 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Parking Analytics Framework using Deep Learning
Mar 15, 2022
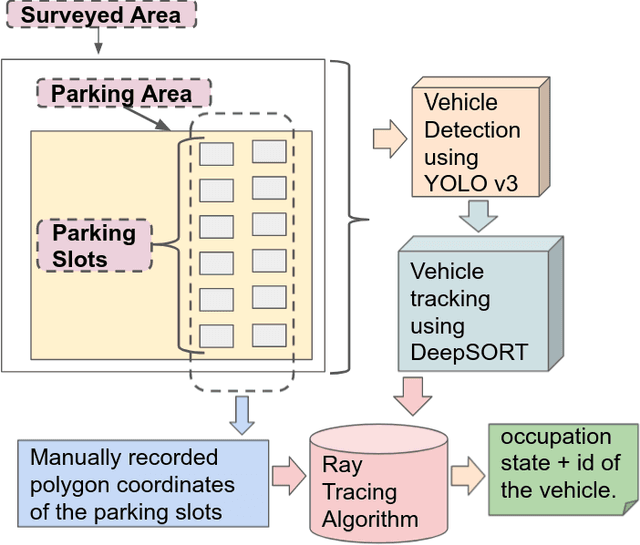
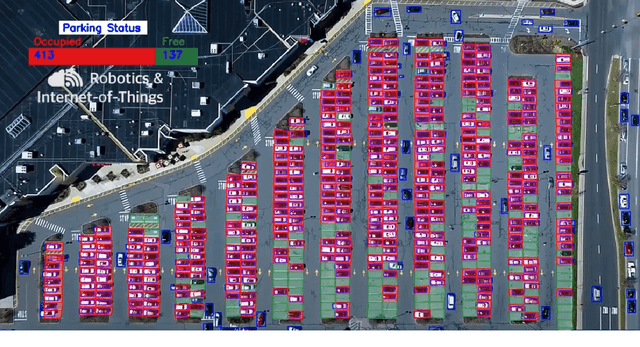
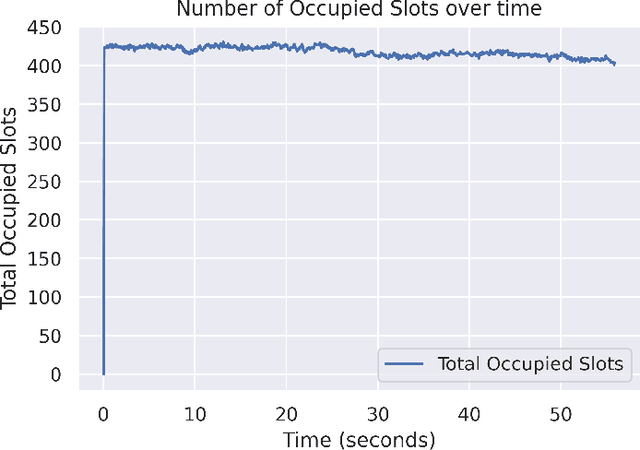
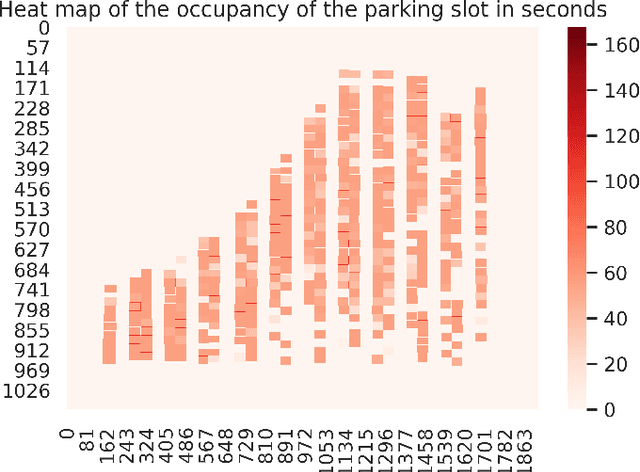
With the number of vehicles continuously increasing, parking monitoring and analysis are becoming a substantial feature of modern cities. In this study, we present a methodology to monitor car parking areas and to analyze their occupancy in real-time. The solution is based on a combination between image analysis and deep learning techniques. It incorporates four building blocks put inside a pipeline: vehicle detection, vehicle tracking, manual annotation of parking slots, and occupancy estimation using the Ray Tracing algorithm. The aim of this methodology is to optimize the use of parking areas and to reduce the time wasted by daily drivers to find the right parking slot for their cars. Also, it helps to better manage the space of the parking areas and to discover misuse cases. A demonstration of the provided solution is shown in the following video link: https://www.youtube.com/watch?v=KbAt8zT14Tc.
Sketch3T: Test-Time Training for Zero-Shot SBIR
Mar 28, 2022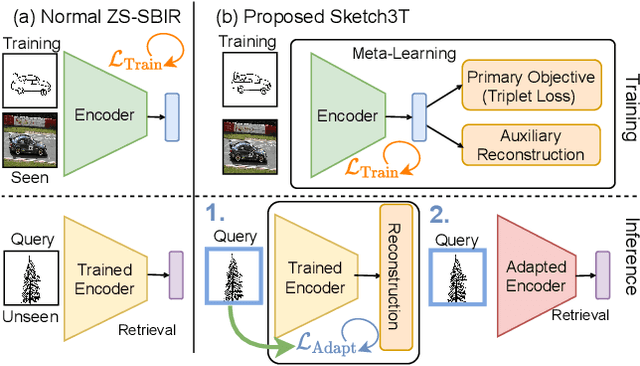
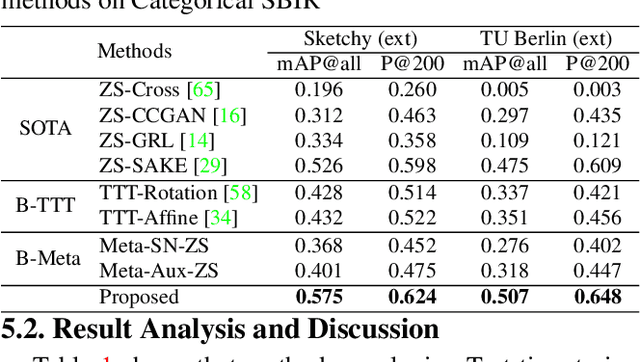
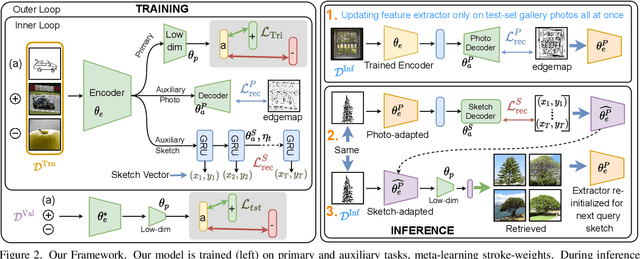
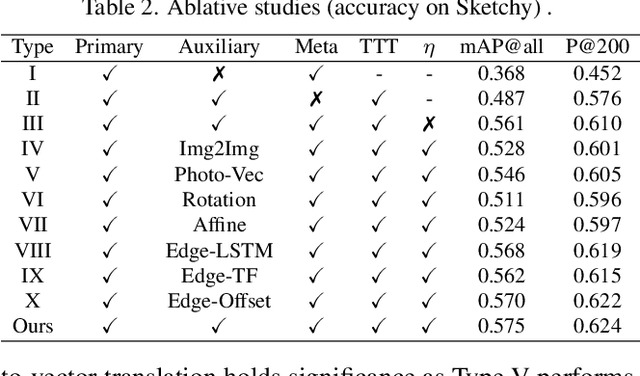
Zero-shot sketch-based image retrieval typically asks for a trained model to be applied as is to unseen categories. In this paper, we question to argue that this setup by definition is not compatible with the inherent abstract and subjective nature of sketches, i.e., the model might transfer well to new categories, but will not understand sketches existing in different test-time distribution as a result. We thus extend ZS-SBIR asking it to transfer to both categories and sketch distributions. Our key contribution is a test-time training paradigm that can adapt using just one sketch. Since there is no paired photo, we make use of a sketch raster-vector reconstruction module as a self-supervised auxiliary task. To maintain the fidelity of the trained cross-modal joint embedding during test-time update, we design a novel meta-learning based training paradigm to learn a separation between model updates incurred by this auxiliary task from those off the primary objective of discriminative learning. Extensive experiments show our model to outperform state of-the-arts, thanks to the proposed test-time adaption that not only transfers to new categories but also accommodates to new sketching styles.
Quality Assessment of Low Light Restored Images: A Subjective Study and an Unsupervised Model
Feb 04, 2022
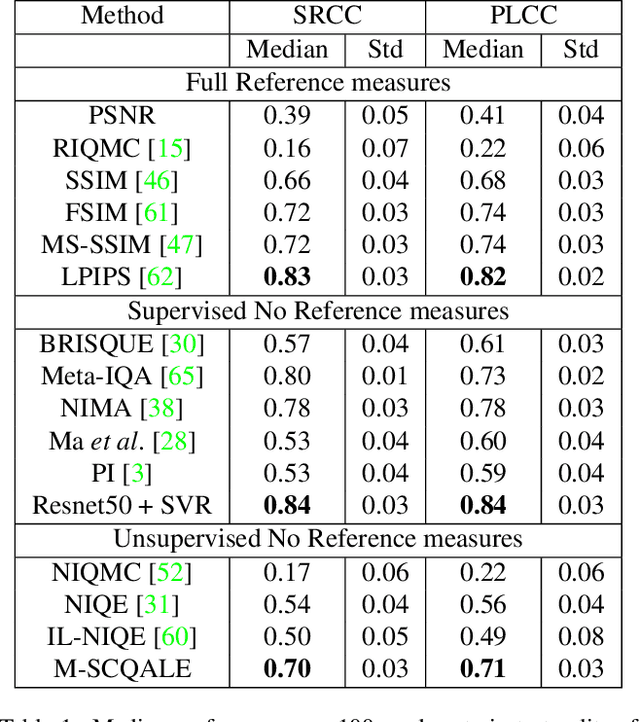
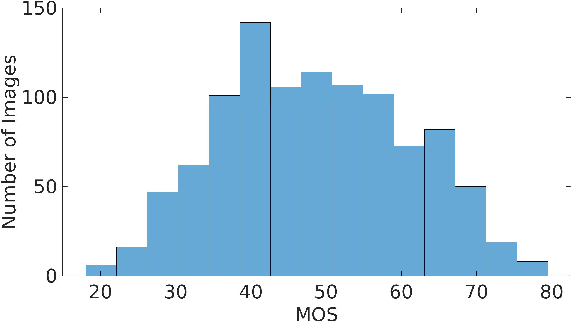

The quality assessment (QA) of restored low light images is an important tool for benchmarking and improving low light restoration (LLR) algorithms. While several LLR algorithms exist, the subjective perception of the restored images has been much less studied. Challenges in capturing aligned low light and well-lit image pairs and collecting a large number of human opinion scores of quality for training, warrant the design of unsupervised (or opinion unaware) no-reference (NR) QA methods. This work studies the subjective perception of low light restored images and their unsupervised NR QA. Our contributions are two-fold. We first create a dataset of restored low light images using various LLR methods, conduct a subjective QA study and benchmark the performance of existing QA methods. We then present a self-supervised contrastive learning technique to extract distortion aware features from the restored low light images. We show that these features can be effectively used to build an opinion unaware image quality analyzer. Detailed experiments reveal that our unsupervised NR QA model achieves state-of-the-art performance among all such quality measures for low light restored images.
Partial-Attribution Instance Segmentation for Astronomical Source Detection and Deblending
Jan 12, 2022
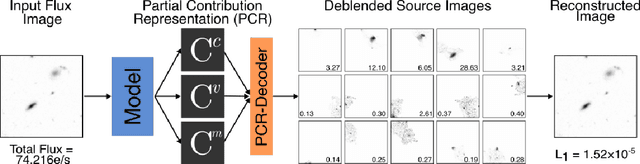
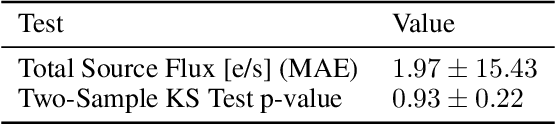
Astronomical source deblending is the process of separating the contribution of individual stars or galaxies (sources) to an image comprised of multiple, possibly overlapping sources. Astronomical sources display a wide range of sizes and brightnesses and may show substantial overlap in images. Astronomical imaging data can further challenge off-the-shelf computer vision algorithms owing to its high dynamic range, low signal-to-noise ratio, and unconventional image format. These challenges make source deblending an open area of astronomical research, and in this work, we introduce a new approach called Partial-Attribution Instance Segmentation that enables source detection and deblending in a manner tractable for deep learning models. We provide a novel neural network implementation as a demonstration of the method.
Auto-Encoding for Shared Cross Domain Feature Representation and Image-to-Image Translation
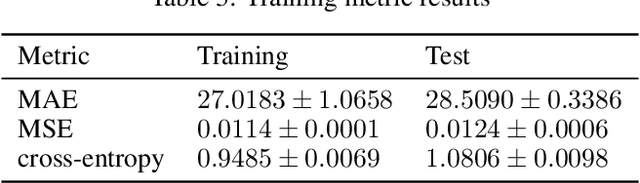
Jun 11, 2020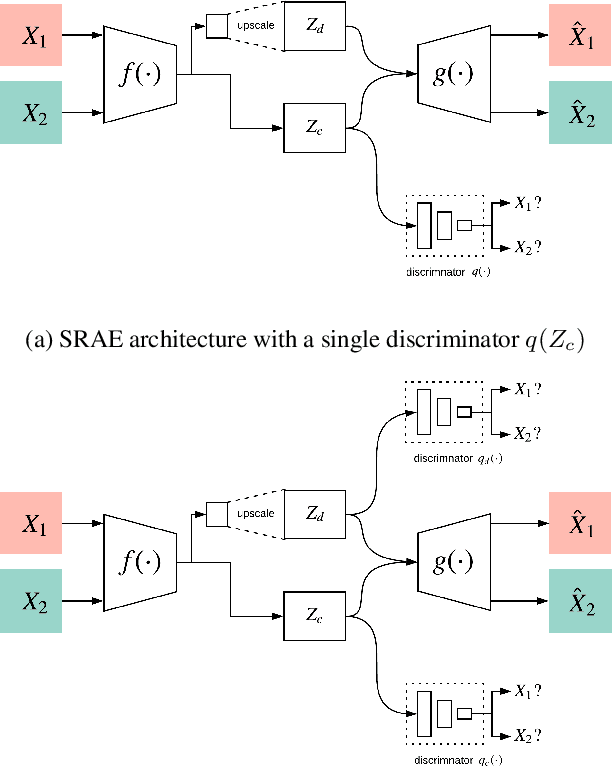
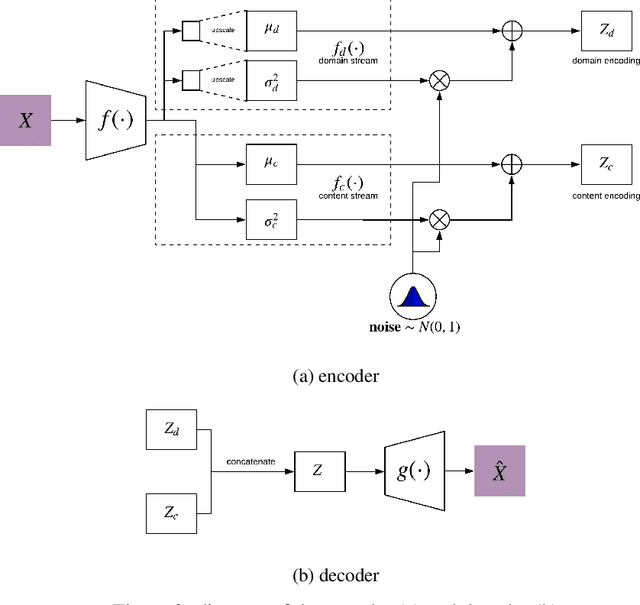
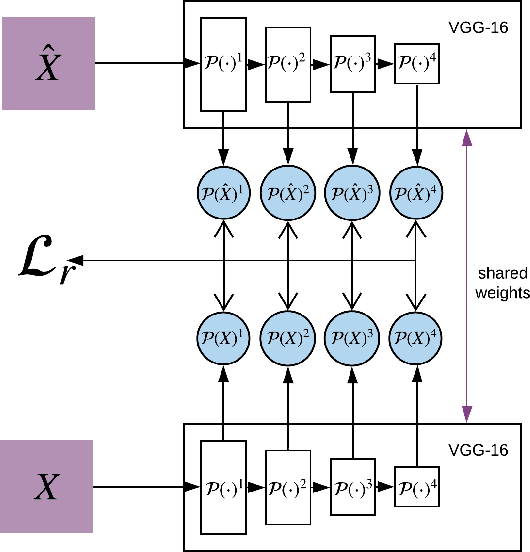

Image-to-image translation is a subset of computer vision and pattern recognition problems where our goal is to learn a mapping between input images of domain $\mathbf{X}_1$ and output images of domain $\mathbf{X}_2$. Current methods use neural networks with an encoder-decoder structure to learn a mapping $G:\mathbf{X}_1 \to\mathbf{X}_2$ such that the distribution of images from $\mathbf{X}_2$ and $G(\mathbf{X}_1)$ are identical, where $G(\mathbf{X}_1) = d_G (f_G (\mathbf{X}_1))$ and $f_G (\cdot)$ is referred as the encoder and $d_G(\cdot)$ is referred to as the decoder. Currently, such methods which also compute an inverse mapping $F:\mathbf{X}_2 \to \mathbf{X}_1$ use a separate encoder-decoder pair $d_F (f_F (\mathbf{X}_2))$ or at least a separate decoder $d_F (\cdot)$ to do so. Here we introduce a method to perform cross domain image-to-image translation across multiple domains using a single encoder-decoder architecture. We use an auto-encoder network which given an input image $\mathbf{X}_1$, first computes a latent domain encoding $Z_d = f_d (\mathbf{X}_1)$ and a latent content encoding $Z_c = f_c (\mathbf{X}_1)$, where the domain encoding $Z_d$ and content encoding $Z_c$ are independent. And then a decoder network $g(Z_d,Z_c)$ creates a reconstruction of the original image $\mathbf{\widehat{X}}_1=g(Z_d,Z_c )\approx \mathbf{X}_1$. Ideally, the domain encoding $Z_d$ contains no information regarding the content of the image and the content encoding $Z_c$ contains no information regarding the domain of the image. We use this property of the encodings to find the mapping across domains $G: X\to Y$ by simply changing the domain encoding $Z_d$ of the decoder's input. $G(\mathbf{X}_1 )=d(f_d (\mathbf{x}_2^i ),f_c (\mathbf{X}_1))$ where $\mathbf{x}_2^i$ is the $i^{th}$ observation of $\mathbf{X}_2$.
Probabilistic Embeddings Revisited
Feb 14, 2022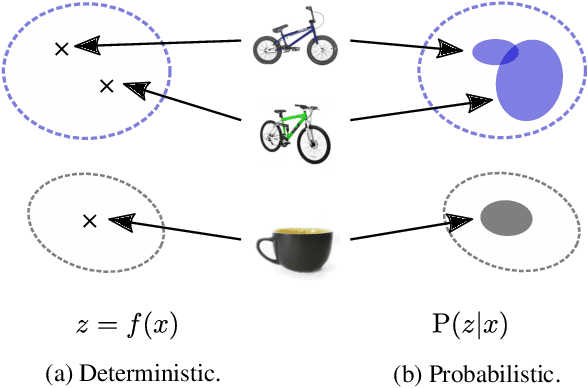
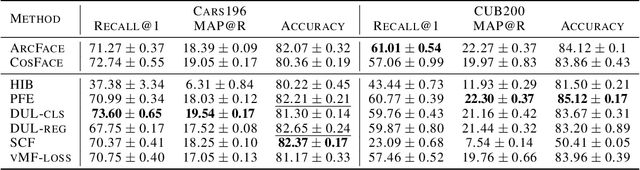
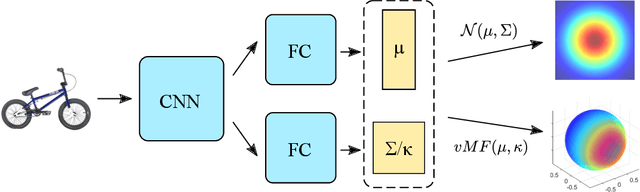
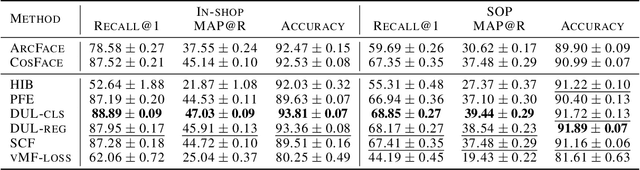
In recent years, deep metric learning and its probabilistic extensions achieved state-of-the-art results in a face verification task. However, despite improvements in face verification, probabilistic methods received little attention in the community. It is still unclear whether they can improve image retrieval quality. In this paper, we present an extensive comparison of probabilistic methods in verification and retrieval tasks. Following the suggested methodology, we outperform metric learning baselines using probabilistic methods and propose several directions for future work and improvements.
Super-Resolved Microbubble Localization in Single-Channel Ultrasound RF Signals Using Deep Learning
Apr 09, 2022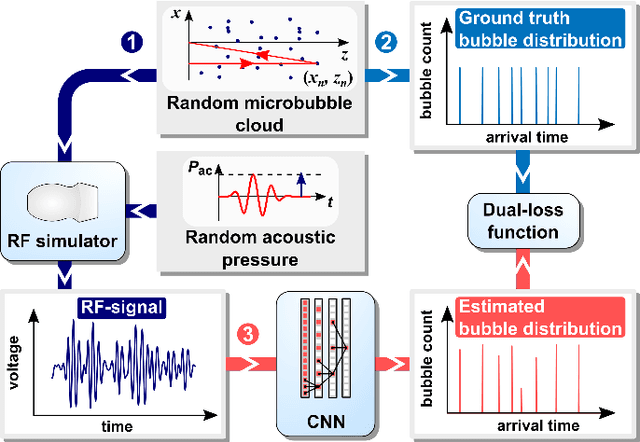
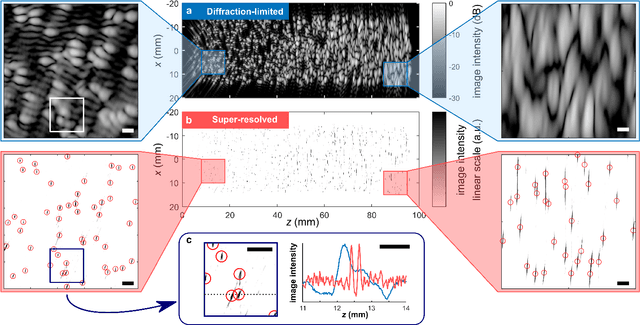
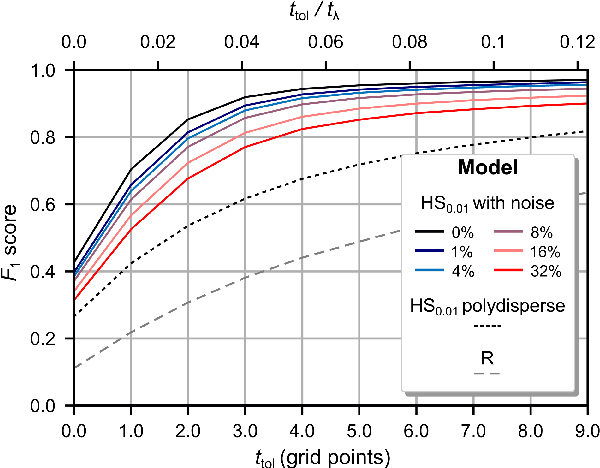
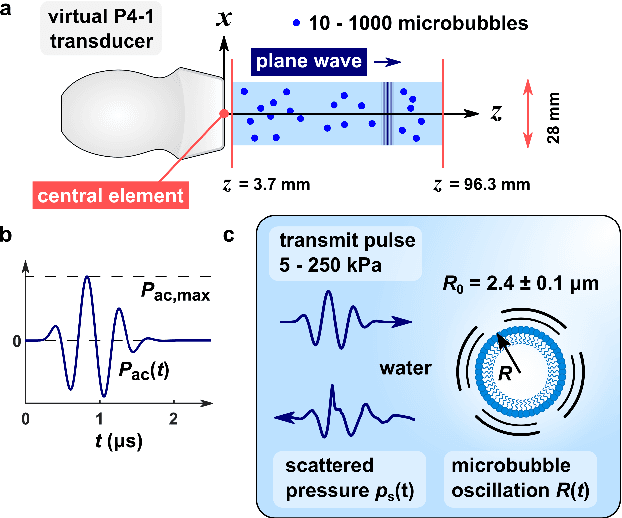
Recently, super-resolution ultrasound imaging with ultrasound localization microscopy (ULM) has received much attention. However, ULM relies on low concentrations of microbubbles in the blood vessels, ultimately resulting in long acquisition times. Here, we present an alternative super-resolution approach, based on direct deconvolution of single-channel ultrasound radio-frequency (RF) signals with a one-dimensional dilated convolutional neural network (CNN). This work focuses on low-frequency ultrasound (1.7 MHz) for deep imaging (10 cm) of a dense cloud of monodisperse microbubbles (up to 1000 microbubbles in the measurement volume, corresponding to an average echo overlap of 94%). Data are generated with a simulator that uses a large range of acoustic pressures (5-250 kPa) and captures the full, nonlinear response of resonant, lipid-coated microbubbles. The network is trained with a novel dual-loss function, which features elements of both a classification loss and a regression loss and improves the detection-localization characteristics of the output. Whereas imposing a localization tolerance of 0 yields poor detection metrics, imposing a localization tolerance corresponding to 4% of the wavelength yields a precision and recall of both 0.90. Furthermore, the detection improves with increasing acoustic pressure and deteriorates with increasing microbubble density. The potential of the presented approach to super-resolution ultrasound imaging is demonstrated with a delay-and-sum reconstruction with deconvolved element data. The resulting image shows an order-of-magnitude gain in axial resolution compared to a delay-and-sum reconstruction with unprocessed element data.
The Vehicle Trajectory Prediction Based on ResNet and EfficientNet Model
Jan 24, 2022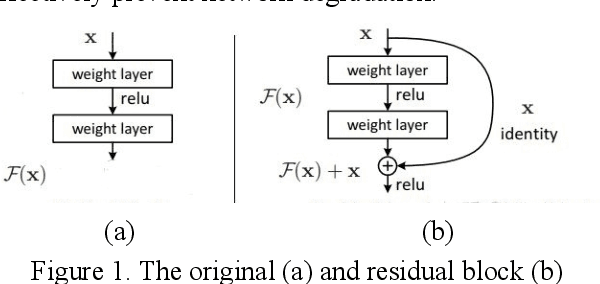
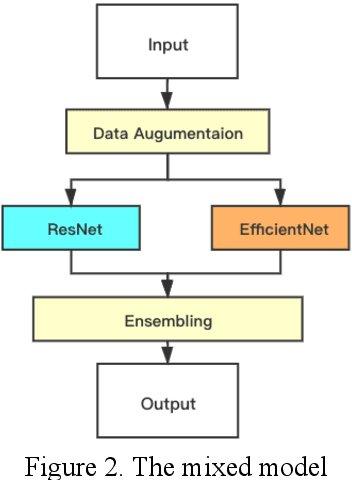
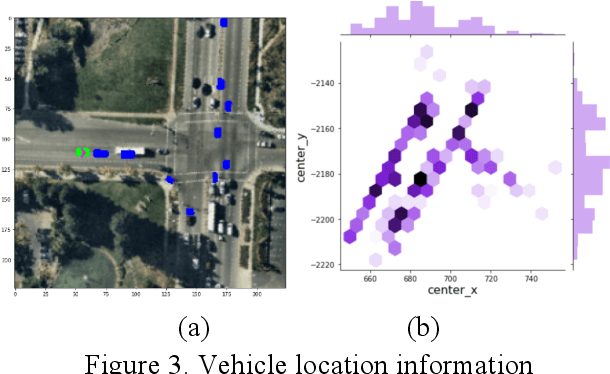

At present, a major challenge for the application of automatic driving technology is the accurate prediction of vehicle trajectory. With the vigorous development of computer technology and the emergence of convolution depth neural network, the accuracy of prediction results has been improved. But, the depth, width of the network and image resolution are still important reasons that restrict the accuracy of the model and the prediction results. The main innovation of this paper is the combination of RESNET network and efficient net network, which not only greatly increases the network depth, but also comprehensively changes the choice of network width and image resolution, so as to make the model performance better, but also save computing resources as much as possible. The experimental results also show that our proposed model obtains the optimal prediction results. Specifically, the loss value of our method is separately 4 less and 2.1 less than that of resnet and efficientnet method.
Adaptive noise imitation for image denoising
Nov 30, 2020
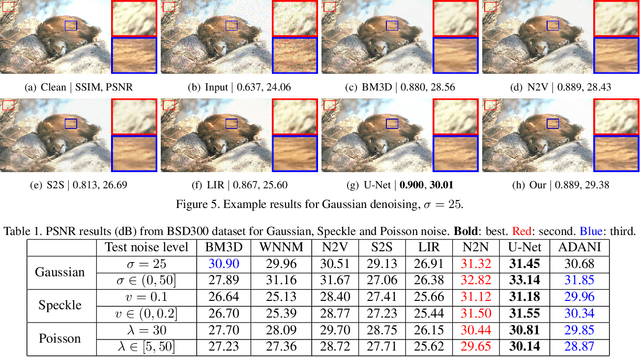
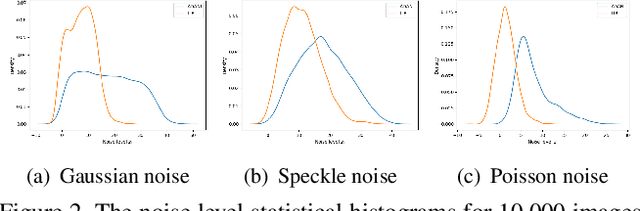

The effectiveness of existing denoising algorithms typically relies on accurate pre-defined noise statistics or plenty of paired data, which limits their practicality. In this work, we focus on denoising in the more common case where noise statistics and paired data are unavailable. Considering that denoising CNNs require supervision, we develop a new \textbf{adaptive noise imitation (ADANI)} algorithm that can synthesize noisy data from naturally noisy images. To produce realistic noise, a noise generator takes unpaired noisy/clean images as input, where the noisy image is a guide for noise generation. By imposing explicit constraints on the type, level and gradient of noise, the output noise of ADANI will be similar to the guided noise, while keeping the original clean background of the image. Coupling the noisy data output from ADANI with the corresponding ground-truth, a denoising CNN is then trained in a fully-supervised manner. Experiments show that the noisy data produced by ADANI are visually and statistically similar to real ones so that the denoising CNN in our method is competitive to other networks trained with external paired data.
Alleviating Noisy Data in Image Captioning with Cooperative Distillation
Dec 21, 2020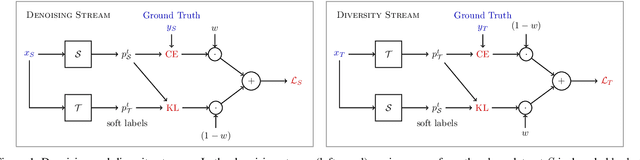

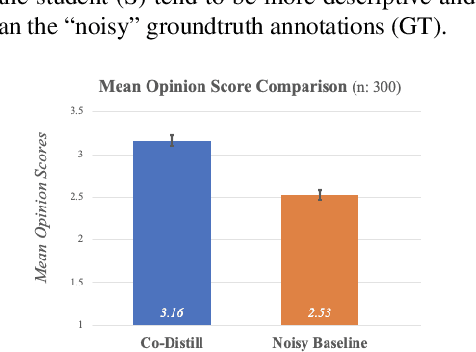
Image captioning systems have made substantial progress, largely due to the availability of curated datasets like Microsoft COCO or Vizwiz that have accurate descriptions of their corresponding images. Unfortunately, scarce availability of such cleanly labeled data results in trained algorithms producing captions that can be terse and idiosyncratically specific to details in the image. We propose a new technique, cooperative distillation that combines clean curated datasets with the web-scale automatically extracted captions of the Google Conceptual Captions dataset (GCC), which can have poor descriptions of images, but is abundant in size and therefore provides a rich vocabulary resulting in more expressive captions.