 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unifying Specialist Image Embedding into Universal Image Embedding
Mar 08, 2020
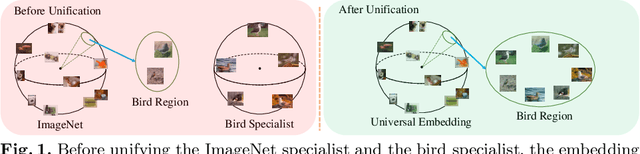
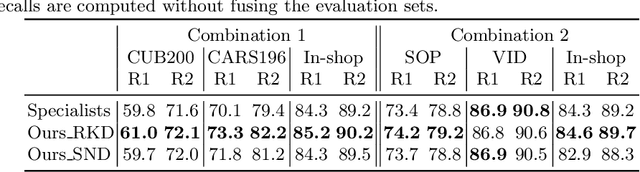
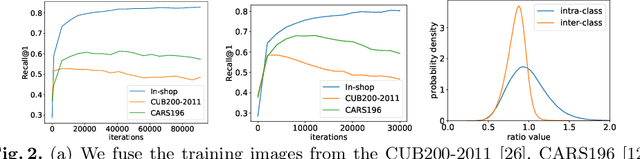
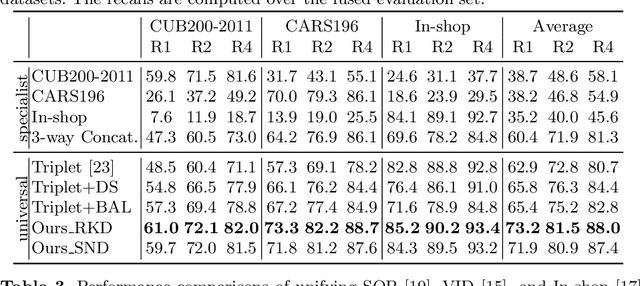
Deep image embedding provides a way to measure the semantic similarity of two images. It plays a central role in many applications such as image search, face verification, and zero-shot learning. It is desirable to have a universal deep embedding model applicable to various domains of images. However, existing methods mainly rely on training specialist embedding models each of which is applicable to images from a single domain. In this paper, we study an important but unexplored task: how to train a single universal image embedding model to match the performance of several specialists on each specialist's domain. Simply fusing the training data from multiple domains cannot solve this problem because some domains become overfitted sooner when trained together using existing methods. Therefore, we propose to distill the knowledge in multiple specialists into a universal embedding to solve this problem. In contrast to existing embedding distillation methods that distill the absolute distances between images, we transform the absolute distances between images into a probabilistic distribution and minimize the KL-divergence between the distributions of the specialists and the universal embedding. Using several public datasets, we validate that our proposed method accomplishes the goal of universal image embedding.
CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations
Dec 14, 2021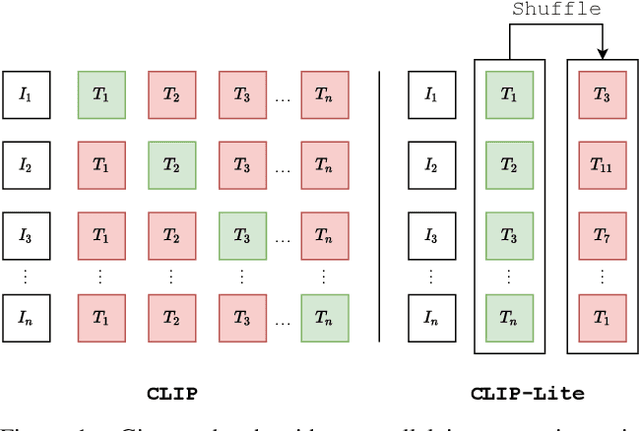
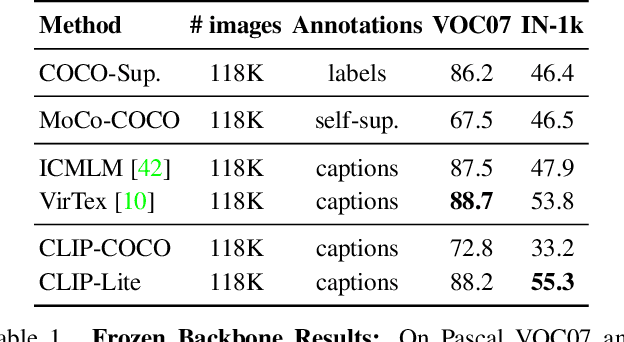
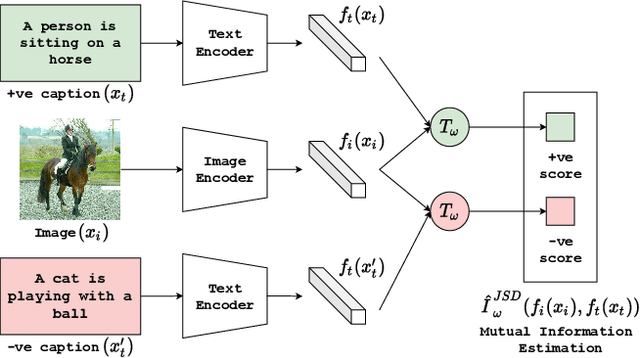
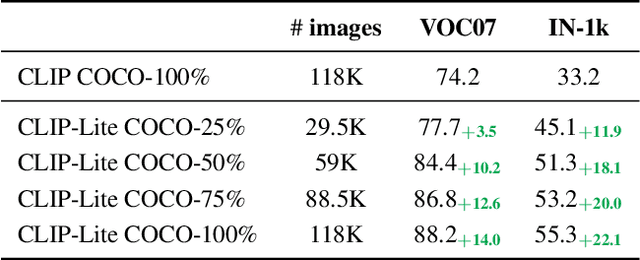
We propose CLIP-Lite, an information efficient method for visual representation learning by feature alignment with textual annotations. Compared to the previously proposed CLIP model, CLIP-Lite requires only one negative image-text sample pair for every positive image-text sample during the optimization of its contrastive learning objective. We accomplish this by taking advantage of an information efficient lower-bound to maximize the mutual information between the two input modalities. This allows CLIP-Lite to be trained with significantly reduced amounts of data and batch sizes while obtaining better performance than CLIP. We evaluate CLIP-Lite by pretraining on the COCO-Captions dataset and testing transfer learning to other datasets. CLIP-Lite obtains a +15.4% mAP absolute gain in performance on Pascal VOC classification, and a +22.1% top-1 accuracy gain on ImageNet, while being comparable or superior to other, more complex, text-supervised models. CLIP-Lite is also superior to CLIP on image and text retrieval, zero-shot classification, and visual grounding. Finally, by performing explicit image-text alignment during representation learning, we show that CLIP-Lite can leverage language semantics to encourage bias-free visual representations that can be used in downstream tasks.
RePre: Improving Self-Supervised Vision Transformer with Reconstructive Pre-training
Jan 19, 2022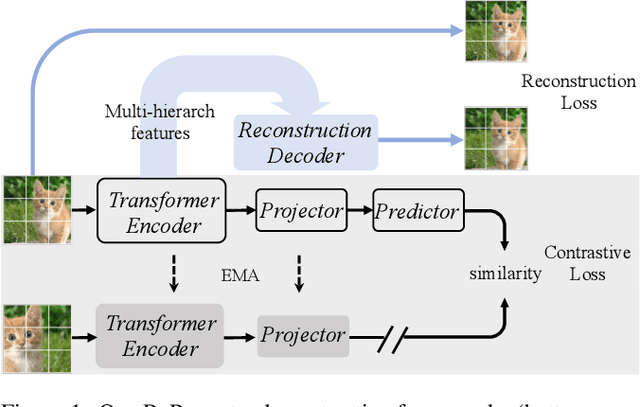
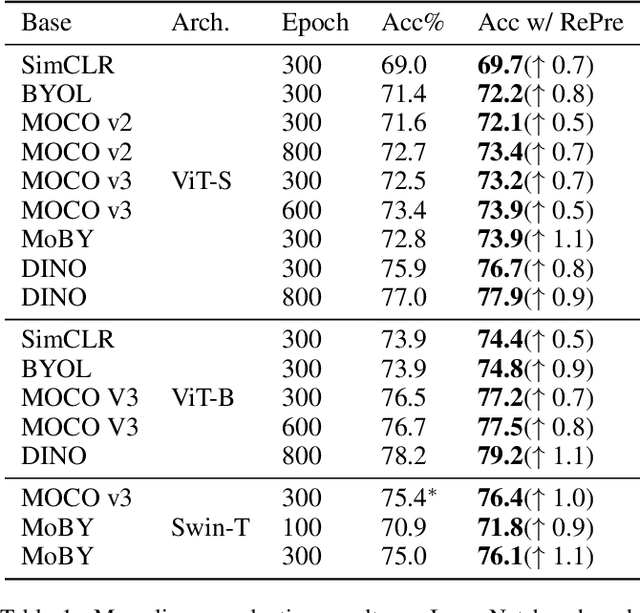
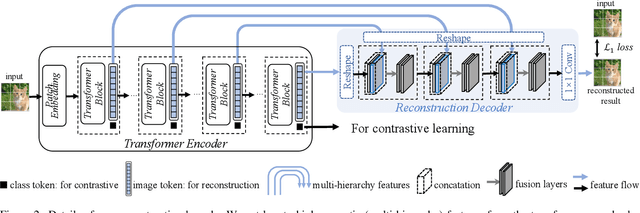
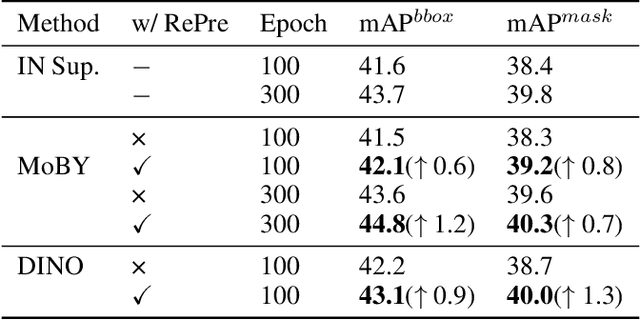
Recently, self-supervised vision transformers have attracted unprecedented attention for their impressive representation learning ability. However, the dominant method, contrastive learning, mainly relies on an instance discrimination pretext task, which learns a global understanding of the image. This paper incorporates local feature learning into self-supervised vision transformers via Reconstructive Pre-training (RePre). Our RePre extends contrastive frameworks by adding a branch for reconstructing raw image pixels in parallel with the existing contrastive objective. RePre is equipped with a lightweight convolution-based decoder that fuses the multi-hierarchy features from the transformer encoder. The multi-hierarchy features provide rich supervisions from low to high semantic information, which are crucial for our RePre. Our RePre brings decent improvements on various contrastive frameworks with different vision transformer architectures. Transfer performance in downstream tasks outperforms supervised pre-training and state-of-the-art (SOTA) self-supervised counterparts.
Machine Learning-Based Automated Thermal Comfort Prediction: Integration of Low-Cost Thermal and Visual Cameras for Higher Accuracy
Apr 14, 2022

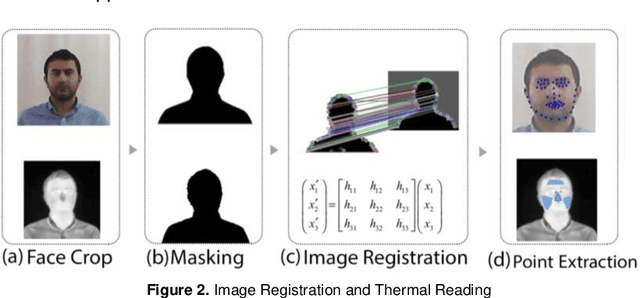
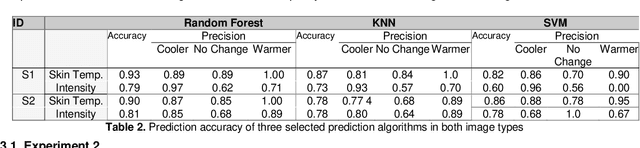
Recent research is trying to leverage occupants' demand in the building's control loop to consider individuals' well-being and the buildings' energy savings. To that end, a real-time feedback system is needed to provide data about occupants' comfort conditions that can be used to control the building's heating, cooling, and air conditioning (HVAC) system. The emergence of thermal imaging techniques provides an excellent opportunity for contactless data gathering with no interruption in occupant conditions and activities. There is increasing attention to infrared thermal camera usage in public buildings because of their non-invasive quality in reading the human skin temperature. However, the state-of-the-art methods need additional modifications to become more reliable. To capitalize potentials and address some existing limitations, new solutions are required to bring a more holistic view toward non-intrusive thermal scanning by leveraging the benefit of machine learning and image processing. This research implements an automated approach to collect and register simultaneous thermal and visual images and read the facial temperature in different regions. This paper also presents two additional investigations. First, through utilizing IButton wearable thermal sensors on the forehead area, we investigate the reliability of an in-expensive thermal camera (FLIR Lepton) in reading the skin temperature. Second, by studying the false-color version of thermal images, we look into the possibility of non-radiometric thermal images for predicting personalized thermal comfort. The results shows the strong performance of Random Forest and K-Nearest Neighbor prediction algorithms in predicting personalized thermal comfort. In addition, we have found that non-radiometric images can also indicate thermal comfort when the algorithm is trained with larger amounts of data.
Condensing a Sequence to One Informative Frame for Video Recognition
Jan 11, 2022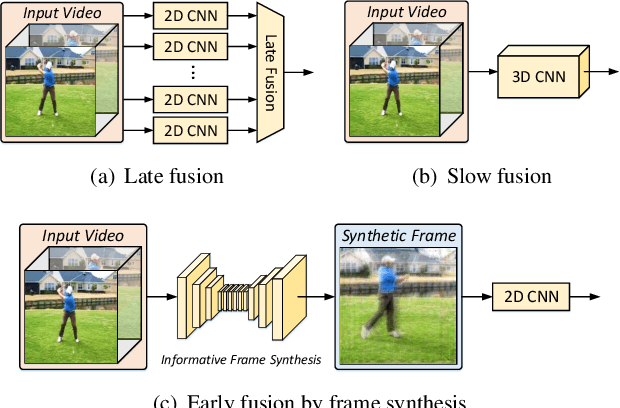
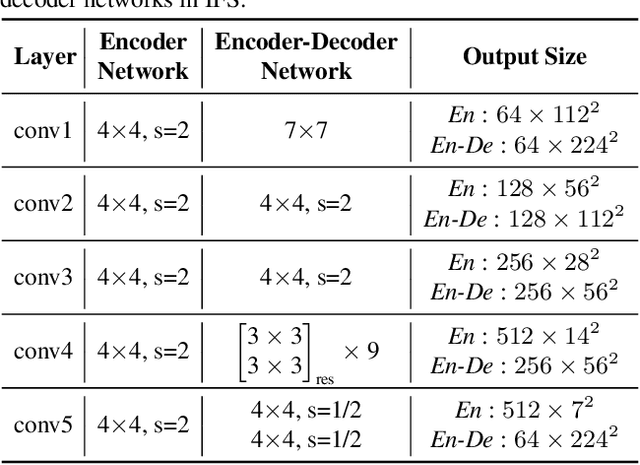
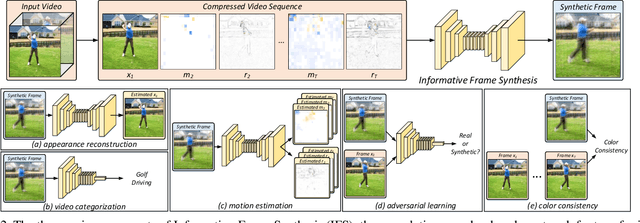
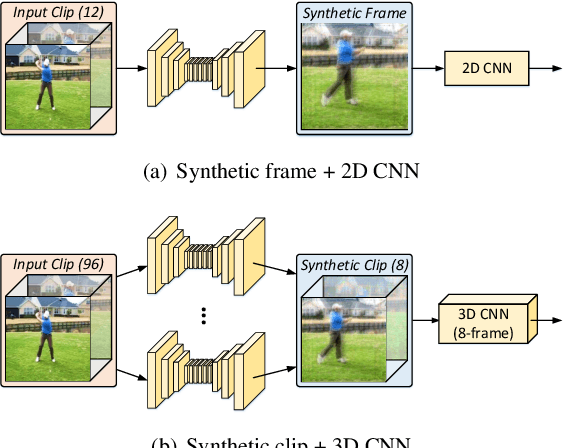
Video is complex due to large variations in motion and rich content in fine-grained visual details. Abstracting useful information from such information-intensive media requires exhaustive computing resources. This paper studies a two-step alternative that first condenses the video sequence to an informative "frame" and then exploits off-the-shelf image recognition system on the synthetic frame. A valid question is how to define "useful information" and then distill it from a video sequence down to one synthetic frame. This paper presents a novel Informative Frame Synthesis (IFS) architecture that incorporates three objective tasks, i.e., appearance reconstruction, video categorization, motion estimation, and two regularizers, i.e., adversarial learning, color consistency. Each task equips the synthetic frame with one ability, while each regularizer enhances its visual quality. With these, by jointly learning the frame synthesis in an end-to-end manner, the generated frame is expected to encapsulate the required spatio-temporal information useful for video analysis. Extensive experiments are conducted on the large-scale Kinetics dataset. When comparing to baseline methods that map video sequence to a single image, IFS shows superior performance. More remarkably, IFS consistently demonstrates evident improvements on image-based 2D networks and clip-based 3D networks, and achieves comparable performance with the state-of-the-art methods with less computational cost.
Towards End-to-End In-Image Neural Machine Translation
Oct 20, 2020

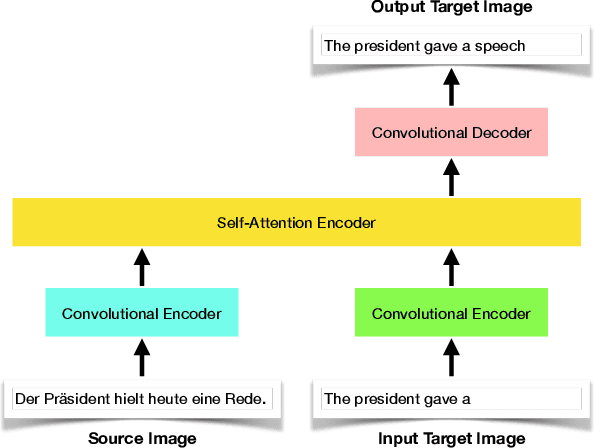
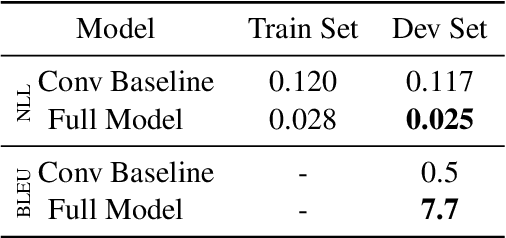
In this paper, we offer a preliminary investigation into the task of in-image machine translation: transforming an image containing text in one language into an image containing the same text in another language. We propose an end-to-end neural model for this task inspired by recent approaches to neural machine translation, and demonstrate promising initial results based purely on pixel-level supervision. We then offer a quantitative and qualitative evaluation of our system outputs and discuss some common failure modes. Finally, we conclude with directions for future work.
Temporal Difference Learning for Model Predictive Control
Mar 09, 2022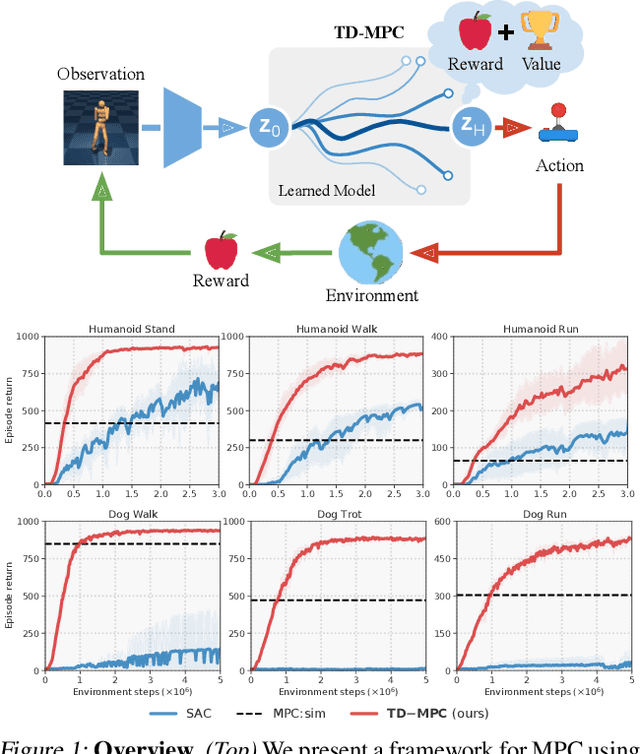

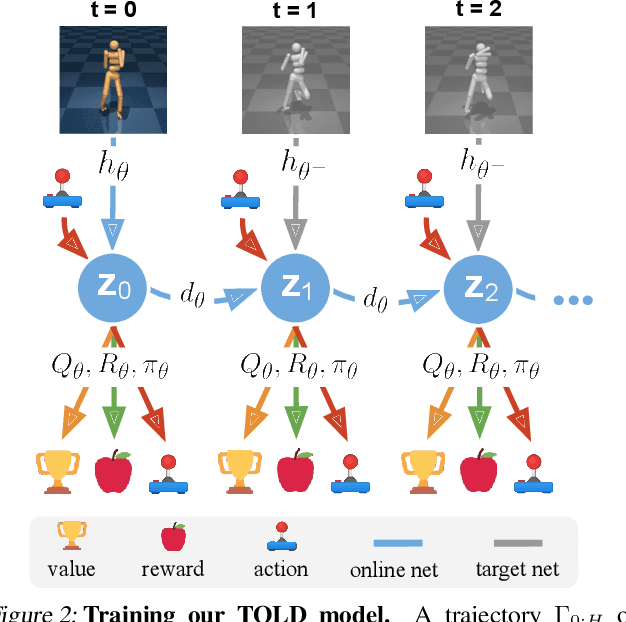
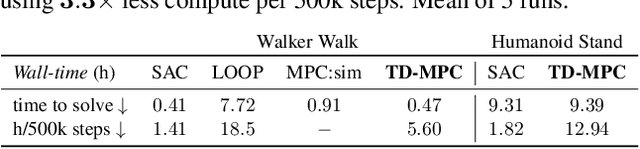
Data-driven model predictive control has two key advantages over model-free methods: a potential for improved sample efficiency through model learning, and better performance as computational budget for planning increases. However, it is both costly to plan over long horizons and challenging to obtain an accurate model of the environment. In this work, we combine the strengths of model-free and model-based methods. We use a learned task-oriented latent dynamics model for local trajectory optimization over a short horizon, and use a learned terminal value function to estimate long-term return, both of which are learned jointly by temporal difference learning. Our method, TD-MPC, achieves superior sample efficiency and asymptotic performance over prior work on both state and image-based continuous control tasks from DMControl and Meta-World. Code and video results are available at https://nicklashansen.github.io/td-mpc.
General framework for reversible data hiding in encrypted image by reserving room before encryption
Mar 28, 2021



In this paper a general framework to adopt different predictors for reversible data hiding in encrypted image is presented. We propose innovative predictors that contribute more significantly than conventional ones results in accomplishing more payload. Reserving room before encryption (RRBE) is designated in the proposed scheme to make possible attaining high embedding capacity. In RRBE procedure, pre-processing is allowed before image encryption. In our scheme, pre-processing comprises of three main steps of computing prediction-errors, blocking and labeling of the errors. By blocking we obviate the need for lossless compression to when content-owner is not enthusiastic. Lossless compression is employed in recent state of the art schemes to improve payload. We surpass prior arts exploiting more proper predictors, more efficient labeling procedure and blocking
A Data-Efficient Deep Learning Training Strategy for Biomedical Ultrasound Imaging: Zone Training
Feb 01, 2022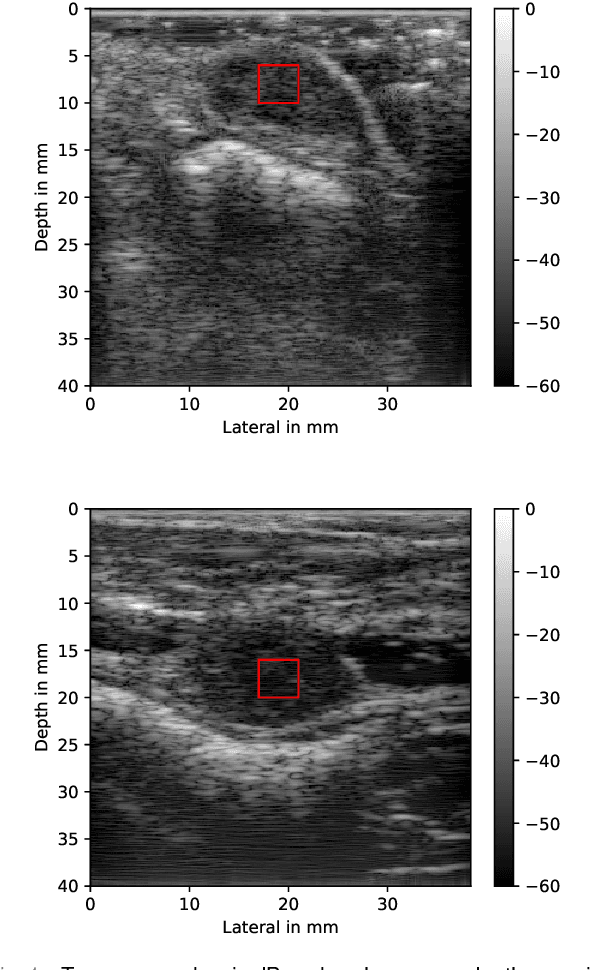
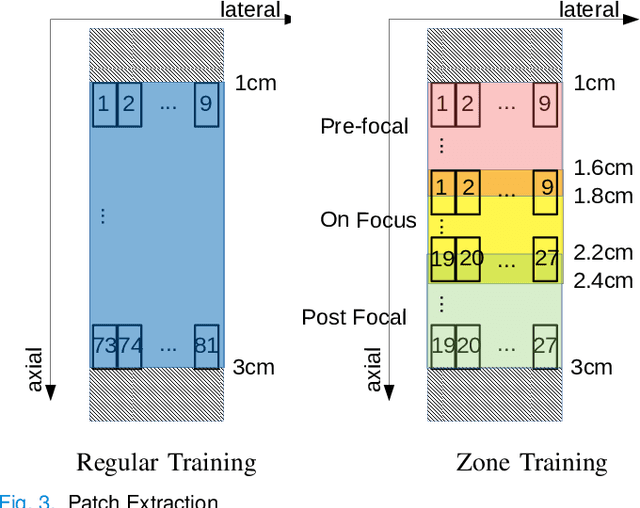
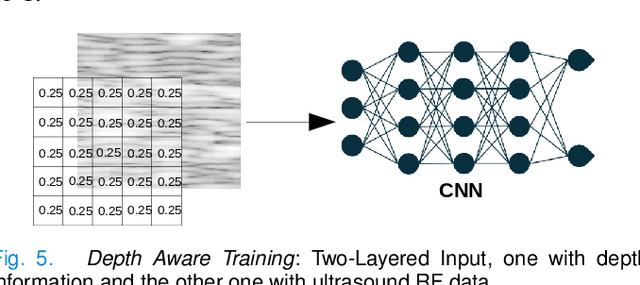
Deep learning (DL) powered biomedical ultrasound imaging is an emerging research field where researchers adapt the image analysis capabilities of DL algorithms to biomedical ultrasound imaging settings. A major roadblock to wider adoption of DL powered biomedical ultrasound imaging is that acquiring large and diverse datasets is expensive in clinical settings, which is a requirement for successful DL implementation. Hence, there is a constant need for developing data-efficient DL techniques to turn DL powered biomedical ultrasound imaging into reality. In this work, we develop a data-efficient deep learning training strategy, which we named \textit{Zone Training}. In \textit{Zone Training}, we propose to divide the complete field of view of an ultrasound image into multiple zones associated with different regions of a diffraction pattern and then, train separate DL networks for each zone. The main advantage of \textit{Zone Training} is that it requires less training data to achieve high accuracy. In this work, three different tissue-mimicking phantoms were classified by a DL network. The results demonstrated that \textit{Zone Training} required a factor of 2-5 less training data to achieve similar classification accuracies compared to a conventional training strategy.
Realistic Image Normalization for Multi-Domain Segmentation
Oct 02, 2020
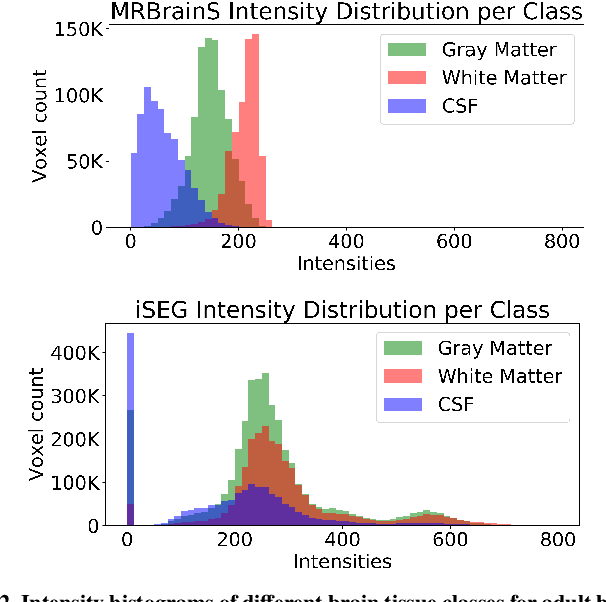
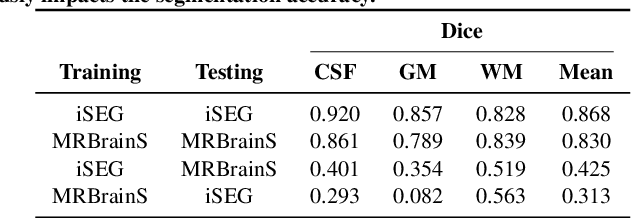
Image normalization is a building block in medical image analysis. Conventional approaches are customarily utilized on a per-dataset basis. This strategy, however, prevents the current normalization algorithms from fully exploiting the complex joint information available across multiple datasets. Consequently, ignoring such joint information has a direct impact on the performance of segmentation algorithms. This paper proposes to revisit the conventional image normalization approach by instead learning a common normalizing function across multiple datasets. Jointly normalizing multiple datasets is shown to yield consistent normalized images as well as an improved image segmentation. To do so, a fully automated adversarial and task-driven normalization approach is employed as it facilitates the training of realistic and interpretable images while keeping performance on-par with the state-of-the-art. The adversarial training of our network aims at finding the optimal transfer function to improve both the segmentation accuracy and the generation of realistic images. We evaluated the performance of our normalizer on both infant and adult brains images from the iSEG, MRBrainS and ABIDE datasets. Results reveal the potential of our normalization approach for segmentation, with Dice improvements of up to 57.5% over our baseline. Our method can also enhance data availability by increasing the number of samples available when learning from multiple imaging domains.