 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Realistic Image Normalization for Multi-Domain Segmentation
Oct 01, 2020

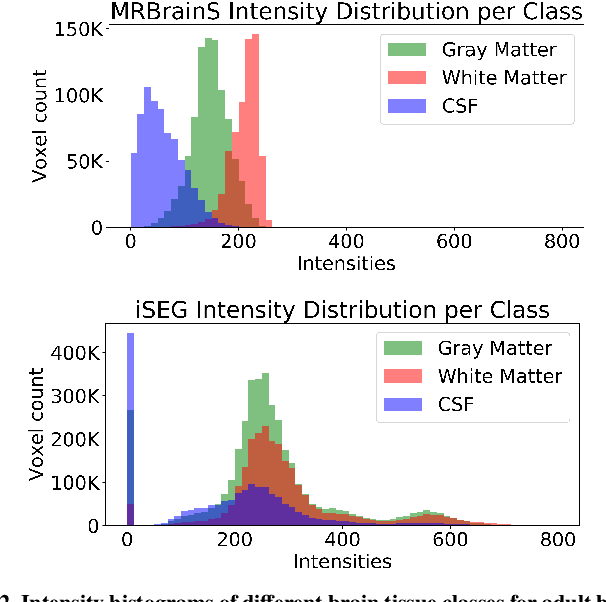
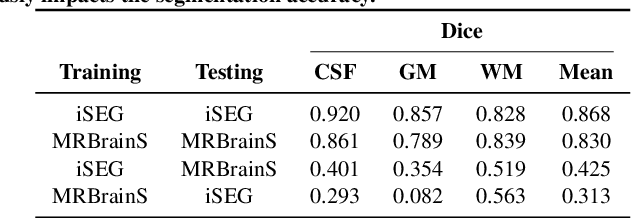
Image normalization is a building block in medical image analysis. Conventional approaches are customarily utilized on a per-dataset basis. This strategy, however, prevents the current normalization algorithms from fully exploiting the complex joint information available across multiple datasets. Consequently, ignoring such joint information has a direct impact on the performance of segmentation algorithms. This paper proposes to revisit the conventional image normalization approach by instead learning a common normalizing function across multiple datasets. Jointly normalizing multiple datasets is shown to yield consistent normalized images as well as an improved image segmentation. To do so, a fully automated adversarial and task-driven normalization approach is employed as it facilitates the training of realistic and interpretable images while keeping performance on-par with the state-of-the-art. The adversarial training of our network aims at finding the optimal transfer function to improve both the segmentation accuracy and the generation of realistic images. We evaluated the performance of our normalizer on both infant and adult brains images from the iSEG, MRBrainS and ABIDE datasets. Results reveal the potential of our normalization approach for segmentation, with Dice improvements of up to 57.5% over our baseline. Our method can also enhance data availability by increasing the number of samples available when learning from multiple imaging domains.
Improving greedy core-set configurations for active learning with uncertainty-scaled distances
Feb 09, 2022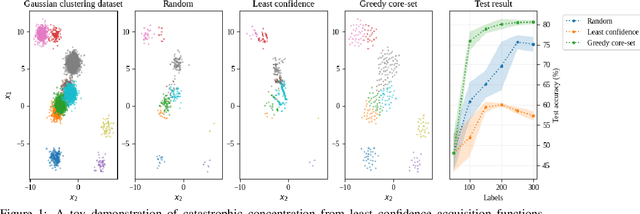
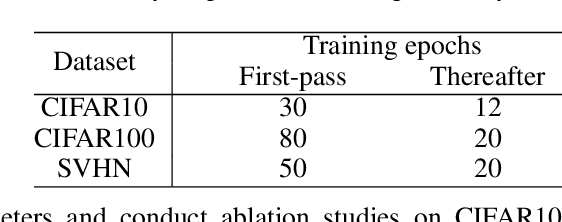
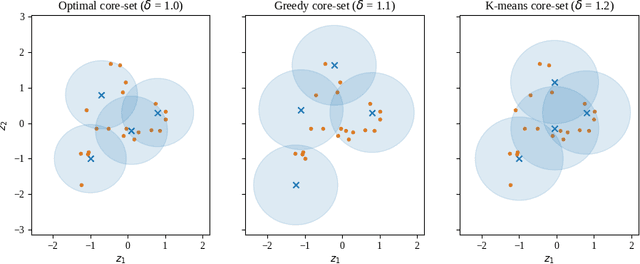
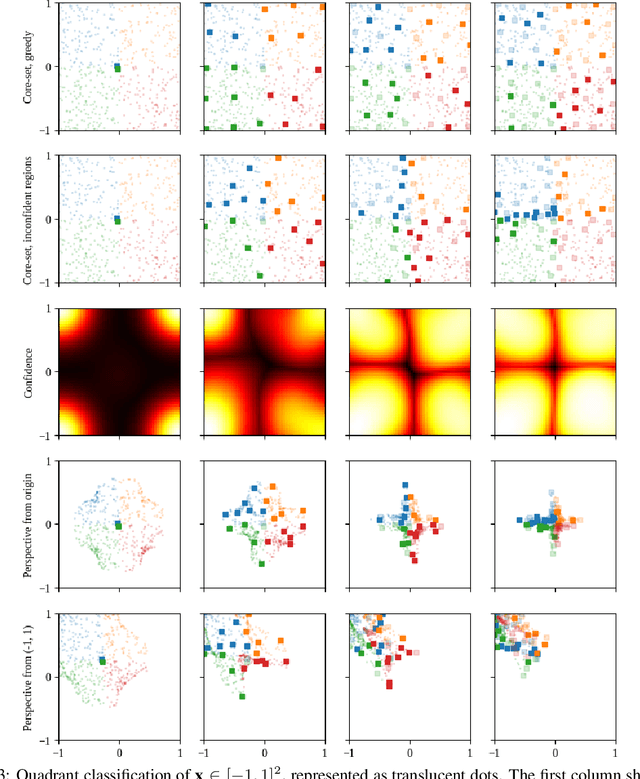
We scale perceived distances of the core-set algorithm by a factor of uncertainty and search for low-confidence configurations, finding significant improvements in sample efficiency across CIFAR10/100 and SVHN image classification, especially in larger acquisition sizes. We show the necessity of our modifications and explain how the improvement is due to a probabilistic quadratic speed-up in the convergence of core-set loss, under assumptions about the relationship of model uncertainty and misclassification.
General framework for reversible data hiding in encrypted image by reserving room before encryption
Mar 28, 2021



In this paper a general framework to adopt different predictors for reversible data hiding in encrypted image is presented. We propose innovative predictors that contribute more significantly than conventional ones results in accomplishing more payload. Reserving room before encryption (RRBE) is designated in the proposed scheme to make possible attaining high embedding capacity. In RRBE procedure, pre-processing is allowed before image encryption. In our scheme, pre-processing comprises of three main steps of computing prediction-errors, blocking and labeling of the errors. By blocking we obviate the need for lossless compression to when content-owner is not enthusiastic. Lossless compression is employed in recent state of the art schemes to improve payload. We surpass prior arts exploiting more proper predictors, more efficient labeling procedure and blocking
VisualCheXbert: Addressing the Discrepancy Between Radiology Report Labels and Image Labels
Mar 15, 2021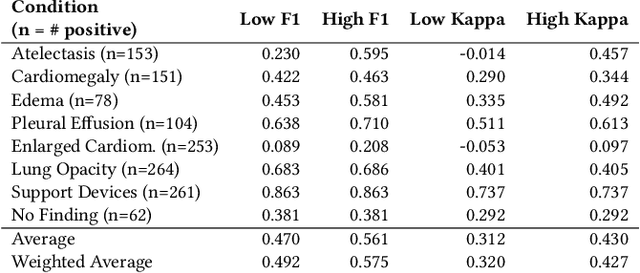
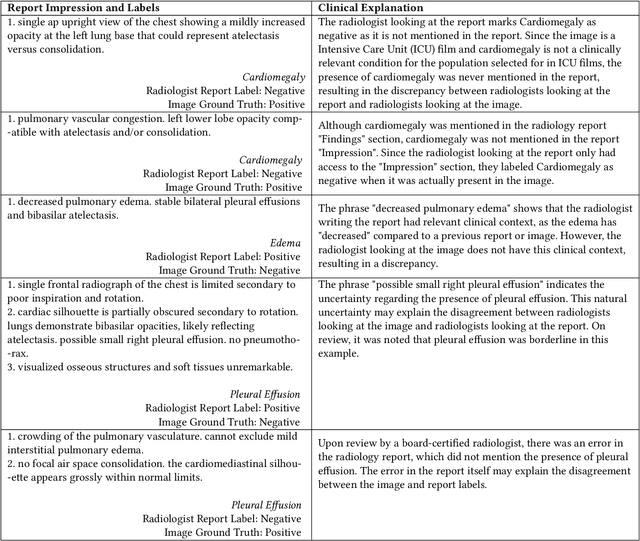
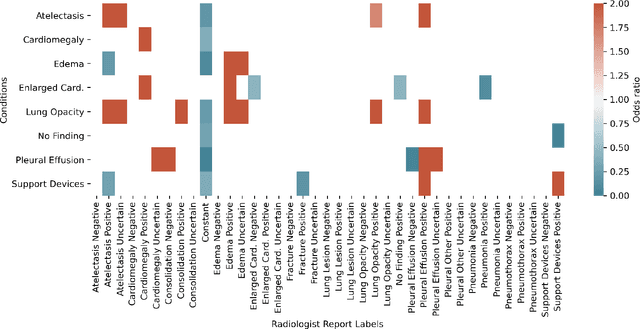
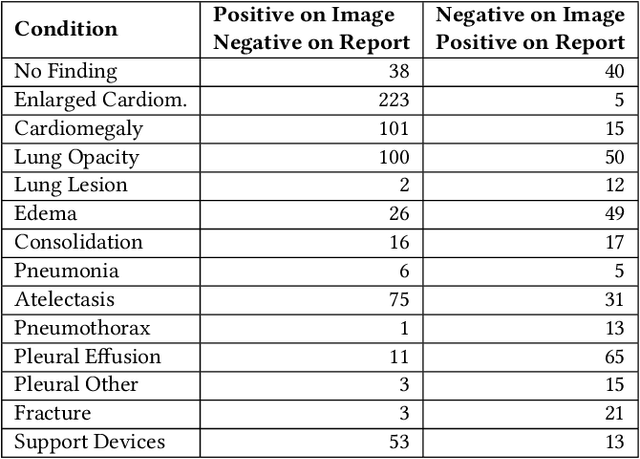
Automatic extraction of medical conditions from free-text radiology reports is critical for supervising computer vision models to interpret medical images. In this work, we show that radiologists labeling reports significantly disagree with radiologists labeling corresponding chest X-ray images, which reduces the quality of report labels as proxies for image labels. We develop and evaluate methods to produce labels from radiology reports that have better agreement with radiologists labeling images. Our best performing method, called VisualCheXbert, uses a biomedically-pretrained BERT model to directly map from a radiology report to the image labels, with a supervisory signal determined by a computer vision model trained to detect medical conditions from chest X-ray images. We find that VisualCheXbert outperforms an approach using an existing radiology report labeler by an average F1 score of 0.14 (95% CI 0.12, 0.17). We also find that VisualCheXbert better agrees with radiologists labeling chest X-ray images than do radiologists labeling the corresponding radiology reports by an average F1 score across several medical conditions of between 0.12 (95% CI 0.09, 0.15) and 0.21 (95% CI 0.18, 0.24).
Super-Resolved Microbubble Localization in Single-Channel Ultrasound RF Signals Using Deep Learning
Apr 09, 2022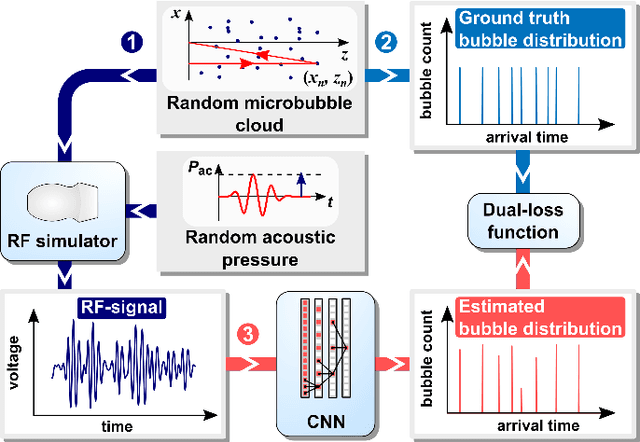
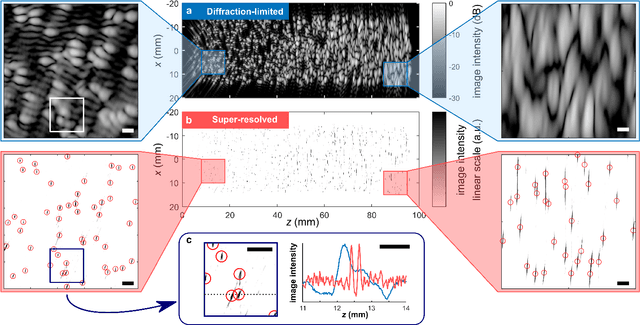
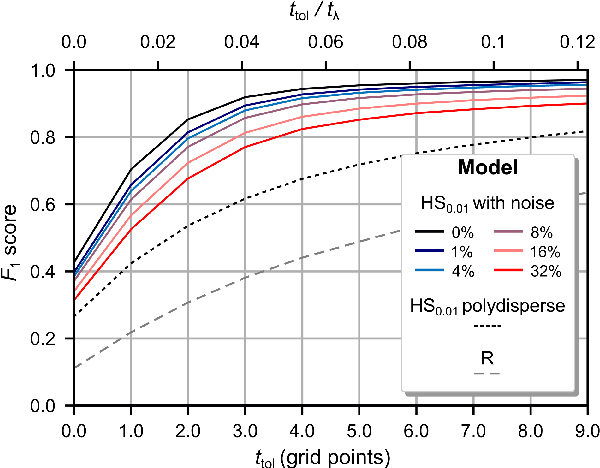
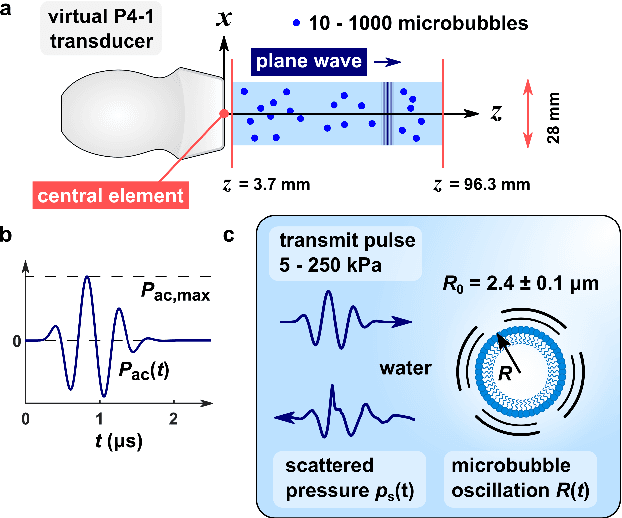
Recently, super-resolution ultrasound imaging with ultrasound localization microscopy (ULM) has received much attention. However, ULM relies on low concentrations of microbubbles in the blood vessels, ultimately resulting in long acquisition times. Here, we present an alternative super-resolution approach, based on direct deconvolution of single-channel ultrasound radio-frequency (RF) signals with a one-dimensional dilated convolutional neural network (CNN). This work focuses on low-frequency ultrasound (1.7 MHz) for deep imaging (10 cm) of a dense cloud of monodisperse microbubbles (up to 1000 microbubbles in the measurement volume, corresponding to an average echo overlap of 94%). Data are generated with a simulator that uses a large range of acoustic pressures (5-250 kPa) and captures the full, nonlinear response of resonant, lipid-coated microbubbles. The network is trained with a novel dual-loss function, which features elements of both a classification loss and a regression loss and improves the detection-localization characteristics of the output. Whereas imposing a localization tolerance of 0 yields poor detection metrics, imposing a localization tolerance corresponding to 4% of the wavelength yields a precision and recall of both 0.90. Furthermore, the detection improves with increasing acoustic pressure and deteriorates with increasing microbubble density. The potential of the presented approach to super-resolution ultrasound imaging is demonstrated with a delay-and-sum reconstruction with deconvolved element data. The resulting image shows an order-of-magnitude gain in axial resolution compared to a delay-and-sum reconstruction with unprocessed element data.
DetMatch: Two Teachers are Better Than One for Joint 2D and 3D Semi-Supervised Object Detection
Mar 17, 2022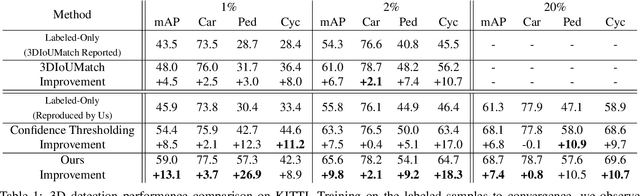
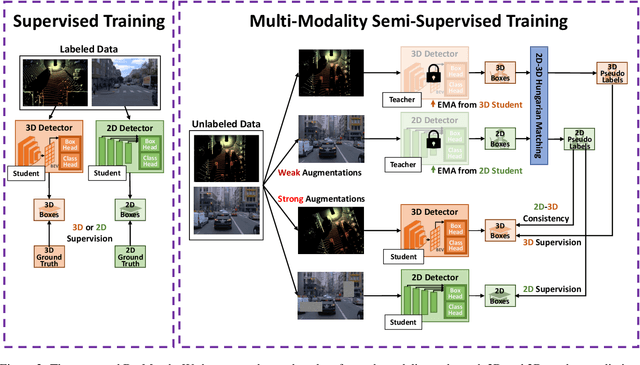

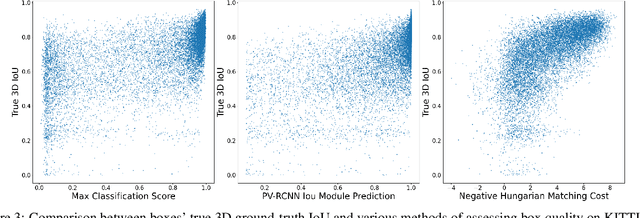
While numerous 3D detection works leverage the complementary relationship between RGB images and point clouds, developments in the broader framework of semi-supervised object recognition remain uninfluenced by multi-modal fusion. Current methods develop independent pipelines for 2D and 3D semi-supervised learning despite the availability of paired image and point cloud frames. Observing that the distinct characteristics of each sensor cause them to be biased towards detecting different objects, we propose DetMatch, a flexible framework for joint semi-supervised learning on 2D and 3D modalities. By identifying objects detected in both sensors, our pipeline generates a cleaner, more robust set of pseudo-labels that both demonstrates stronger performance and stymies single-modality error propagation. Further, we leverage the richer semantics of RGB images to rectify incorrect 3D class predictions and improve localization of 3D boxes. Evaluating on the challenging KITTI and Waymo datasets, we improve upon strong semi-supervised learning methods and observe higher quality pseudo-labels. Code will be released at https://github.com/Divadi/DetMatch
Unsupervised Clustering of Roman Potsherds via Variational Autoencoders
Mar 14, 2022
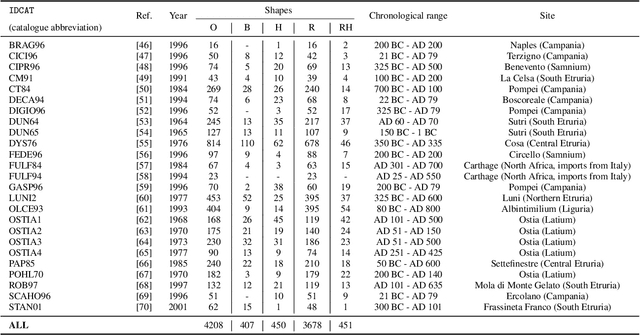
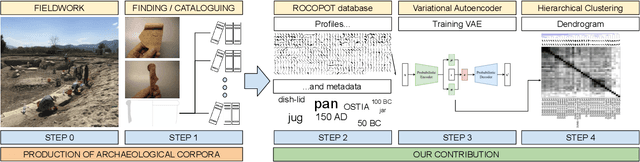
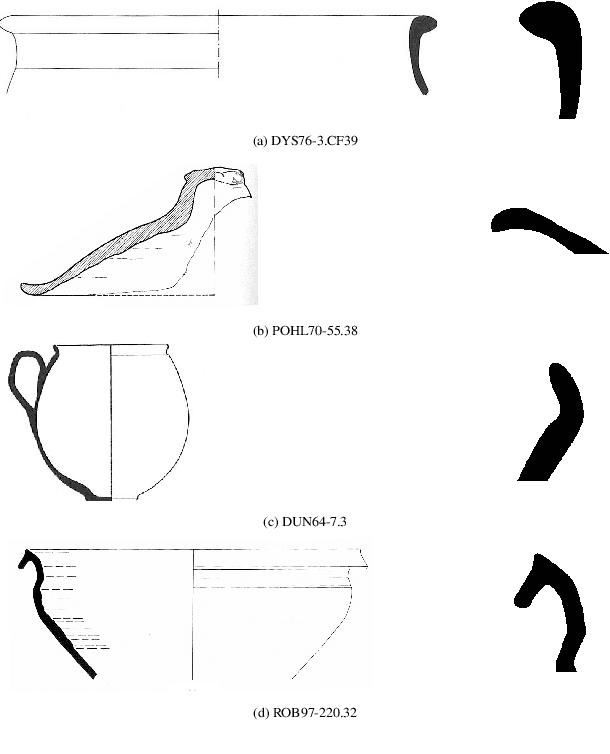
In this paper we propose an artificial intelligence imaging solution to support archaeologists in the classification task of Roman commonware potsherds. Usually, each potsherd is represented by its sectional profile as a two dimensional black-white image and printed in archaeological books related to specific archaeological excavations. The partiality and handcrafted variance of the fragments make their matching a challenging problem: we propose to pair similar profiles via the unsupervised hierarchical clustering of non-linear features learned in the latent space of a deep convolutional Variational Autoencoder (VAE) network. Our contribution also include the creation of a ROman COmmonware POTtery (ROCOPOT) database, with more than 4000 potsherds profiles extracted from 25 Roman pottery corpora, and a MATLAB GUI software for the easy inspection of shape similarities. Results are commented both from a mathematical and archaeological perspective so as to unlock new research directions in both communities.
Multi-institutional Collaborations for Improving Deep Learning-based Magnetic Resonance Image Reconstruction Using Federated Learning
Mar 10, 2021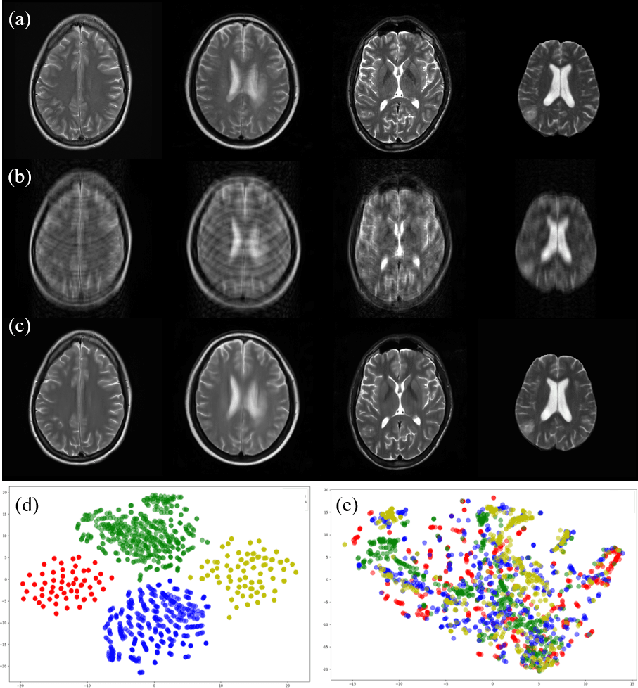
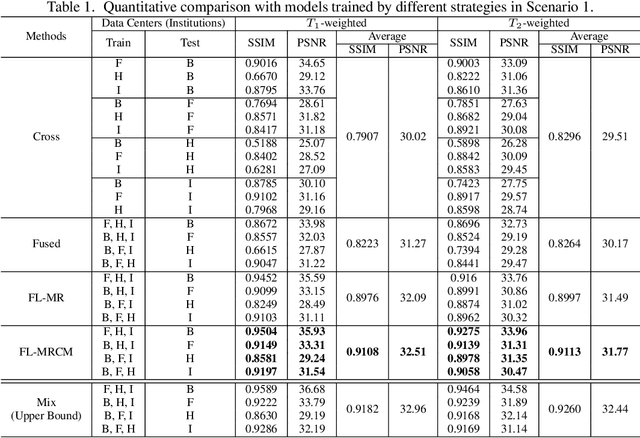
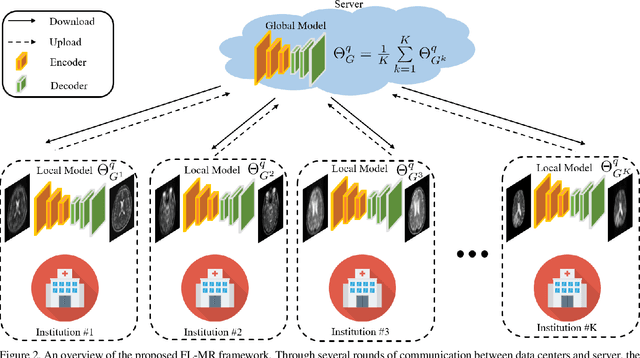
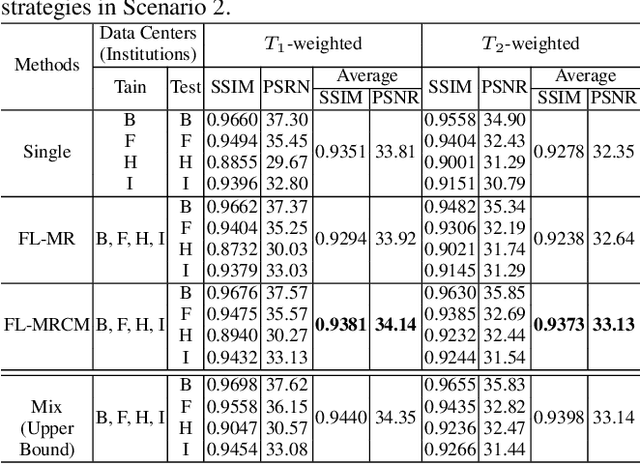
Fast and accurate reconstruction of magnetic resonance (MR) images from under-sampled data is important in many clinical applications. In recent years, deep learning-based methods have been shown to produce superior performance on MR image reconstruction. However, these methods require large amounts of data which is difficult to collect and share due to the high cost of acquisition and medical data privacy regulations. In order to overcome this challenge, we propose a federated learning (FL) based solution in which we take advantage of the MR data available at different institutions while preserving patients' privacy. However, the generalizability of models trained with the FL setting can still be suboptimal due to domain shift, which results from the data collected at multiple institutions with different sensors, disease types, and acquisition protocols, etc. With the motivation of circumventing this challenge, we propose a cross-site modeling for MR image reconstruction in which the learned intermediate latent features among different source sites are aligned with the distribution of the latent features at the target site. Extensive experiments are conducted to provide various insights about FL for MR image reconstruction. Experimental results demonstrate that the proposed framework is a promising direction to utilize multi-institutional data without compromising patients' privacy for achieving improved MR image reconstruction. Our code will be available at https://github.com/guopengf/FLMRCM.
Human-Object Interaction Detection via Weak Supervision
Dec 01, 2021

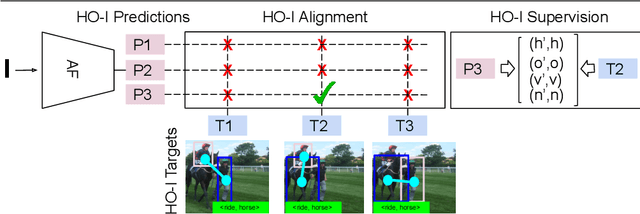
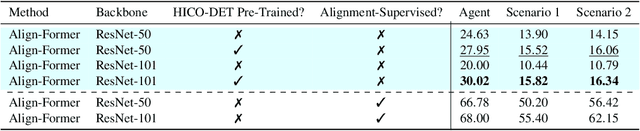
The goal of this paper is Human-object Interaction (HO-I) detection. HO-I detection aims to find interacting human-objects regions and classify their interaction from an image. Researchers obtain significant improvement in recent years by relying on strong HO-I alignment supervision from [5]. HO-I alignment supervision pairs humans with their interacted objects, and then aligns human-object pair(s) with their interaction categories. Since collecting such annotation is expensive, in this paper, we propose to detect HO-I without alignment supervision. We instead rely on image-level supervision that only enumerates existing interactions within the image without pointing where they happen. Our paper makes three contributions: i) We propose Align-Former, a visual-transformer based CNN that can detect HO-I with only image-level supervision. ii) Align-Former is equipped with HO-I align layer, that can learn to select appropriate targets to allow detector supervision. iii) We evaluate Align-Former on HICO-DET [5] and V-COCO [13], and show that Align-Former outperforms existing image-level supervised HO-I detectors by a large margin (4.71% mAP improvement from 16.14% to 20.85% on HICO-DET [5]).
Fine Detailed Texture Learning for 3D Meshes with Generative Models
Mar 17, 2022
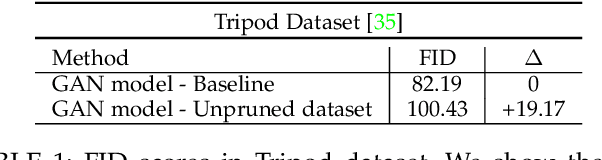
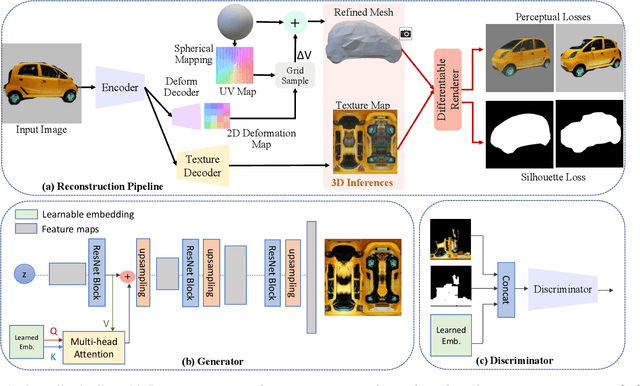

This paper presents a method to reconstruct high-quality textured 3D models from both multi-view and single-view images. The reconstruction is posed as an adaptation problem and is done progressively where in the first stage, we focus on learning accurate geometry, whereas in the second stage, we focus on learning the texture with a generative adversarial network. In the generative learning pipeline, we propose two improvements. First, since the learned textures should be spatially aligned, we propose an attention mechanism that relies on the learnable positions of pixels. Secondly, since discriminator receives aligned texture maps, we augment its input with a learnable embedding which improves the feedback to the generator. We achieve significant improvements on multi-view sequences from Tripod dataset as well as on single-view image datasets, Pascal 3D+ and CUB. We demonstrate that our method achieves superior 3D textured models compared to the previous works. Please visit our web-page for 3D visuals.