 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Feature-enhanced Adversarial Semi-supervised Semantic Segmentation Network for Pulmonary Embolism Annotation
Apr 08, 2022
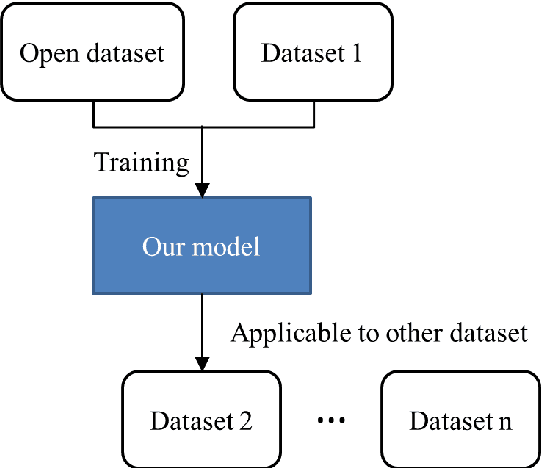
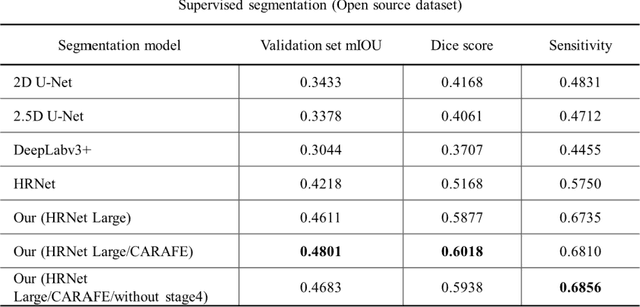
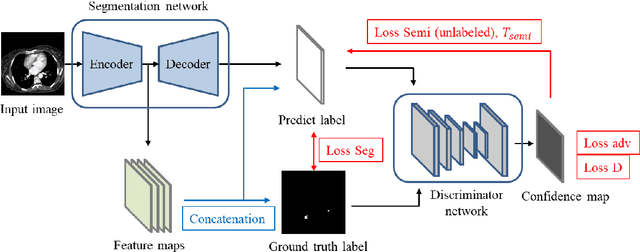
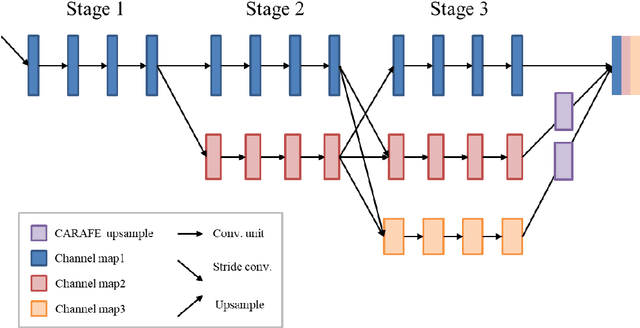
This study established a feature-enhanced adversarial semi-supervised semantic segmentation model to automatically annotate pulmonary embolism lesion areas in computed tomography pulmonary angiogram (CTPA) images. In current studies, all of the PE CTPA image segmentation methods are trained by supervised learning. However, the supervised learning models need to be retrained and the images need to be relabeled when the CTPA images come from different hospitals. This study proposed a semi-supervised learning method to make the model applicable to different datasets by adding a small amount of unlabeled images. By training the model with both labeled and unlabeled images, the accuracy of unlabeled images can be improved and the labeling cost can be reduced. Our semi-supervised segmentation model includes a segmentation network and a discriminator network. We added feature information generated from the encoder of segmentation network to the discriminator so that it can learn the similarity between predicted mask and ground truth mask. This HRNet-based architecture can maintain a higher resolution for convolutional operations so the prediction of small PE lesion areas can be improved. We used the labeled open-source dataset and the unlabeled National Cheng Kung University Hospital (NCKUH) (IRB number: B-ER-108-380) dataset to train the semi-supervised learning model, and the resulting mean intersection over union (mIOU), dice score, and sensitivity achieved 0.3510, 0.4854, and 0.4253, respectively on the NCKUH dataset. Then, we fine-tuned and tested the model with a small amount of unlabeled PE CTPA images from China Medical University Hospital (CMUH) (IRB number: CMUH110-REC3-173) dataset. Comparing the results of our semi-supervised model with the supervised model, the mIOU, dice score, and sensitivity improved from 0.2344, 0.3325, and 0.3151 to 0.3721, 0.5113, and 0.4967, respectively.
Animatable Neural Implicit Surfaces for Creating Avatars from Videos
Mar 15, 2022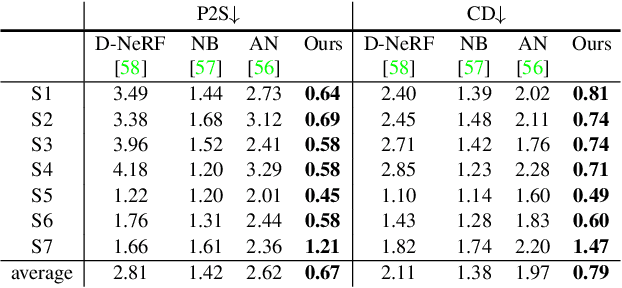
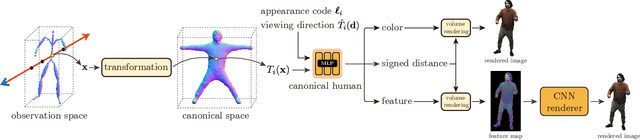
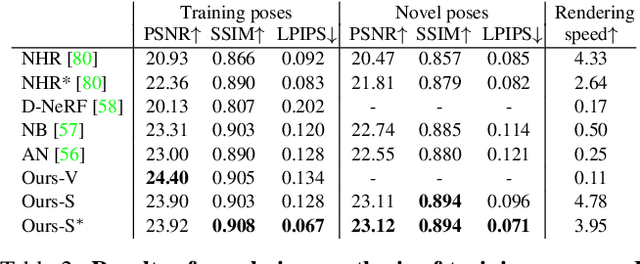
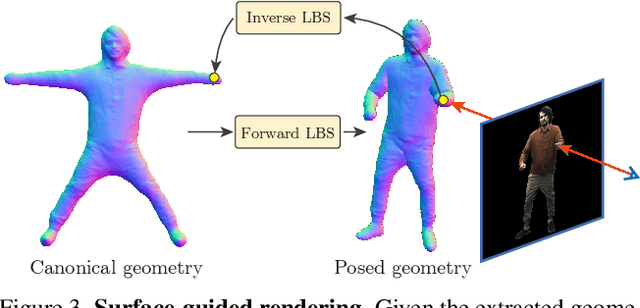
This paper aims to reconstruct an animatable human model from a video of very sparse camera views. Some recent works represent human geometry and appearance with neural radiance fields and utilize parametric human models to produce deformation fields for animation, which enables them to recover detailed 3D human models from videos. However, their reconstruction results tend to be noisy due to the lack of surface constraints on radiance fields. Moreover, as they generate the human appearance in 3D space, their rendering quality heavily depends on the accuracy of deformation fields. To solve these problems, we propose Animatable Neural Implicit Surface (AniSDF), which models the human geometry with a signed distance field and defers the appearance generation to the 2D image space with a 2D neural renderer. The signed distance field naturally regularizes the learned geometry, enabling the high-quality reconstruction of human bodies, which can be further used to improve the rendering speed. Moreover, the 2D neural renderer can be learned to compensate for geometric errors, making the rendering more robust to inaccurate deformations. Experiments on several datasets show that the proposed approach outperforms recent human reconstruction and synthesis methods by a large margin.
GANHopper: Multi-Hop GAN for Unsupervised Image-to-Image Translation
Feb 29, 2020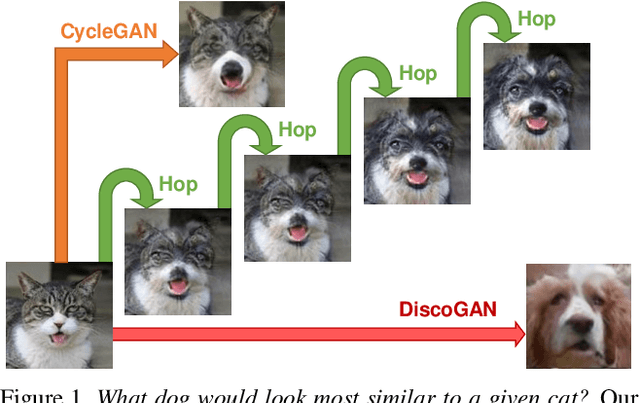
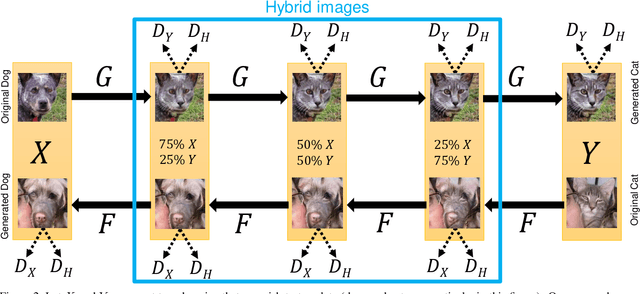
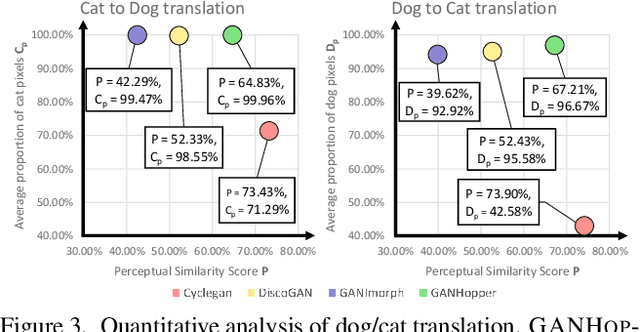
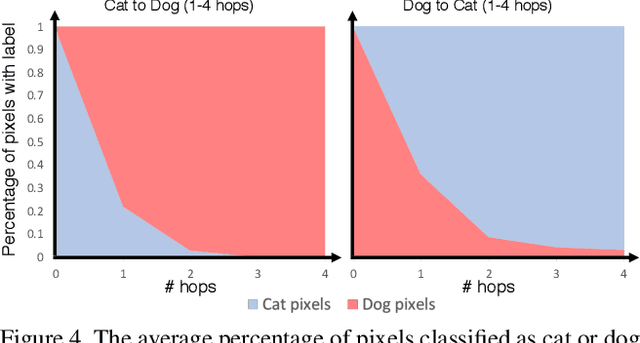
We introduce GANHopper, an unsupervised image-to-image translation network that transforms images gradually between two domains, through multiple hops. Instead of executing translation directly, we steer the translation by requiring the network to produce in-between images which resemble weighted hybrids between images from the two in-put domains. Our network is trained on unpaired images from the two domains only, without any in-between images.All hops are produced using a single generator along each direction. In addition to the standard cycle-consistency and adversarial losses, we introduce a new hybrid discrimina-tor, which is trained to classify the intermediate images produced by the generator as weighted hybrids, with weights based on a predetermined hop count. We also introduce a smoothness term to constrain the magnitude of each hop,further regularizing the translation. Compared to previous methods, GANHopper excels at image translations involving domain-specific image features and geometric variations while also preserving non-domain-specific features such as backgrounds and general color schemes.
SSCAN: A Spatial-spectral Cross Attention Network for Hyperspectral Image Denoising
May 23, 2021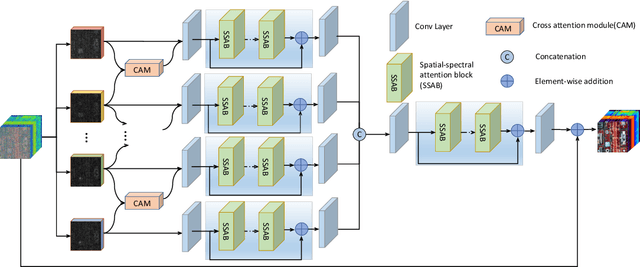
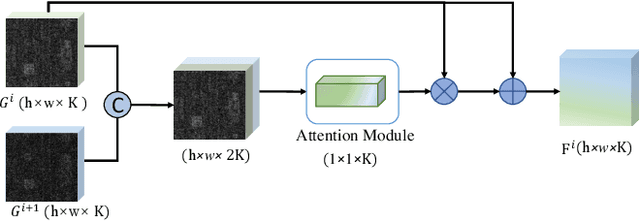
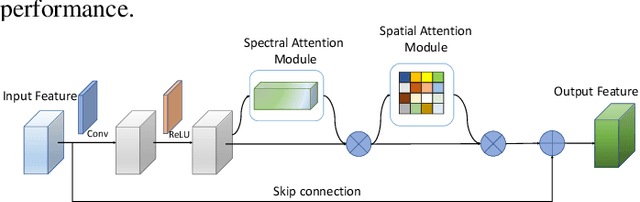
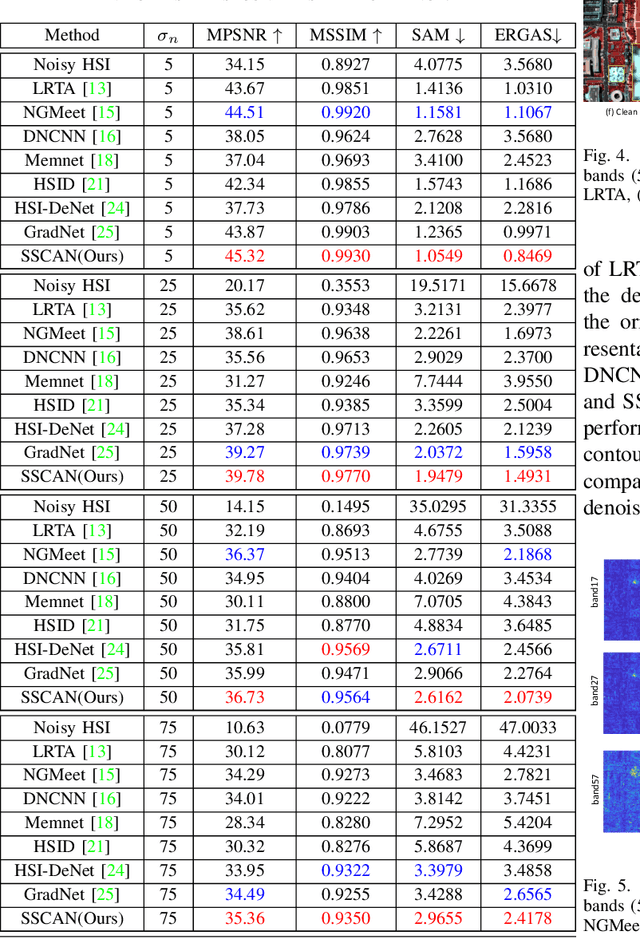
Hyperspectral images (HSIs) have been widely used in a variety of applications thanks to the rich spectral information they are able to provide. Among all HSI processing tasks, HSI denoising is a crucial step. Recently, deep learning-based image denoising methods have made great progress and achieved great performance. However, existing methods tend to ignore the correlations between adjacent spectral bands, leading to problems such as spectral distortion and blurred edges in denoised results. In this study, we propose a novel HSI denoising network, termed SSCAN, that combines group convolutions and attention modules. Specifically, we use a group convolution with a spatial attention module to facilitate feature extraction by directing models' attention to band-wise important features. We propose a spectral-spatial attention block (SSAB) to exploit the spatial and spectral information in hyperspectral images in an effective manner. In addition, we adopt residual learning operations with skip connections to ensure training stability. The experimental results indicate that the proposed SSCAN outperforms several state-of-the-art HSI denoising algorithms.
A Simple Baseline for Zero-shot Semantic Segmentation with Pre-trained Vision-language Model
Dec 29, 2021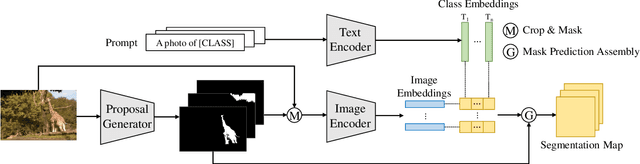
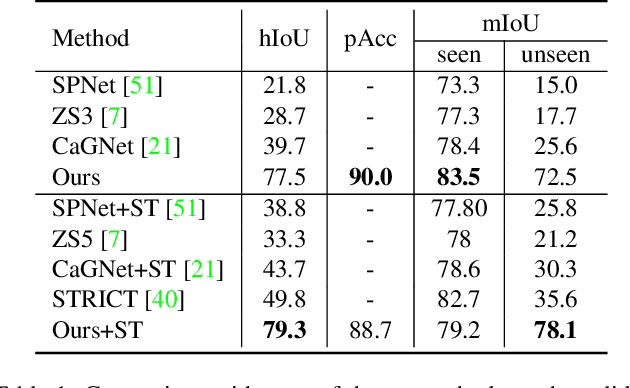

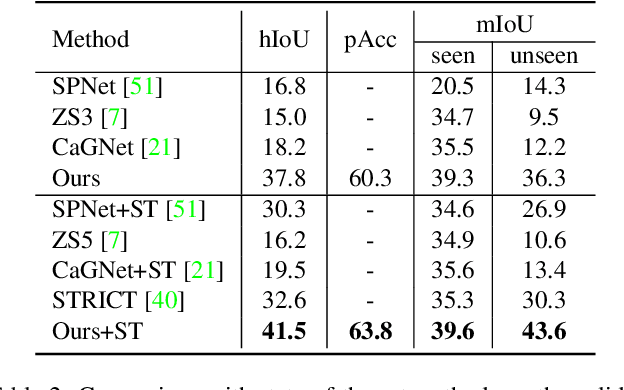
Recently, zero-shot image classification by vision-language pre-training has demonstrated incredible achievements, that the model can classify arbitrary category without seeing additional annotated images of that category. However, it is still unclear how to make the zero-shot recognition working well on broader vision problems, such as object detection and semantic segmentation. In this paper, we target for zero-shot semantic segmentation, by building it on an off-the-shelf pre-trained vision-language model, i.e., CLIP. It is difficult because semantic segmentation and the CLIP model perform on different visual granularity, that semantic segmentation processes on pixels while CLIP performs on images. To remedy the discrepancy on processing granularity, we refuse the use of the prevalent one-stage FCN based framework, and advocate a two-stage semantic segmentation framework, with the first stage extracting generalizable mask proposals and the second stage leveraging an image based CLIP model to perform zero-shot classification on the masked image crops which are generated in the first stage. Our experimental results show that this simple framework surpasses previous state-of-the-arts by a large margin: +29.5 hIoU on the Pascal VOC 2012 dataset, and +8.9 hIoU on the COCO Stuff dataset. With its simplicity and strong performance, we hope this framework to serve as a baseline to facilitate the future research.
The First Principles of Deep Learning and Compression
Apr 04, 2022The deep learning revolution incited by the 2012 Alexnet paper has been transformative for the field of computer vision. Many problems which were severely limited using classical solutions are now seeing unprecedented success. The rapid proliferation of deep learning methods has led to a sharp increase in their use in consumer and embedded applications. One consequence of consumer and embedded applications is lossy multimedia compression which is required to engineer the efficient storage and transmission of data in these real-world scenarios. As such, there has been increased interest in a deep learning solution for multimedia compression which would allow for higher compression ratios and increased visual quality. The deep learning approach to multimedia compression, so called Learned Multimedia Compression, involves computing a compressed representation of an image or video using a deep network for the encoder and the decoder. While these techniques have enjoyed impressive academic success, their industry adoption has been essentially non-existent. Classical compression techniques like JPEG and MPEG are too entrenched in modern computing to be easily replaced. This dissertation takes an orthogonal approach and leverages deep learning to improve the compression fidelity of these classical algorithms. This allows the incredible advances in deep learning to be used for multimedia compression without threatening the ubiquity of the classical methods. The key insight of this work is that methods which are motivated by first principles, i.e., the underlying engineering decisions that were made when the compression algorithms were developed, are more effective than general methods. By encoding prior knowledge into the design of the algorithm, the flexibility, performance, and/or accuracy are improved at the cost of generality...
Deep learning for the rare-event rational design of 3D printed multi-material mechanical metamaterials
Apr 04, 2022
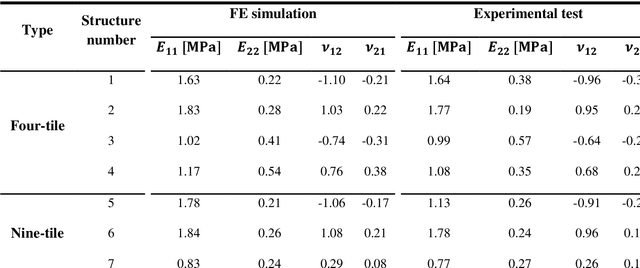
Emerging multi-material 3D printing techniques have paved the way for the rational design of metamaterials with not only complex geometries but also arbitrary distributions of multiple materials within those geometries. Varying the spatial distribution of multiple materials gives rise to many interesting and potentially unique combinations of anisotropic elastic properties. While the availability of a design approach to cover a large portion of all possible combinations of elastic properties is interesting in itself, it is even more important to find the extremely rare designs that lead to highly unusual combinations of material properties (e.g., double-auxeticity and high elastic moduli). Here, we used a random distribution of a hard phase and a soft phase within a regular lattice to study the resulting anisotropic mechanical properties of the network in general and the abovementioned rare designs in particular. The primary challenge to take up concerns the huge number of design parameters and the extreme rarity of such designs. We, therefore, used computational models and deep learning algorithms to create a mapping from the space of design parameters to the space of mechanical properties, thereby (i) reducing the computational time required for evaluating each designand (ii) making the process of evaluating the different designs highly parallelizable. Furthermore, we selected ten designs to be fabricated using polyjet multi-material 3D printing techniques, mechanically tested them, and characterized their behavior using digital image correlation (DIC, 3 designs) to validate the accuracy of our computational models. The results of our simulations show that deep learning-based algorithms can accurately predict the mechanical properties of the different designs, which match the various deformation mechanisms observed in the experiments.
A Switched View of Retinex: Deep Self-Regularized Low-Light Image Enhancement
Jan 03, 2021
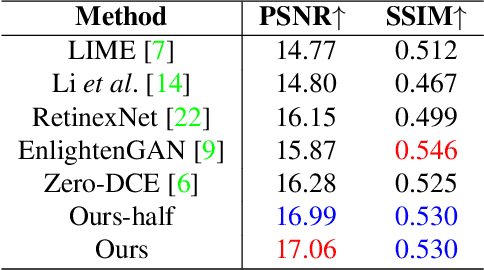
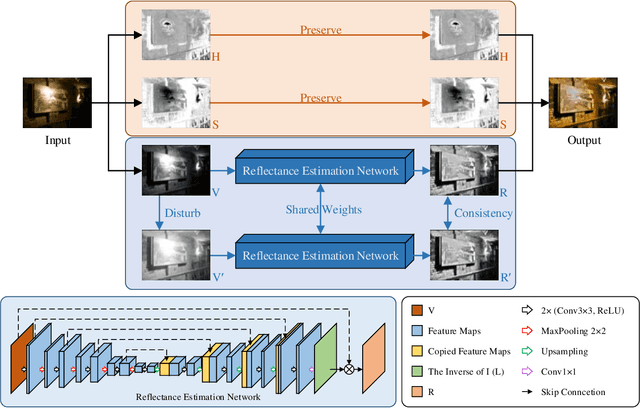
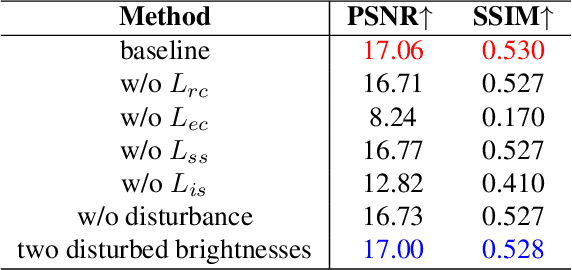
Self-regularized low-light image enhancement does not require any normal-light image in training, thereby freeing from the chains on paired or unpaired low-/normal-images. However, existing methods suffer color deviation and fail to generalize to various lighting conditions. This paper presents a novel self-regularized method based on Retinex, which, inspired by HSV, preserves all colors (Hue, Saturation) and only integrates Retinex theory into brightness (Value). We build a reflectance estimation network by restricting the consistency of reflectances embedded in both the original and a novel random disturbed form of the brightness of the same scene. The generated reflectance, which is assumed to be irrelevant of illumination by Retinex, is treated as enhanced brightness. Our method is efficient as a low-light image is decoupled into two subspaces, color and brightness, for better preservation and enhancement. Extensive experiments demonstrate that our method outperforms multiple state-of-the-art algorithms qualitatively and quantitatively and adapts to more lighting conditions.
FlowReg: Fast Deformable Unsupervised Medical Image Registration using Optical Flow
Jan 24, 2021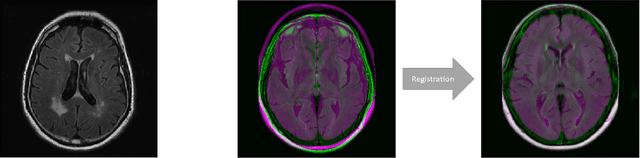
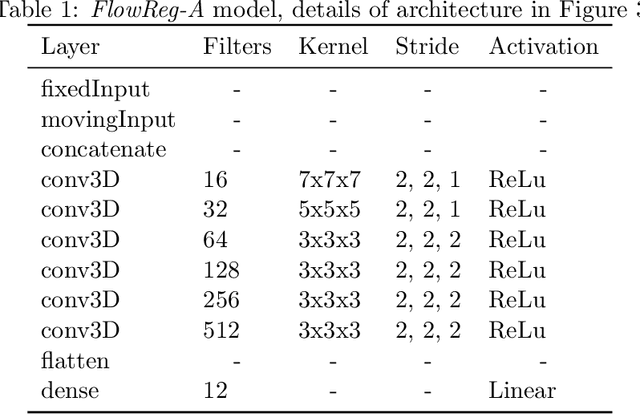
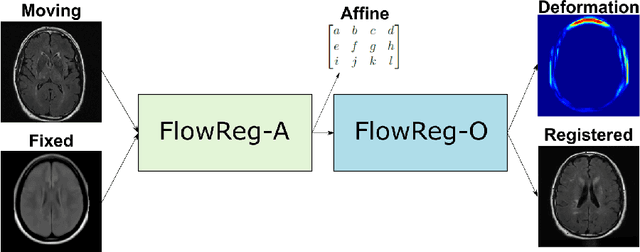
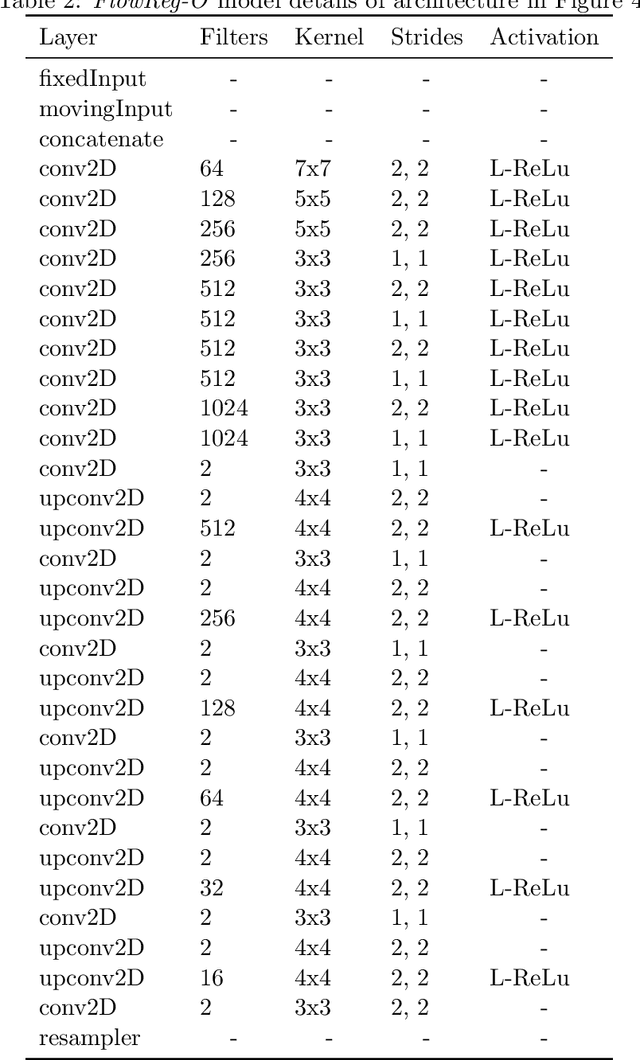
We propose FlowReg, a deep learning-based framework for unsupervised image registration for neuroimaging applications. The system is composed of two architectures that are trained sequentially: FlowReg-A which affinely corrects for gross differences between moving and fixed volumes in 3D followed by FlowReg-O which performs pixel-wise deformations on a slice-by-slice basis for fine tuning in 2D. The affine network regresses the 3D affine matrix based on a correlation loss function that enforces global similarity. The deformable network operates on 2D image slices based on the optical flow network FlowNet-Simple but with three loss components. The photometric loss minimizes pixel intensity differences differences, the smoothness loss encourages similar magnitudes between neighbouring vectors, and a correlation loss that is used to maintain the intensity similarity between fixed and moving image slices. The proposed method is compared to four open source registration techniques ANTs, Demons, SE, and Voxelmorph. In total, 4643 FLAIR MR imaging volumes are used from dementia and vascular disease cohorts, acquired from over 60 international centres with varying acquisition parameters. A battery of quantitative novel registration validation metrics are proposed that focus on the structural integrity of tissues, spatial alignment, and intensity similarity. Experimental results show FlowReg (FlowReg-A+O) performs better than iterative-based registration algorithms for intensity and spatial alignment metrics with a Pixelwise Agreement of 0.65, correlation coefficient of 0.80, and Mutual Information of 0.29. Among the deep learning frameworks, FlowReg-A or FlowReg-A+O provided the highest performance over all but one of the metrics. Results show that FlowReg is able to obtain high intensity and spatial similarity while maintaining the shape and structure of anatomy and pathology.
D-Unet: A Dual-encoder U-Net for Image Splicing Forgery Detection and Localization
Dec 03, 2020

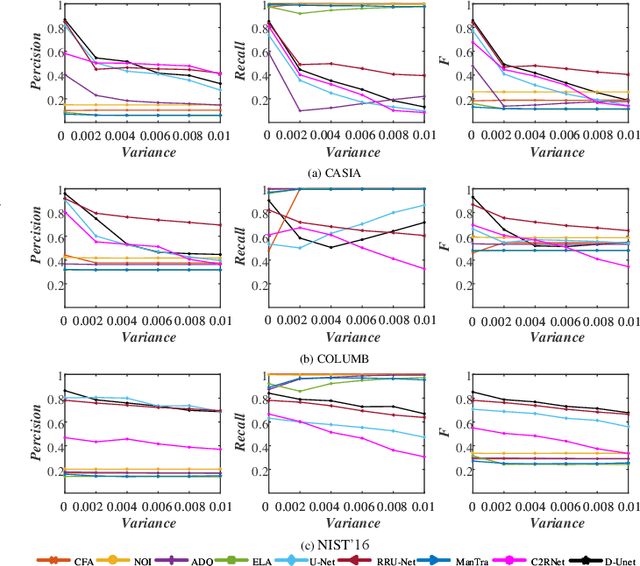
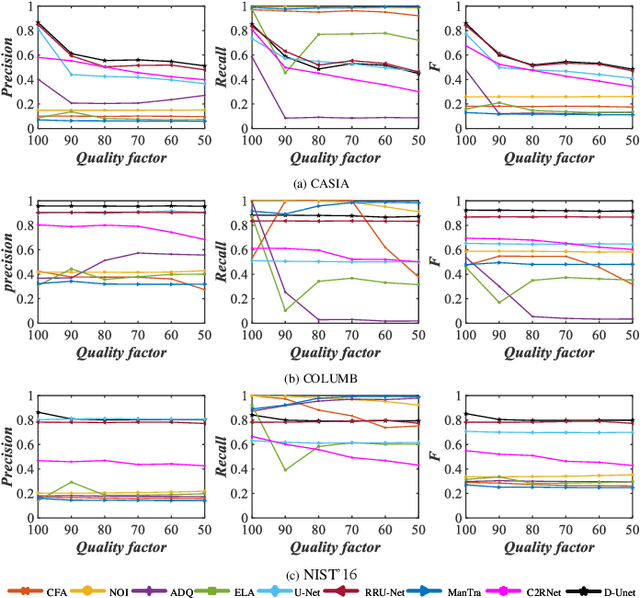
Recently, many detection methods based on convolutional neural networks (CNNs) have been proposed for image splicing forgery detection. Most of these detection methods focus on the local patches or local objects. In fact, image splicing forgery detection is a global binary classification task that distinguishes the tampered and non-tampered regions by image fingerprints. However, some specific image contents are hardly retained by CNN-based detection networks, but if included, would improve the detection accuracy of the networks. To resolve these issues, we propose a novel network called dual-encoder U-Net (D-Unet) for image splicing forgery detection, which employs an unfixed encoder and a fixed encoder. The unfixed encoder autonomously learns the image fingerprints that differentiate between the tampered and non-tampered regions, whereas the fixed encoder intentionally provides the direction information that assists the learning and detection of the network. This dual-encoder is followed by a spatial pyramid global-feature extraction module that expands the global insight of D-Unet for classifying the tampered and non-tampered regions more accurately. In an experimental comparison study of D-Unet and state-of-the-art methods, D-Unet outperformed the other methods in image-level and pixel-level detection, without requiring pre-training or training on a large number of forgery images. Moreover, it was stably robust to different attacks.