 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Omni-frequency Region-adaptive Representations for Real Image Super-Resolution
Dec 11, 2020
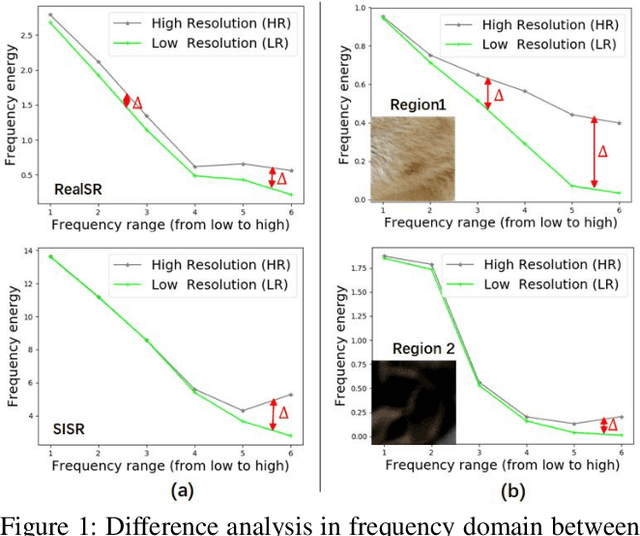
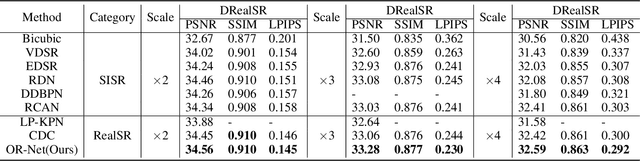
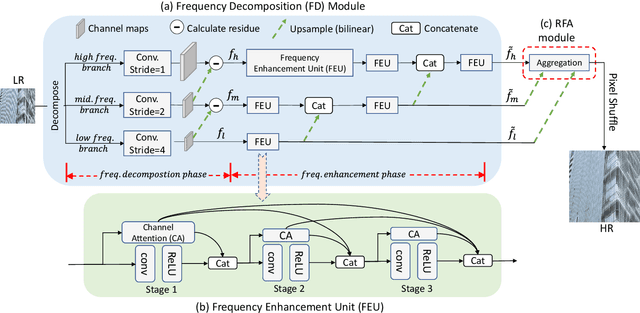
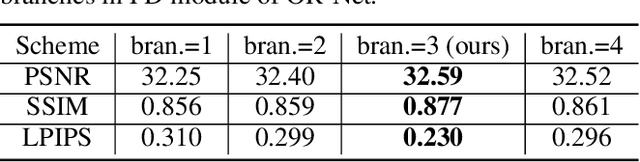
Traditional single image super-resolution (SISR) methods that focus on solving single and uniform degradation (i.e., bicubic down-sampling), typically suffer from poor performance when applied into real-world low-resolution (LR) images due to the complicated realistic degradations. The key to solving this more challenging real image super-resolution (RealSR) problem lies in learning feature representations that are both informative and content-aware. In this paper, we propose an Omni-frequency Region-adaptive Network (ORNet) to address both challenges, here we call features of all low, middle and high frequencies omni-frequency features. Specifically, we start from the frequency perspective and design a Frequency Decomposition (FD) module to separate different frequency components to comprehensively compensate the information lost for real LR image. Then, considering the different regions of real LR image have different frequency information lost, we further design a Region-adaptive Frequency Aggregation (RFA) module by leveraging dynamic convolution and spatial attention to adaptively restore frequency components for different regions. The extensive experiments endorse the effective, and scenario-agnostic nature of our OR-Net for RealSR.
Automated Scoring of Graphical Open-Ended Responses Using Artificial Neural Networks
Jan 05, 2022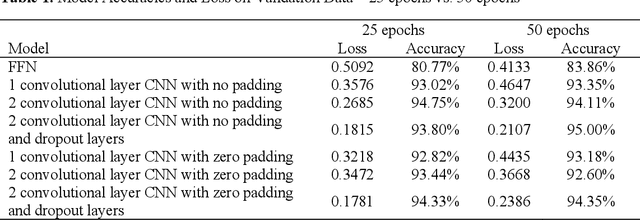
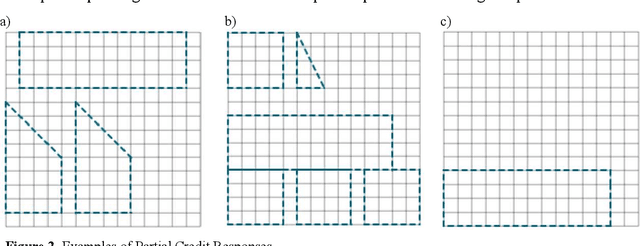
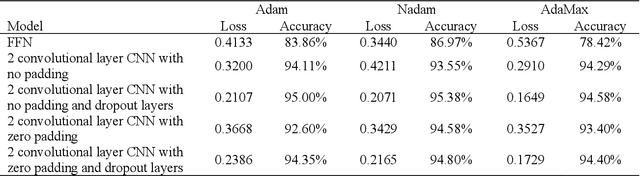

Automated scoring of free drawings or images as responses has yet to be utilized in large-scale assessments of student achievement. In this study, we propose artificial neural networks to classify these types of graphical responses from a computer based international mathematics and science assessment. We are comparing classification accuracy of convolutional and feedforward approaches. Our results show that convolutional neural networks (CNNs) outperform feedforward neural networks in both loss and accuracy. The CNN models classified up to 97.71% of the image responses into the appropriate scoring category, which is comparable to, if not more accurate, than typical human raters. These findings were further strengthened by the observation that the most accurate CNN models correctly classified some image responses that had been incorrectly scored by the human raters. As an additional innovation, we outline a method to select human rated responses for the training sample based on an application of the expected response function derived from item response theory. This paper argues that CNN-based automated scoring of image responses is a highly accurate procedure that could potentially replace the workload and cost of second human raters for large scale assessments, while improving the validity and comparability of scoring complex constructed-response items.
Multi-institutional Collaborations for Improving Deep Learning-based Magnetic Resonance Image Reconstruction Using Federated Learning
Mar 05, 2021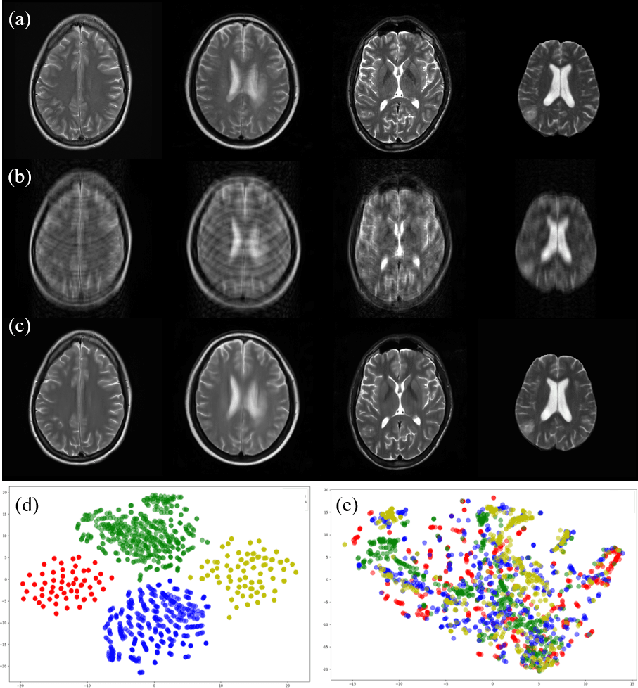
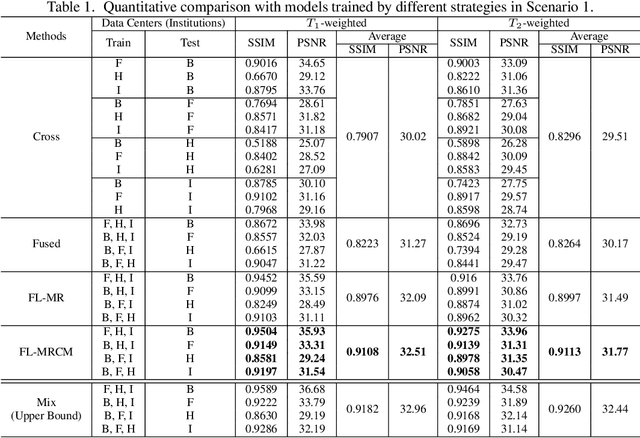
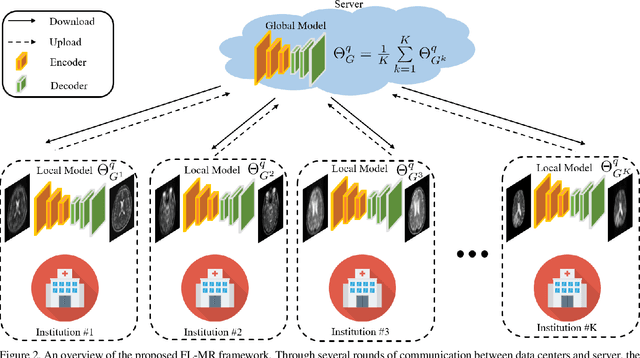
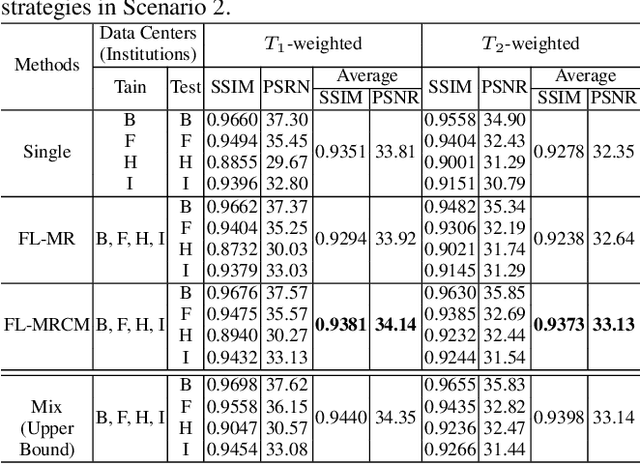
Fast and accurate reconstruction of magnetic resonance (MR) images from under-sampled data is important in many clinical applications. In recent years, deep learning-based methods have been shown to produce superior performance on MR image reconstruction. However, these methods require large amounts of data which is difficult to collect and share due to the high cost of acquisition and medical data privacy regulations. In order to overcome this challenge, we propose a federated learning (FL) based solution in which we take advantage of the MR data available at different institutions while preserving patients' privacy. However, the generalizability of models trained with the FL setting can still be suboptimal due to domain shift, which results from the data collected at multiple institutions with different sensors, disease types, and acquisition protocols, etc. With the motivation of circumventing this challenge, we propose a cross-site modeling for MR image reconstruction in which the learned intermediate latent features among different source sites are aligned with the distribution of the latent features at the target site. Extensive experiments are conducted to provide various insights about FL for MR image reconstruction. Experimental results demonstrate that the proposed framework is a promising direction to utilize multi-institutional data without compromising patients' privacy for achieving improved MR image reconstruction. Our code will be available at https://github.com/guopengf/FLMRCM.
Deep Triplet Hashing Network for Case-based Medical Image Retrieval
Jan 29, 2021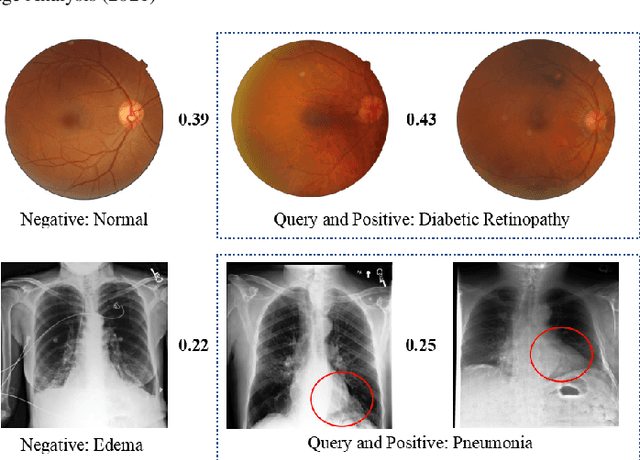
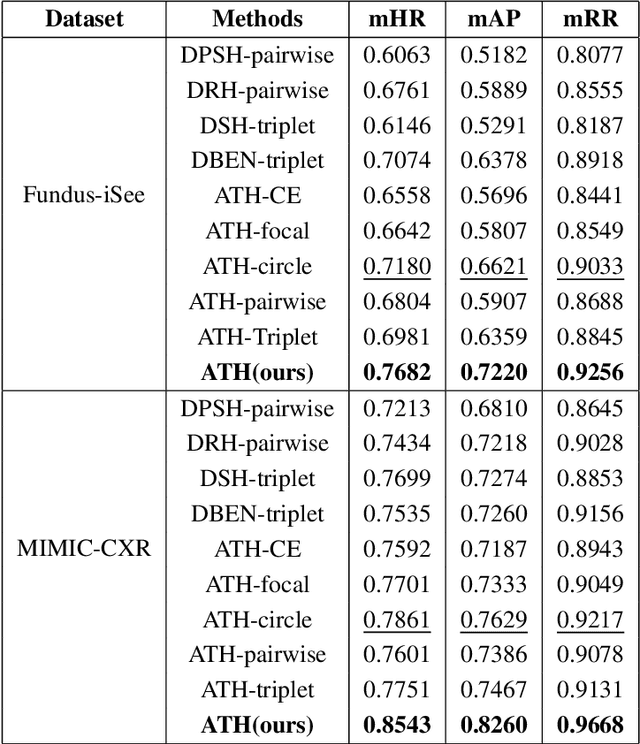
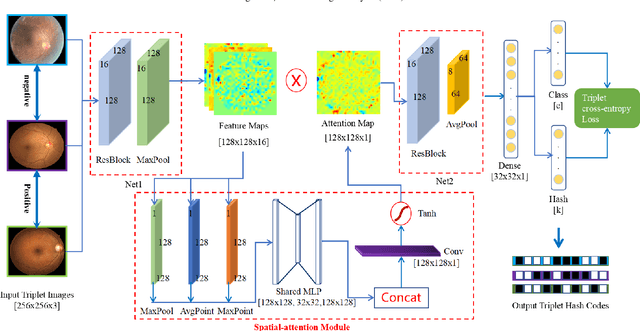
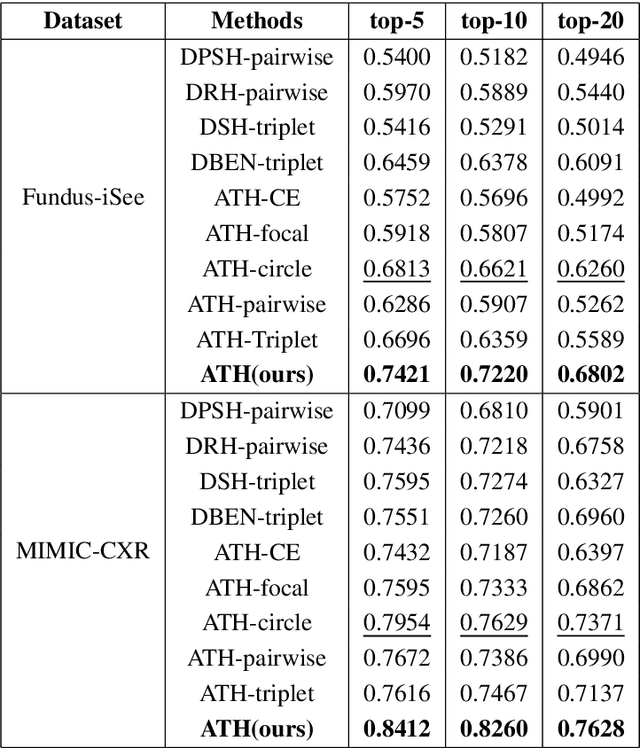
Deep hashing methods have been shown to be the most efficient approximate nearest neighbor search techniques for large-scale image retrieval. However, existing deep hashing methods have a poor small-sample ranking performance for case-based medical image retrieval. The top-ranked images in the returned query results may be as a different class than the query image. This ranking problem is caused by classification, regions of interest (ROI), and small-sample information loss in the hashing space. To address the ranking problem, we propose an end-to-end framework, called Attention-based Triplet Hashing (ATH) network, to learn low-dimensional hash codes that preserve the classification, ROI, and small-sample information. We embed a spatial-attention module into the network structure of our ATH to focus on ROI information. The spatial-attention module aggregates the spatial information of feature maps by utilizing max-pooling, element-wise maximum, and element-wise mean operations jointly along the channel axis. The triplet cross-entropy loss can help to map the classification information of images and similarity between images into the hash codes. Extensive experiments on two case-based medical datasets demonstrate that our proposed ATH can further improve the retrieval performance compared to the state-of-the-art deep hashing methods and boost the ranking performance for small samples. Compared to the other loss methods, the triplet cross-entropy loss can enhance the classification performance and hash code-discriminability
Effective Evaluation of Deep Active Learning on Image Classification Tasks
Jun 30, 2021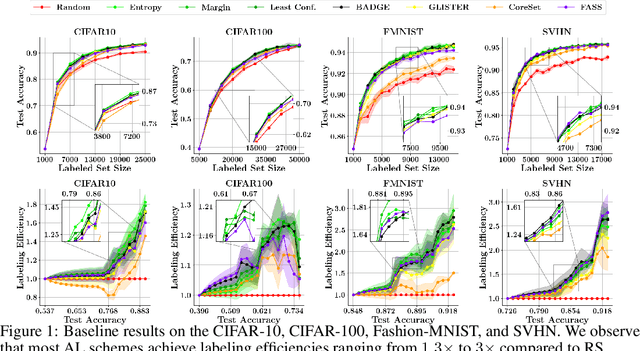
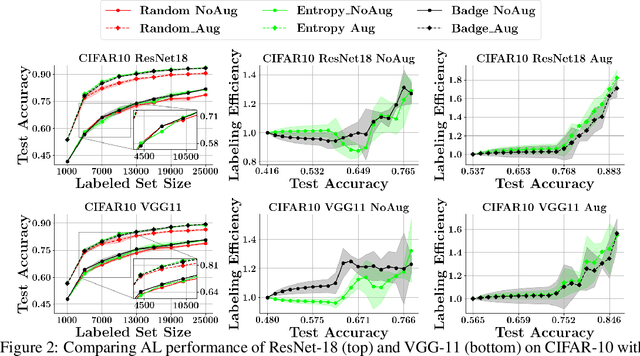
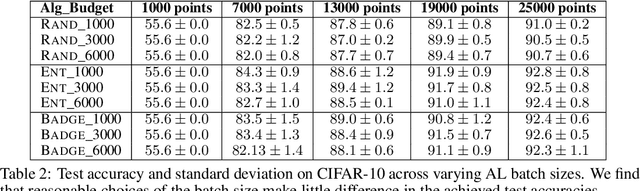
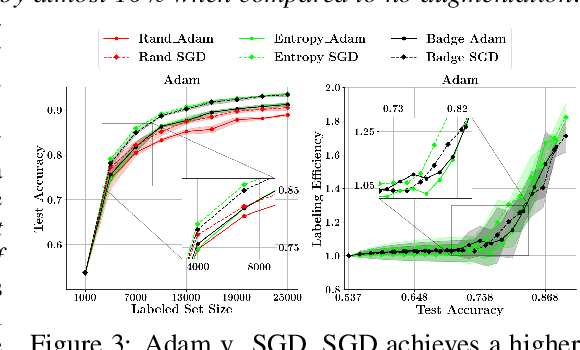
With the goal of making deep learning more label-efficient, a growing number of papers have been studying active learning (AL) for deep models. However, there are a number of issues in the prevalent experimental settings, mainly stemming from a lack of unified implementation and benchmarking. Issues in the current literature include sometimes contradictory observations on the performance of different AL algorithms, unintended exclusion of important generalization approaches such as data augmentation and SGD for optimization, a lack of study of evaluation facets like the labeling efficiency of AL, and little or no clarity on the scenarios in which AL outperforms random sampling (RS). In this work, we present a unified re-implementation of state-of-the-art AL algorithms in the context of image classification, and we carefully study these issues as facets of effective evaluation. On the positive side, we show that AL techniques are 2x to 4x more label-efficient compared to RS with the use of data augmentation. Surprisingly, when data augmentation is included, there is no longer a consistent gain in using BADGE, a state-of-the-art approach, over simple uncertainty sampling. We then do a careful analysis of how existing approaches perform with varying amounts of redundancy and number of examples per class. Finally, we provide several insights for AL practitioners to consider in future work, such as the effect of the AL batch size, the effect of initialization, the importance of retraining a new model at every round, and other insights.
YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
Apr 14, 2022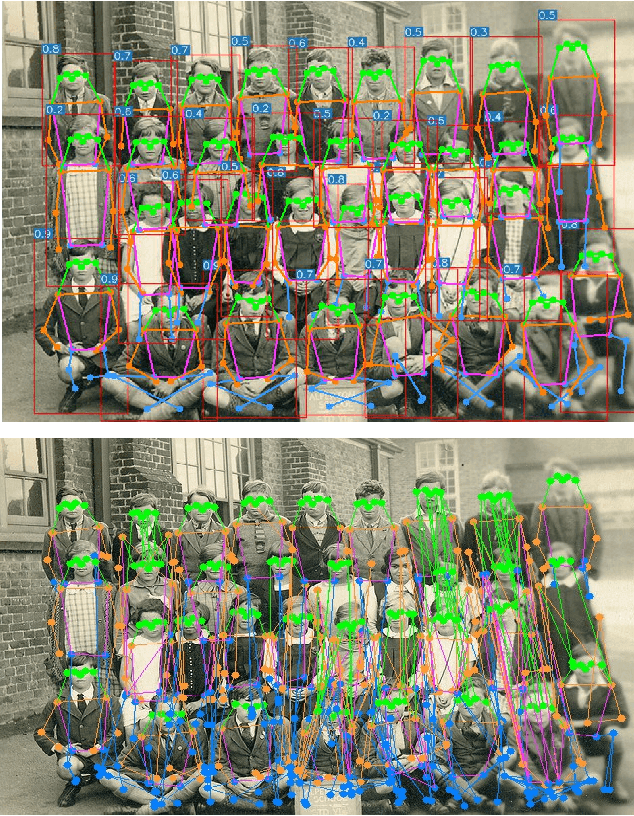
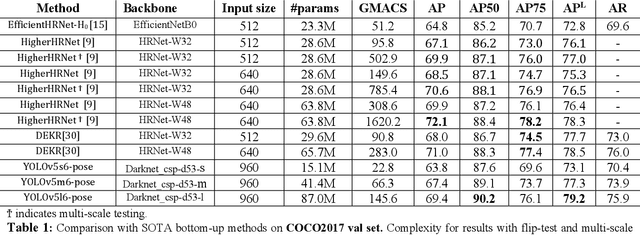
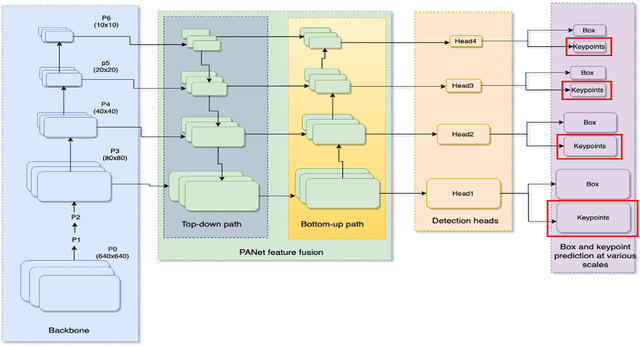
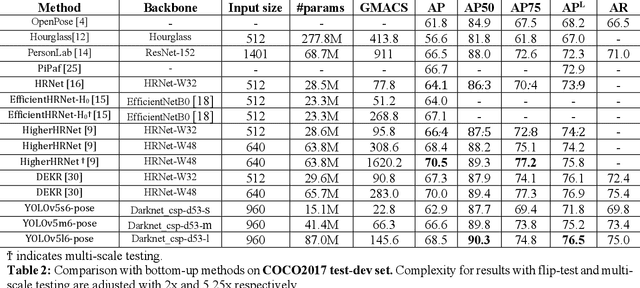
We introduce YOLO-pose, a novel heatmap-free approach for joint detection, and 2D multi-person pose estimation in an image based on the popular YOLO object detection framework. Existing heatmap based two-stage approaches are sub-optimal as they are not end-to-end trainable and training relies on a surrogate L1 loss that is not equivalent to maximizing the evaluation metric, i.e. Object Keypoint Similarity (OKS). Our framework allows us to train the model end-to-end and optimize the OKS metric itself. The proposed model learns to jointly detect bounding boxes for multiple persons and their corresponding 2D poses in a single forward pass and thus bringing in the best of both top-down and bottom-up approaches. Proposed approach doesn't require the postprocessing of bottom-up approaches to group detected keypoints into a skeleton as each bounding box has an associated pose, resulting in an inherent grouping of the keypoints. Unlike top-down approaches, multiple forward passes are done away with since all persons are localized along with their pose in a single inference. YOLO-pose achieves new state-of-the-art results on COCO validation (90.2% AP50) and test-dev set (90.3% AP50), surpassing all existing bottom-up approaches in a single forward pass without flip test, multi-scale testing, or any other test time augmentation. All experiments and results reported in this paper are without any test time augmentation, unlike traditional approaches that use flip-test and multi-scale testing to boost performance. Our training codes will be made publicly available at https://github.com/TexasInstruments/edgeai-yolov5 and https://github.com/TexasInstruments/edgeai-yolox
Scene Graph Generation with Geometric Context
Nov 25, 2021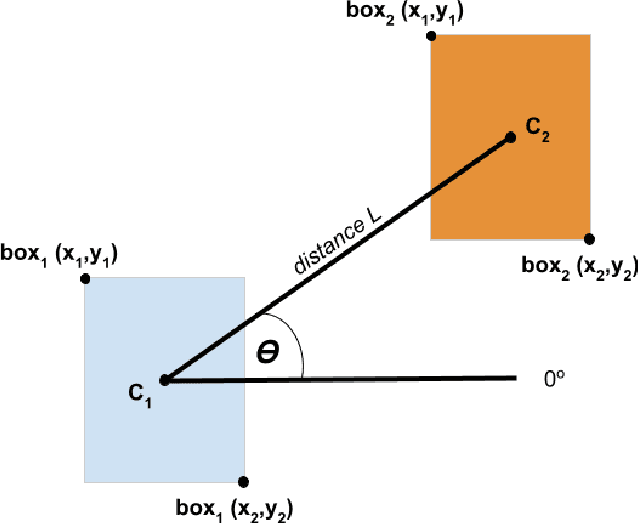

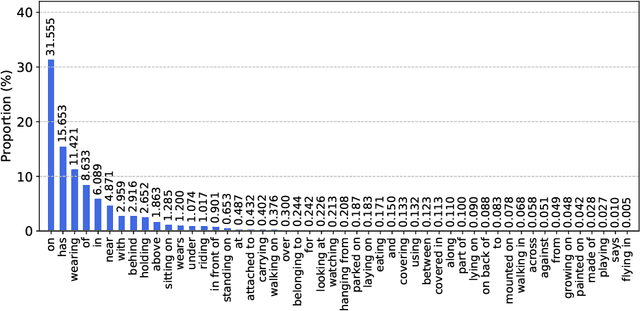
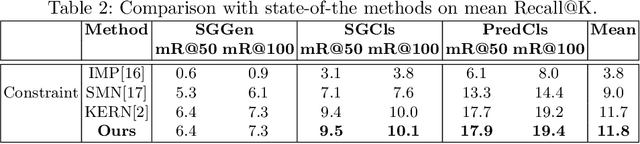
Scene Graph Generation has gained much attention in computer vision research with the growing demand in image understanding projects like visual question answering, image captioning, self-driving cars, crowd behavior analysis, activity recognition, and more. Scene graph, a visually grounded graphical structure of an image, immensely helps to simplify the image understanding tasks. In this work, we introduced a post-processing algorithm called Geometric Context to understand the visual scenes better geometrically. We use this post-processing algorithm to add and refine the geometric relationships between object pairs to a prior model. We exploit this context by calculating the direction and distance between object pairs. We use Knowledge Embedded Routing Network (KERN) as our baseline model, extend the work with our algorithm, and show comparable results on the recent state-of-the-art algorithms.
RestoreFormer: High-Quality Blind Face Restoration From Undegraded Key-Value Pairs
Jan 17, 2022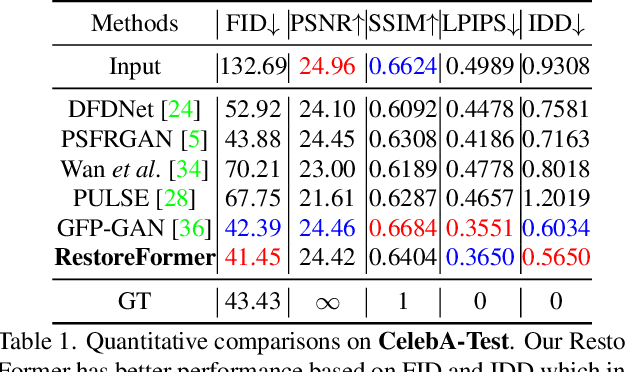
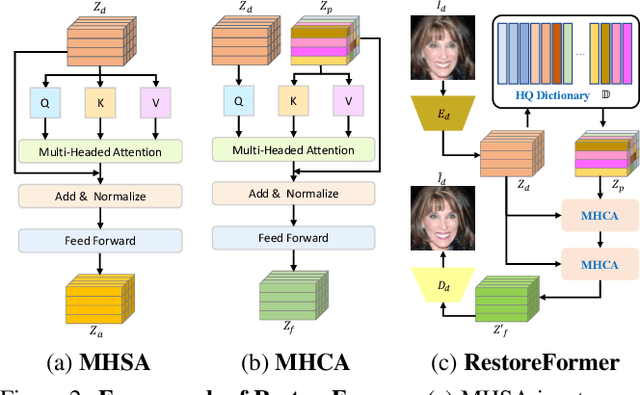
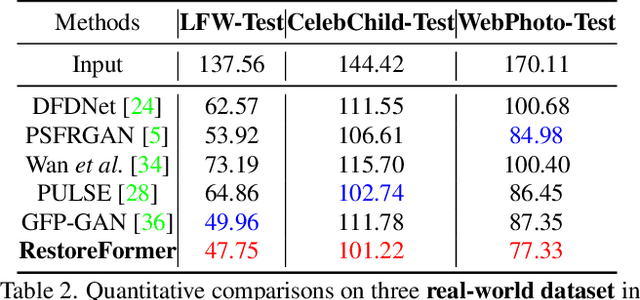
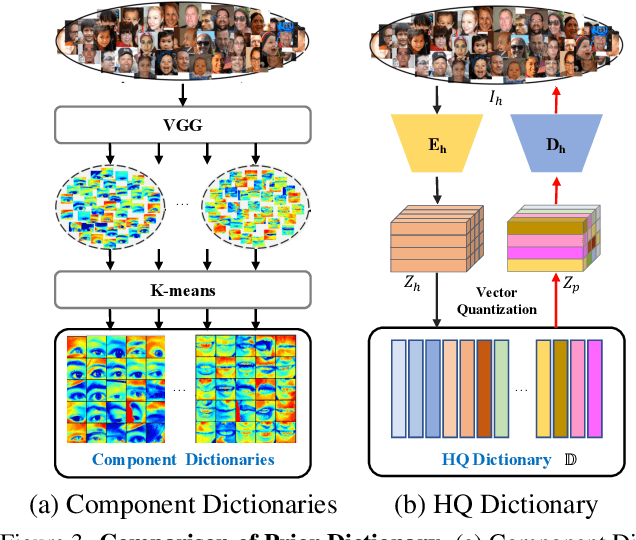
Blind face restoration is to recover a high-quality face image from unknown degradations. As face image contains abundant contextual information, we propose a method, RestoreFormer, which explores fully-spatial attentions to model contextual information and surpasses existing works that use local operators. RestoreFormer has several benefits compared to prior arts. First, unlike the conventional multi-head self-attention in previous Vision Transformers (ViTs), RestoreFormer incorporates a multi-head cross-attention layer to learn fully-spatial interactions between corrupted queries and high-quality key-value pairs. Second, the key-value pairs in ResotreFormer are sampled from a reconstruction-oriented high-quality dictionary, whose elements are rich in high-quality facial features specifically aimed for face reconstruction, leading to superior restoration results. Third, RestoreFormer outperforms advanced state-of-the-art methods on one synthetic dataset and three real-world datasets, as well as produces images with better visual quality.
Semi-Supervised Learning for Eye Image Segmentation
Mar 17, 2021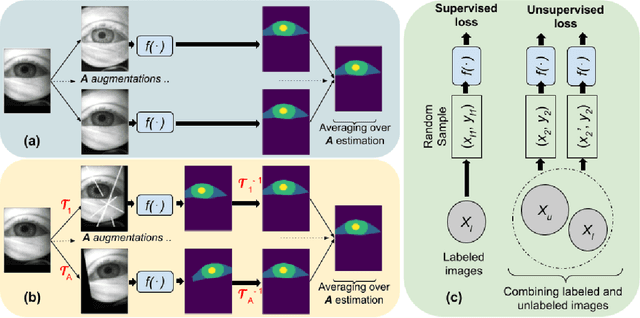
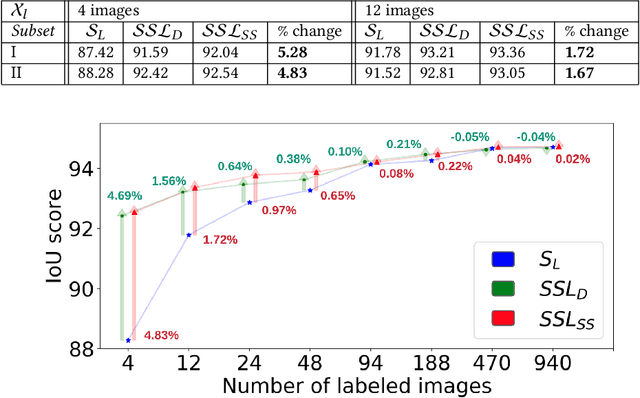
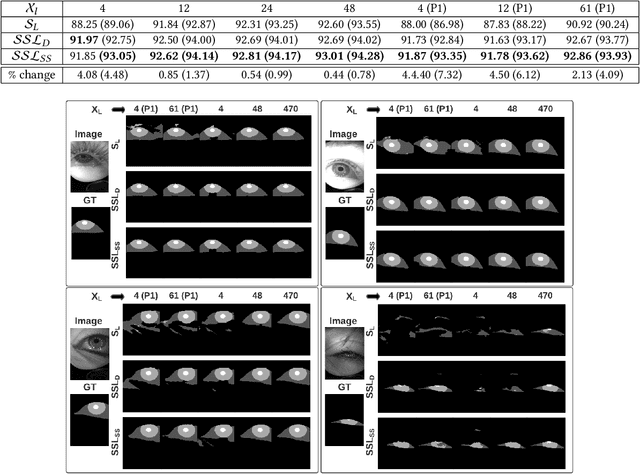
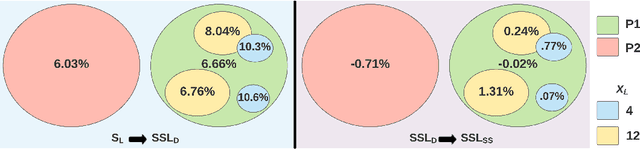
Recent advances in appearance-based models have shown improved eye tracking performance in difficult scenarios like occlusion due to eyelashes, eyelids or camera placement, and environmental reflections on the cornea and glasses. The key reason for the improvement is the accurate and robust identification of eye parts (pupil, iris, and sclera regions). The improved accuracy often comes at the cost of labeling an enormous dataset, which is complex and time-consuming. This work presents two semi-supervised learning frameworks to identify eye-parts by taking advantage of unlabeled images where labeled datasets are scarce. With these frameworks, leveraging the domain-specific augmentation and novel spatially varying transformations for image segmentation, we show improved performance on various test cases. For instance, for a model trained on just 48 labeled images, these frameworks achieved an improvement of 0.38% and 0.65% in segmentation performance over the baseline model, which is trained only with the labeled dataset.
Tactile Image-to-Image Disentanglement of Contact Geometry from Motion-Induced Shear
Sep 08, 2021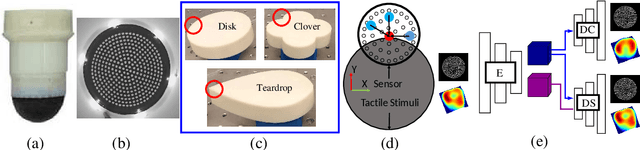
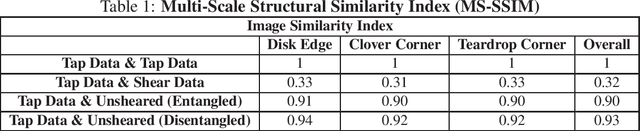
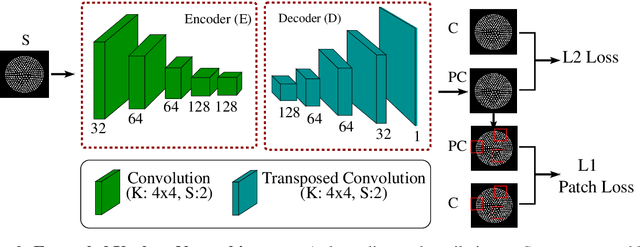
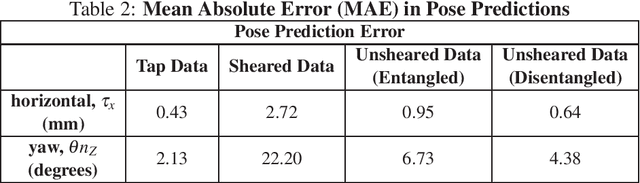
Robotic touch, particularly when using soft optical tactile sensors, suffers from distortion caused by motion-dependent shear. The manner in which the sensor contacts a stimulus is entangled with the tactile information about the geometry of the stimulus. In this work, we propose a supervised convolutional deep neural network model that learns to disentangle, in the latent space, the components of sensor deformations caused by contact geometry from those due to sliding-induced shear. The approach is validated by reconstructing unsheared tactile images from sheared images and showing they match unsheared tactile images collected with no sliding motion. In addition, the unsheared tactile images give a faithful reconstruction of the contact geometry that is not possible from the sheared data, and robust estimation of the contact pose that can be used for servo control sliding around various 2D shapes. Finally, the contact geometry reconstruction in conjunction with servo control sliding were used for faithful full object reconstruction of various 2D shapes. The methods have broad applicability to deep learning models for robots with a shear-sensitive sense of touch.