 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explaining Deep Convolutional Neural Networks via Latent Visual-Semantic Filter Attention
Apr 10, 2022
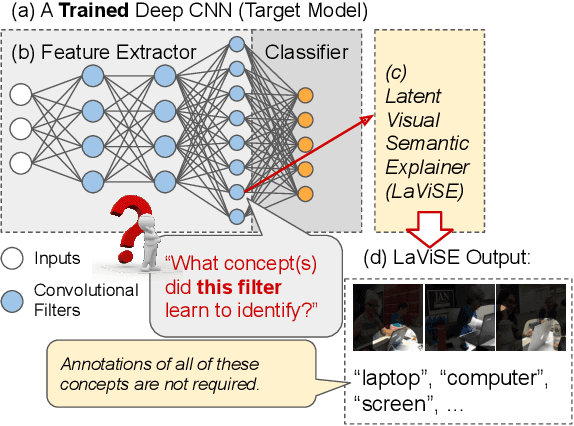
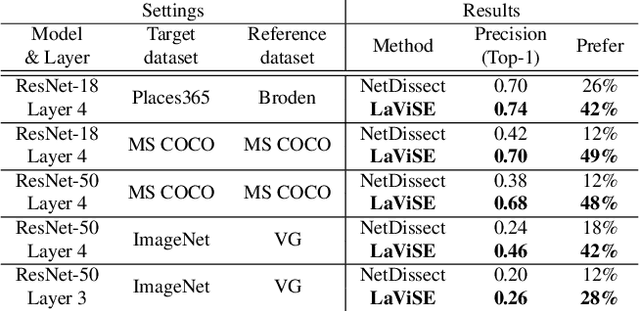
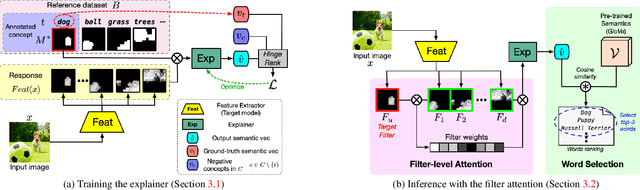
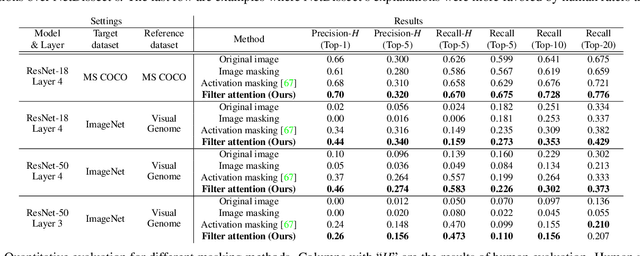
Interpretability is an important property for visual models as it helps researchers and users understand the internal mechanism of a complex model. However, generating semantic explanations about the learned representation is challenging without direct supervision to produce such explanations. We propose a general framework, Latent Visual Semantic Explainer (LaViSE), to teach any existing convolutional neural network to generate text descriptions about its own latent representations at the filter level. Our method constructs a mapping between the visual and semantic spaces using generic image datasets, using images and category names. It then transfers the mapping to the target domain which does not have semantic labels. The proposed framework employs a modular structure and enables to analyze any trained network whether or not its original training data is available. We show that our method can generate novel descriptions for learned filters beyond the set of categories defined in the training dataset and perform an extensive evaluation on multiple datasets. We also demonstrate a novel application of our method for unsupervised dataset bias analysis which allows us to automatically discover hidden biases in datasets or compare different subsets without using additional labels. The dataset and code are made public to facilitate further research.
On Guiding Visual Attention with Language Specification
Feb 17, 2022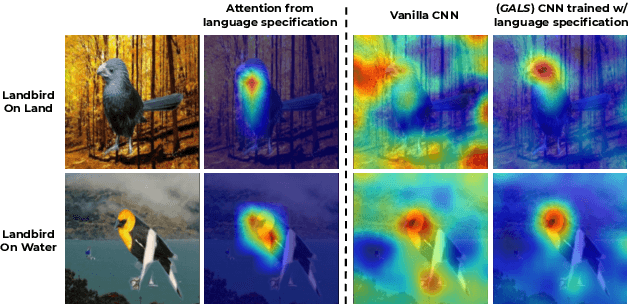

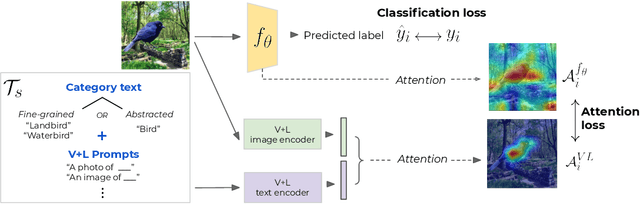
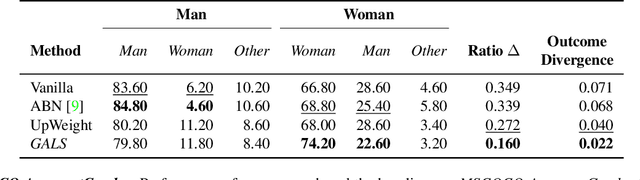
While real world challenges typically define visual categories with language words or phrases, most visual classification methods define categories with numerical indices. However, the language specification of the classes provides an especially useful prior for biased and noisy datasets, where it can help disambiguate what features are task-relevant. Recently, large-scale multimodal models have been shown to recognize a wide variety of high-level concepts from a language specification even without additional image training data, but they are often unable to distinguish classes for more fine-grained tasks. CNNs, in contrast, can extract subtle image features that are required for fine-grained discrimination, but will overfit to any bias or noise in datasets. Our insight is to use high-level language specification as advice for constraining the classification evidence to task-relevant features, instead of distractors. To do this, we ground task-relevant words or phrases with attention maps from a pretrained large-scale model. We then use this grounding to supervise a classifier's spatial attention away from distracting context. We show that supervising spatial attention in this way improves performance on classification tasks with biased and noisy data, including about 3-15% worst-group accuracy improvements and 41-45% relative improvements on fairness metrics.
Quality-Aware Memory Network for Interactive Volumetric Image Segmentation
Jun 20, 2021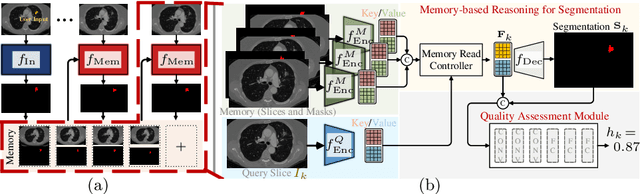
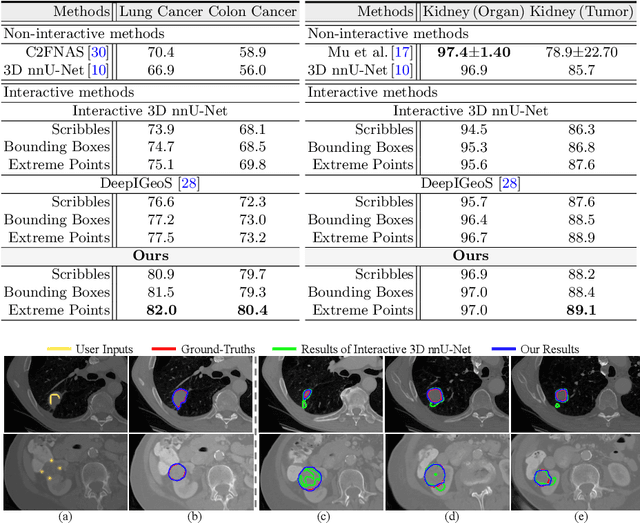
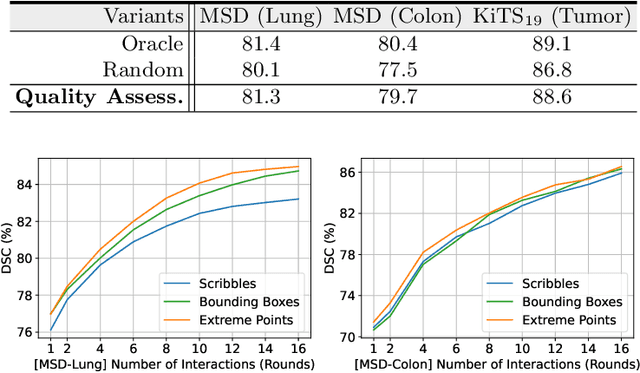
Despite recent progress of automatic medical image segmentation techniques, fully automatic results usually fail to meet the clinical use and typically require further refinement. In this work, we propose a quality-aware memory network for interactive segmentation of 3D medical images. Provided by user guidance on an arbitrary slice, an interaction network is firstly employed to obtain an initial 2D segmentation. The quality-aware memory network subsequently propagates the initial segmentation estimation bidirectionally over the entire volume. Subsequent refinement based on additional user guidance on other slices can be incorporated in the same manner. To further facilitate interactive segmentation, a quality assessment module is introduced to suggest the next slice to segment based on the current segmentation quality of each slice. The proposed network has two appealing characteristics: 1) The memory-augmented network offers the ability to quickly encode past segmentation information, which will be retrieved for the segmentation of other slices; 2) The quality assessment module enables the model to directly estimate the qualities of segmentation predictions, which allows an active learning paradigm where users preferentially label the lowest-quality slice for multi-round refinement. The proposed network leads to a robust interactive segmentation engine, which can generalize well to various types of user annotations (e.g., scribbles, boxes). Experimental results on various medical datasets demonstrate the superiority of our approach in comparison with existing techniques.
OCTOPUS -- optical coherence tomography plaque and stent analysis software
Apr 21, 2022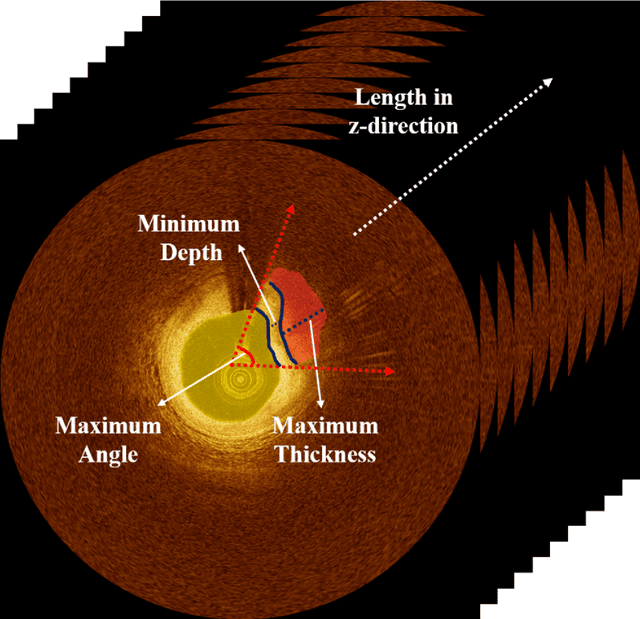
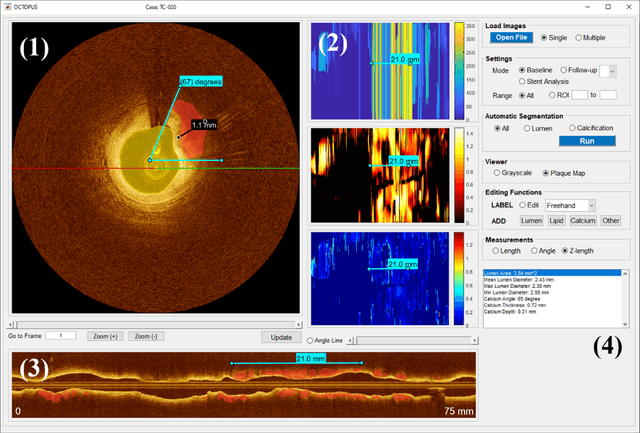
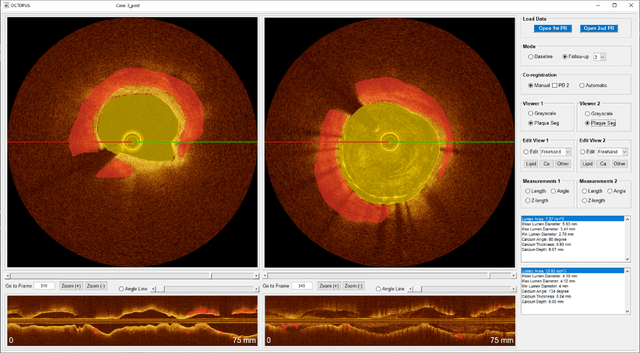
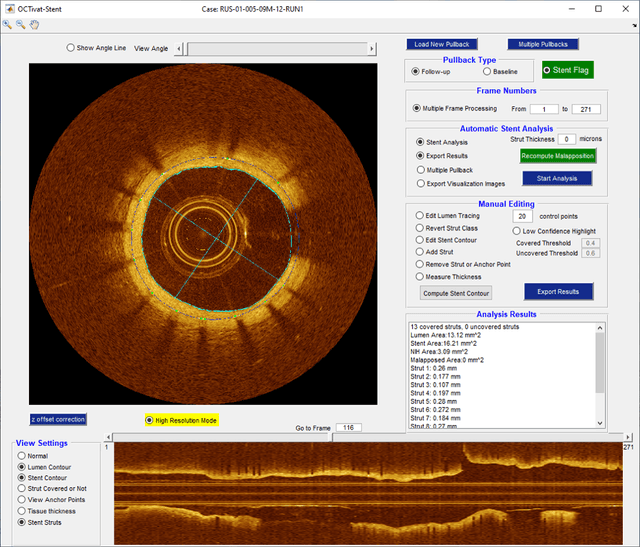
Compared with other imaging modalities, intravascular optical coherence tomography (IVOCT) has significant advantages for guiding percutaneous coronary interventions. To aid IVOCT research studies, we developed the Optical Coherence TOmography PlaqUe and Stent (OCTOPUS) analysis software. To automate image analysis results, the software includes several important algorithmic steps: pre-processing, deep learning plaque segmentation, machine learning identification of stent struts, and registration of pullbacks. Interactive visualization and manual editing of segmentations were included in the software. Quantifications include stent deployment characteristics (e.g., stent strut malapposition), strut level analysis, calcium angle, and calcium thickness measurements. Interactive visualizations include (x,y) anatomical, en face, and longitudinal views with optional overlays. Underlying plaque segmentation algorithm yielded excellent pixel-wise results (86.2% sensitivity and 0.781 F1 score). Using OCTOPUS on 34 new pullbacks, we determined that following automated segmentation, only 13% and 23% of frames needed any manual touch up for detailed lumen and calcification labeling, respectively. Only up to 3.8% of plaque pixels were modified, leading to an average editing time of only 7.5 seconds/frame, an approximately 80% reduction compared to manual analysis. Regarding stent analysis, sensitivity and precision were both greater than 90%, and each strut was successfully classified as either covered or uncovered with high sensitivity (94%) and specificity (90%). We introduced and evaluated the clinical application of a highly automated software package, OCTOPUS, for quantitative plaque and stent analysis in IVOCT images. The software is currently used as an offline tool for research purposes; however, the software's embedded algorithms may also be useful for real-time treatment planning.
Lost in Latent Space: Disentangled Models and the Challenge of Combinatorial Generalisation
Apr 05, 2022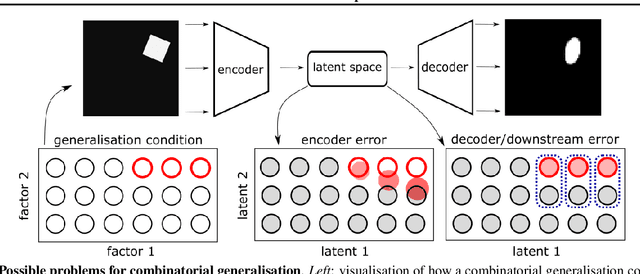
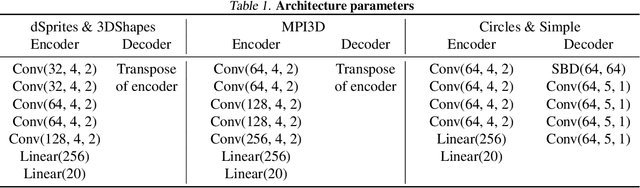
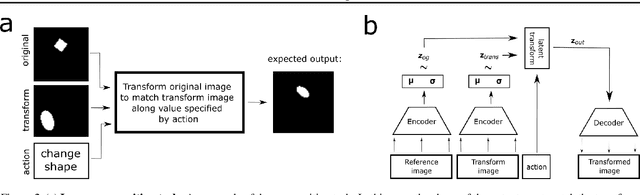
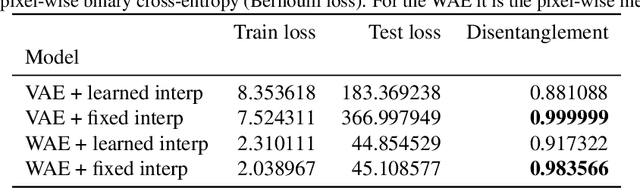
Recent research has shown that generative models with highly disentangled representations fail to generalise to unseen combination of generative factor values. These findings contradict earlier research which showed improved performance in out-of-training distribution settings when compared to entangled representations. Additionally, it is not clear if the reported failures are due to (a) encoders failing to map novel combinations to the proper regions of the latent space or (b) novel combinations being mapped correctly but the decoder/downstream process is unable to render the correct output for the unseen combinations. We investigate these alternatives by testing several models on a range of datasets and training settings. We find that (i) when models fail, their encoders also fail to map unseen combinations to correct regions of the latent space and (ii) when models succeed, it is either because the test conditions do not exclude enough examples, or because excluded generative factors determine independent parts of the output image. Based on these results, we argue that to generalise properly, models not only need to capture factors of variation, but also understand how to invert the generative process that was used to generate the data.
Generative adversarial network for super-resolution imaging through a fiber
Jan 03, 2022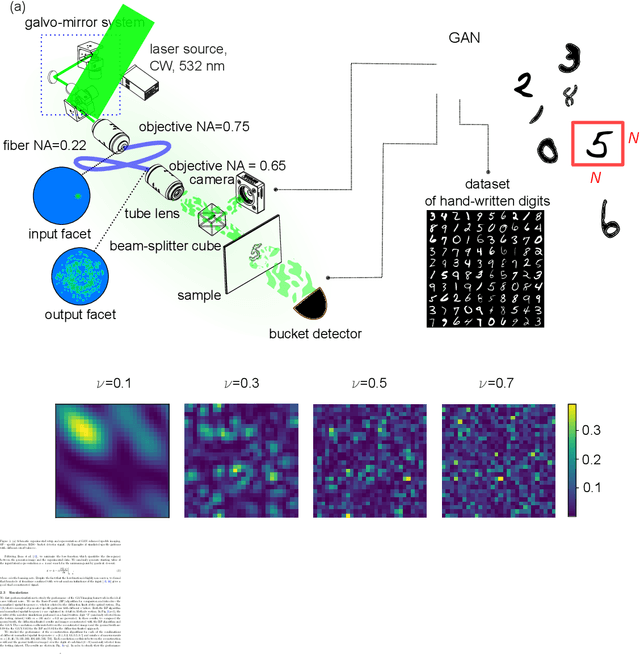
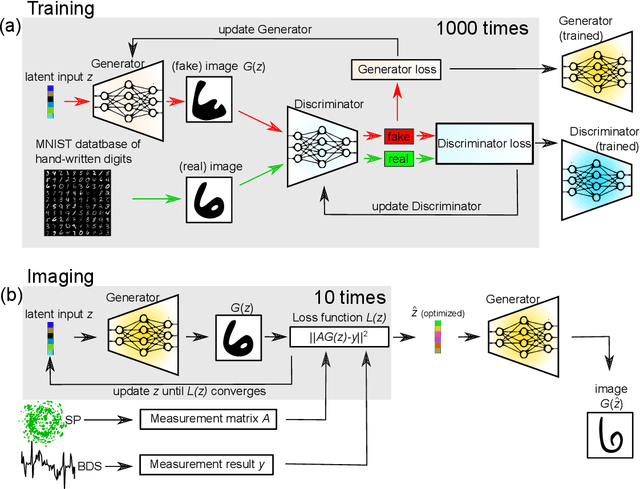
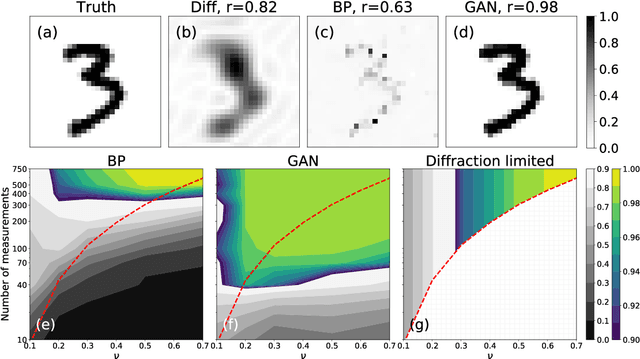
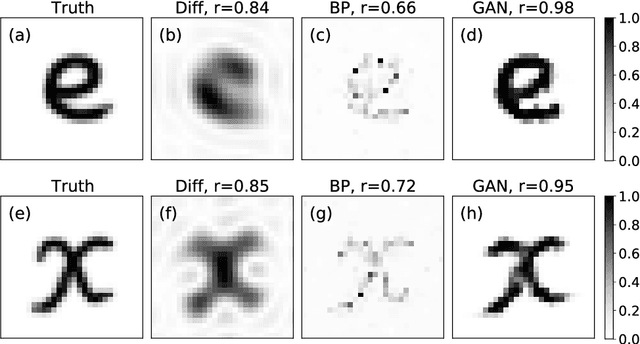
A multimode fiber represents the ultimate limit in miniaturization of imaging endoscopes. Here we propose a fiber imaging approach employing compressive sensing with a data-driven machine learning framework. We implement a generative adversarial network for image reconstruction without relying on a sample sparsity constraint. The proposed method outperforms the conventional compressive imaging algorithms in terms of image quality and noise robustness. We experimentally demonstrate speckle-based imaging below the diffraction limit at a sub-Nyquist speed through a multimode fiber.
Gradient Inversion with Generative Image Prior
Oct 28, 2021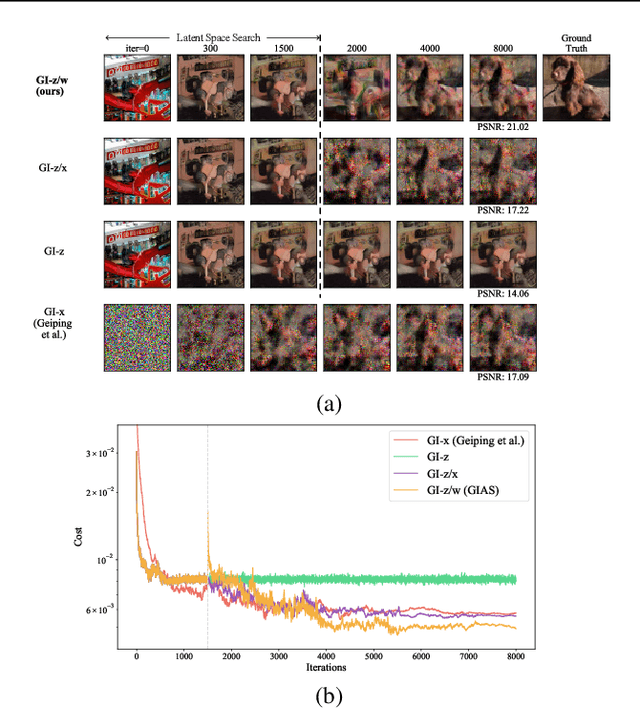

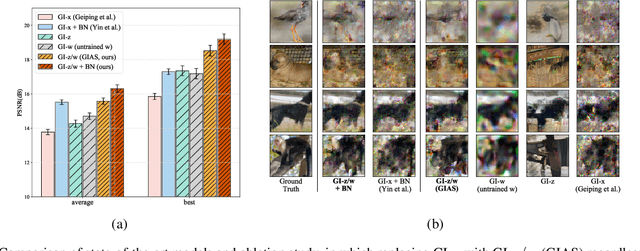
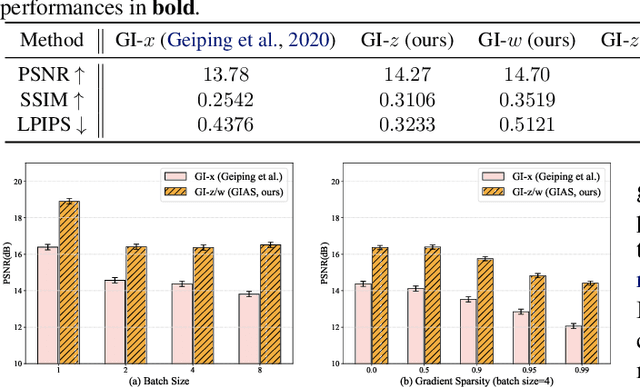
Federated Learning (FL) is a distributed learning framework, in which the local data never leaves clients devices to preserve privacy, and the server trains models on the data via accessing only the gradients of those local data. Without further privacy mechanisms such as differential privacy, this leaves the system vulnerable against an attacker who inverts those gradients to reveal clients sensitive data. However, a gradient is often insufficient to reconstruct the user data without any prior knowledge. By exploiting a generative model pretrained on the data distribution, we demonstrate that data privacy can be easily breached. Further, when such prior knowledge is unavailable, we investigate the possibility of learning the prior from a sequence of gradients seen in the process of FL training. We experimentally show that the prior in a form of generative model is learnable from iterative interactions in FL. Our findings strongly suggest that additional mechanisms are necessary to prevent privacy leakage in FL.
A survey of active learning algorithms for supervised remote sensing image classification
Apr 15, 2021
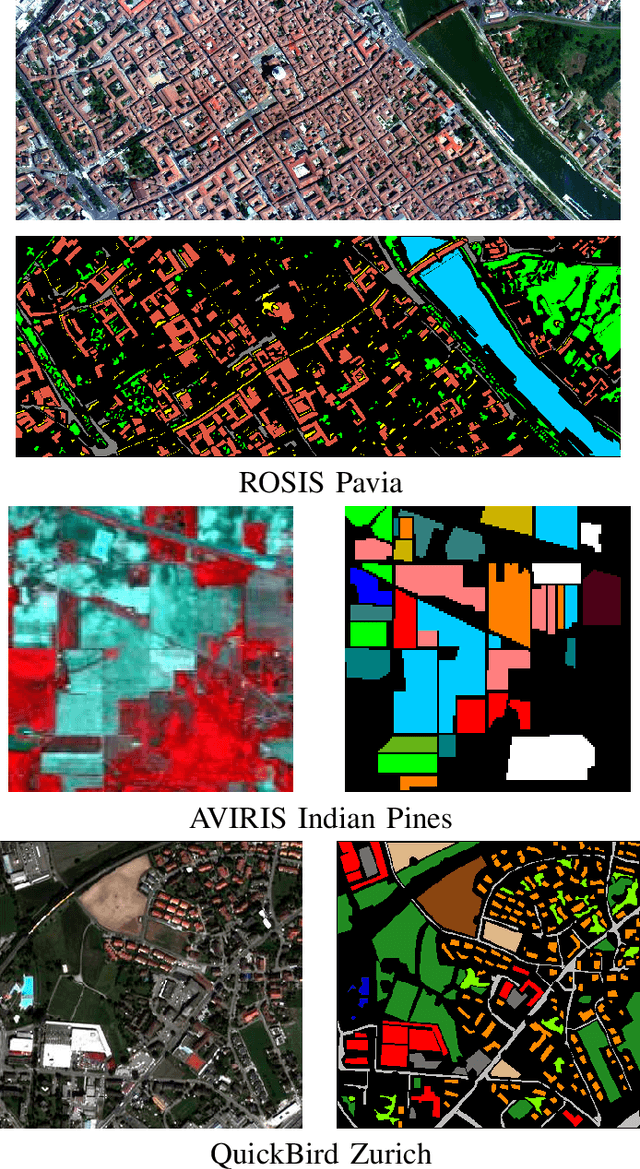

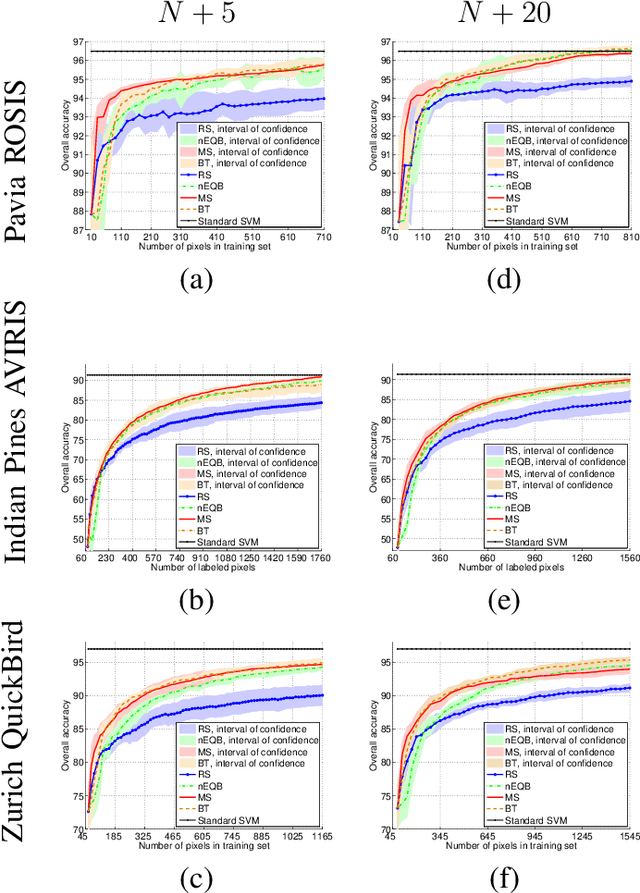
Defining an efficient training set is one of the most delicate phases for the success of remote sensing image classification routines. The complexity of the problem, the limited temporal and financial resources, as well as the high intraclass variance can make an algorithm fail if it is trained with a suboptimal dataset. Active learning aims at building efficient training sets by iteratively improving the model performance through sampling. A user-defined heuristic ranks the unlabeled pixels according to a function of the uncertainty of their class membership and then the user is asked to provide labels for the most uncertain pixels. This paper reviews and tests the main families of active learning algorithms: committee, large margin and posterior probability-based. For each of them, the most recent advances in the remote sensing community are discussed and some heuristics are detailed and tested. Several challenging remote sensing scenarios are considered, including very high spatial resolution and hyperspectral image classification. Finally, guidelines for choosing the good architecture are provided for new and/or unexperienced user.
Optimizing Ghost Imaging via Analysis and Design of Speckle Patterns
Mar 10, 2022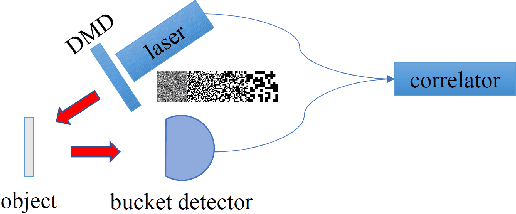



We study the influence rules of the speckle size of light source on ghost imaging, and propose a new type of speckle patterns to improve the quality of ghost imaging. The results show that the image quality will first increase and then decrease with the increase of the speckle size, and there is an optimal speckle size for a specific object. Moreover, by using the random distribution of speckle positions, a new type of displacement speckle patterns is designed, and the imaging quality is better than that of the random speckle patterns. These results are of great significances for finding the best speckle patterns suitable for detecting targets, which further promotes the practical applications of ghost imaging.
Templates for 3D Object Pose Estimation Revisited: Generalization to New Objects and Robustness to Occlusions
Mar 31, 2022


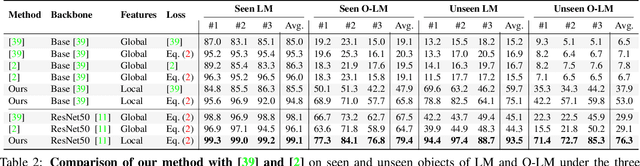
We present a method that can recognize new objects and estimate their 3D pose in RGB images even under partial occlusions. Our method requires neither a training phase on these objects nor real images depicting them, only their CAD models. It relies on a small set of training objects to learn local object representations, which allow us to locally match the input image to a set of "templates", rendered images of the CAD models for the new objects. In contrast with the state-of-the-art methods, the new objects on which our method is applied can be very different from the training objects. As a result, we are the first to show generalization without retraining on the LINEMOD and Occlusion-LINEMOD datasets. Our analysis of the failure modes of previous template-based approaches further confirms the benefits of local features for template matching. We outperform the state-of-the-art template matching methods on the LINEMOD, Occlusion-LINEMOD and T-LESS datasets. Our source code and data are publicly available at https://github.com/nv-nguyen/template-pose