 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
STCrowd: A Multimodal Dataset for Pedestrian Perception in Crowded Scenes
Apr 03, 2022
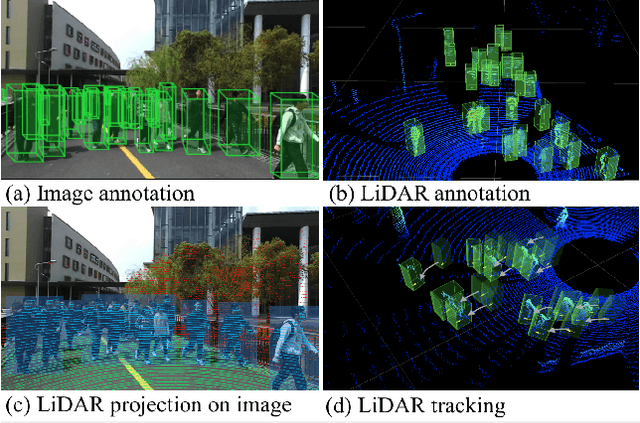
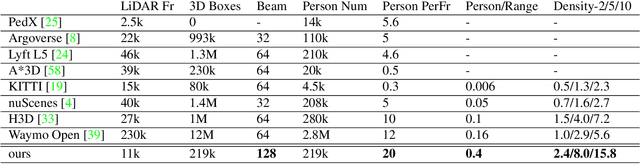

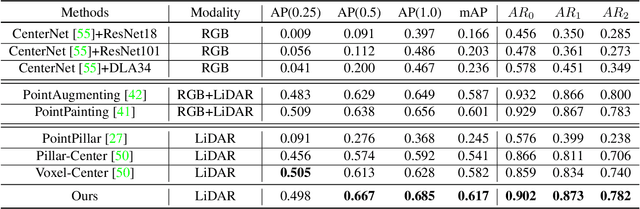
Accurately detecting and tracking pedestrians in 3D space is challenging due to large variations in rotations, poses and scales. The situation becomes even worse for dense crowds with severe occlusions. However, existing benchmarks either only provide 2D annotations, or have limited 3D annotations with low-density pedestrian distribution, making it difficult to build a reliable pedestrian perception system especially in crowded scenes. To better evaluate pedestrian perception algorithms in crowded scenarios, we introduce a large-scale multimodal dataset,STCrowd. Specifically, in STCrowd, there are a total of 219 K pedestrian instances and 20 persons per frame on average, with various levels of occlusion. We provide synchronized LiDAR point clouds and camera images as well as their corresponding 3D labels and joint IDs. STCrowd can be used for various tasks, including LiDAR-only, image-only, and sensor-fusion based pedestrian detection and tracking. We provide baselines for most of the tasks. In addition, considering the property of sparse global distribution and density-varying local distribution of pedestrians, we further propose a novel method, Density-aware Hierarchical heatmap Aggregation (DHA), to enhance pedestrian perception in crowded scenes. Extensive experiments show that our new method achieves state-of-the-art performance for pedestrian detection on various datasets.
Understanding Robustness of Transformers for Image Classification
Mar 26, 2021
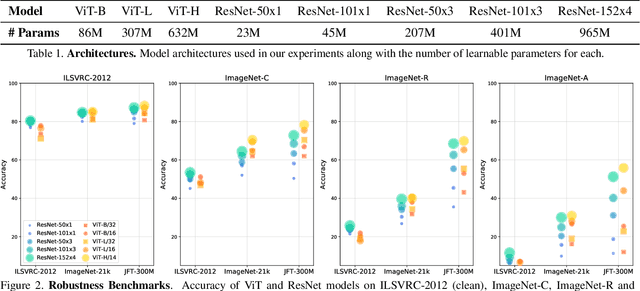
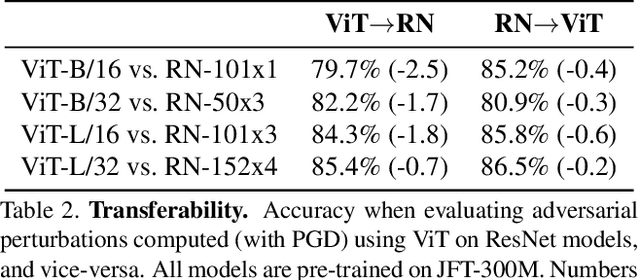

Deep Convolutional Neural Networks (CNNs) have long been the architecture of choice for computer vision tasks. Recently, Transformer-based architectures like Vision Transformer (ViT) have matched or even surpassed ResNets for image classification. However, details of the Transformer architecture -- such as the use of non-overlapping patches -- lead one to wonder whether these networks are as robust. In this paper, we perform an extensive study of a variety of different measures of robustness of ViT models and compare the findings to ResNet baselines. We investigate robustness to input perturbations as well as robustness to model perturbations. We find that when pre-trained with a sufficient amount of data, ViT models are at least as robust as the ResNet counterparts on a broad range of perturbations. We also find that Transformers are robust to the removal of almost any single layer, and that while activations from later layers are highly correlated with each other, they nevertheless play an important role in classification.
Symmetric Parallax Attention for Stereo Image Super-Resolution
Nov 07, 2020

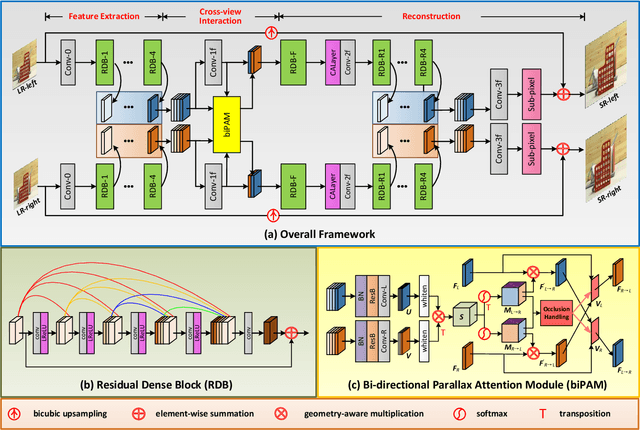
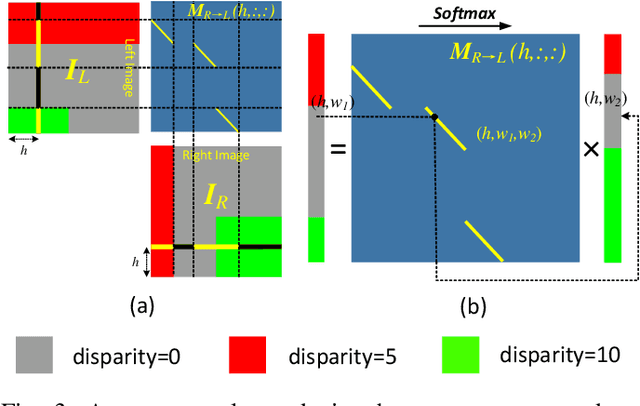
Although recent years have witnessed the great advances in stereo image super-resolution (SR), the beneficial information provided by binocular systems has not been fully used. Since stereo images are highly symmetric under epipolar constraint, in this paper, we improve the performance of stereo image SR by exploiting symmetry cues in stereo image pairs. Specifically, we propose a symmetric bi-directional parallax attention module (biPAM) and an inline occlusion handling scheme to effectively interact cross-view information. Then, we design a Siamese network equipped with a biPAM to super-resolve both sides of views in a highly symmetric manner. Finally, we design several illuminance-robust bilateral losses to enforce stereo consistency. Experiments on four public datasets have demonstrated the superiority of our method. As compared to PASSRnet, our method achieves notable performance improvements with a comparable model size. Source codes are available at https://github.com/YingqianWang/iPASSR.
Style and Pose Control for Image Synthesis of Humans from a Single Monocular View
Feb 22, 2021
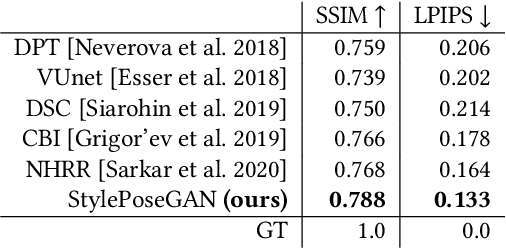


Photo-realistic re-rendering of a human from a single image with explicit control over body pose, shape and appearance enables a wide range of applications, such as human appearance transfer, virtual try-on, motion imitation, and novel view synthesis. While significant progress has been made in this direction using learning-based image generation tools, such as GANs, existing approaches yield noticeable artefacts such as blurring of fine details, unrealistic distortions of the body parts and garments as well as severe changes of the textures. We, therefore, propose a new method for synthesising photo-realistic human images with explicit control over pose and part-based appearance, i.e., StylePoseGAN, where we extend a non-controllable generator to accept conditioning of pose and appearance separately. Our network can be trained in a fully supervised way with human images to disentangle pose, appearance and body parts, and it significantly outperforms existing single image re-rendering methods. Our disentangled representation opens up further applications such as garment transfer, motion transfer, virtual try-on, head (identity) swap and appearance interpolation. StylePoseGAN achieves state-of-the-art image generation fidelity on common perceptual metrics compared to the current best-performing methods and convinces in a comprehensive user study.
ProFormer: Learning Data-efficient Representations of Body Movement with Prototype-based Feature Augmentation and Visual Transformers
Feb 23, 2022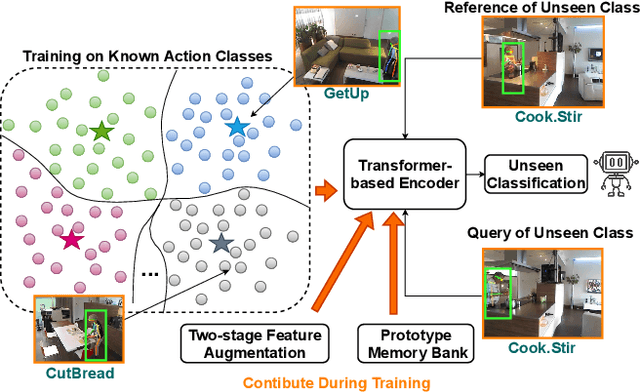
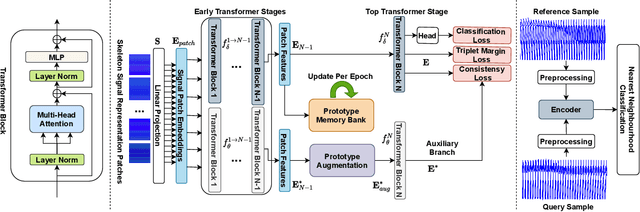
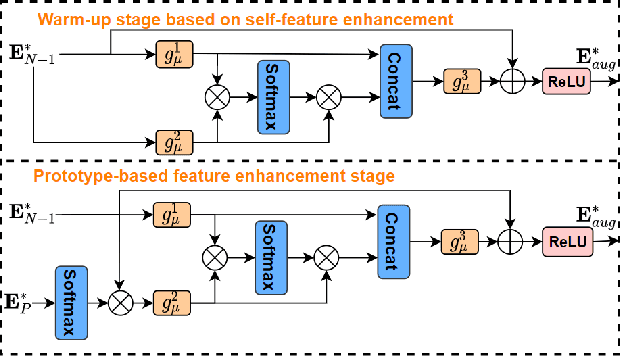
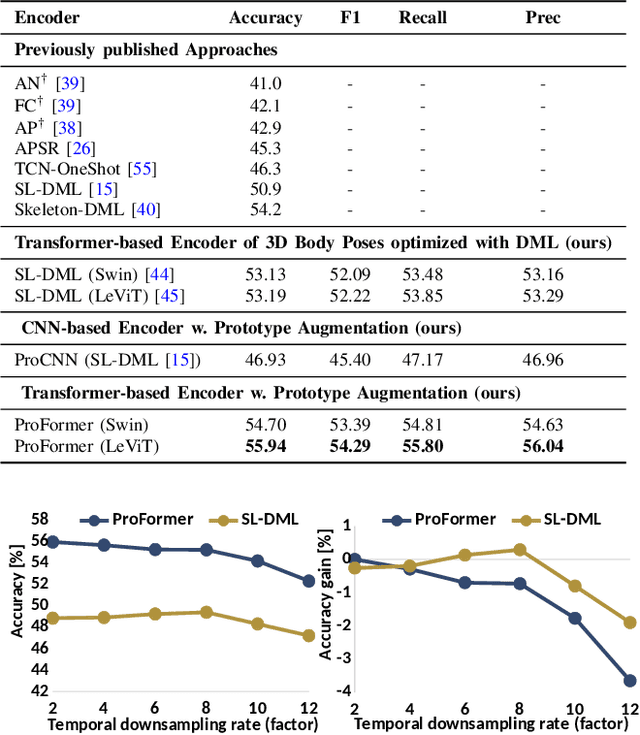
Automatically understanding human behaviour allows household robots to identify the most critical needs and plan how to assist the human according to the current situation. However, the majority of such methods are developed under the assumption that a large amount of labelled training examples is available for all concepts-of-interest. Robots, on the other hand, operate in constantly changing unstructured environments, and need to adapt to novel action categories from very few samples. Methods for data-efficient recognition from body poses increasingly leverage skeleton sequences structured as image-like arrays and then used as input to convolutional neural networks. We look at this paradigm from the perspective of transformer networks, for the first time exploring visual transformers as data-efficient encoders of skeleton movement. In our pipeline, body pose sequences cast as image-like representations are converted into patch embeddings and then passed to a visual transformer backbone optimized with deep metric learning. Inspired by recent success of feature enhancement methods in semi-supervised learning, we further introduce ProFormer -- an improved training strategy which uses soft-attention applied on iteratively estimated action category prototypes used to augment the embeddings and compute an auxiliary consistency loss. Extensive experiments consistently demonstrate the effectiveness of our approach for one-shot recognition from body poses, achieving state-of-the-art results on multiple datasets and surpassing the best published approach on the challenging NTU-120 one-shot benchmark by 1.84%. Our code will be made publicly available at https://github.com/KPeng9510/ProFormer.
Fast and Scalable Computation of the Forward and Inverse Discrete Periodic Radon Transform
Dec 24, 2021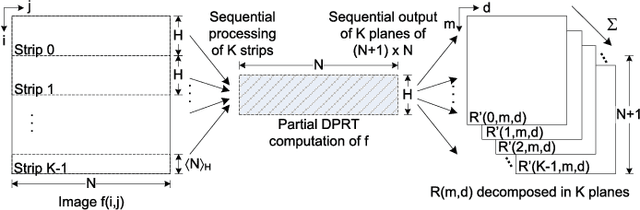
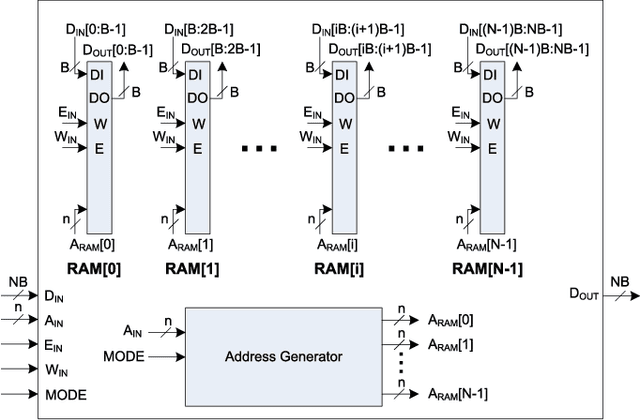

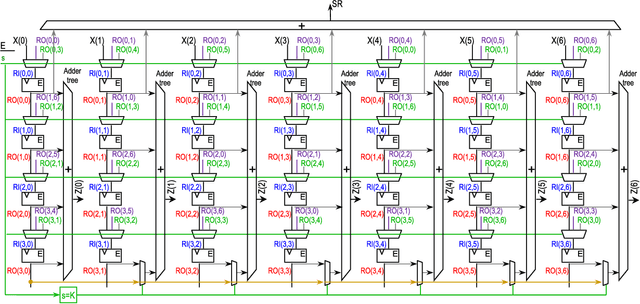
The Discrete Periodic Radon Transform (DPRT) has been extensively used in applications that involve image reconstructions from projections. This manuscript introduces a fast and scalable approach for computing the forward and inverse DPRT that is based on the use of: (i) a parallel array of fixed-point adder trees, (ii) circular shift registers to remove the need for accessing external memory components when selecting the input data for the adder trees, (iii) an image block-based approach to DPRT computation that can fit the proposed architecture to available resources, and (iv) fast transpositions that are computed in one or a few clock cycles that do not depend on the size of the input image. As a result, for an $N\times N$ image ($N$ prime), the proposed approach can compute up to $N^{2}$ additions per clock cycle. Compared to previous approaches, the scalable approach provides the fastest known implementations for different amounts of computational resources. For example, for a $251\times 251$ image, for approximately $25\%$ fewer flip-flops than required for a systolic implementation, we have that the scalable DPRT is computed 36 times faster. For the fastest case, we introduce optimized architectures that can compute the DPRT and its inverse in just $2N+\left\lceil \log_{2}N\right\rceil+1$ and $2N+3\left\lceil \log_{2}N\right\rceil+B+2$ cycles respectively, where $B$ is the number of bits used to represent each input pixel. On the other hand, the scalable DPRT approach requires more 1-bit additions than for the systolic implementation and provides a trade-off between speed and additional 1-bit additions. All of the proposed DPRT architectures were implemented in VHDL and validated using an FPGA implementation.
* This paper has been published as follows: C. Carranza, D. Llamocca, and M. Pattichis. "Fast and scalable computation of the forward and inverse discrete periodic radon transform", IEEE Transactions on Image Processing, 25(1):119-133, Jan 2016
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation
Mar 29, 2022
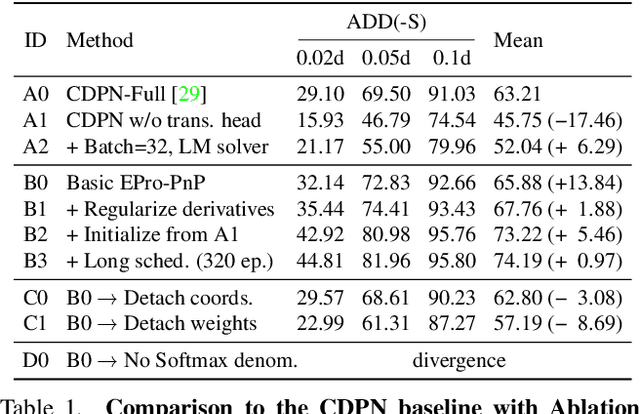
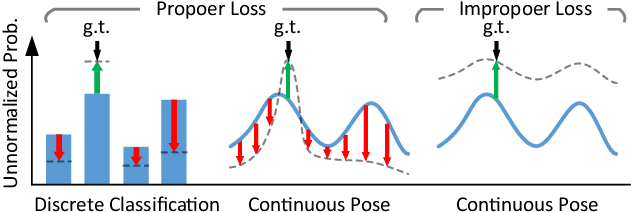
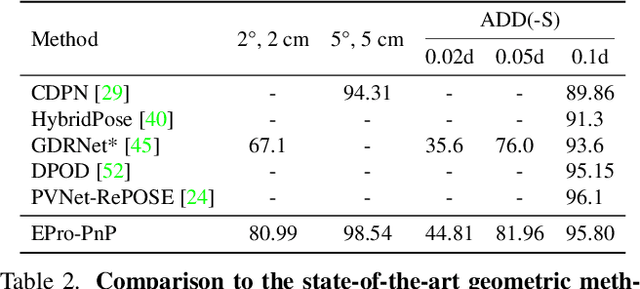
Locating 3D objects from a single RGB image via Perspective-n-Points (PnP) is a long-standing problem in computer vision. Driven by end-to-end deep learning, recent studies suggest interpreting PnP as a differentiable layer, so that 2D-3D point correspondences can be partly learned by backpropagating the gradient w.r.t. object pose. Yet, learning the entire set of unrestricted 2D-3D points from scratch fails to converge with existing approaches, since the deterministic pose is inherently non-differentiable. In this paper, we propose the EPro-PnP, a probabilistic PnP layer for general end-to-end pose estimation, which outputs a distribution of pose on the SE(3) manifold, essentially bringing categorical Softmax to the continuous domain. The 2D-3D coordinates and corresponding weights are treated as intermediate variables learned by minimizing the KL divergence between the predicted and target pose distribution. The underlying principle unifies the existing approaches and resembles the attention mechanism. EPro-PnP significantly outperforms competitive baselines, closing the gap between PnP-based method and the task-specific leaders on the LineMOD 6DoF pose estimation and nuScenes 3D object detection benchmarks.
Enabling Deep Learning for All-in EDGE paradigm
Apr 07, 2022
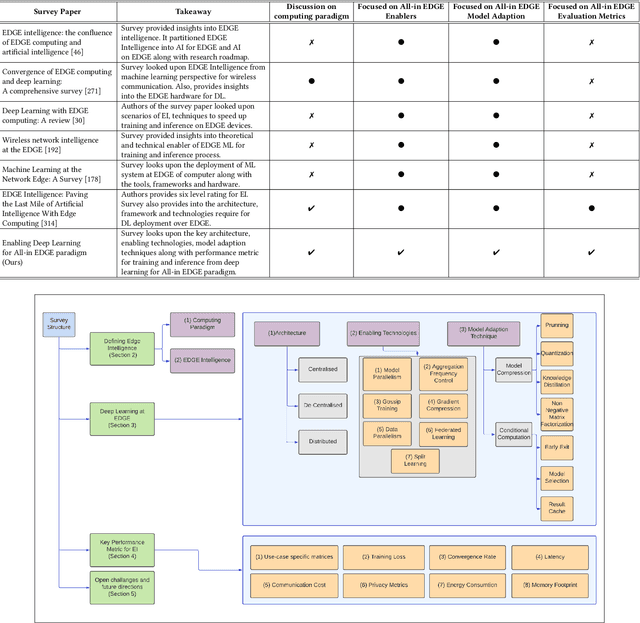
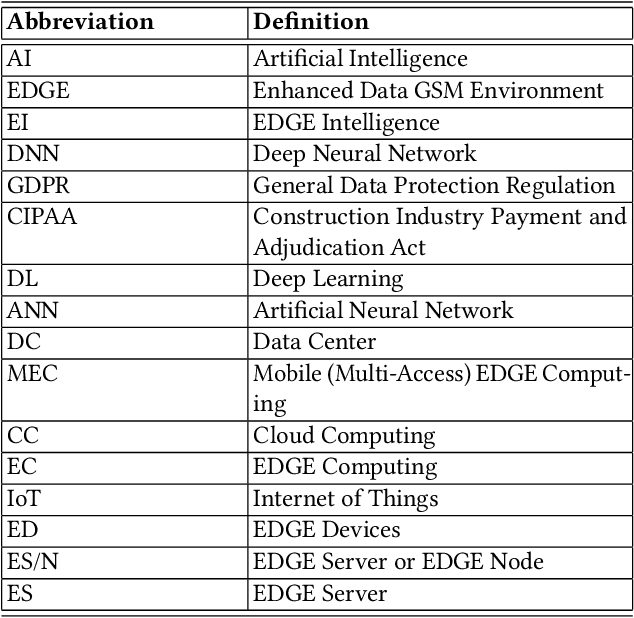
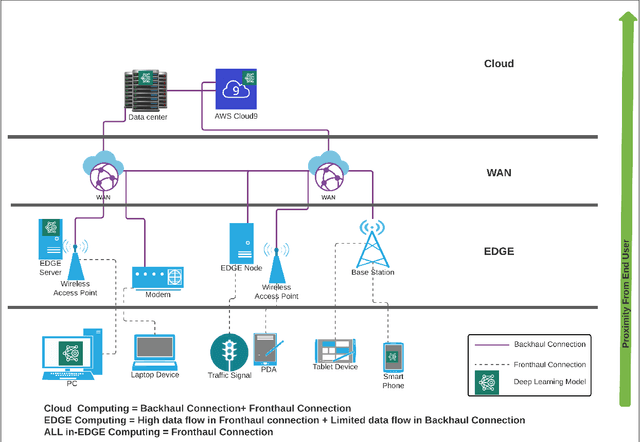
Deep Learning-based models have been widely investigated, and they have demonstrated significant performance on non-trivial tasks such as speech recognition, image processing, and natural language understanding. However, this is at the cost of substantial data requirements. Considering the widespread proliferation of edge devices (e.g. Internet of Things devices) over the last decade, Deep Learning in the edge paradigm, such as device-cloud integrated platforms, is required to leverage its superior performance. Moreover, it is suitable from the data requirements perspective in the edge paradigm because the proliferation of edge devices has resulted in an explosion in the volume of generated and collected data. However, there are difficulties due to other requirements such as high computation, high latency, and high bandwidth caused by Deep Learning applications in real-world scenarios. In this regard, this survey paper investigates Deep Learning at the edge, its architecture, enabling technologies, and model adaption techniques, where edge servers and edge devices participate in deep learning training and inference. For simplicity, we call this paradigm the All-in EDGE paradigm. Besides, this paper presents the key performance metrics for Deep Learning at the All-in EDGE paradigm to evaluate various deep learning techniques and choose a suitable design. Moreover, various open challenges arising from the deployment of Deep Learning at the All-in EDGE paradigm are identified and discussed.
Generative Max-Mahalanobis Classifiers for Image Classification, Generation and More
Jan 01, 2021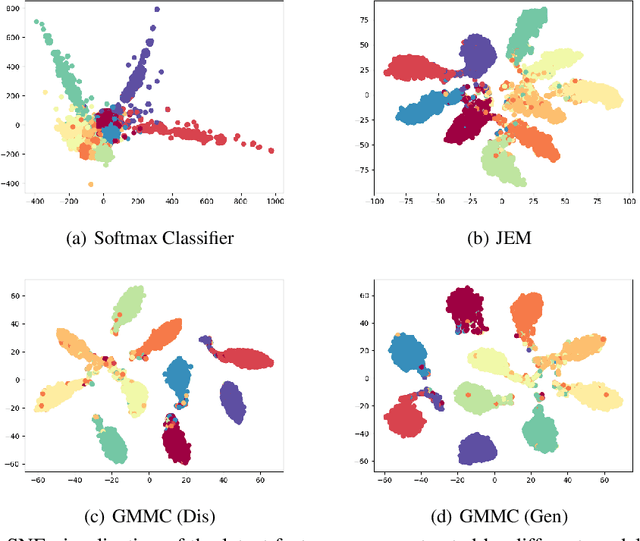
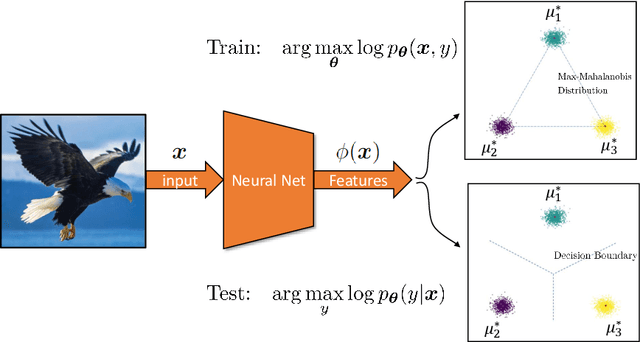

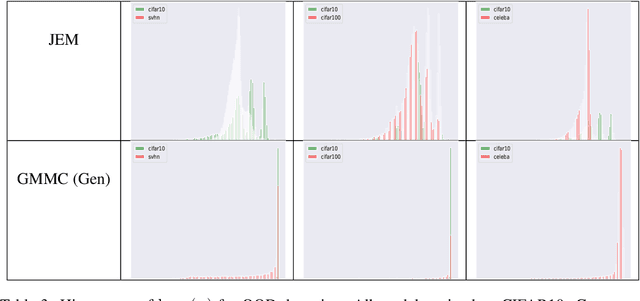
Joint Energy-based Model (JEM) of~\cite{jem} shows that a standard softmax classifier can be reinterpreted as an energy-based model (EBM) for the joint distribution $p(\boldsymbol{x}, y)$; the resulting model can be optimized with an energy-based training to improve calibration, robustness and out-of-distribution detection, while generating samples rivaling the quality of recent GAN-based approaches. However, the softmax classifier that JEM exploits is inherently discriminative and its latent feature space is not well formulated as probabilistic distributions, which may hinder its potential for image generation and incur training instability as observed in~\cite{jem}. We hypothesize that generative classifiers, such as Linear Discriminant Analysis (LDA), might be more suitable hybrid models for image generation since generative classifiers model the data generation process explicitly. This paper therefore investigates an LDA classifier for image classification and generation. In particular, the Max-Mahalanobis Classifier (MMC)~\cite{Pang2020Rethinking}, a special case of LDA, fits our goal very well since MMC formulates the latent feature space explicitly as the Max-Mahalanobis distribution~\cite{pang2018max}. We term our algorithm Generative MMC (GMMC), and show that it can be trained discriminatively, generatively or jointly for image classification and generation. Extensive experiments on multiple datasets (CIFAR10, CIFAR100 and SVHN) show that GMMC achieves state-of-the-art discriminative and generative performances, while outperforming JEM in calibration, adversarial robustness and out-of-distribution detection by a significant margin.
Localizing Visual Sounds the Easy Way
Mar 29, 2022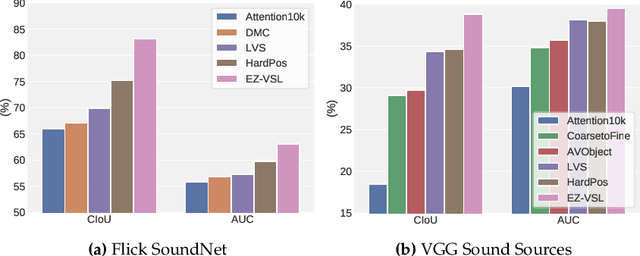
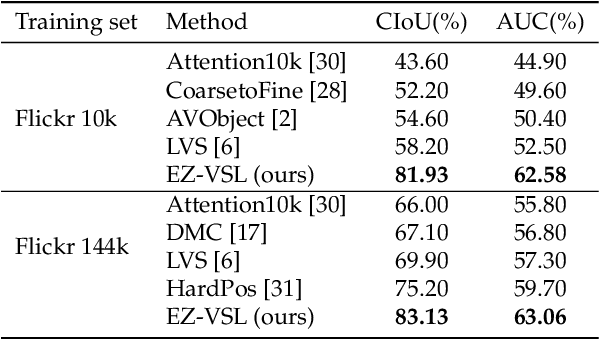
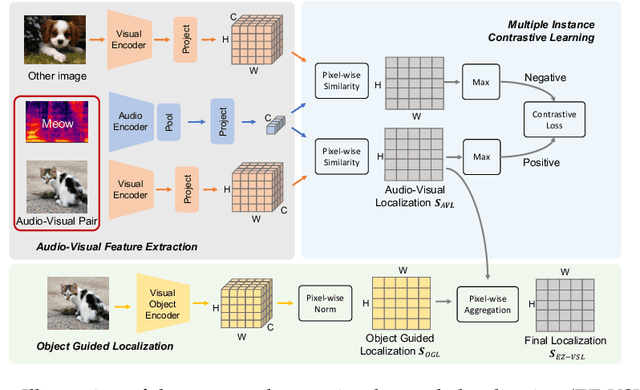
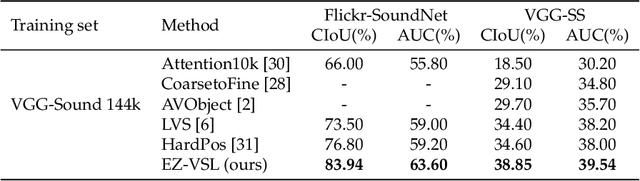
Unsupervised audio-visual source localization aims at localizing visible sound sources in a video without relying on ground-truth localization for training. Previous works often seek high audio-visual similarities for likely positive (sounding) regions and low similarities for likely negative regions. However, accurately distinguishing between sounding and non-sounding regions is challenging without manual annotations. In this work, we propose a simple yet effective approach for Easy Visual Sound Localization, namely EZ-VSL, without relying on the construction of positive and/or negative regions during training. Instead, we align audio and visual spaces by seeking audio-visual representations that are aligned in, at least, one location of the associated image, while not matching other images, at any location. We also introduce a novel object guided localization scheme at inference time for improved precision. Our simple and effective framework achieves state-of-the-art performance on two popular benchmarks, Flickr SoundNet and VGG-Sound Source. In particular, we improve the CIoU of the Flickr SoundNet test set from 76.80% to 83.94%, and on the VGG-Sound Source dataset from 34.60% to 38.85%. The code is available at https://github.com/stoneMo/EZ-VSL.