 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Out of Distribution Data Detection Using Dropout Bayesian Neural Networks
Feb 18, 2022
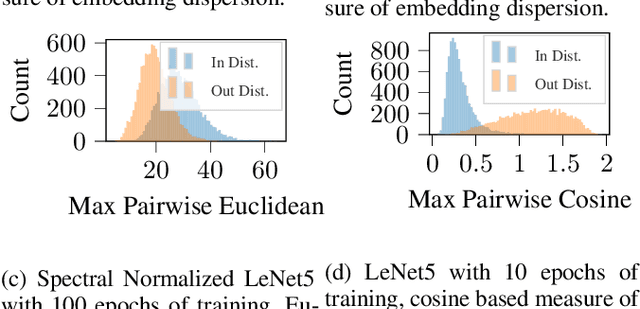
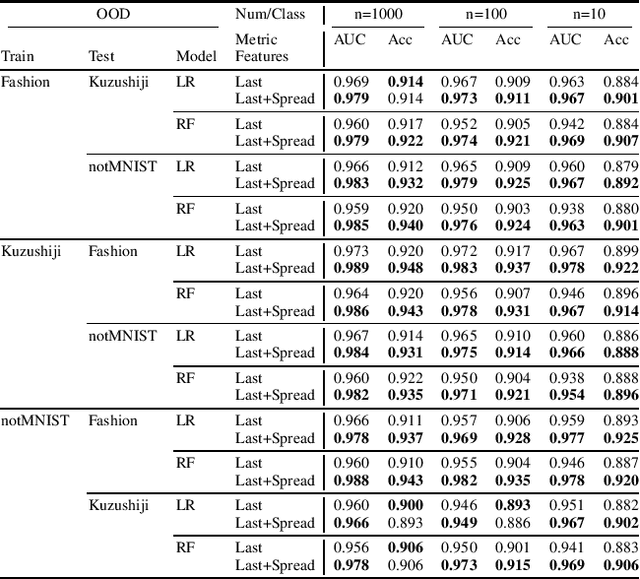
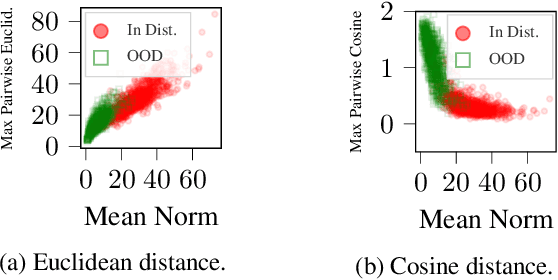
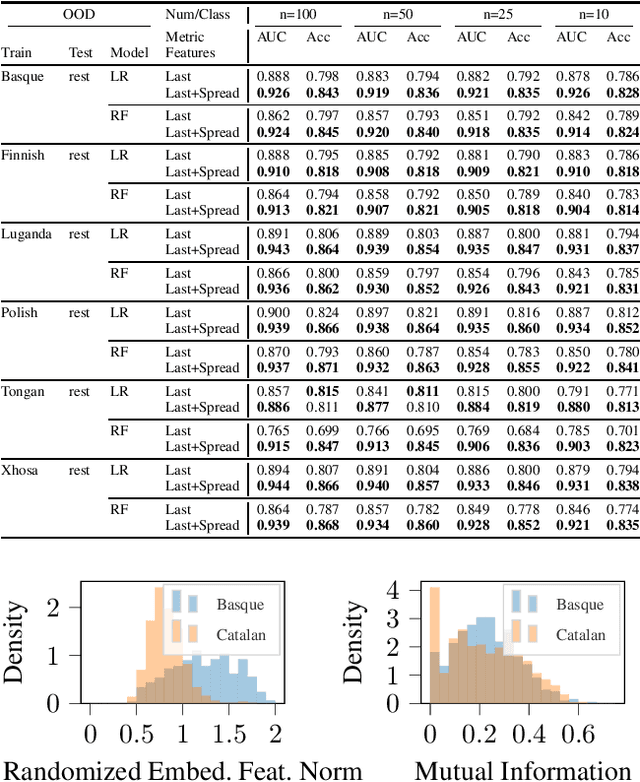
We explore the utility of information contained within a dropout based Bayesian neural network (BNN) for the task of detecting out of distribution (OOD) data. We first show how previous attempts to leverage the randomized embeddings induced by the intermediate layers of a dropout BNN can fail due to the distance metric used. We introduce an alternative approach to measuring embedding uncertainty, justify its use theoretically, and demonstrate how incorporating embedding uncertainty improves OOD data identification across three tasks: image classification, language classification, and malware detection.
A Saliency based Feature Fusion Model for EEG Emotion Estimation
Jan 26, 2022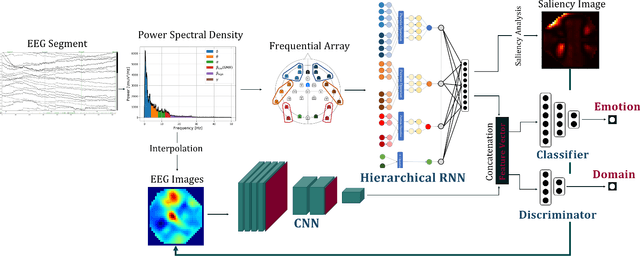

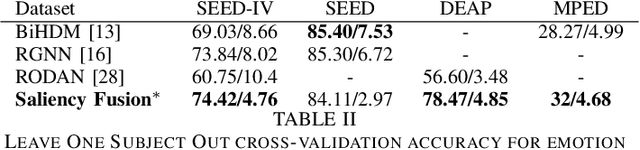
Among the different modalities to assess emotion, electroencephalogram (EEG), representing the electrical brain activity, achieved motivating results over the last decade. Emotion estimation from EEG could help in the diagnosis or rehabilitation of certain diseases. In this paper, we propose a dual model considering two different representations of EEG feature maps: 1) a sequential based representation of EEG band power, 2) an image-based representation of the feature vectors. We also propose an innovative method to combine the information based on a saliency analysis of the image-based model to promote joint learning of both model parts. The model has been evaluated on four publicly available datasets and achieves similar results to the state-of-the-art approaches. It outperforms results for two of the proposed datasets with a lower standard deviation that reflects higher stability. For sake of reproducibility, the codes and models proposed in this paper are available at https://github.com/VDelv/Emotion-EEG.
Uni-EDEN: Universal Encoder-Decoder Network by Multi-Granular Vision-Language Pre-training
Jan 11, 2022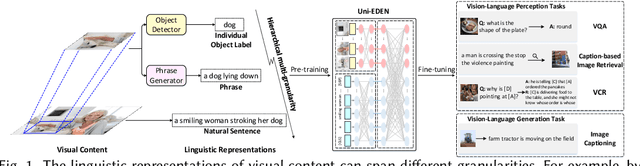
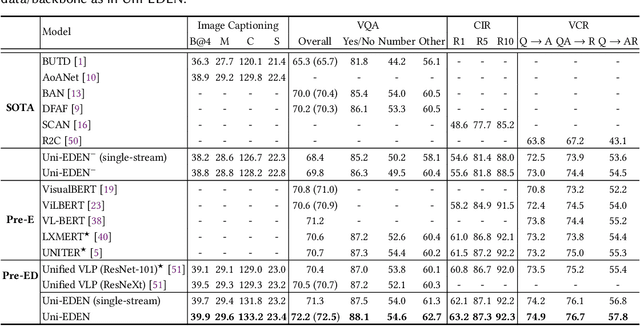
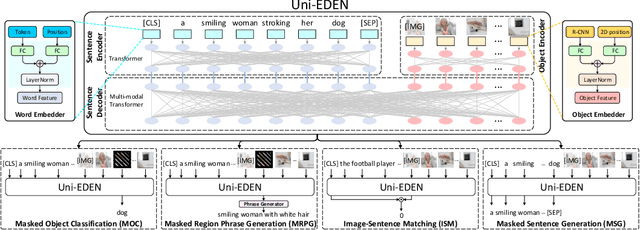
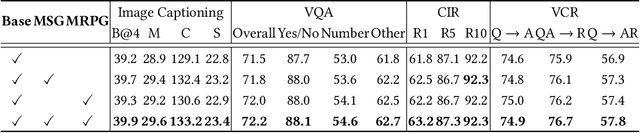
Vision-language pre-training has been an emerging and fast-developing research topic, which transfers multi-modal knowledge from rich-resource pre-training task to limited-resource downstream tasks. Unlike existing works that predominantly learn a single generic encoder, we present a pre-trainable Universal Encoder-DEcoder Network (Uni-EDEN) to facilitate both vision-language perception (e.g., visual question answering) and generation (e.g., image captioning). Uni-EDEN is a two-stream Transformer based structure, consisting of three modules: object and sentence encoders that separately learns the representations of each modality, and sentence decoder that enables both multi-modal reasoning and sentence generation via inter-modal interaction. Considering that the linguistic representations of each image can span different granularities in this hierarchy including, from simple to comprehensive, individual label, a phrase, and a natural sentence, we pre-train Uni-EDEN through multi-granular vision-language proxy tasks: Masked Object Classification (MOC), Masked Region Phrase Generation (MRPG), Image-Sentence Matching (ISM), and Masked Sentence Generation (MSG). In this way, Uni-EDEN is endowed with the power of both multi-modal representation extraction and language modeling. Extensive experiments demonstrate the compelling generalizability of Uni-EDEN by fine-tuning it to four vision-language perception and generation downstream tasks.
A Deep-Discrete Learning Framework for Spherical Surface Registration
Mar 24, 2022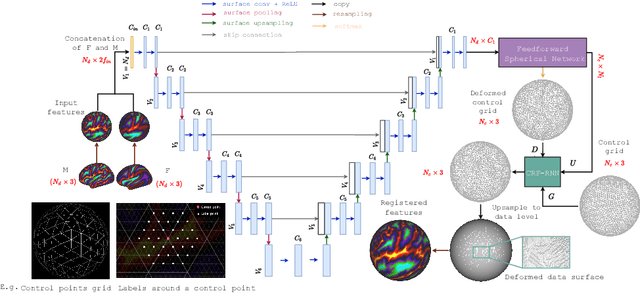
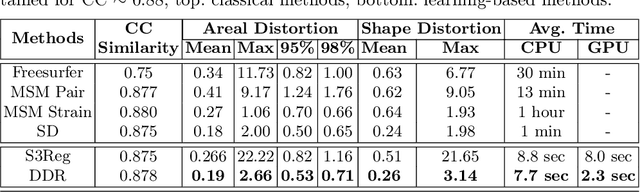
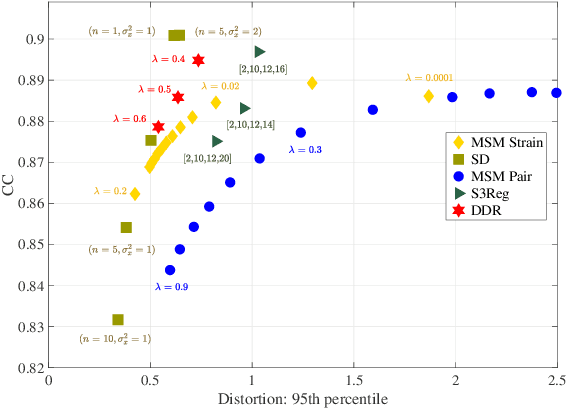
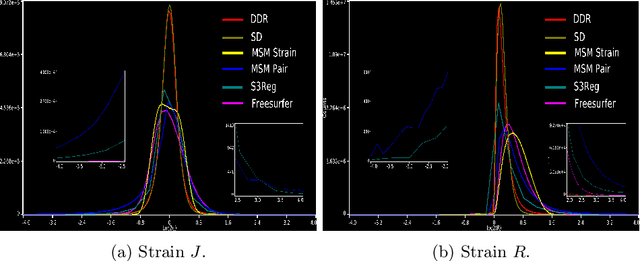
Cortical surface registration is a fundamental tool for neuroimaging analysis that has been shown to improve the alignment of functional regions relative to volumetric approaches. Classically, image registration is performed by optimizing a complex objective similarity function, leading to long run times. This contributes to a convention for aligning all data to a global average reference frame that poorly reflects the underlying cortical heterogeneity. In this paper, we propose a novel unsupervised learning-based framework that converts registration to a multi-label classification problem, where each point in a low-resolution control grid deforms to one of fixed, finite number of endpoints. This is learned using a spherical geometric deep learning architecture, in an end-to-end unsupervised way, with regularization imposed using a deep Conditional Random Field (CRF). Experiments show that our proposed framework performs competitively, in terms of similarity and areal distortion, relative to the most popular classical surface registration algorithms and generates smoother deformations than other learning-based surface registration methods, even in subjects with atypical cortical morphology.
Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning
Nov 29, 2021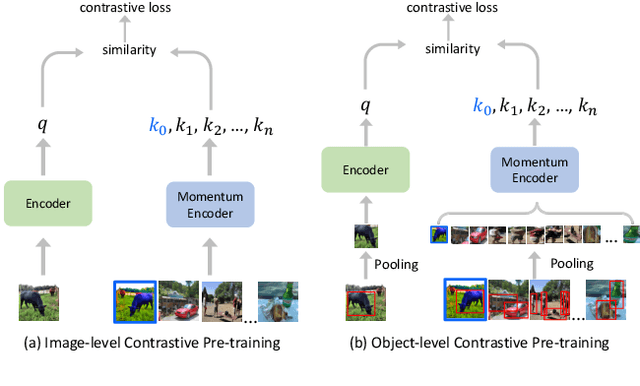
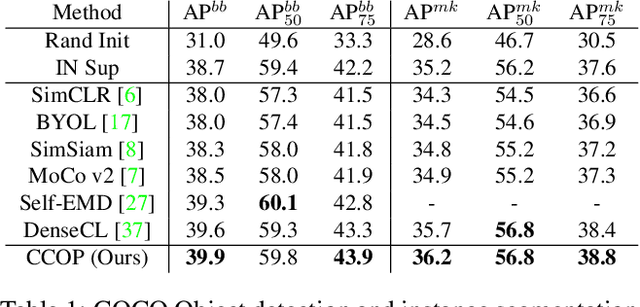
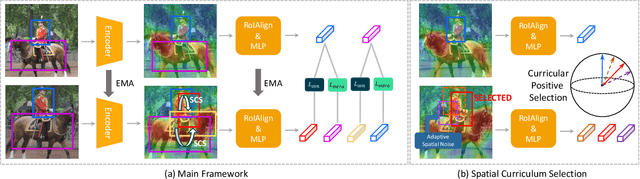
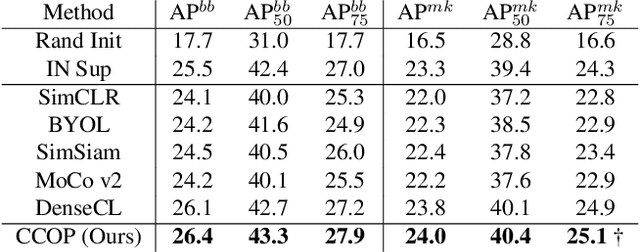
The goal of contrastive learning based pre-training is to leverage large quantities of unlabeled data to produce a model that can be readily adapted downstream. Current approaches revolve around solving an image discrimination task: given an anchor image, an augmented counterpart of that image, and some other images, the model must produce representations such that the distance between the anchor and its counterpart is small, and the distances between the anchor and the other images are large. There are two significant problems with this approach: (i) by contrasting representations at the image-level, it is hard to generate detailed object-sensitive features that are beneficial to downstream object-level tasks such as instance segmentation; (ii) the augmentation strategy of producing an augmented counterpart is fixed, making learning less effective at the later stages of pre-training. In this work, we introduce Curricular Contrastive Object-level Pre-training (CCOP) to tackle these problems: (i) we use selective search to find rough object regions and use them to build an inter-image object-level contrastive loss and an intra-image object-level discrimination loss into our pre-training objective; (ii) we present a curriculum learning mechanism that adaptively augments the generated regions, which allows the model to consistently acquire a useful learning signal, even in the later stages of pre-training. Our experiments show that our approach improves on the MoCo v2 baseline by a large margin on multiple object-level tasks when pre-training on multi-object scene image datasets. Code is available at https://github.com/ChenhongyiYang/CCOP.
UQGAN: A Unified Model for Uncertainty Quantification of Deep Classifiers trained via Conditional GANs
Jan 31, 2022
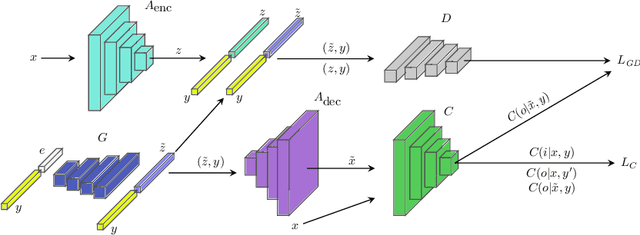
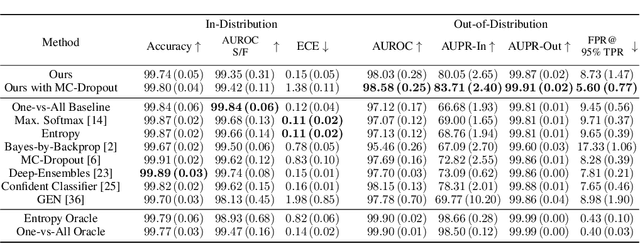

We present an approach to quantifying both aleatoric and epistemic uncertainty for deep neural networks in image classification, based on generative adversarial networks (GANs). While most works in the literature that use GANs to generate out-of-distribution (OoD) examples only focus on the evaluation of OoD detection, we present a GAN based approach to learn a classifier that exhibits proper uncertainties for OoD examples as well as for false positives (FPs). Instead of shielding the entire in-distribution data with GAN generated OoD examples which is state-of-the-art, we shield each class separately with out-of-class examples generated by a conditional GAN and complement this with a one-vs-all image classifier. In our experiments, in particular on CIFAR10, we improve over the OoD detection and FP detection performance of state-of-the-art GAN-training based classifiers. Furthermore, we also find that the generated GAN examples do not significantly affect the calibration error of our classifier and result in a significant gain in model accuracy.
ProFormer: Learning Data-efficient Representations of Body Movement with Prototype-based Feature Augmentation and Visual Transformers
Feb 23, 2022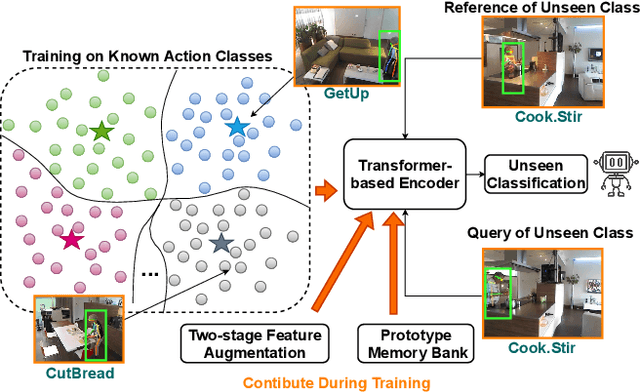
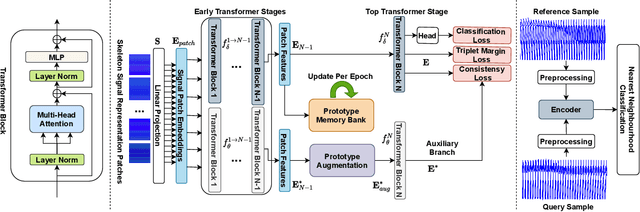
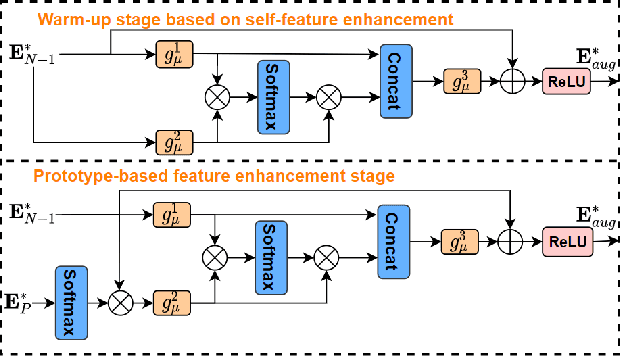
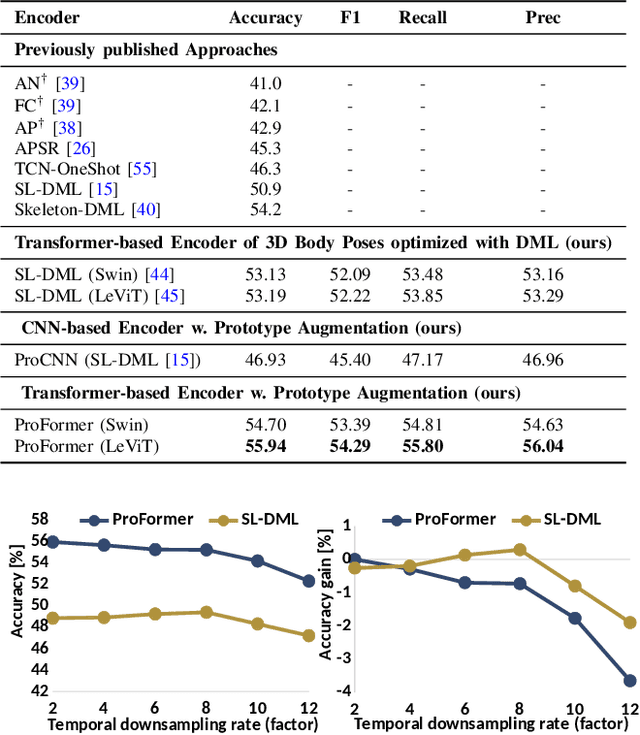
Automatically understanding human behaviour allows household robots to identify the most critical needs and plan how to assist the human according to the current situation. However, the majority of such methods are developed under the assumption that a large amount of labelled training examples is available for all concepts-of-interest. Robots, on the other hand, operate in constantly changing unstructured environments, and need to adapt to novel action categories from very few samples. Methods for data-efficient recognition from body poses increasingly leverage skeleton sequences structured as image-like arrays and then used as input to convolutional neural networks. We look at this paradigm from the perspective of transformer networks, for the first time exploring visual transformers as data-efficient encoders of skeleton movement. In our pipeline, body pose sequences cast as image-like representations are converted into patch embeddings and then passed to a visual transformer backbone optimized with deep metric learning. Inspired by recent success of feature enhancement methods in semi-supervised learning, we further introduce ProFormer -- an improved training strategy which uses soft-attention applied on iteratively estimated action category prototypes used to augment the embeddings and compute an auxiliary consistency loss. Extensive experiments consistently demonstrate the effectiveness of our approach for one-shot recognition from body poses, achieving state-of-the-art results on multiple datasets and surpassing the best published approach on the challenging NTU-120 one-shot benchmark by 1.84%. Our code will be made publicly available at https://github.com/KPeng9510/ProFormer.
SODA: Site Object Detection dAtaset for Deep Learning in Construction
Feb 19, 2022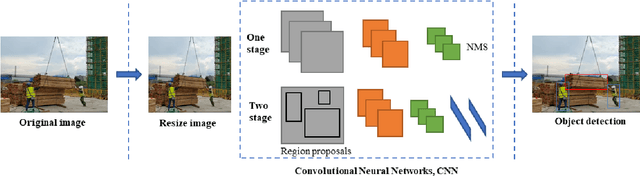
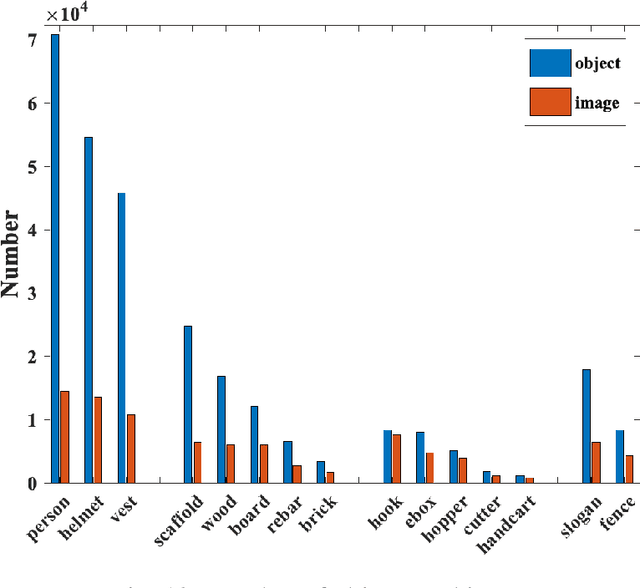
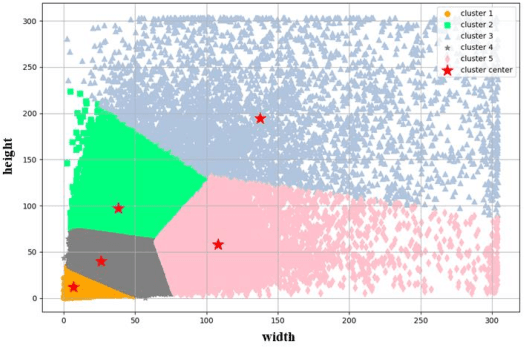
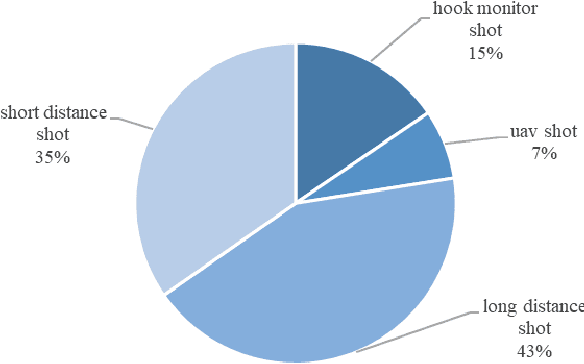
Computer vision-based deep learning object detection algorithms have been developed sufficiently powerful to support the ability to recognize various objects. Although there are currently general datasets for object detection, there is still a lack of large-scale, open-source dataset for the construction industry, which limits the developments of object detection algorithms as they tend to be data-hungry. Therefore, this paper develops a new large-scale image dataset specifically collected and annotated for the construction site, called Site Object Detection dAtaset (SODA), which contains 15 kinds of object classes categorized by workers, materials, machines, and layout. Firstly, more than 20,000 images were collected from multiple construction sites in different site conditions, weather conditions, and construction phases, which covered different angles and perspectives. After careful screening and processing, 19,846 images including 286,201 objects were then obtained and annotated with labels in accordance with predefined categories. Statistical analysis shows that the developed dataset is advantageous in terms of diversity and volume. Further evaluation with two widely-adopted object detection algorithms based on deep learning (YOLO v3/ YOLO v4) also illustrates the feasibility of the dataset for typical construction scenarios, achieving a maximum mAP of 81.47%. In this manner, this research contributes a large-scale image dataset for the development of deep learning-based object detection methods in the construction industry and sets up a performance benchmark for further evaluation of corresponding algorithms in this area.
Multi-level Second-order Few-shot Learning
Jan 15, 2022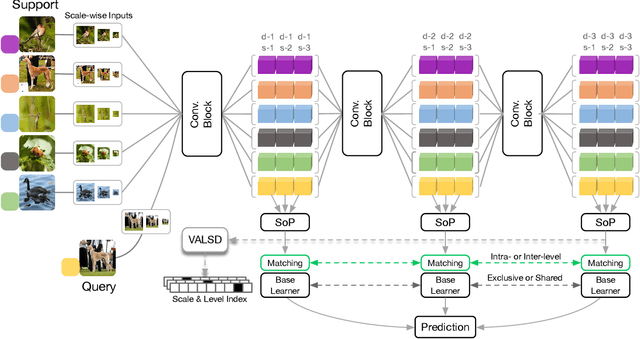
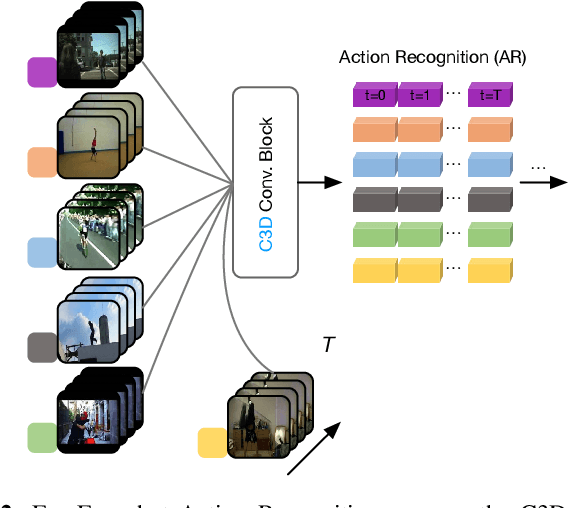
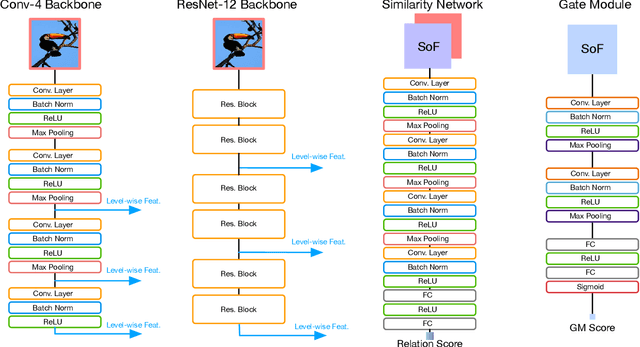
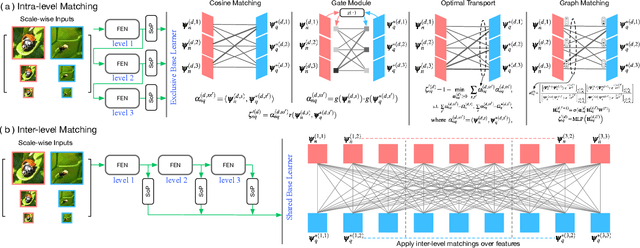
We propose a Multi-level Second-order (MlSo) few-shot learning network for supervised or unsupervised few-shot image classification and few-shot action recognition. We leverage so-called power-normalized second-order base learner streams combined with features that express multiple levels of visual abstraction, and we use self-supervised discriminating mechanisms. As Second-order Pooling (SoP) is popular in image recognition, we employ its basic element-wise variant in our pipeline. The goal of multi-level feature design is to extract feature representations at different layer-wise levels of CNN, realizing several levels of visual abstraction to achieve robust few-shot learning. As SoP can handle convolutional feature maps of varying spatial sizes, we also introduce image inputs at multiple spatial scales into MlSo. To exploit the discriminative information from multi-level and multi-scale features, we develop a Feature Matching (FM) module that reweights their respective branches. We also introduce a self-supervised step, which is a discriminator of the spatial level and the scale of abstraction. Our pipeline is trained in an end-to-end manner. With a simple architecture, we demonstrate respectable results on standard datasets such as Omniglot, mini-ImageNet, tiered-ImageNet, Open MIC, fine-grained datasets such as CUB Birds, Stanford Dogs and Cars, and action recognition datasets such as HMDB51, UCF101, and mini-MIT.
Contrastive Learning with Large Memory Bank and Negative Embedding Subtraction for Accurate Copy Detection
Dec 08, 2021


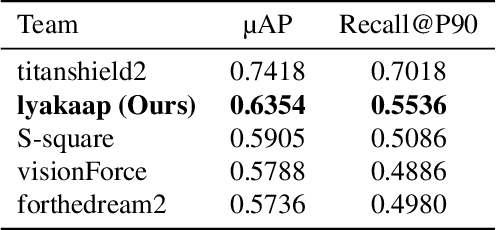
Copy detection, which is a task to determine whether an image is a modified copy of any image in a database, is an unsolved problem. Thus, we addressed copy detection by training convolutional neural networks (CNNs) with contrastive learning. Training with a large memory-bank and hard data augmentation enables the CNNs to obtain more discriminative representation. Our proposed negative embedding subtraction further boosts the copy detection accuracy. Using our methods, we achieved 1st place in the Facebook AI Image Similarity Challenge: Descriptor Track. Our code is publicly available here: \url{https://github.com/lyakaap/ISC21-Descriptor-Track-1st}