 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Checkerboard-Artifact-Free Image-Enhancement Network Considering Local and Global Features
Oct 13, 2020

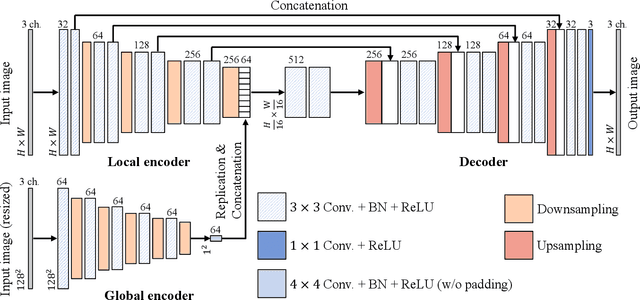
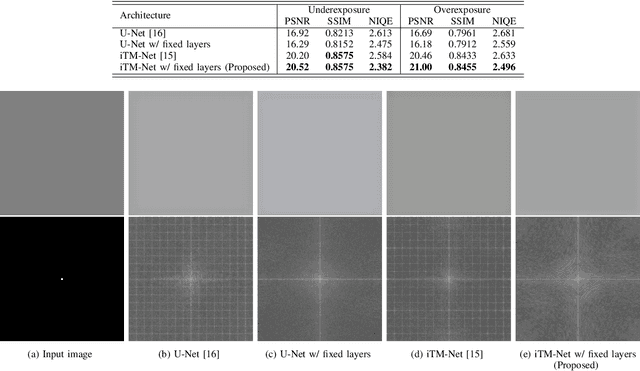

In this paper, we propose a novel convolutional neural network (CNN) that never causes checkerboard artifacts, for image enhancement. In research fields of image-to-image translation problems, it is well-known that images generated by usual CNNs are distorted by checkerboard artifacts which mainly caused in forward-propagation of upsampling layers. However, checkerboard artifacts in image enhancement have never been discussed. In this paper, we point out that applying U-Net based CNNs to image enhancement causes checkerboard artifacts. In contrast, the proposed network that contains fixed convolutional layers can perfectly prevent the artifacts. In addition, the proposed network architecture, which can handle both local and global features, enables us to improve the performance of image enhancement. Experimental results show that the use of fixed convolutional layers can prevent checkerboard artifacts and the proposed network outperforms state-of-the-art CNN-based image-enhancement methods in terms of various objective quality metrics: PSNR, SSIM, and NIQE.
Face Deblurring Based on Separable Normalization and Adaptive Denormalization
Dec 18, 2021



Face deblurring aims to restore a clear face image from a blurred input image with more explicit structure and facial details. However, most conventional image and face deblurring methods focus on the whole generated image resolution without consideration of special face part texture and generally produce unsufficient details. Considering that faces and backgrounds have different distribution information, in this study, we designed an effective face deblurring network based on separable normalization and adaptive denormalization (SNADNet). First, We fine-tuned the face parsing network to obtain an accurate face structure. Then, we divided the face parsing feature into face foreground and background. Moreover, we constructed a new feature adaptive denormalization to regularize fafcial structures as a condition of the auxiliary to generate more harmonious and undistorted face structure. In addition, we proposed a texture extractor and multi-patch discriminator to enhance the generated facial texture information. Experimental results on both CelebA and CelebA-HQ datasets demonstrate that the proposed face deblurring network restores face structure with more facial details and performs favorably against state-of-the-art methods in terms of structured similarity indexing method (SSIM), peak signal-to-noise ratio (PSNR), Frechet inception distance (FID) and L1, and qualitative comparisons.
Learning Spatial and Spatio-Temporal Pixel Aggregations for Image and Video Denoising
Jan 26, 2021
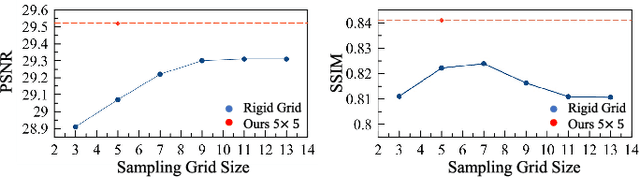
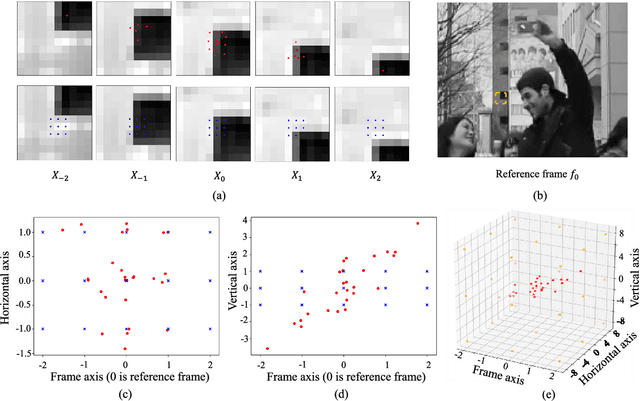
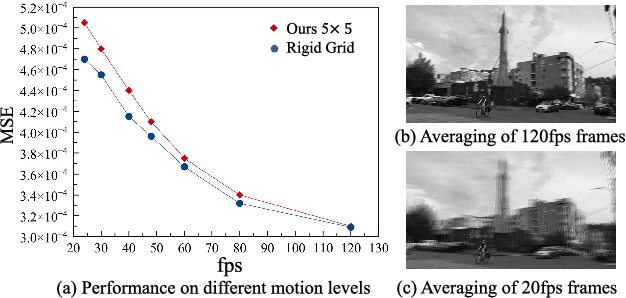
Existing denoising methods typically restore clear results by aggregating pixels from the noisy input. Instead of relying on hand-crafted aggregation schemes, we propose to explicitly learn this process with deep neural networks. We present a spatial pixel aggregation network and learn the pixel sampling and averaging strategies for image denoising. The proposed model naturally adapts to image structures and can effectively improve the denoised results. Furthermore, we develop a spatio-temporal pixel aggregation network for video denoising to efficiently sample pixels across the spatio-temporal space. Our method is able to solve the misalignment issues caused by large motion in dynamic scenes. In addition, we introduce a new regularization term for effectively training the proposed video denoising model. We present extensive analysis of the proposed method and demonstrate that our model performs favorably against the state-of-the-art image and video denoising approaches on both synthetic and real-world data.
* Project page: https://sites.google.com/view/xiangyuxu/denoise_stpan. arXiv admin note: substantial text overlap with arXiv:1904.06903
I2L-MeshNet: Image-to-Lixel Prediction Network for Accurate 3D Human Pose and Mesh Estimation from a Single RGB Image
Aug 09, 2020
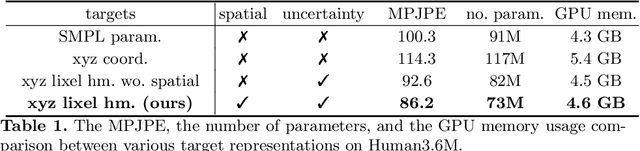
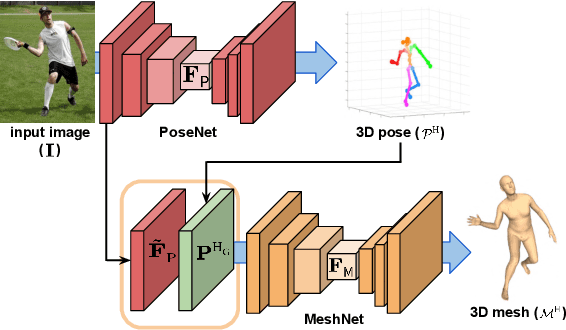
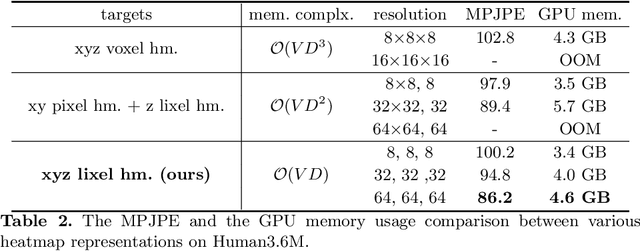
Most of the previous image-based 3D human pose and mesh estimation methods estimate parameters of the human mesh model from an input image. However, directly regressing the parameters from the input image is a highly non-linear mapping because it breaks the spatial relationship between pixels in the input image. In addition, it cannot model the prediction uncertainty, which can make training harder. To resolve the above issues, we propose I2L-MeshNet, an image-to-lixel (line+pixel) prediction network. The proposed I2L-MeshNet predicts the per-lixel likelihood on 1D heatmaps for each mesh vertex coordinate instead of directly regressing the parameters. Our lixel-based 1D heatmap preserves the spatial relationship in the input image and models the prediction uncertainty. We demonstrate the benefit of the image-to-lixel prediction and show that the proposed I2L-MeshNet outperforms previous methods. The code is publicly available \footnote{\url{https://github.com/mks0601/I2L-MeshNet_RELEASE}}.
Benchmarking the performance of a low-cost Magnetic Resonance Control System at multiple sites in the open MaRCoS community
Mar 21, 2022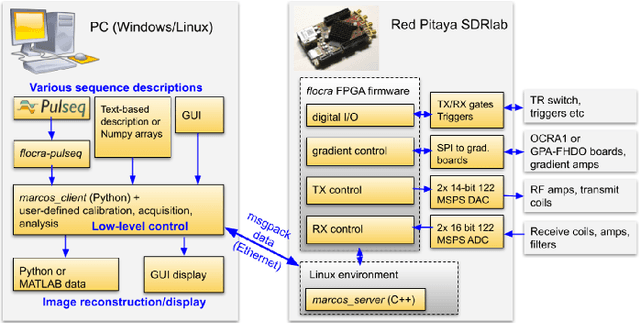
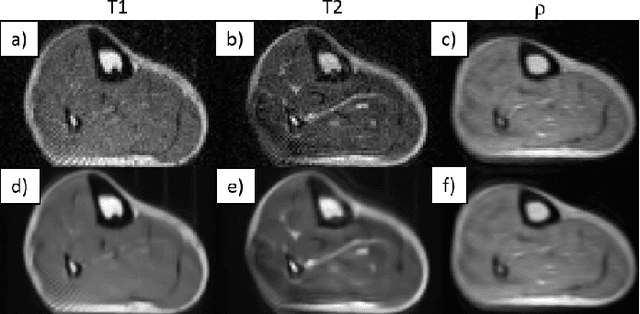

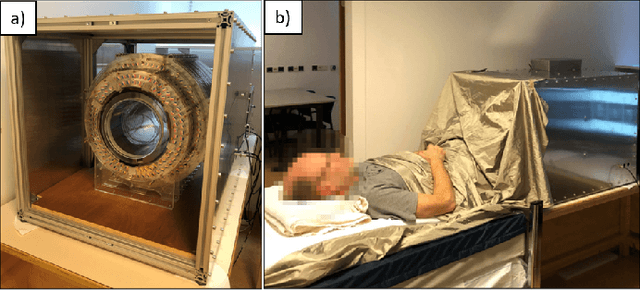
Purpose: To describe the current properties and capabilities of an open-source hardware and software package that is being developed by many sites internationally with the aim of providing an inexpensive yet flexible platform for low-cost MRI. Methods: This paper describes three different setups from 50 to 360 mT in different settings, all of which used the MaRCoS console for acquiring data, and different types of software interfaces (custom-built GUI or PulSeq overlay) to acquire the data. Results: Images are presented from both phantoms and in vivo from healthy volunteers to demonstrate the image quality that can be obtained from the MaRCoS hardware/software interfaced to different low-field magnets. Conclusions: The results presented here show that a number of different sequences commonly used in the clinic can be programmed into an open-source system relatively quickly and easily, and can produce good quality images even at this early stage of development. Both the hardware and software will continue to develop, and it is an aim of this paper to encourage other groups to join this international consortium.
Condensing a Sequence to One Informative Frame for Video Recognition
Jan 11, 2022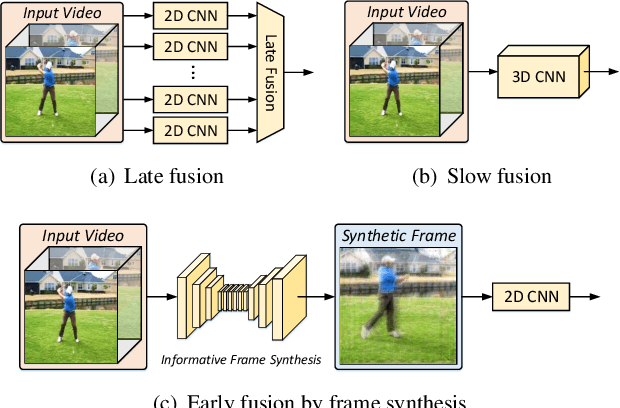
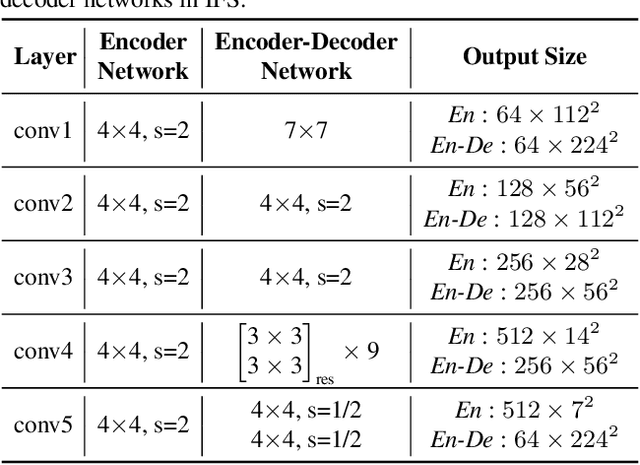
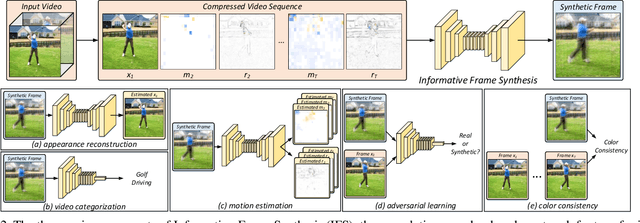
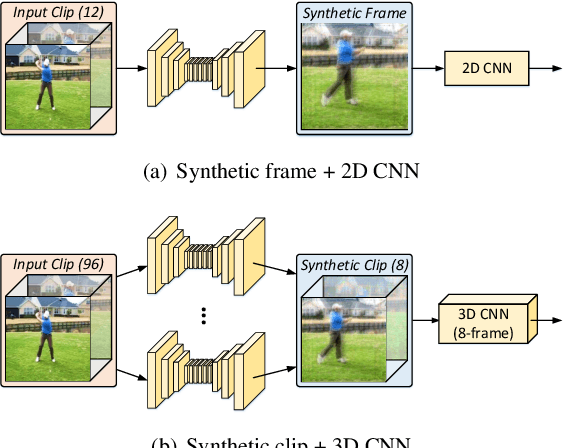
Video is complex due to large variations in motion and rich content in fine-grained visual details. Abstracting useful information from such information-intensive media requires exhaustive computing resources. This paper studies a two-step alternative that first condenses the video sequence to an informative "frame" and then exploits off-the-shelf image recognition system on the synthetic frame. A valid question is how to define "useful information" and then distill it from a video sequence down to one synthetic frame. This paper presents a novel Informative Frame Synthesis (IFS) architecture that incorporates three objective tasks, i.e., appearance reconstruction, video categorization, motion estimation, and two regularizers, i.e., adversarial learning, color consistency. Each task equips the synthetic frame with one ability, while each regularizer enhances its visual quality. With these, by jointly learning the frame synthesis in an end-to-end manner, the generated frame is expected to encapsulate the required spatio-temporal information useful for video analysis. Extensive experiments are conducted on the large-scale Kinetics dataset. When comparing to baseline methods that map video sequence to a single image, IFS shows superior performance. More remarkably, IFS consistently demonstrates evident improvements on image-based 2D networks and clip-based 3D networks, and achieves comparable performance with the state-of-the-art methods with less computational cost.
Tech Report: A Homogeneity-Based Multiscale Hyperspectral Image Representation for Sparse Spectral Unmixing
Feb 11, 2021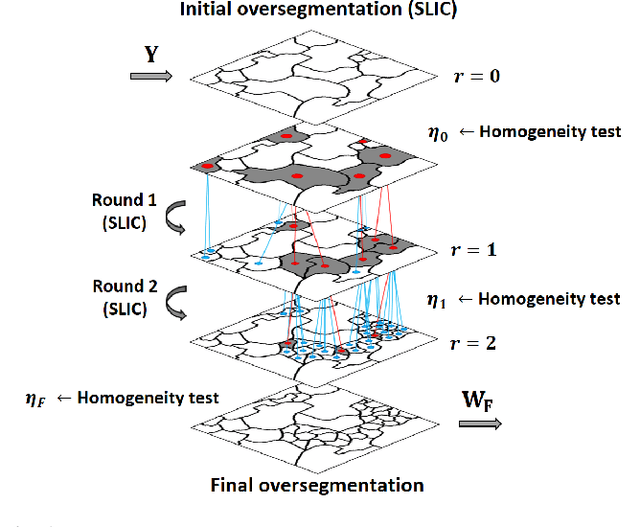
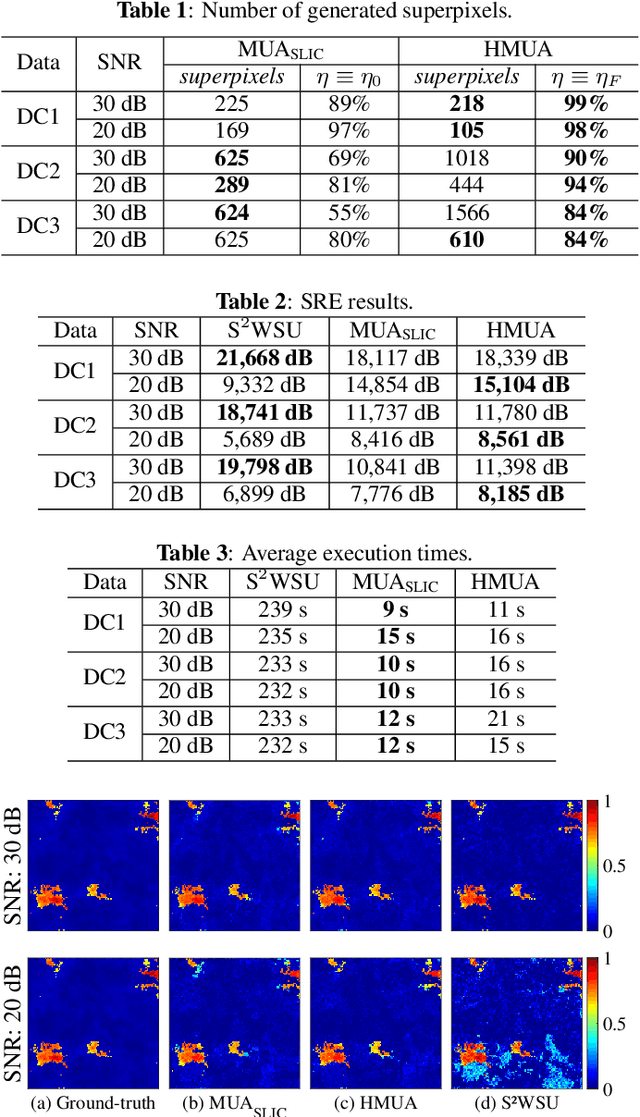

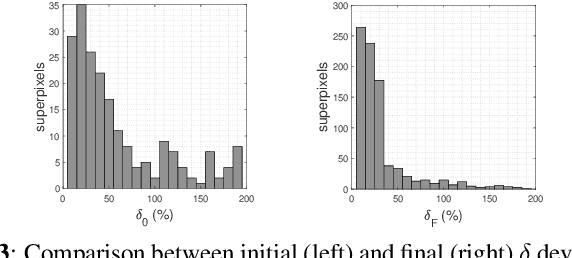
Several approaches have been proposed to solve the spectral unmixing problem in hyperspectral image analysis. Among them the use of sparse regression techniques aims to characterize the abundances in pixels based on a large library of spectral signatures known a priori. Recently, the integration of image spatial-contextual information significantly enhanced the performance of sparse unmixing. In this work, we propose a computationally efficient multiscale representation method for hyperspectral data adapted to the unmixing problem. The proposed method is based on a hierarchical extension of the SLIC oversegmentation algorithm constructed using a robust homogeneity testing. The image is subdivided into a set of spectrally homogeneous regions formed by pixels with similar characteristics (superpixels). This representation is then used to provide prior spatial regularity information for the abundances of materials present in the scene, improving the conditioning of the unmixing problem. Simulation results illustrate that the method is capable of estimating abundances with high quality and low computational cost, especially in noisy scenarios.
Motion Sickness Modeling with Visual Vertical Estimation and Its Application to Autonomous Personal Mobility Vehicles
Feb 20, 2022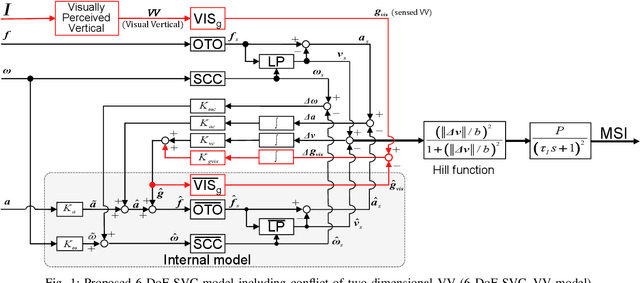


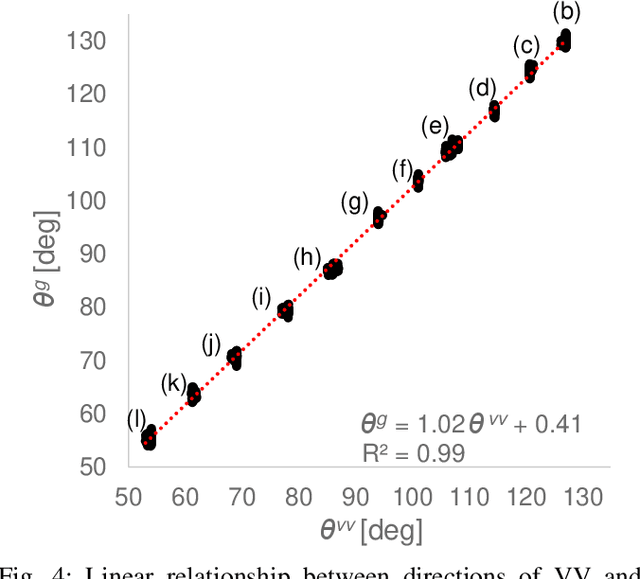
Passengers (drivers) of level 3-5 autonomous personal mobility vehicles (APMV) and cars can perform non-driving tasks, such as reading books and smartphones, while driving. It has been pointed out that such activities may increase motion sickness. Many studies have been conducted to build countermeasures, of which various computational motion sickness models have been developed. Many of these are based on subjective vertical conflict (SVC) theory, which describes vertical changes in direction sensed by human sensory organs vs. those expected by the central nervous system. Such models are expected to be applied to autonomous driving scenarios. However, no current computational model can integrate visual vertical information with vestibular sensations. We proposed a 6 DoF SVC-VV model which add a visually perceived vertical block into a conventional six-degrees-of-freedom SVC model to predict VV directions from image data simulating the visual input of a human. Hence, a simple image-based VV estimation method is proposed. As the validation of the proposed model, this paper focuses on describing the fact that the motion sickness increases as a passenger reads a book while using an AMPV, assuming that visual vertical (VV) plays an important role. In the static experiment, it is demonstrated that the estimated VV by the proposed method accurately described the gravitational acceleration direction with a low mean absolute deviation. In addition, the results of the driving experiment using an APMV demonstrated that the proposed 6 DoF SVC-VV model could describe that the increased motion sickness experienced when the VV and gravitational acceleration directions were different.
MPS-NeRF: Generalizable 3D Human Rendering from Multiview Images
Mar 31, 2022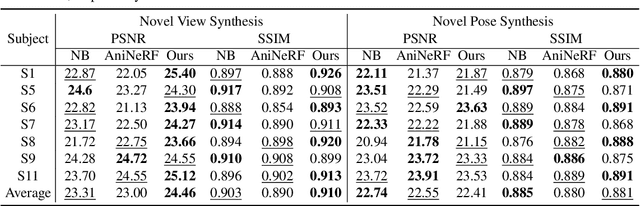
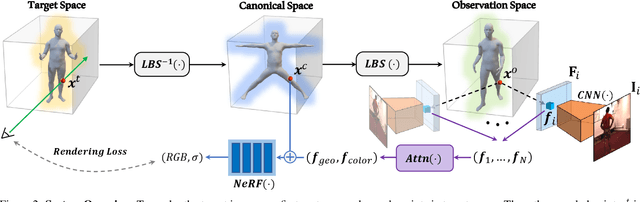
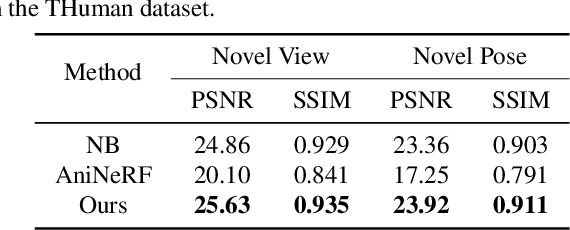

There has been rapid progress recently on 3D human rendering, including novel view synthesis and pose animation, based on the advances of neural radiance fields (NeRF). However, most existing methods focus on person-specific training and their training typically requires multi-view videos. This paper deals with a new challenging task -- rendering novel views and novel poses for a person unseen in training, using only multiview images as input. For this task, we propose a simple yet effective method to train a generalizable NeRF with multiview images as conditional input. The key ingredient is a dedicated representation combining a canonical NeRF and a volume deformation scheme. Using a canonical space enables our method to learn shared properties of human and easily generalize to different people. Volume deformation is used to connect the canonical space with input and target images and query image features for radiance and density prediction. We leverage the parametric 3D human model fitted on the input images to derive the deformation, which works quite well in practice when combined with our canonical NeRF. The experiments on both real and synthetic data with the novel view synthesis and pose animation tasks collectively demonstrate the efficacy of our method.
RePre: Improving Self-Supervised Vision Transformer with Reconstructive Pre-training
Jan 19, 2022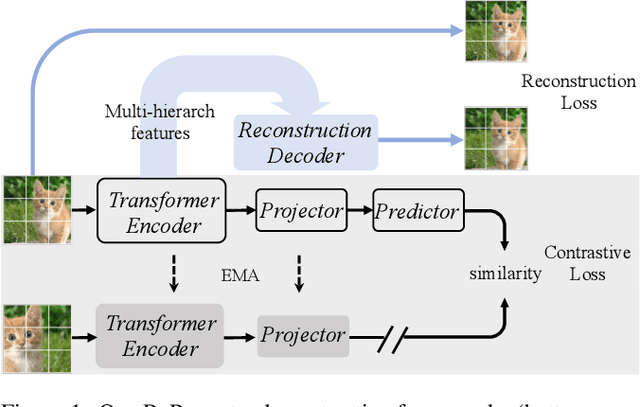
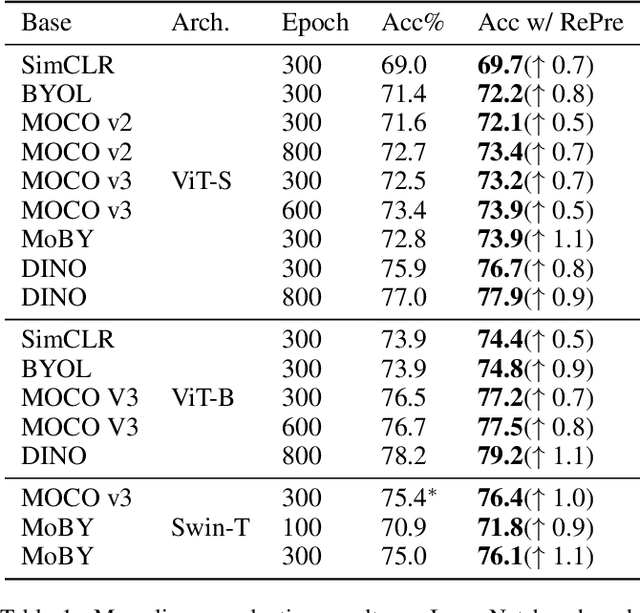
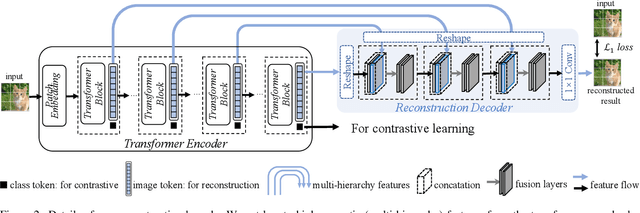
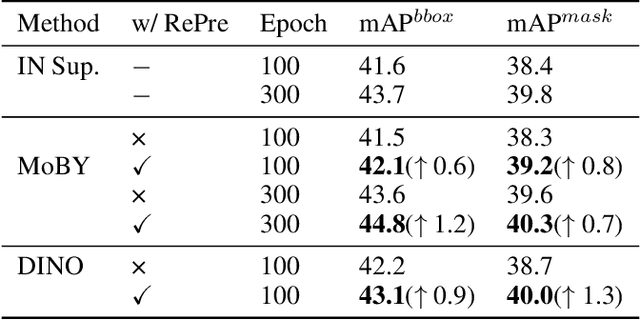
Recently, self-supervised vision transformers have attracted unprecedented attention for their impressive representation learning ability. However, the dominant method, contrastive learning, mainly relies on an instance discrimination pretext task, which learns a global understanding of the image. This paper incorporates local feature learning into self-supervised vision transformers via Reconstructive Pre-training (RePre). Our RePre extends contrastive frameworks by adding a branch for reconstructing raw image pixels in parallel with the existing contrastive objective. RePre is equipped with a lightweight convolution-based decoder that fuses the multi-hierarchy features from the transformer encoder. The multi-hierarchy features provide rich supervisions from low to high semantic information, which are crucial for our RePre. Our RePre brings decent improvements on various contrastive frameworks with different vision transformer architectures. Transfer performance in downstream tasks outperforms supervised pre-training and state-of-the-art (SOTA) self-supervised counterparts.