 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Super-Resolved Microbubble Localization in Single-Channel Ultrasound RF Signals Using Deep Learning
Apr 09, 2022
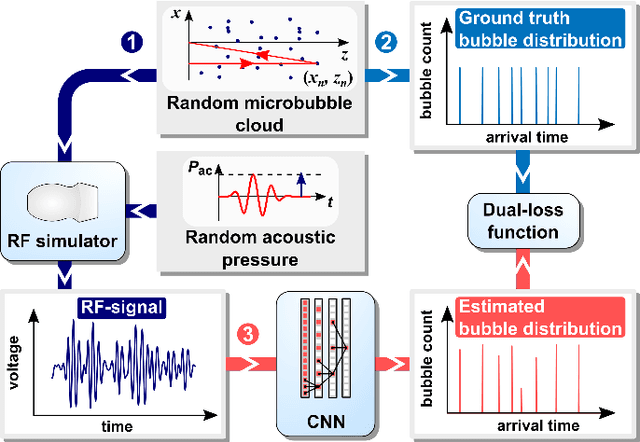
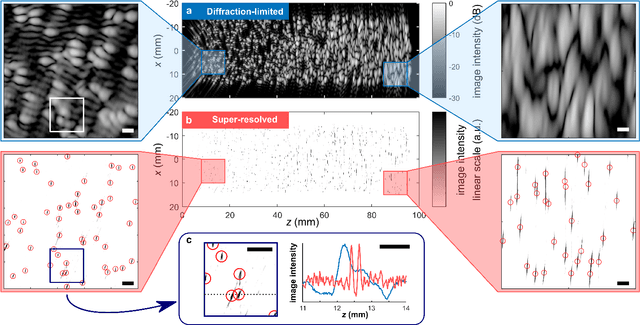
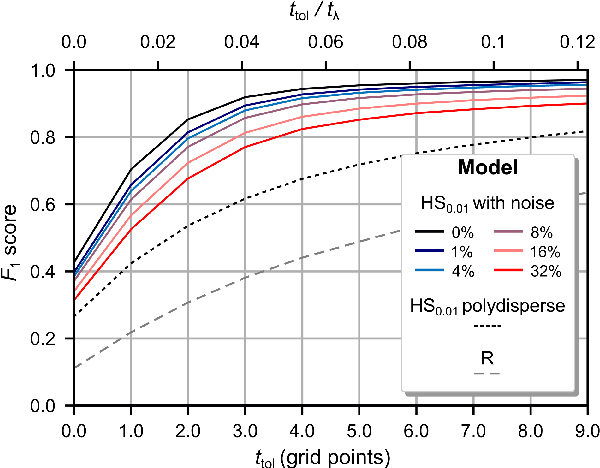
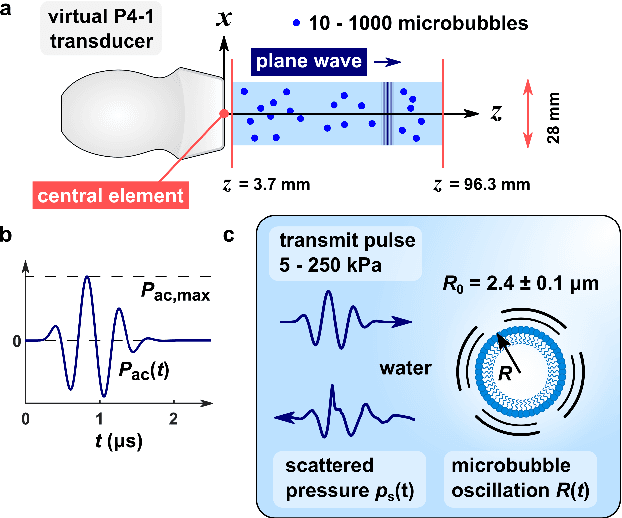
Recently, super-resolution ultrasound imaging with ultrasound localization microscopy (ULM) has received much attention. However, ULM relies on low concentrations of microbubbles in the blood vessels, ultimately resulting in long acquisition times. Here, we present an alternative super-resolution approach, based on direct deconvolution of single-channel ultrasound radio-frequency (RF) signals with a one-dimensional dilated convolutional neural network (CNN). This work focuses on low-frequency ultrasound (1.7 MHz) for deep imaging (10 cm) of a dense cloud of monodisperse microbubbles (up to 1000 microbubbles in the measurement volume, corresponding to an average echo overlap of 94%). Data are generated with a simulator that uses a large range of acoustic pressures (5-250 kPa) and captures the full, nonlinear response of resonant, lipid-coated microbubbles. The network is trained with a novel dual-loss function, which features elements of both a classification loss and a regression loss and improves the detection-localization characteristics of the output. Whereas imposing a localization tolerance of 0 yields poor detection metrics, imposing a localization tolerance corresponding to 4% of the wavelength yields a precision and recall of both 0.90. Furthermore, the detection improves with increasing acoustic pressure and deteriorates with increasing microbubble density. The potential of the presented approach to super-resolution ultrasound imaging is demonstrated with a delay-and-sum reconstruction with deconvolved element data. The resulting image shows an order-of-magnitude gain in axial resolution compared to a delay-and-sum reconstruction with unprocessed element data.
Unsupervised Clustering of Roman Potsherds via Variational Autoencoders
Mar 14, 2022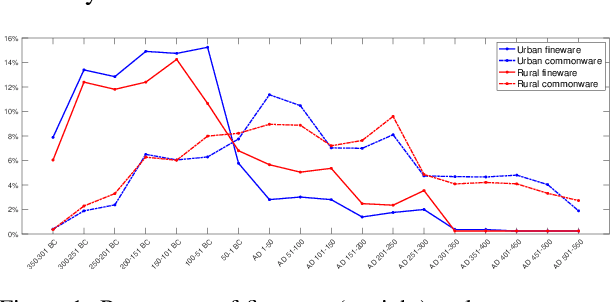
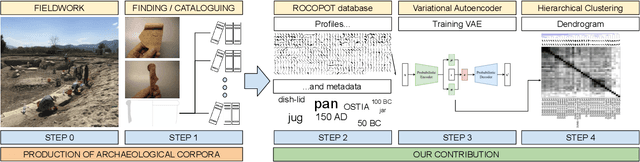
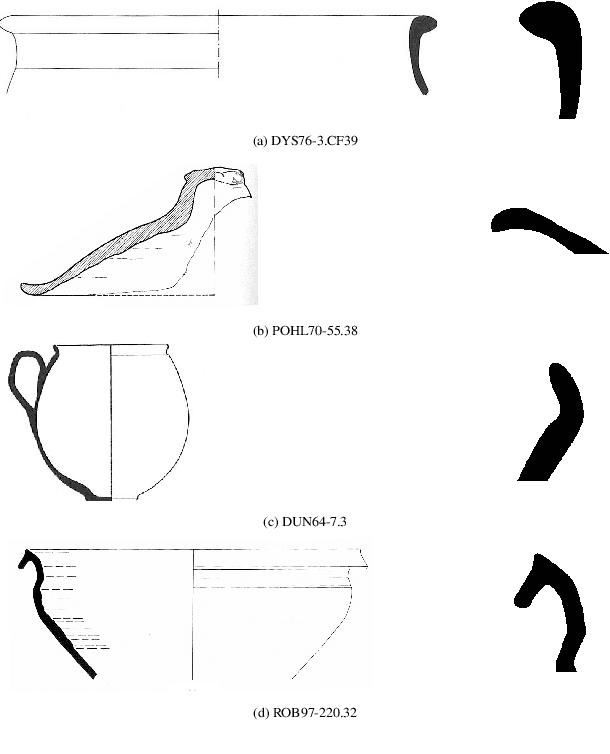
In this paper we propose an artificial intelligence imaging solution to support archaeologists in the classification task of Roman commonware potsherds. Usually, each potsherd is represented by its sectional profile as a two dimensional black-white image and printed in archaeological books related to specific archaeological excavations. The partiality and handcrafted variance of the fragments make their matching a challenging problem: we propose to pair similar profiles via the unsupervised hierarchical clustering of non-linear features learned in the latent space of a deep convolutional Variational Autoencoder (VAE) network. Our contribution also include the creation of a ROman COmmonware POTtery (ROCOPOT) database, with more than 4000 potsherds profiles extracted from 25 Roman pottery corpora, and a MATLAB GUI software for the easy inspection of shape similarities. Results are commented both from a mathematical and archaeological perspective so as to unlock new research directions in both communities.
Catalyzing Clinical Diagnostic Pipelines Through Volumetric Medical Image Segmentation Using Deep Neural Networks: Past, Present, & Future
Mar 27, 2021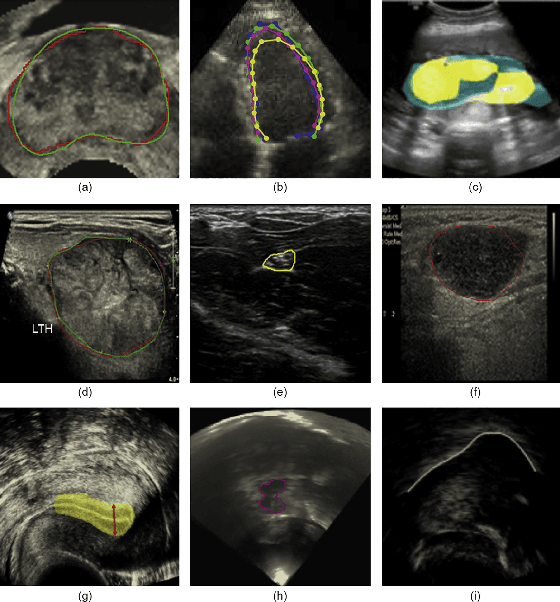
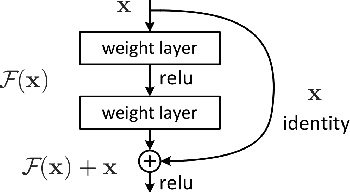
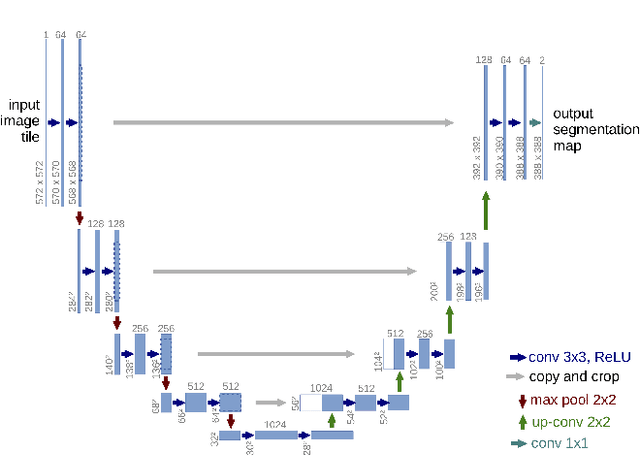
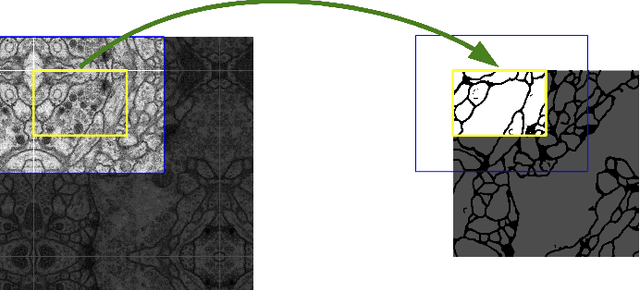
Deep learning has made a remarkable impact in the field of natural image processing over the past decade. Consequently, there is a great deal of interest in replicating this success across unsolved tasks in related domains, such as medical image analysis. Core to medical image analysis is the task of semantic segmentation which enables various clinical workflows. Due to the challenges inherent in manual segmentation, many decades of research have been devoted to discovering extensible, automated, expert-level segmentation techniques. Given the groundbreaking performance demonstrated by recent neural network-based techniques, deep learning seems poised to achieve what classic methods have historically been unable. This paper will briefly overview some of the state-of-the-art (SoTA) neural network-based segmentation algorithms with a particular emphasis on the most recent architectures, comparing and contrasting the contributions and characteristics of each network topology. Using ultrasonography as a motivating example, it will also demonstrate important clinical implications of effective deep learning-based solutions, articulate challenges unique to the modality, and discuss novel approaches developed in response to those challenges, concluding with the proposal of future directions in the field. Given the generally observed ephemerality of the best deep learning approaches (i.e. the extremely quick succession of the SoTA), the main contributions of the paper are its contextualization of modern deep learning architectures with historical background and the elucidation of the current trajectory of volumetric medical image segmentation research.
Data augmentation with mixtures of max-entropy transformations for filling-level classification
Mar 08, 2022

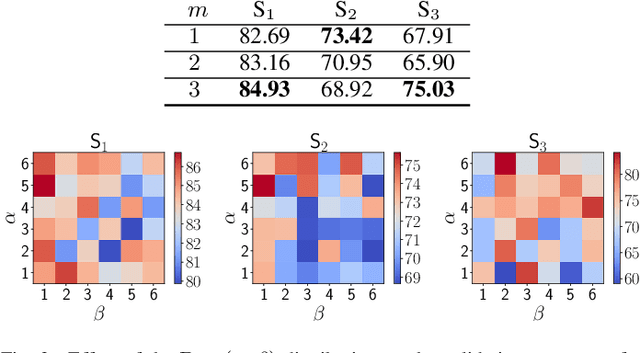
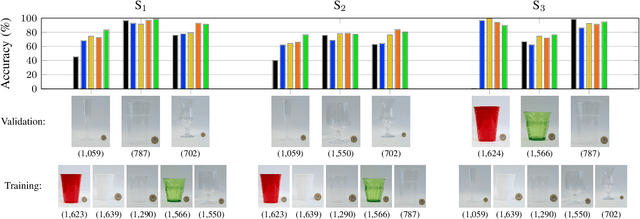
We address the problem of distribution shifts in test-time data with a principled data augmentation scheme for the task of content-level classification. In such a task, properties such as shape or transparency of test-time containers (cup or drinking glass) may differ from those represented in the training data. Dealing with such distribution shifts using standard augmentation schemes is challenging and transforming the training images to cover the properties of the test-time instances requires sophisticated image manipulations. We therefore generate diverse augmentations using a family of max-entropy transformations that create samples with new shapes, colors and spectral characteristics. We show that such a principled augmentation scheme, alone, can replace current approaches that use transfer learning or can be used in combination with transfer learning to improve its performance.
Fine Detailed Texture Learning for 3D Meshes with Generative Models
Mar 17, 2022
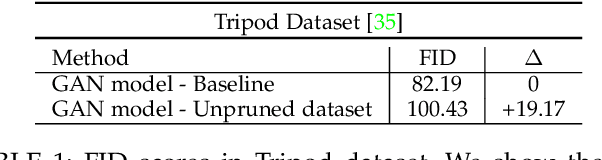
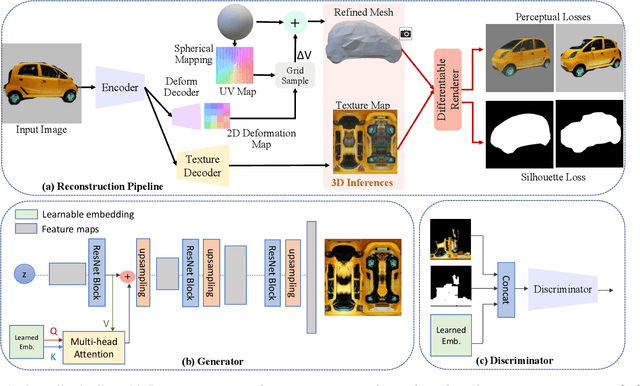

This paper presents a method to reconstruct high-quality textured 3D models from both multi-view and single-view images. The reconstruction is posed as an adaptation problem and is done progressively where in the first stage, we focus on learning accurate geometry, whereas in the second stage, we focus on learning the texture with a generative adversarial network. In the generative learning pipeline, we propose two improvements. First, since the learned textures should be spatially aligned, we propose an attention mechanism that relies on the learnable positions of pixels. Secondly, since discriminator receives aligned texture maps, we augment its input with a learnable embedding which improves the feedback to the generator. We achieve significant improvements on multi-view sequences from Tripod dataset as well as on single-view image datasets, Pascal 3D+ and CUB. We demonstrate that our method achieves superior 3D textured models compared to the previous works. Please visit our web-page for 3D visuals.
Soft-Label Anonymous Gastric X-ray Image Distillation
Apr 07, 2021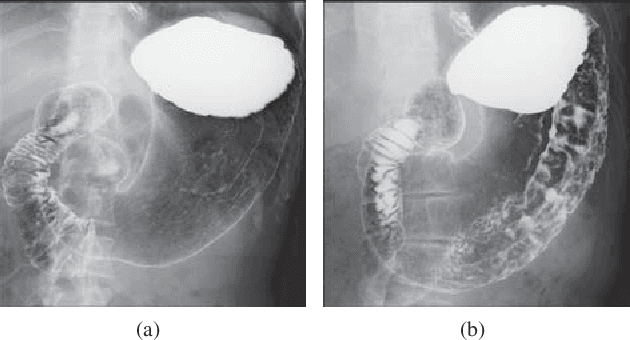
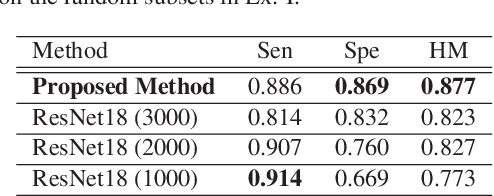
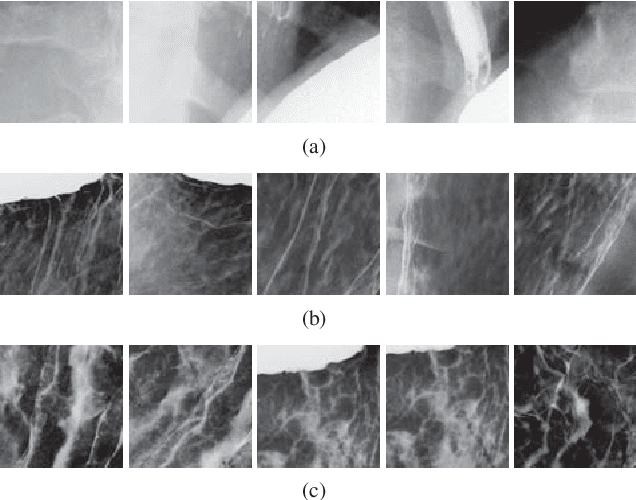
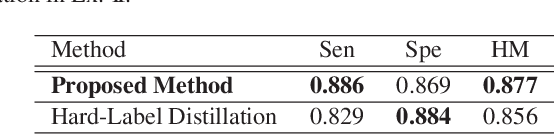
This paper presents a soft-label anonymous gastric X-ray image distillation method based on a gradient descent approach. The sharing of medical data is demanded to construct high-accuracy computer-aided diagnosis (CAD) systems. However, the large size of the medical dataset and privacy protection are remaining problems in medical data sharing, which hindered the research of CAD systems. The idea of our distillation method is to extract the valid information of the medical dataset and generate a tiny distilled dataset that has a different data distribution. Different from model distillation, our method aims to find the optimal distilled images, distilled labels and the optimized learning rate. Experimental results show that the proposed method can not only effectively compress the medical dataset but also anonymize medical images to protect the patient's private information. The proposed approach can improve the efficiency and security of medical data sharing.
On Hamilton-Jacobi PDEs and image denoising models with certain non-additive noise
May 28, 2021
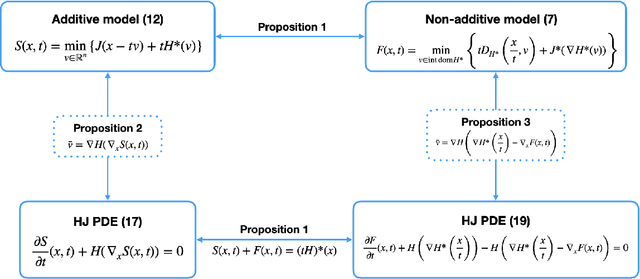


We consider image denoising problems formulated as variational problems. It is known that Hamilton-Jacobi PDEs govern the solution of such optimization problems when the noise model is additive. In this work, we address certain non-additive noise models and show that they are also related to Hamilton-Jacobi PDEs. These findings allow us to establish new connections between additive and non-additive noise imaging models. With these connections, some non-convex models for non-additive noise can be solved by applying convex optimization algorithms to the equivalent convex models for additive noise. Several numerical results are provided for denoising problems with Poisson noise or multiplicative noise.
Unsupervised Domain-Specific Deblurring using Scale-Specific Attention
Dec 12, 2021
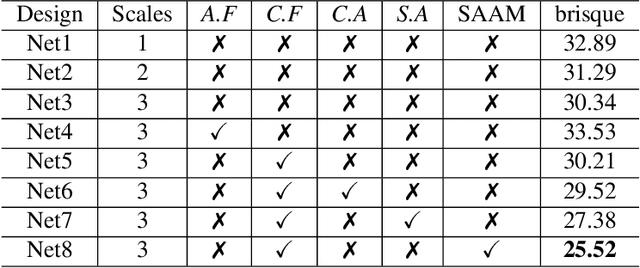
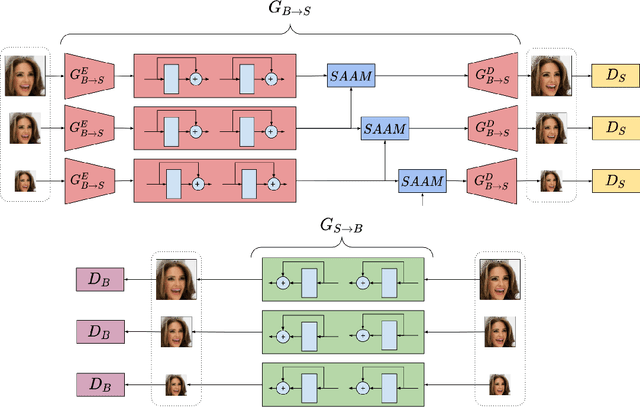
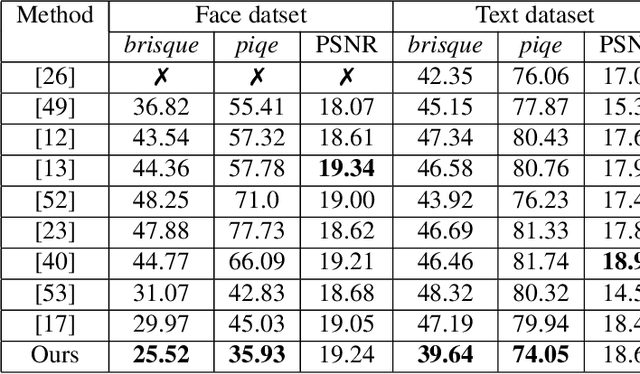
In the literature, coarse-to-fine or scale-recurrent approach i.e. progressively restoring a clean image from its low-resolution versions has been successfully employed for single image deblurring. However, a major disadvantage of existing methods is the need for paired data; i.e. sharpblur image pairs of the same scene, which is a complicated and cumbersome acquisition procedure. Additionally, due to strong supervision on loss functions, pre-trained models of such networks are strongly biased towards the blur experienced during training and tend to give sub-optimal performance when confronted by new blur kernels during inference time. To address the above issues, we propose unsupervised domain-specific deblurring using a scale-adaptive attention module (SAAM). Our network does not require supervised pairs for training, and the deblurring mechanism is primarily guided by adversarial loss, thus making our network suitable for a distribution of blur functions. Given a blurred input image, different resolutions of the same image are used in our model during training and SAAM allows for effective flow of information across the resolutions. For network training at a specific scale, SAAM attends to lower scale features as a function of the current scale. Different ablation studies show that our coarse-to-fine mechanism outperforms end-to-end unsupervised models and SAAM is able to attend better compared to attention models used in literature. Qualitative and quantitative comparisons (on no-reference metrics) show that our method outperforms prior unsupervised methods.
Unifying Remote Sensing Image Retrieval and Classification with Robust Fine-tuning
Feb 26, 2021

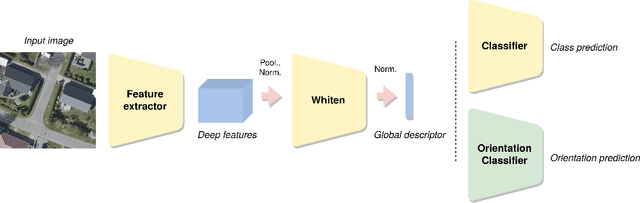
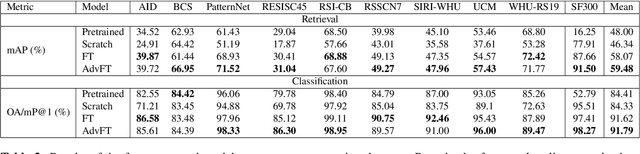
Advances in high resolution remote sensing image analysis are currently hampered by the difficulty of gathering enough annotated data for training deep learning methods, giving rise to a variety of small datasets and associated dataset-specific methods. Moreover, typical tasks such as classification and retrieval lack a systematic evaluation on standard benchmarks and training datasets, which make it hard to identify durable and generalizable scientific contributions. We aim at unifying remote sensing image retrieval and classification with a new large-scale training and testing dataset, SF300, including both vertical and oblique aerial images and made available to the research community, and an associated fine-tuning method. We additionally propose a new adversarial fine-tuning method for global descriptors. We show that our framework systematically achieves a boost of retrieval and classification performance on nine different datasets compared to an ImageNet pretrained baseline, with currently no other method to compare to.
Memory-Efficient Hierarchical Neural Architecture Search for Image Restoration
Dec 28, 2020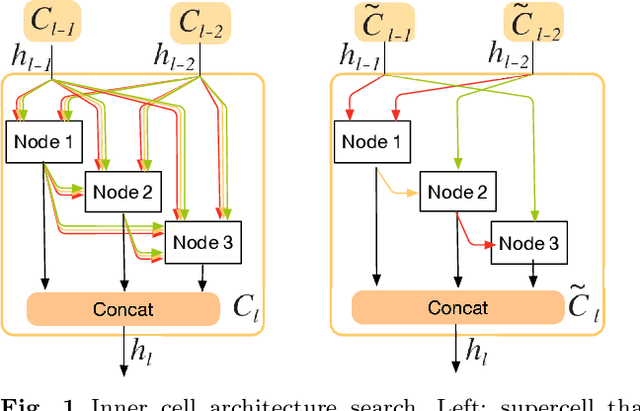

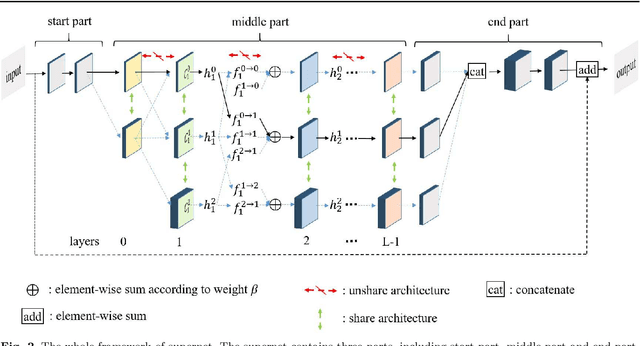

Recently, much attention has been spent on neural architecture search (NAS) approaches, which often outperform manually designed architectures on highlevel vision tasks. Inspired by this, we attempt to leverage NAS technique to automatically design efficient network architectures for low-level image restoration tasks. In this paper, we propose a memory-efficient hierarchical NAS HiNAS (HiNAS) and apply to two such tasks: image denoising and image super-resolution. HiNAS adopts gradient based search strategies and builds an flexible hierarchical search space, including inner search space and outer search space, which in charge of designing cell architectures and deciding cell widths, respectively. For inner search space, we propose layerwise architecture sharing strategy (LWAS), resulting in more flexible architectures and better performance. For outer search space, we propose cell sharing strategy to save memory, and considerably accelerate the search speed. The proposed HiNAS is both memory and computation efficient. With a single GTX1080Ti GPU, it takes only about 1 hour for searching for denoising network on BSD 500 and 3.5 hours for searching for the super-resolution structure on DIV2K. Experimental results show that the architectures found by HiNAS have fewer parameters and enjoy a faster inference speed, while achieving highly competitive performance compared with state-of-the-art methods.