 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Instance-aware Image Colorization
May 21, 2020
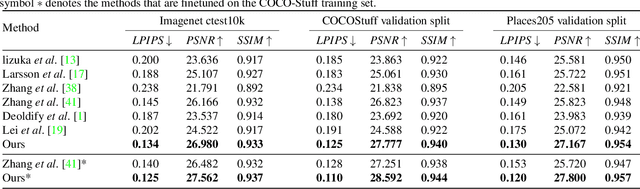

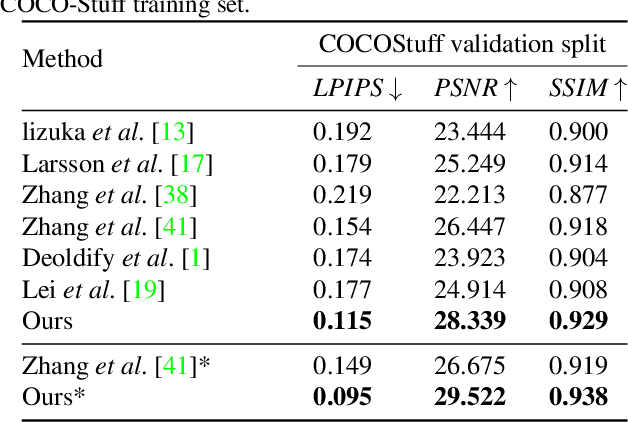
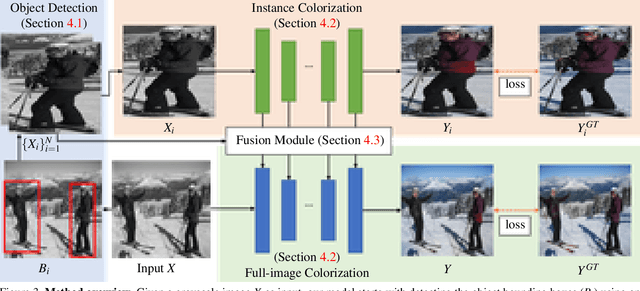
Image colorization is inherently an ill-posed problem with multi-modal uncertainty. Previous methods leverage the deep neural network to map input grayscale images to plausible color outputs directly. Although these learning-based methods have shown impressive performance, they usually fail on the input images that contain multiple objects. The leading cause is that existing models perform learning and colorization on the entire image. In the absence of a clear figure-ground separation, these models cannot effectively locate and learn meaningful object-level semantics. In this paper, we propose a method for achieving instance-aware colorization. Our network architecture leverages an off-the-shelf object detector to obtain cropped object images and uses an instance colorization network to extract object-level features. We use a similar network to extract the full-image features and apply a fusion module to full object-level and image-level features to predict the final colors. Both colorization networks and fusion modules are learned from a large-scale dataset. Experimental results show that our work outperforms existing methods on different quality metrics and achieves state-of-the-art performance on image colorization.
Analyzing Generalization of Vision and Language Navigation to Unseen Outdoor Areas
Mar 25, 2022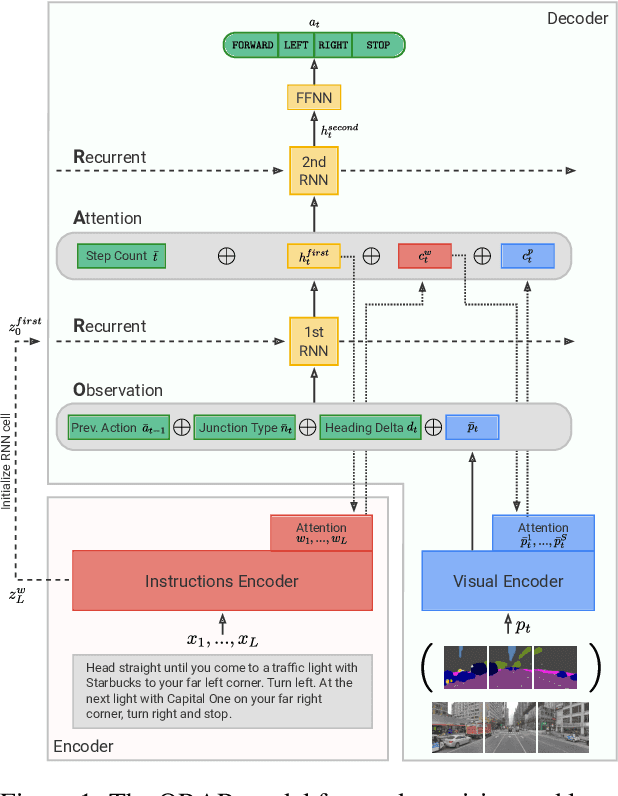
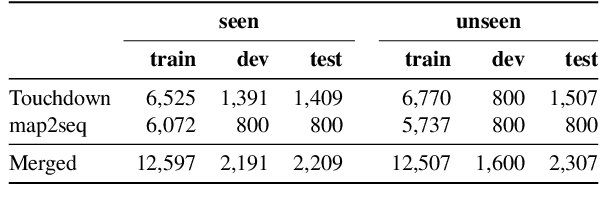
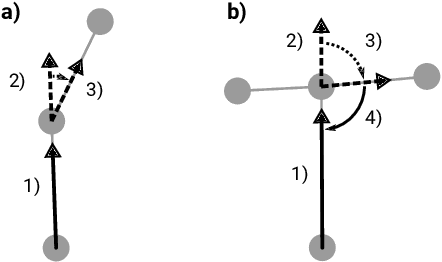
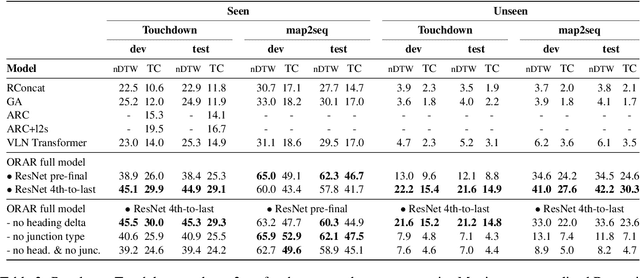
Vision and language navigation (VLN) is a challenging visually-grounded language understanding task. Given a natural language navigation instruction, a visual agent interacts with a graph-based environment equipped with panorama images and tries to follow the described route. Most prior work has been conducted in indoor scenarios where best results were obtained for navigation on routes that are similar to the training routes, with sharp drops in performance when testing on unseen environments. We focus on VLN in outdoor scenarios and find that in contrast to indoor VLN, most of the gain in outdoor VLN on unseen data is due to features like junction type embedding or heading delta that are specific to the respective environment graph, while image information plays a very minor role in generalizing VLN to unseen outdoor areas. These findings show a bias to specifics of graph representations of urban environments, demanding that VLN tasks grow in scale and diversity of geographical environments.
Super-Efficient Super Resolution for Fast Adversarial Defense at the Edge
Dec 29, 2021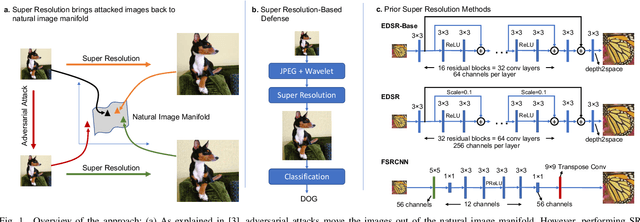
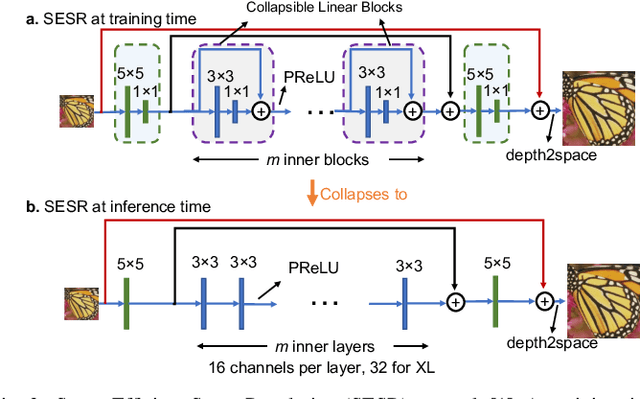
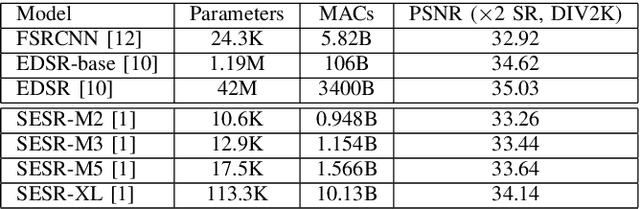
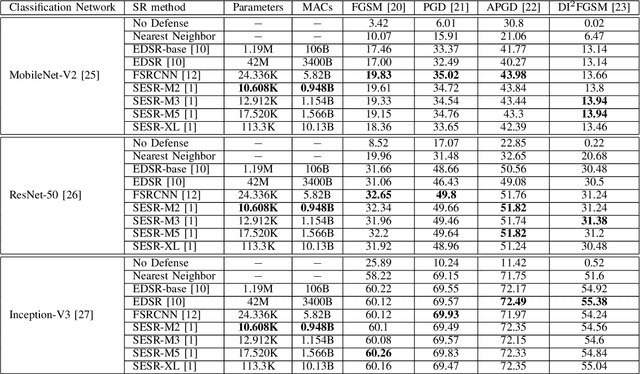
Autonomous systems are highly vulnerable to a variety of adversarial attacks on Deep Neural Networks (DNNs). Training-free model-agnostic defenses have recently gained popularity due to their speed, ease of deployment, and ability to work across many DNNs. To this end, a new technique has emerged for mitigating attacks on image classification DNNs, namely, preprocessing adversarial images using super resolution -- upscaling low-quality inputs into high-resolution images. This defense requires running both image classifiers and super resolution models on constrained autonomous systems. However, super resolution incurs a heavy computational cost. Therefore, in this paper, we investigate the following question: Does the robustness of image classifiers suffer if we use tiny super resolution models? To answer this, we first review a recent work called Super-Efficient Super Resolution (SESR) that achieves similar or better image quality than prior art while requiring 2x to 330x fewer Multiply-Accumulate (MAC) operations. We demonstrate that despite being orders of magnitude smaller than existing models, SESR achieves the same level of robustness as significantly larger networks. Finally, we estimate end-to-end performance of super resolution-based defenses on a commercial Arm Ethos-U55 micro-NPU. Our findings show that SESR achieves nearly 3x higher FPS than a baseline while achieving similar robustness.
RealNet: Combining Optimized Object Detection with Information Fusion Depth Estimation Co-Design Method on IoT
Apr 24, 2022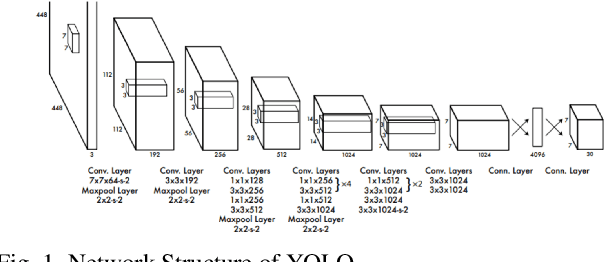

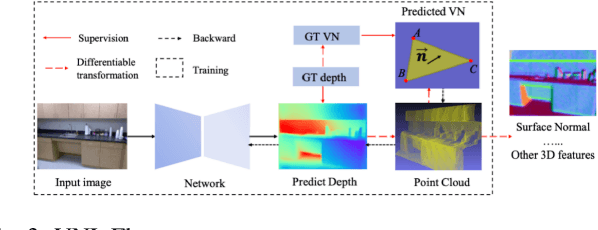

Depth Estimation and Object Detection Recognition play an important role in autonomous driving technology under the guidance of deep learning artificial intelligence. We propose a hybrid structure called RealNet: a co-design method combining the model-streamlined recognition algorithm, the depth estimation algorithm with information fusion, and deploying them on the Jetson-Nano for unmanned vehicles with monocular vision sensors. We use ROS for experiment. The method proposed in this paper is suitable for mobile platforms with high real-time request. Innovation of our method is using information fusion to compensate the problem of insufficient frame rate of output image, and improve the robustness of target detection and depth estimation under monocular vision.Object Detection is based on YOLO-v5. We have simplified the network structure of its DarkNet53 and realized a prediction speed up to 0.01s. Depth Estimation is based on the VNL Depth Estimation, which considers multiple geometric constraints in 3D global space. It calculates the loss function by calculating the deviation of the virtual normal vector VN and the label, which can obtain deeper depth information. We use PnP fusion algorithm to solve the problem of insufficient frame rate of depth map output. It solves the motion estimation depth from three-dimensional target to two-dimensional point based on corner feature matching, which is faster than VNL calculation. We interpolate VNL output and PnP output to achieve information fusion. Experiments show that this can effectively eliminate the jitter of depth information and improve robustness. At the control end, this method combines the results of target detection and depth estimation to calculate the target position, and uses a pure tracking control algorithm to track it.
Hybrid Saturation Restoration for LDR Images of HDR Scenes
Nov 11, 2021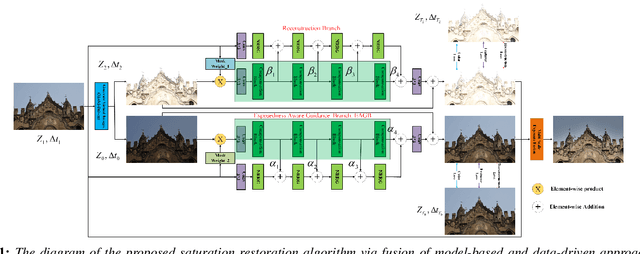
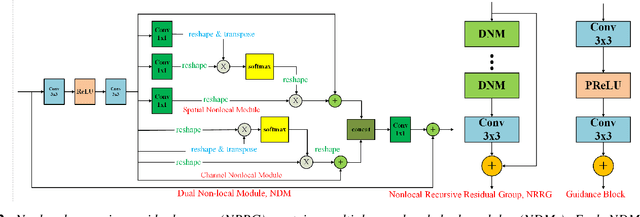

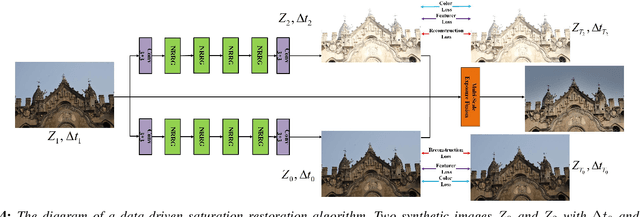
There are shadow and highlight regions in a low dynamic range (LDR) image which is captured from a high dynamic range (HDR) scene. It is an ill-posed problem to restore the saturated regions of the LDR image. In this paper, the saturated regions of the LDR image are restored by fusing model-based and data-driven approaches. With such a neural augmentation, two synthetic LDR images are first generated from the underlying LDR image via the model-based approach. One is brighter than the input image to restore the shadow regions and the other is darker than the input image to restore the high-light regions. Both synthetic images are then refined via a novel exposedness aware saturation restoration network (EASRN). Finally, the two synthetic images and the input image are combined together via an HDR synthesis algorithm or a multi-scale exposure fusion algorithm. The proposed algorithm can be embedded in any smart phones or digital cameras to produce an information-enriched LDR image.
Structurally aware bidirectional unpaired image to image translation between CT and MR
Jun 05, 2020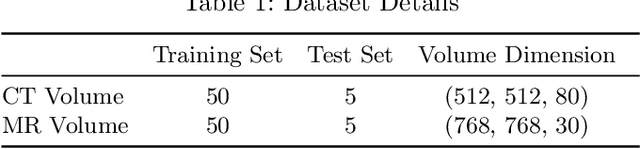
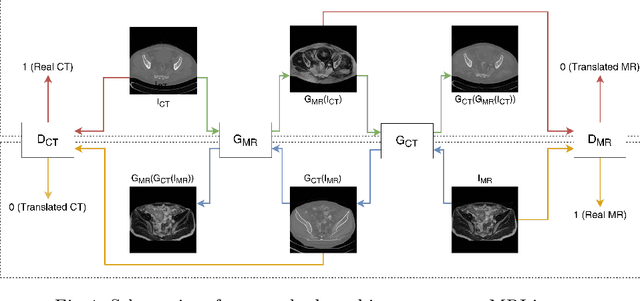
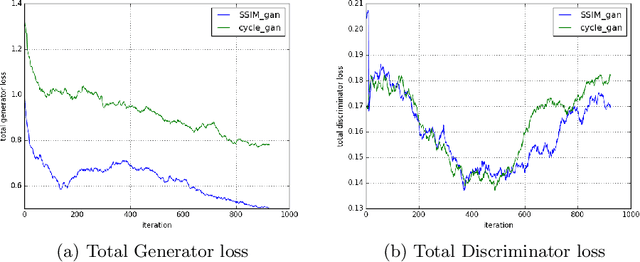
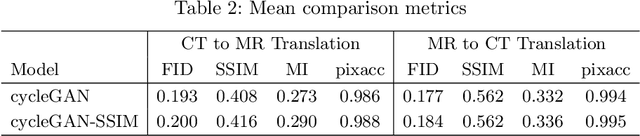
Magnetic Resonance (MR) Imaging and Computed Tomography (CT) are the primary diagnostic imaging modalities quite frequently used for surgical planning and analysis. A general problem with medical imaging is that the acquisition process is quite expensive and time-consuming. Deep learning techniques like generative adversarial networks (GANs) can help us to leverage the possibility of an image to image translation between multiple imaging modalities, which in turn helps in saving time and cost. These techniques will help to conduct surgical planning under CT with the feedback of MRI information. While previous studies have shown paired and unpaired image synthesis from MR to CT, image synthesis from CT to MR still remains a challenge, since it involves the addition of extra tissue information. In this manuscript, we have implemented two different variations of Generative Adversarial Networks exploiting the cycling consistency and structural similarity between both CT and MR image modalities on a pelvis dataset, thus facilitating a bidirectional exchange of content and style between these image modalities. The proposed GANs translate the input medical images by different mechanisms, and hence generated images not only appears realistic but also performs well across various comparison metrics, and these images have also been cross verified with a radiologist. The radiologist verification has shown that slight variations in generated MR and CT images may not be exactly the same as their true counterpart but it can be used for medical purposes.
Implicit Neural Representations for Deconvolving SAS Images
Dec 16, 2021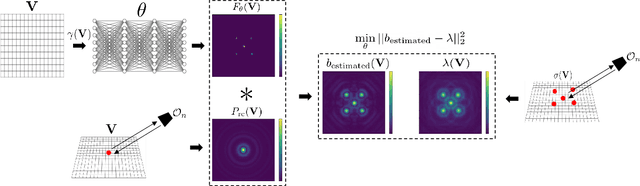
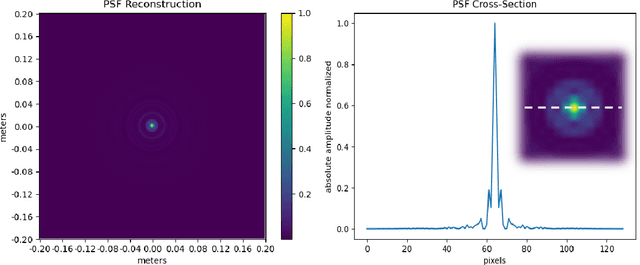
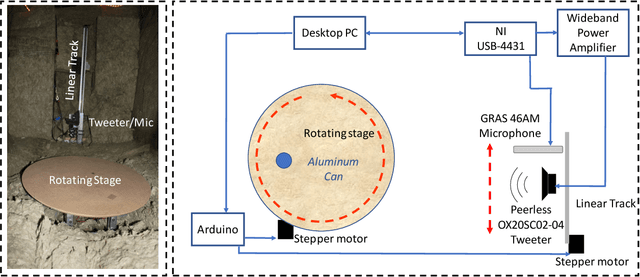
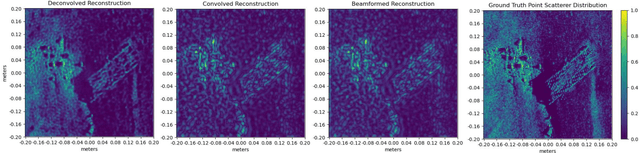
Synthetic aperture sonar (SAS) image resolution is constrained by waveform bandwidth and array geometry. Specifically, the waveform bandwidth determines a point spread function (PSF) that blurs the locations of point scatterers in the scene. In theory, deconvolving the reconstructed SAS image with the scene PSF restores the original distribution of scatterers and yields sharper reconstructions. However, deconvolution is an ill-posed operation that is highly sensitive to noise. In this work, we leverage implicit neural representations (INRs), shown to be strong priors for the natural image space, to deconvolve SAS images. Importantly, our method does not require training data, as we perform our deconvolution through an analysis-bysynthesis optimization in a self-supervised fashion. We validate our method on simulated SAS data created with a point scattering model and real data captured with an in-air circular SAS. This work is an important first step towards applying neural networks for SAS image deconvolution.
ReflectNet -- A Generative Adversarial Method for Single Image Reflection Suppression
May 11, 2021
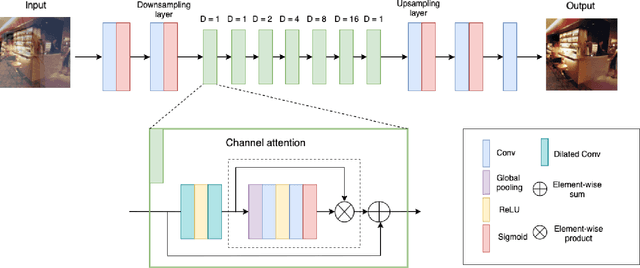


Taking pictures through glass windows almost always produces undesired reflections that degrade the quality of the photo. The ill-posed nature of the reflection removal problem reached the attention of many researchers for more than decades. The main challenge of this problem is the lack of real training data and the necessity of generating realistic synthetic data. In this paper, we proposed a single image reflection removal method based on context understanding modules and adversarial training to efficiently restore the transmission layer without reflection. We also propose a complex data generation model in order to create a large training set with various type of reflections. Our proposed reflection removal method outperforms state-of-the-art methods in terms of PSNR and SSIM on the SIR benchmark dataset.
Multiple Code Hashing for Efficient Image Retrieval
Aug 04, 2020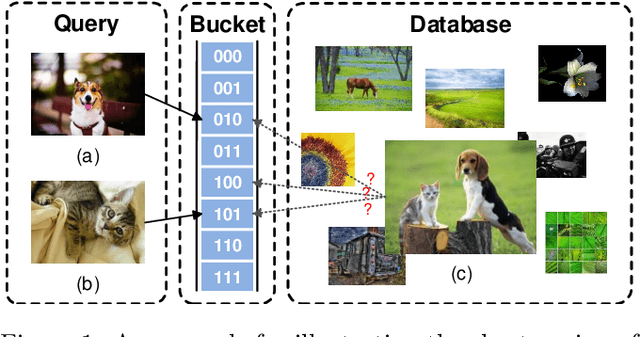

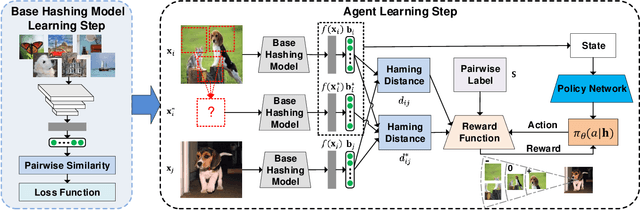
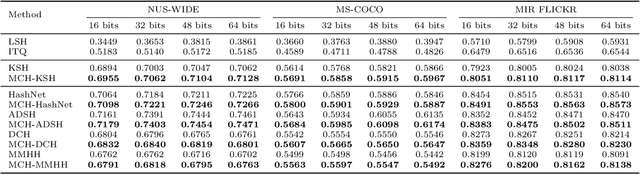
Due to its low storage cost and fast query speed, hashing has been widely used in large-scale image retrieval tasks. Hash bucket search returns data points within a given Hamming radius to each query, which can enable search at a constant or sub-linear time cost. However, existing hashing methods cannot achieve satisfactory retrieval performance for hash bucket search in complex scenarios, since they learn only one hash code for each image. More specifically, by using one hash code to represent one image, existing methods might fail to put similar image pairs to the buckets with a small Hamming distance to the query when the semantic information of images is complex. As a result, a large number of hash buckets need to be visited for retrieving similar images, based on the learned codes. This will deteriorate the efficiency of hash bucket search. In this paper, we propose a novel hashing framework, called multiple code hashing (MCH), to improve the performance of hash bucket search. The main idea of MCH is to learn multiple hash codes for each image, with each code representing a different region of the image. Furthermore, we propose a deep reinforcement learning algorithm to learn the parameters in MCH. To the best of our knowledge, this is the first work that proposes to learn multiple hash codes for each image in image retrieval. Experiments demonstrate that MCH can achieve a significant improvement in hash bucket search, compared with existing methods that learn only one hash code for each image.
Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision
Feb 16, 2022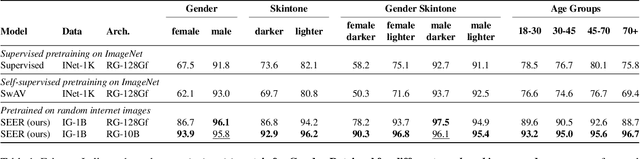
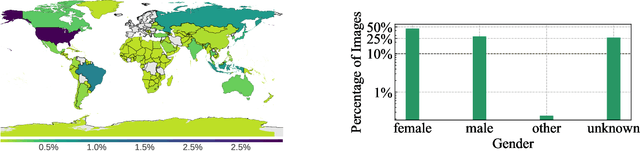
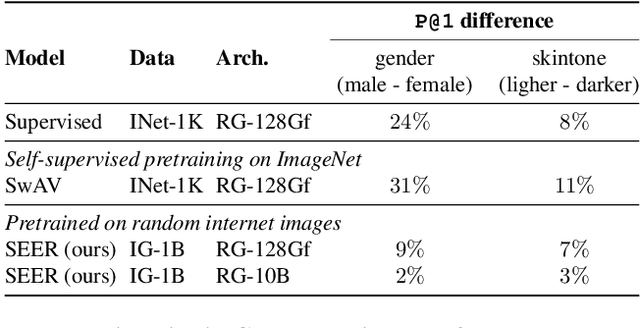
Discriminative self-supervised learning allows training models on any random group of internet images, and possibly recover salient information that helps differentiate between the images. Applied to ImageNet, this leads to object centric features that perform on par with supervised features on most object-centric downstream tasks. In this work, we question if using this ability, we can learn any salient and more representative information present in diverse unbounded set of images from across the globe. To do so, we train models on billions of random images without any data pre-processing or prior assumptions about what we want the model to learn. We scale our model size to dense 10 billion parameters to avoid underfitting on a large data size. We extensively study and validate our model performance on over 50 benchmarks including fairness, robustness to distribution shift, geographical diversity, fine grained recognition, image copy detection and many image classification datasets. The resulting model, not only captures well semantic information, it also captures information about artistic style and learns salient information such as geolocations and multilingual word embeddings based on visual content only. More importantly, we discover that such model is more robust, more fair, less harmful and less biased than supervised models or models trained on object centric datasets such as ImageNet.