 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Training Compact CNNs for Image Classification using Dynamic-coded Filter Fusion
Jul 14, 2021
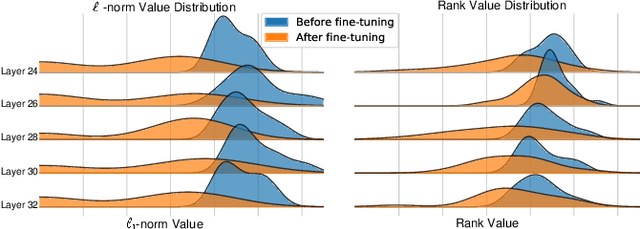
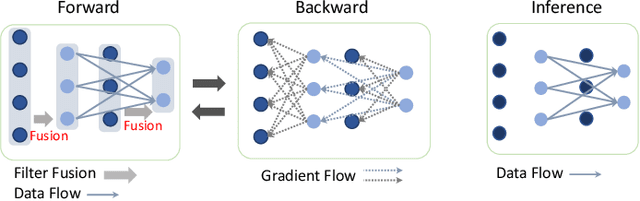
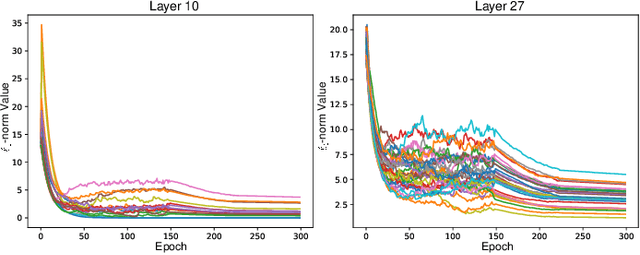

The mainstream approach for filter pruning is usually either to force a hard-coded importance estimation upon a computation-heavy pretrained model to select "important" filters, or to impose a hyperparameter-sensitive sparse constraint on the loss objective to regularize the network training. In this paper, we present a novel filter pruning method, dubbed dynamic-coded filter fusion (DCFF), to derive compact CNNs in a computation-economical and regularization-free manner for efficient image classification. Each filter in our DCFF is firstly given an inter-similarity distribution with a temperature parameter as a filter proxy, on top of which, a fresh Kullback-Leibler divergence based dynamic-coded criterion is proposed to evaluate the filter importance. In contrast to simply keeping high-score filters in other methods, we propose the concept of filter fusion, i.e., the weighted averages using the assigned proxies, as our preserved filters. We obtain a one-hot inter-similarity distribution as the temperature parameter approaches infinity. Thus, the relative importance of each filter can vary along with the training of the compact CNN, leading to dynamically changeable fused filters without both the dependency on the pretrained model and the introduction of sparse constraints. Extensive experiments on classification benchmarks demonstrate the superiority of our DCFF over the compared counterparts. For example, our DCFF derives a compact VGGNet-16 with only 72.77M FLOPs and 1.06M parameters while reaching top-1 accuracy of 93.47% on CIFAR-10. A compact ResNet-50 is obtained with 63.8% FLOPs and 58.6% parameter reductions, retaining 75.60% top-1 accuracy on ILSVRC-2012. Our code, narrower models and training logs are available at https://github.com/lmbxmu/DCFF.
On the Calibration of Pre-trained Language Models using Mixup Guided by Area Under the Margin and Saliency
Mar 14, 2022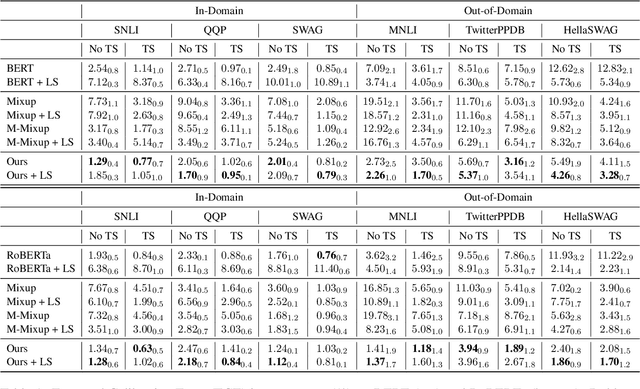
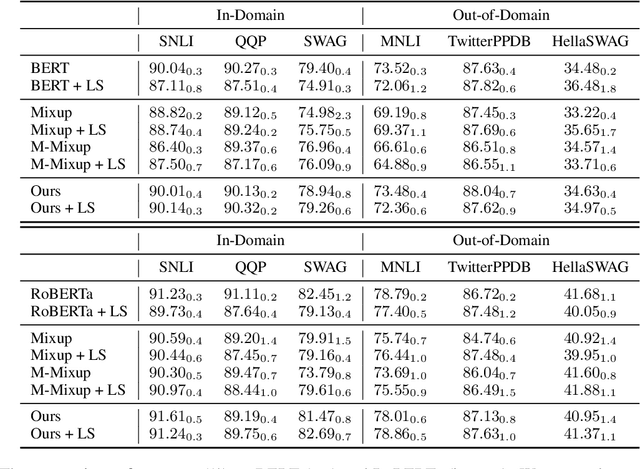
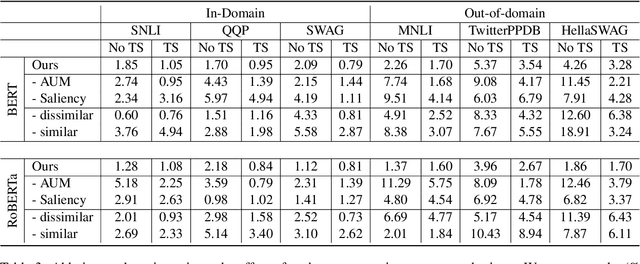
A well-calibrated neural model produces confidence (probability outputs) closely approximated by the expected accuracy. While prior studies have shown that mixup training as a data augmentation technique can improve model calibration on image classification tasks, little is known about using mixup for model calibration on natural language understanding (NLU) tasks. In this paper, we explore mixup for model calibration on several NLU tasks and propose a novel mixup strategy for pre-trained language models that improves model calibration further. Our proposed mixup is guided by both the Area Under the Margin (AUM) statistic (Pleiss et al., 2020) and the saliency map of each sample (Simonyan et al.,2013). Moreover, we combine our mixup strategy with model miscalibration correction techniques (i.e., label smoothing and temperature scaling) and provide detailed analyses of their impact on our proposed mixup. We focus on systematically designing experiments on three NLU tasks: natural language inference, paraphrase detection, and commonsense reasoning. Our method achieves the lowest expected calibration error compared to strong baselines on both in-domain and out-of-domain test samples while maintaining competitive accuracy.
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
Apr 01, 2022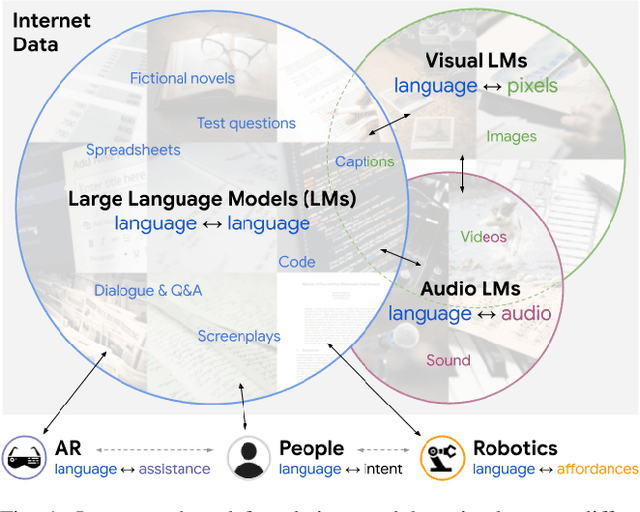
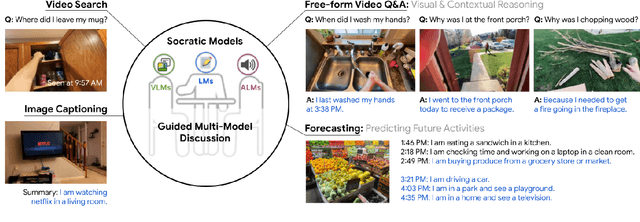
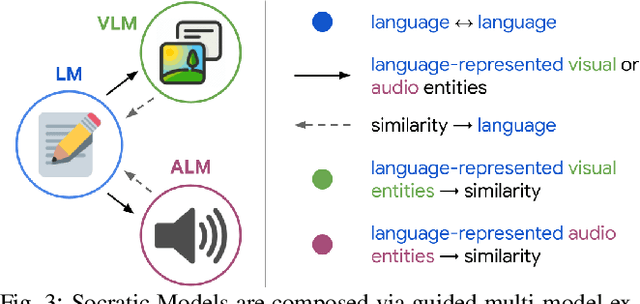
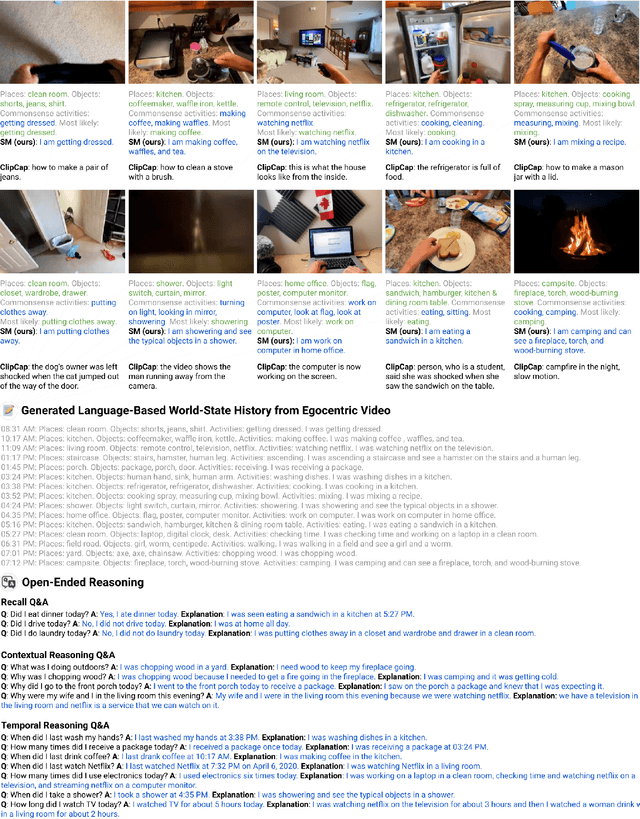
Large foundation models can exhibit unique capabilities depending on the domain of data they are trained on. While these domains are generic, they may only barely overlap. For example, visual-language models (VLMs) are trained on Internet-scale image captions, but large language models (LMs) are further trained on Internet-scale text with no images (e.g. from spreadsheets, to SAT questions). As a result, these models store different forms of commonsense knowledge across different domains. In this work, we show that this model diversity is symbiotic, and can be leveraged to build AI systems with structured Socratic dialogue -- in which new multimodal tasks are formulated as a guided language-based exchange between different pre-existing foundation models, without additional finetuning. In the context of egocentric perception, we present a case study of Socratic Models (SMs) that can provide meaningful results for complex tasks such as generating free-form answers to contextual questions about egocentric video, by formulating video Q&A as short story Q&A, i.e. summarizing the video into a short story, then answering questions about it. Additionally, SMs can generate captions for Internet images, and are competitive with state-of-the-art on zero-shot video-to-text retrieval with 42.8 R@1 on MSR-VTT 1k-A. SMs demonstrate how to compose foundation models zero-shot to capture new multimodal functionalities, without domain-specific data collection. Prototypes are available at socraticmodels.github.io.
OVE6D: Object Viewpoint Encoding for Depth-based 6D Object Pose Estimation
Mar 06, 2022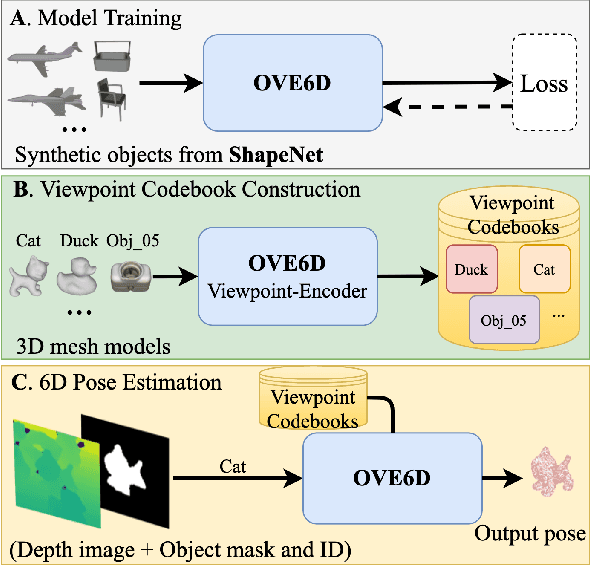
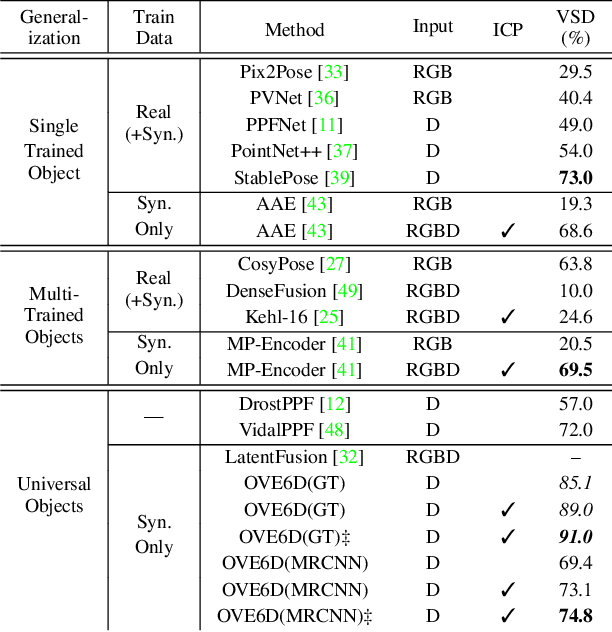
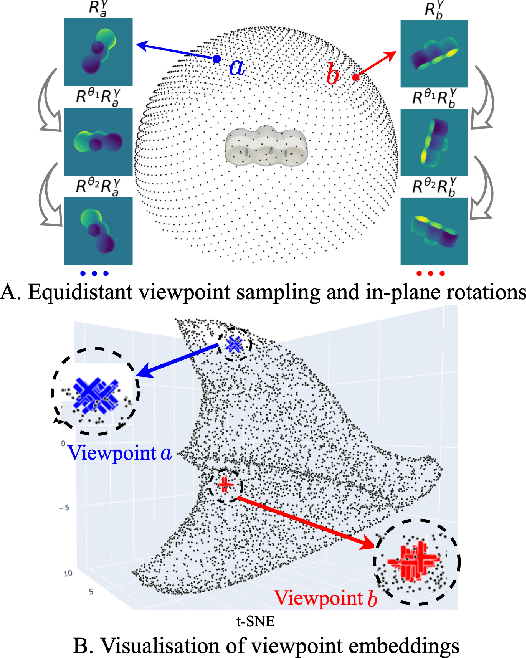
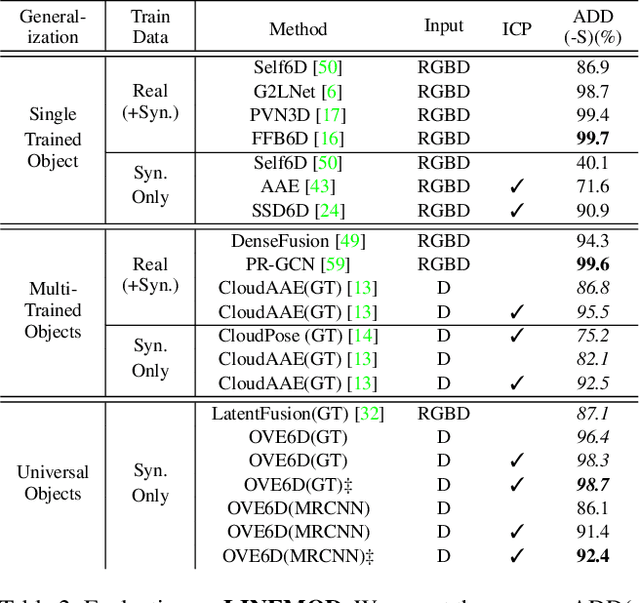
This paper proposes a universal framework, called OVE6D, for model-based 6D object pose estimation from a single depth image and a target object mask. Our model is trained using purely synthetic data rendered from ShapeNet, and, unlike most of the existing methods, it generalizes well on new real-world objects without any fine-tuning. We achieve this by decomposing the 6D pose into viewpoint, in-plane rotation around the camera optical axis and translation, and introducing novel lightweight modules for estimating each component in a cascaded manner. The resulting network contains less than 4M parameters while demonstrating excellent performance on the challenging T-LESS and Occluded LINEMOD datasets without any dataset-specific training. We show that OVE6D outperforms some contemporary deep learning-based pose estimation methods specifically trained for individual objects or datasets with real-world training data. The implementation and the pre-trained model will be made publicly available.
Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework
Mar 24, 2022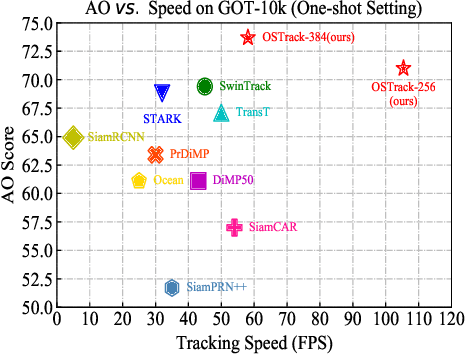
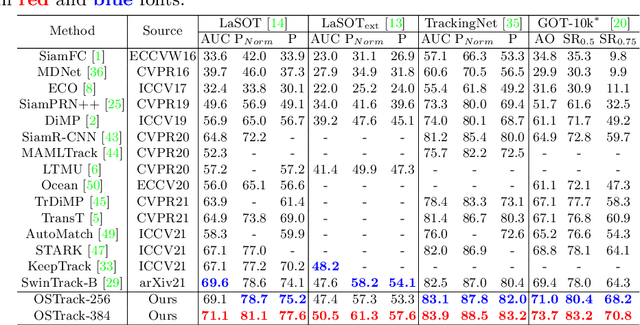
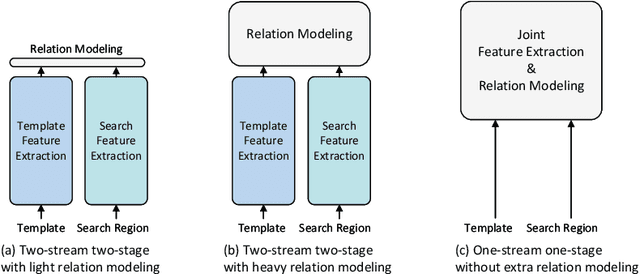

The current popular two-stream, two-stage tracking framework extracts the template and the search region features separately and then performs relation modeling, thus the extracted features lack the awareness of the target and have limited target-background discriminability. To tackle the above issue, we propose a novel one-stream tracking (OSTrack) framework that unifies feature learning and relation modeling by bridging the template-search image pairs with bidirectional information flows. In this way, discriminative target-oriented features can be dynamically extracted by mutual guidance. Since no extra heavy relation modeling module is needed and the implementation is highly parallelized, the proposed tracker runs at a fast speed. To further improve the inference efficiency, an in-network candidate early elimination module is proposed based on the strong similarity prior calculated in the one-stream framework. As a unified framework, OSTrack achieves state-of-the-art performance on multiple benchmarks, in particular, it shows impressive results on the one-shot tracking benchmark GOT-10k, i.e., achieving 73.7% AO, improving the existing best result (SwinTrack) by 4.3%. Besides, our method maintains a good performance-speed trade-off and shows faster convergence. The code and models will be available at https://github.com/botaoye/OSTrack.
DDR-Net: Dividing and Downsampling Mixed Network for Diffeomorphic Image Registration
May 24, 2021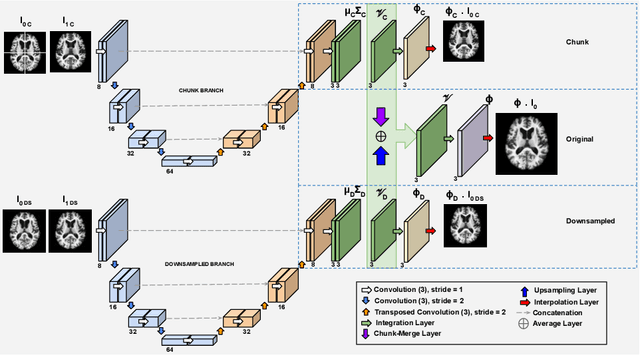
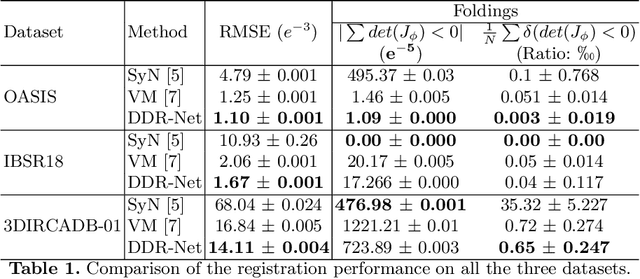
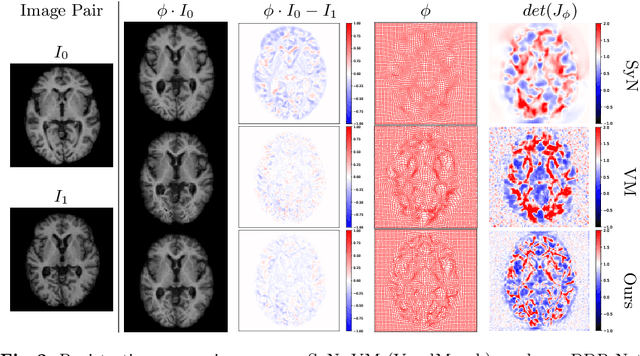
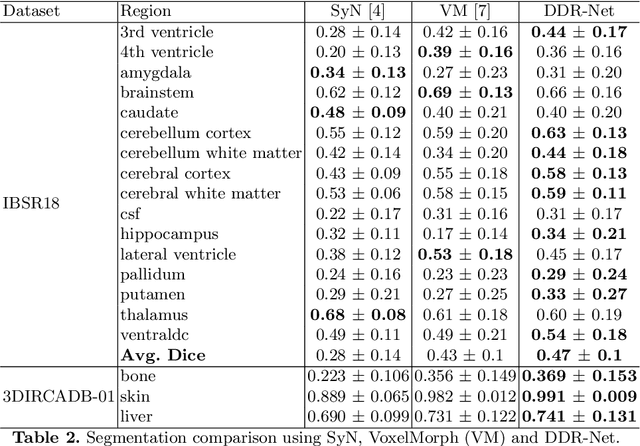
Deep diffeomorphic registration faces significant challenges for high-dimensional images, especially in terms of memory limits. Existing approaches either downsample original images, or approximate underlying transformations, or reduce model size. The information loss during the approximation or insufficient model capacity is a hindrance to the registration accuracy for high-dimensional images, e.g., 3D medical volumes. In this paper, we propose a Dividing and Downsampling mixed Registration network (DDR-Net), a general architecture that preserves most of the image information at multiple scales. DDR-Net leverages the global context via downsampling the input and utilizes the local details from divided chunks of the input images. This design reduces the network input size and its memory cost; meanwhile, by fusing global and local information, DDR-Net obtains both coarse-level and fine-level alignments in the final deformation fields. We evaluate DDR-Net on three public datasets, i.e., OASIS, IBSR18, and 3DIRCADB-01, and the experimental results demonstrate our approach outperforms existing approaches.
Towards Exemplar-Free Continual Learning in Vision Transformers: an Account of Attention, Functional and Weight Regularization
Mar 28, 2022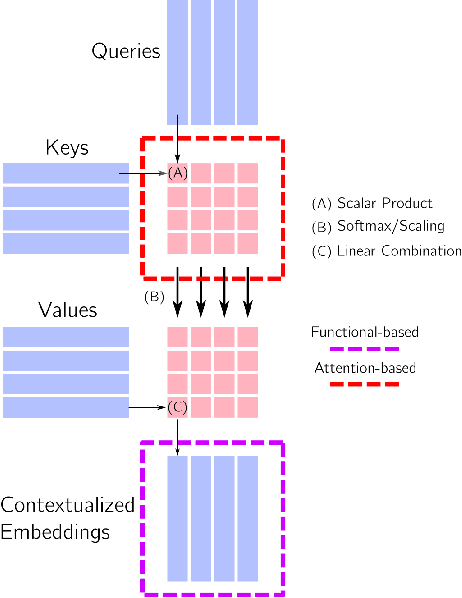
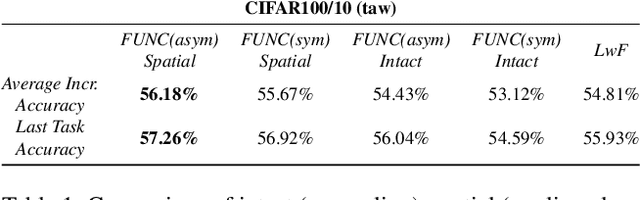
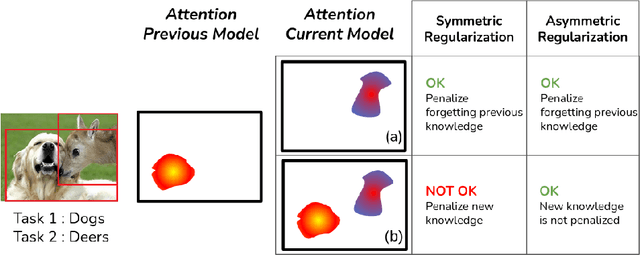
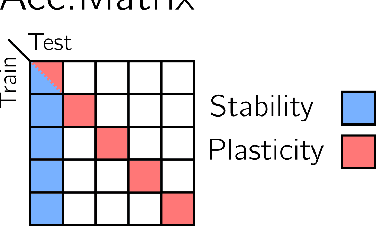
In this paper, we investigate the continual learning of Vision Transformers (ViT) for the challenging exemplar-free scenario, with special focus on how to efficiently distill the knowledge of its crucial self-attention mechanism (SAM). Our work takes an initial step towards a surgical investigation of SAM for designing coherent continual learning methods in ViTs. We first carry out an evaluation of established continual learning regularization techniques. We then examine the effect of regularization when applied to two key enablers of SAM: (a) the contextualized embedding layers, for their ability to capture well-scaled representations with respect to the values, and (b) the prescaled attention maps, for carrying value-independent global contextual information. We depict the perks of each distilling strategy on two image recognition benchmarks (CIFAR100 and ImageNet-32) -- while (a) leads to a better overall accuracy, (b) helps enhance the rigidity by maintaining competitive performances. Furthermore, we identify the limitation imposed by the symmetric nature of regularization losses. To alleviate this, we propose an asymmetric variant and apply it to the pooled output distillation (POD) loss adapted for ViTs. Our experiments confirm that introducing asymmetry to POD boosts its plasticity while retaining stability across (a) and (b). Moreover, we acknowledge low forgetting measures for all the compared methods, indicating that ViTs might be naturally inclined continual learner
An Efficient Technique for Image Captioning using Deep Neural Network
Sep 05, 2020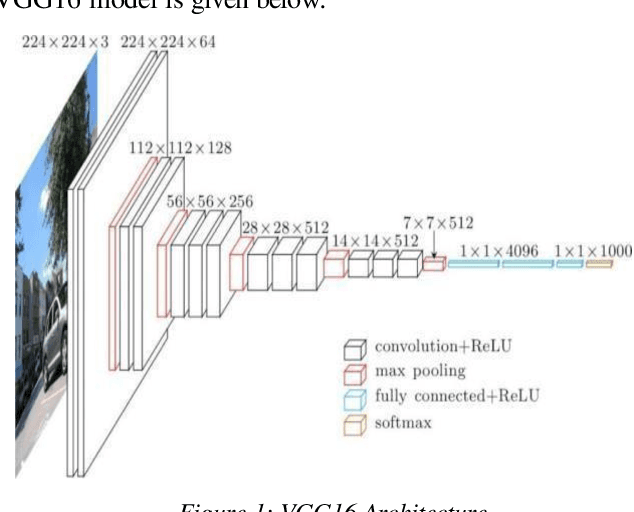
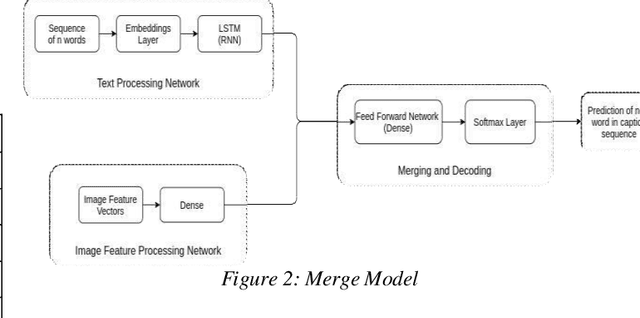
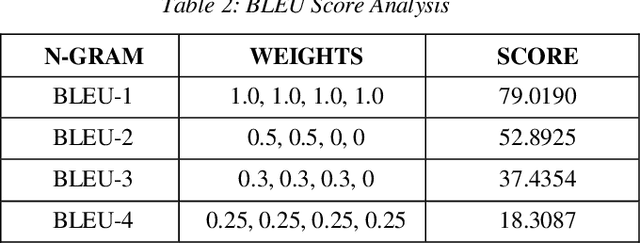
With the huge expansion of internet and trillions of gigabytes of data generated every single day, the needs for the development of various tools has become mandatory in order to maintain system adaptability to rapid changes. One of these tools is known as Image Captioning. Every entity in internet must be properly identified and managed and therefore in the case of image data, automatic captioning for identification is required. Similarly, content generation for missing labels, image classification and artificial languages all requires the process of Image Captioning. This paper discusses an efficient and unique way to perform automatic image captioning on individual image and discusses strategies to improve its performances and functionalities.
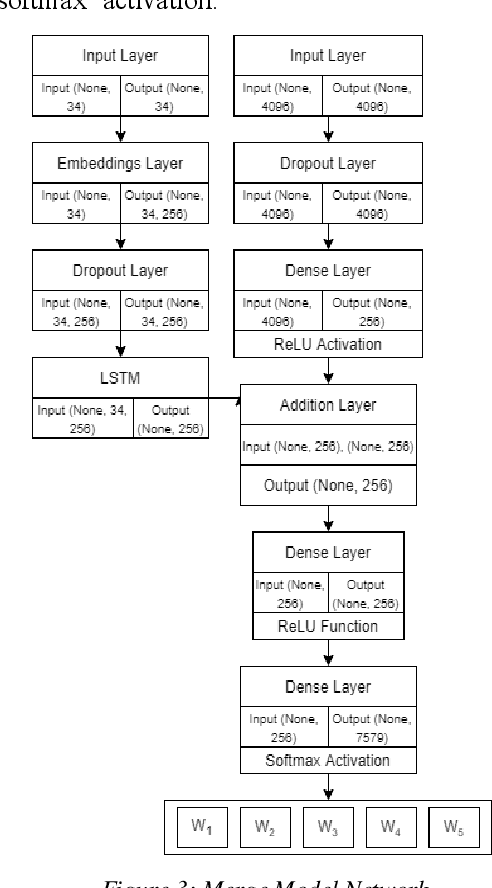
An End-to-End Breast Tumour Classification Model Using Context-Based Patch Modelling- A BiLSTM Approach for Image Classification
Jun 05, 2021
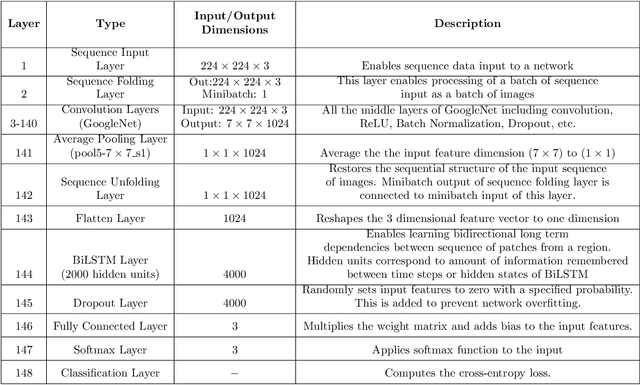
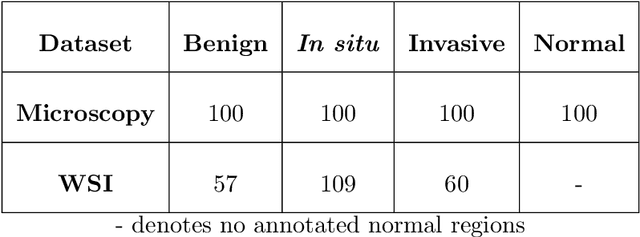
Researchers working on computational analysis of Whole Slide Images (WSIs) in histopathology have primarily resorted to patch-based modelling due to large resolution of each WSI. The large resolution makes WSIs infeasible to be fed directly into the machine learning models due to computational constraints. However, due to patch-based analysis, most of the current methods fail to exploit the underlying spatial relationship among the patches. In our work, we have tried to integrate this relationship along with feature-based correlation among the extracted patches from the particular tumorous region. For the given task of classification, we have used BiLSTMs to model both forward and backward contextual relationship. RNN based models eliminate the limitation of sequence size by allowing the modelling of variable size images within a deep learning model. We have also incorporated the effect of spatial continuity by exploring different scanning techniques used to sample patches. To establish the efficiency of our approach, we trained and tested our model on two datasets, microscopy images and WSI tumour regions. After comparing with contemporary literature we achieved the better performance with accuracy of 90% for microscopy image dataset. For WSI tumour region dataset, we compared the classification results with deep learning networks such as ResNet, DenseNet, and InceptionV3 using maximum voting technique. We achieved the highest performance accuracy of 84%. We found out that BiLSTMs with CNN features have performed much better in modelling patches into an end-to-end Image classification network. Additionally, the variable dimensions of WSI tumour regions were used for classification without the need for resizing. This suggests that our method is independent of tumour image size and can process large dimensional images without losing the resolution details.
* 36 pages, 5 figures, 9 tables. Published in Computerized Medical Imaging and Graphics
Labeling-Free Comparison Testing of Deep Learning Models
Apr 08, 2022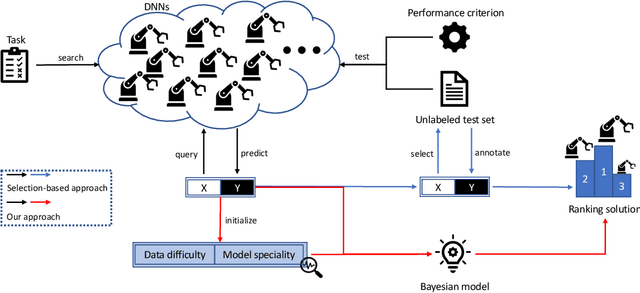

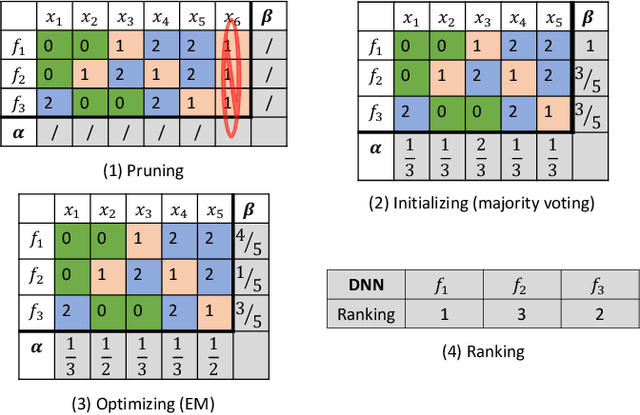
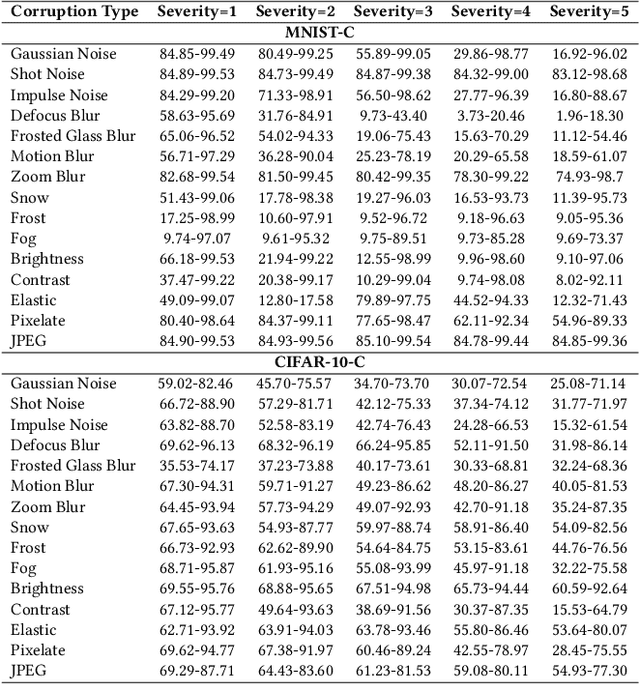
Various deep neural networks (DNNs) are developed and reported for their tremendous success in multiple domains. Given a specific task, developers can collect massive DNNs from public sources for efficient reusing and avoid redundant work from scratch. However, testing the performance (e.g., accuracy and robustness) of multiple DNNs and giving a reasonable recommendation that which model should be used is challenging regarding the scarcity of labeled data and demand of domain expertise. Existing testing approaches are mainly selection-based where after sampling, a few of the test data are labeled to discriminate DNNs. Therefore, due to the randomness of sampling, the performance ranking is not deterministic. In this paper, we propose a labeling-free comparison testing approach to overcome the limitations of labeling effort and sampling randomness. The main idea is to learn a Bayesian model to infer the models' specialty only based on predicted labels. To evaluate the effectiveness of our approach, we undertook exhaustive experiments on 9 benchmark datasets spanning in the domains of image, text, and source code, and 165 DNNs. In addition to accuracy, we consider the robustness against synthetic and natural distribution shifts. The experimental results demonstrate that the performance of existing approaches degrades under distribution shifts. Our approach outperforms the baseline methods by up to 0.74 and 0.53 on Spearman's correlation and Kendall's $\tau$, respectively, regardless of the dataset and distribution shift. Additionally, we investigated the impact of model quality (accuracy and robustness) and diversity (standard deviation of the quality) on the testing effectiveness and observe that there is a higher chance of a good result when the quality is over 50\% and the diversity is larger than 18\%.