 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
I2L-MeshNet: Image-to-Lixel Prediction Network for Accurate 3D Human Pose and Mesh Estimation from a Single RGB Image
Aug 09, 2020

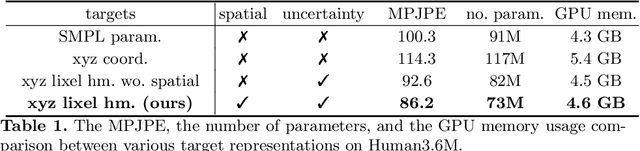
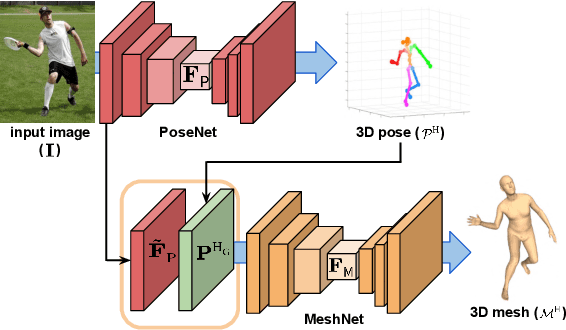
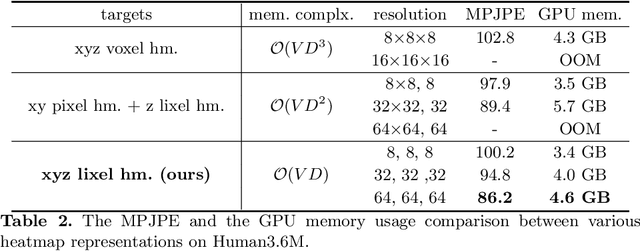
Most of the previous image-based 3D human pose and mesh estimation methods estimate parameters of the human mesh model from an input image. However, directly regressing the parameters from the input image is a highly non-linear mapping because it breaks the spatial relationship between pixels in the input image. In addition, it cannot model the prediction uncertainty, which can make training harder. To resolve the above issues, we propose I2L-MeshNet, an image-to-lixel (line+pixel) prediction network. The proposed I2L-MeshNet predicts the per-lixel likelihood on 1D heatmaps for each mesh vertex coordinate instead of directly regressing the parameters. Our lixel-based 1D heatmap preserves the spatial relationship in the input image and models the prediction uncertainty. We demonstrate the benefit of the image-to-lixel prediction and show that the proposed I2L-MeshNet outperforms previous methods. The code is publicly available \footnote{\url{https://github.com/mks0601/I2L-MeshNet_RELEASE}}.
3D Brain Reconstruction by Hierarchical Shape-Perception Network from a Single Incomplete Image
Jul 23, 2021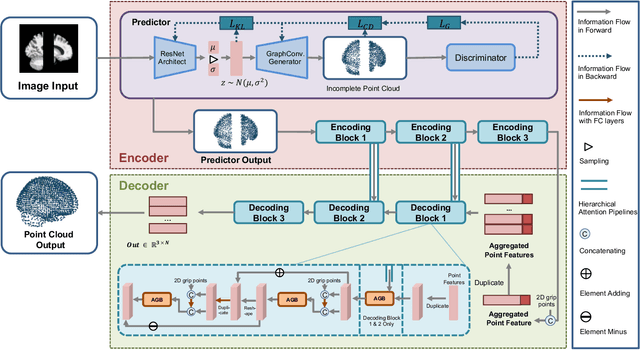
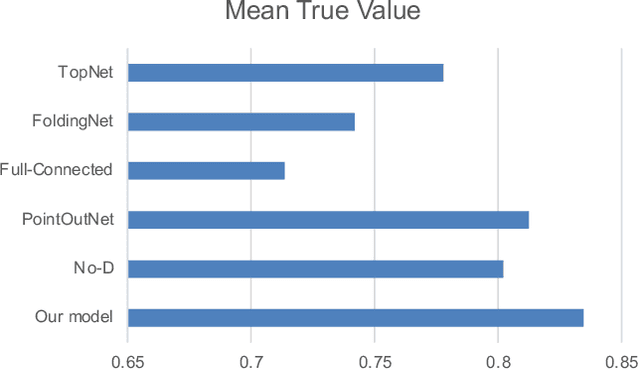
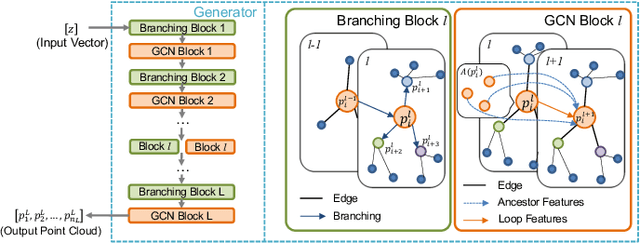
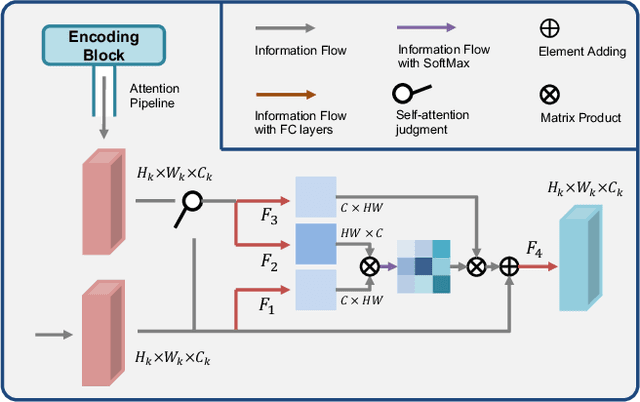
3D shape reconstruction is essential in the navigation of minimally-invasive and auto robot-guided surgeries whose operating environments are indirect and narrow, and there have been some works that focused on reconstructing the 3D shape of the surgical organ through limited 2D information available. However, the lack and incompleteness of such information caused by intraoperative emergencies (such as bleeding) and risk control conditions have not been considered. In this paper, a novel hierarchical shape-perception network (HSPN) is proposed to reconstruct the 3D point clouds (PCs) of specific brains from one single incomplete image with low latency. A tree-structured predictor and several hierarchical attention pipelines are constructed to generate point clouds that accurately describe the incomplete images and then complete these point clouds with high quality. Meanwhile, attention gate blocks (AGBs) are designed to efficiently aggregate geometric local features of incomplete PCs transmitted by hierarchical attention pipelines and internal features of reconstructing point clouds. With the proposed HSPN, 3D shape perception and completion can be achieved spontaneously. Comprehensive results measured by Chamfer distance and PC-to-PC error demonstrate that the performance of the proposed HSPN outperforms other competitive methods in terms of qualitative displays, quantitative experiment, and classification evaluation.
Learning Spatial and Spatio-Temporal Pixel Aggregations for Image and Video Denoising
Jan 26, 2021
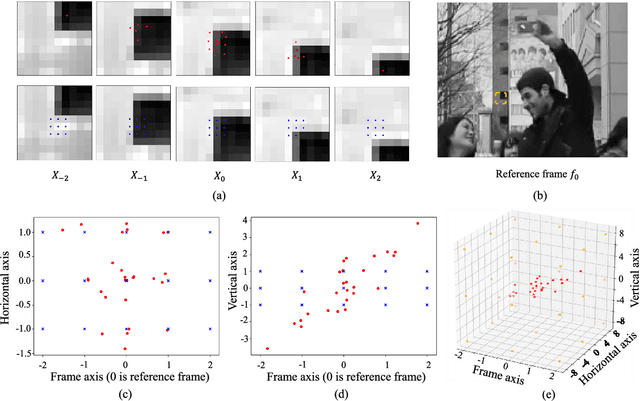
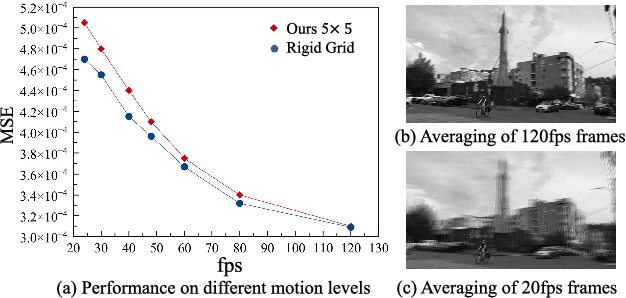
Existing denoising methods typically restore clear results by aggregating pixels from the noisy input. Instead of relying on hand-crafted aggregation schemes, we propose to explicitly learn this process with deep neural networks. We present a spatial pixel aggregation network and learn the pixel sampling and averaging strategies for image denoising. The proposed model naturally adapts to image structures and can effectively improve the denoised results. Furthermore, we develop a spatio-temporal pixel aggregation network for video denoising to efficiently sample pixels across the spatio-temporal space. Our method is able to solve the misalignment issues caused by large motion in dynamic scenes. In addition, we introduce a new regularization term for effectively training the proposed video denoising model. We present extensive analysis of the proposed method and demonstrate that our model performs favorably against the state-of-the-art image and video denoising approaches on both synthetic and real-world data.
* Project page: https://sites.google.com/view/xiangyuxu/denoise_stpan. arXiv admin note: substantial text overlap with arXiv:1904.06903
CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations
Dec 14, 2021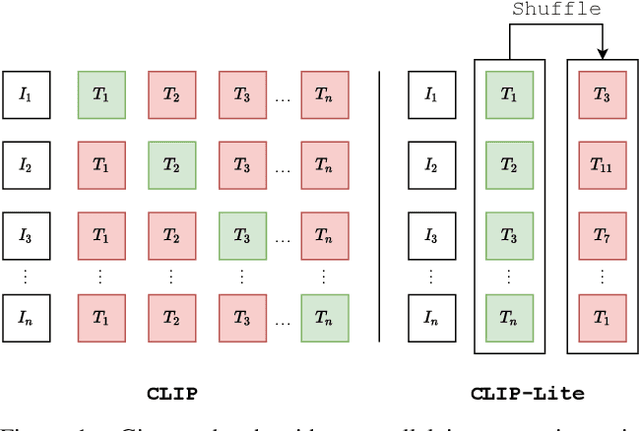
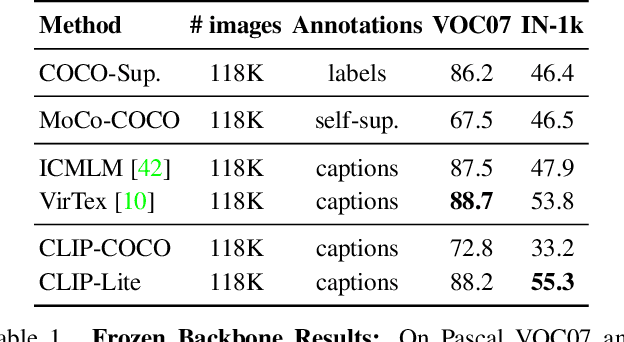
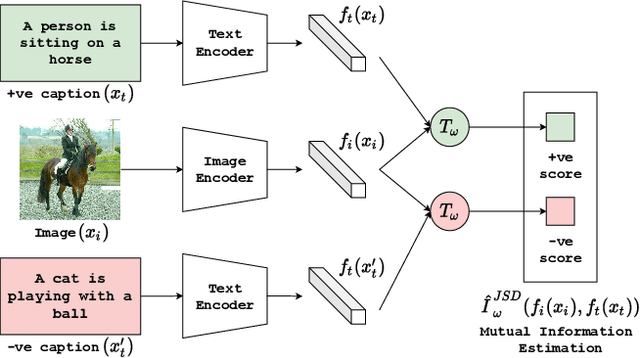
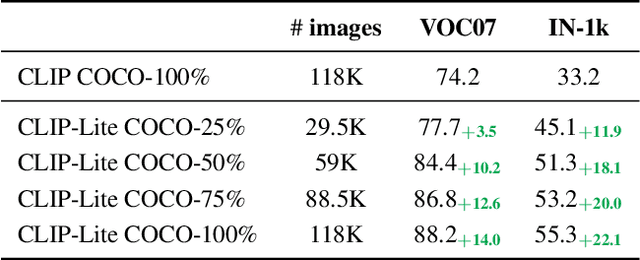
We propose CLIP-Lite, an information efficient method for visual representation learning by feature alignment with textual annotations. Compared to the previously proposed CLIP model, CLIP-Lite requires only one negative image-text sample pair for every positive image-text sample during the optimization of its contrastive learning objective. We accomplish this by taking advantage of an information efficient lower-bound to maximize the mutual information between the two input modalities. This allows CLIP-Lite to be trained with significantly reduced amounts of data and batch sizes while obtaining better performance than CLIP. We evaluate CLIP-Lite by pretraining on the COCO-Captions dataset and testing transfer learning to other datasets. CLIP-Lite obtains a +15.4% mAP absolute gain in performance on Pascal VOC classification, and a +22.1% top-1 accuracy gain on ImageNet, while being comparable or superior to other, more complex, text-supervised models. CLIP-Lite is also superior to CLIP on image and text retrieval, zero-shot classification, and visual grounding. Finally, by performing explicit image-text alignment during representation learning, we show that CLIP-Lite can leverage language semantics to encourage bias-free visual representations that can be used in downstream tasks.
MyStyle: A Personalized Generative Prior
Mar 31, 2022
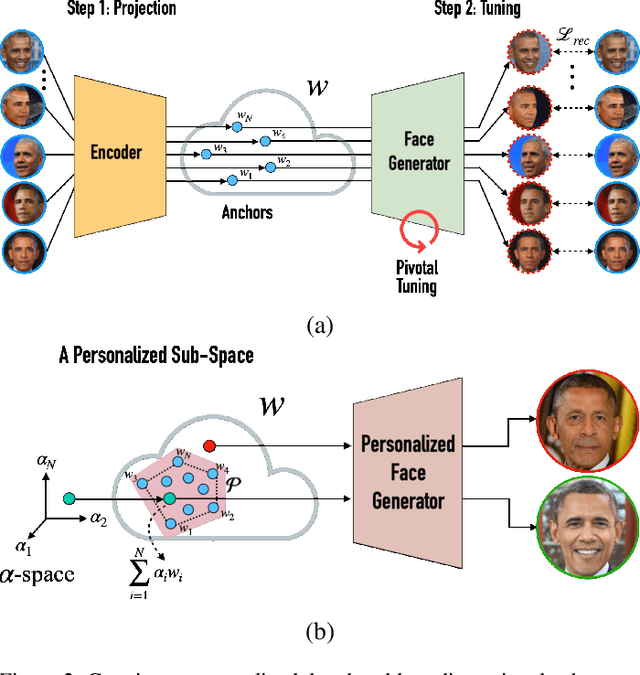
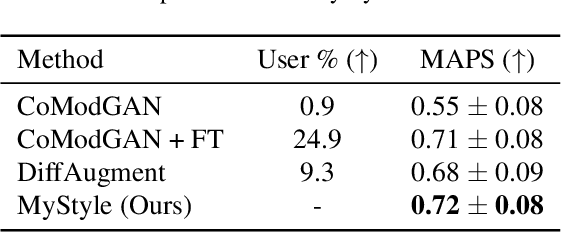

We introduce MyStyle, a personalized deep generative prior trained with a few shots of an individual. MyStyle allows to reconstruct, enhance and edit images of a specific person, such that the output is faithful to the person's key facial characteristics. Given a small reference set of portrait images of a person (~100), we tune the weights of a pretrained StyleGAN face generator to form a local, low-dimensional, personalized manifold in the latent space. We show that this manifold constitutes a personalized region that spans latent codes associated with diverse portrait images of the individual. Moreover, we demonstrate that we obtain a personalized generative prior, and propose a unified approach to apply it to various ill-posed image enhancement problems, such as inpainting and super-resolution, as well as semantic editing. Using the personalized generative prior we obtain outputs that exhibit high-fidelity to the input images and are also faithful to the key facial characteristics of the individual in the reference set. We demonstrate our method with fair-use images of numerous widely recognizable individuals for whom we have the prior knowledge for a qualitative evaluation of the expected outcome. We evaluate our approach against few-shots baselines and show that our personalized prior, quantitatively and qualitatively, outperforms state-of-the-art alternatives.
Rethinking Video Salient Object Ranking
Mar 31, 2022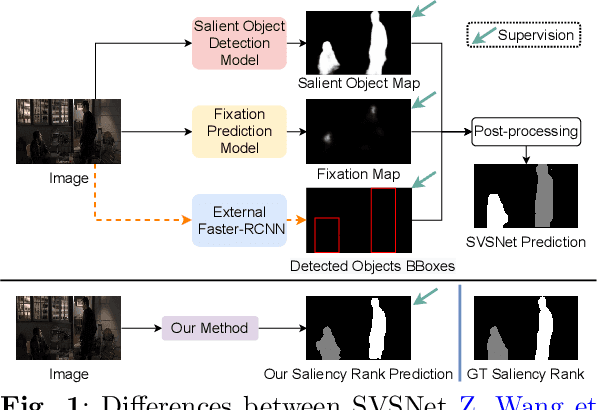


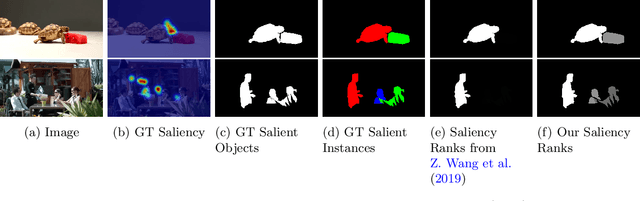
Salient Object Ranking (SOR) involves ranking the degree of saliency of multiple salient objects in an input image. Most recently, a method is proposed for ranking salient objects in an input video based on a predicted fixation map. It relies solely on the density of the fixations within the salient objects to infer their saliency ranks, which is incompatible with human perception of saliency ranking. In this work, we propose to explicitly learn the spatial and temporal relations between different salient objects to produce the saliency ranks. To this end, we propose an end-to-end method for video salient object ranking (VSOR), with two novel modules: an intra-frame adaptive relation (IAR) module to learn the spatial relation among the salient objects in the same frame locally and globally, and an inter-frame dynamic relation (IDR) module to model the temporal relation of saliency across different frames. In addition, to address the limited video types (just sports and movies) and scene diversity in the existing VSOR dataset, we propose a new dataset that covers different video types and diverse scenes on a large scale. Experimental results demonstrate that our method outperforms state-of-the-art methods in relevant fields. We will make the source code and our proposed dataset available.
SimVQA: Exploring Simulated Environments for Visual Question Answering
Mar 31, 2022
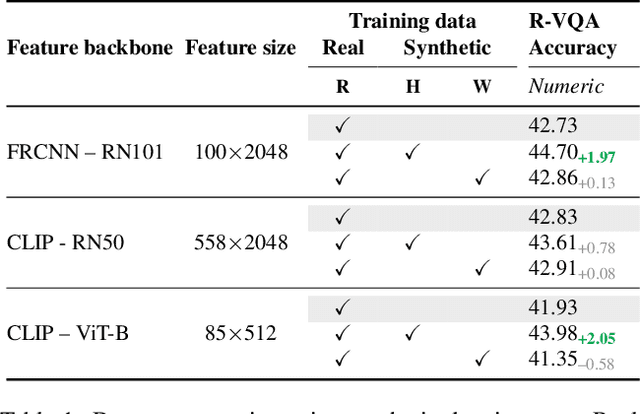
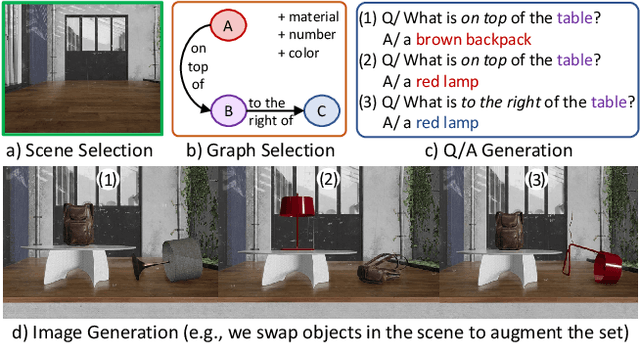
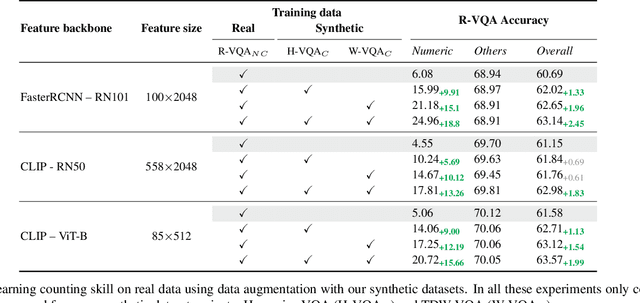
Existing work on VQA explores data augmentation to achieve better generalization by perturbing the images in the dataset or modifying the existing questions and answers. While these methods exhibit good performance, the diversity of the questions and answers are constrained by the available image set. In this work we explore using synthetic computer-generated data to fully control the visual and language space, allowing us to provide more diverse scenarios. We quantify the effect of synthetic data in real-world VQA benchmarks and to which extent it produces results that generalize to real data. By exploiting 3D and physics simulation platforms, we provide a pipeline to generate synthetic data to expand and replace type-specific questions and answers without risking the exposure of sensitive or personal data that might be present in real images. We offer a comprehensive analysis while expanding existing hyper-realistic datasets to be used for VQA. We also propose Feature Swapping (F-SWAP) -- where we randomly switch object-level features during training to make a VQA model more domain invariant. We show that F-SWAP is effective for enhancing a currently existing VQA dataset of real images without compromising on the accuracy to answer existing questions in the dataset.
360° Optical Flow using Tangent Images
Dec 28, 2021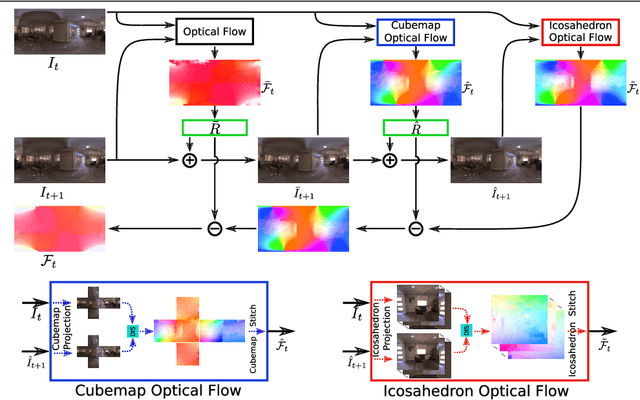
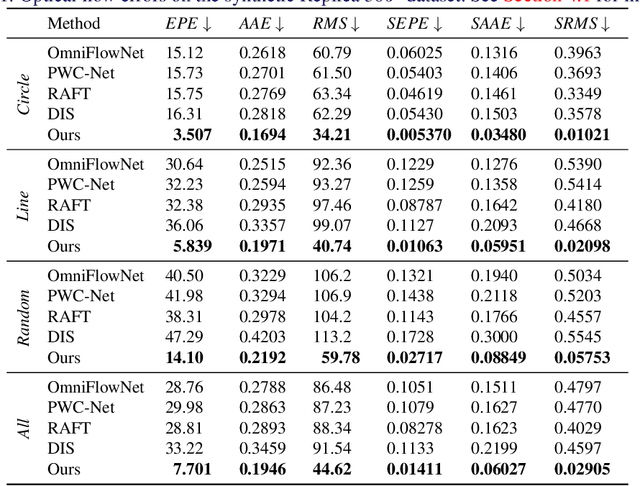

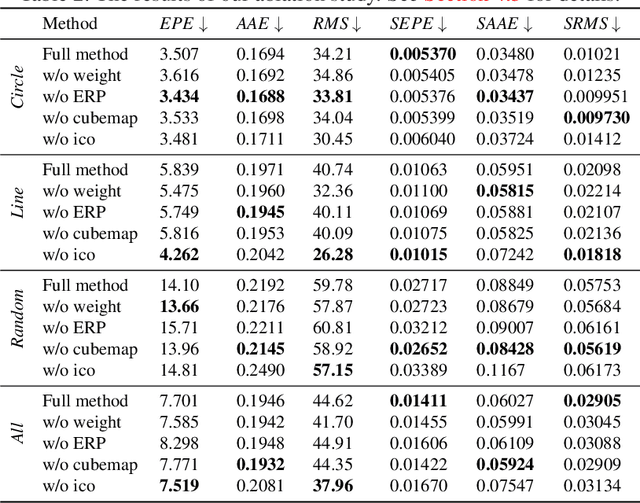
Omnidirectional 360{\deg} images have found many promising and exciting applications in computer vision, robotics and other fields, thanks to their increasing affordability, portability and their 360{\deg} field of view. The most common format for storing, processing and visualising 360{\deg} images is equirectangular projection (ERP). However, the distortion introduced by the nonlinear mapping from 360{\deg} image to ERP image is still a barrier that holds back ERP images from being used as easily as conventional perspective images. This is especially relevant when estimating 360{\deg} optical flow, as the distortions need to be mitigated appropriately. In this paper, we propose a 360{\deg} optical flow method based on tangent images. Our method leverages gnomonic projection to locally convert ERP images to perspective images, and uniformly samples the ERP image by projection to a cubemap and regular icosahedron vertices, to incrementally refine the estimated 360{\deg} flow fields even in the presence of large rotations. Our experiments demonstrate the benefits of our proposed method both quantitatively and qualitatively.
Tech Report: A Homogeneity-Based Multiscale Hyperspectral Image Representation for Sparse Spectral Unmixing
Feb 11, 2021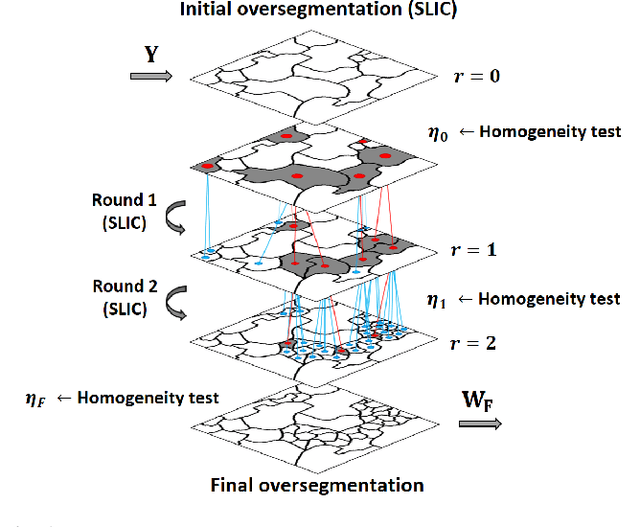
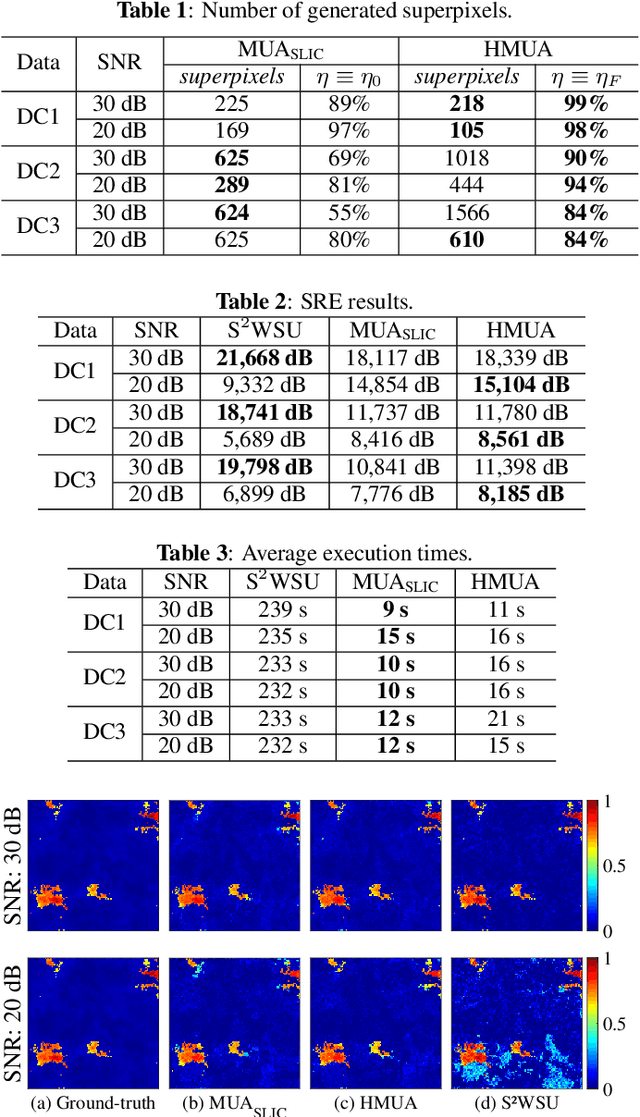

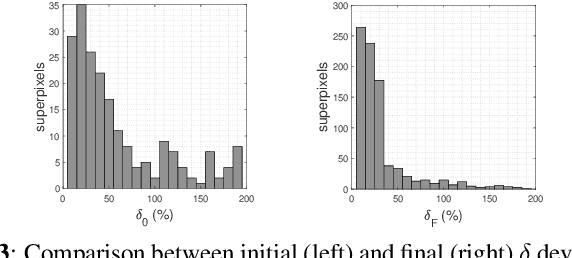
Several approaches have been proposed to solve the spectral unmixing problem in hyperspectral image analysis. Among them the use of sparse regression techniques aims to characterize the abundances in pixels based on a large library of spectral signatures known a priori. Recently, the integration of image spatial-contextual information significantly enhanced the performance of sparse unmixing. In this work, we propose a computationally efficient multiscale representation method for hyperspectral data adapted to the unmixing problem. The proposed method is based on a hierarchical extension of the SLIC oversegmentation algorithm constructed using a robust homogeneity testing. The image is subdivided into a set of spectrally homogeneous regions formed by pixels with similar characteristics (superpixels). This representation is then used to provide prior spatial regularity information for the abundances of materials present in the scene, improving the conditioning of the unmixing problem. Simulation results illustrate that the method is capable of estimating abundances with high quality and low computational cost, especially in noisy scenarios.
Semantic-Sparse Colorization Network for Deep Exemplar-based Colorization
Dec 02, 2021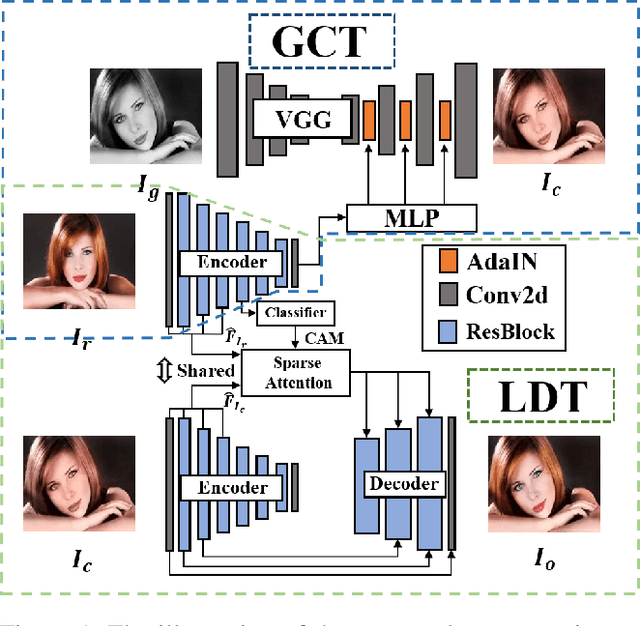
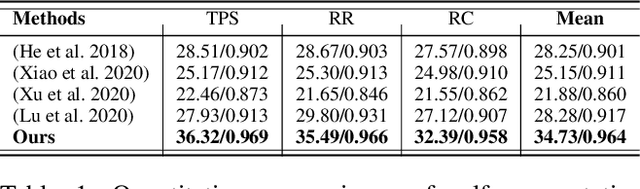
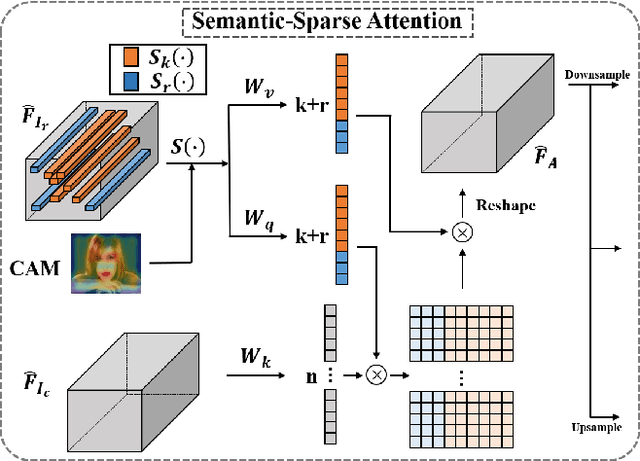
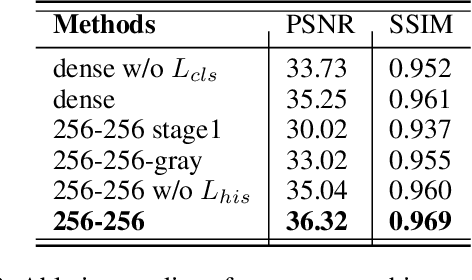
Exemplar-based colorization approaches rely on reference image to provide plausible colors for target gray-scale image. The key and difficulty of exemplar-based colorization is to establish an accurate correspondence between these two images. Previous approaches have attempted to construct such a correspondence but are faced with two obstacles. First, using luminance channels for the calculation of correspondence is inaccurate. Second, the dense correspondence they built introduces wrong matching results and increases the computation burden. To address these two problems, we propose Semantic-Sparse Colorization Network (SSCN) to transfer both the global image style and detailed semantic-related colors to the gray-scale image in a coarse-to-fine manner. Our network can perfectly balance the global and local colors while alleviating the ambiguous matching problem. Experiments show that our method outperforms existing methods in both quantitative and qualitative evaluation and achieves state-of-the-art performance.