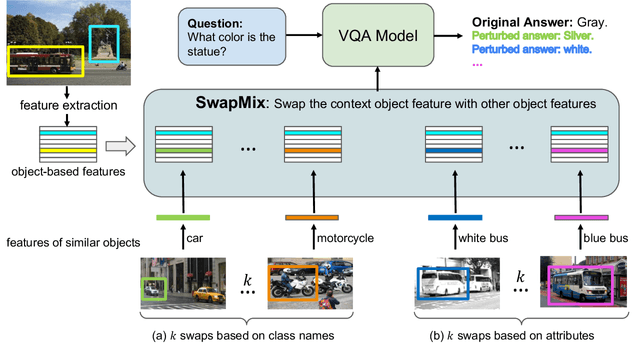
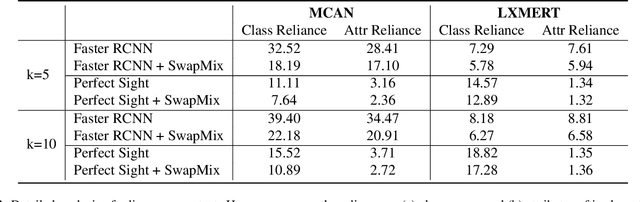
While Visual Question Answering (VQA) has progressed rapidly, previous works raise concerns about robustness of current VQA models. In this work, we study the robustness of VQA models from a novel perspective: visual context. We suggest that the models over-rely on the visual context, i.e., irrelevant objects in the image, to make predictions. To diagnose the model's reliance on visual context and measure their robustness, we propose a simple yet effective perturbation technique, SwapMix. SwapMix perturbs the visual context by swapping features of irrelevant context objects with features from other objects in the dataset. Using SwapMix we are able to change answers to more than 45 % of the questions for a representative VQA model. Additionally, we train the models with perfect sight and find that the context over-reliance highly depends on the quality of visual representations. In addition to diagnosing, SwapMix can also be applied as a data augmentation strategy during training in order to regularize the context over-reliance. By swapping the context object features, the model reliance on context can be suppressed effectively. Two representative VQA models are studied using SwapMix: a co-attention model MCAN and a large-scale pretrained model LXMERT. Our experiments on the popular GQA dataset show the effectiveness of SwapMix for both diagnosing model robustness and regularizing the over-reliance on visual context. The code for our method is available at https://github.com/vipulgupta1011/swapmix
A study on joint modeling and data augmentation of multi-modalities for audio-visual scene classification
Mar 07, 2022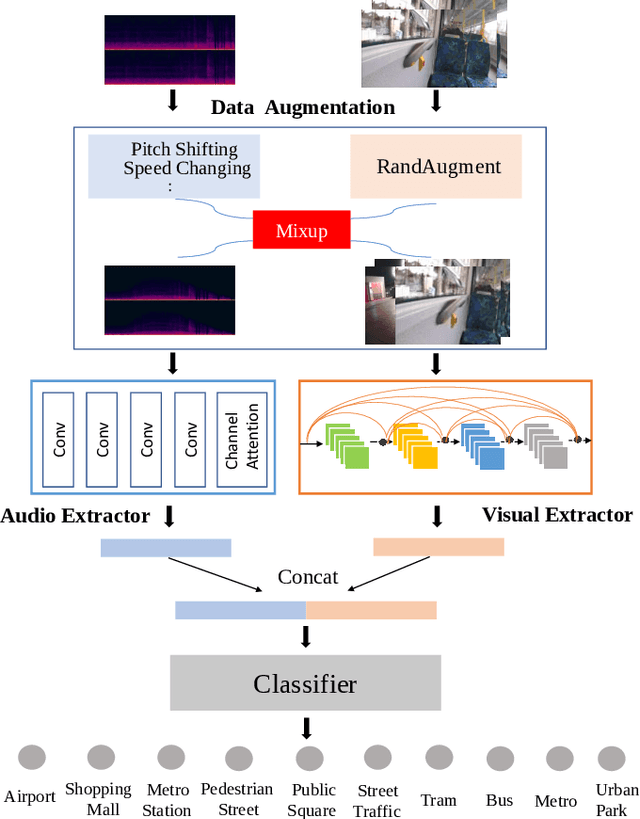
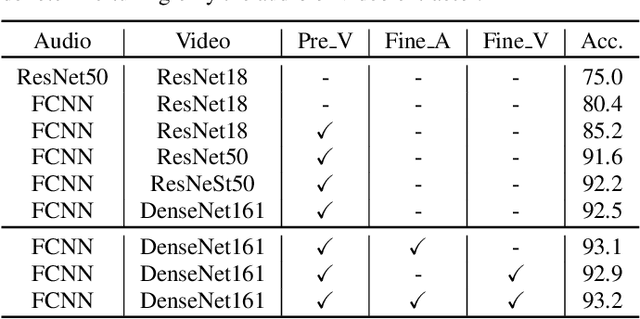
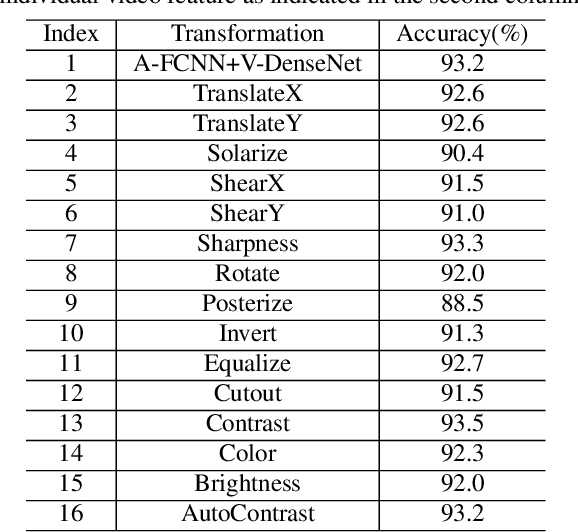
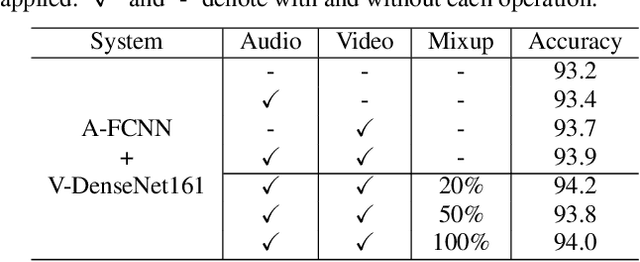
In this paper, we propose two techniques, namely joint modeling and data augmentation, to improve system performances for audio-visual scene classification (AVSC). We employ pre-trained networks trained only on image data sets to extract video embedding; whereas for audio embedding models, we decide to train them from scratch. We explore different neural network architectures for joint modeling to effectively combine the video and audio modalities. Moreover, data augmentation strategies are investigated to increase audio-visual training set size. For the video modality the effectiveness of several operations in RandAugment is verified. An audio-video joint mixup scheme is proposed to further improve AVSC performances. Evaluated on the development set of TAU Urban Audio Visual Scenes 2021, our final system can achieve the best accuracy of 94.2% among all single AVSC systems submitted to DCASE 2021 Task 1b.
A deep learning framework for the detection and quantification of drusen and reticular pseudodrusen on optical coherence tomography
Apr 05, 2022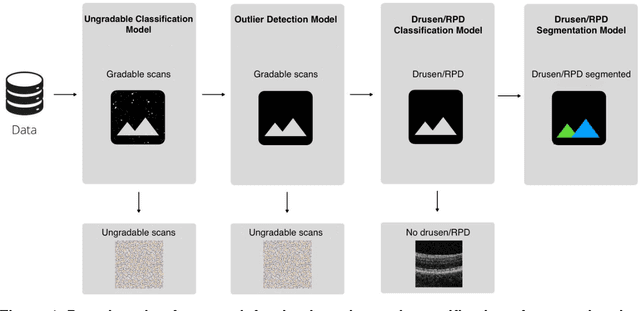
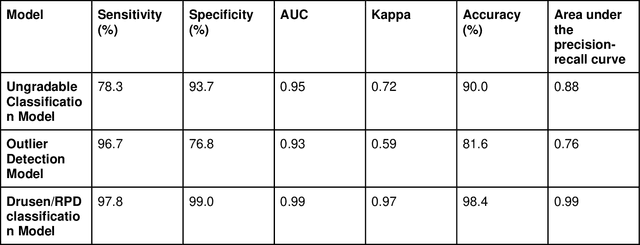
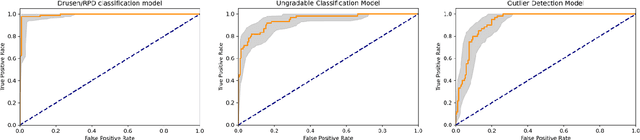

Purpose - To develop and validate a deep learning (DL) framework for the detection and quantification of drusen and reticular pseudodrusen (RPD) on optical coherence tomography scans. Design - Development and validation of deep learning models for classification and feature segmentation. Methods - A DL framework was developed consisting of a classification model and an out-of-distribution (OOD) detection model for the identification of ungradable scans; a classification model to identify scans with drusen or RPD; and an image segmentation model to independently segment lesions as RPD or drusen. Data were obtained from 1284 participants in the UK Biobank (UKBB) with a self-reported diagnosis of age-related macular degeneration (AMD) and 250 UKBB controls. Drusen and RPD were manually delineated by five retina specialists. The main outcome measures were sensitivity, specificity, area under the ROC curve (AUC), kappa, accuracy and intraclass correlation coefficient (ICC). Results - The classification models performed strongly at their respective tasks (0.95, 0.93, and 0.99 AUC, respectively, for the ungradable scans classifier, the OOD model, and the drusen and RPD classification model). The mean ICC for drusen and RPD area vs. graders was 0.74 and 0.61, respectively, compared with 0.69 and 0.68 for intergrader agreement. FROC curves showed that the model's sensitivity was close to human performance. Conclusions - The models achieved high classification and segmentation performance, similar to human performance. Application of this robust framework will further our understanding of RPD as a separate entity from drusen in both research and clinical settings.
Blind Image Restoration with Flow Based Priors
Sep 09, 2020
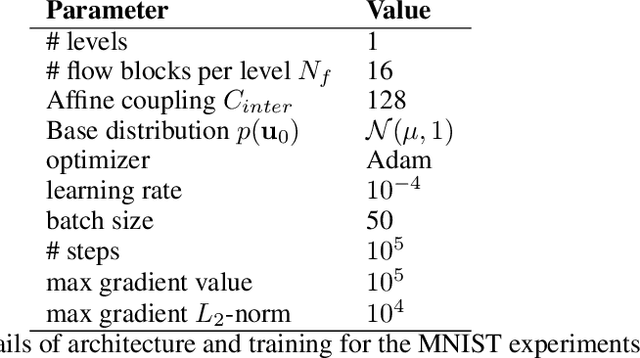
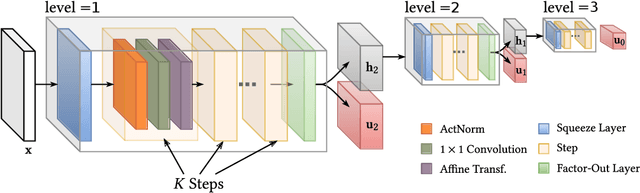

Image restoration has seen great progress in the last years thanks to the advances in deep neural networks. Most of these existing techniques are trained using full supervision with suitable image pairs to tackle a specific degradation. However, in a blind setting with unknown degradations this is not possible and a good prior remains crucial. Recently, neural network based approaches have been proposed to model such priors by leveraging either denoising autoencoders or the implicit regularization captured by the neural network structure itself. In contrast to this, we propose using normalizing flows to model the distribution of the target content and to use this as a prior in a maximum a posteriori (MAP) formulation. By expressing the MAP optimization process in the latent space through the learned bijective mapping, we are able to obtain solutions through gradient descent. To the best of our knowledge, this is the first work that explores normalizing flows as prior in image enhancement problems. Furthermore, we present experimental results for a number of different degradations on data sets varying in complexity and show competitive results when comparing with the deep image prior approach.
Bayesian Low-rank Matrix Completion with Dual-graph Embedding: Prior Analysis and Tuning-free Inference
Mar 18, 2022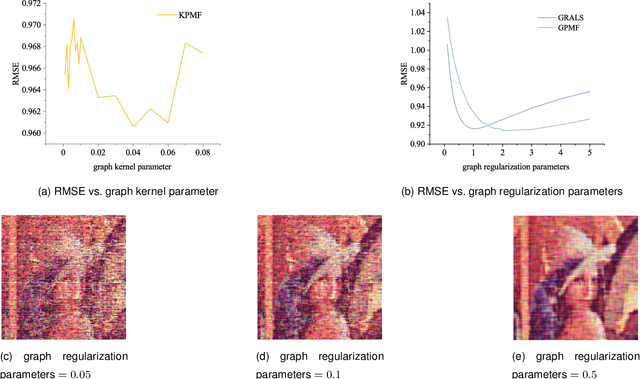
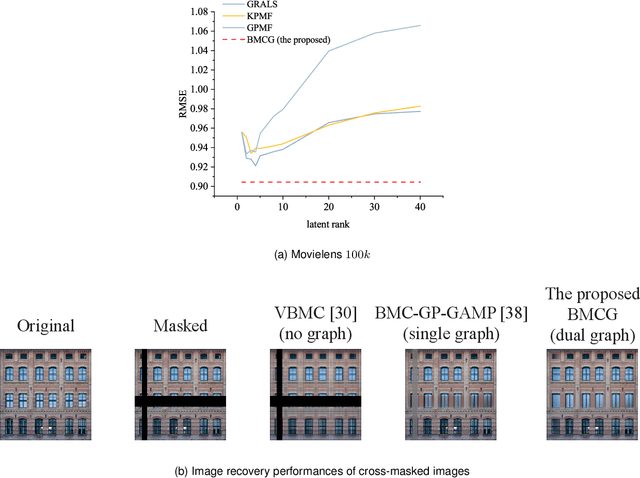
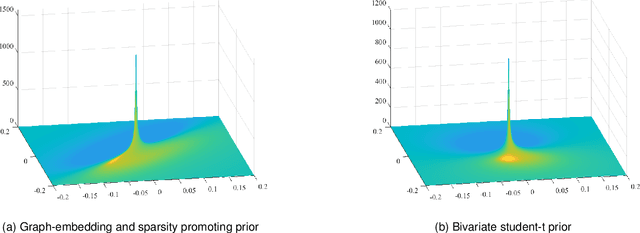
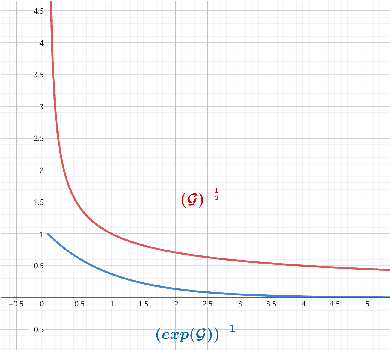
Recently, there is a revival of interest in low-rank matrix completion-based unsupervised learning through the lens of dual-graph regularization, which has significantly improved the performance of multidisciplinary machine learning tasks such as recommendation systems, genotype imputation and image inpainting. While the dual-graph regularization contributes a major part of the success, computational costly hyper-parameter tunning is usually involved. To circumvent such a drawback and improve the completion performance, we propose a novel Bayesian learning algorithm that automatically learns the hyper-parameters associated with dual-graph regularization, and at the same time, guarantees the low-rankness of matrix completion. Notably, a novel prior is devised to promote the low-rankness of the matrix and encode the dual-graph information simultaneously, which is more challenging than the single-graph counterpart. A nontrivial conditional conjugacy between the proposed priors and likelihood function is then explored such that an efficient algorithm is derived under variational inference framework. Extensive experiments using synthetic and real-world datasets demonstrate the state-of-the-art performance of the proposed learning algorithm for various data analysis tasks.
Pyramid Feature Alignment Network for Video Deblurring
Mar 28, 2022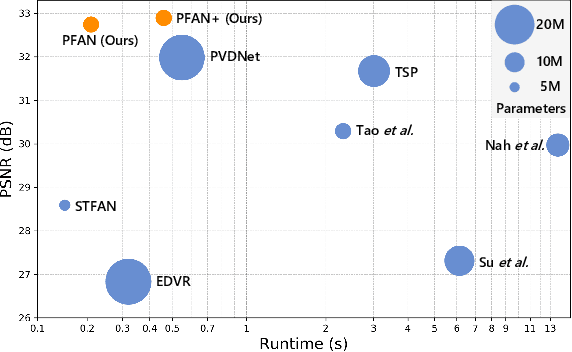
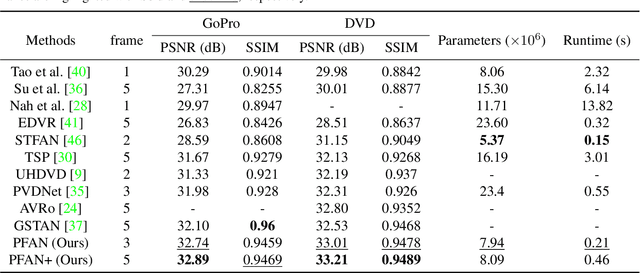
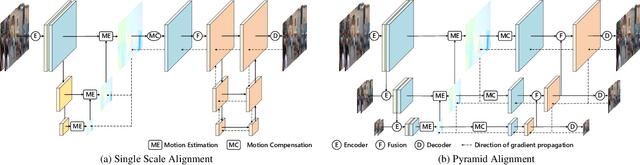

Video deblurring remains a challenging task due to various causes of blurring. Traditional methods have considered how to utilize neighboring frames by the single-scale alignment for restoration. However, they typically suffer from misalignment caused by severe blur. In this work, we aim to better utilize neighboring frames with high efficient feature alignment. We propose a Pyramid Feature Alignment Network (PFAN) for video deblurring. First, the multi-scale feature of blurry frames is extracted with the strategy of Structure-to-Detail Downsampling (SDD) before alignment. This downsampling strategy makes the edges sharper, which is helpful for alignment. Then we align the feature at each scale and reconstruct the image at the corresponding scale. This strategy effectively supervises the alignment at each scale, overcoming the problem of propagated errors from the above scales at the alignment stage. To better handle the challenges of complex and large motions, instead of aligning features at each scale separately, lower-scale motion information is used to guide the higher-scale motion estimation. Accordingly, a Cascade Guided Deformable Alignment (CGDA) is proposed to integrate coarse motion into deformable convolution for finer and more accurate alignment. As demonstrated in extensive experiments, our proposed PFAN achieves superior performance with competitive speed compared to the state-of-the-art methods.
VT-ADL: A Vision Transformer Network for Image Anomaly Detection and Localization
Apr 20, 2021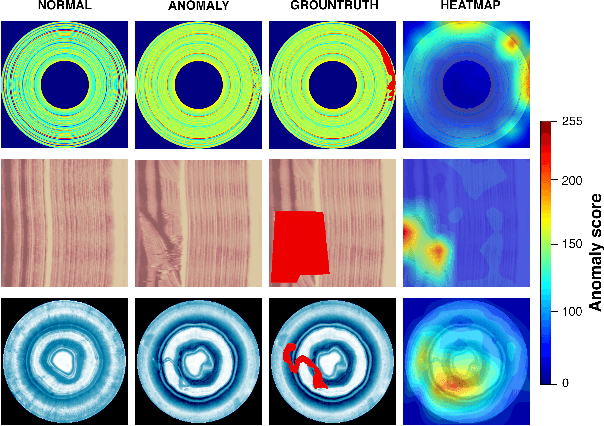
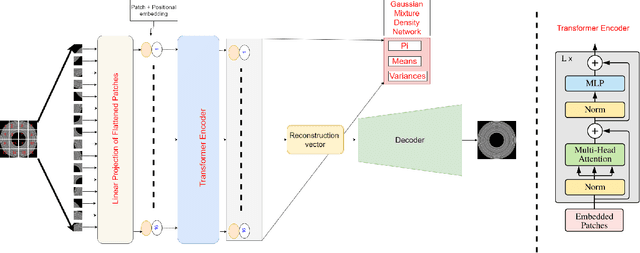

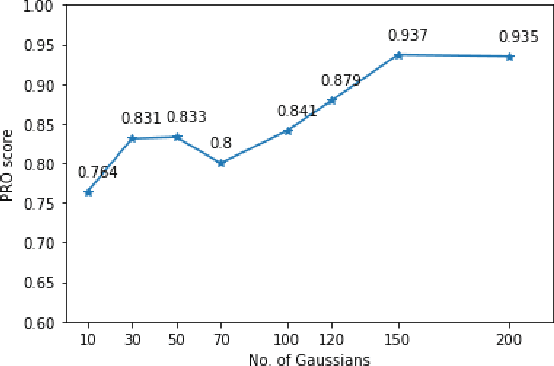
We present a transformer-based image anomaly detection and localization network. Our proposed model is a combination of a reconstruction-based approach and patch embedding. The use of transformer networks helps to preserve the spatial information of the embedded patches, which are later processed by a Gaussian mixture density network to localize the anomalous areas. In addition, we also publish BTAD, a real-world industrial anomaly dataset. Our results are compared with other state-of-the-art algorithms using publicly available datasets like MNIST and MVTec.
* 6 Pages, 4 images, conference published paper
Weakly Supervised Regional and Temporal Learning for Facial Action Unit Recognition
Apr 01, 2022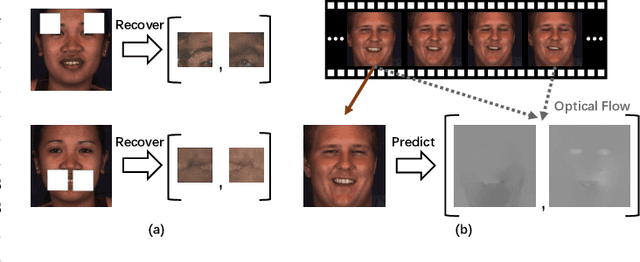
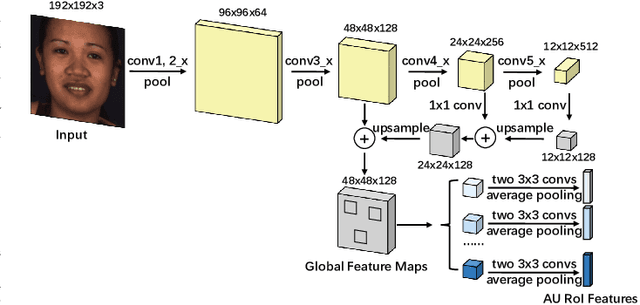
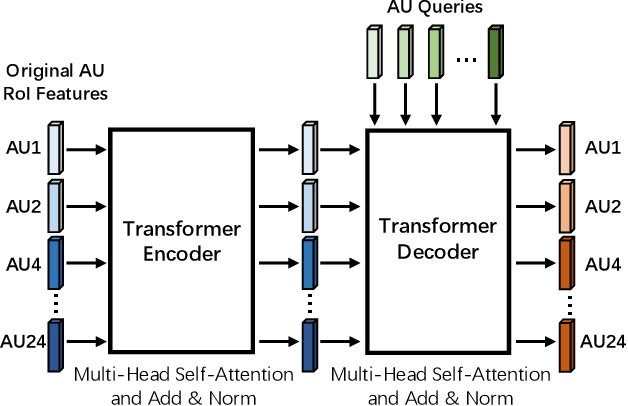
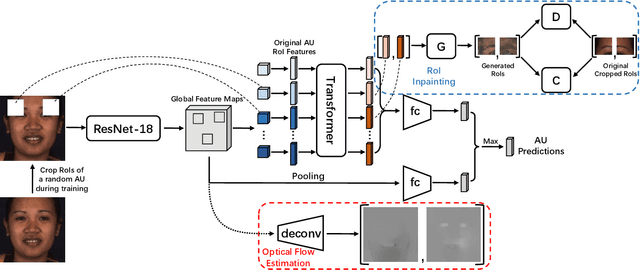
Automatic facial action unit (AU) recognition is a challenging task due to the scarcity of manual annotations. To alleviate this problem, a large amount of efforts has been dedicated to exploiting various weakly supervised methods which leverage numerous unlabeled data. However, many aspects with regard to some unique properties of AUs, such as the regional and relational characteristics, are not sufficiently explored in previous works. Motivated by this, we take the AU properties into consideration and propose two auxiliary AU related tasks to bridge the gap between limited annotations and the model performance in a self-supervised manner via the unlabeled data. Specifically, to enhance the discrimination of regional features with AU relation embedding, we design a task of RoI inpainting to recover the randomly cropped AU patches. Meanwhile, a single image based optical flow estimation task is proposed to leverage the dynamic change of facial muscles and encode the motion information into the global feature representation. Based on these two self-supervised auxiliary tasks, local features, mutual relation and motion cues of AUs are better captured in the backbone network. Furthermore, by incorporating semi-supervised learning, we propose an end-to-end trainable framework named weakly supervised regional and temporal learning (WSRTL) for AU recognition. Extensive experiments on BP4D and DISFA demonstrate the superiority of our method and new state-of-the-art performances are achieved.