 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Coarse-to-Fine Embedded PatchMatch and Multi-Scale Dynamic Aggregation for Reference-based Super-Resolution
Jan 12, 2022

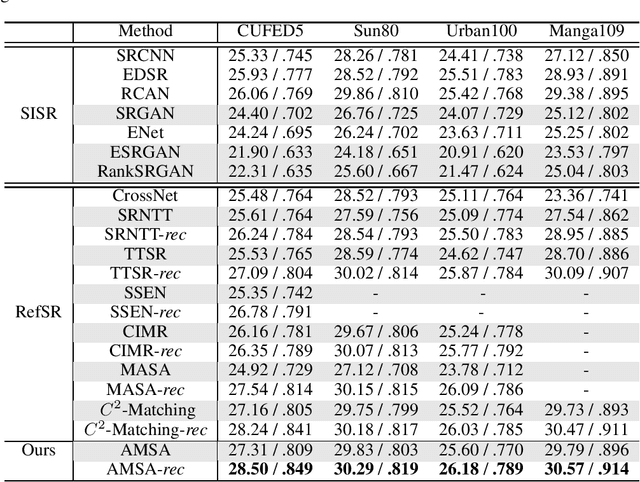
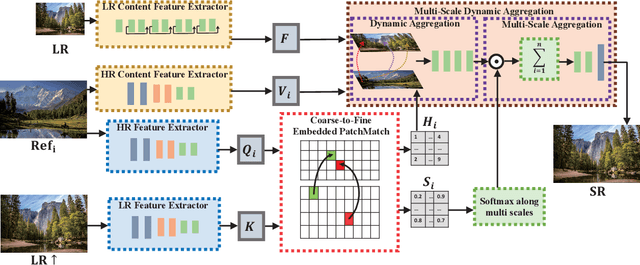
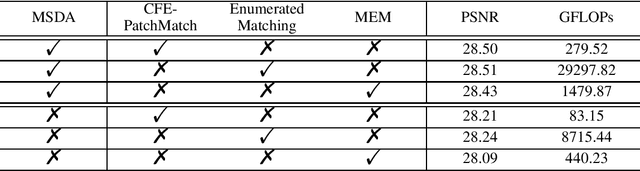
Reference-based super-resolution (RefSR) has made significant progress in producing realistic textures using an external reference (Ref) image. However, existing RefSR methods obtain high-quality correspondence matchings consuming quadratic computation resources with respect to the input size, limiting its application. Moreover, these approaches usually suffer from scale misalignments between the low-resolution (LR) image and Ref image. In this paper, we propose an Accelerated Multi-Scale Aggregation network (AMSA) for Reference-based Super-Resolution, including Coarse-to-Fine Embedded PatchMatch (CFE-PatchMatch) and Multi-Scale Dynamic Aggregation (MSDA) module. To improve matching efficiency, we design a novel Embedded PatchMacth scheme with random samples propagation, which involves end-to-end training with asymptotic linear computational cost to the input size. To further reduce computational cost and speed up convergence, we apply the coarse-to-fine strategy on Embedded PatchMacth constituting CFE-PatchMatch. To fully leverage reference information across multiple scales and enhance robustness to scale misalignment, we develop the MSDA module consisting of Dynamic Aggregation and Multi-Scale Aggregation. The Dynamic Aggregation corrects minor scale misalignment by dynamically aggregating features, and the Multi-Scale Aggregation brings robustness to large scale misalignment by fusing multi-scale information. Experimental results show that the proposed AMSA achieves superior performance over state-of-the-art approaches on both quantitative and qualitative evaluations.
Multi-institutional Collaborations for Improving Deep Learning-based Magnetic Resonance Image Reconstruction Using Federated Learning
Mar 09, 2021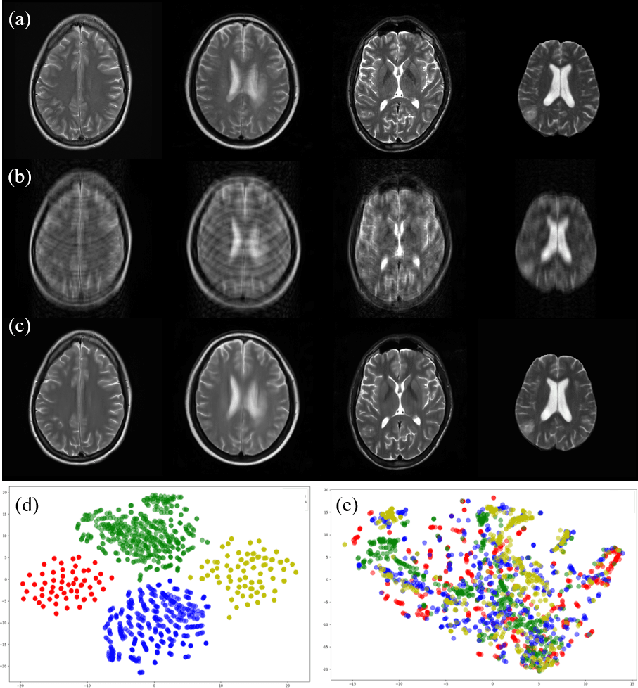
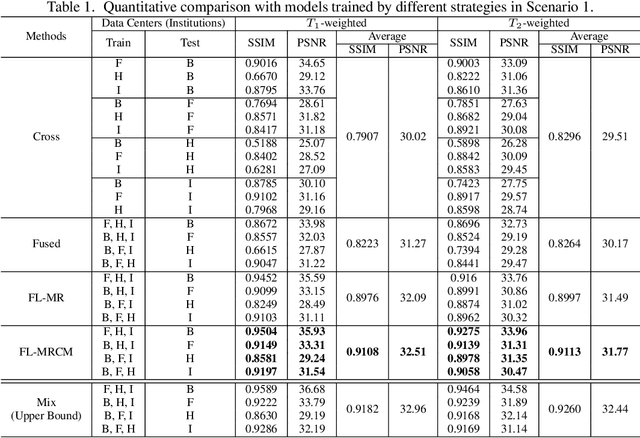
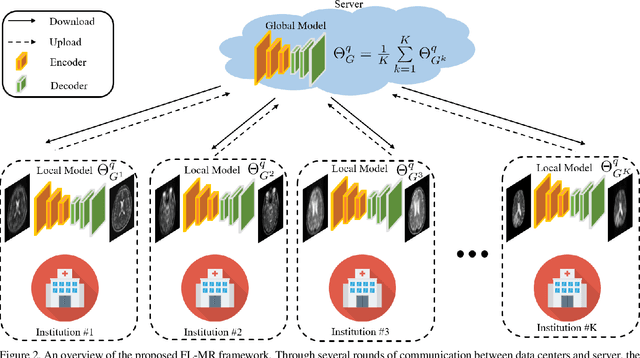
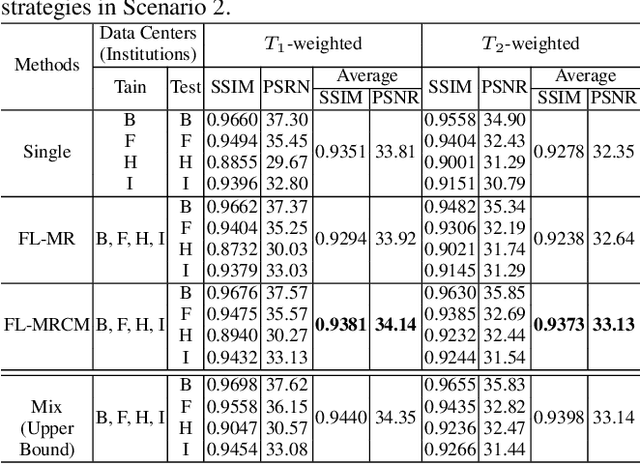
Fast and accurate reconstruction of magnetic resonance (MR) images from under-sampled data is important in many clinical applications. In recent years, deep learning-based methods have been shown to produce superior performance on MR image reconstruction. However, these methods require large amounts of data which is difficult to collect and share due to the high cost of acquisition and medical data privacy regulations. In order to overcome this challenge, we propose a federated learning (FL) based solution in which we take advantage of the MR data available at different institutions while preserving patients' privacy. However, the generalizability of models trained with the FL setting can still be suboptimal due to domain shift, which results from the data collected at multiple institutions with different sensors, disease types, and acquisition protocols, etc. With the motivation of circumventing this challenge, we propose a cross-site modeling for MR image reconstruction in which the learned intermediate latent features among different source sites are aligned with the distribution of the latent features at the target site. Extensive experiments are conducted to provide various insights about FL for MR image reconstruction. Experimental results demonstrate that the proposed framework is a promising direction to utilize multi-institutional data without compromising patients' privacy for achieving improved MR image reconstruction. Our code will be available at https://github.com/guopengf/FLMRCM.
On Hamilton-Jacobi PDEs and image denoising models with certain non-additive noise
May 28, 2021
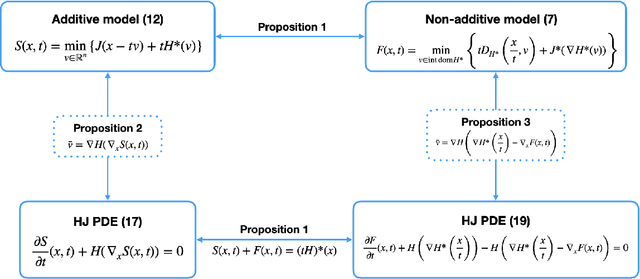


We consider image denoising problems formulated as variational problems. It is known that Hamilton-Jacobi PDEs govern the solution of such optimization problems when the noise model is additive. In this work, we address certain non-additive noise models and show that they are also related to Hamilton-Jacobi PDEs. These findings allow us to establish new connections between additive and non-additive noise imaging models. With these connections, some non-convex models for non-additive noise can be solved by applying convex optimization algorithms to the equivalent convex models for additive noise. Several numerical results are provided for denoising problems with Poisson noise or multiplicative noise.
Improving spatial domain based image formation through compressed sensing
Oct 01, 2020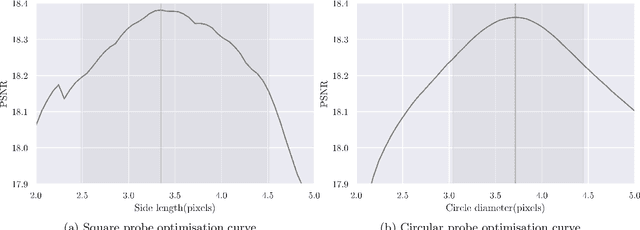
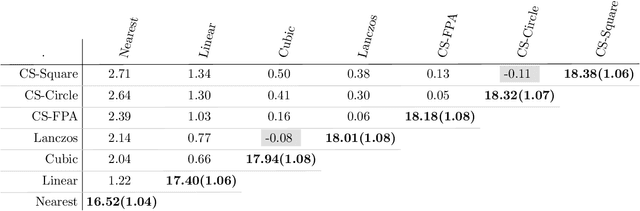

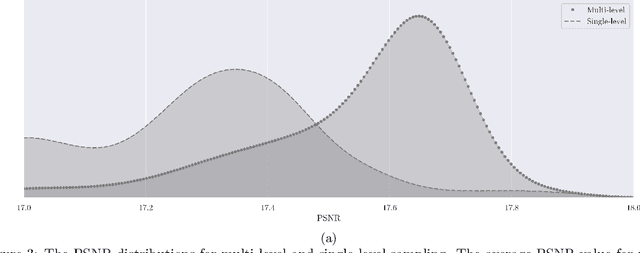
In this paper, we improve image reconstruction in a single-pixel scanning system by selecting an detector optimal field of view. Image reconstruction is based on compressed sensing and image quality is compared to interpolated staring arrays. The image quality comparisons use a "dead leaves" data set, Bayesian estimation and the Peak-Signal-to-Noise Ratio (PSNR) measure. Compressed sensing is explored as an interpolation algorithm and shows with high probability an improved performance compared to Lanczos interpolation. Furthermore, multi-level sampling in a single-pixel scanning system is simulated by dynamically altering the detector field of view. It was shown that multi-level sampling improves the distribution of the Peak-Signal-to-Noise Ratio. We further explore the expected sampling level distributions and PSNR distributions for multi-level sampling. The PSNR distribution indicates that there is a small set of levels which will improve image quality over interpolated staring arrays. We further conclude that multi-level sampling will outperform single-level uniform random sampling on average.
MyStyle: A Personalized Generative Prior
Mar 31, 2022
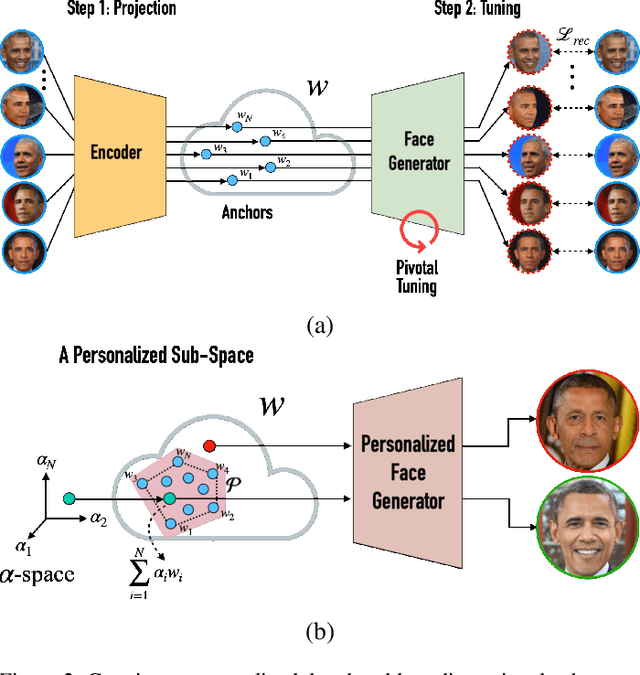
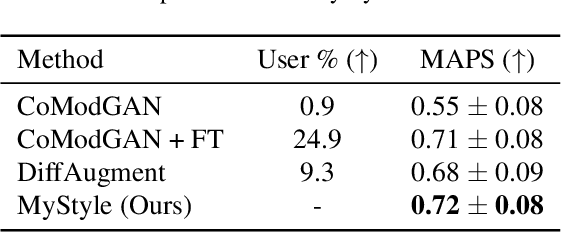

We introduce MyStyle, a personalized deep generative prior trained with a few shots of an individual. MyStyle allows to reconstruct, enhance and edit images of a specific person, such that the output is faithful to the person's key facial characteristics. Given a small reference set of portrait images of a person (~100), we tune the weights of a pretrained StyleGAN face generator to form a local, low-dimensional, personalized manifold in the latent space. We show that this manifold constitutes a personalized region that spans latent codes associated with diverse portrait images of the individual. Moreover, we demonstrate that we obtain a personalized generative prior, and propose a unified approach to apply it to various ill-posed image enhancement problems, such as inpainting and super-resolution, as well as semantic editing. Using the personalized generative prior we obtain outputs that exhibit high-fidelity to the input images and are also faithful to the key facial characteristics of the individual in the reference set. We demonstrate our method with fair-use images of numerous widely recognizable individuals for whom we have the prior knowledge for a qualitative evaluation of the expected outcome. We evaluate our approach against few-shots baselines and show that our personalized prior, quantitatively and qualitatively, outperforms state-of-the-art alternatives.
Rethinking Video Salient Object Ranking
Mar 31, 2022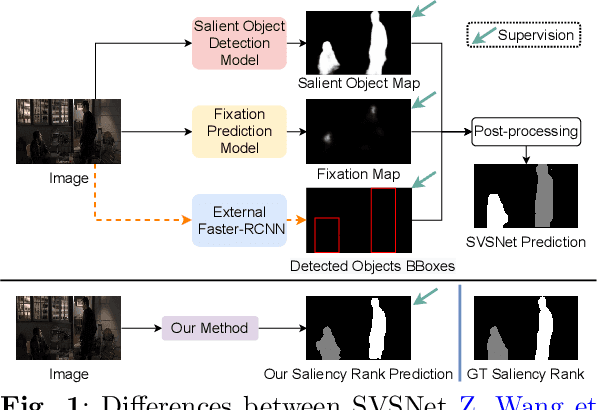


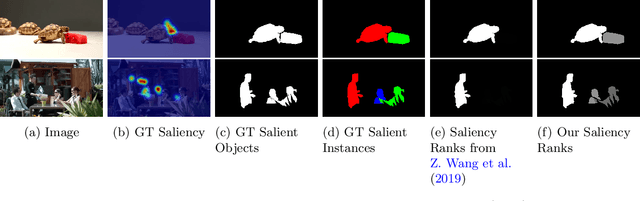
Salient Object Ranking (SOR) involves ranking the degree of saliency of multiple salient objects in an input image. Most recently, a method is proposed for ranking salient objects in an input video based on a predicted fixation map. It relies solely on the density of the fixations within the salient objects to infer their saliency ranks, which is incompatible with human perception of saliency ranking. In this work, we propose to explicitly learn the spatial and temporal relations between different salient objects to produce the saliency ranks. To this end, we propose an end-to-end method for video salient object ranking (VSOR), with two novel modules: an intra-frame adaptive relation (IAR) module to learn the spatial relation among the salient objects in the same frame locally and globally, and an inter-frame dynamic relation (IDR) module to model the temporal relation of saliency across different frames. In addition, to address the limited video types (just sports and movies) and scene diversity in the existing VSOR dataset, we propose a new dataset that covers different video types and diverse scenes on a large scale. Experimental results demonstrate that our method outperforms state-of-the-art methods in relevant fields. We will make the source code and our proposed dataset available.
Catalyzing Clinical Diagnostic Pipelines Through Volumetric Medical Image Segmentation Using Deep Neural Networks: Past, Present, & Future
Mar 27, 2021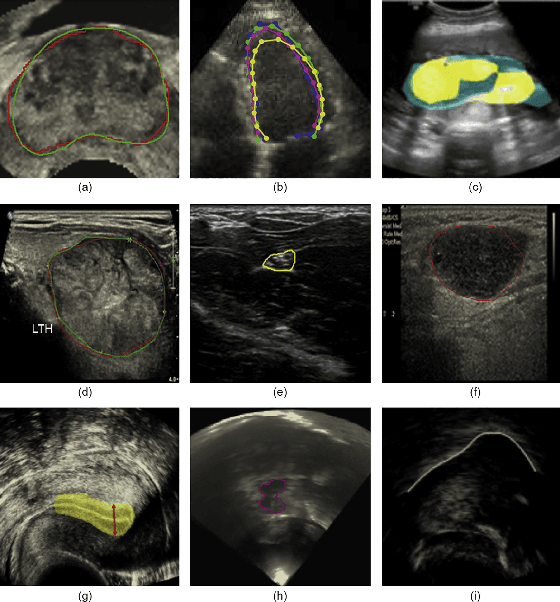
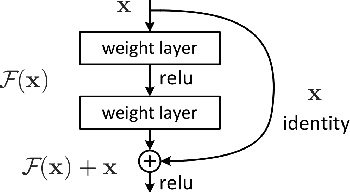
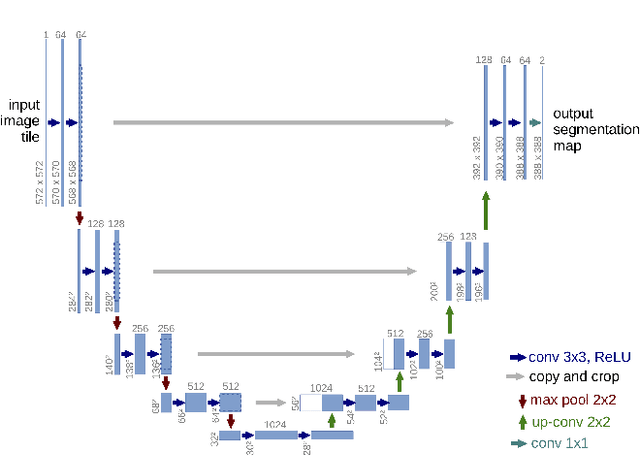
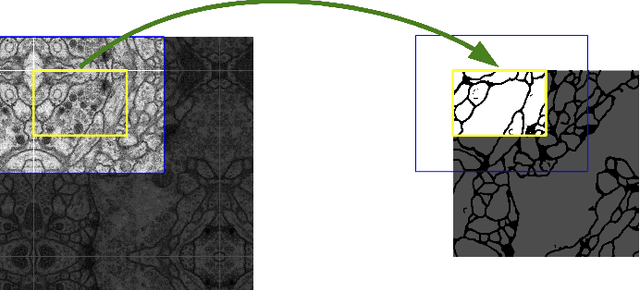
Deep learning has made a remarkable impact in the field of natural image processing over the past decade. Consequently, there is a great deal of interest in replicating this success across unsolved tasks in related domains, such as medical image analysis. Core to medical image analysis is the task of semantic segmentation which enables various clinical workflows. Due to the challenges inherent in manual segmentation, many decades of research have been devoted to discovering extensible, automated, expert-level segmentation techniques. Given the groundbreaking performance demonstrated by recent neural network-based techniques, deep learning seems poised to achieve what classic methods have historically been unable. This paper will briefly overview some of the state-of-the-art (SoTA) neural network-based segmentation algorithms with a particular emphasis on the most recent architectures, comparing and contrasting the contributions and characteristics of each network topology. Using ultrasonography as a motivating example, it will also demonstrate important clinical implications of effective deep learning-based solutions, articulate challenges unique to the modality, and discuss novel approaches developed in response to those challenges, concluding with the proposal of future directions in the field. Given the generally observed ephemerality of the best deep learning approaches (i.e. the extremely quick succession of the SoTA), the main contributions of the paper are its contextualization of modern deep learning architectures with historical background and the elucidation of the current trajectory of volumetric medical image segmentation research.
SimVQA: Exploring Simulated Environments for Visual Question Answering
Mar 31, 2022
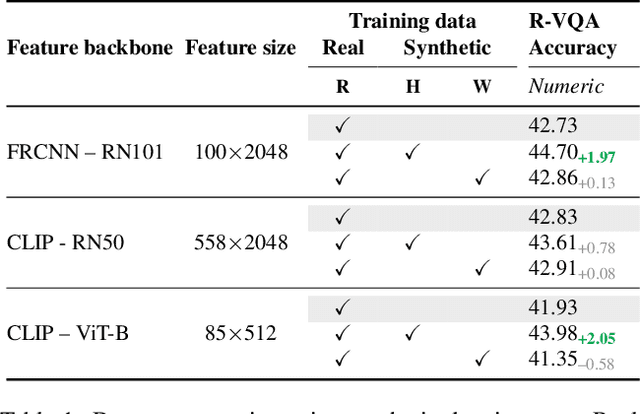
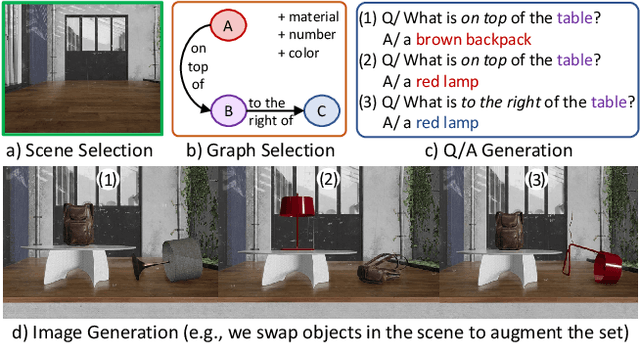
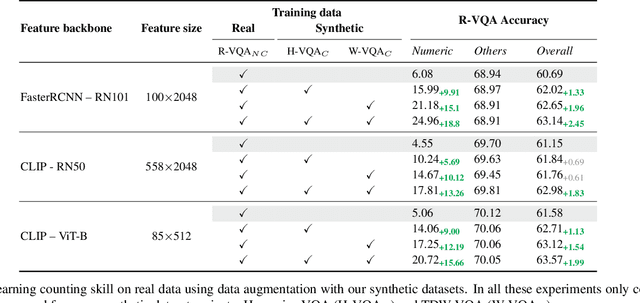
Existing work on VQA explores data augmentation to achieve better generalization by perturbing the images in the dataset or modifying the existing questions and answers. While these methods exhibit good performance, the diversity of the questions and answers are constrained by the available image set. In this work we explore using synthetic computer-generated data to fully control the visual and language space, allowing us to provide more diverse scenarios. We quantify the effect of synthetic data in real-world VQA benchmarks and to which extent it produces results that generalize to real data. By exploiting 3D and physics simulation platforms, we provide a pipeline to generate synthetic data to expand and replace type-specific questions and answers without risking the exposure of sensitive or personal data that might be present in real images. We offer a comprehensive analysis while expanding existing hyper-realistic datasets to be used for VQA. We also propose Feature Swapping (F-SWAP) -- where we randomly switch object-level features during training to make a VQA model more domain invariant. We show that F-SWAP is effective for enhancing a currently existing VQA dataset of real images without compromising on the accuracy to answer existing questions in the dataset.
Self-Adaptively Learning to Demoire from Focused and Defocused Image Pairs
Nov 05, 2020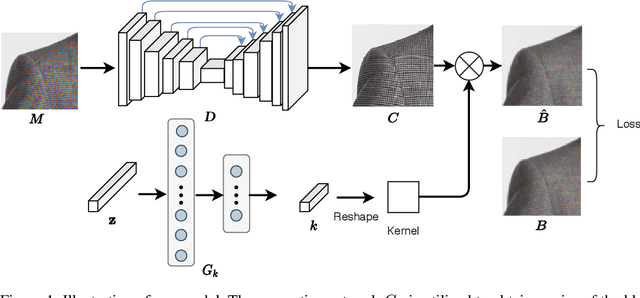



Moire artifacts are common in digital photography, resulting from the interference between high-frequency scene content and the color filter array of the camera. Existing deep learning-based demoireing methods trained on large scale datasets are limited in handling various complex moire patterns, and mainly focus on demoireing of photos taken of digital displays. Moreover, obtaining moire-free ground-truth in natural scenes is difficult but needed for training. In this paper, we propose a self-adaptive learning method for demoireing a high-frequency image, with the help of an additional defocused moire-free blur image. Given an image degraded with moire artifacts and a moire-free blur image, our network predicts a moire-free clean image and a blur kernel with a self-adaptive strategy that does not require an explicit training stage, instead performing test-time adaptation. Our model has two sub-networks and works iteratively. During each iteration, one sub-network takes the moire image as input, removing moire patterns and restoring image details, and the other sub-network estimates the blur kernel from the blur image. The two sub-networks are jointly optimized. Extensive experiments demonstrate that our method outperforms state-of-the-art methods and can produce high-quality demoired results. It can generalize well to the task of removing moire artifacts caused by display screens. In addition, we build a new moire dataset, including images with screen and texture moire artifacts. As far as we know, this is the first dataset with real texture moire patterns.
Bilateral Cross-Modality Graph Matching Attention for Feature Fusion in Visual Question Answering
Dec 14, 2021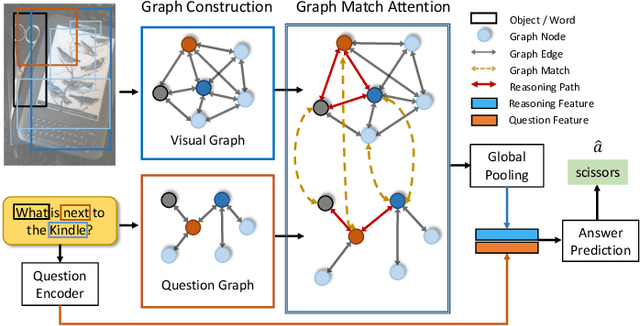
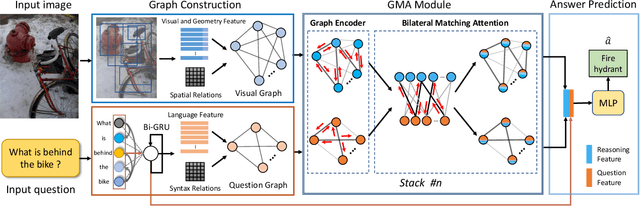
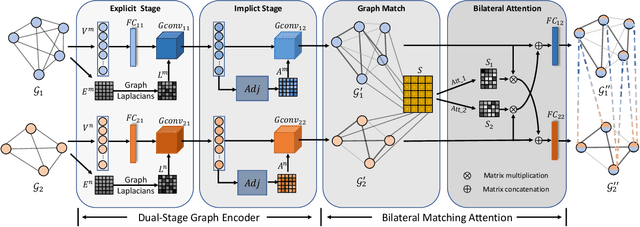
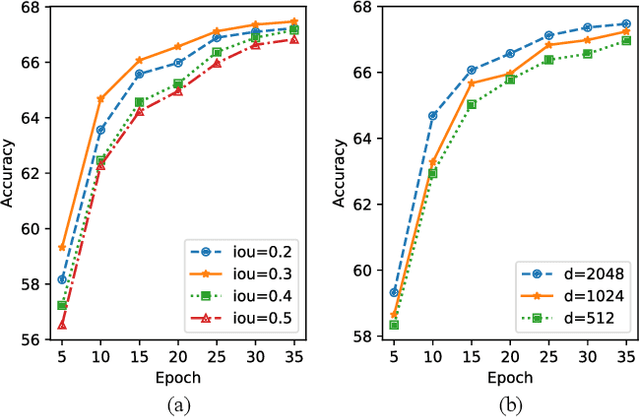
Answering semantically-complicated questions according to an image is challenging in Visual Question Answering (VQA) task. Although the image can be well represented by deep learning, the question is always simply embedded and cannot well indicate its meaning. Besides, the visual and textual features have a gap for different modalities, it is difficult to align and utilize the cross-modality information. In this paper, we focus on these two problems and propose a Graph Matching Attention (GMA) network. Firstly, it not only builds graph for the image, but also constructs graph for the question in terms of both syntactic and embedding information. Next, we explore the intra-modality relationships by a dual-stage graph encoder and then present a bilateral cross-modality graph matching attention to infer the relationships between the image and the question. The updated cross-modality features are then sent into the answer prediction module for final answer prediction. Experiments demonstrate that our network achieves state-of-the-art performance on the GQA dataset and the VQA 2.0 dataset. The ablation studies verify the effectiveness of each modules in our GMA network.