 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GradViT: Gradient Inversion of Vision Transformers
Mar 28, 2022
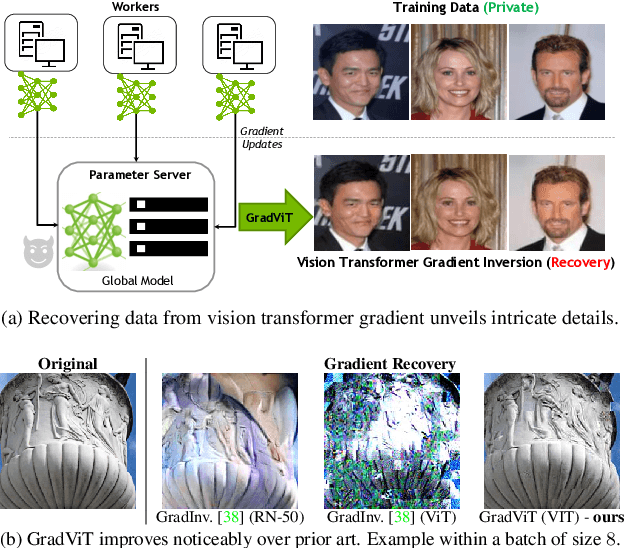
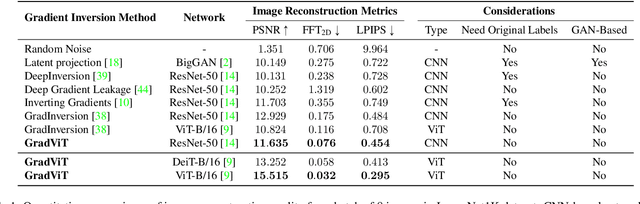
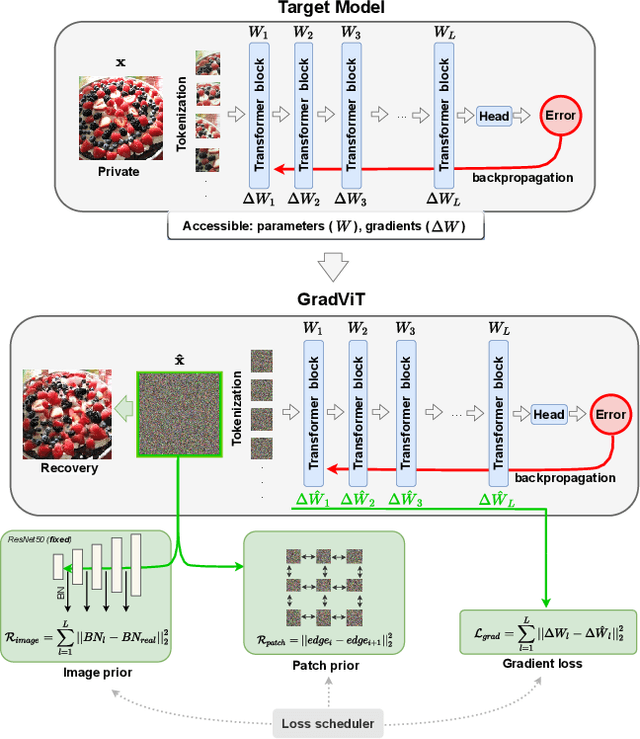
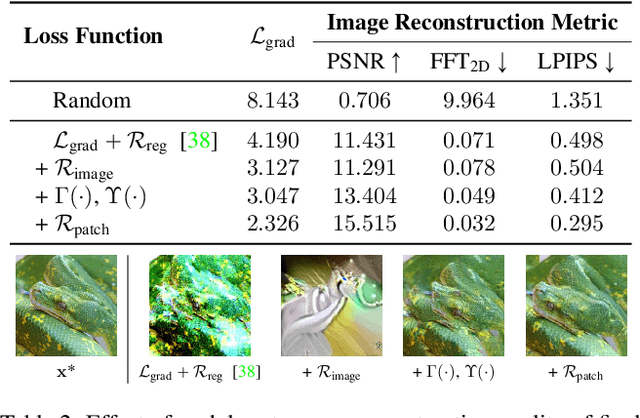
In this work we demonstrate the vulnerability of vision transformers (ViTs) to gradient-based inversion attacks. During this attack, the original data batch is reconstructed given model weights and the corresponding gradients. We introduce a method, named GradViT, that optimizes random noise into naturally looking images via an iterative process. The optimization objective consists of (i) a loss on matching the gradients, (ii) image prior in the form of distance to batch-normalization statistics of a pretrained CNN model, and (iii) a total variation regularization on patches to guide correct recovery locations. We propose a unique loss scheduling function to overcome local minima during optimization. We evaluate GadViT on ImageNet1K and MS-Celeb-1M datasets, and observe unprecedentedly high fidelity and closeness to the original (hidden) data. During the analysis we find that vision transformers are significantly more vulnerable than previously studied CNNs due to the presence of the attention mechanism. Our method demonstrates new state-of-the-art results for gradient inversion in both qualitative and quantitative metrics. Project page at https://gradvit.github.io/.
A Simple Yet Effective Pretraining Strategy for Graph Few-shot Learning
Apr 02, 2022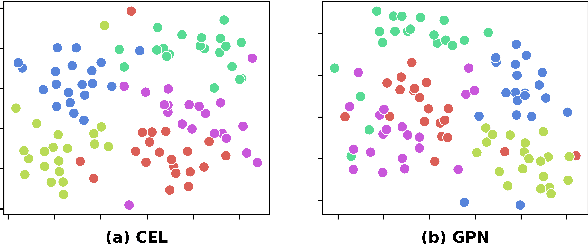
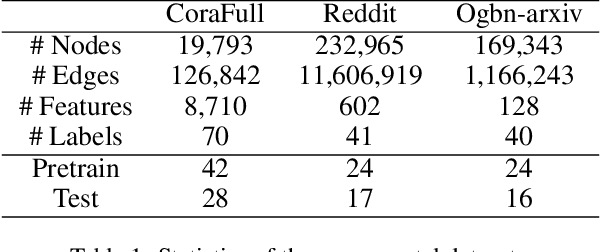
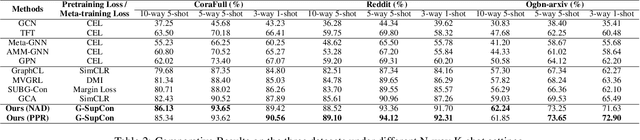
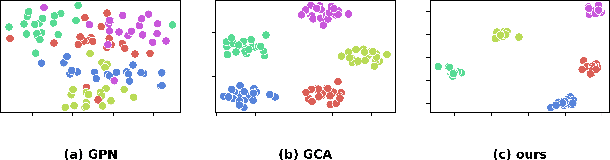
Recently, increasing attention has been devoted to the graph few-shot learning problem, where the target novel classes only contain a few labeled nodes. Among many existing endeavors, episodic meta-learning has become the most prevailing paradigm, and its episodic emulation of the test environment is believed to equip the graph neural network models with adaptability to novel node classes. However, in the image domain, recent results have shown that feature reuse is more likely to be the key of meta-learning to few-shot extrapolation. Based on such observation, in this work, we propose a simple transductive fine-tuning based framework as a new paradigm for graph few-shot learning. In the proposed paradigm, a graph encoder backbone is pretrained with base classes, and a simple linear classifier is fine-tuned by the few labeled samples and is tasked to classify the unlabeled ones. For pretraining, we propose a supervised contrastive learning framework with data augmentation strategies specific for few-shot node classification to improve the extrapolation of a GNN encoder. Finally, extensive experiments conducted on three benchmark datasets demonstrate the superior advantage of our framework over the state-of-the-art methods.
A Survey on Intrinsic Images: Delving Deep Into Lambert and Beyond
Dec 07, 2021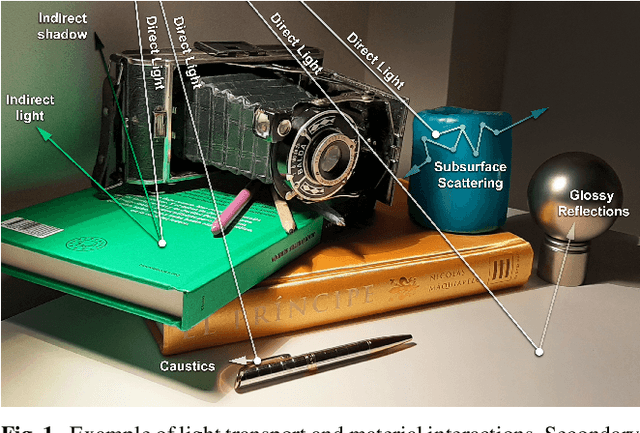
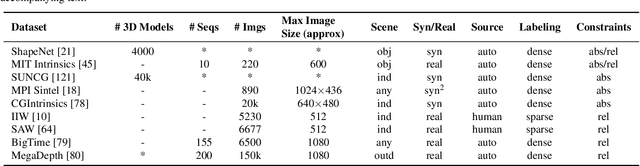
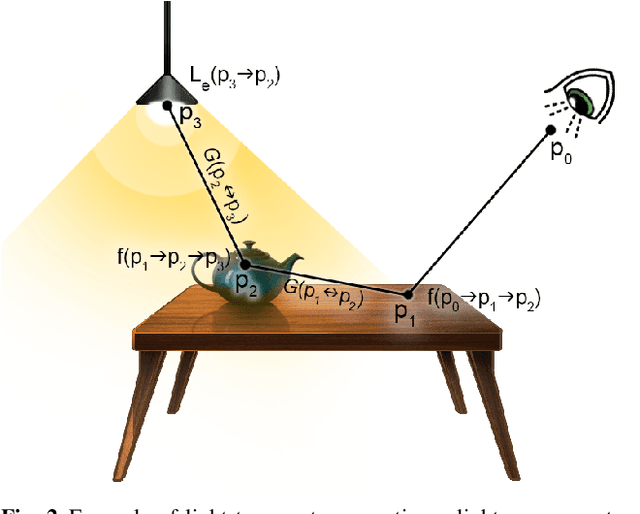
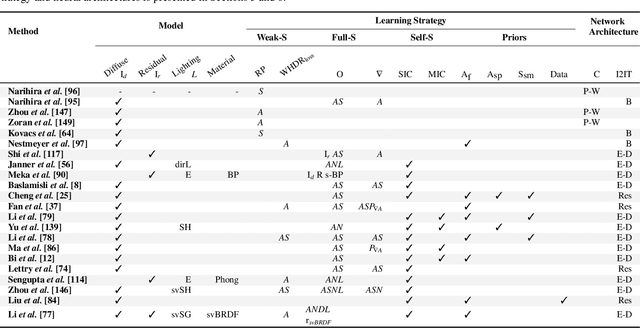
Intrinsic imaging or intrinsic image decomposition has traditionally been described as the problem of decomposing an image into two layers: a reflectance, the albedo invariant color of the material; and a shading, produced by the interaction between light and geometry. Deep learning techniques have been broadly applied in recent years to increase the accuracy of those separations. In this survey, we overview those results in context of well-known intrinsic image data sets and relevant metrics used in the literature, discussing their suitability to predict a desirable intrinsic image decomposition. Although the Lambertian assumption is still a foundational basis for many methods, we show that there is increasing awareness on the potential of more sophisticated physically-principled components of the image formation process, that is, optically accurate material models and geometry, and more complete inverse light transport estimations. We classify these methods in terms of the type of decomposition, considering the priors and models used, as well as the learning architecture and methodology driving the decomposition process. We also provide insights about future directions for research, given the recent advances in neural, inverse and differentiable rendering techniques.
FedDC: Federated Learning with Non-IID Data via Local Drift Decoupling and Correction
Mar 22, 2022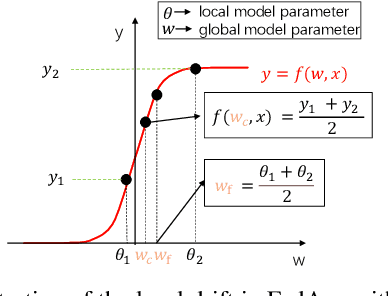
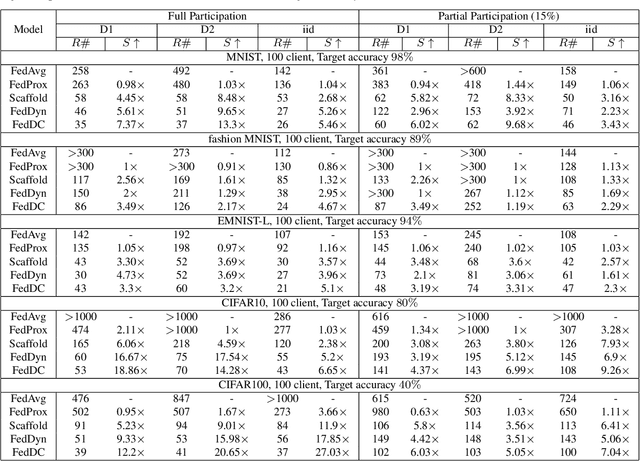
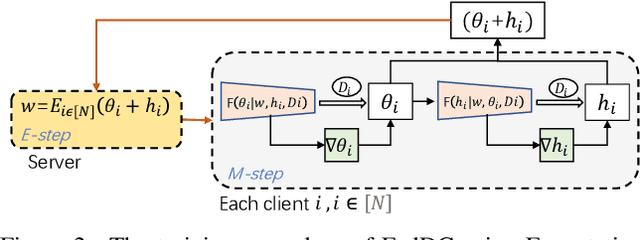
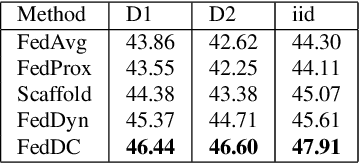
Federated learning (FL) allows multiple clients to collectively train a high-performance global model without sharing their private data. However, the key challenge in federated learning is that the clients have significant statistical heterogeneity among their local data distributions, which would cause inconsistent optimized local models on the client-side. To address this fundamental dilemma, we propose a novel federated learning algorithm with local drift decoupling and correction (FedDC). Our FedDC only introduces lightweight modifications in the local training phase, in which each client utilizes an auxiliary local drift variable to track the gap between the local model parameter and the global model parameters. The key idea of FedDC is to utilize this learned local drift variable to bridge the gap, i.e., conducting consistency in parameter-level. The experiment results and analysis demonstrate that FedDC yields expediting convergence and better performance on various image classification tasks, robust in partial participation settings, non-iid data, and heterogeneous clients.
Scale Invariant Semantic Segmentation with RGB-D Fusion
Apr 10, 2022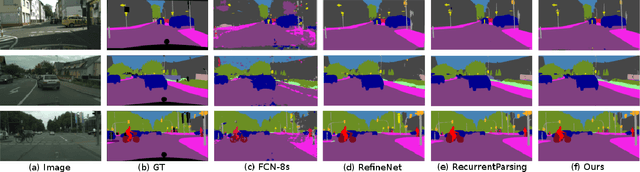
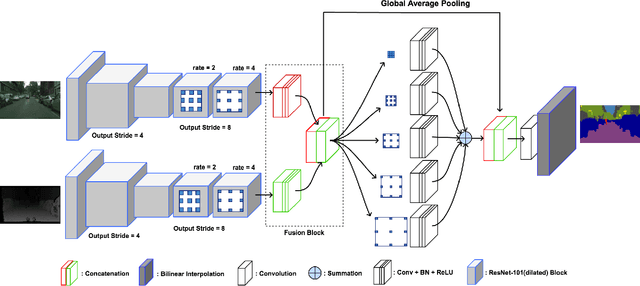
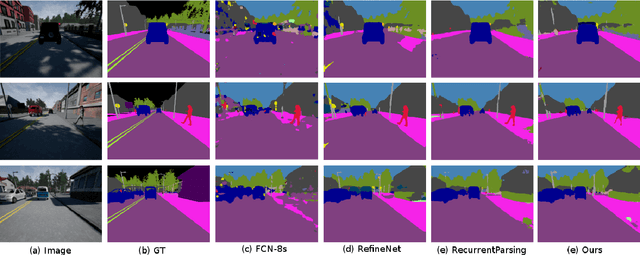

In this paper, we propose a neural network architecture for scale-invariant semantic segmentation using RGB-D images. We utilize depth information as an additional modality apart from color images only. Especially in an outdoor scene which consists of different scale objects due to the distance of the objects from the camera. The near distance objects consist of significantly more pixels than the far ones. We propose to incorporate depth information to the RGB data for pixel-wise semantic segmentation to address the different scale objects in an outdoor scene. We adapt to a well-known DeepLab-v2(ResNet-101) model as our RGB baseline. Depth images are passed separately as an additional input with a distinct branch. The intermediate feature maps of both color and depth image branch are fused using a novel fusion block. Our model is compact and can be easily applied to the other RGB model. We perform extensive qualitative and quantitative evaluation on a challenging dataset Cityscapes. The results obtained are comparable to the state-of-the-art. Additionally, we evaluated our model on a self-recorded real dataset. For the shake of extended evaluation of a driving scene with ground truth we generated a synthetic dataset using popular vehicle simulation project CARLA. The results obtained from the real and synthetic dataset shows the effectiveness of our approach.
Regularized Bilinear Discriminant Analysis for Multivariate Time Series Data
Feb 26, 2022
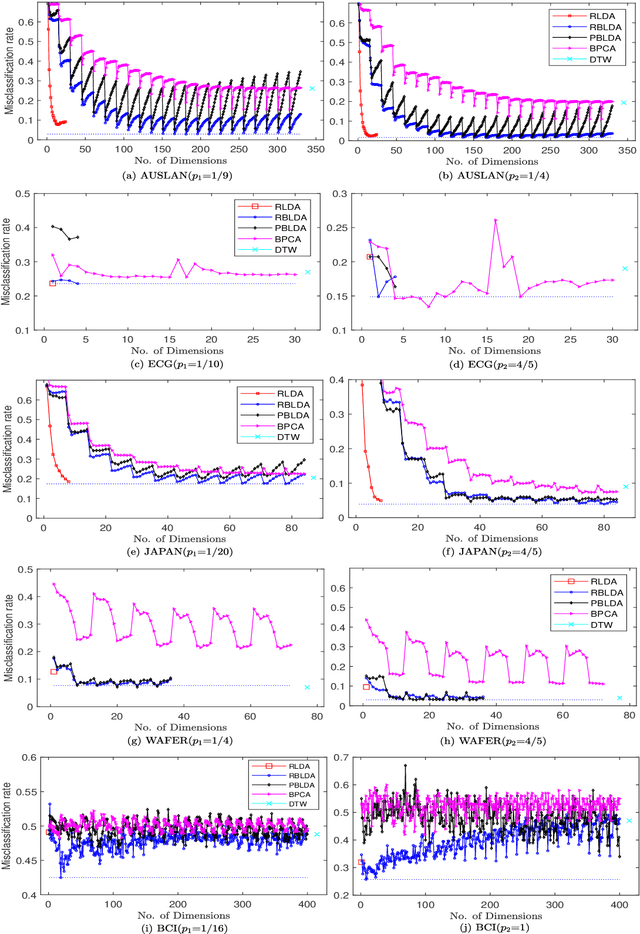
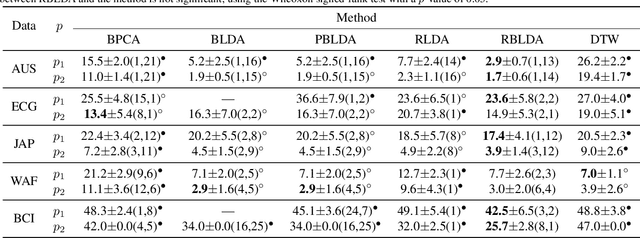
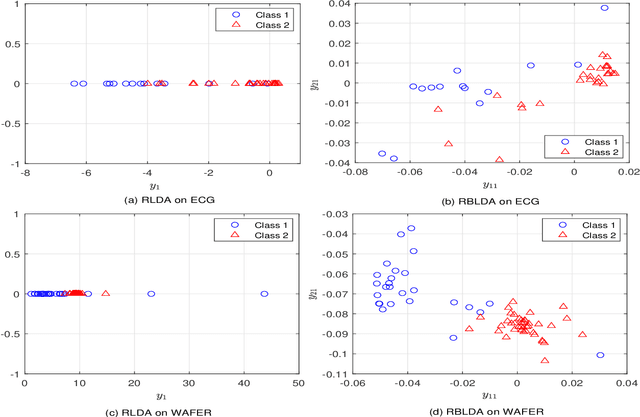
In recent years, the methods on matrix-based or bilinear discriminant analysis (BLDA) have received much attention. Despite their advantages, it has been reported that the traditional vector-based regularized LDA (RLDA) is still quite competitive and could outperform BLDA on some benchmark datasets. Nevertheless, it is also noted that this finding is mainly limited to image data. In this paper, we propose regularized BLDA (RBLDA) and further explore the comparison between RLDA and RBLDA on another type of matrix data, namely multivariate time series (MTS). Unlike image data, MTS typically consists of multiple variables measured at different time points. Although many methods for MTS data classification exist within the literature, there is relatively little work in exploring the matrix data structure of MTS data. Moreover, the existing BLDA can not be performed when one of its within-class matrices is singular. To address the two problems, we propose RBLDA for MTS data classification, where each of the two within-class matrices is regularized via one parameter. We develop an efficient implementation of RBLDA and an efficient model selection algorithm with which the cross validation procedure for RBLDA can be performed efficiently. Experiments on a number of real MTS data sets are conducted to evaluate the proposed algorithm and compare RBLDA with several closely related methods, including RLDA and BLDA. The results reveal that RBLDA achieves the best overall recognition performance and the proposed model selection algorithm is efficient; Moreover, RBLDA can produce better visualization of MTS data than RLDA.
Open-Domain, Content-based, Multi-modal Fact-checking of Out-of-Context Images via Online Resources
Nov 30, 2021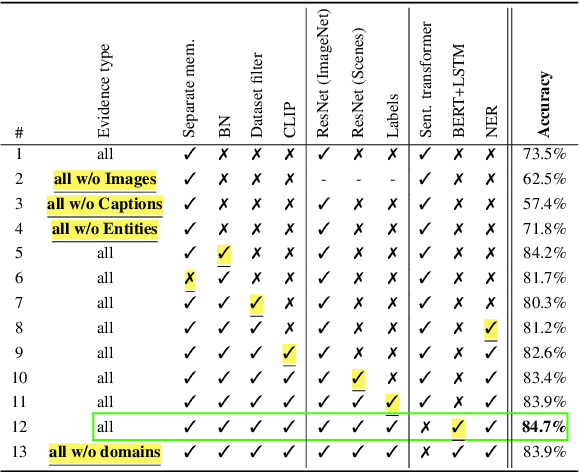
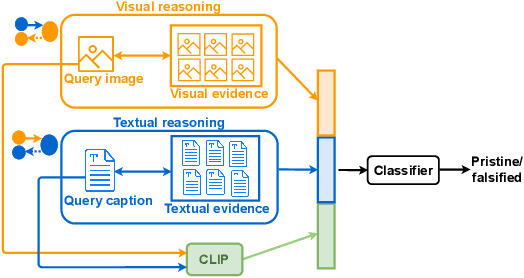
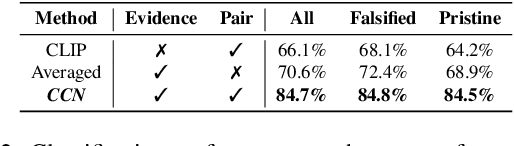
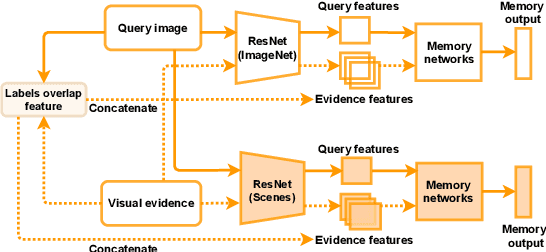
Misinformation is now a major problem due to its potential high risks to our core democratic and societal values and orders. Out-of-context misinformation is one of the easiest and effective ways used by adversaries to spread viral false stories. In this threat, a real image is re-purposed to support other narratives by misrepresenting its context and/or elements. The internet is being used as the go-to way to verify information using different sources and modalities. Our goal is an inspectable method that automates this time-consuming and reasoning-intensive process by fact-checking the image-caption pairing using Web evidence. To integrate evidence and cues from both modalities, we introduce the concept of 'multi-modal cycle-consistency check'; starting from the image/caption, we gather textual/visual evidence, which will be compared against the other paired caption/image, respectively. Moreover, we propose a novel architecture, Consistency-Checking Network (CCN), that mimics the layered human reasoning across the same and different modalities: the caption vs. textual evidence, the image vs. visual evidence, and the image vs. caption. Our work offers the first step and benchmark for open-domain, content-based, multi-modal fact-checking, and significantly outperforms previous baselines that did not leverage external evidence.
Glance and Focus Networks for Dynamic Visual Recognition
Jan 09, 2022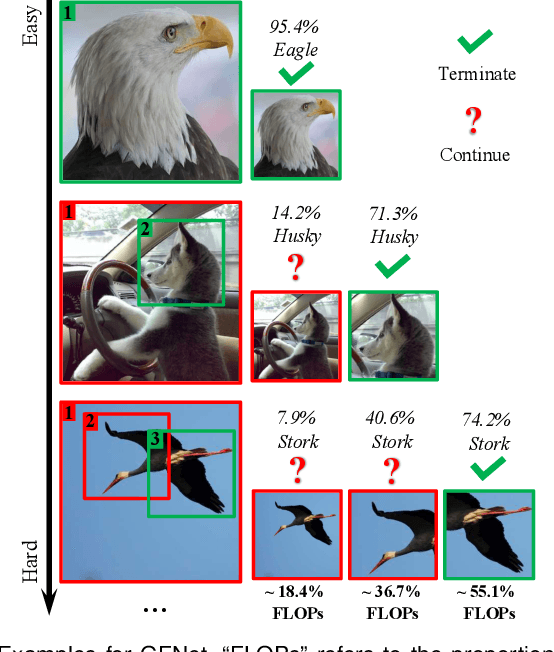
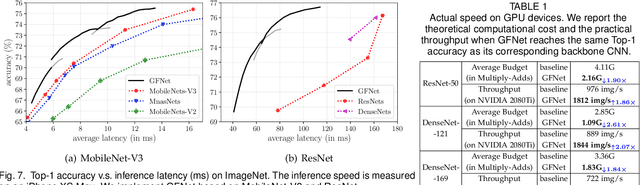
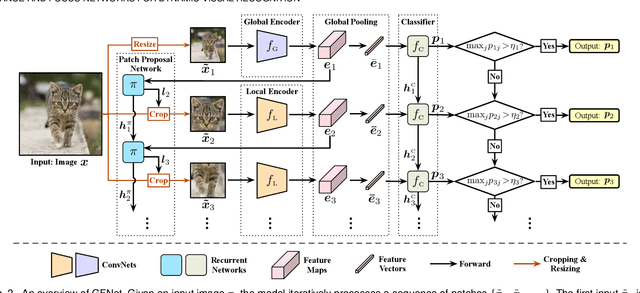
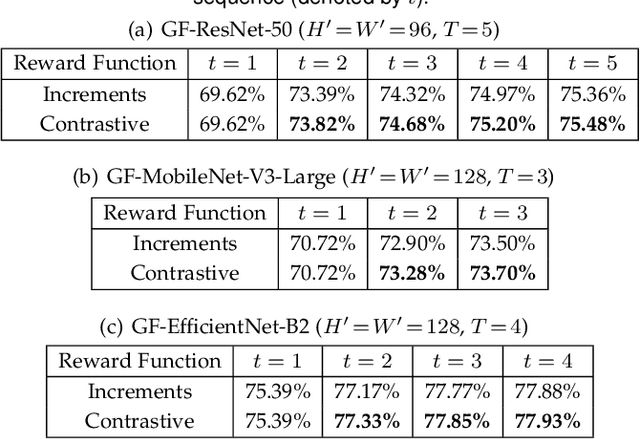
Spatial redundancy widely exists in visual recognition tasks, i.e., discriminative features in an image or video frame usually correspond to only a subset of pixels, while the remaining regions are irrelevant to the task at hand. Therefore, static models which process all the pixels with an equal amount of computation result in considerable redundancy in terms of time and space consumption. In this paper, we formulate the image recognition problem as a sequential coarse-to-fine feature learning process, mimicking the human visual system. Specifically, the proposed Glance and Focus Network (GFNet) first extracts a quick global representation of the input image at a low resolution scale, and then strategically attends to a series of salient (small) regions to learn finer features. The sequential process naturally facilitates adaptive inference at test time, as it can be terminated once the model is sufficiently confident about its prediction, avoiding further redundant computation. It is worth noting that the problem of locating discriminant regions in our model is formulated as a reinforcement learning task, thus requiring no additional manual annotations other than classification labels. GFNet is general and flexible as it is compatible with any off-the-shelf backbone models (such as MobileNets, EfficientNets and TSM), which can be conveniently deployed as the feature extractor. Extensive experiments on a variety of image classification and video recognition tasks and with various backbone models demonstrate the remarkable efficiency of our method. For example, it reduces the average latency of the highly efficient MobileNet-V3 on an iPhone XS Max by 1.3x without sacrificing accuracy. Code and pre-trained models are available at https://github.com/blackfeather-wang/GFNet-Pytorch.
Real-time Rendering for Integral Imaging Light Field Displays Based on a Voxel-Pixel Lookup Table
Jan 26, 2022A real-time elemental image array (EIA) generation method which does not sacrifice accuracy nor rely on high-performance hardware is developed, through raytracing and pre-stored voxel-pixel lookup table (LUT). Benefiting from both offline and online working flow, experiments verified the effectiveness.
A Benchmark and Baseline for Language-Driven Image Editing
Oct 05, 2020

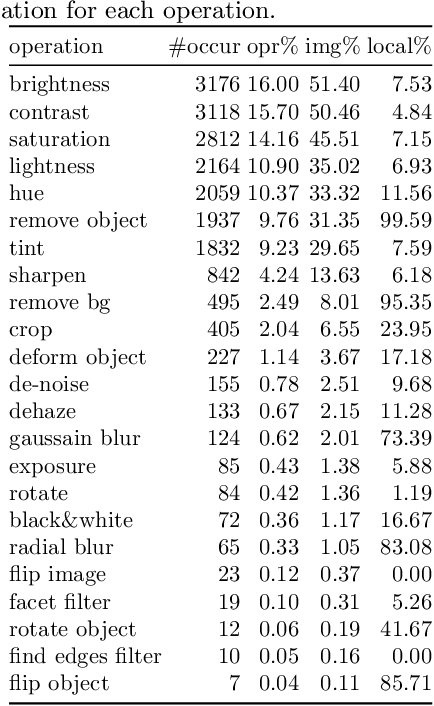
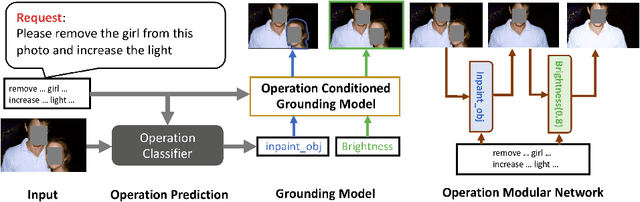
Language-driven image editing can significantly save the laborious image editing work and be friendly to the photography novice. However, most similar work can only deal with a specific image domain or can only do global retouching. To solve this new task, we first present a new language-driven image editing dataset that supports both local and global editing with editing operation and mask annotations. Besides, we also propose a baseline method that fully utilizes the annotation to solve this problem. Our new method treats each editing operation as a sub-module and can automatically predict operation parameters. Not only performing well on challenging user data, but such an approach is also highly interpretable. We believe our work, including both the benchmark and the baseline, will advance the image editing area towards a more general and free-form level.