 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards End-to-End In-Image Neural Machine Translation
Oct 20, 2020
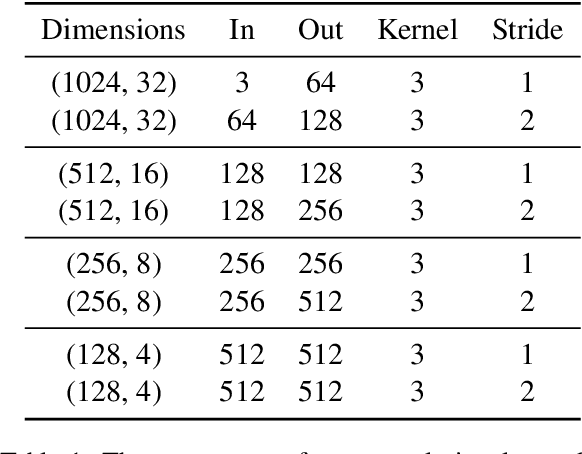

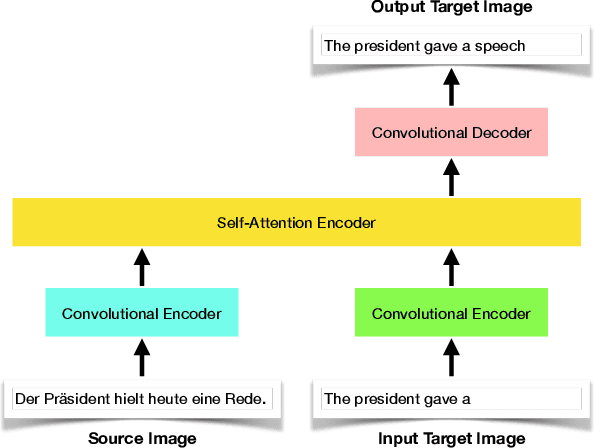
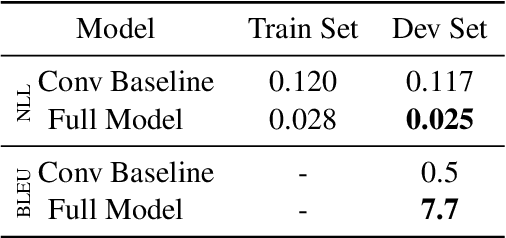
In this paper, we offer a preliminary investigation into the task of in-image machine translation: transforming an image containing text in one language into an image containing the same text in another language. We propose an end-to-end neural model for this task inspired by recent approaches to neural machine translation, and demonstrate promising initial results based purely on pixel-level supervision. We then offer a quantitative and qualitative evaluation of our system outputs and discuss some common failure modes. Finally, we conclude with directions for future work.
HMFS: Hybrid Masking for Few-Shot Segmentation
Mar 24, 2022
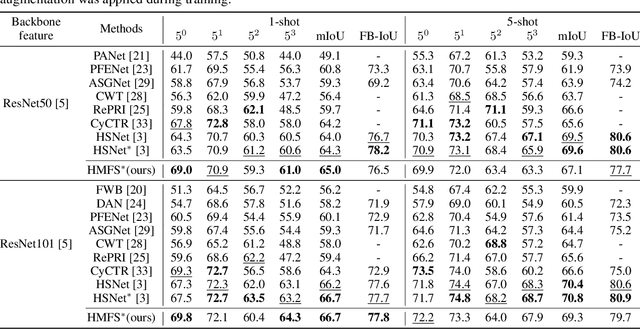
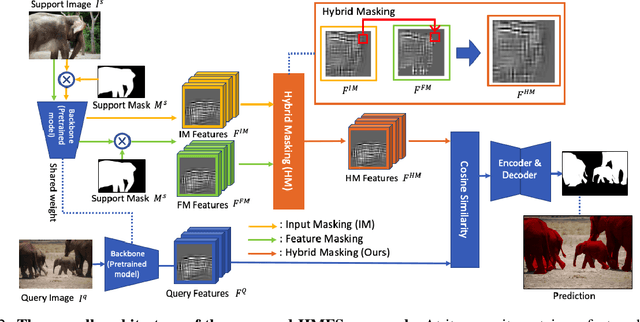
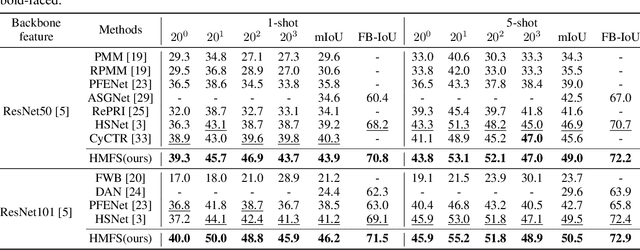
We study few-shot semantic segmentation that aims to segment a target object from a query image when provided with a few annotated support images of the target class. Several recent methods resort to a feature masking (FM) technique, introduced by [1], to discard irrelevant feature activations to facilitate reliable segmentation mask prediction. A fundamental limitation of FM is the inability to preserve the fine-grained spatial details that affect the accuracy of segmentation mask, especially for small target objects. In this paper, we develop a simple, effective, and efficient approach to enhance feature masking (FM). We dub the enhanced FM as hybrid masking (HM). Specifically, we compensate for the loss of fine-grained spatial details in FM technique by investigating and leveraging a complementary basic input masking method [2]. To validate the effectiveness of HM, we instantiate it into a strong baseline [3], and coin the resulting framework as HMFS. Experimental results on three publicly available benchmarks reveal that HMFS outperforms the current state-of-the-art methods by visible margins.
Probabilistic Embeddings Revisited
Feb 14, 2022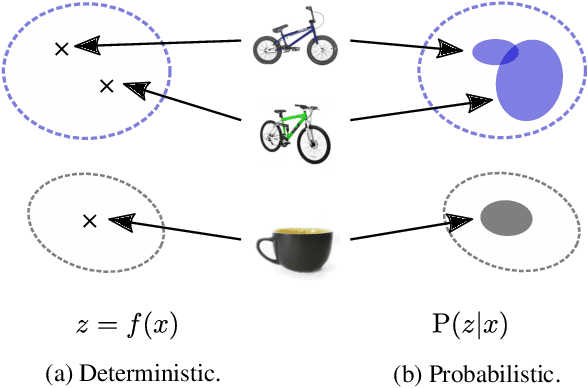
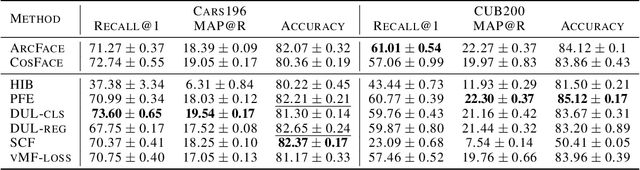
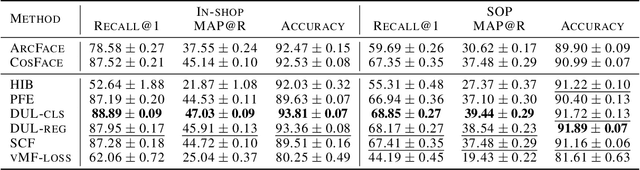
In recent years, deep metric learning and its probabilistic extensions achieved state-of-the-art results in a face verification task. However, despite improvements in face verification, probabilistic methods received little attention in the community. It is still unclear whether they can improve image retrieval quality. In this paper, we present an extensive comparison of probabilistic methods in verification and retrieval tasks. Following the suggested methodology, we outperform metric learning baselines using probabilistic methods and propose several directions for future work and improvements.
An Improved Lightweight YOLOv5 Model Based on Attention Mechanism for Face Mask Detection
Apr 02, 2022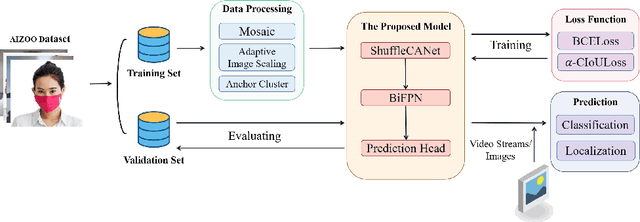
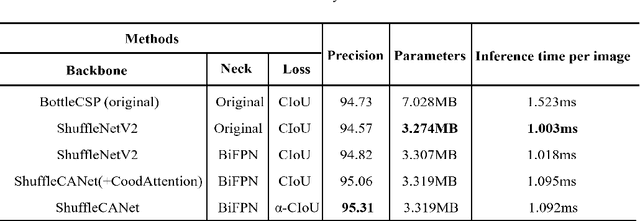
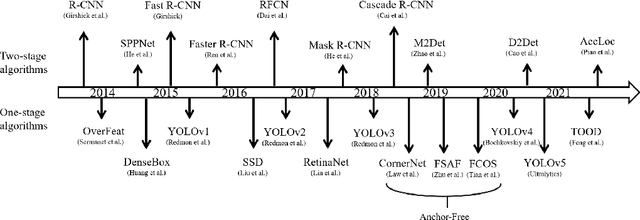
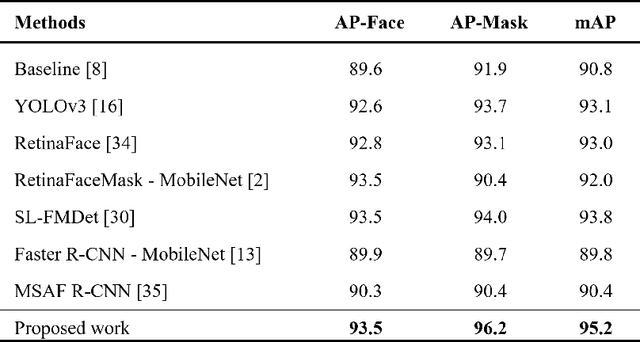
Coronavirus 2019 has brought severe challenges to social stability and public health worldwide. One effective way of curbing the epidemic is to require people to wear masks in public places and monitor mask-wearing states by utilizing suitable automatic detectors. However, existing deep learning based models struggle to simultaneously achieve the requirements of both high precision and real-time performance. To solve this problem, we propose an improved lightweight face mask detector based on YOLOv5, which can achieve an excellent balance of precision and speed. Firstly, a novel backbone ShuffleCANet that combines ShuffleNetV2 network with Coordinate Attention mechanism is proposed as the backbone. Afterwards, an efficient path aggression network BiFPN is applied as the feature fusion neck. Furthermore, the localization loss is replaced with alpha-CIoU in model training phase to obtain higher-quality anchors. Some valuable strategies such as data augmentation, adaptive image scaling, and anchor cluster operation are also utilized. Experimental results on AIZOO face mask dataset show the superiority of the proposed model. Compared with the original YOLOv5, the proposed model increases the inference speed by 28.3% while still improving the precision by 0.58%. It achieves the best mean average precision of 95.2% compared with other seven existing models, which is 4.4% higher than the baseline.
An Exploration of Active Learning for Affective Digital Phenotyping
Apr 06, 2022
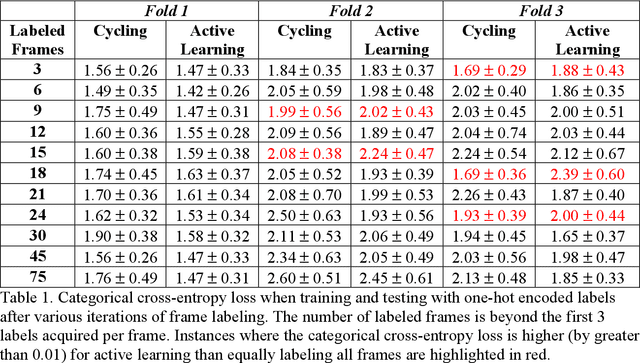
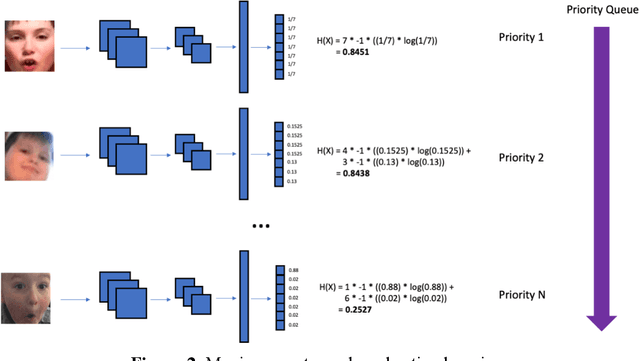
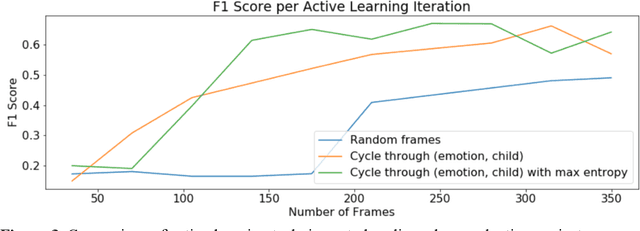
Some of the most severe bottlenecks preventing widespread development of machine learning models for human behavior include a dearth of labeled training data and difficulty of acquiring high quality labels. Active learning is a paradigm for using algorithms to computationally select a useful subset of data points to label using metrics for model uncertainty and data similarity. We explore active learning for naturalistic computer vision emotion data, a particularly heterogeneous and complex data space due to inherently subjective labels. Using frames collected from gameplay acquired from a therapeutic smartphone game for children with autism, we run a simulation of active learning using gameplay prompts as metadata to aid in the active learning process. We find that active learning using information generated during gameplay slightly outperforms random selection of the same number of labeled frames. We next investigate a method to conduct active learning with subjective data, such as in affective computing, and where multiple crowdsourced labels can be acquired for each image. Using the Child Affective Facial Expression (CAFE) dataset, we simulate an active learning process for crowdsourcing many labels and find that prioritizing frames using the entropy of the crowdsourced label distribution results in lower categorical cross-entropy loss compared to random frame selection. Collectively, these results demonstrate pilot evaluations of two novel active learning approaches for subjective affective data collected in noisy settings.
Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning
Nov 26, 2021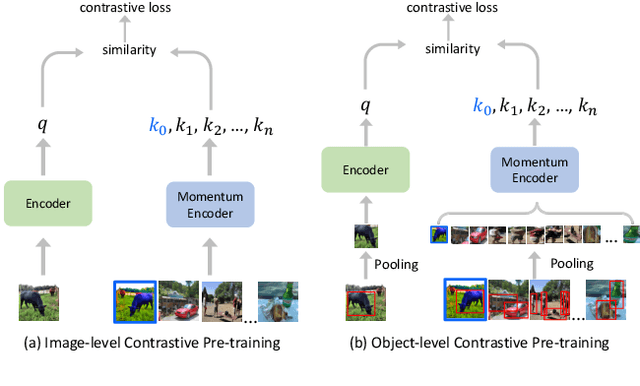
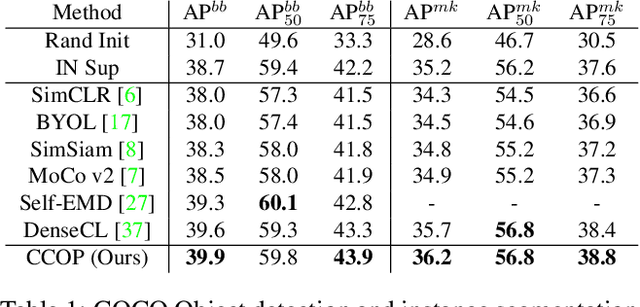
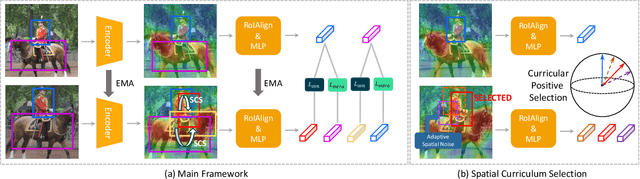
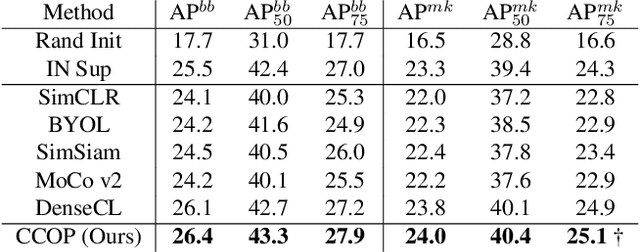
The goal of contrastive learning based pre-training is to leverage large quantities of unlabeled data to produce a model that can be readily adapted downstream. Current approaches revolve around solving an image discrimination task: given an anchor image, an augmented counterpart of that image, and some other images, the model must produce representations such that the distance between the anchor and its counterpart is small, and the distances between the anchor and the other images are large. There are two significant problems with this approach: (i) by contrasting representations at the image-level, it is hard to generate detailed object-sensitive features that are beneficial to downstream object-level tasks such as instance segmentation; (ii) the augmentation strategy of producing an augmented counterpart is fixed, making learning less effective at the later stages of pre-training. In this work, we introduce Curricular Contrastive Object-level Pre-training (CCOP) to tackle these problems: (i) we use selective search to find rough object regions and use them to build an inter-image object-level contrastive loss and an intra-image object-level discrimination loss into our pre-training objective; (ii) we present a curriculum learning mechanism that adaptively augments the generated regions, which allows the model to consistently acquire a useful learning signal, even in the later stages of pre-training. Our experiments show that our approach improves on the MoCo v2 baseline by a large margin on multiple object-level tasks when pre-training on multi-object scene image datasets. Code is available at https://github.com/ChenhongyiYang/CCOP.
Relative Pose from SIFT Features
Mar 15, 2022
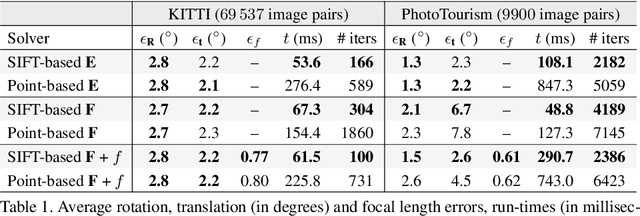
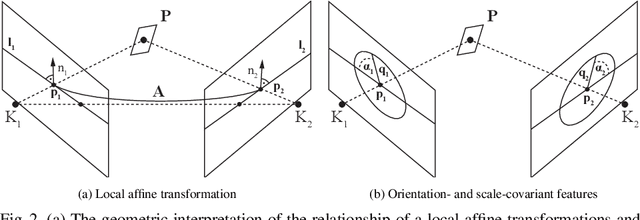
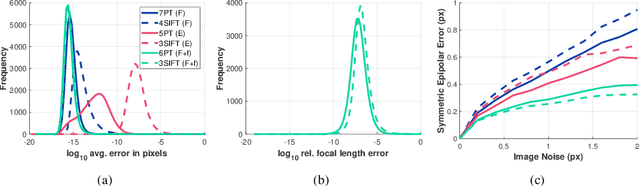
This paper proposes the geometric relationship of epipolar geometry and orientation- and scale-covariant, e.g., SIFT, features. We derive a new linear constraint relating the unknown elements of the fundamental matrix and the orientation and scale. This equation can be used together with the well-known epipolar constraint to, e.g., estimate the fundamental matrix from four SIFT correspondences, essential matrix from three, and to solve the semi-calibrated case from three correspondences. Requiring fewer correspondences than the well-known point-based approaches (e.g., 5PT, 6PT and 7PT solvers) for epipolar geometry estimation makes RANSAC-like randomized robust estimation significantly faster. The proposed constraint is tested on a number of problems in a synthetic environment and on publicly available real-world datasets on more than 80000 image pairs. It is superior to the state-of-the-art in terms of processing time while often leading to more accurate results.
Is my Driver Observation Model Overconfident? Input-guided Calibration Networks for Reliable and Interpretable Confidence Estimates
Apr 10, 2022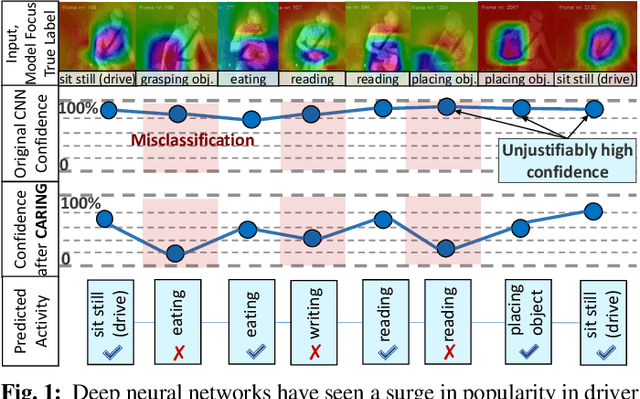
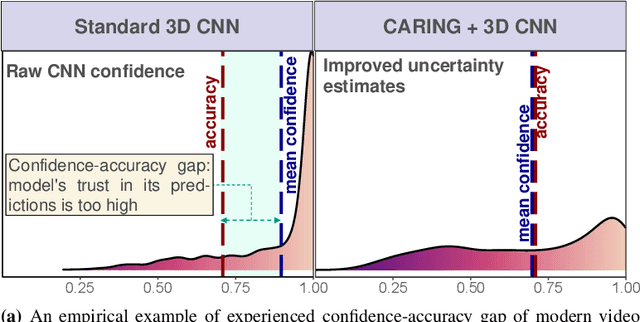
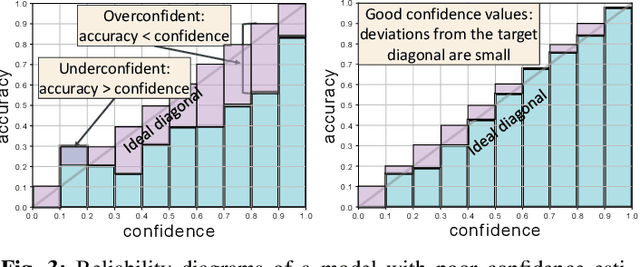

Driver observation models are rarely deployed under perfect conditions. In practice, illumination, camera placement and type differ from the ones present during training and unforeseen behaviours may occur at any time. While observing the human behind the steering wheel leads to more intuitive human-vehicle-interaction and safer driving, it requires recognition algorithms which do not only predict the correct driver state, but also determine their prediction quality through realistic and interpretable confidence measures. Reliable uncertainty estimates are crucial for building trust and are a serious obstacle for deploying activity recognition networks in real driving systems. In this work, we for the first time examine how well the confidence values of modern driver observation models indeed match the probability of the correct outcome and show that raw neural network-based approaches tend to significantly overestimate their prediction quality. To correct this misalignment between the confidence values and the actual uncertainty, we consider two strategies. First, we enhance two activity recognition models often used for driver observation with temperature scaling-an off-the-shelf method for confidence calibration in image classification. Then, we introduce Calibrated Action Recognition with Input Guidance (CARING)-a novel approach leveraging an additional neural network to learn scaling the confidences depending on the video representation. Extensive experiments on the Drive&Act dataset demonstrate that both strategies drastically improve the quality of model confidences, while our CARING model out-performs both, the original architectures and their temperature scaling enhancement, leading to best uncertainty estimates.
Semantic-Aware Domain Generalized Segmentation
Apr 02, 2022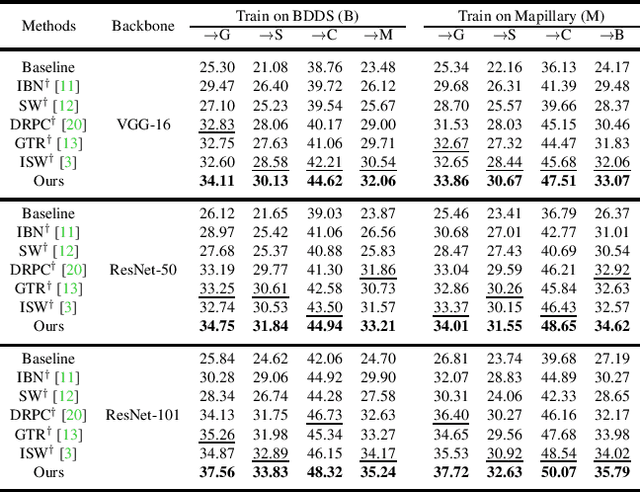
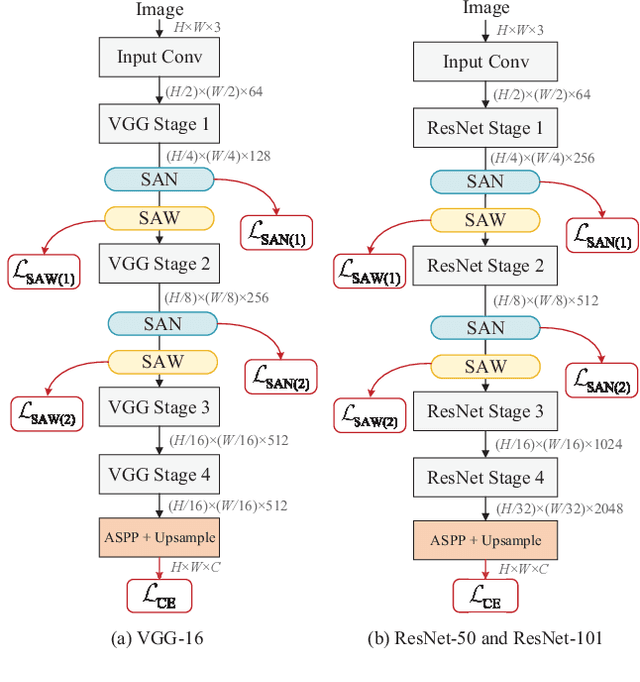
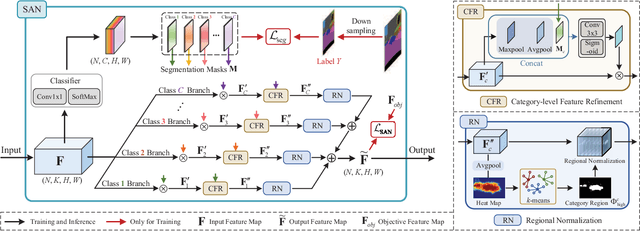

Deep models trained on source domain lack generalization when evaluated on unseen target domains with different data distributions. The problem becomes even more pronounced when we have no access to target domain samples for adaptation. In this paper, we address domain generalized semantic segmentation, where a segmentation model is trained to be domain-invariant without using any target domain data. Existing approaches to tackle this problem standardize data into a unified distribution. We argue that while such a standardization promotes global normalization, the resulting features are not discriminative enough to get clear segmentation boundaries. To enhance separation between categories while simultaneously promoting domain invariance, we propose a framework including two novel modules: Semantic-Aware Normalization (SAN) and Semantic-Aware Whitening (SAW). Specifically, SAN focuses on category-level center alignment between features from different image styles, while SAW enforces distributed alignment for the already center-aligned features. With the help of SAN and SAW, we encourage both intra-category compactness and inter-category separability. We validate our approach through extensive experiments on widely-used datasets (i.e. GTAV, SYNTHIA, Cityscapes, Mapillary and BDDS). Our approach shows significant improvements over existing state-of-the-art on various backbone networks. Code is available at https://github.com/leolyj/SAN-SAW
ShowFace: Coordinated Face Inpainting with Memory-Disentangled Refinement Networks
Apr 06, 2022
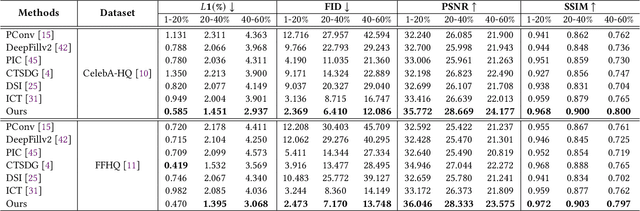
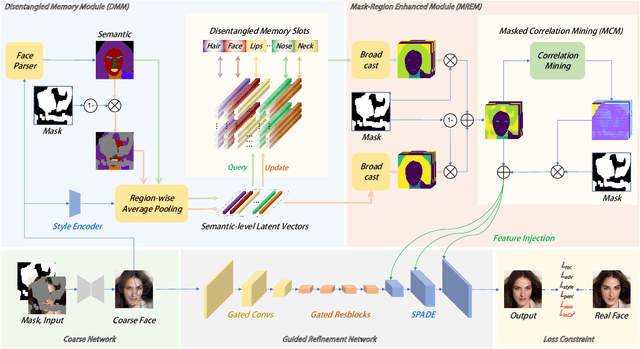
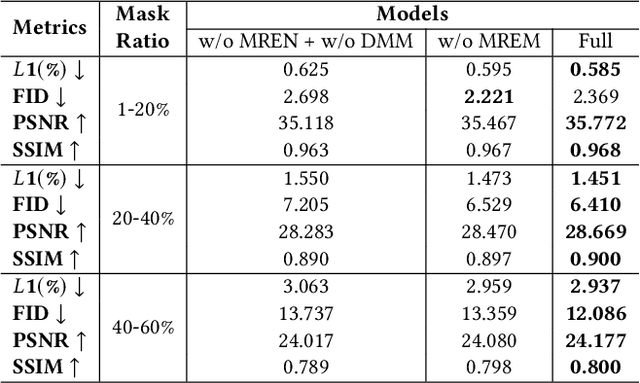
Face inpainting aims to complete the corrupted regions of the face images, which requires coordination between the completed areas and the non-corrupted areas. Recently, memory-oriented methods illustrate great prospects in the generation related tasks by introducing an external memory module to improve image coordination. However, such methods still have limitations in restoring the consistency and continuity for specificfacial semantic parts. In this paper, we propose the coarse-to-fine Memory-Disentangled Refinement Networks (MDRNets) for coordinated face inpainting, in which two collaborative modules are integrated, Disentangled Memory Module (DMM) and Mask-Region Enhanced Module (MREM). Specifically, the DMM establishes a group of disentangled memory blocks to store the semantic-decoupled face representations, which could provide the most relevant information to refine the semantic-level coordination. The MREM involves a masked correlation mining mechanism to enhance the feature relationships into the corrupted regions, which could also make up for the correlation loss caused by memory disentanglement. Furthermore, to better improve the inter-coordination between the corrupted and non-corrupted regions and enhance the intra-coordination in corrupted regions, we design InCo2 Loss, a pair of similarity based losses to constrain the feature consistency. Eventually, extensive experiments conducted on CelebA-HQ and FFHQ datasets demonstrate the superiority of our MDRNets compared with previous State-Of-The-Art methods.