 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Full-Spectrum Out-of-Distribution Detection
Apr 11, 2022
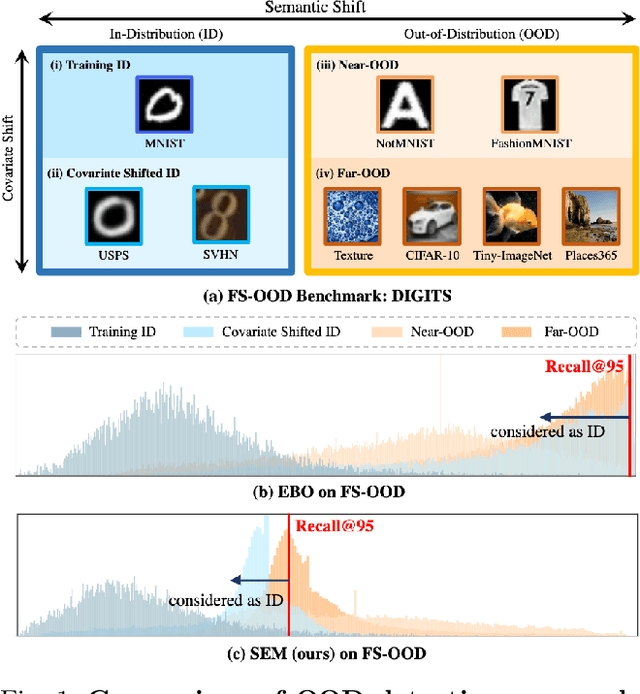
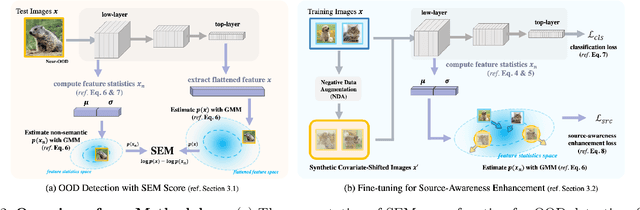
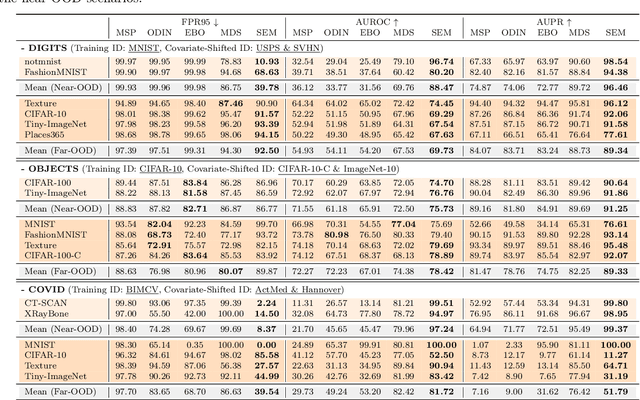
Existing out-of-distribution (OOD) detection literature clearly defines semantic shift as a sign of OOD but does not have a consensus over covariate shift. Samples experiencing covariate shift but not semantic shift are either excluded from the test set or treated as OOD, which contradicts the primary goal in machine learning -- being able to generalize beyond the training distribution. In this paper, we take into account both shift types and introduce full-spectrum OOD (FS-OOD) detection, a more realistic problem setting that considers both detecting semantic shift and being tolerant to covariate shift; and designs three benchmarks. These new benchmarks have a more fine-grained categorization of distributions (i.e., training ID, covariate-shifted ID, near-OOD, and far-OOD) for the purpose of more comprehensively evaluating the pros and cons of algorithms. To address the FS-OOD detection problem, we propose SEM, a simple feature-based semantics score function. SEM is mainly composed of two probability measures: one is based on high-level features containing both semantic and non-semantic information, while the other is based on low-level feature statistics only capturing non-semantic image styles. With a simple combination, the non-semantic part is cancelled out, which leaves only semantic information in SEM that can better handle FS-OOD detection. Extensive experiments on the three new benchmarks show that SEM significantly outperforms current state-of-the-art methods. Our code and benchmarks are released in https://github.com/Jingkang50/OpenOOD.
BankNote-Net: Open dataset for assistive universal currency recognition
Apr 07, 2022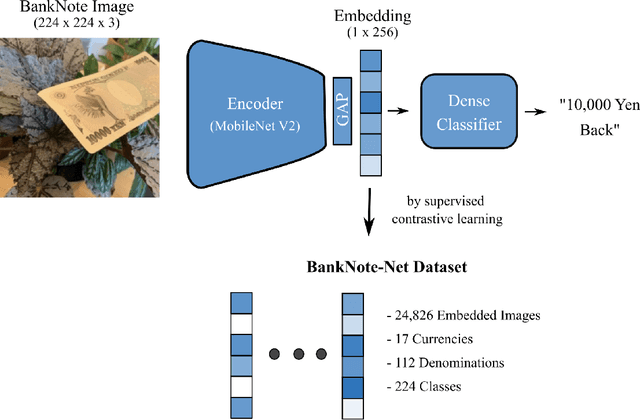
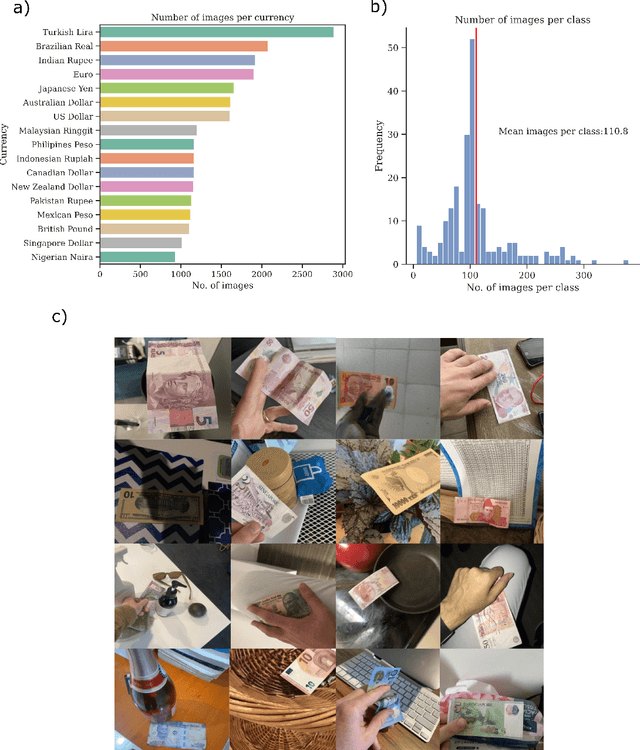
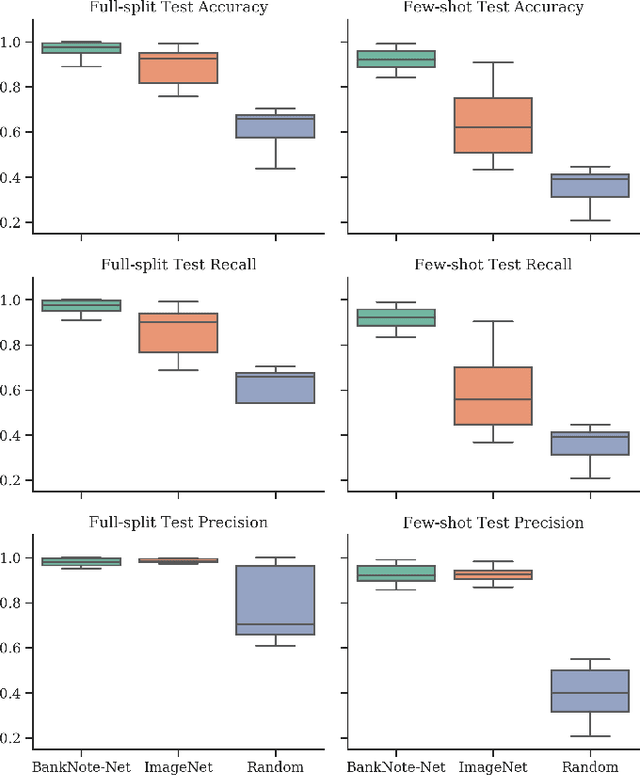
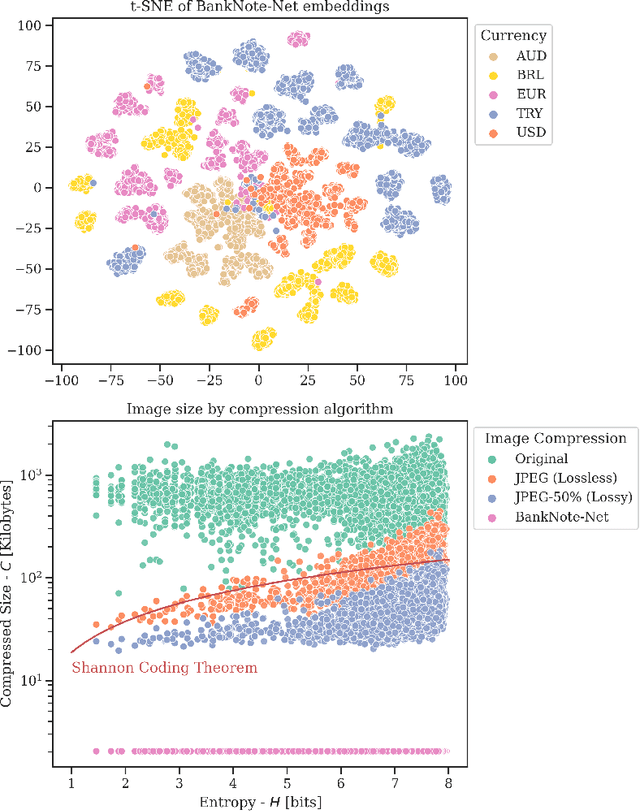
Millions of people around the world have low or no vision. Assistive software applications have been developed for a variety of day-to-day tasks, including optical character recognition, scene identification, person recognition, and currency recognition. This last task, the recognition of banknotes from different denominations, has been addressed by the use of computer vision models for image recognition. However, the datasets and models available for this task are limited, both in terms of dataset size and in variety of currencies covered. In this work, we collect a total of 24,826 images of banknotes in variety of assistive settings, spanning 17 currencies and 112 denominations. Using supervised contrastive learning, we develop a machine learning model for universal currency recognition. This model learns compliant embeddings of banknote images in a variety of contexts, which can be shared publicly (as a compressed vector representation), and can be used to train and test specialized downstream models for any currency, including those not covered by our dataset or for which only a few real images per denomination are available (few-shot learning). We deploy a variation of this model for public use in the last version of the Seeing AI app developed by Microsoft. We share our encoder model and the embeddings as an open dataset in our BankNote-Net repository.
IAE-Net: Integral Autoencoders for Discretization-Invariant Learning
Mar 30, 2022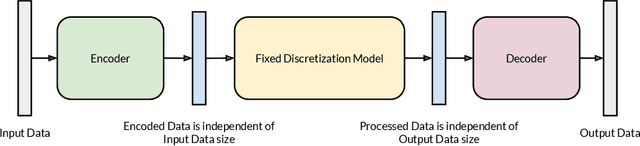

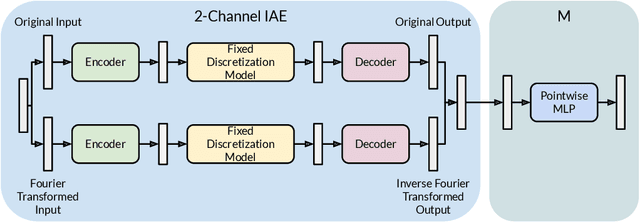

Discretization invariant learning aims at learning in the infinite-dimensional function spaces with the capacity to process heterogeneous discrete representations of functions as inputs and/or outputs of a learning model. This paper proposes a novel deep learning framework based on integral autoencoders (IAE-Net) for discretization invariant learning. The basic building block of IAE-Net consists of an encoder and a decoder as integral transforms with data-driven kernels, and a fully connected neural network between the encoder and decoder. This basic building block is applied in parallel in a wide multi-channel structure, which are repeatedly composed to form a deep and densely connected neural network with skip connections as IAE-Net. IAE-Net is trained with randomized data augmentation that generates training data with heterogeneous structures to facilitate the performance of discretization invariant learning. The proposed IAE-Net is tested with various applications in predictive data science, solving forward and inverse problems in scientific computing, and signal/image processing. Compared with alternatives in the literature, IAE-Net achieves state-of-the-art performance in existing applications and creates a wide range of new applications.
Contrastive Learning with Large Memory Bank and Negative Embedding Subtraction for Accurate Copy Detection
Dec 08, 2021


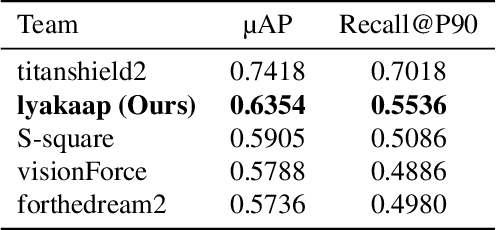
Copy detection, which is a task to determine whether an image is a modified copy of any image in a database, is an unsolved problem. Thus, we addressed copy detection by training convolutional neural networks (CNNs) with contrastive learning. Training with a large memory-bank and hard data augmentation enables the CNNs to obtain more discriminative representation. Our proposed negative embedding subtraction further boosts the copy detection accuracy. Using our methods, we achieved 1st place in the Facebook AI Image Similarity Challenge: Descriptor Track. Our code is publicly available here: \url{https://github.com/lyakaap/ISC21-Descriptor-Track-1st}
Bina-Rep Event Frames: a Simple and Effective Representation for Event-based cameras
Feb 28, 2022
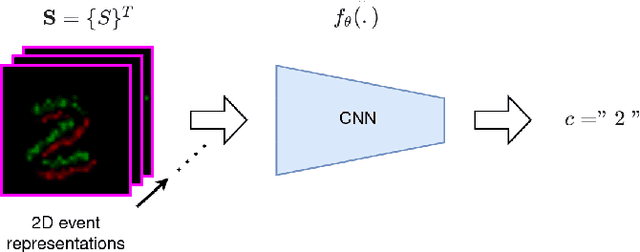
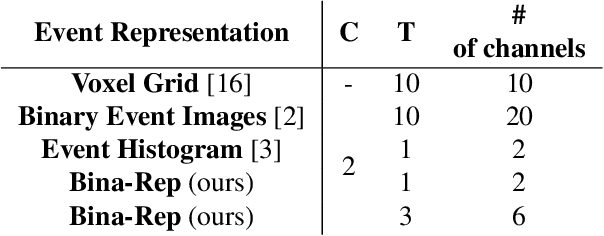
This paper presents "Bina-Rep", a simple representation method that converts asynchronous streams of events from event cameras to a sequence of sparse and expressive event frames. By representing multiple binary event images as a single frame of $N$-bit numbers, our method is able to obtain sparser and more expressive event frames thanks to the retained information about event orders in the original stream. Coupled with our proposed model based on a convolutional neural network, the reported results achieve state-of-the-art performance and repeatedly outperforms other common event representation methods. Our approach also shows competitive robustness against common image corruptions, compared to other representation techniques.
Vision Transformer Compression with Structured Pruning and Low Rank Approximation
Mar 25, 2022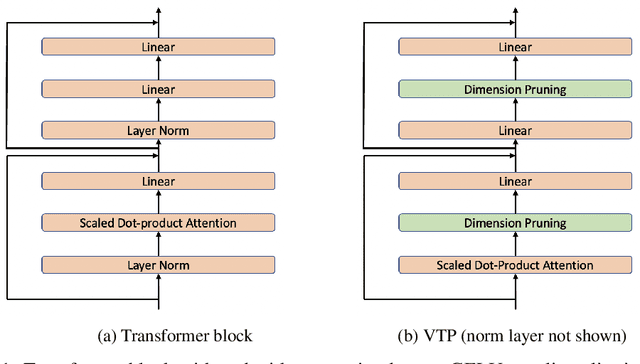
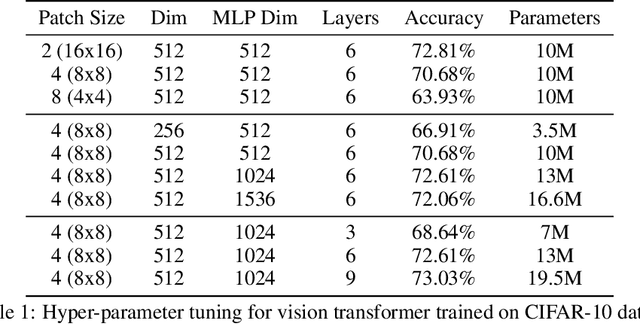
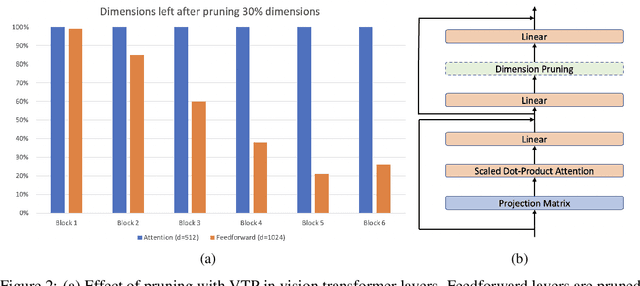
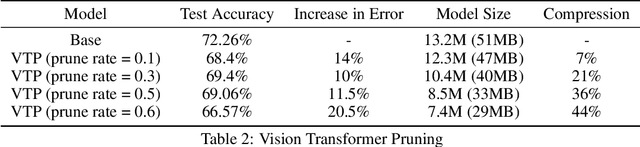
Transformer architecture has gained popularity due to its ability to scale with large dataset. Consequently, there is a need to reduce the model size and latency, especially for on-device deployment. We focus on vision transformer proposed for image recognition task (Dosovitskiy et al., 2021), and explore the application of different compression techniques such as low rank approximation and pruning for this purpose. Specifically, we investigate a structured pruning method proposed recently in Zhu et al. (2021) and find that mostly feedforward blocks are pruned with this approach, that too, with severe degradation in accuracy. We propose a hybrid compression approach to mitigate this where we compress the attention blocks using low rank approximation and use the previously mentioned pruning with a lower rate for feedforward blocks in each transformer layer. Our technique results in 50% compression with 14% relative increase in classification error whereas we obtain 44% compression with 20% relative increase in error when only pruning is applied. We propose further enhancements to bridge the accuracy gap but leave it as a future work.
Unsupervised domain adaptation and super resolution on drone images for autonomous dry herbage biomass estimation
Apr 18, 2022
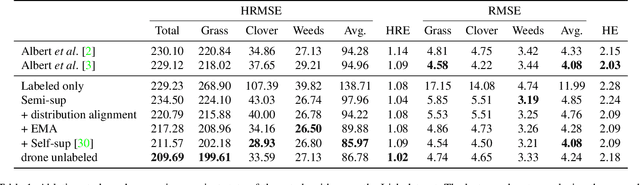

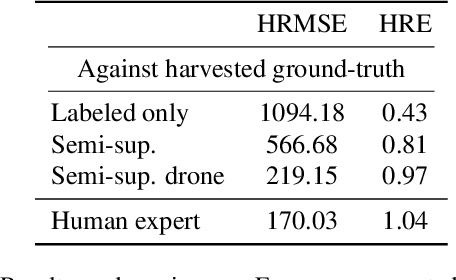
Herbage mass yield and composition estimation is an important tool for dairy farmers to ensure an adequate supply of high quality herbage for grazing and subsequently milk production. By accurately estimating herbage mass and composition, targeted nitrogen fertiliser application strategies can be deployed to improve localised regions in a herbage field, effectively reducing the negative impacts of over-fertilization on biodiversity and the environment. In this context, deep learning algorithms offer a tempting alternative to the usual means of sward composition estimation, which involves the destructive process of cutting a sample from the herbage field and sorting by hand all plant species in the herbage. The process is labour intensive and time consuming and so not utilised by farmers. Deep learning has been successfully applied in this context on images collected by high-resolution cameras on the ground. Moving the deep learning solution to drone imaging, however, has the potential to further improve the herbage mass yield and composition estimation task by extending the ground-level estimation to the large surfaces occupied by fields/paddocks. Drone images come at the cost of lower resolution views of the fields taken from a high altitude and requires further herbage ground-truth collection from the large surfaces covered by drone images. This paper proposes to transfer knowledge learned on ground-level images to raw drone images in an unsupervised manner. To do so, we use unpaired image style translation to enhance the resolution of drone images by a factor of eight and modify them to appear closer to their ground-level counterparts. We then ... ~\url{www.github.com/PaulAlbert31/Clover_SSL}.
SurroundDepth: Entangling Surrounding Views for Self-Supervised Multi-Camera Depth Estimation
Apr 07, 2022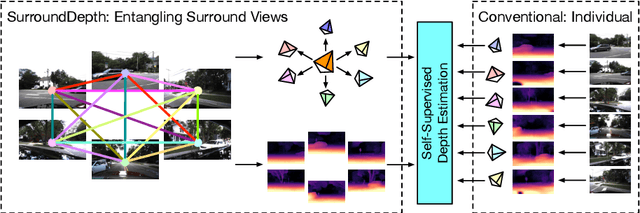
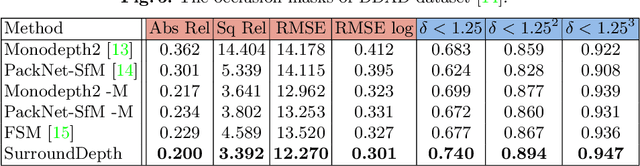
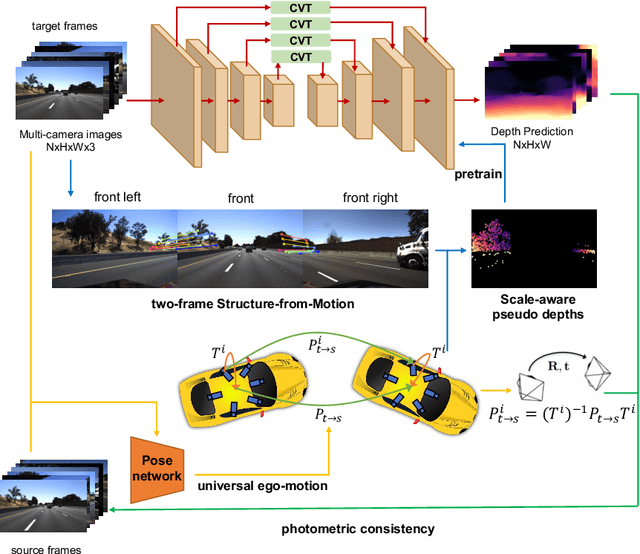

Depth estimation from images serves as the fundamental step of 3D perception for autonomous driving and is an economical alternative to expensive depth sensors like LiDAR. The temporal photometric consistency enables self-supervised depth estimation without labels, further facilitating its application. However, most existing methods predict the depth solely based on each monocular image and ignore the correlations among multiple surrounding cameras, which are typically available for modern self-driving vehicles. In this paper, we propose a SurroundDepth method to incorporate the information from multiple surrounding views to predict depth maps across cameras. Specifically, we employ a joint network to process all the surrounding views and propose a cross-view transformer to effectively fuse the information from multiple views. We apply cross-view self-attention to efficiently enable the global interactions between multi-camera feature maps. Different from self-supervised monocular depth estimation, we are able to predict real-world scales given multi-camera extrinsic matrices. To achieve this goal, we adopt structure-from-motion to extract scale-aware pseudo depths to pretrain the models. Further, instead of predicting the ego-motion of each individual camera, we estimate a universal ego-motion of the vehicle and transfer it to each view to achieve multi-view consistency. In experiments, our method achieves the state-of-the-art performance on the challenging multi-camera depth estimation datasets DDAD and nuScenes.
DualConv: Dual Convolutional Kernels for Lightweight Deep Neural Networks
Feb 15, 2022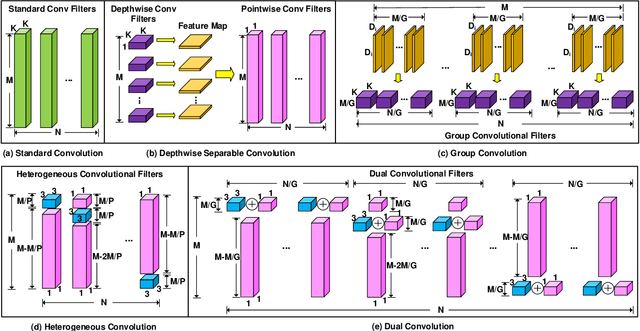
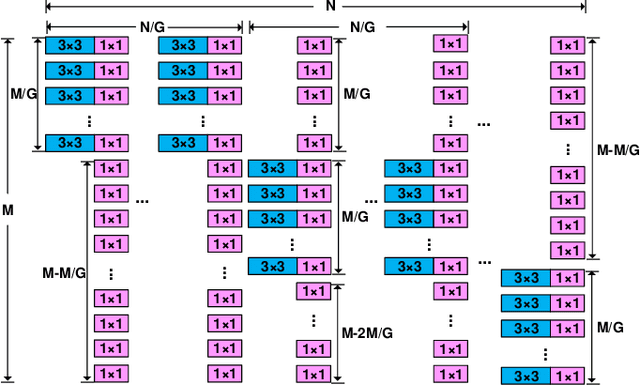
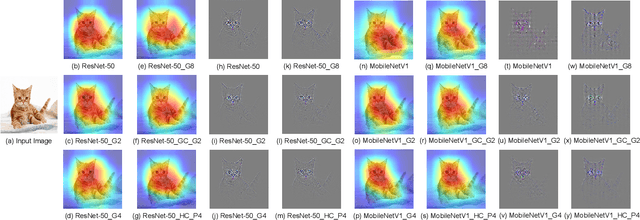
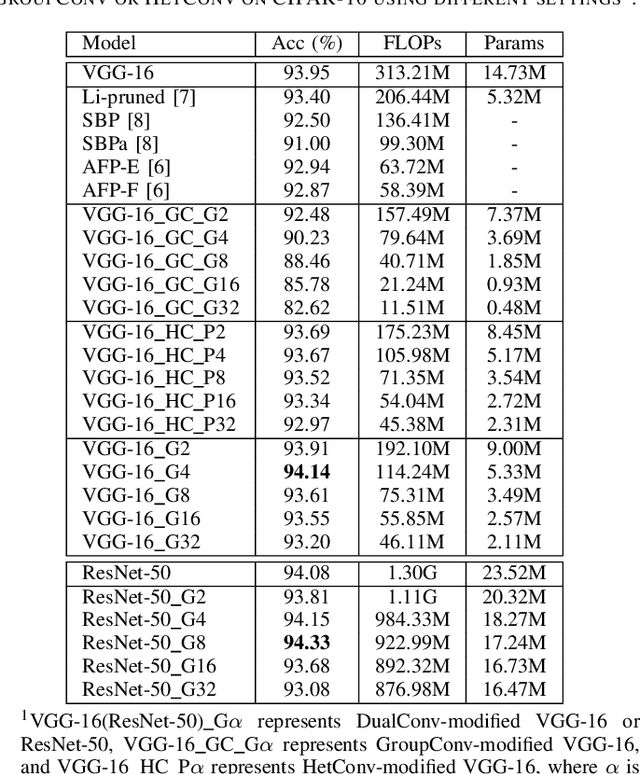
CNN architectures are generally heavy on memory and computational requirements which makes them infeasible for embedded systems with limited hardware resources. We propose dual convolutional kernels (DualConv) for constructing lightweight deep neural networks. DualConv combines 3$\times$3 and 1$\times$1 convolutional kernels to process the same input feature map channels simultaneously and exploits the group convolution technique to efficiently arrange convolutional filters. DualConv can be employed in any CNN model such as VGG-16 and ResNet-50 for image classification, YOLO and R-CNN for object detection, or FCN for semantic segmentation. In this paper, we extensively test DualConv for classification since these network architectures form the backbones for many other tasks. We also test DualConv for image detection on YOLO-V3. Experimental results show that, combined with our structural innovations, DualConv significantly reduces the computational cost and number of parameters of deep neural networks while surprisingly achieving slightly higher accuracy than the original models in some cases. We use DualConv to further reduce the number of parameters of the lightweight MobileNetV2 by 54% with only 0.68% drop in accuracy on CIFAR-100 dataset. When the number of parameters is not an issue, DualConv increases the accuracy of MobileNetV1 by 4.11% on the same dataset. Furthermore, DualConv significantly improves the YOLO-V3 object detection speed and improves its accuracy by 4.4% on PASCAL VOC dataset.
Iterative Deep Homography Estimation
Mar 30, 2022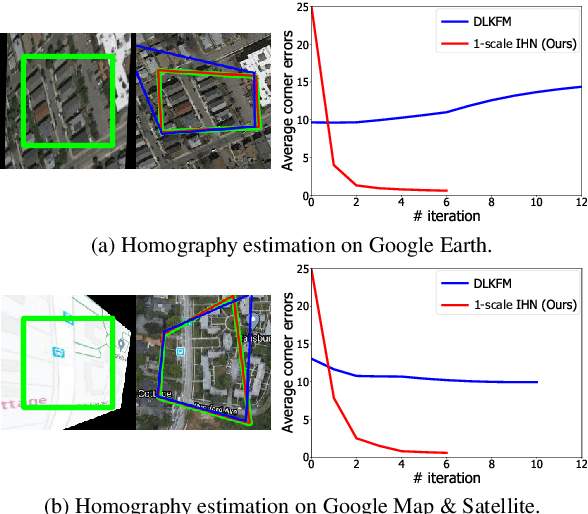
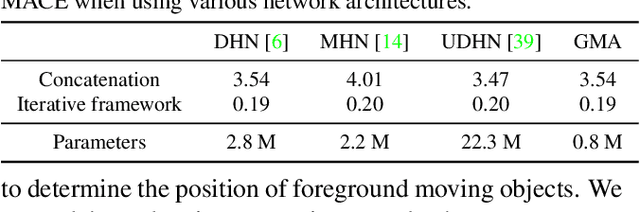
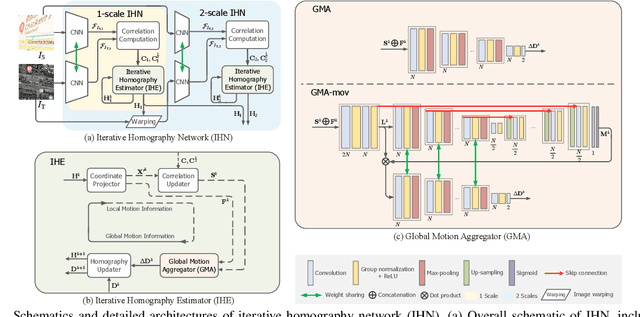
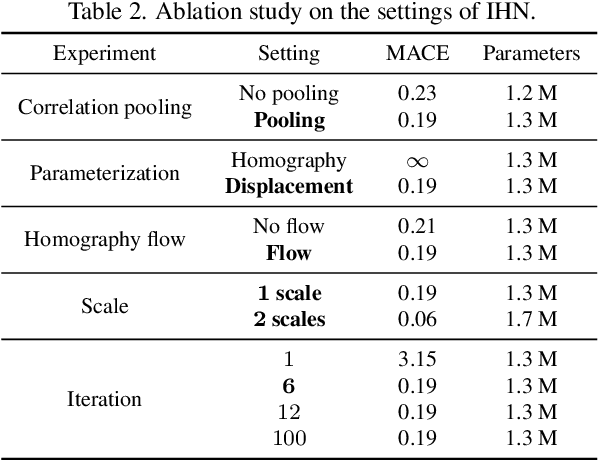
We propose Iterative Homography Network, namely IHN, a new deep homography estimation architecture. Different from previous works that achieve iterative refinement by network cascading or untrainable IC-LK iterator, the iterator of IHN has tied weights and is completely trainable. IHN achieves state-of-the-art accuracy on several datasets including challenging scenes. We propose 2 versions of IHN: (1) IHN for static scenes, (2) IHN-mov for dynamic scenes with moving objects. Both versions can be arranged in 1-scale for efficiency or 2-scale for accuracy. We show that the basic 1-scale IHN already outperforms most of the existing methods. On a variety of datasets, the 2-scale IHN outperforms all competitors by a large gap. We introduce IHN-mov by producing an inlier mask to further improve the estimation accuracy of moving-objects scenes. We experimentally show that the iterative framework of IHN can achieve 95% error reduction while considerably saving network parameters. When processing sequential image pairs, IHN can achieve 32.7 fps, which is about 8x the speed of IC-LK iterator. Source code is available at https://github.com/imdumpl78/IHN.