 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Feature based Cross-slide Registration
Feb 27, 2022
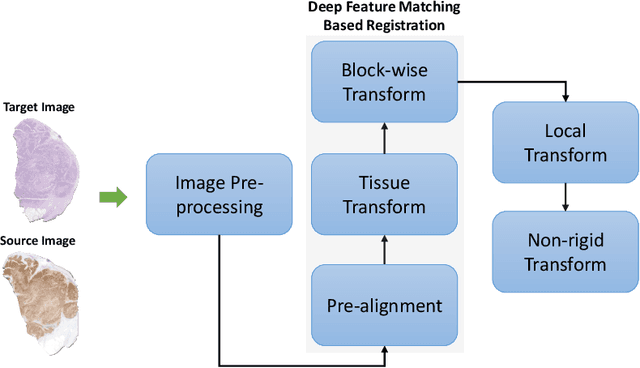
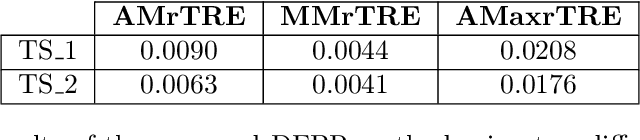
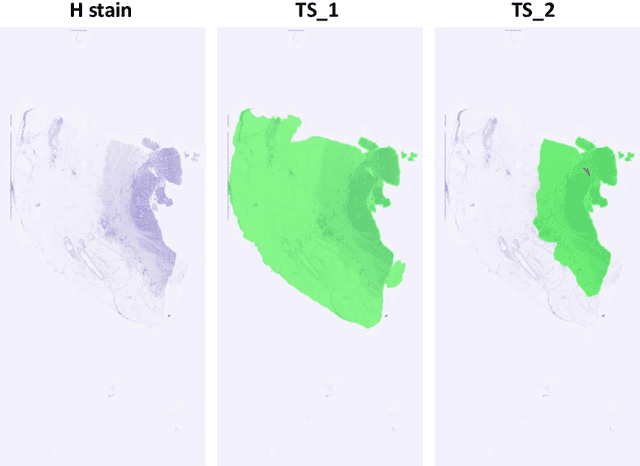
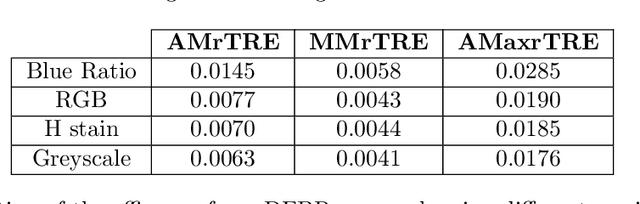
Cross-slide image analysis provides additional information by analysing the expression of different biomarkers as compared to a single slide analysis. Slides stained with different biomarkers are analysed side by side which may reveal unknown relations between the different biomarkers. During the slide preparation, a tissue section may be placed at an arbitrary orientation as compared to other sections of the same tissue block. The problem is compounded by the fact that tissue contents are likely to change from one section to the next and there may be unique artefacts on some of the slides. This makes registration of each section to a reference section of the same tissue block an important pre-requisite task before any cross-slide analysis. We propose a deep feature based registration (DFBR) method which utilises data-driven features to estimate the rigid transformation. We adopted a multi-stage strategy for improving the quality of registration. We also developed a visualisation tool to view registered pairs of WSIs at different magnifications. With the help of this tool, one can apply a transformation on the fly without the need to generate transformed source WSI in a pyramidal form. We compared the performance of data-driven features with that of hand-crafted features on the COMET dataset. Our approach can align the images with low registration errors. Generally, the success of non-rigid registration is dependent on the quality of rigid registration. To evaluate the efficacy of the DFBR method, the first two steps of the ANHIR winner's framework are replaced with our DFBR to register challenge provided image pairs. The modified framework produce comparable results to that of challenge winning team.
Enabling Deep Learning for All-in EDGE paradigm
Apr 07, 2022
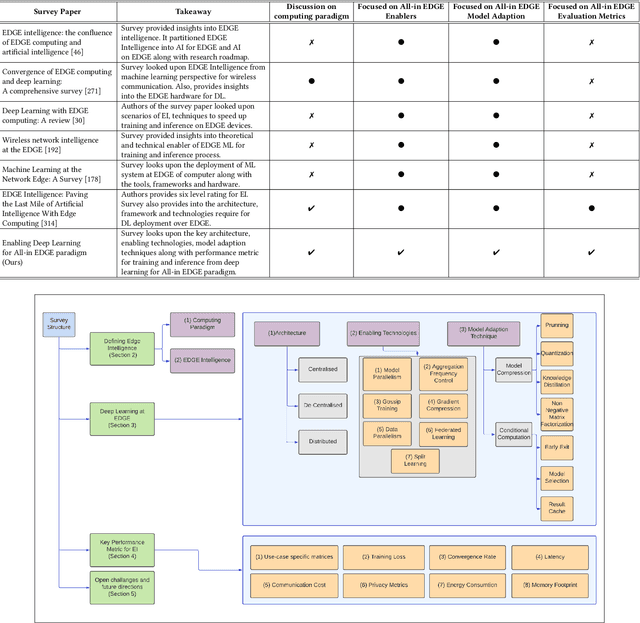
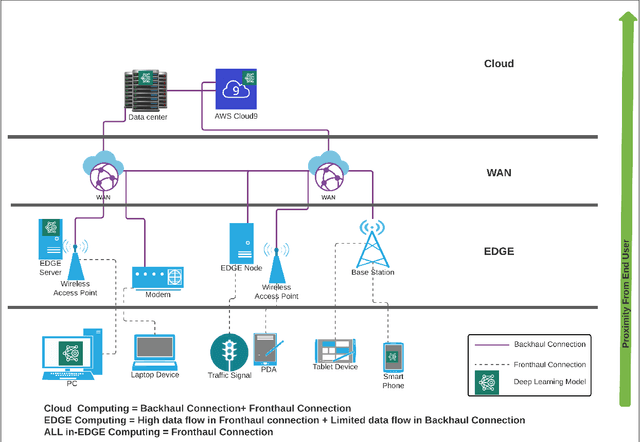
Deep Learning-based models have been widely investigated, and they have demonstrated significant performance on non-trivial tasks such as speech recognition, image processing, and natural language understanding. However, this is at the cost of substantial data requirements. Considering the widespread proliferation of edge devices (e.g. Internet of Things devices) over the last decade, Deep Learning in the edge paradigm, such as device-cloud integrated platforms, is required to leverage its superior performance. Moreover, it is suitable from the data requirements perspective in the edge paradigm because the proliferation of edge devices has resulted in an explosion in the volume of generated and collected data. However, there are difficulties due to other requirements such as high computation, high latency, and high bandwidth caused by Deep Learning applications in real-world scenarios. In this regard, this survey paper investigates Deep Learning at the edge, its architecture, enabling technologies, and model adaption techniques, where edge servers and edge devices participate in deep learning training and inference. For simplicity, we call this paradigm the All-in EDGE paradigm. Besides, this paper presents the key performance metrics for Deep Learning at the All-in EDGE paradigm to evaluate various deep learning techniques and choose a suitable design. Moreover, various open challenges arising from the deployment of Deep Learning at the All-in EDGE paradigm are identified and discussed.
Interactive Object Segmentation in 3D Point Clouds
Apr 14, 2022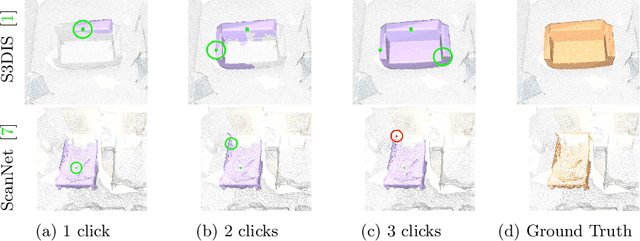
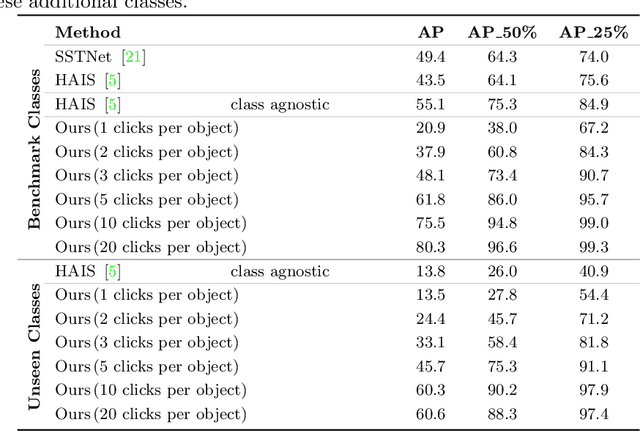
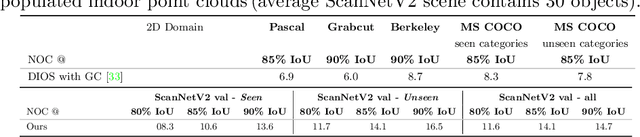
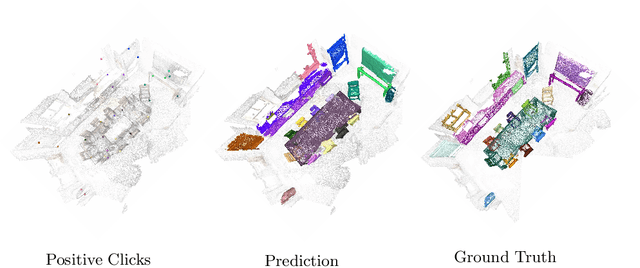
Deep learning depends on large amounts of labeled training data. Manual labeling is expensive and represents a bottleneck, especially for tasks such as segmentation, where labels must be assigned down to the level of individual points. That challenge is even more daunting for 3D data: 3D point clouds contain millions of points per scene, and their accurate annotation is markedly more time-consuming. The situation is further aggravated by the added complexity of user interfaces for 3D point clouds, which slows down annotation even more. For the case of 2D image segmentation, interactive techniques have become common, where user feedback in the form of a few clicks guides a segmentation algorithm -- nowadays usually a neural network -- to achieve an accurate labeling with minimal effort. Surprisingly, interactive segmentation of 3D scenes has not been explored much. Previous work has attempted to obtain accurate 3D segmentation masks using human feedback from the 2D domain, which is only possible if correctly aligned images are available together with the 3D point cloud, and it involves switching between the 2D and 3D domains. Here, we present an interactive 3D object segmentation method in which the user interacts directly with the 3D point cloud. Importantly, our model does not require training data from the target domain: when trained on ScanNet, it performs well on several other datasets with different data characteristics as well as different object classes. Moreover, our method is orthogonal to supervised (instance) segmentation methods and can be combined with them to refine automatic segmentations with minimal human effort.
Why adversarial training can hurt robust accuracy
Mar 03, 2022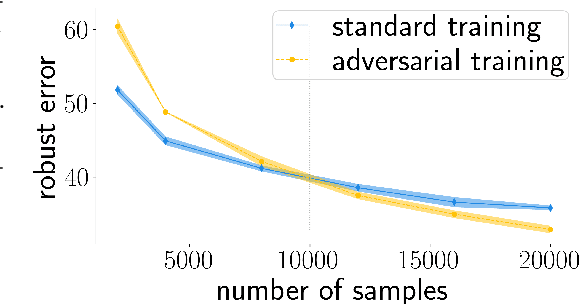
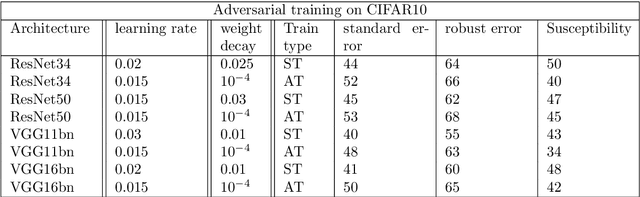

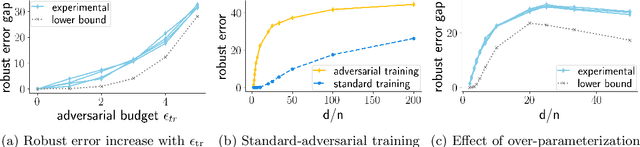
Machine learning classifiers with high test accuracy often perform poorly under adversarial attacks. It is commonly believed that adversarial training alleviates this issue. In this paper, we demonstrate that, surprisingly, the opposite may be true -- Even though adversarial training helps when enough data is available, it may hurt robust generalization in the small sample size regime. We first prove this phenomenon for a high-dimensional linear classification setting with noiseless observations. Our proof provides explanatory insights that may also transfer to feature learning models. Further, we observe in experiments on standard image datasets that the same behavior occurs for perceptible attacks that effectively reduce class information such as mask attacks and object corruptions.
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation
Mar 29, 2022
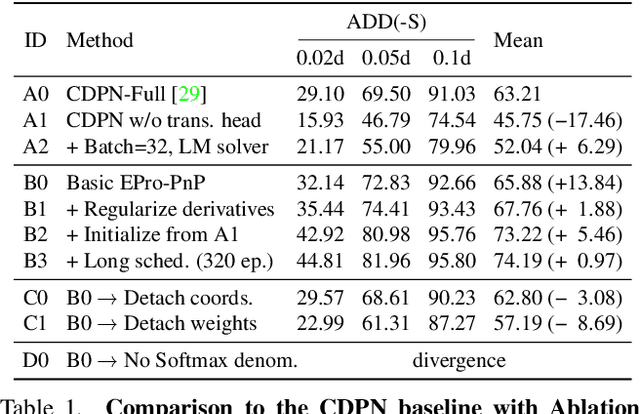
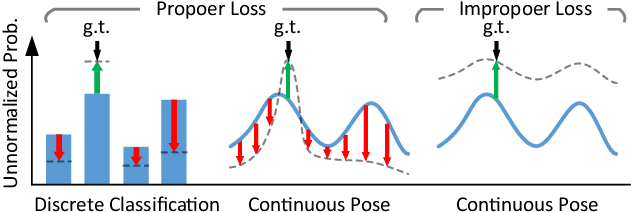
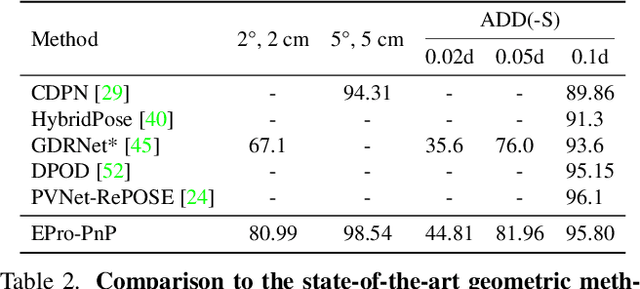
Locating 3D objects from a single RGB image via Perspective-n-Points (PnP) is a long-standing problem in computer vision. Driven by end-to-end deep learning, recent studies suggest interpreting PnP as a differentiable layer, so that 2D-3D point correspondences can be partly learned by backpropagating the gradient w.r.t. object pose. Yet, learning the entire set of unrestricted 2D-3D points from scratch fails to converge with existing approaches, since the deterministic pose is inherently non-differentiable. In this paper, we propose the EPro-PnP, a probabilistic PnP layer for general end-to-end pose estimation, which outputs a distribution of pose on the SE(3) manifold, essentially bringing categorical Softmax to the continuous domain. The 2D-3D coordinates and corresponding weights are treated as intermediate variables learned by minimizing the KL divergence between the predicted and target pose distribution. The underlying principle unifies the existing approaches and resembles the attention mechanism. EPro-PnP significantly outperforms competitive baselines, closing the gap between PnP-based method and the task-specific leaders on the LineMOD 6DoF pose estimation and nuScenes 3D object detection benchmarks.
Using Navigational Information to Learn Visual Representations
Feb 10, 2022
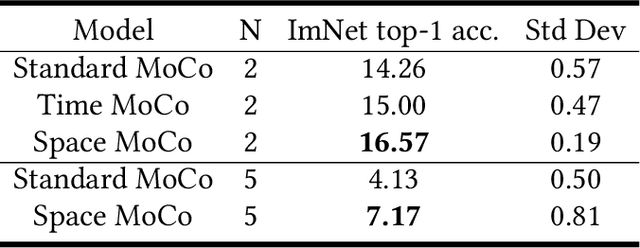
Children learn to build a visual representation of the world from unsupervised exploration and we hypothesize that a key part of this learning ability is the use of self-generated navigational information as a similarity label to drive a learning objective for self-supervised learning. The goal of this work is to exploit navigational information in a visual environment to provide performance in training that exceeds the state-of-the-art self-supervised training. Here, we show that using spatial and temporal information in the pretraining stage of contrastive learning can improve the performance of downstream classification relative to conventional contrastive learning approaches that use instance discrimination to discriminate between two alterations of the same image or two different images. We designed a pipeline to generate egocentric-vision images from a photorealistic ray-tracing environment (ThreeDWorld) and record relevant navigational information for each image. Modifying the Momentum Contrast (MoCo) model, we introduced spatial and temporal information to evaluate the similarity of two views in the pretraining stage instead of instance discrimination. This work reveals the effectiveness and efficiency of contextual information for improving representation learning. The work informs our understanding of the means by which children might learn to see the world without external supervision.
Protecting Celebrities with Identity Consistency Transformer
Mar 03, 2022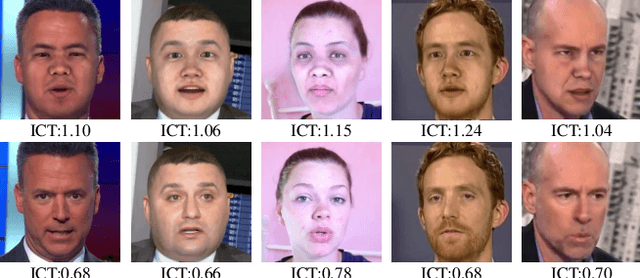
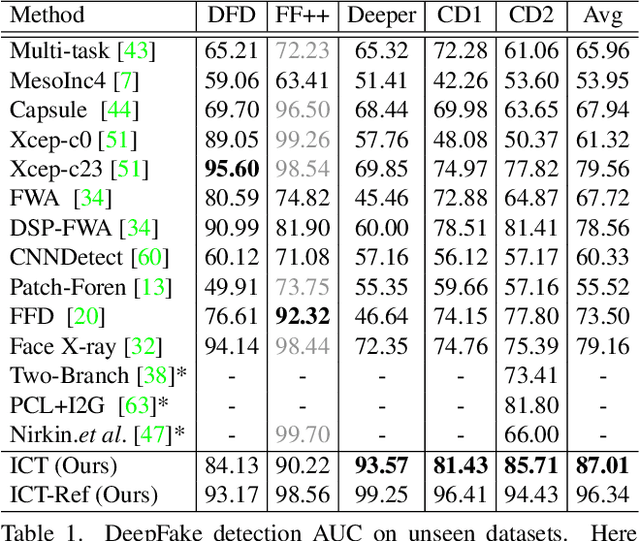

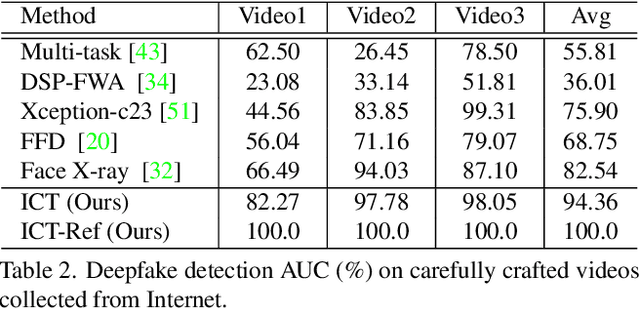
In this work we propose Identity Consistency Transformer, a novel face forgery detection method that focuses on high-level semantics, specifically identity information, and detecting a suspect face by finding identity inconsistency in inner and outer face regions. The Identity Consistency Transformer incorporates a consistency loss for identity consistency determination. We show that Identity Consistency Transformer exhibits superior generalization ability not only across different datasets but also across various types of image degradation forms found in real-world applications including deepfake videos. The Identity Consistency Transformer can be easily enhanced with additional identity information when such information is available, and for this reason it is especially well-suited for detecting face forgeries involving celebrities.
A Saliency based Feature Fusion Model for EEG Emotion Estimation
Jan 26, 2022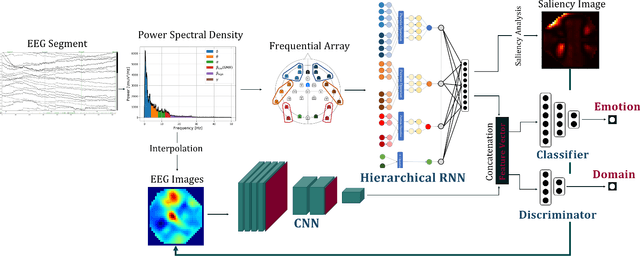

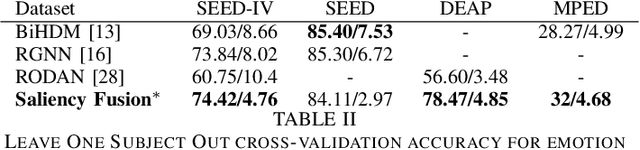
Among the different modalities to assess emotion, electroencephalogram (EEG), representing the electrical brain activity, achieved motivating results over the last decade. Emotion estimation from EEG could help in the diagnosis or rehabilitation of certain diseases. In this paper, we propose a dual model considering two different representations of EEG feature maps: 1) a sequential based representation of EEG band power, 2) an image-based representation of the feature vectors. We also propose an innovative method to combine the information based on a saliency analysis of the image-based model to promote joint learning of both model parts. The model has been evaluated on four publicly available datasets and achieves similar results to the state-of-the-art approaches. It outperforms results for two of the proposed datasets with a lower standard deviation that reflects higher stability. For sake of reproducibility, the codes and models proposed in this paper are available at https://github.com/VDelv/Emotion-EEG.
HIT-UAV: A High-altitude Infrared Thermal Dataset for Unmanned Aerial Vehicles
Apr 07, 2022

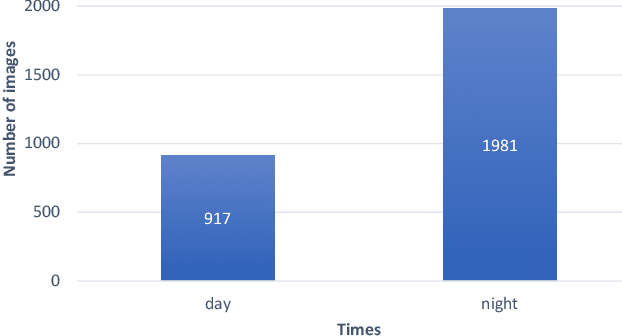

This paper presents a High-altitude infrared thermal dataset, HIT-UAV, for object detection applications on Unmanned Aerial Vehicles (UAVs). HIT-UAV contains 2898 infrared thermal images extracted from 43470 frames. These images are collected by UAV from schools, parking lots, roads, playgrounds, etc. HIT-UAV provides different flight data for each place, including flight altitude (from 60 to 130 meters), camera perspective (from 30 to 90 degrees), date, and daylight intensity. For each image, the HIT-UAV manual annotates object instances with two types of the bounding box (oriented and standard) to address the challenge that object instances have a significant overlap in aerial images. To the best of our knowledge, HIT-UAV is the first publicly available high-altitude infrared thermal UAV dataset for persons and vehicles detection. Moreover, we trained and evaluated the benchmark detection algorithms (YOLOv4 and YOLOv4-tiny) on HIT-UAV. Compared to the visual light dataset, the detection algorithms have excellent performance on HIT-UAV because the infrared thermal images do not contain a significant quantity of irrelevant information with detection objects. This indicates that infrared thermal datasets can significantly promote the development of object detection applications. We hope HIT-UAV contributes to UAV applications such as traffic surveillance and city monitoring at night. The dataset is available at https://github.com/suojiashun/HIT-UAV-Infrared-Thermal-Dataset.
Center-wise Local Image Mixture For Contrastive Representation Learning
Nov 05, 2020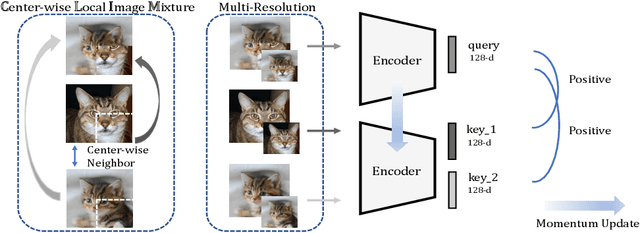
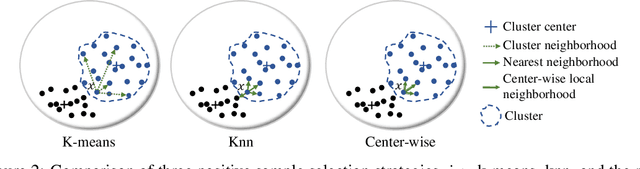
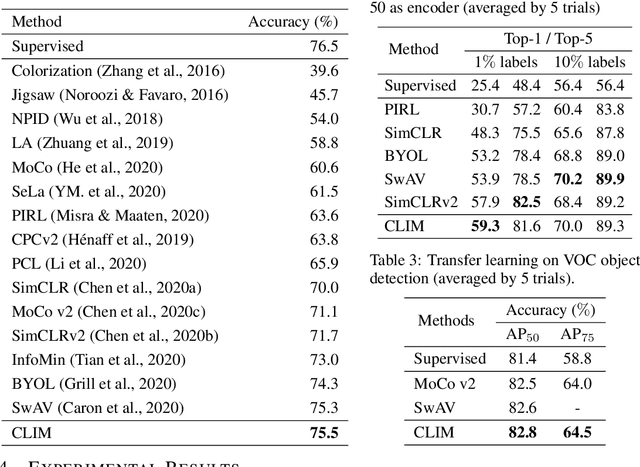
Recent advances in unsupervised representation learning have experienced remarkable progress, especially with the achievements of contrastive learning, which regards each image as well its augmentations as a separate class, while does not consider the semantic similarity among images. This paper proposes a new kind of data augmentation, named Center-wise Local Image Mixture, to expand the neighborhood space of an image. CLIM encourages both local similarity and global aggregation while pulling similar images. This is achieved by searching local similar samples of an image, and only selecting images that are closer to the corresponding cluster center, which we denote as center-wise local selection. As a result, similar representations are progressively approaching the clusters, while do not break the local similarity. Furthermore, image mixture is used as a smoothing regularization to avoid overconfidence on the selected samples. Besides, we introduce multi-resolution augmentation, which enables the representation to be scale invariant. Integrating the two augmentations produces better feature representation on several unsupervised benchmarks. Notably, we reach 75.5% top-1 accuracy with linear evaluation over ResNet-50, and 59.3% top-1 accuracy when fine-tuned with only 1% labels, as well as consistently outperforming supervised pretraining on several downstream transfer tasks.