 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Colour alignment for relative colour constancy via non-standard references
Dec 30, 2021

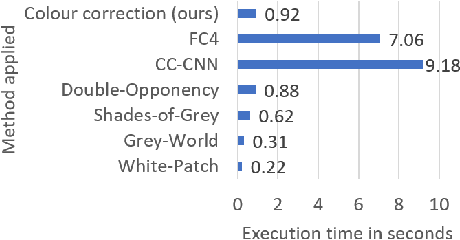
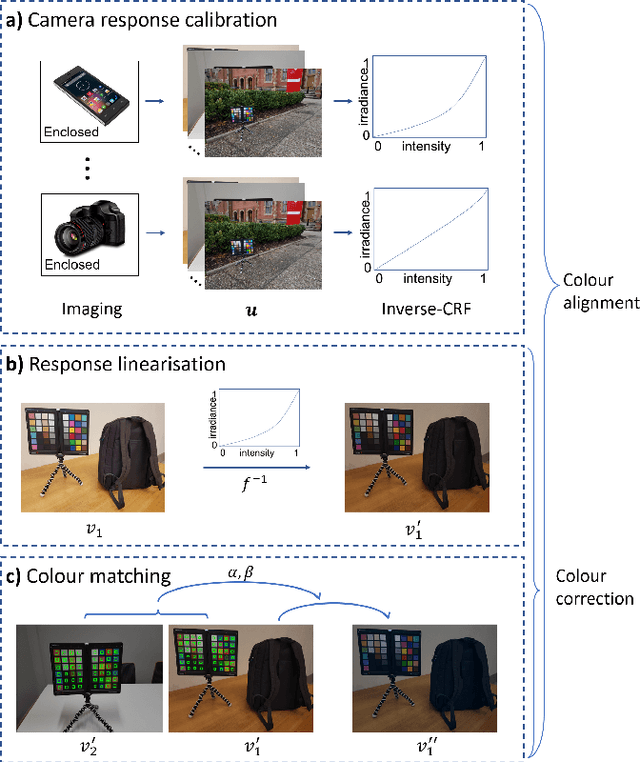
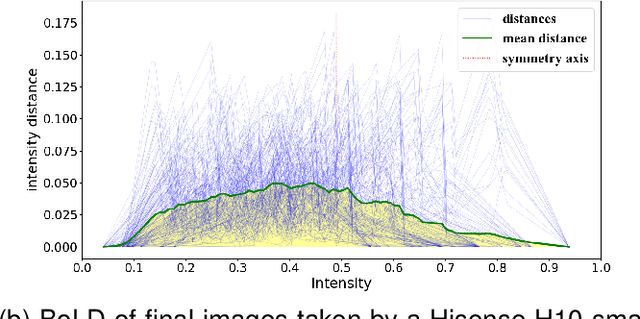
Relative colour constancy is an essential requirement for many scientific imaging applications. However, most digital cameras differ in their image formations and native sensor output is usually inaccessible, e.g., in smartphone camera applications. This makes it hard to achieve consistent colour assessment across a range of devices, and that undermines the performance of computer vision algorithms. To resolve this issue, we propose a colour alignment model that considers the camera image formation as a black-box and formulates colour alignment as a three-step process: camera response calibration, response linearisation, and colour matching. The proposed model works with non-standard colour references, i.e., colour patches without knowing the true colour values, by utilising a novel balance-of-linear-distances feature. It is equivalent to determining the camera parameters through an unsupervised process. It also works with a minimum number of corresponding colour patches across the images to be colour aligned to deliver the applicable processing. Two challenging image datasets collected by multiple cameras under various illumination and exposure conditions were used to evaluate the model. Performance benchmarks demonstrated that our model achieved superior performance compared to other popular and state-of-the-art methods.
The Fixed Sub-Center: A Better Way to Capture Data Complexity
Mar 24, 2022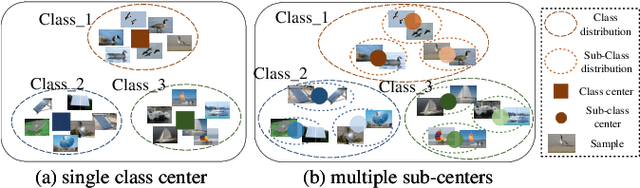
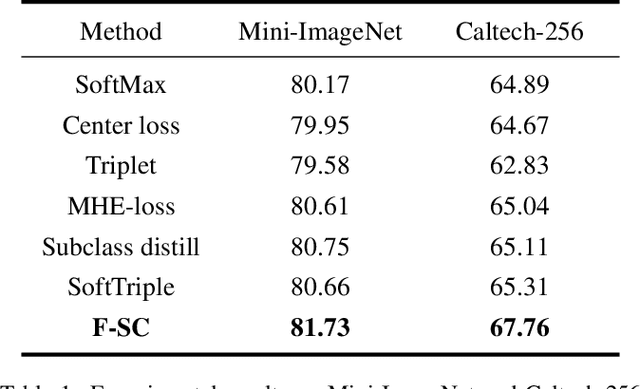
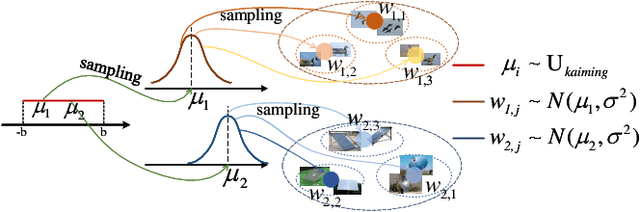
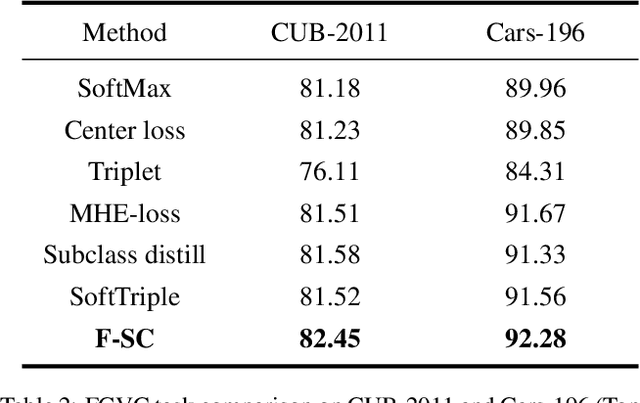
Treating class with a single center may hardly capture data distribution complexities. Using multiple sub-centers is an alternative way to address this problem. However, highly correlated sub-classes, the classifier's parameters grow linearly with the number of classes, and lack of intra-class compactness are three typical issues that need to be addressed in existing multi-subclass methods. To this end, we propose to use Fixed Sub-Center (F-SC), which allows the model to create more discrepant sub-centers while saving memory and cutting computational costs considerably. The F-SC specifically, first samples a class center Ui for each class from a uniform distribution, and then generates a normal distribution for each class, where the mean is equal to Ui. Finally, the sub-centers are sampled based on the normal distribution corresponding to each class, and the sub-centers are fixed during the training process avoiding the overhead of gradient calculation. Moreover, F-SC penalizes the Euclidean distance between the samples and their corresponding sub-centers, it helps remain intra-compactness. The experimental results show that F-SC significantly improves the accuracy of both image classification and fine-grained recognition tasks.
ComBiNet: Compact Convolutional Bayesian Neural Network for Image Segmentation
Apr 14, 2021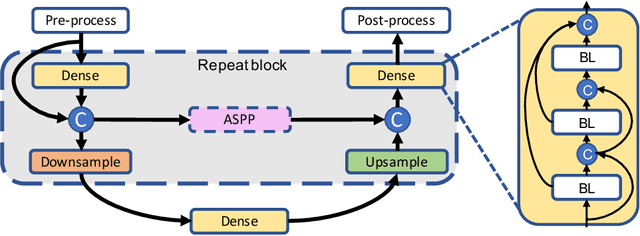
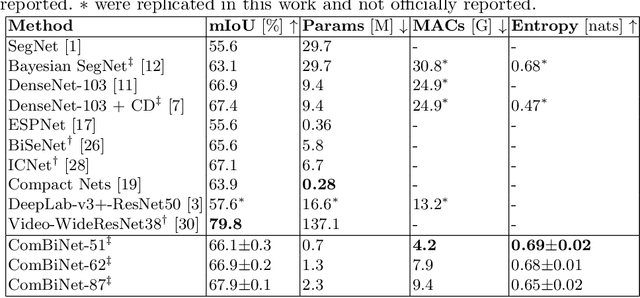
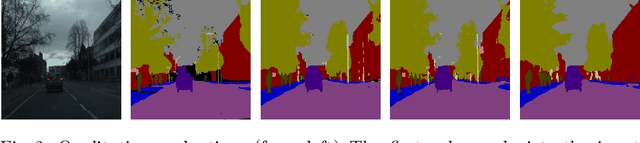
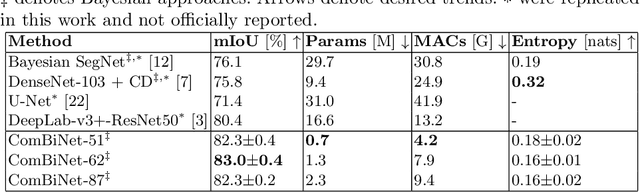
Fully convolutional U-shaped neural networks have largely been the dominant approach for pixel-wise image segmentation. In this work, we tackle two defects that hinder their deployment in real-world applications: 1) Predictions lack uncertainty quantification that may be crucial to many decision making systems; 2) Large memory storage and computational consumption demanding extensive hardware resources. To address these issues and improve their practicality we demonstrate a few-parameter compact Bayesian convolutional architecture, that achieves a marginal improvement in accuracy in comparison to related work using significantly fewer parameters and compute operations. The architecture combines parameter-efficient operations such as separable convolutions, bi-linear interpolation, multi-scale feature propagation and Bayesian inference for per-pixel uncertainty quantification through Monte Carlo Dropout. The best performing configurations required fewer than 2.5 million parameters on diverse challenging datasets with few observations.
Class-Aware Contrastive Semi-Supervised Learning
Mar 24, 2022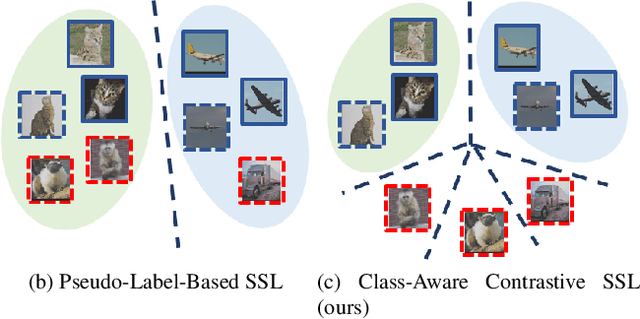
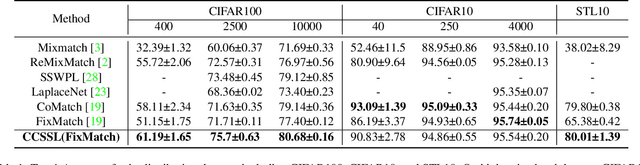
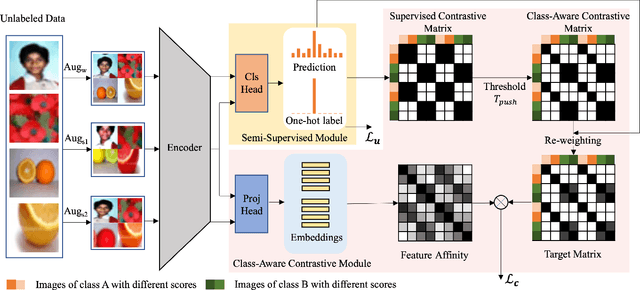
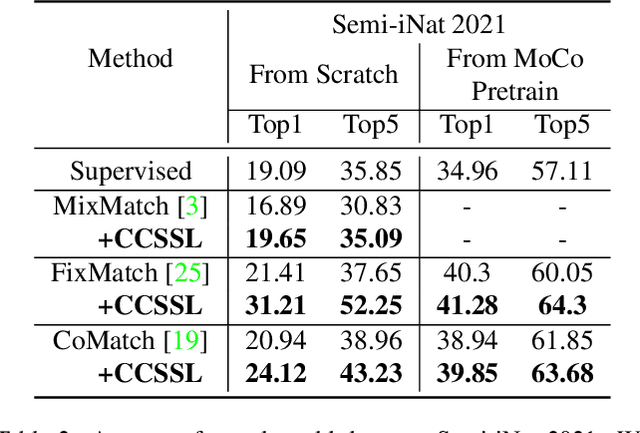
Pseudo-label-based semi-supervised learning (SSL) has achieved great success on raw data utilization. However, its training procedure suffers from confirmation bias due to the noise contained in self-generated artificial labels. Moreover, the model's judgment becomes noisier in real-world applications with extensive out-of-distribution data. To address this issue, we propose a general method named Class-aware Contrastive Semi-Supervised Learning (CCSSL), which is a drop-in helper to improve the pseudo-label quality and enhance the model's robustness in the real-world setting. Rather than treating real-world data as a union set, our method separately handles reliable in-distribution data with class-wise clustering for blending into downstream tasks and noisy out-of-distribution data with image-wise contrastive for better generalization. Furthermore, by applying target re-weighting, we successfully emphasize clean label learning and simultaneously reduce noisy label learning. Despite its simplicity, our proposed CCSSL has significant performance improvements over the state-of-the-art SSL methods on the standard datasets CIFAR100 and STL10. On the real-world dataset Semi-iNat 2021, we improve FixMatch by 9.80% and CoMatch by 3.18%. Code is available https://github.com/TencentYoutuResearch/Classification-SemiCLS.
A Triple-Double Convolutional Neural Network for Panchromatic Sharpening
Dec 04, 2021
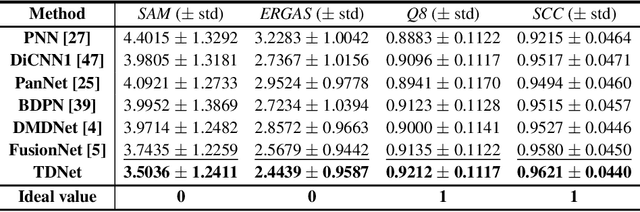
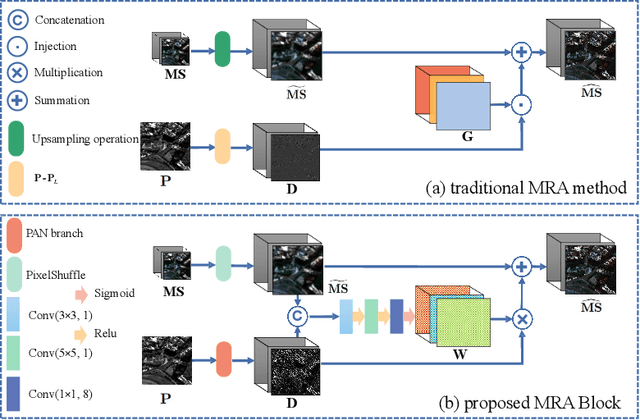
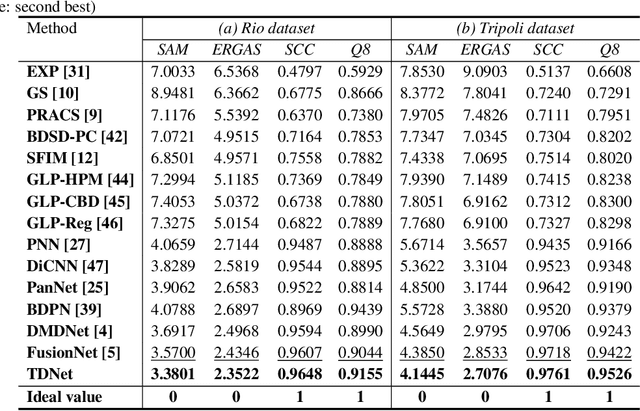
Pansharpening refers to the fusion of a panchromatic image with a high spatial resolution and a multispectral image with a low spatial resolution, aiming to obtain a high spatial resolution multispectral image. In this paper, we propose a novel deep neural network architecture with level-domain based loss function for pansharpening by taking into account the following double-type structures, \emph{i.e.,} double-level, double-branch, and double-direction, called as triple-double network (TDNet). By using the structure of TDNet, the spatial details of the panchromatic image can be fully exploited and utilized to progressively inject into the low spatial resolution multispectral image, thus yielding the high spatial resolution output. The specific network design is motivated by the physical formula of the traditional multi-resolution analysis (MRA) methods. Hence, an effective MRA fusion module is also integrated into the TDNet. Besides, we adopt a few ResNet blocks and some multi-scale convolution kernels to deepen and widen the network to effectively enhance the feature extraction and the robustness of the proposed TDNet. Extensive experiments on reduced- and full-resolution datasets acquired by WorldView-3, QuickBird, and GaoFen-2 sensors demonstrate the superiority of the proposed TDNet compared with some recent state-of-the-art pansharpening approaches. An ablation study has also corroborated the effectiveness of the proposed approach.
Delving into Inter-Image Invariance for Unsupervised Visual Representations
Aug 26, 2020
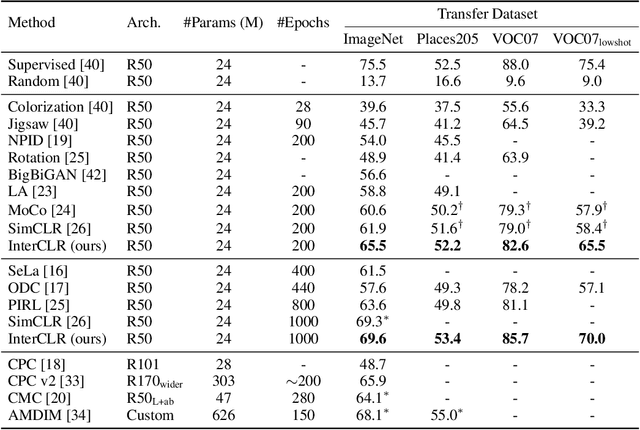
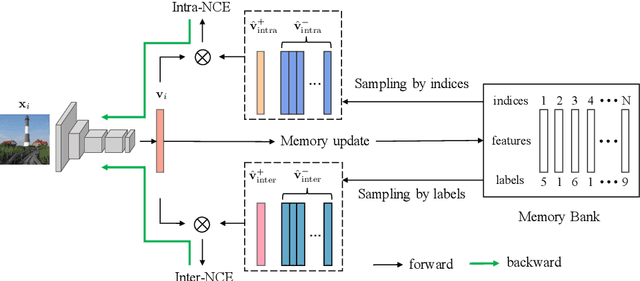
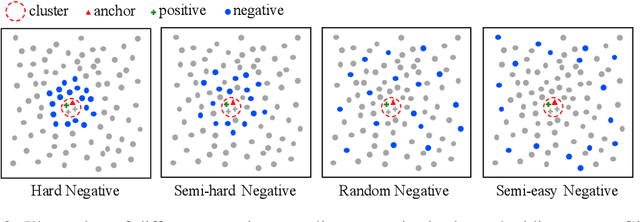
Contrastive learning has recently shown immense potential in unsupervised visual representation learning. Existing studies in this track mainly focus on intra-image invariance learning. The learning typically uses rich intra-image transformations to construct positive pairs and then maximizes agreement using a contrastive loss. The merits of inter-image invariance, conversely, remain much less explored. One major obstacle to exploit inter-image invariance is that it is unclear how to reliably construct inter-image positive pairs, and further derive effective supervision from them since there are no pair annotations available. In this work, we present a rigorous and comprehensive study on inter-image invariance learning from three main constituting components: pseudo-label maintenance, sampling strategy, and decision boundary design. Through carefully-designed comparisons and analysis, we propose a unified framework that supports the integration of unsupervised intra- and inter-image invariance learning. With all the obtained recipes, our final model, namely InterCLR, achieves state-of-the-art performance on standard benchmarks. Code and models will be available at https://github.com/open-mmlab/OpenSelfSup.
A Hybrid Mesh-neural Representation for 3D Transparent Object Reconstruction
Mar 24, 2022
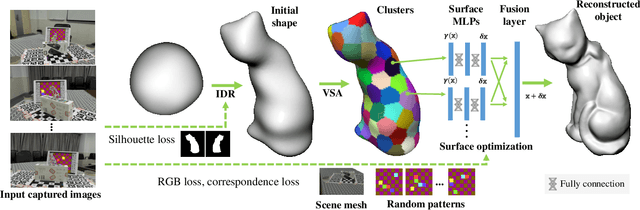

We propose a novel method to reconstruct the 3D shapes of transparent objects using hand-held captured images under natural light conditions. It combines the advantage of explicit mesh and multi-layer perceptron (MLP) network, a hybrid representation, to simplify the capture setting used in recent contributions. After obtaining an initial shape through the multi-view silhouettes, we introduce surface-based local MLPs to encode the vertex displacement field (VDF) for the reconstruction of surface details. The design of local MLPs allows to represent the VDF in a piece-wise manner using two layer MLP networks, which is beneficial to the optimization algorithm. Defining local MLPs on the surface instead of the volume also reduces the searching space. Such a hybrid representation enables us to relax the ray-pixel correspondences that represent the light path constraint to our designed ray-cell correspondences, which significantly simplifies the implementation of single-image based environment matting algorithm. We evaluate our representation and reconstruction algorithm on several transparent objects with ground truth models. Our experiments show that our method can produce high-quality reconstruction results superior to state-of-the-art methods using a simplified data acquisition setup.
An overview of deep learning in medical imaging
Feb 17, 2022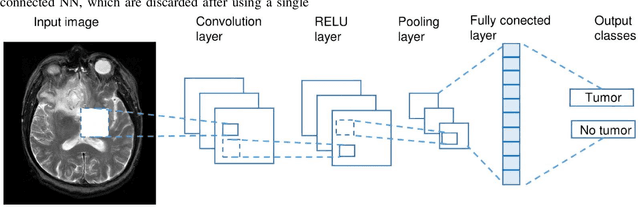
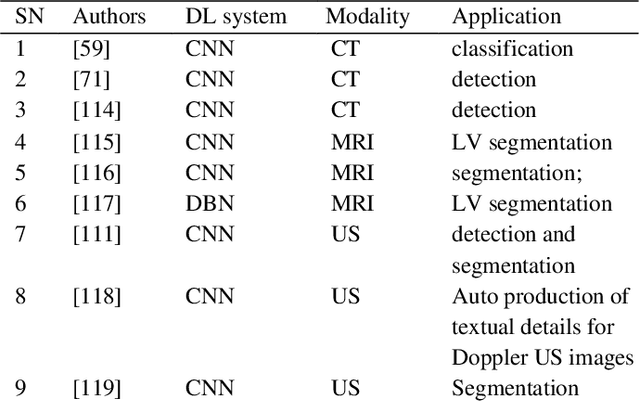
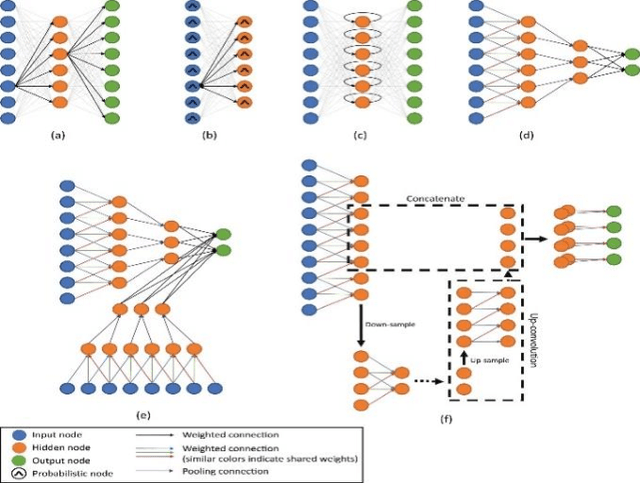
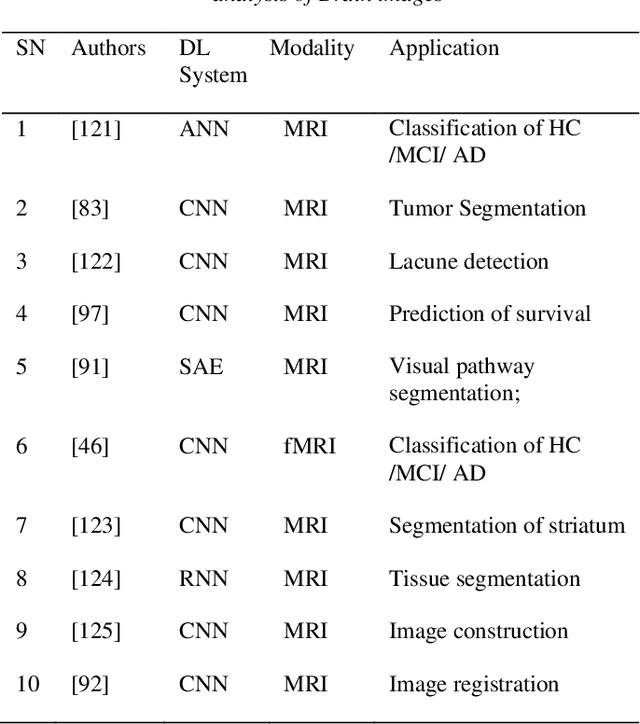
Machine learning (ML) has seen enormous consideration during the most recent decade. This success started in 2012 when an ML model accomplished a remarkable triumph in the ImageNet Classification, the world's most famous competition for computer vision. This model was a kind of convolutional neural system (CNN) called deep learning (DL). Since then, researchers have started to participate efficiently in DL's fastest developing area of research. These days, DL systems are cutting-edge ML systems spanning a broad range of disciplines, from human language processing to video analysis, and commonly used in the scholarly world and enterprise sector. Recent advances can bring tremendous improvement to the medical field. Improved and innovative methods for data processing, image analysis and can significantly improve the diagnostic technologies and medicinal services gradually. A quick review of current developments with relevant problems in the field of DL used for medical imaging has been provided. The primary purposes of the review are four: (i) provide a brief prolog to DL by discussing different DL models, (ii) review of the DL usage for medical image analysis (classification, detection, segmentation, and registration), (iii) review seven main application fields of DL in medical imaging, (iv) give an initial stage to those keen on adding to the research area about DL in clinical imaging by providing links of some useful informative assets, such as freely available DL codes, public datasets Table 7, and medical imaging competition sources Table 8 and end our survey by outlining distinct continuous difficulties, lessons learned and future of DL in the field of medical science.
PyNET-CA: Enhanced PyNET with Channel Attention for End-to-End Mobile Image Signal Processing
Apr 07, 2021

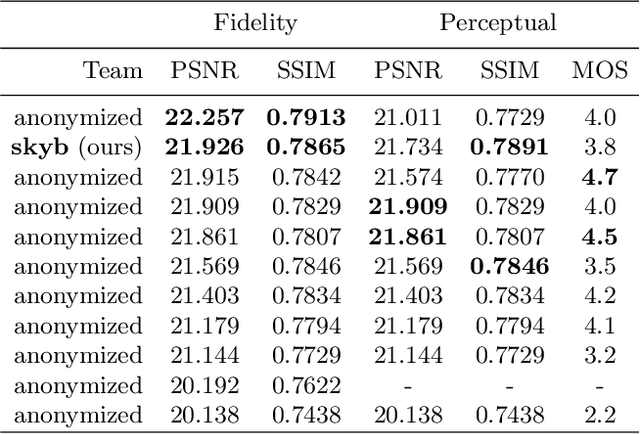
Reconstructing RGB image from RAW data obtained with a mobile device is related to a number of image signal processing (ISP) tasks, such as demosaicing, denoising, etc. Deep neural networks have shown promising results over hand-crafted ISP algorithms on solving these tasks separately, or even replacing the whole reconstruction process with one model. Here, we propose PyNET-CA, an end-to-end mobile ISP deep learning algorithm for RAW to RGB reconstruction. The model enhances PyNET, a recently proposed state-of-the-art model for mobile ISP, and improve its performance with channel attention and subpixel reconstruction module. We demonstrate the performance of the proposed method with comparative experiments and results from the AIM 2020 learned smartphone ISP challenge. The source code of our implementation is available at https://github.com/egyptdj/skyb-aim2020-public
A precortical module for robust CNNs to light variations
Feb 21, 2022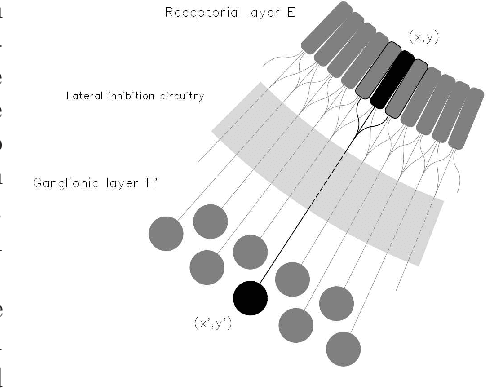
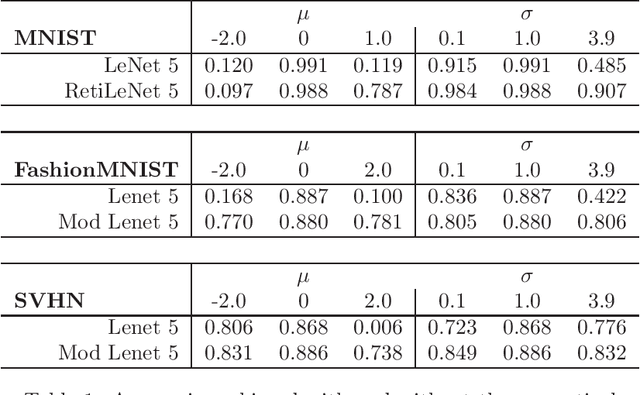

We present a simple mathematical model for the mammalian low visual pathway, taking into account its key elements: retina, lateral geniculate nucleus (LGN), primary visual cortex (V1). The analogies between the cortical level of the visual system and the structure of popular CNNs, used in image classification tasks, suggests the introduction of an additional preliminary convolutional module inspired to precortical neuronal circuits to improve robustness with respect to global light intensity and contrast variations in the input images. We validate our hypothesis on the popular databases MNIST, FashionMNIST and SVHN, obtaining significantly more robust CNNs with respect to these variations, once such extra module is added.