 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Temporally Resolution Decrement: Utilizing the Shape Consistency for Higher Computational Efficiency
Dec 02, 2021
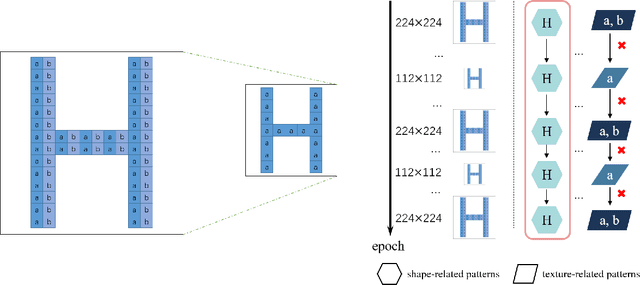
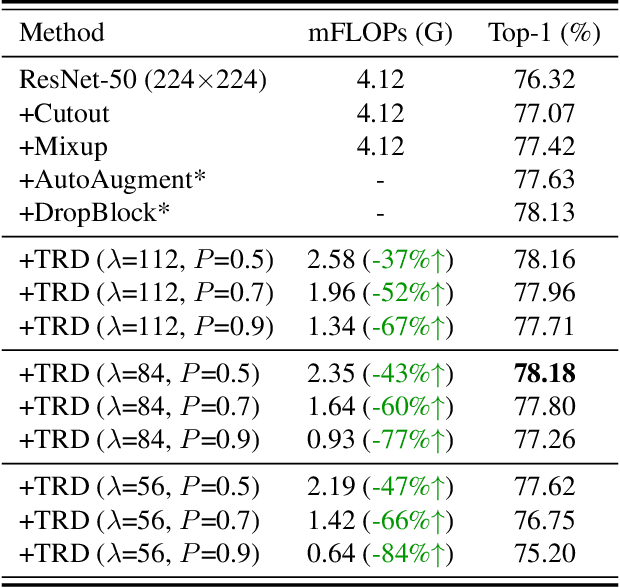
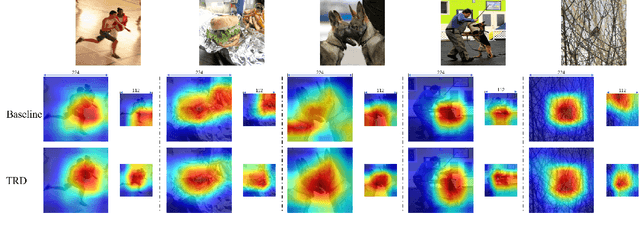
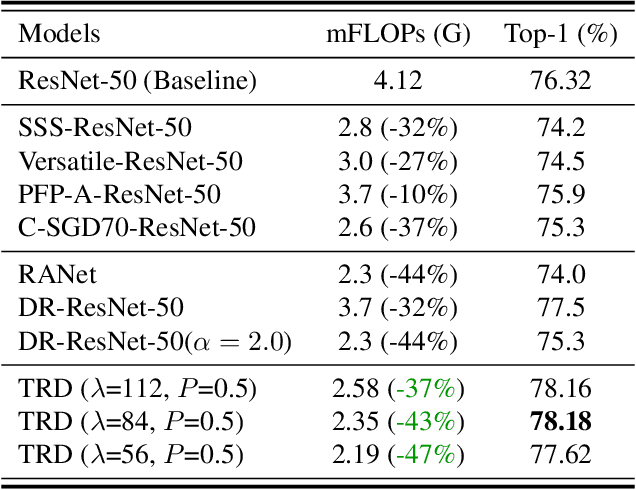
Image resolution that has close relations with accuracy and computational cost plays a pivotal role in network training. In this paper, we observe that the reduced image retains relatively complete shape semantics but loses extensive texture information. Inspired by the consistency of the shape semantics as well as the fragility of the texture information, we propose a novel training strategy named Temporally Resolution Decrement. Wherein, we randomly reduce the training images to a smaller resolution in the time domain. During the alternate training with the reduced images and the original images, the unstable texture information in the images results in a weaker correlation between the texture-related patterns and the correct label, naturally enforcing the model to rely more on shape properties that are robust and conform to the human decision rule. Surprisingly, our approach greatly improves the computational efficiency of convolutional neural networks. On ImageNet classification, using only 33% calculation quantity (randomly reducing the training image to 112$\times$112 within 90% epochs) can still improve ResNet-50 from 76.32% to 77.71%, and using 63% calculation quantity (randomly reducing the training image to 112 x 112 within 50% epochs) can improve ResNet-50 to 78.18%.
Neural Image Representations for Multi-Image Fusion and Layer Separation
Aug 02, 2021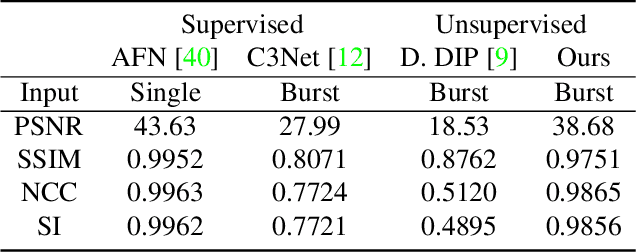
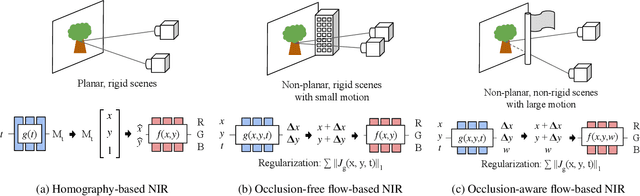
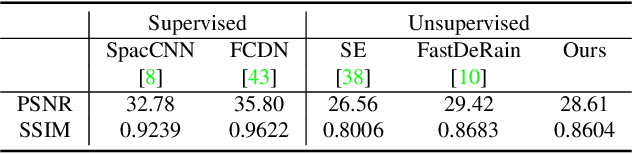
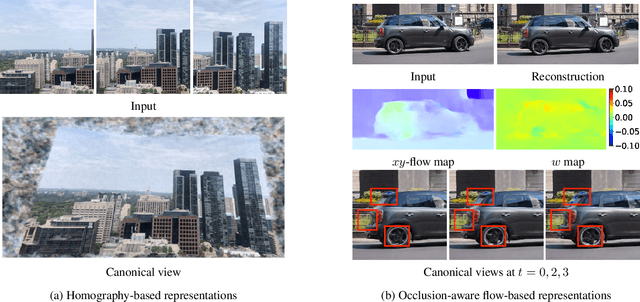
We propose a framework for aligning and fusing multiple images into a single coordinate-based neural representations. Our framework targets burst images that have misalignment due to camera ego motion and small changes in the scene. We describe different strategies for alignment depending on the assumption of the scene motion, namely, perspective planar (i.e., homography), optical flow with minimal scene change, and optical flow with notable occlusion and disocclusion. Our framework effectively combines the multiple inputs into a single neural implicit function without the need for selecting one of the images as a reference frame. We demonstrate how to use this multi-frame fusion framework for various layer separation tasks.
The First Principles of Deep Learning and Compression
Apr 04, 2022The deep learning revolution incited by the 2012 Alexnet paper has been transformative for the field of computer vision. Many problems which were severely limited using classical solutions are now seeing unprecedented success. The rapid proliferation of deep learning methods has led to a sharp increase in their use in consumer and embedded applications. One consequence of consumer and embedded applications is lossy multimedia compression which is required to engineer the efficient storage and transmission of data in these real-world scenarios. As such, there has been increased interest in a deep learning solution for multimedia compression which would allow for higher compression ratios and increased visual quality. The deep learning approach to multimedia compression, so called Learned Multimedia Compression, involves computing a compressed representation of an image or video using a deep network for the encoder and the decoder. While these techniques have enjoyed impressive academic success, their industry adoption has been essentially non-existent. Classical compression techniques like JPEG and MPEG are too entrenched in modern computing to be easily replaced. This dissertation takes an orthogonal approach and leverages deep learning to improve the compression fidelity of these classical algorithms. This allows the incredible advances in deep learning to be used for multimedia compression without threatening the ubiquity of the classical methods. The key insight of this work is that methods which are motivated by first principles, i.e., the underlying engineering decisions that were made when the compression algorithms were developed, are more effective than general methods. By encoding prior knowledge into the design of the algorithm, the flexibility, performance, and/or accuracy are improved at the cost of generality...
Deep learning for the rare-event rational design of 3D printed multi-material mechanical metamaterials
Apr 04, 2022
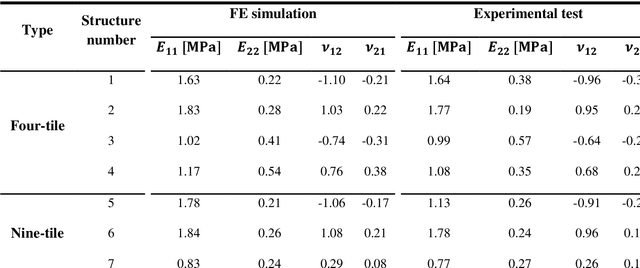
Emerging multi-material 3D printing techniques have paved the way for the rational design of metamaterials with not only complex geometries but also arbitrary distributions of multiple materials within those geometries. Varying the spatial distribution of multiple materials gives rise to many interesting and potentially unique combinations of anisotropic elastic properties. While the availability of a design approach to cover a large portion of all possible combinations of elastic properties is interesting in itself, it is even more important to find the extremely rare designs that lead to highly unusual combinations of material properties (e.g., double-auxeticity and high elastic moduli). Here, we used a random distribution of a hard phase and a soft phase within a regular lattice to study the resulting anisotropic mechanical properties of the network in general and the abovementioned rare designs in particular. The primary challenge to take up concerns the huge number of design parameters and the extreme rarity of such designs. We, therefore, used computational models and deep learning algorithms to create a mapping from the space of design parameters to the space of mechanical properties, thereby (i) reducing the computational time required for evaluating each designand (ii) making the process of evaluating the different designs highly parallelizable. Furthermore, we selected ten designs to be fabricated using polyjet multi-material 3D printing techniques, mechanically tested them, and characterized their behavior using digital image correlation (DIC, 3 designs) to validate the accuracy of our computational models. The results of our simulations show that deep learning-based algorithms can accurately predict the mechanical properties of the different designs, which match the various deformation mechanisms observed in the experiments.
Unified Visual Transformer Compression
Mar 15, 2022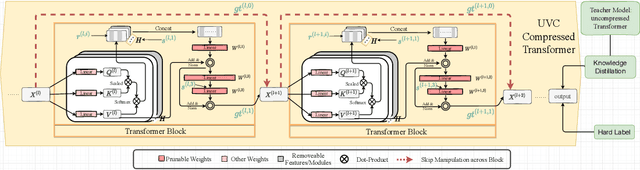
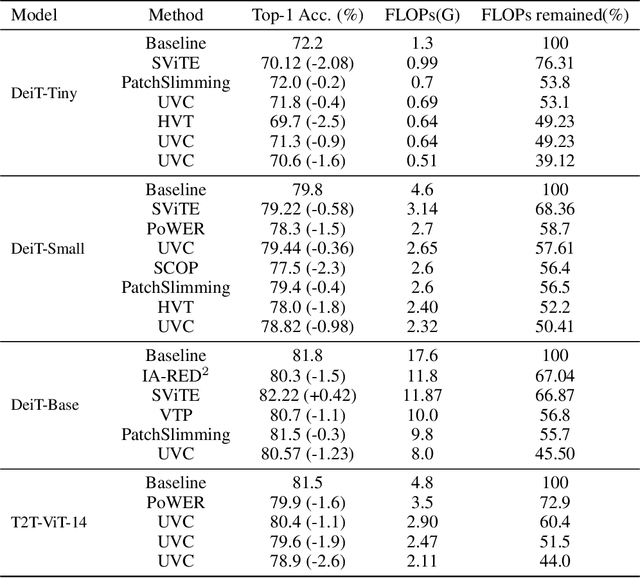
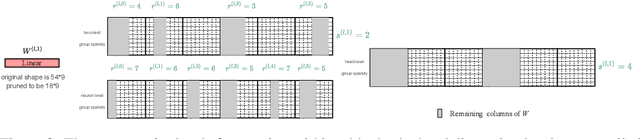
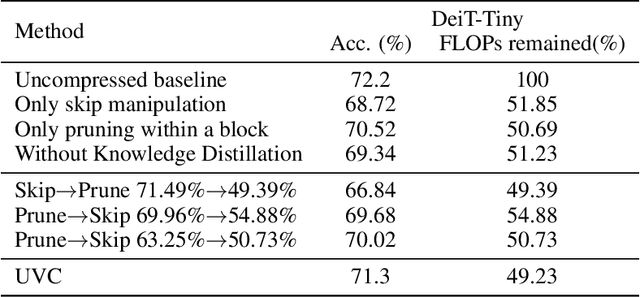
Vision transformers (ViTs) have gained popularity recently. Even without customized image operators such as convolutions, ViTs can yield competitive performance when properly trained on massive data. However, the computational overhead of ViTs remains prohibitive, due to stacking multi-head self-attention modules and else. Compared to the vast literature and prevailing success in compressing convolutional neural networks, the study of Vision Transformer compression has also just emerged, and existing works focused on one or two aspects of compression. This paper proposes a unified ViT compression framework that seamlessly assembles three effective techniques: pruning, layer skipping, and knowledge distillation. We formulate a budget-constrained, end-to-end optimization framework, targeting jointly learning model weights, layer-wise pruning ratios/masks, and skip configurations, under a distillation loss. The optimization problem is then solved using the primal-dual algorithm. Experiments are conducted with several ViT variants, e.g. DeiT and T2T-ViT backbones on the ImageNet dataset, and our approach consistently outperforms recent competitors. For example, DeiT-Tiny can be trimmed down to 50\% of the original FLOPs almost without losing accuracy. Codes are available online:~\url{https://github.com/VITA-Group/UVC}.
Galaxy Image Restoration with Shape Constraint
Jan 25, 2021
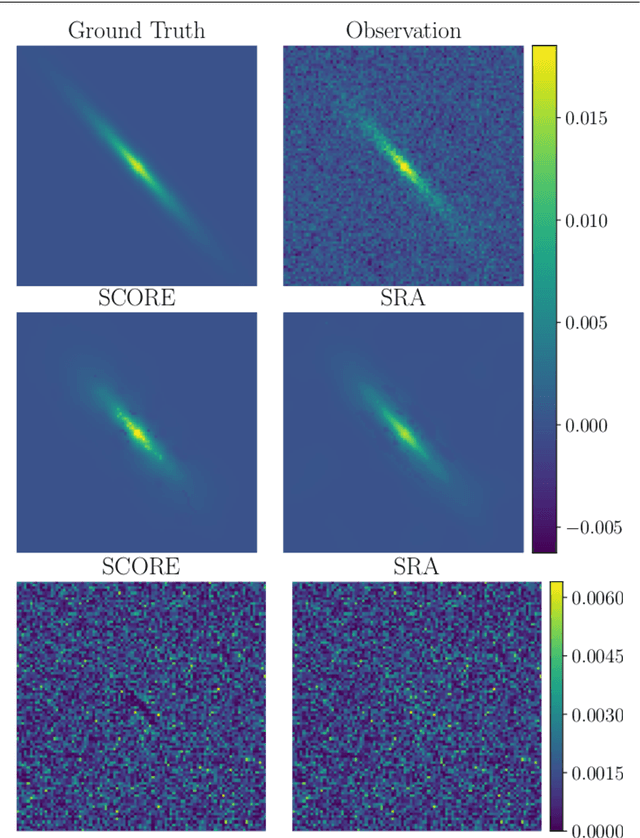
Images acquired with a telescope are blurred and corrupted by noise. The blurring is usually modeled by a convolution with the Point Spread Function and the noise by Additive Gaussian Noise. Recovering the observed image is an ill-posed inverse problem. Sparse deconvolution is well known to be an efficient deconvolution technique, leading to optimized pixel Mean Square Errors, but without any guarantee that the shapes of objects (e.g. galaxy images) contained in the data will be preserved. In this paper, we introduce a new shape constraint and exhibit its properties. By combining it with a standard sparse regularization in the wavelet domain, we introduce the Shape COnstraint REstoration algorithm (SCORE), which performs a standard sparse deconvolution, while preserving galaxy shapes. We show through numerical experiments that this new approach leads to a reduction of galaxy ellipticity measurement errors by at least 44%.
Artifact Reduction in Fundus Imaging using Cycle Consistent Adversarial Neural Networks
Dec 25, 2021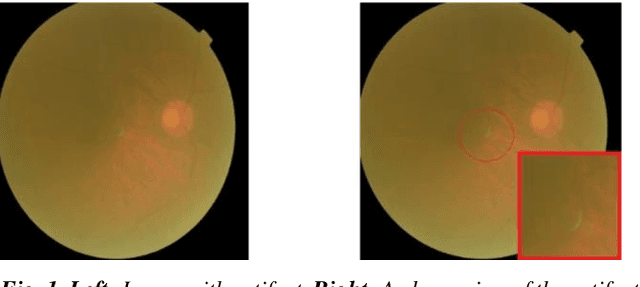
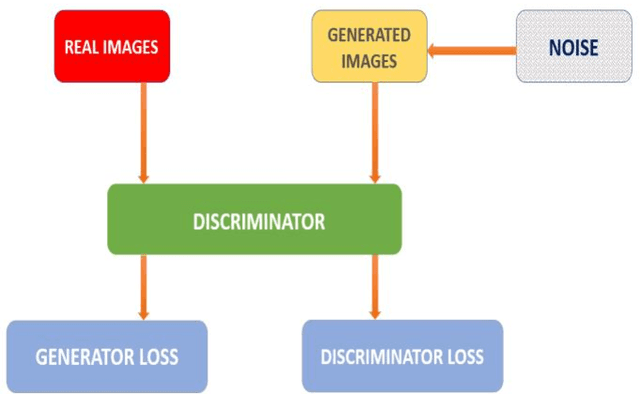
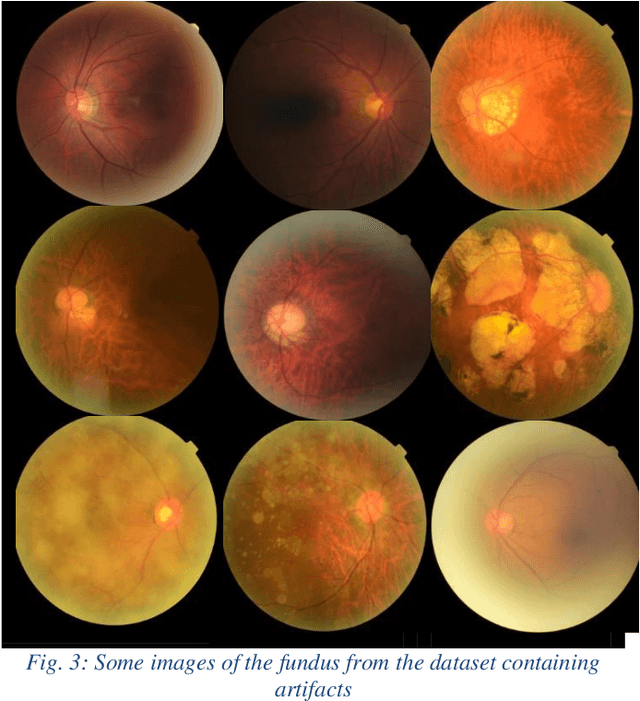
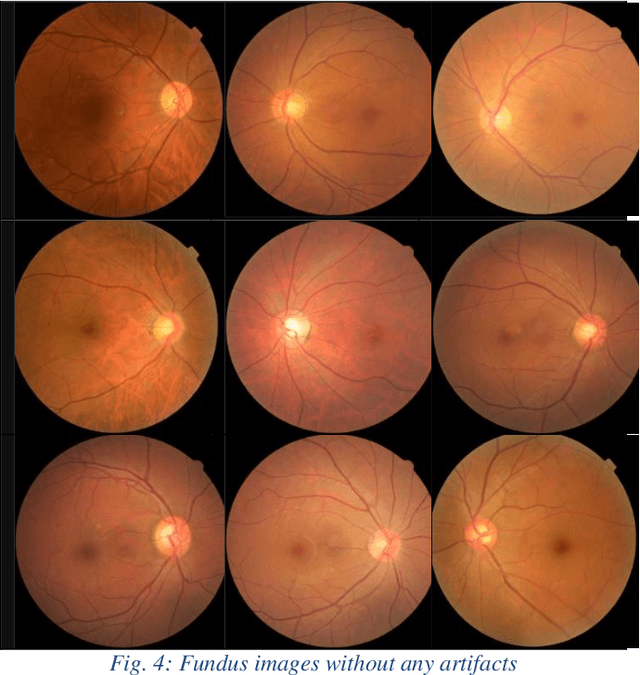
Fundus images are very useful in identifying various ophthalmic disorders. However, due to the presence of artifacts, the visibility of the retina is severely affected. This may result in misdiagnosis of the disorder which may lead to more complicated problems. Since deep learning is a powerful tool to extract patterns from data without much human intervention, they can be applied to image-to-image translation problems. An attempt has been made in this paper to automatically rectify such artifacts present in the images of the fundus. We use a CycleGAN based model which consists of residual blocks to reduce the artifacts in the images. Significant improvements are seen when compared to the existing techniques.
DAQ: Distribution-Aware Quantization for Deep Image Super-Resolution Networks
Dec 21, 2020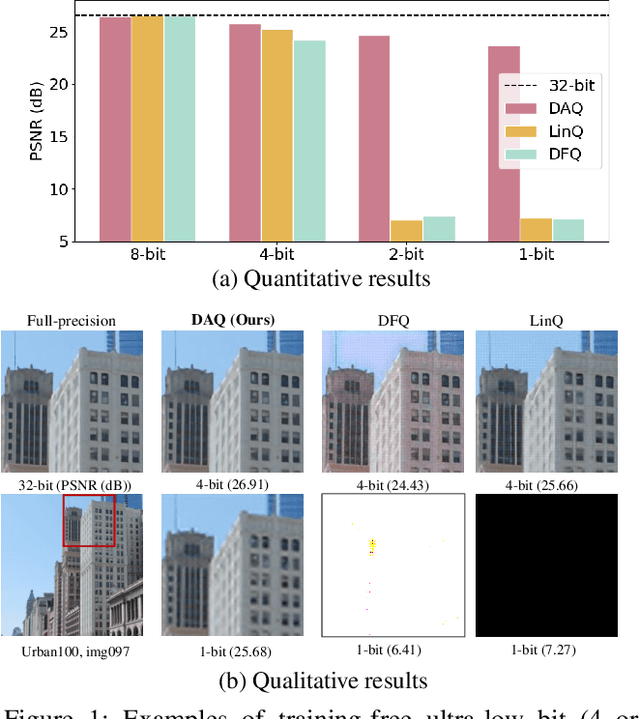

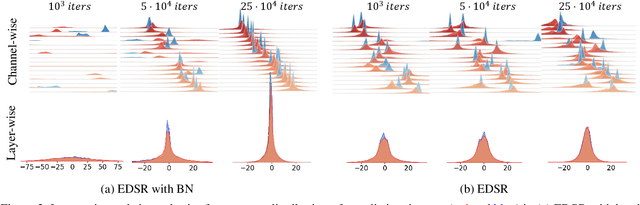
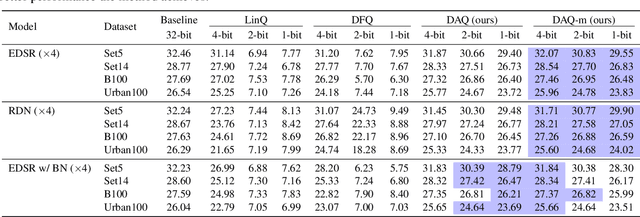
Quantizing deep convolutional neural networks for image super-resolution substantially reduces their computational costs. However, existing works either suffer from a severe performance drop in ultra-low precision of 4 or lower bit-widths, or require a heavy fine-tuning process to recover the performance. To our knowledge, this vulnerability to low precisions relies on two statistical observations of feature map values. First, distribution of feature map values varies significantly per channel and per input image. Second, feature maps have outliers that can dominate the quantization error. Based on these observations, we propose a novel distribution-aware quantization scheme (DAQ) which facilitates accurate training-free quantization in ultra-low precision. A simple function of DAQ determines dynamic range of feature maps and weights with low computational burden. Furthermore, our method enables mixed-precision quantization by calculating the relative sensitivity of each channel, without any training process involved. Nonetheless, quantization-aware training is also applicable for auxiliary performance gain. Our new method outperforms recent training-free and even training-based quantization methods to the state-of-the-art image super-resolution networks in ultra-low precision.
Animatable Neural Implicit Surfaces for Creating Avatars from Videos
Mar 15, 2022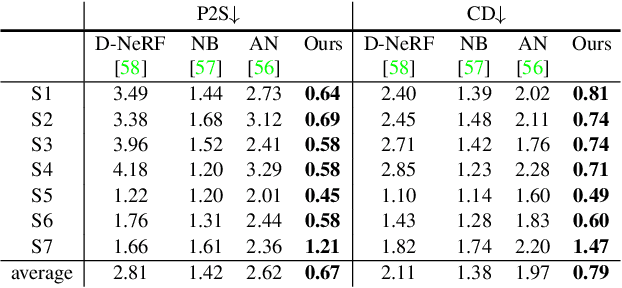
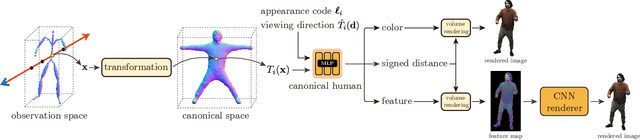
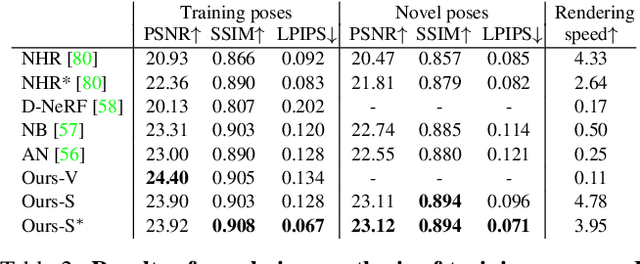
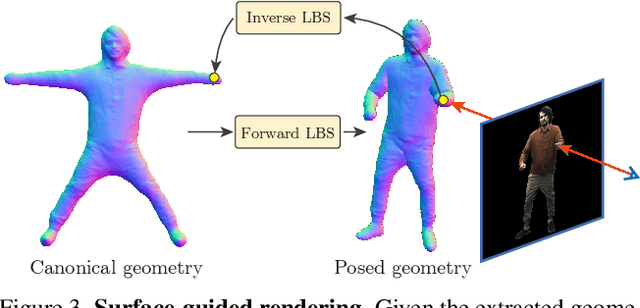
This paper aims to reconstruct an animatable human model from a video of very sparse camera views. Some recent works represent human geometry and appearance with neural radiance fields and utilize parametric human models to produce deformation fields for animation, which enables them to recover detailed 3D human models from videos. However, their reconstruction results tend to be noisy due to the lack of surface constraints on radiance fields. Moreover, as they generate the human appearance in 3D space, their rendering quality heavily depends on the accuracy of deformation fields. To solve these problems, we propose Animatable Neural Implicit Surface (AniSDF), which models the human geometry with a signed distance field and defers the appearance generation to the 2D image space with a 2D neural renderer. The signed distance field naturally regularizes the learned geometry, enabling the high-quality reconstruction of human bodies, which can be further used to improve the rendering speed. Moreover, the 2D neural renderer can be learned to compensate for geometric errors, making the rendering more robust to inaccurate deformations. Experiments on several datasets show that the proposed approach outperforms recent human reconstruction and synthesis methods by a large margin.
Deconvolution of the Functional Ultrasound Response in the Mouse Visual Pathway Using Block-Term Decomposition
Apr 07, 2022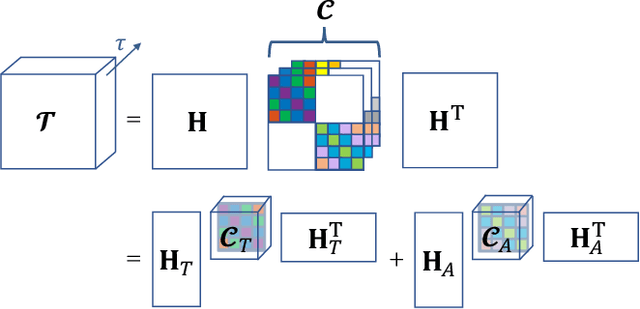
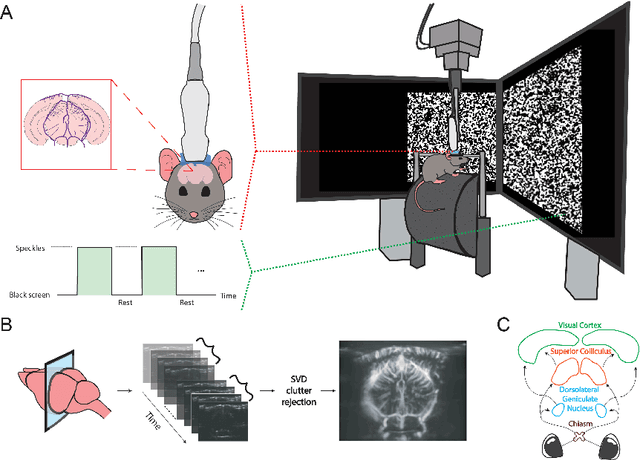
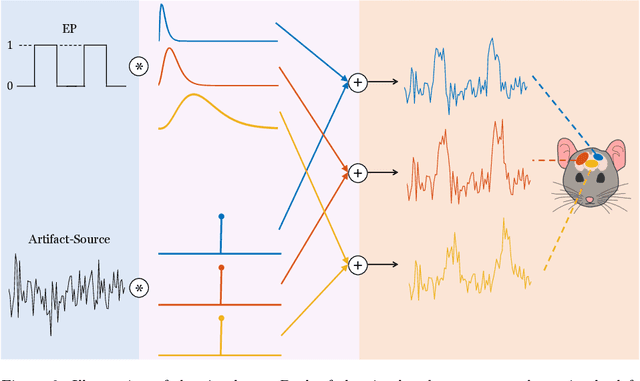
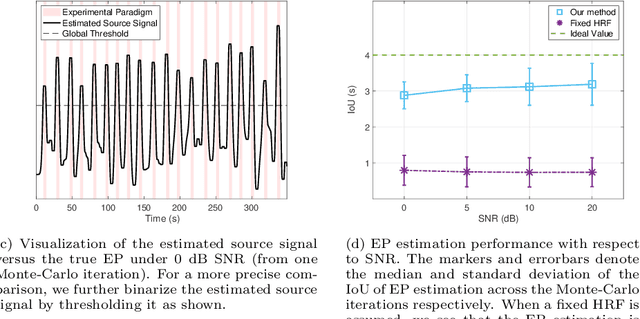
Functional ultrasound (fUS) indirectly measures brain activity by recording changes in cerebral blood volume and flow in response to neural activation. Conventional approaches model such functional neuroimaging data as the convolution between an impulse response, known as the hemodynamic response function (HRF), and a binarized representation of the input (i.e., source) signal based on the stimulus onsets, the so-called experimental paradigm (EP). However, the EP may not be enough to characterize the whole complexity of the underlying source signals that evoke the hemodynamic changes, such as in the case of spontaneous resting state activity. Furthermore, the HRF varies across brain areas and stimuli. To achieve an adaptable framework that can capture such dynamics and unknowns of the brain function, we propose a deconvolution method for multivariate fUS time-series that reveals both the region-specific HRFs, and the source signals that induce the hemodynamic responses in the studied regions. We start by modeling the fUS time-series as convolutive mixtures and use a tensor-based approach for deconvolution based on two assumptions: (1) HRFs are parametrizable, and (2) source signals are uncorrelated. We test our approach on fUS data acquired during a visual experiment on a mouse subject, focusing on three regions within the mouse brain's colliculo-cortical, image-forming pathway: the lateral geniculate nucleus, superior colliculus and visual cortex. The estimated HRFs in each region are in agreement with prior works, whereas the estimated source signal is observed to closely follow the EP. Yet, we note a few deviations from the EP in the estimated source signal that most likely arise due to the trial-by-trial variability of the neural response across different repetitions of the stimulus observed in the selected regions.