 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SATA: Sparsity-Aware Training Accelerator for Spiking Neural Networks
Apr 11, 2022
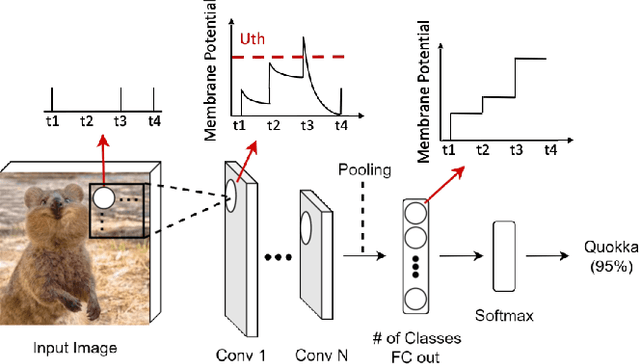
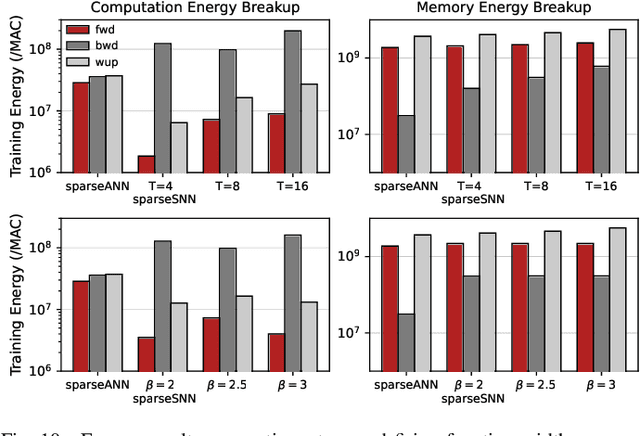
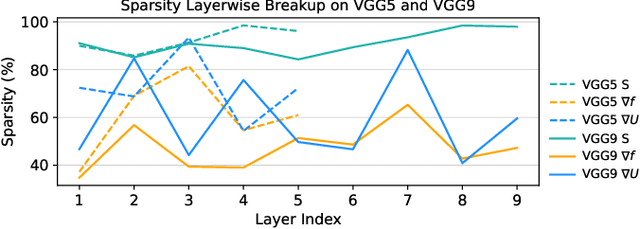
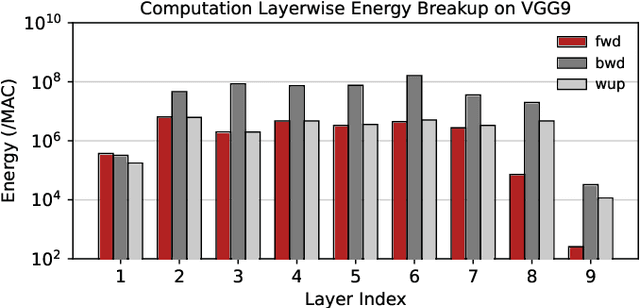
Spiking Neural Networks (SNNs) have gained huge attention as a potential energy-efficient alternative to conventional Artificial Neural Networks (ANNs) due to their inherent high-sparsity activation. Recently, SNNs with backpropagation through time (BPTT) have achieved a higher accuracy result on image recognition tasks compared to other SNN training algorithms. Despite the success on the algorithm perspective, prior works neglect the evaluation of the hardware energy overheads of BPTT, due to the lack of a hardware evaluation platform for SNN training algorithm design. Moreover, although SNNs have been long seen as an energy-efficient counterpart of ANNs, a quantitative comparison between the training cost of SNNs and ANNs is missing. To address the above-mentioned issues, in this work, we introduce SATA (Sparsity-Aware Training Accelerator), a BPTT-based training accelerator for SNNs. The proposed SATA provides a simple and re-configurable accelerator architecture for the general-purpose hardware evaluation platform, which makes it easier to analyze the training energy for SNN training algorithms. Based on SATA, we show quantitative analyses on the energy efficiency of SNN training and make a comparison between the training cost of SNNs and ANNs. The results show that SNNs consume $1.27\times$ more total energy with considering sparsity (spikes, gradient of firing function, and gradient of membrane potential) when compared to ANNs. We find that such high training energy cost is from time-repetitive convolution operations and data movements during backpropagation. Moreover, to guide the future SNN training algorithm design, we provide several observations on energy efficiency with respect to different SNN-specific training parameters.
ML Attack Models: Adversarial Attacks and Data Poisoning Attacks
Dec 06, 2021
Many state-of-the-art ML models have outperformed humans in various tasks such as image classification. With such outstanding performance, ML models are widely used today. However, the existence of adversarial attacks and data poisoning attacks really questions the robustness of ML models. For instance, Engstrom et al. demonstrated that state-of-the-art image classifiers could be easily fooled by a small rotation on an arbitrary image. As ML systems are being increasingly integrated into safety and security-sensitive applications, adversarial attacks and data poisoning attacks pose a considerable threat. This chapter focuses on the two broad and important areas of ML security: adversarial attacks and data poisoning attacks.
A Data-Efficient Deep Learning Training Strategy for Biomedical Ultrasound Imaging: Zone Training
Feb 01, 2022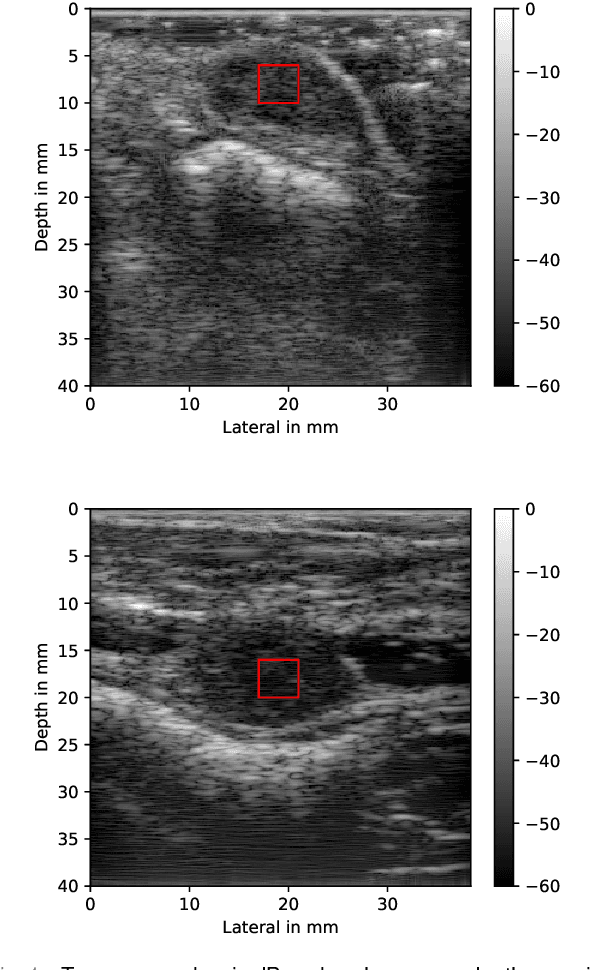
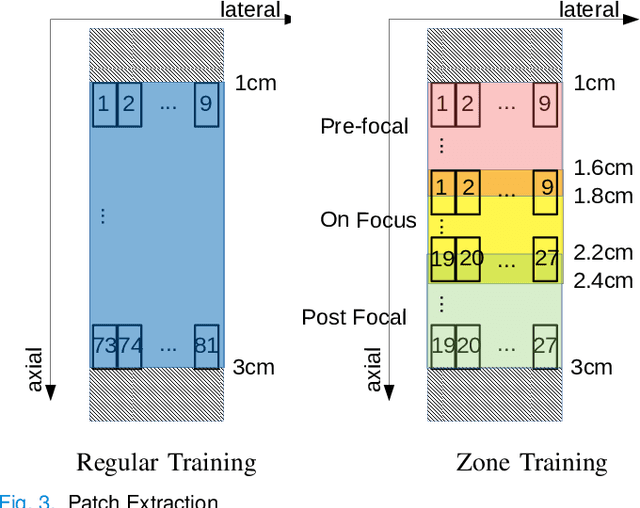
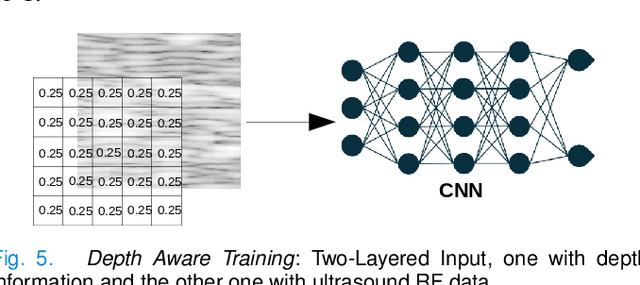
Deep learning (DL) powered biomedical ultrasound imaging is an emerging research field where researchers adapt the image analysis capabilities of DL algorithms to biomedical ultrasound imaging settings. A major roadblock to wider adoption of DL powered biomedical ultrasound imaging is that acquiring large and diverse datasets is expensive in clinical settings, which is a requirement for successful DL implementation. Hence, there is a constant need for developing data-efficient DL techniques to turn DL powered biomedical ultrasound imaging into reality. In this work, we develop a data-efficient deep learning training strategy, which we named \textit{Zone Training}. In \textit{Zone Training}, we propose to divide the complete field of view of an ultrasound image into multiple zones associated with different regions of a diffraction pattern and then, train separate DL networks for each zone. The main advantage of \textit{Zone Training} is that it requires less training data to achieve high accuracy. In this work, three different tissue-mimicking phantoms were classified by a DL network. The results demonstrated that \textit{Zone Training} required a factor of 2-5 less training data to achieve similar classification accuracies compared to a conventional training strategy.
Privacy Preserving for Medical Image Analysis via Non-Linear Deformation Proxy
Nov 26, 2020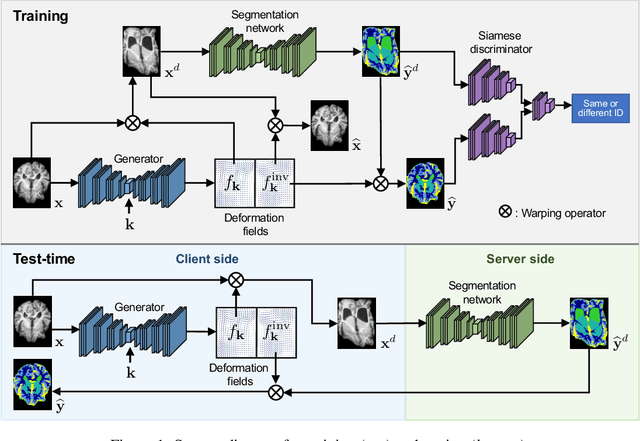
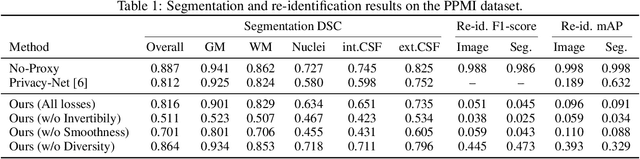
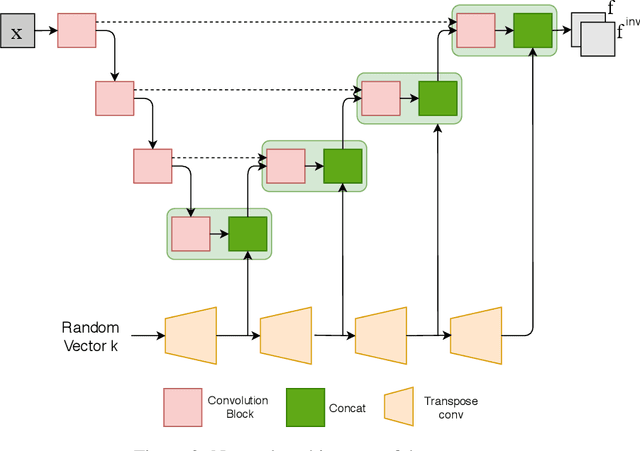
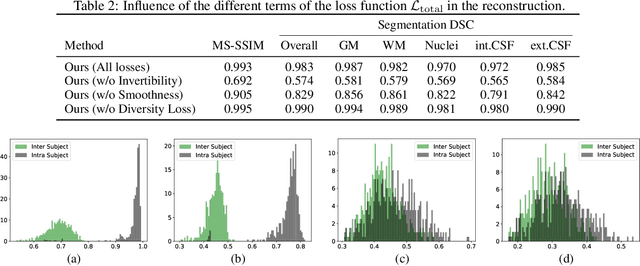
We propose a client-server system which allows for the analysis of multi-centric medical images while preserving patient identity. In our approach, the client protects the patient identity by applying a pseudo-random non-linear deformation to the input image. This results into a proxy image which is sent to the server for processing. The server then returns back the deformed processed image which the client reverts to a canonical form. Our system has three components: 1) a flow-field generator which produces a pseudo-random deformation function, 2) a Siamese discriminator that learns the patient identity from the processed image, 3) a medical image processing network that analyzes the content of the proxy images. The system is trained end-to-end in an adversarial manner. By fooling the discriminator, the flow-field generator learns to produce a bi-directional non-linear deformation which allows to remove and recover the identity of the subject from both the input image and output result. After end-to-end training, the flow-field generator is deployed on the client side and the segmentation network is deployed on the server side. The proposed method is validated on the task of MRI brain segmentation using images from two different datasets. Results show that the segmentation accuracy of our method is similar to a system trained on non-encoded images, while considerably reducing the ability to recover subject identity.
Uncertainty Estimation in Medical Image Denoising with Bayesian Deep Image Prior
Aug 20, 2020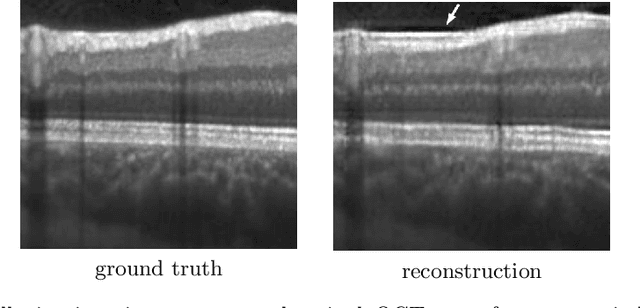

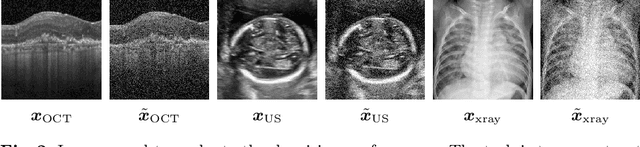

Uncertainty quantification in inverse medical imaging tasks with deep learning has received little attention. However, deep models trained on large data sets tend to hallucinate and create artifacts in the reconstructed output that are not anatomically present. We use a randomly initialized convolutional network as parameterization of the reconstructed image and perform gradient descent to match the observation, which is known as deep image prior. In this case, the reconstruction does not suffer from hallucinations as no prior training is performed. We extend this to a Bayesian approach with Monte Carlo dropout to quantify both aleatoric and epistemic uncertainty. The presented method is evaluated on the task of denoising different medical imaging modalities. The experimental results show that our approach yields well-calibrated uncertainty. That is, the predictive uncertainty correlates with the predictive error. This allows for reliable uncertainty estimates and can tackle the problem of hallucinations and artifacts in inverse medical imaging tasks.
The Spectral Bias of Polynomial Neural Networks
Feb 27, 2022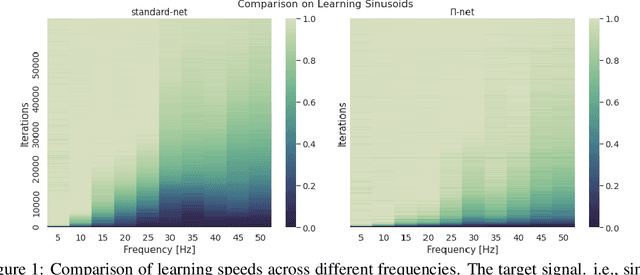
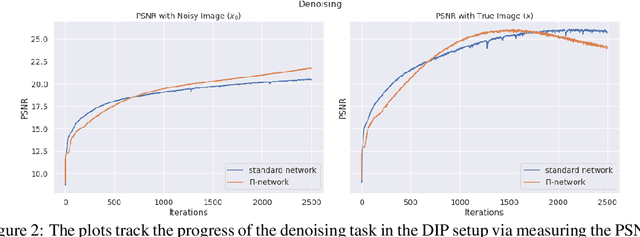
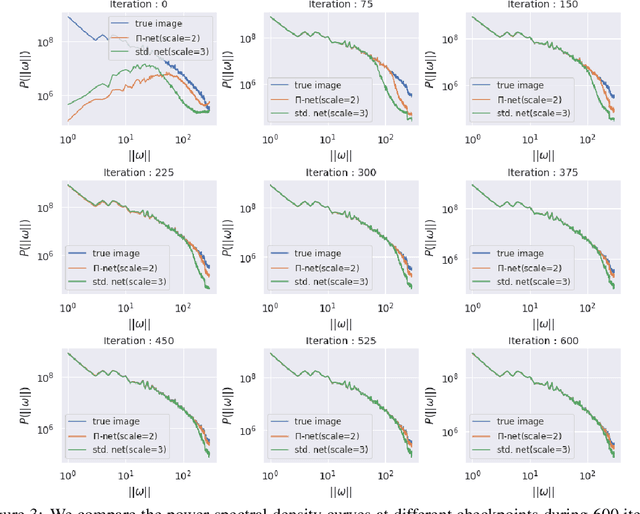
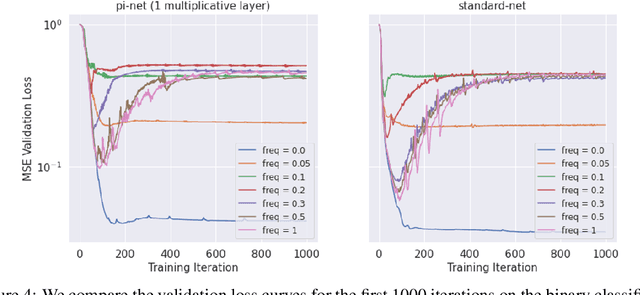
Polynomial neural networks (PNNs) have been recently shown to be particularly effective at image generation and face recognition, where high-frequency information is critical. Previous studies have revealed that neural networks demonstrate a $\textit{spectral bias}$ towards low-frequency functions, which yields faster learning of low-frequency components during training. Inspired by such studies, we conduct a spectral analysis of the Neural Tangent Kernel (NTK) of PNNs. We find that the $\Pi$-Net family, i.e., a recently proposed parametrization of PNNs, speeds up the learning of the higher frequencies. We verify the theoretical bias through extensive experiments. We expect our analysis to provide novel insights into designing architectures and learning frameworks by incorporating multiplicative interactions via polynomials.
Efficient divide-and-conquer registration of UAV and ground LiDAR point clouds through canopy shape context
Jan 27, 2022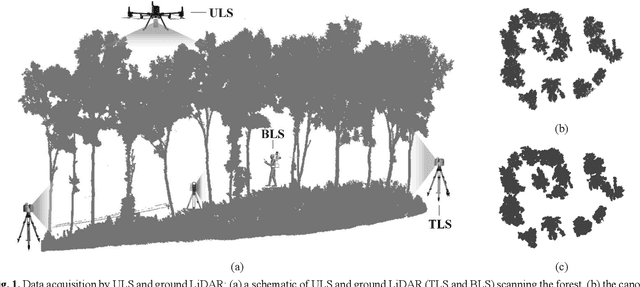
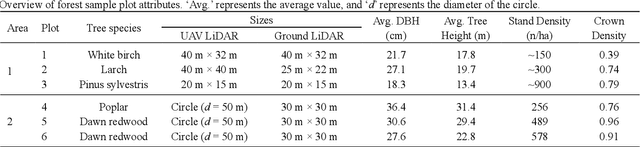
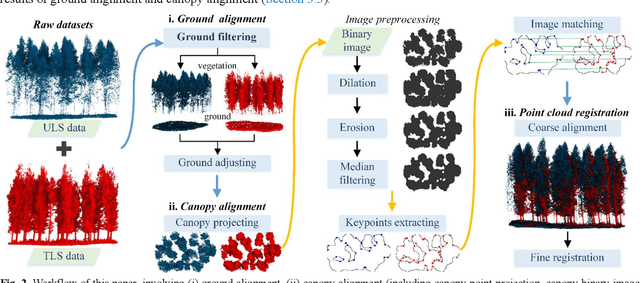
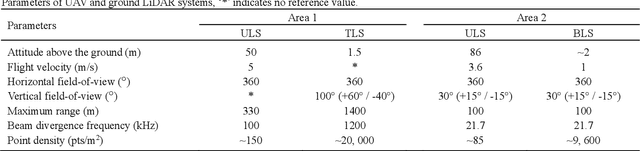
Registration of unmanned aerial vehicle laser scanning (ULS) and ground light detection and ranging (LiDAR) point clouds in forests is critical to create a detailed representation of a forest structure and an accurate inversion of forest parameters. However, forest occlusion poses challenges for marker-based registration methods, and some marker-free automated registration methods have low efficiency due to the process of object (e.g., tree, crown) segmentation. Therefore, we use a divide-and-conquer strategy and propose an automated and efficient method to register ULS and ground LiDAR point clouds in forests. Registration involves coarse alignment and fine registration, where the coarse alignment of point clouds is divided into vertical and horizontal alignment. The vertical alignment is achieved by ground alignment, which is achieved by the transformation relationship between normal vectors of the ground point cloud and the horizontal plane, and the horizontal alignment is achieved by canopy projection image matching. During image matching, vegetation points are first distinguished by the ground filtering algorithm, and then, vegetation points are projected onto the horizontal plane to obtain two binary images. To match the two images, a matching strategy is used based on canopy shape context features, which are described by a two-point congruent set and canopy overlap. Finally, we implement coarse alignment of ULS and ground LiDAR datasets by combining the results of ground alignment and image matching and finish fine registration. Also, the effectiveness, accuracy, and efficiency of the proposed method are demonstrated by field measurements of forest plots. Experimental results show that the ULS and ground LiDAR data in different plots are registered, of which the horizontal alignment errors are less than 0.02 m, and the average runtime of the proposed method is less than 1 second.
Effective Shortcut Technique for GAN
Jan 27, 2022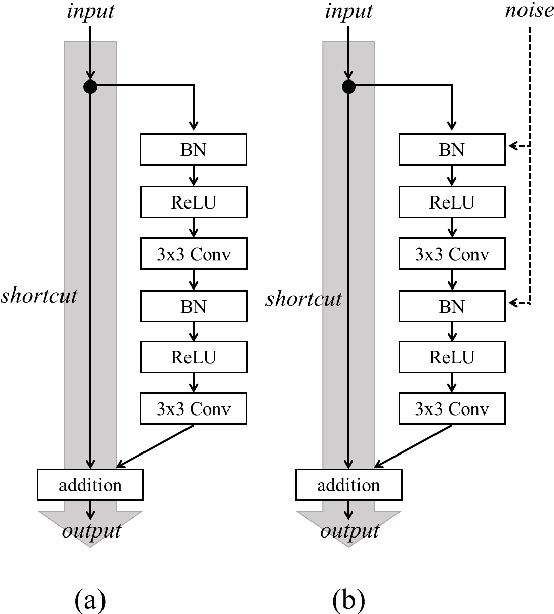
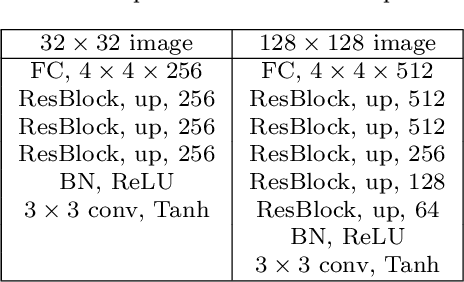
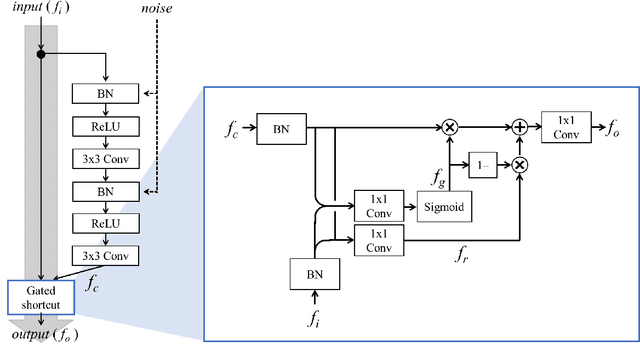
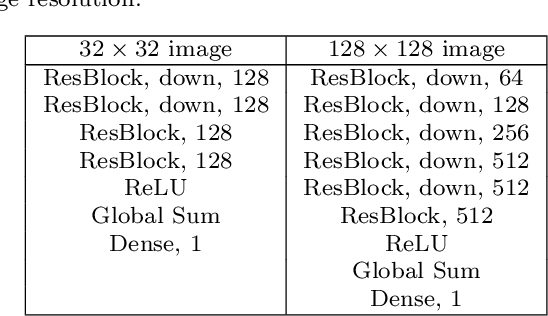
In recent years, generative adversarial network (GAN)-based image generation techniques design their generators by stacking up multiple residual blocks. The residual block generally contains a shortcut, \ie skip connection, which effectively supports information propagation in the network. In this paper, we propose a novel shortcut method, called the gated shortcut, which not only embraces the strength point of the residual block but also further boosts the GAN performance. More specifically, based on the gating mechanism, the proposed method leads the residual block to keep (or remove) information that is relevant (or irrelevant) to the image being generated. To demonstrate that the proposed method brings significant improvements in the GAN performance, this paper provides extensive experimental results on the various standard datasets such as CIFAR-10, CIFAR-100, LSUN, and tiny-ImageNet. Quantitative evaluations show that the gated shortcut achieves the impressive GAN performance in terms of Frechet inception distance (FID) and Inception score (IS). For instance, the proposed method improves the FID and IS scores on the tiny-ImageNet dataset from 35.13 to 27.90 and 20.23 to 23.42, respectively.
Learning Structral coherence Via Generative Adversarial Network for Single Image Super-Resolution
Jan 25, 2021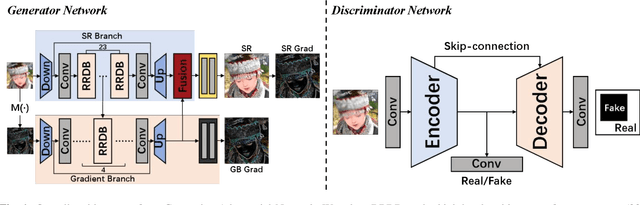
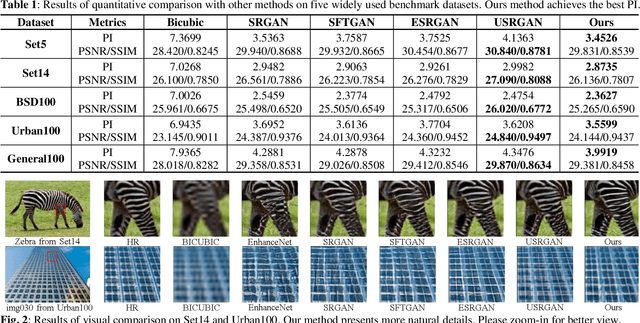
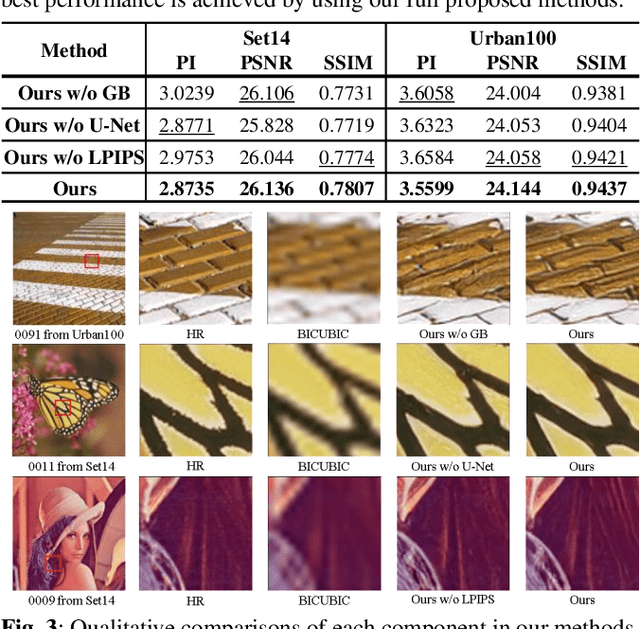
Among the major remaining challenges for single image super resolution (SISR) is the capacity to recover coherent images with global shapes and local details conforming to human vision system. Recent generative adversarial network (GAN) based SISR methods have yielded overall realistic SR images, however, there are always unpleasant textures accompanied with structural distortions in local regions. To target these issues, we introduce the gradient branch into the generator to preserve structural information by restoring high-resolution gradient maps in SR process. In addition, we utilize a U-net based discriminator to consider both the whole image and the detailed per-pixel authenticity, which could encourage the generator to maintain overall coherence of the reconstructed images. Moreover, we have studied objective functions and LPIPS perceptual loss is added to generate more realistic and natural details. Experimental results show that our proposed method outperforms state-of-the-art perceptual-driven SR methods in perception index (PI), and obtains more geometrically consistent and visually pleasing textures in natural image restoration.
A Critical Analysis of Patch Similarity Based Image Denoising Algorithms
Aug 25, 2020
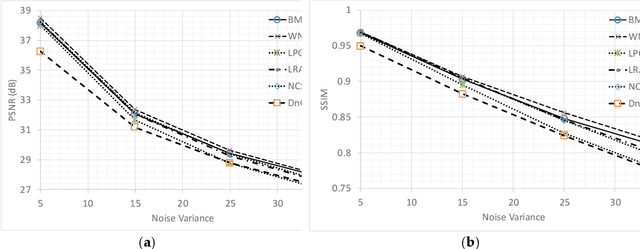
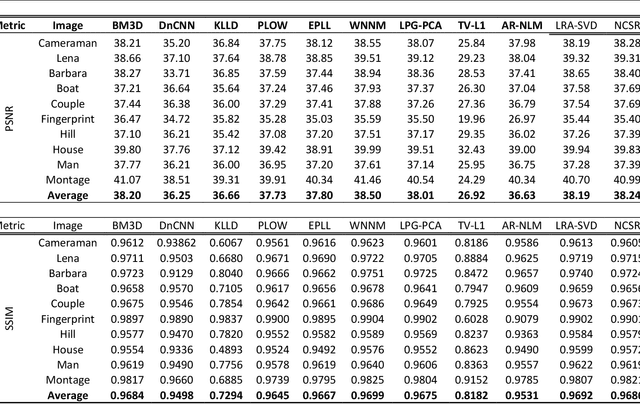
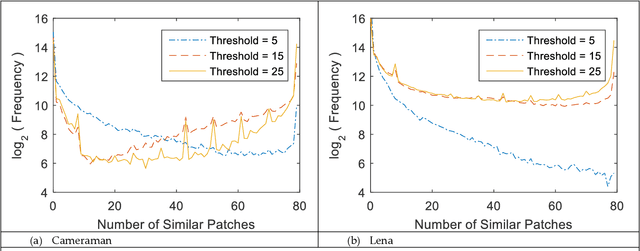
Image denoising is a classical signal processing problem that has received significant interest within the image processing community during the past two decades. Most of the algorithms for image denoising has focused on the paradigm of non-local similarity, where image blocks in the neighborhood that are similar, are collected to build a basis for reconstruction. Through rigorous experimentation, this paper reviews multiple aspects of image denoising algorithm development based on non-local similarity. Firstly, the concept of non-local similarity as a foundational quality that exists in natural images has not received adequate attention. Secondly, the image denoising algorithms that are developed are a combination of multiple building blocks, making comparison among them a tedious task. Finally, most of the work surrounding image denoising presents performance results based on Peak-Signal-to-Noise Ratio (PSNR) between a denoised image and a reference image (which is perturbed with Additive White Gaussian Noise). This paper starts with a statistical analysis on non-local similarity and its effectiveness under various noise levels, followed by a theoretical comparison of different state-of-the-art image denoising algorithms. Finally, we argue for a methodological overhaul to incorporate no-reference image quality measures and unprocessed images (raw) during performance evaluation of image denoising algorithms.