 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Colour alignment for relative colour constancy via non-standard references
Dec 30, 2021

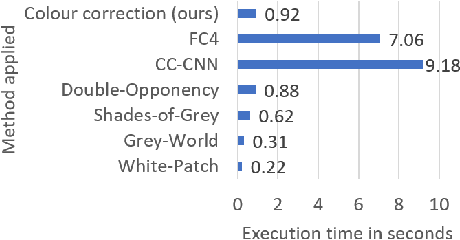
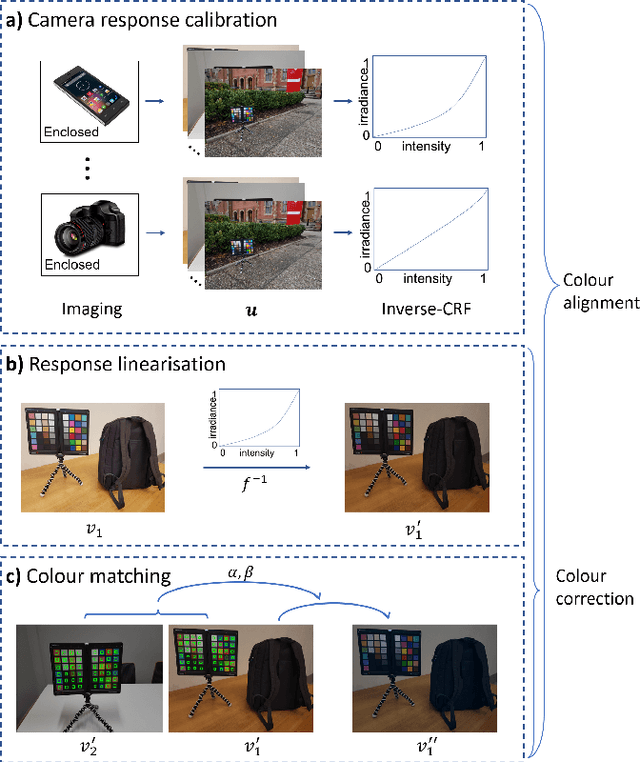
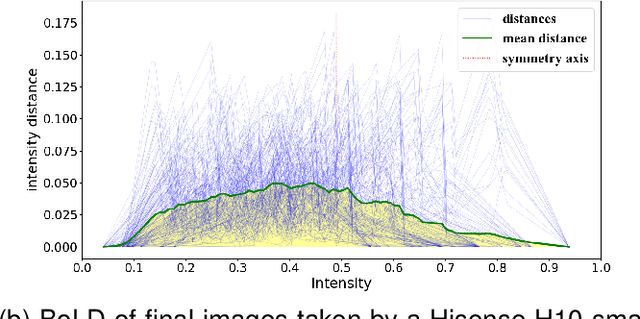
Relative colour constancy is an essential requirement for many scientific imaging applications. However, most digital cameras differ in their image formations and native sensor output is usually inaccessible, e.g., in smartphone camera applications. This makes it hard to achieve consistent colour assessment across a range of devices, and that undermines the performance of computer vision algorithms. To resolve this issue, we propose a colour alignment model that considers the camera image formation as a black-box and formulates colour alignment as a three-step process: camera response calibration, response linearisation, and colour matching. The proposed model works with non-standard colour references, i.e., colour patches without knowing the true colour values, by utilising a novel balance-of-linear-distances feature. It is equivalent to determining the camera parameters through an unsupervised process. It also works with a minimum number of corresponding colour patches across the images to be colour aligned to deliver the applicable processing. Two challenging image datasets collected by multiple cameras under various illumination and exposure conditions were used to evaluate the model. Performance benchmarks demonstrated that our model achieved superior performance compared to other popular and state-of-the-art methods.
Characterizing and Understanding the Behavior of Quantized Models for Reliable Deployment
Apr 08, 2022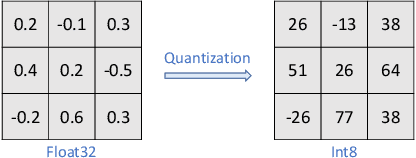
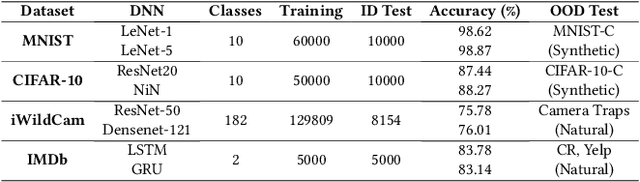
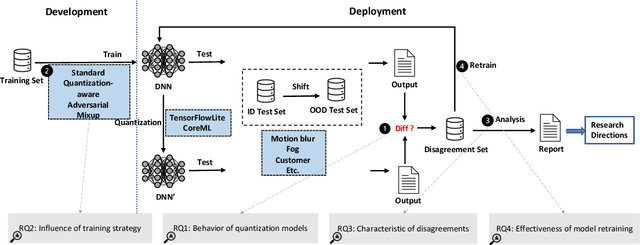
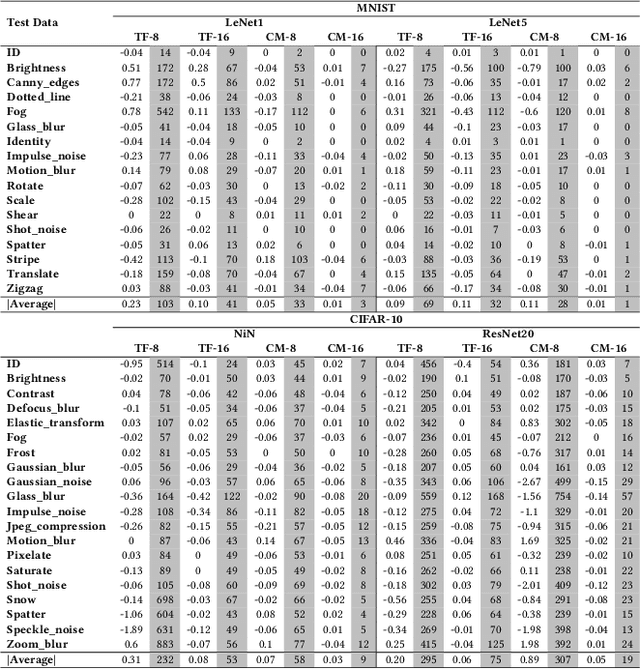
Deep Neural Networks (DNNs) have gained considerable attention in the past decades due to their astounding performance in different applications, such as natural language modeling, self-driving assistance, and source code understanding. With rapid exploration, more and more complex DNN architectures have been proposed along with huge pre-trained model parameters. The common way to use such DNN models in user-friendly devices (e.g., mobile phones) is to perform model compression before deployment. However, recent research has demonstrated that model compression, e.g., model quantization, yields accuracy degradation as well as outputs disagreements when tested on unseen data. Since the unseen data always include distribution shifts and often appear in the wild, the quality and reliability of quantized models are not ensured. In this paper, we conduct a comprehensive study to characterize and help users understand the behaviors of quantized models. Our study considers 4 datasets spanning from image to text, 8 DNN architectures including feed-forward neural networks and recurrent neural networks, and 42 shifted sets with both synthetic and natural distribution shifts. The results reveal that 1) data with distribution shifts happen more disagreements than without. 2) Quantization-aware training can produce more stable models than standard, adversarial, and Mixup training. 3) Disagreements often have closer top-1 and top-2 output probabilities, and $Margin$ is a better indicator than the other uncertainty metrics to distinguish disagreements. 4) Retraining with disagreements has limited efficiency in removing disagreements. We opensource our code and models as a new benchmark for further studying the quantized models.
Which Style Makes Me Attractive? Interpretable Control Discovery and Counterfactual Explanation on StyleGAN
Jan 24, 2022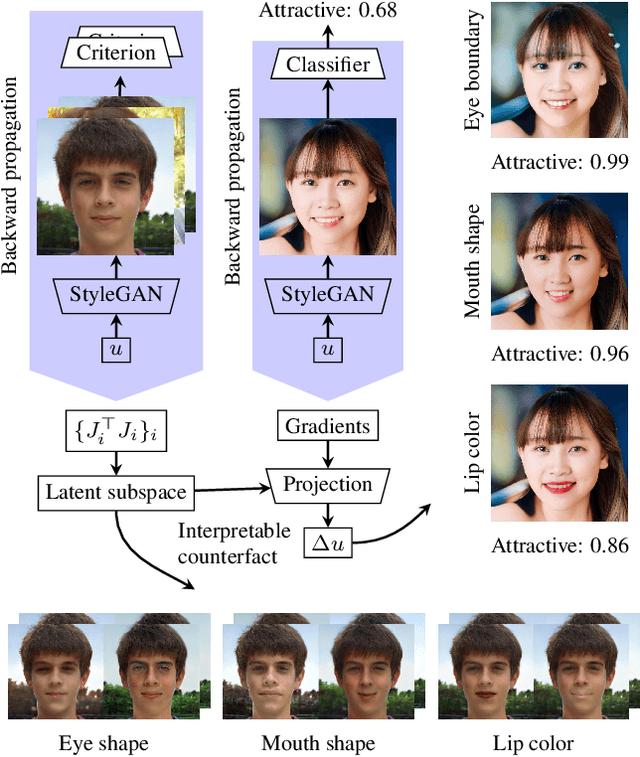



The semantically disentangled latent subspace in GAN provides rich interpretable controls in image generation. This paper includes two contributions on semantic latent subspace analysis in the scenario of face generation using StyleGAN2. First, we propose a novel approach to disentangle latent subspace semantics by exploiting existing face analysis models, e.g., face parsers and face landmark detectors. These models provide the flexibility to construct various criterions with very concrete and interpretable semantic meanings (e.g., change face shape or change skin color) to restrict latent subspace disentanglement. Rich latent space controls unknown previously can be discovered using the constructed criterions. Second, we propose a new perspective to explain the behavior of a CNN classifier by generating counterfactuals in the interpretable latent subspaces we discovered. This explanation helps reveal whether the classifier learns semantics as intended. Experiments on various disentanglement criterions demonstrate the effectiveness of our approach. We believe this approach contributes to both areas of image manipulation and counterfactual explainability of CNNs. The code is available at \url{https://github.com/prclibo/ice}.
AutoAdversary: A Pixel Pruning Method for Sparse Adversarial Attack
Mar 18, 2022
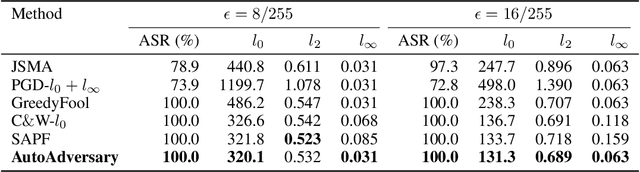

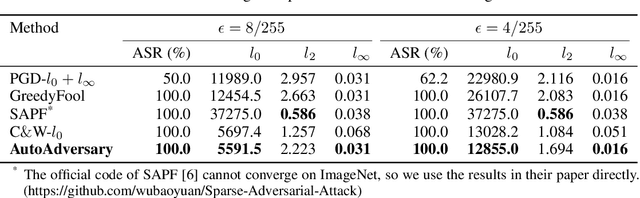
Deep neural networks (DNNs) have been proven to be vulnerable to adversarial examples. A special branch of adversarial examples, namely sparse adversarial examples, can fool the target DNNs by perturbing only a few pixels. However, many existing sparse adversarial attacks use heuristic methods to select the pixels to be perturbed, and regard the pixel selection and the adversarial attack as two separate steps. From the perspective of neural network pruning, we propose a novel end-to-end sparse adversarial attack method, namely AutoAdversary, which can find the most important pixels automatically by integrating the pixel selection into the adversarial attack. Specifically, our method utilizes a trainable neural network to generate a binary mask for the pixel selection. After jointly optimizing the adversarial perturbation and the neural network, only the pixels corresponding to the value 1 in the mask are perturbed. Experiments demonstrate the superiority of our proposed method over several state-of-the-art methods. Furthermore, since AutoAdversary does not require a heuristic pixel selection process, it does not slow down excessively as other methods when the image size increases.
Federated Semi-supervised Medical Image Classification via Inter-client Relation Matching
Jun 16, 2021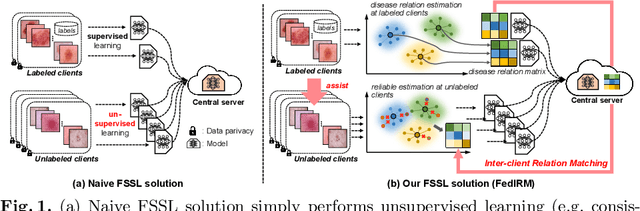
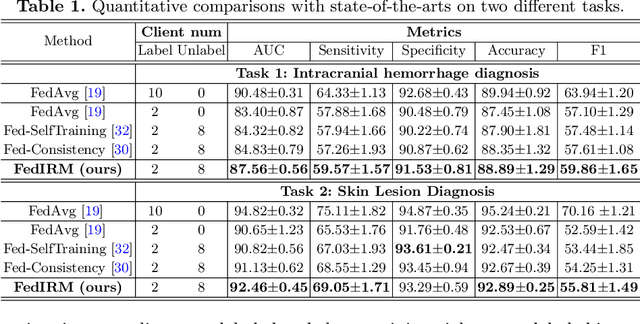
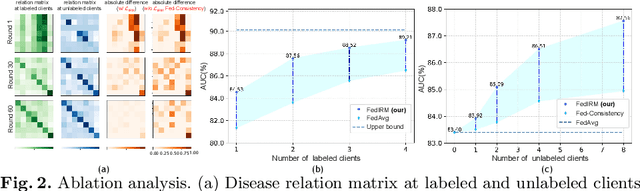
Federated learning (FL) has emerged with increasing popularity to collaborate distributed medical institutions for training deep networks. However, despite existing FL algorithms only allow the supervised training setting, most hospitals in realistic usually cannot afford the intricate data labeling due to absence of budget or expertise. This paper studies a practical yet challenging FL problem, named \textit{Federated Semi-supervised Learning} (FSSL), which aims to learn a federated model by jointly utilizing the data from both labeled and unlabeled clients (i.e., hospitals). We present a novel approach for this problem, which improves over traditional consistency regularization mechanism with a new inter-client relation matching scheme. The proposed learning scheme explicitly connects the learning across labeled and unlabeled clients by aligning their extracted disease relationships, thereby mitigating the deficiency of task knowledge at unlabeled clients and promoting discriminative information from unlabeled samples. We validate our method on two large-scale medical image classification datasets. The effectiveness of our method has been demonstrated with the clear improvements over state-of-the-arts as well as the thorough ablation analysis on both tasks\footnote{Code will be made available at \url{https://github.com/liuquande/FedIRM}}.
SEN12MS-CR-TS: A Remote Sensing Data Set for Multi-modal Multi-temporal Cloud Removal
Jan 24, 2022


About half of all optical observations collected via spaceborne satellites are affected by haze or clouds. Consequently, cloud coverage affects the remote sensing practitioner's capabilities of a continuous and seamless monitoring of our planet. This work addresses the challenge of optical satellite image reconstruction and cloud removal by proposing a novel multi-modal and multi-temporal data set called SEN12MS-CR-TS. We propose two models highlighting the benefits and use cases of SEN12MS-CR-TS: First, a multi-modal multi-temporal 3D-Convolution Neural Network that predicts a cloud-free image from a sequence of cloudy optical and radar images. Second, a sequence-to-sequence translation model that predicts a cloud-free time series from a cloud-covered time series. Both approaches are evaluated experimentally, with their respective models trained and tested on SEN12MS-CR-TS. The conducted experiments highlight the contribution of our data set to the remote sensing community as well as the benefits of multi-modal and multi-temporal information to reconstruct noisy information. Our data set is available at https://patrickTUM.github.io/cloud_removal
Does Proprietary Software Still Offer Protection of Intellectual Property in the Age of Machine Learning? -- A Case Study using Dual Energy CT Data
Dec 06, 2021
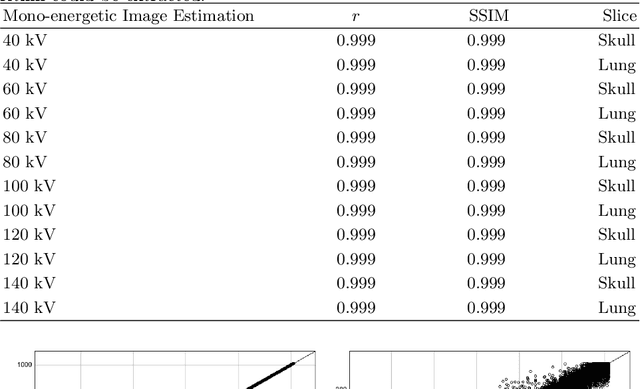
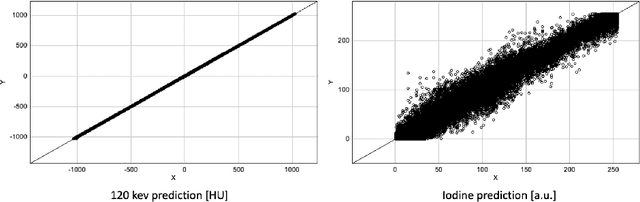
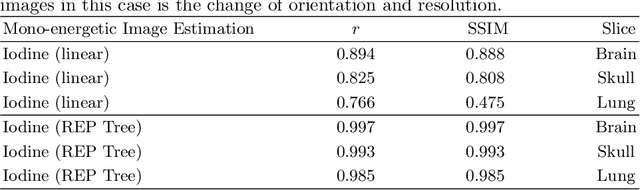
In the domain of medical image processing, medical device manufacturers protect their intellectual property in many cases by shipping only compiled software, i.e. binary code which can be executed but is difficult to be understood by a potential attacker. In this paper, we investigate how well this procedure is able to protect image processing algorithms. In particular, we investigate whether the computation of mono-energetic images and iodine maps from dual energy CT data can be reverse-engineered by machine learning methods. Our results indicate that both can be approximated using only one single slice image as training data at a very high accuracy with structural similarity greater than 0.98 in all investigated cases.
Memory-Efficient Hierarchical Neural Architecture Search for Image Restoration
Dec 24, 2020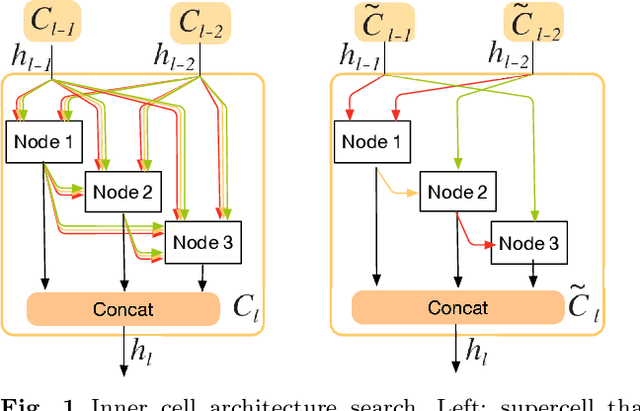

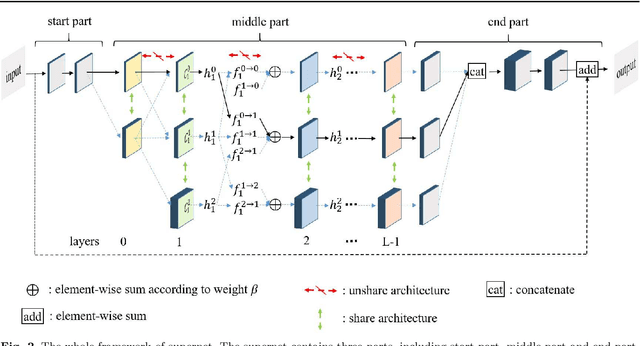

Recently, much attention has been spent on neural architecture search (NAS) approaches, which often outperform manually designed architectures on highlevel vision tasks. Inspired by this, we attempt to leverage NAS technique to automatically design efficient network architectures for low-level image restoration tasks. In this paper, we propose a memory-efficient hierarchical NAS HiNAS (HiNAS) and apply to two such tasks: image denoising and image super-resolution. HiNAS adopts gradient based search strategies and builds an flexible hierarchical search space, including inner search space and outer search space, which in charge of designing cell architectures and deciding cell widths, respectively. For inner search space, we propose layerwise architecture sharing strategy (LWAS), resulting in more flexible architectures and better performance. For outer search space, we propose cell sharing strategy to save memory, and considerably accelerate the search speed. The proposed HiNAS is both memory and computation efficient. With a single GTX1080Ti GPU, it takes only about 1 hour for searching for denoising network on BSD 500 and 3.5 hours for searching for the super-resolution structure on DIV2K. Experimental results show that the architectures found by HiNAS have fewer parameters and enjoy a faster inference speed, while achieving highly competitive performance compared with state-of-the-art methods.
Rethinking the optimization process for self-supervised model-driven MRI reconstruction
Mar 18, 2022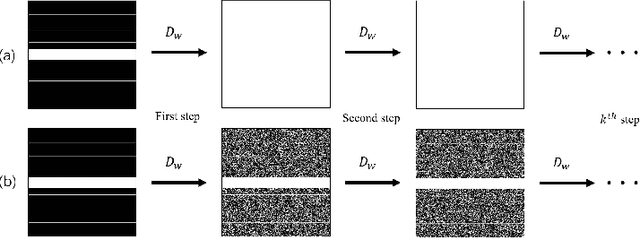
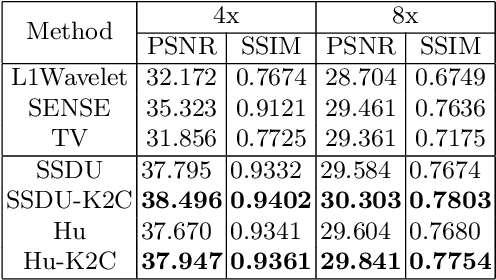
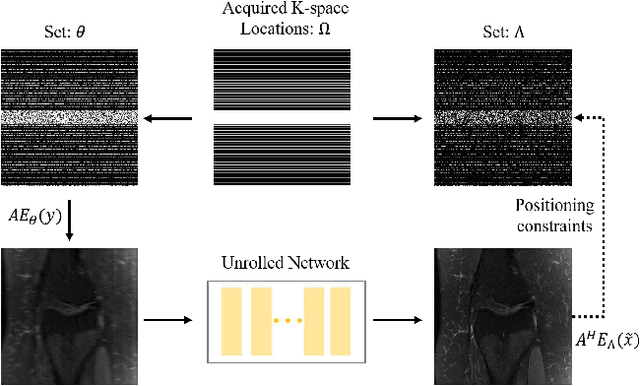
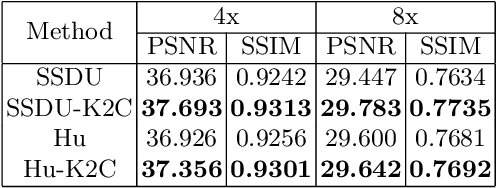
Recovering high-quality images from undersampled measurements is critical for accelerated MRI reconstruction. Recently, various supervised deep learning-based MRI reconstruction methods have been developed. Despite the achieved promising performances, these methods require fully sampled reference data, the acquisition of which is resource-intensive and time-consuming. Self-supervised learning has emerged as a promising solution to alleviate the reliance on fully sampled datasets. However, existing self-supervised methods suffer from reconstruction errors due to the insufficient constraint enforced on the non-sampled data points and the error accumulation happened alongside the iterative image reconstruction process for model-driven deep learning reconstrutions. To address these challenges, we propose K2Calibrate, a K-space adaptation strategy for self-supervised model-driven MR reconstruction optimization. By iteratively calibrating the learned measurements, K2Calibrate can reduce the network's reconstruction deterioration caused by statistically dependent noise. Extensive experiments have been conducted on the open-source dataset FastMRI, and K2Calibrate achieves better results than five state-of-the-art methods. The proposed K2Calibrate is plug-and-play and can be easily integrated with different model-driven deep learning reconstruction methods.
Multimodal Image-to-Image Translation via a Single Generative Adversarial Network
Aug 04, 2020
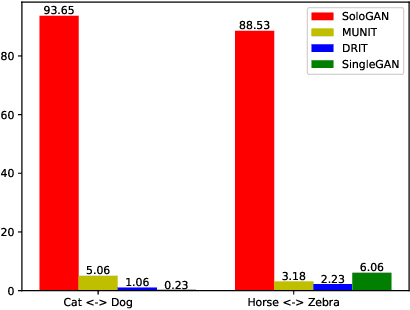


Despite significant advances in image-to-image (I2I) translation with Generative Adversarial Networks (GANs) have been made, it remains challenging to effectively translate an image to a set of diverse images in multiple target domains using a pair of generator and discriminator. Existing multimodal I2I translation methods adopt multiple domain-specific content encoders for different domains, where each domain-specific content encoder is trained with images from the same domain only. Nevertheless, we argue that the content (domain-invariant) features should be learned from images among all the domains. Consequently, each domain-specific content encoder of existing schemes fails to extract the domain-invariant features efficiently. To address this issue, we present a flexible and general SoloGAN model for efficient multimodal I2I translation among multiple domains with unpaired data. In contrast to existing methods, the SoloGAN algorithm uses a single projection discriminator with an additional auxiliary classifier, and shares the encoder and generator for all domains. As such, the SoloGAN model can be trained effectively with images from all domains such that the domain-invariant content representation can be efficiently extracted. Qualitative and quantitative results over a wide range of datasets against several counterparts and variants of the SoloGAN model demonstrate the merits of the method, especially for the challenging I2I translation tasks, i.e., tasks that involve extreme shape variations or need to keep the complex backgrounds unchanged after translations. Furthermore, we demonstrate the contribution of each component using ablation studies.