 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Real-time Rendering for Integral Imaging Light Field Displays Based on a Voxel-Pixel Lookup Table
Jan 26, 2022
A real-time elemental image array (EIA) generation method which does not sacrifice accuracy nor rely on high-performance hardware is developed, through raytracing and pre-stored voxel-pixel lookup table (LUT). Benefiting from both offline and online working flow, experiments verified the effectiveness.
The artificial synesthete: Image-melody translations with variational autoencoders
Dec 06, 2021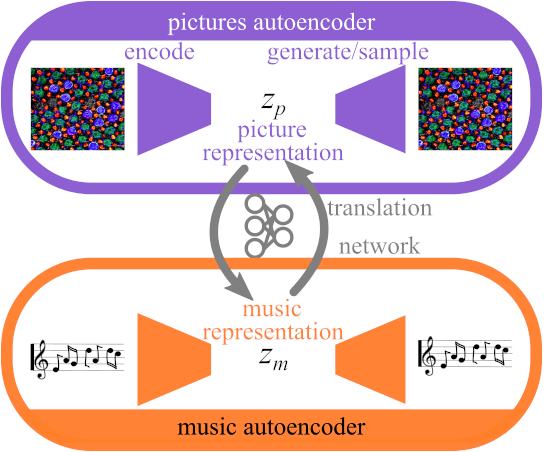
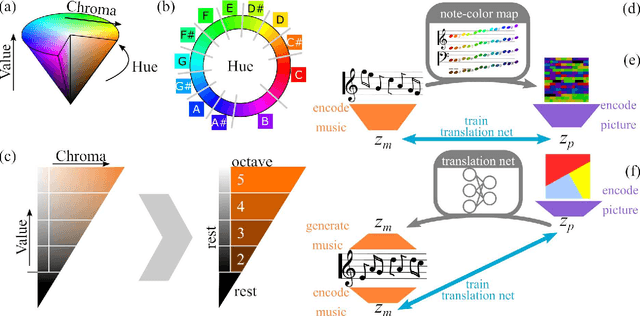
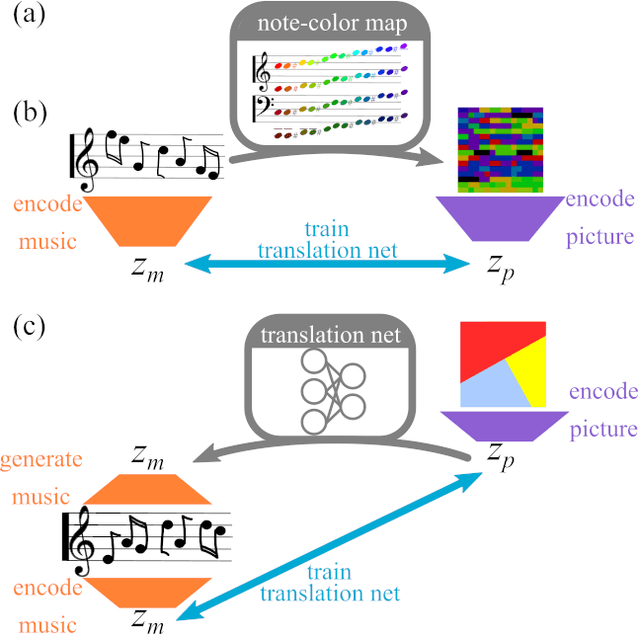
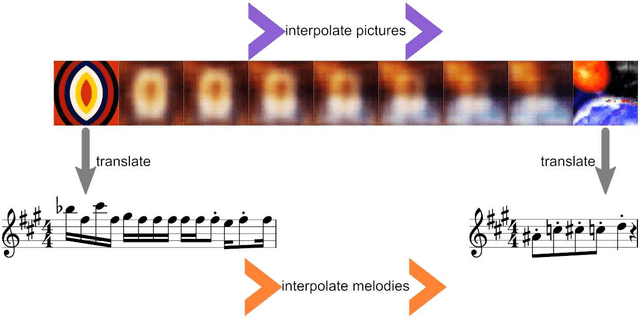
Abstract This project presents a system of neural networks to translate between images and melodies. Autoencoders compress the information in samples to abstract representation. A translation network learns a set of correspondences between musical and visual concepts from repeated joint exposure. The resulting "artificial synesthete" generates simple melodies inspired by images, and images from music. These are novel interpretation (not transposed data), expressing the machine' perception and understanding. Observing the work, one explores the machine's perception and thus, by contrast, one's own.
MRI Reconstruction via Data Driven Markov Chain with Joint Uncertainty Estimation
Feb 03, 2022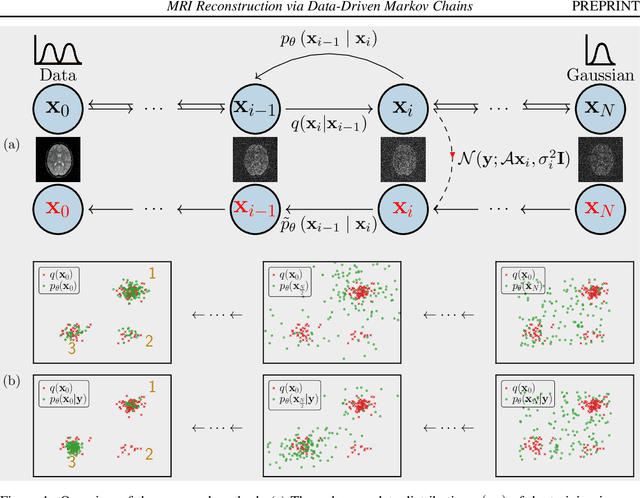
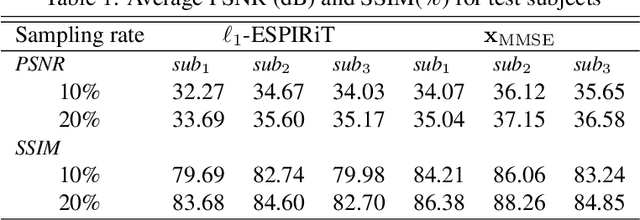
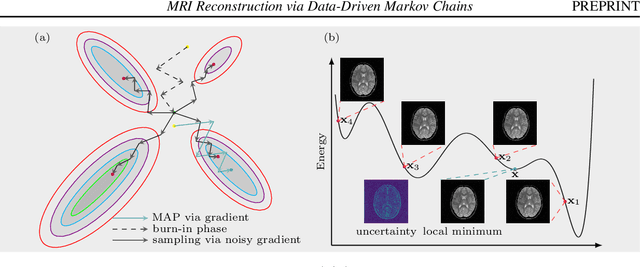

We introduce a framework that enables efficient sampling from learned probability distributions for MRI reconstruction. Different from conventional deep learning-based MRI reconstruction techniques, samples are drawn from the posterior distribution given the measured k-space using the Markov chain Monte Carlo (MCMC) method. In addition to the maximum a posteriori (MAP) estimate for the image, which can be obtained with conventional methods, the minimum mean square error (MMSE) estimate and uncertainty maps can also be computed. The data-driven Markov chains are constructed from the generative model learned from a given image database and are independent of the forward operator that is used to model the k-space measurement. This provides flexibility because the method can be applied to k-space acquired with different sampling schemes or receive coils using the same pre-trained models. Furthermore, we use a framework based on a reverse diffusion process to be able to utilize advanced generative models. The performance of the method is evaluated on an open dataset using 10-fold accelerated acquisition.
Rich CNN-Transformer Feature Aggregation Networks for Super-Resolution
Mar 16, 2022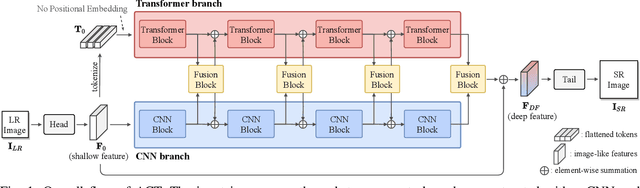


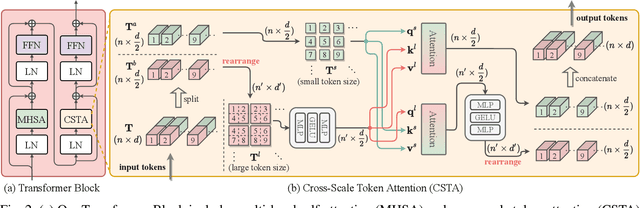
Recent vision transformers along with self-attention have achieved promising results on various computer vision tasks. In particular, a pure transformer-based image restoration architecture surpasses the existing CNN-based methods using multi-task pre-training with a large number of trainable parameters. In this paper, we introduce an effective hybrid architecture for super-resolution (SR) tasks, which leverages local features from CNNs and long-range dependencies captured by transformers to further improve the SR results. Specifically, our architecture comprises of transformer and convolution branches, and we substantially elevate the performance by mutually fusing two branches to complement each representation. Furthermore, we propose a cross-scale token attention module, which allows the transformer to efficiently exploit the informative relationships among tokens across different scales. Our proposed method achieves state-of-the-art SR results on numerous benchmark datasets.
Möbius Convolutions for Spherical CNNs
Jan 28, 2022
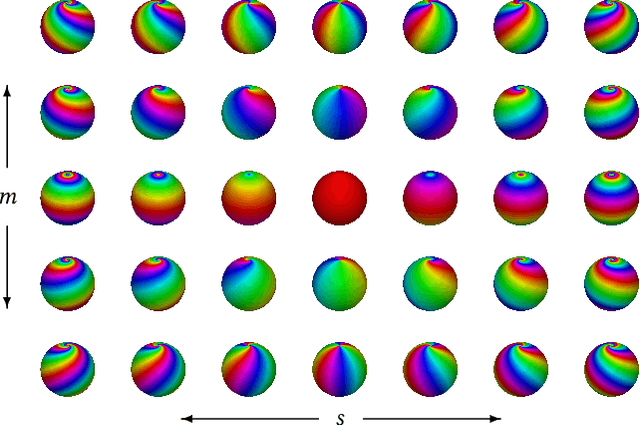
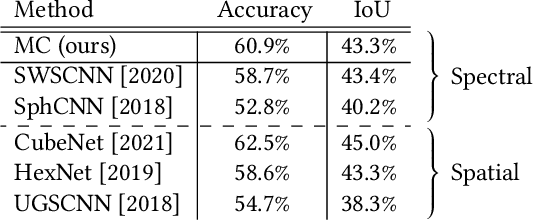
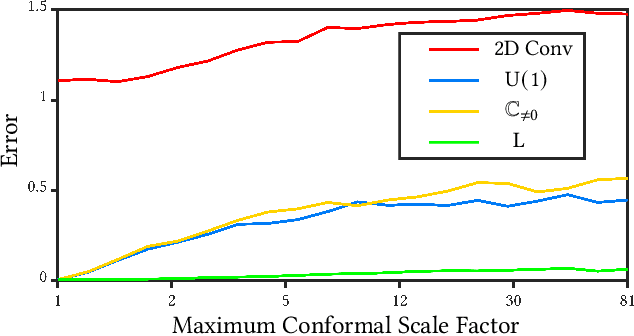
M\"{o}bius transformations play an important role in both geometry and spherical image processing -- they are the group of conformal automorphisms of 2D surfaces and the spherical equivalent of homographies. Here we present a novel, M\"{o}bius-equivariant spherical convolution operator which we call M\"{o}bius convolution, and with it, develop the foundations for M\"{o}bius-equivariant spherical CNNs. Our approach is based on a simple observation: to achieve equivariance, we only need to consider the lower-dimensional subgroup which transforms the positions of points as seen in the frames of their neighbors. To efficiently compute M\"{o}bius convolutions at scale we derive an approximation of the action of the transformations on spherical filters, allowing us to compute our convolutions in the spectral domain with the fast Spherical Harmonic Transform. The resulting framework is both flexible and descriptive, and we demonstrate its utility by achieving promising results in both shape classification and image segmentation tasks.
Transformers for 1D Signals in Parkinson's Disease Detection from Gait
Apr 01, 2022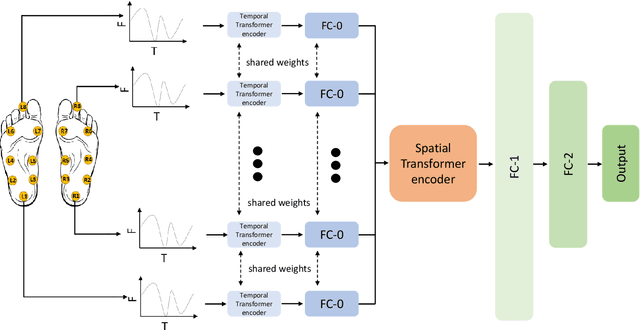
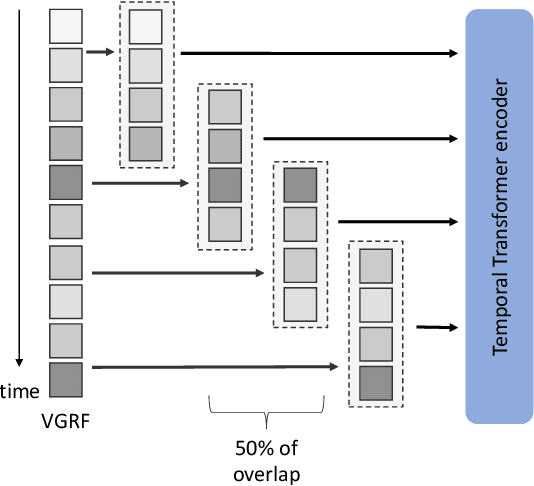
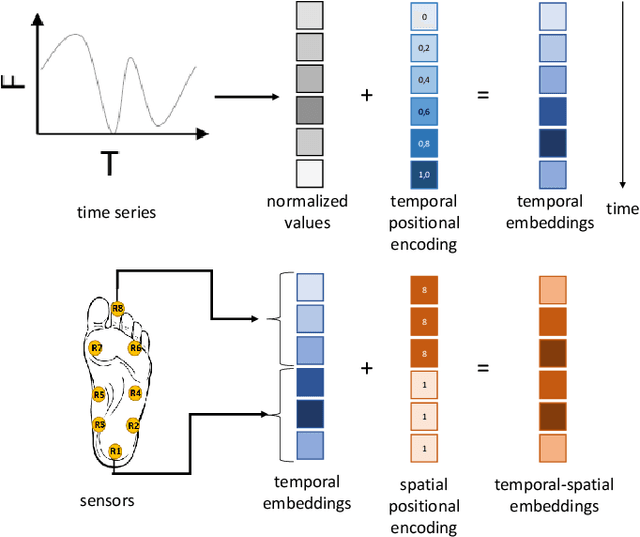
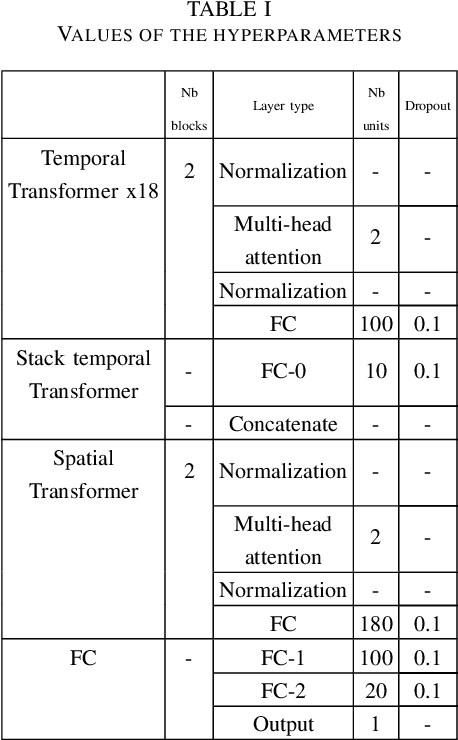
This paper focuses on the detection of Parkinson's disease based on the analysis of a patient's gait. The growing popularity and success of Transformer networks in natural language processing and image recognition motivated us to develop a novel method for this problem based on an automatic features extraction via Transformers. The use of Transformers in 1D signal is not really widespread yet, but we show in this paper that they are effective in extracting relevant features from 1D signals. As Transformers require a lot of memory, we decoupled temporal and spatial information to make the model smaller. Our architecture used temporal Transformers, dimension reduction layers to reduce the dimension of the data, a spatial Transformer, two fully connected layers and an output layer for the final prediction. Our model outperforms the current state-of-the-art algorithm with 95.2\% accuracy in distinguishing a Parkinsonian patient from a healthy one on the Physionet dataset. A key learning from this work is that Transformers allow for greater stability in results. The source code and pre-trained models are released in https://github.com/DucMinhDimitriNguyen/Transformers-for-1D-signals-in-Parkinson-s-disease-detection-from-gait.git
Fusing Local Similarities for Retrieval-based 3D Orientation Estimation of Unseen Objects
Mar 16, 2022
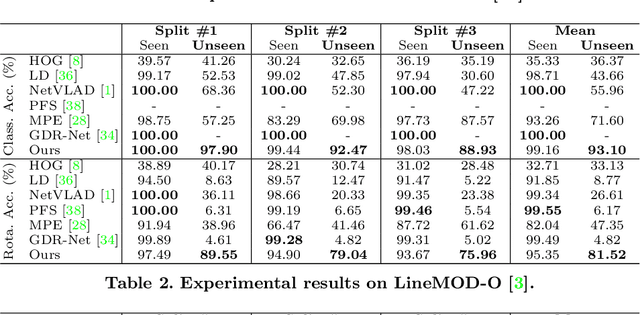
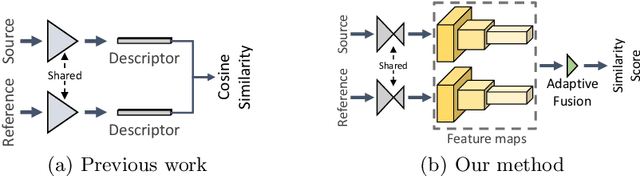
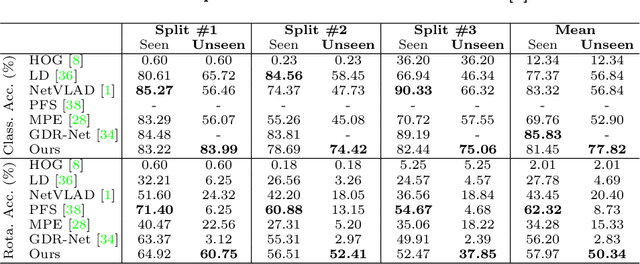
In this paper, we tackle the task of estimating the 3D orientation of previously-unseen objects from monocular images. This task contrasts with the one considered by most existing deep learning methods which typically assume that the testing objects have been observed during training. To handle the unseen objects, we follow a retrieval-based strategy and prevent the network from learning object-specific features by computing multi-scale local similarities between the query image and synthetically-generated reference images. We then introduce an adaptive fusion module that robustly aggregates the local similarities into a global similarity score of pairwise images. Furthermore, we speed up the retrieval process by developing a fast clustering-based retrieval strategy. Our experiments on the LineMOD, LineMOD-Occluded, and T-LESS datasets show that our method yields a significantly better generalization to unseen objects than previous works.
Cascade Convolutional Neural Network for Image Super-Resolution
Aug 25, 2020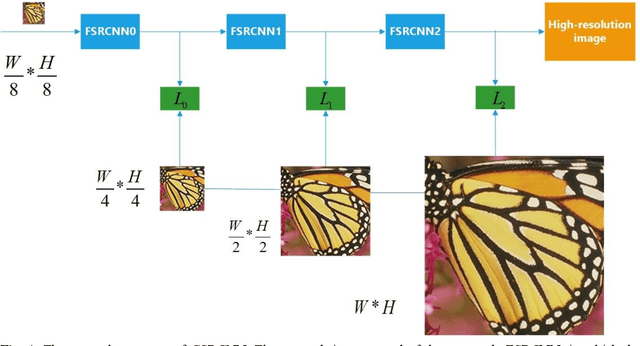
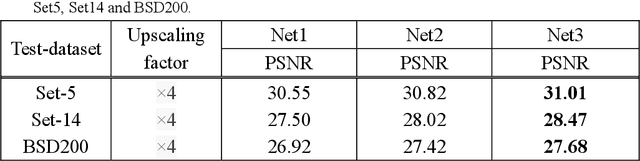
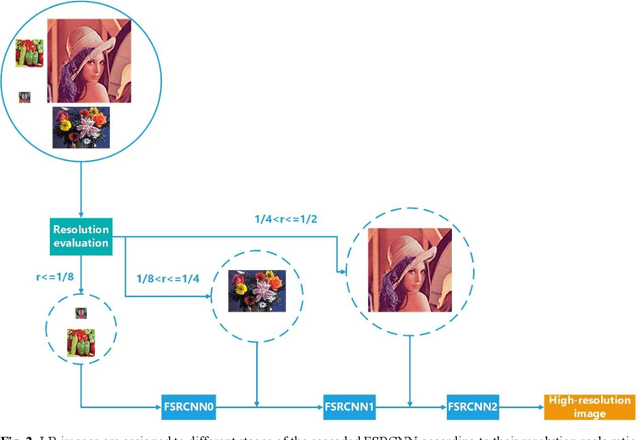
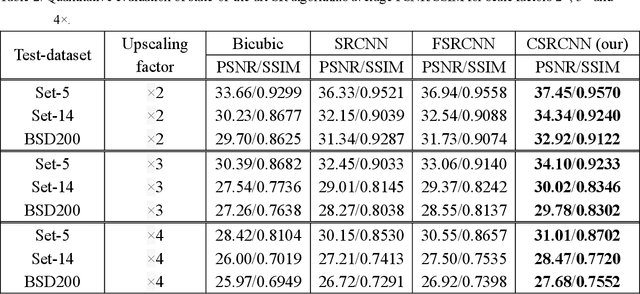
With the development of the super-resolution convolutional neural network (SRCNN), deep learning technique has been widely applied in the field of image super-resolution. Previous works mainly focus on optimizing the structure of SRCNN, which have been achieved well performance in speed and restoration quality for image super-resolution. However, most of these approaches only consider a specific scale image during the training process, while ignoring the relationship between different scales of images. Motivated by this concern, in this paper, we propose a cascaded convolution neural network for image super-resolution (CSRCNN), which includes three cascaded Fast SRCNNs and each Fast SRCNN can process a specific scale image. Images of different scales can be trained simultaneously and the learned network can make full use of the information resided in different scales of images. Extensive experiments show that our network can achieve well performance for image SR.
Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation
Mar 22, 2022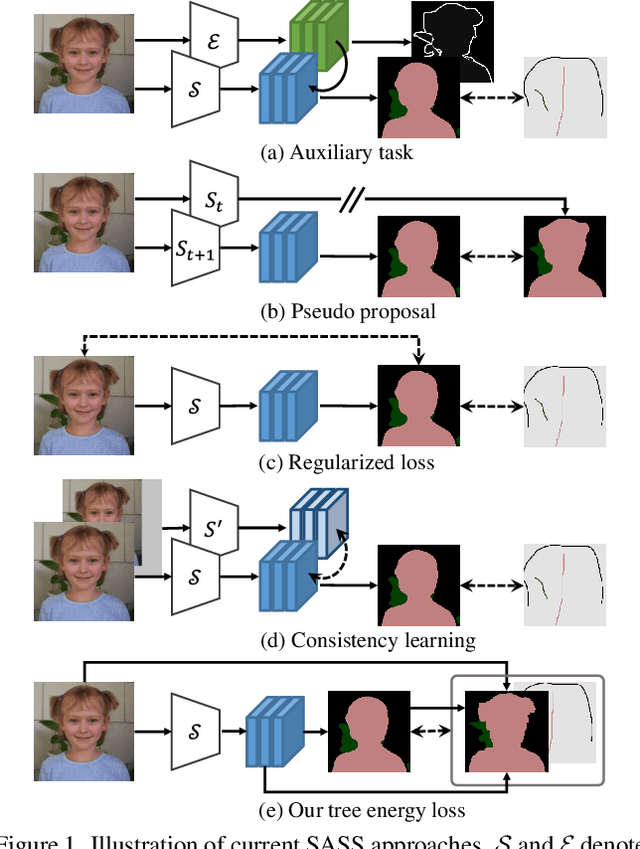
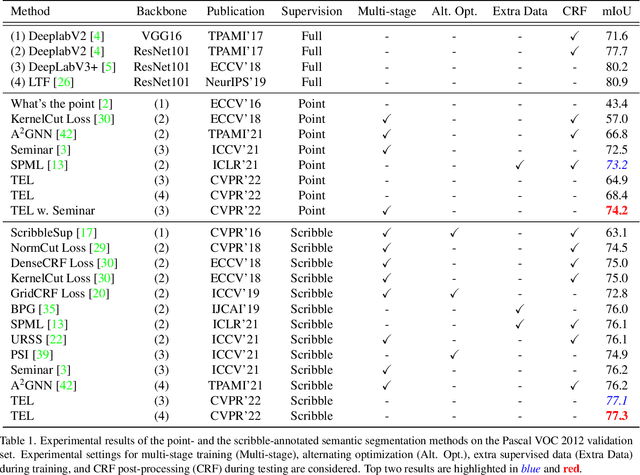

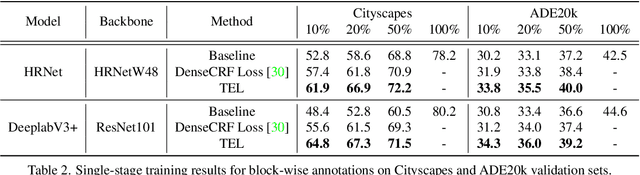
Sparsely annotated semantic segmentation (SASS) aims to train a segmentation network with coarse-grained (i.e., point-, scribble-, and block-wise) supervisions, where only a small proportion of pixels are labeled in each image. In this paper, we propose a novel tree energy loss for SASS by providing semantic guidance for unlabeled pixels. The tree energy loss represents images as minimum spanning trees to model both low-level and high-level pair-wise affinities. By sequentially applying these affinities to the network prediction, soft pseudo labels for unlabeled pixels are generated in a coarse-to-fine manner, achieving dynamic online self-training. The tree energy loss is effective and easy to be incorporated into existing frameworks by combining it with a traditional segmentation loss. Compared with previous SASS methods, our method requires no multistage training strategies, alternating optimization procedures, additional supervised data, or time-consuming post-processing while outperforming them in all SASS settings. Code is available at https://github.com/megvii-research/TreeEnergyLoss.
MobRecon: Mobile-Friendly Hand Mesh Reconstruction from Monocular Image
Dec 06, 2021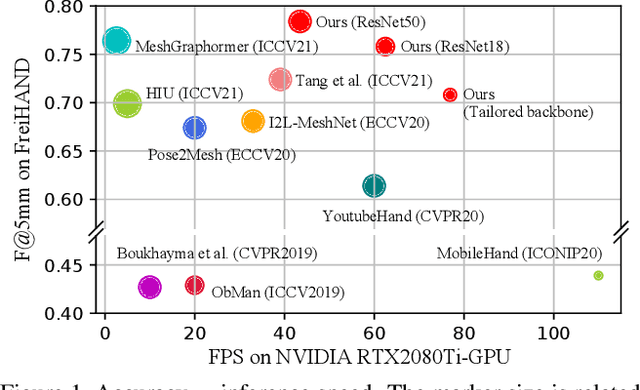
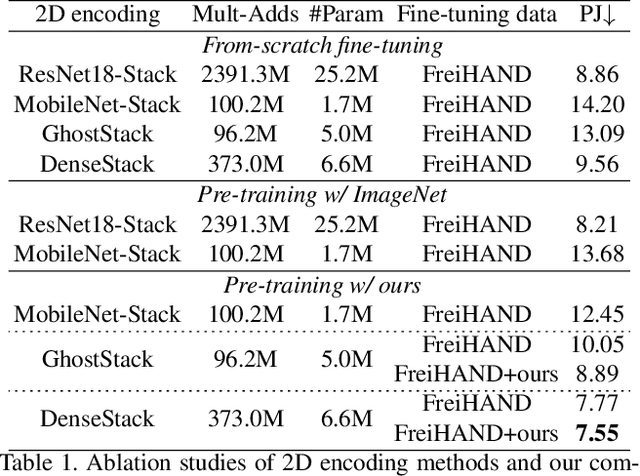


In this work, we propose a framework for single-view hand mesh reconstruction, which can simultaneously achieve high reconstruction accuracy, fast inference speed, and temporal coherence. Specifically, for 2D encoding, we propose lightweight yet effective stacked structures. Regarding 3D decoding, we provide an efficient graph operator, namely depth-separable spiral convolution. Moreover, we present a novel feature lifting module for bridging the gap between 2D and 3D representations. This module starts with a map-based position regression (MapReg) block to integrate the merits of both heatmap encoding and position regression paradigms to improve 2D accuracy and temporal coherence. Furthermore, MapReg is followed by pose pooling and pose-to-vertex lifting approaches, which transform 2D pose encodings to semantic features of 3D vertices. Overall, our hand reconstruction framework, called MobRecon, comprises affordable computational costs and miniature model size, which reaches a high inference speed of 83FPS on Apple A14 CPU. Extensive experiments on popular datasets such as FreiHAND, RHD, and HO3Dv2 demonstrate that our MobRecon achieves superior performance on reconstruction accuracy and temporal coherence. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.