 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly-Supervised Semantic Segmentation with Visual Words Learning and Hybrid Pooling
Feb 10, 2022

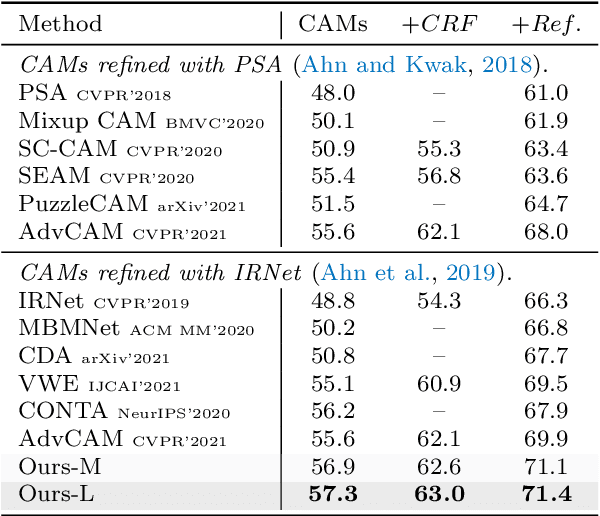
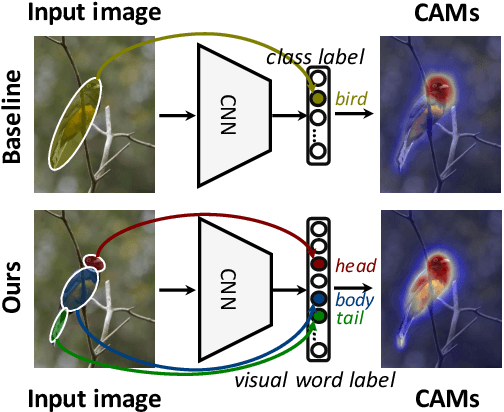
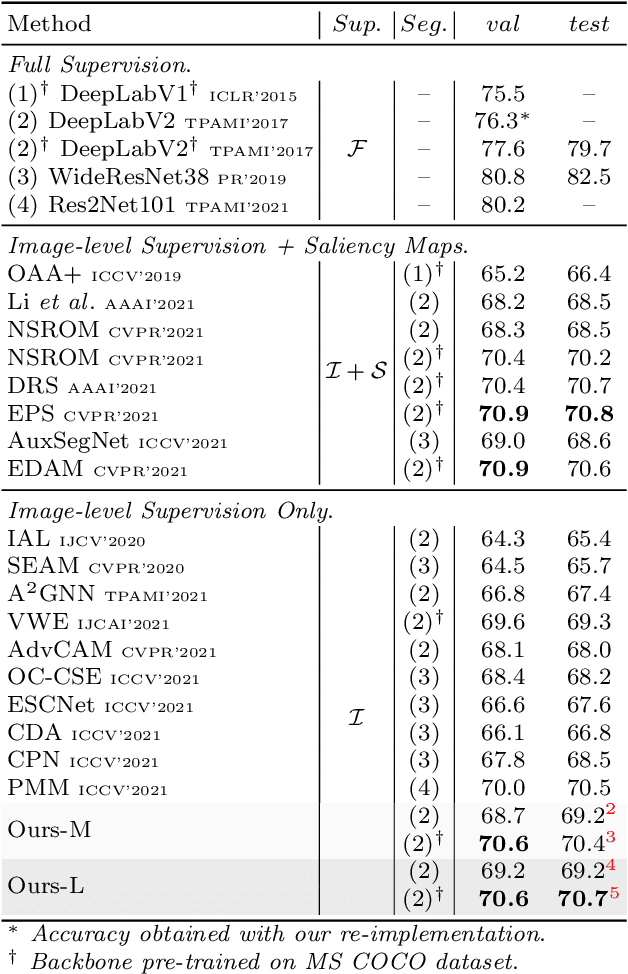
Weakly-Supervised Semantic Segmentation (WSSS) methods with image-level labels generally train a classification network to generate the Class Activation Maps (CAMs) as the initial coarse segmentation labels. However, current WSSS methods still perform far from satisfactorily because their adopted CAMs 1) typically focus on partial discriminative object regions and 2) usually contain useless background regions. These two problems are attributed to the sole image-level supervision and aggregation of global information when training the classification networks. In this work, we propose the visual words learning module and hybrid pooling approach, and incorporate them in the classification network to mitigate the above problems. In the visual words learning module, we counter the first problem by enforcing the classification network to learn fine-grained visual word labels so that more object extents could be discovered. Specifically, the visual words are learned with a codebook, which could be updated via two proposed strategies, i.e. learning-based strategy and memory-bank strategy. The second drawback of CAMs is alleviated with the proposed hybrid pooling, which incorporates the global average and local discriminative information to simultaneously ensure object completeness and reduce background regions. We evaluated our methods on PASCAL VOC 2012 and MS COCO 2014 datasets. Without any extra saliency prior, our method achieved 70.6% and 70.7% mIoU on the $val$ and $test$ set of PASCAL VOC dataset, respectively, and 36.2% mIoU on the $val$ set of MS COCO dataset, which significantly surpassed the performance of state-of-the-art WSSS methods.
Improving Performance of Semantic Segmentation CycleGANs by Noise Injection into the Latent Segmentation Space
Jan 17, 2022In recent years, semantic segmentation has taken benefit from various works in computer vision. Inspired by the very versatile CycleGAN architecture, we combine semantic segmentation with the concept of cycle consistency to enable a multitask training protocol. However, learning is largely prevented by the so-called steganography effect, which expresses itself as watermarks in the latent segmentation domain, making image reconstruction a too easy task. To combat this, we propose a noise injection, based either on quantization noise or on Gaussian noise addition to avoid this disadvantageous information flow in the cycle architecture. We find that noise injection significantly reduces the generation of watermarks and thus allows the recognition of highly relevant classes such as "traffic signs", which are hardly detected by the ERFNet baseline. We report mIoU and PSNR results on the Cityscapes dataset for semantic segmentation and image reconstruction, respectively. The proposed methodology allows to achieve an mIoU improvement on the Cityscapes validation set of 5.7% absolute over the same CycleGAN without noise injection, and still an absolute 4.9% over the ERFNet non-cyclic baseline.
ArtFlow: Unbiased Image Style Transfer via Reversible Neural Flows
Mar 31, 2021

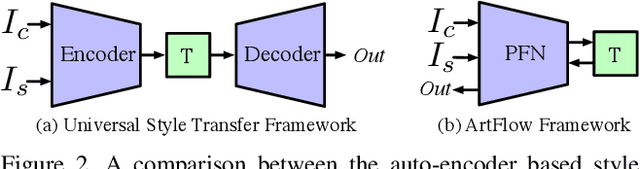

Universal style transfer retains styles from reference images in content images. While existing methods have achieved state-of-the-art style transfer performance, they are not aware of the content leak phenomenon that the image content may corrupt after several rounds of stylization process. In this paper, we propose ArtFlow to prevent content leak during universal style transfer. ArtFlow consists of reversible neural flows and an unbiased feature transfer module. It supports both forward and backward inferences and operates in a projection-transfer-reversion scheme. The forward inference projects input images into deep features, while the backward inference remaps deep features back to input images in a lossless and unbiased way. Extensive experiments demonstrate that ArtFlow achieves comparable performance to state-of-the-art style transfer methods while avoiding content leak.
Classifications of Skull Fractures using CT Scan Images via CNN with Lazy Learning Approach
Mar 21, 2022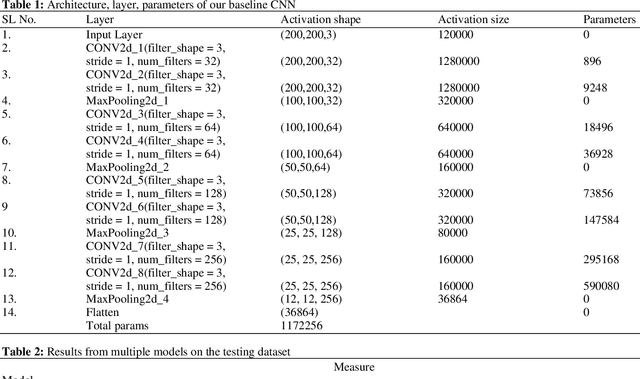
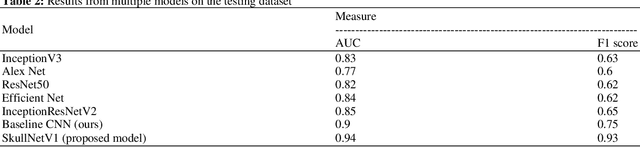
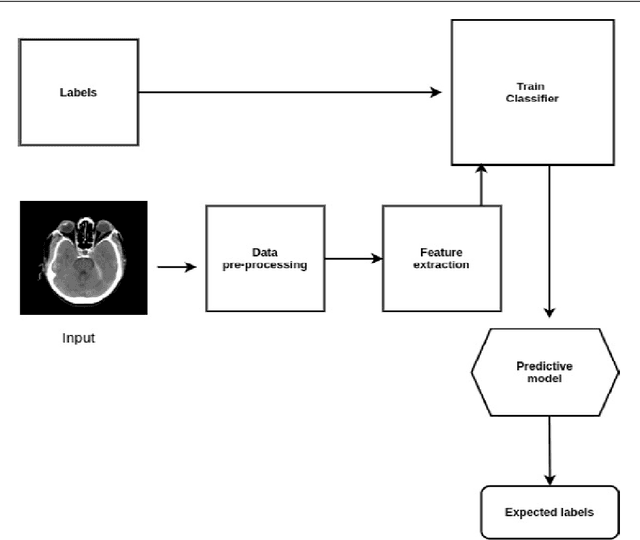
Classification of skull fracture is a challenging task for both radiologists and researchers. Skull fractures result in broken pieces of bone, which can cut into the brain and cause bleeding and other injury types. So it is vital to detect and classify the fracture very early. In real world, often fractures occur at multiple sites. This makes it harder to detect the fracture type where many fracture types might summarize a skull fracture. Unfortunately, manual detection of skull fracture and the classification process is time-consuming, threatening a patient's life. Because of the emergence of deep learning, this process could be automated. Convolutional Neural Networks (CNNs) are the most widely used deep learning models for image categorization because they deliver high accuracy and outstanding outcomes compared to other models. We propose a new model called SkullNetV1 comprising a novel CNN by taking advantage of CNN for feature extraction and lazy learning approach which acts as a classifier for classification of skull fractures from brain CT images to classify five fracture types. Our suggested model achieved a subset accuracy of 88%, an F1 score of 93%, the Area Under the Curve (AUC) of 0.89 to 0.98, a Hamming score of 92% and a Hamming loss of 0.04 for this seven-class multi-labeled classification.
Self-supervised Transparent Liquid Segmentation for Robotic Pouring
Mar 03, 2022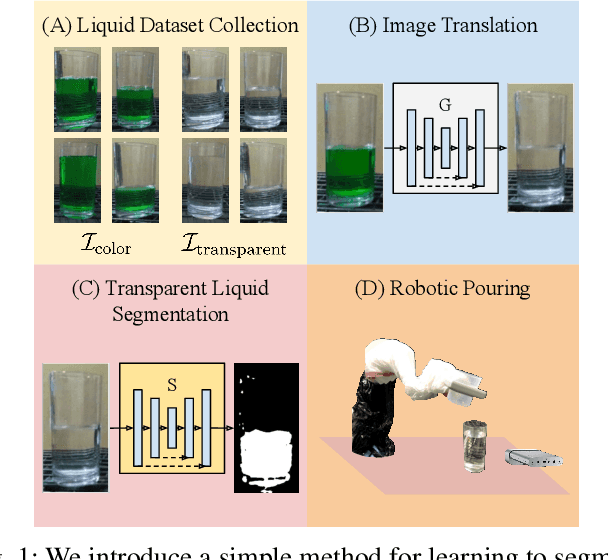
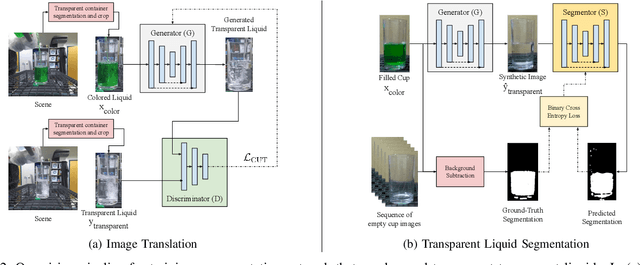
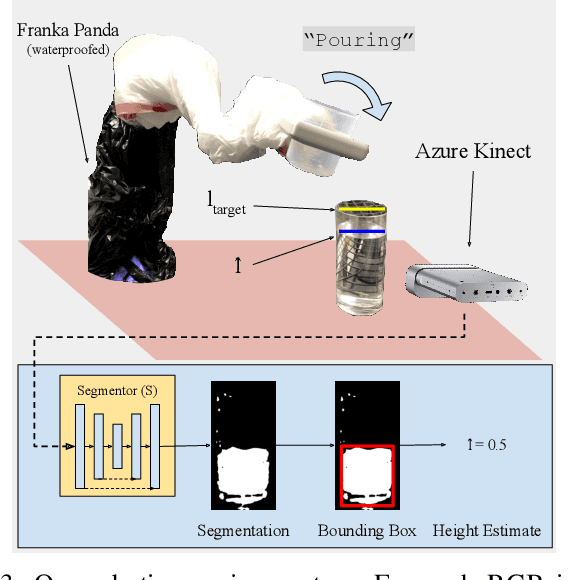

Liquid state estimation is important for robotics tasks such as pouring; however, estimating the state of transparent liquids is a challenging problem. We propose a novel segmentation pipeline that can segment transparent liquids such as water from a static, RGB image without requiring any manual annotations or heating of the liquid for training. Instead, we use a generative model that is capable of translating images of colored liquids into synthetically generated transparent liquid images, trained only on an unpaired dataset of colored and transparent liquid images. Segmentation labels of colored liquids are obtained automatically using background subtraction. Our experiments show that we are able to accurately predict a segmentation mask for transparent liquids without requiring any manual annotations. We demonstrate the utility of transparent liquid segmentation in a robotic pouring task that controls pouring by perceiving the liquid height in a transparent cup. Accompanying video and supplementary materials can be found
* Accepted at ICRA 2022
Parallel Discrete Convolutions on Adaptive Particle Representations of Images
Dec 07, 2021



We present data structures and algorithms for native implementations of discrete convolution operators over Adaptive Particle Representations (APR) of images on parallel computer architectures. The APR is a content-adaptive image representation that locally adapts the sampling resolution to the image signal. It has been developed as an alternative to pixel representations for large, sparse images as they typically occur in fluorescence microscopy. It has been shown to reduce the memory and runtime costs of storing, visualizing, and processing such images. This, however, requires that image processing natively operates on APRs, without intermediately reverting to pixels. Designing efficient and scalable APR-native image processing primitives, however, is complicated by the APR's irregular memory structure. Here, we provide the algorithmic building blocks required to efficiently and natively process APR images using a wide range of algorithms that can be formulated in terms of discrete convolutions. We show that APR convolution naturally leads to scale-adaptive algorithms that efficiently parallelize on multi-core CPU and GPU architectures. We quantify the speedups in comparison to pixel-based algorithms and convolutions on evenly sampled data. We achieve pixel-equivalent throughputs of up to 1 TB/s on a single Nvidia GeForce RTX 2080 gaming GPU, requiring up to two orders of magnitude less memory than a pixel-based implementation.
Learning Perspective Deformation in X-Ray Transmission Imaging
Feb 13, 2022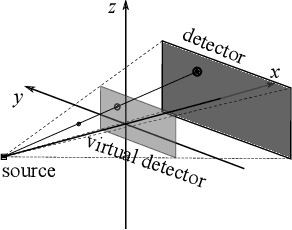

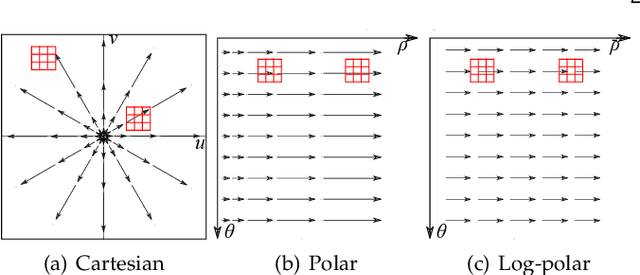

In cone-beam X-ray transmission imaging, due to the divergence of X-rays, imaged structures with different depths have different magnification factors on an X-ray detector, which results in perspective deformation. Perspective deformation causes difficulty in direct, accurate geometric assessments of anatomical structures. In this work, to reduce perspective deformation in X-ray images acquired from regular cone-beam computed tomography (CBCT) systems, we investigate on learning perspective deformation, i.e., converting perspective projections into orthogonal projections. Directly converting a single perspective projection image into an orthogonal projection image is extremely challenging due to the lack of depth information. Therefore, we propose to utilize one additional perspective projection, a complementary (180-degree) or orthogonal (90-degree) view, to provide a certain degree of depth information. Furthermore, learning perspective deformation in different spatial domains is investigated. Our proposed method is evaluated on numerical spherical bead phantoms as well as patients' chest and head X-ray data. The experiments on numerical bead phantom data demonstrate that learning perspective deformation in polar coordinates has significant advantages over learning in Cartesian coordinates, as root-mean-square error (RMSE) decreases from 5.31 to 1.40, while learning in log-polar coordinates has no further considerable improvement (RMSE = 1.85). In addition, using a complementary view (RMSE = 1.40) is better than an orthogonal view (RMSE = 3.87). The experiments on patients' chest and head data demonstrate that learning perspective deformation using dual complementary views is also applicable in anatomical X-ray data, allowing accurate cardiothoracic ratio measurements in chest X-ray images and cephalometric analysis in synthetic cephalograms from cone-beam X-ray projections.
CPTR: Full Transformer Network for Image Captioning
Jan 26, 2021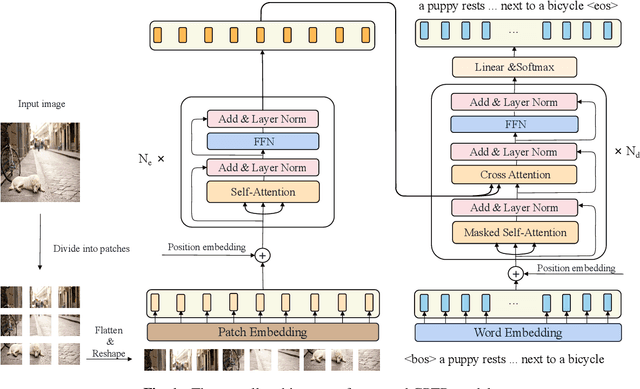


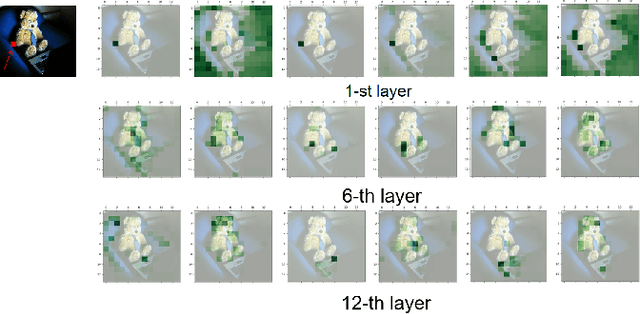
In this paper, we consider the image captioning task from a new sequence-to-sequence prediction perspective and propose Caption TransformeR (CPTR) which takes the sequentialized raw images as the input to Transformer. Compared to the "CNN+Transformer" design paradigm, our model can model global context at every encoder layer from the beginning and is totally convolution-free. Extensive experiments demonstrate the effectiveness of the proposed model and we surpass the conventional "CNN+Transformer" methods on the MSCOCO dataset. Besides, we provide detailed visualizations of the self-attention between patches in the encoder and the "words-to-patches" attention in the decoder thanks to the full Transformer architecture.
Content-aware Warping for View Synthesis
Jan 22, 2022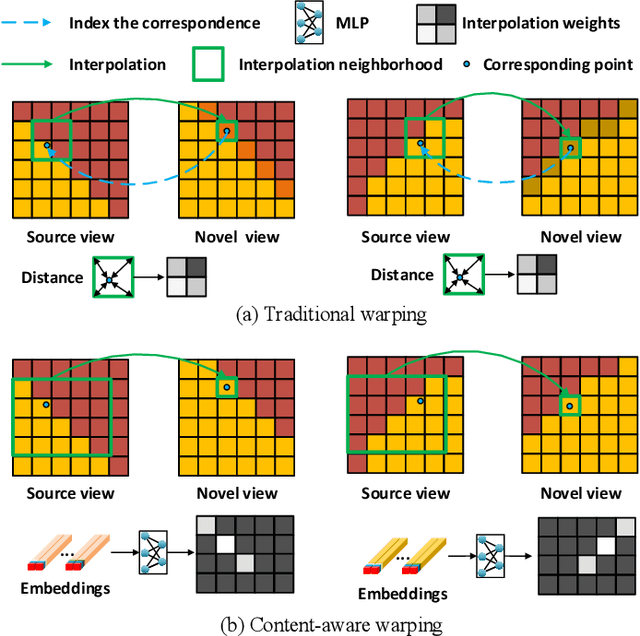
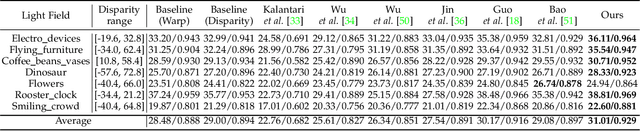
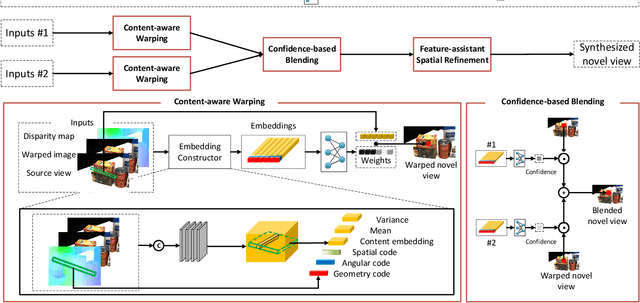

Existing image-based rendering methods usually adopt depth-based image warping operation to synthesize novel views. In this paper, we reason the essential limitations of the traditional warping operation to be the limited neighborhood and only distance-based interpolation weights. To this end, we propose content-aware warping, which adaptively learns the interpolation weights for pixels of a relatively large neighborhood from their contextual information via a lightweight neural network. Based on this learnable warping module, we propose a new end-to-end learning-based framework for novel view synthesis from two input source views, in which two additional modules, namely confidence-based blending and feature-assistant spatial refinement, are naturally proposed to handle the occlusion issue and capture the spatial correlation among pixels of the synthesized view, respectively. Besides, we also propose a weight-smoothness loss term to regularize the network. Experimental results on structured light field datasets with wide baselines and unstructured multi-view datasets show that the proposed method significantly outperforms state-of-the-art methods both quantitatively and visually. The source code will be publicly available at https://github.com/MantangGuo/CW4VS.
MonoJSG: Joint Semantic and Geometric Cost Volume for Monocular 3D Object Detection
Mar 16, 2022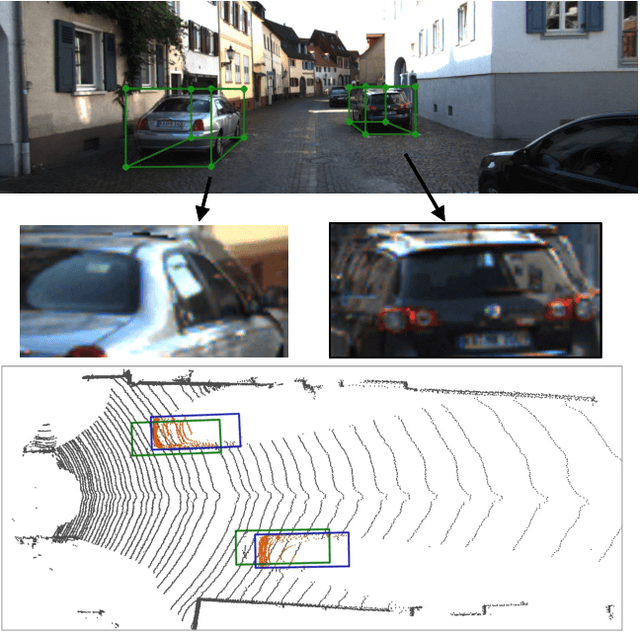
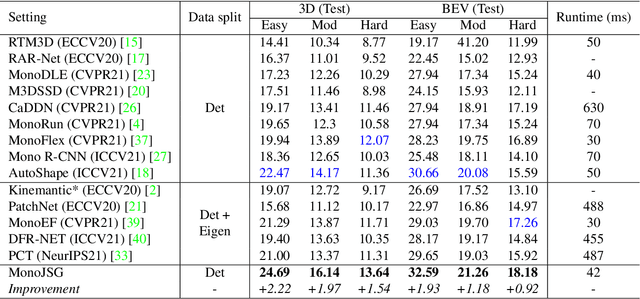
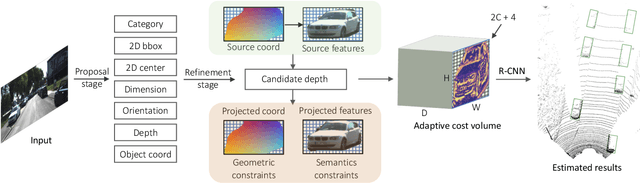
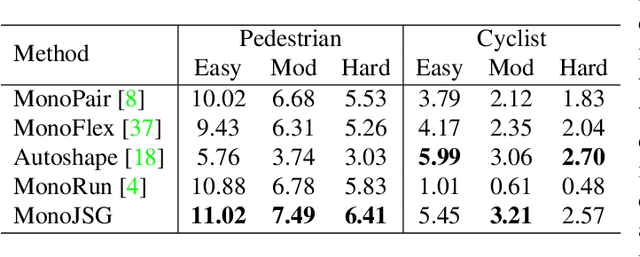
Due to the inherent ill-posed nature of 2D-3D projection, monocular 3D object detection lacks accurate depth recovery ability. Although the deep neural network (DNN) enables monocular depth-sensing from high-level learned features, the pixel-level cues are usually omitted due to the deep convolution mechanism. To benefit from both the powerful feature representation in DNN and pixel-level geometric constraints, we reformulate the monocular object depth estimation as a progressive refinement problem and propose a joint semantic and geometric cost volume to model the depth error. Specifically, we first leverage neural networks to learn the object position, dimension, and dense normalized 3D object coordinates. Based on the object depth, the dense coordinates patch together with the corresponding object features is reprojected to the image space to build a cost volume in a joint semantic and geometric error manner. The final depth is obtained by feeding the cost volume to a refinement network, where the distribution of semantic and geometric error is regularized by direct depth supervision. Through effectively mitigating depth error by the refinement framework, we achieve state-of-the-art results on both the KITTI and Waymo datasets.