 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VisualCheXbert: Addressing the Discrepancy Between Radiology Report Labels and Image Labels
Mar 15, 2021
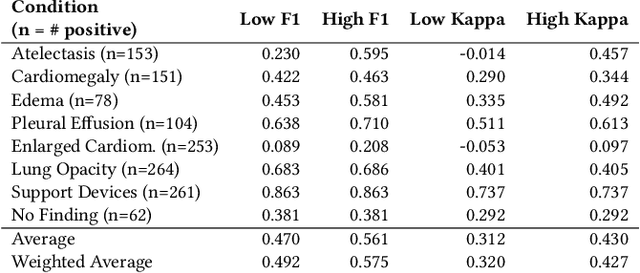
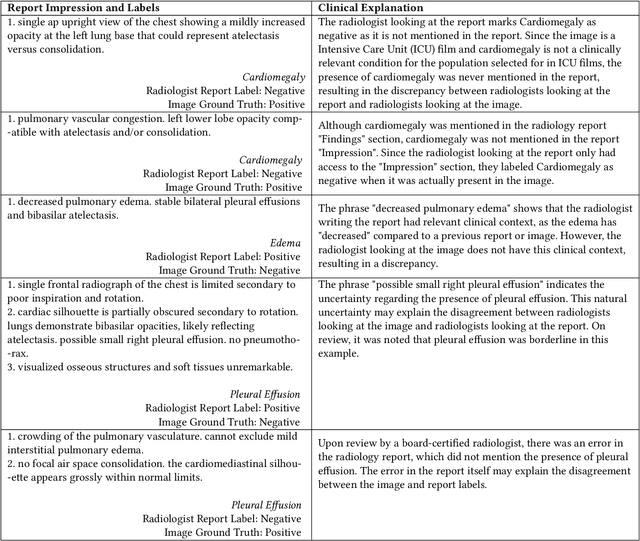
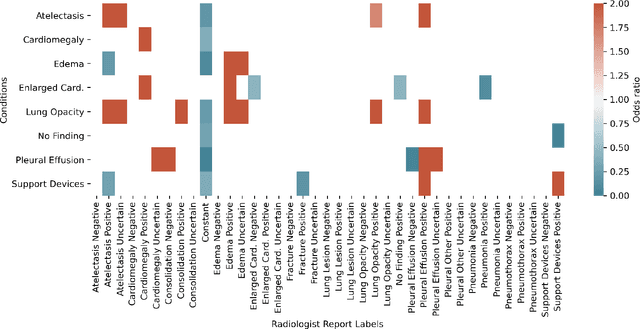
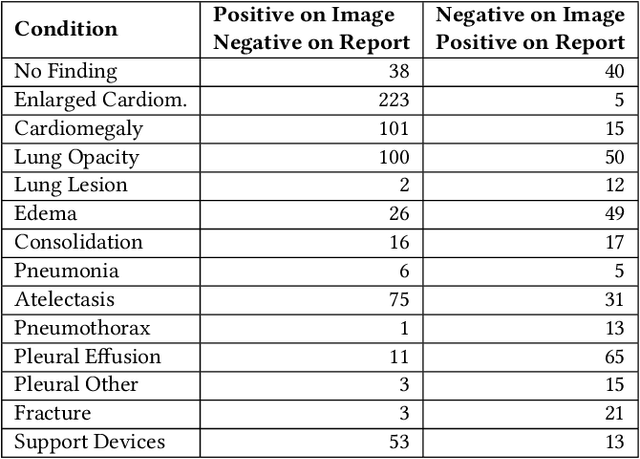
Automatic extraction of medical conditions from free-text radiology reports is critical for supervising computer vision models to interpret medical images. In this work, we show that radiologists labeling reports significantly disagree with radiologists labeling corresponding chest X-ray images, which reduces the quality of report labels as proxies for image labels. We develop and evaluate methods to produce labels from radiology reports that have better agreement with radiologists labeling images. Our best performing method, called VisualCheXbert, uses a biomedically-pretrained BERT model to directly map from a radiology report to the image labels, with a supervisory signal determined by a computer vision model trained to detect medical conditions from chest X-ray images. We find that VisualCheXbert outperforms an approach using an existing radiology report labeler by an average F1 score of 0.14 (95% CI 0.12, 0.17). We also find that VisualCheXbert better agrees with radiologists labeling chest X-ray images than do radiologists labeling the corresponding radiology reports by an average F1 score across several medical conditions of between 0.12 (95% CI 0.09, 0.15) and 0.21 (95% CI 0.18, 0.24).
Human-Object Interaction Detection via Weak Supervision
Dec 01, 2021

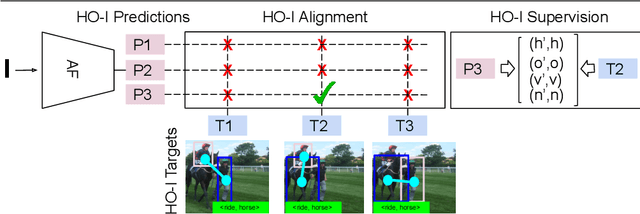
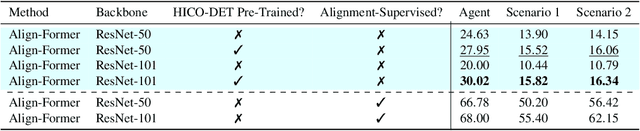
The goal of this paper is Human-object Interaction (HO-I) detection. HO-I detection aims to find interacting human-objects regions and classify their interaction from an image. Researchers obtain significant improvement in recent years by relying on strong HO-I alignment supervision from [5]. HO-I alignment supervision pairs humans with their interacted objects, and then aligns human-object pair(s) with their interaction categories. Since collecting such annotation is expensive, in this paper, we propose to detect HO-I without alignment supervision. We instead rely on image-level supervision that only enumerates existing interactions within the image without pointing where they happen. Our paper makes three contributions: i) We propose Align-Former, a visual-transformer based CNN that can detect HO-I with only image-level supervision. ii) Align-Former is equipped with HO-I align layer, that can learn to select appropriate targets to allow detector supervision. iii) We evaluate Align-Former on HICO-DET [5] and V-COCO [13], and show that Align-Former outperforms existing image-level supervised HO-I detectors by a large margin (4.71% mAP improvement from 16.14% to 20.85% on HICO-DET [5]).
CLIP Models are Few-shot Learners: Empirical Studies on VQA and Visual Entailment
Mar 14, 2022
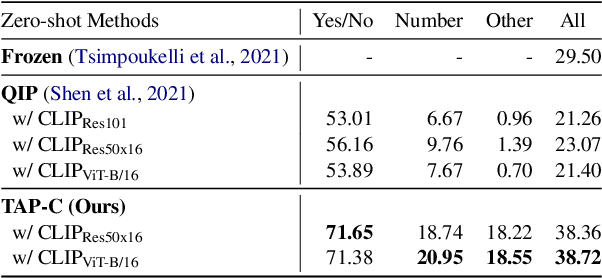
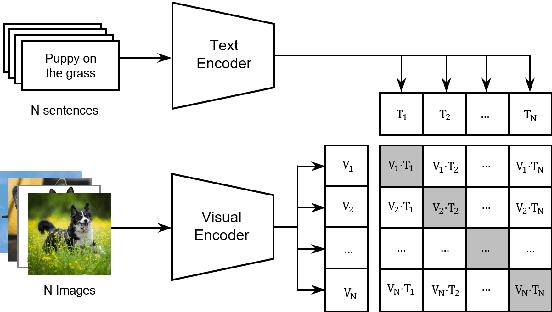
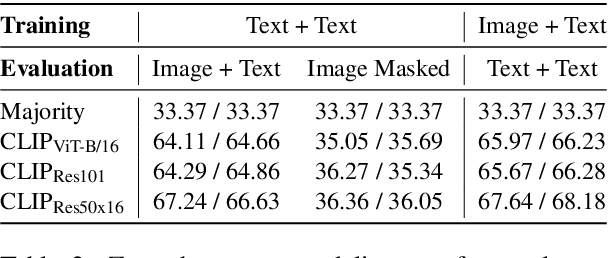
CLIP has shown a remarkable zero-shot capability on a wide range of vision tasks. Previously, CLIP is only regarded as a powerful visual encoder. However, after being pre-trained by language supervision from a large amount of image-caption pairs, CLIP itself should also have acquired some few-shot abilities for vision-language tasks. In this work, we empirically show that CLIP can be a strong vision-language few-shot learner by leveraging the power of language. We first evaluate CLIP's zero-shot performance on a typical visual question answering task and demonstrate a zero-shot cross-modality transfer capability of CLIP on the visual entailment task. Then we propose a parameter-efficient fine-tuning strategy to boost the few-shot performance on the vqa task. We achieve competitive zero/few-shot results on the visual question answering and visual entailment tasks without introducing any additional pre-training procedure.
Retrieving Black-box Optimal Images from External Databases
Dec 30, 2021



Suppose we have a black-box function (e.g., deep neural network) that takes an image as input and outputs a value that indicates preference. How can we retrieve optimal images with respect to this function from an external database on the Internet? Standard retrieval problems in the literature (e.g., item recommendations) assume that an algorithm has full access to the set of items. In other words, such algorithms are designed for service providers. In this paper, we consider the retrieval problem under different assumptions. Specifically, we consider how users with limited access to an image database can retrieve images using their own black-box functions. This formulation enables a flexible and finer-grained image search defined by each user. We assume the user can access the database through a search query with tight API limits. Therefore, a user needs to efficiently retrieve optimal images in terms of the number of queries. We propose an efficient retrieval algorithm Tiara for this problem. In the experiments, we confirm that our proposed method performs better than several baselines under various settings.
On the relationship between calibrated predictors and unbiased volume estimation
Dec 23, 2021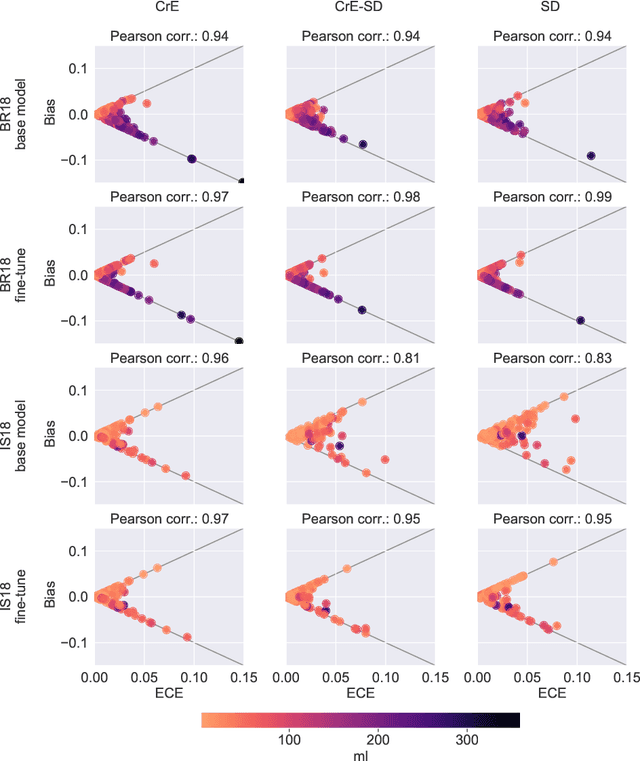
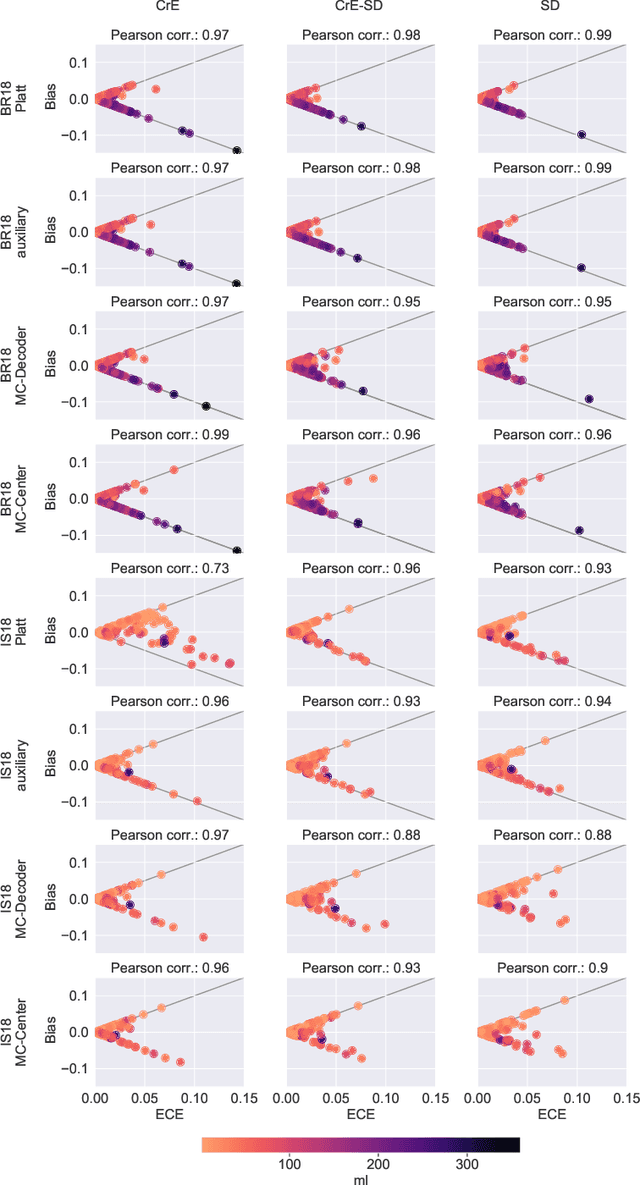
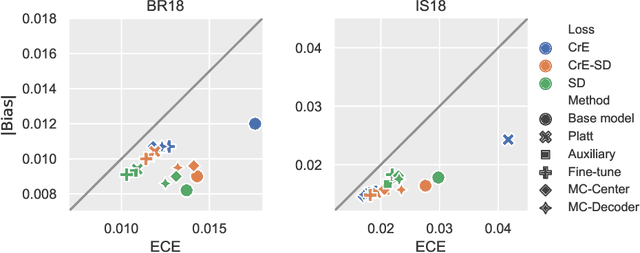
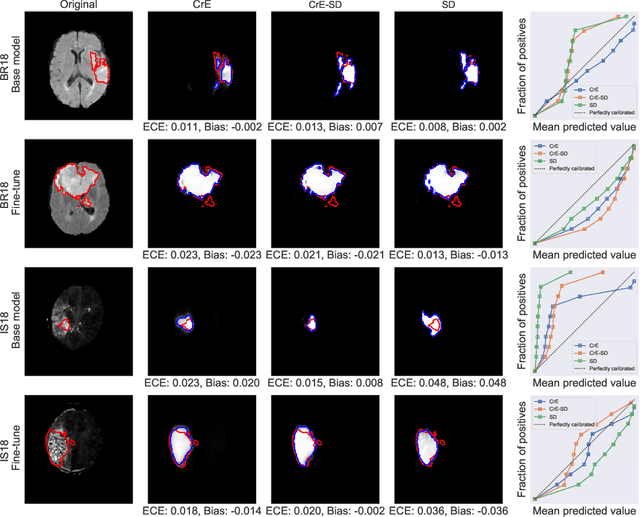
Machine learning driven medical image segmentation has become standard in medical image analysis. However, deep learning models are prone to overconfident predictions. This has led to a renewed focus on calibrated predictions in the medical imaging and broader machine learning communities. Calibrated predictions are estimates of the probability of a label that correspond to the true expected value of the label conditioned on the confidence. Such calibrated predictions have utility in a range of medical imaging applications, including surgical planning under uncertainty and active learning systems. At the same time it is often an accurate volume measurement that is of real importance for many medical applications. This work investigates the relationship between model calibration and volume estimation. We demonstrate both mathematically and empirically that if the predictor is calibrated per image, we can obtain the correct volume by taking an expectation of the probability scores per pixel/voxel of the image. Furthermore, we show that convex combinations of calibrated classifiers preserve volume estimation, but do not preserve calibration. Therefore, we conclude that having a calibrated predictor is a sufficient, but not necessary condition for obtaining an unbiased estimate of the volume. We validate our theoretical findings empirically on a collection of 18 different (calibrated) training strategies on the tasks of glioma volume estimation on BraTS 2018, and ischemic stroke lesion volume estimation on ISLES 2018 datasets.
Multi-institutional Collaborations for Improving Deep Learning-based Magnetic Resonance Image Reconstruction Using Federated Learning
Mar 10, 2021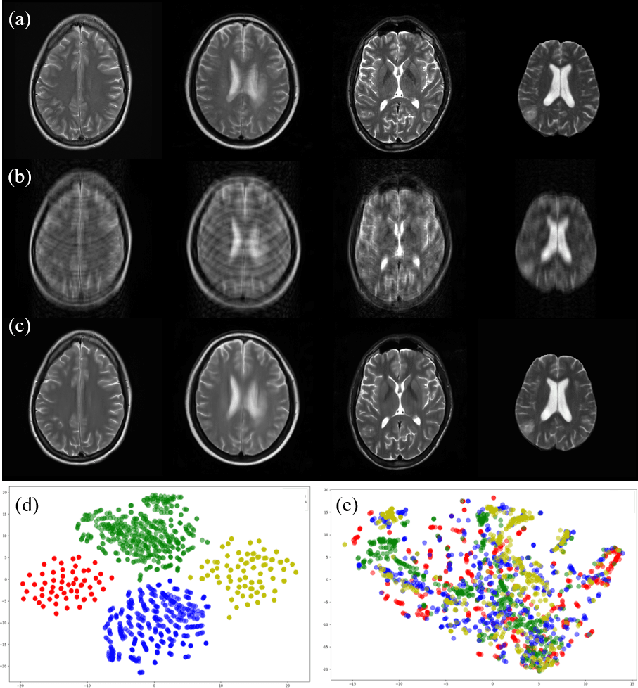
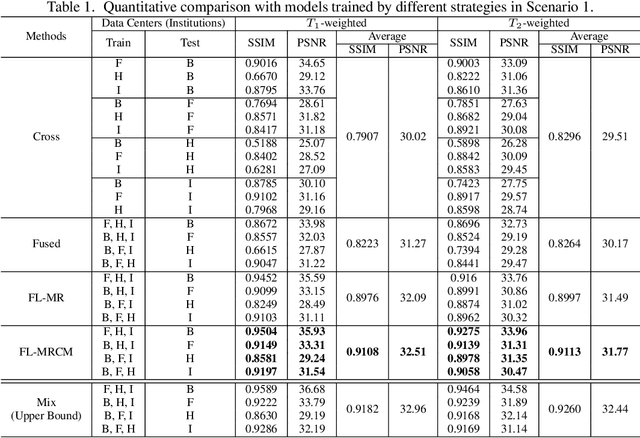
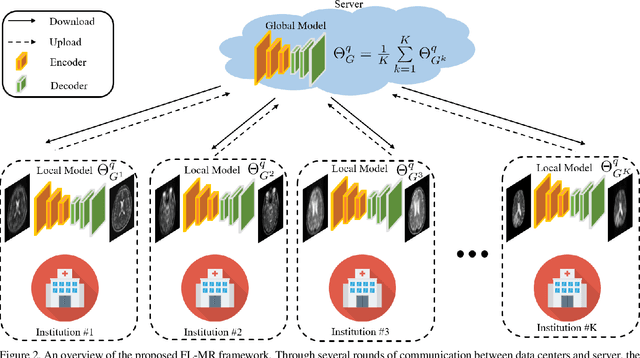
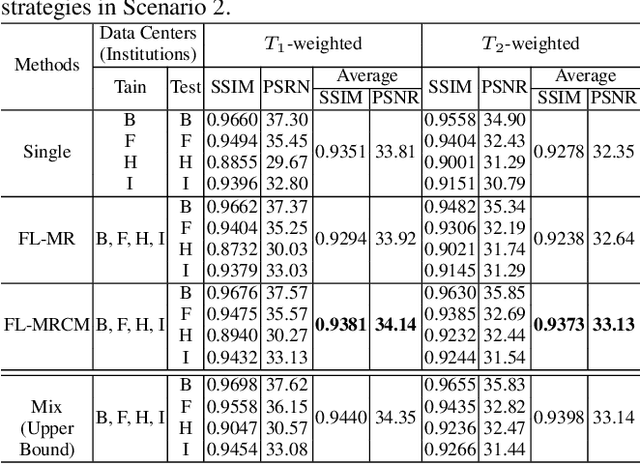
Fast and accurate reconstruction of magnetic resonance (MR) images from under-sampled data is important in many clinical applications. In recent years, deep learning-based methods have been shown to produce superior performance on MR image reconstruction. However, these methods require large amounts of data which is difficult to collect and share due to the high cost of acquisition and medical data privacy regulations. In order to overcome this challenge, we propose a federated learning (FL) based solution in which we take advantage of the MR data available at different institutions while preserving patients' privacy. However, the generalizability of models trained with the FL setting can still be suboptimal due to domain shift, which results from the data collected at multiple institutions with different sensors, disease types, and acquisition protocols, etc. With the motivation of circumventing this challenge, we propose a cross-site modeling for MR image reconstruction in which the learned intermediate latent features among different source sites are aligned with the distribution of the latent features at the target site. Extensive experiments are conducted to provide various insights about FL for MR image reconstruction. Experimental results demonstrate that the proposed framework is a promising direction to utilize multi-institutional data without compromising patients' privacy for achieving improved MR image reconstruction. Our code will be available at https://github.com/guopengf/FLMRCM.
An Interactive Explanatory AI System for Industrial Quality Control
Mar 17, 2022Machine learning based image classification algorithms, such as deep neural network approaches, will be increasingly employed in critical settings such as quality control in industry, where transparency and comprehensibility of decisions are crucial. Therefore, we aim to extend the defect detection task towards an interactive human-in-the-loop approach that allows us to integrate rich background knowledge and the inference of complex relationships going beyond traditional purely data-driven approaches. We propose an approach for an interactive support system for classifications in an industrial quality control setting that combines the advantages of both (explainable) knowledge-driven and data-driven machine learning methods, in particular inductive logic programming and convolutional neural networks, with human expertise and control. The resulting system can assist domain experts with decisions, provide transparent explanations for results, and integrate feedback from users; thus reducing workload for humans while both respecting their expertise and without removing their agency or accountability.
Towards Domain Invariant Single Image Dehazing
Jan 09, 2021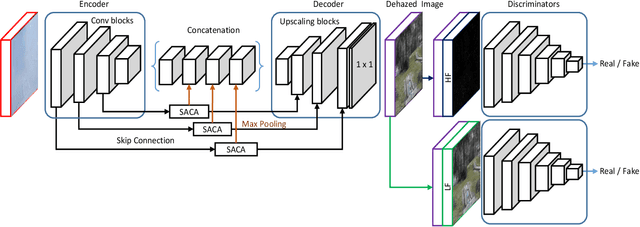
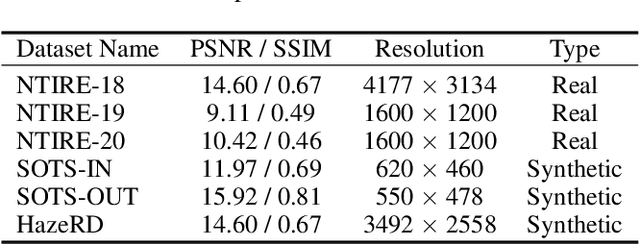

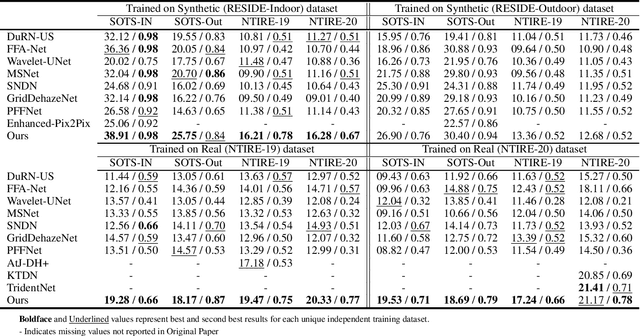
Presence of haze in images obscures underlying information, which is undesirable in applications requiring accurate environment information. To recover such an image, a dehazing algorithm should localize and recover affected regions while ensuring consistency between recovered and its neighboring regions. However owing to fixed receptive field of convolutional kernels and non uniform haze distribution, assuring consistency between regions is difficult. In this paper, we utilize an encoder-decoder based network architecture to perform the task of dehazing and integrate an spatially aware channel attention mechanism to enhance features of interest beyond the receptive field of traditional conventional kernels. To ensure performance consistency across diverse range of haze densities, we utilize greedy localized data augmentation mechanism. Synthetic datasets are typically used to ensure a large amount of paired training samples, however the methodology to generate such samples introduces a gap between them and real images while accounting for only uniform haze distribution and overlooking more realistic scenario of non-uniform haze distribution resulting in inferior dehazing performance when evaluated on real datasets. Despite this, the abundance of paired samples within synthetic datasets cannot be ignored. Thus to ensure performance consistency across diverse datasets, we train the proposed network within an adversarial prior-guided framework that relies on a generated image along with its low and high frequency components to determine if properties of dehazed images matches those of ground truth. We preform extensive experiments to validate the dehazing and domain invariance performance of proposed framework across diverse domains and report state-of-the-art (SoTA) results.
Birds of A Feather Flock Together: Category-Divergence Guidance for Domain Adaptive Segmentation
Apr 05, 2022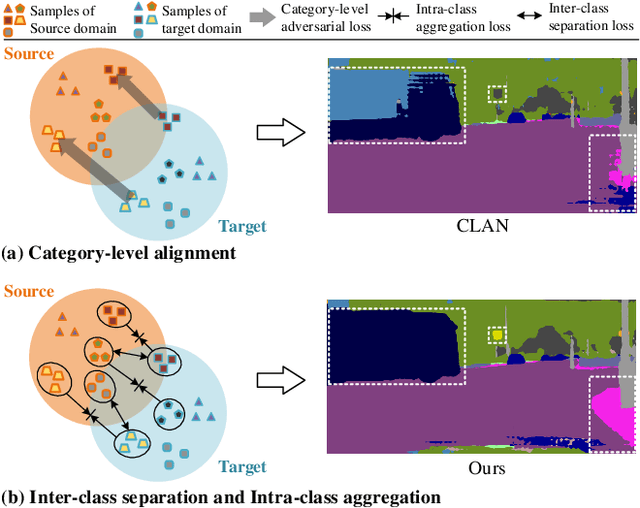

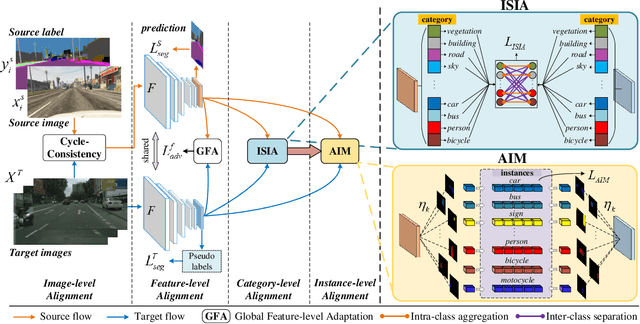
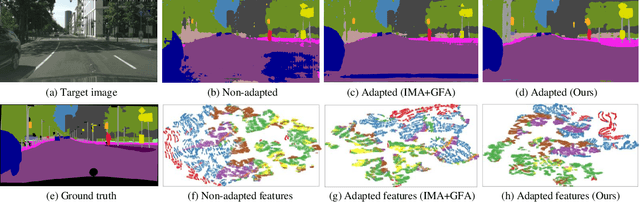
Unsupervised domain adaptation (UDA) aims to enhance the generalization capability of a certain model from a source domain to a target domain. Present UDA models focus on alleviating the domain shift by minimizing the feature discrepancy between the source domain and the target domain but usually ignore the class confusion problem. In this work, we propose an Inter-class Separation and Intra-class Aggregation (ISIA) mechanism. It encourages the cross-domain representative consistency between the same categories and differentiation among diverse categories. In this way, the features belonging to the same categories are aligned together and the confusable categories are separated. By measuring the align complexity of each category, we design an Adaptive-weighted Instance Matching (AIM) strategy to further optimize the instance-level adaptation. Based on our proposed methods, we also raise a hierarchical unsupervised domain adaptation framework for cross-domain semantic segmentation task. Through performing the image-level, feature-level, category-level and instance-level alignment, our method achieves a stronger generalization performance of the model from the source domain to the target domain. In two typical cross-domain semantic segmentation tasks, i.e., GTA5 to Cityscapes and SYNTHIA to Cityscapes, our method achieves the state-of-the-art segmentation accuracy. We also build two cross-domain semantic segmentation datasets based on the publicly available data, i.e., remote sensing building segmentation and road segmentation, for domain adaptive segmentation.
Slice-Connection Clustering Algorithm for Tree Roots Recognition in Noisy 3D GPR Data
Mar 08, 2022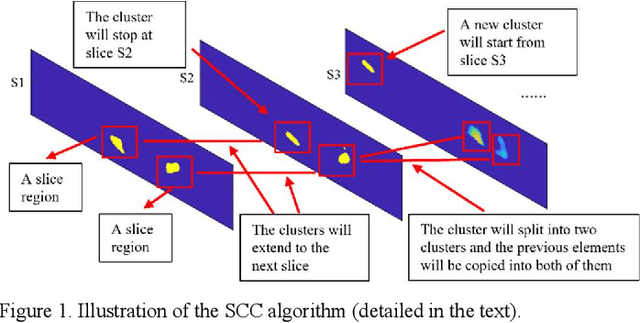
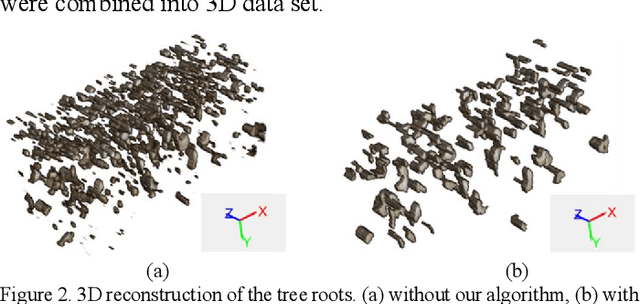

3D mapping of tree roots is a popular ground-penetrating radar (GPR) application. In real field tests, the recognition of tree roots suffers due to noisey reflection patterns from subsurface targets that are not of interest, such as rocks, cavities, soil unevenness, etc. A Slice-Connection Clustering Algorithm (SCC) is applied to separate the regions of interest from each other in a reconstructed 3D image. The proposed method can successfully recognize the radar signatures of the roots and distinguish roots from other objects. Meanwhile, most noise radar features are ignored through our method. The final 3D mapping of the radargram obtained by the method can be used to estimate the location and extension trend of the tree roots. The effectiveness of the proposed system is tested on real GPR data.