 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Optimization of phase-only holograms calculated with scaled diffraction calculation through deep neural networks
Dec 02, 2021

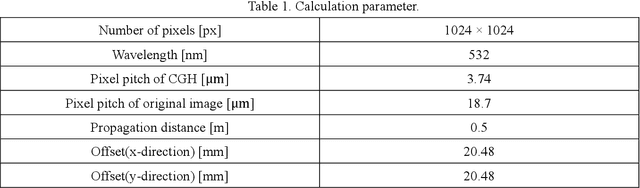
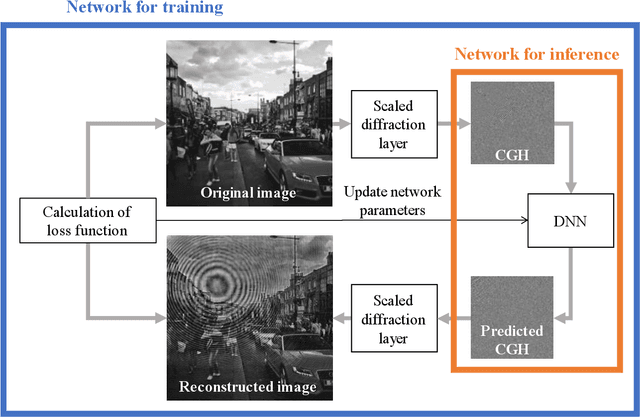
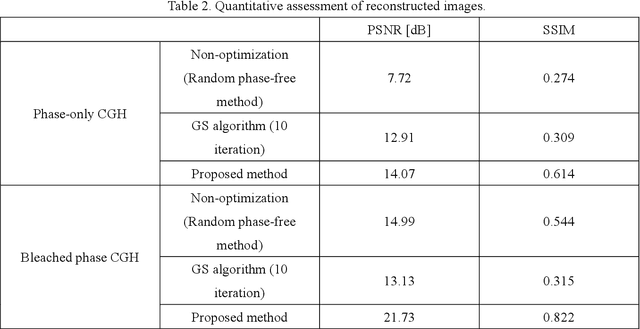
Computer-generated holograms (CGHs) are used in holographic three-dimensional (3D) displays and holographic projections. The quality of the reconstructed images using phase-only CGHs is degraded because the amplitude of the reconstructed image is difficult to control. Iterative optimization methods such as the Gerchberg-Saxton (GS) algorithm are one option for improving image quality. They optimize CGHs in an iterative fashion to obtain a higher image quality. However, such iterative computation is time consuming, and the improvement in image quality is often stagnant. Recently, deep learning-based hologram computation has been proposed. Deep neural networks directly infer CGHs from input image data. However, it is limited to reconstructing images that are the same size as the hologram. In this study, we use deep learning to optimize phase-only CGHs generated using scaled diffraction computations and the random phase-free method. By combining the random phase-free method with the scaled diffraction computation, it is possible to handle a zoomable reconstructed image larger than the hologram. In comparison to the GS algorithm, the proposed method optimizes both high quality and speed.
FaceVerse: a Fine-grained and Detail-controllable 3D Face Morphable Model from a Hybrid Dataset
Mar 29, 2022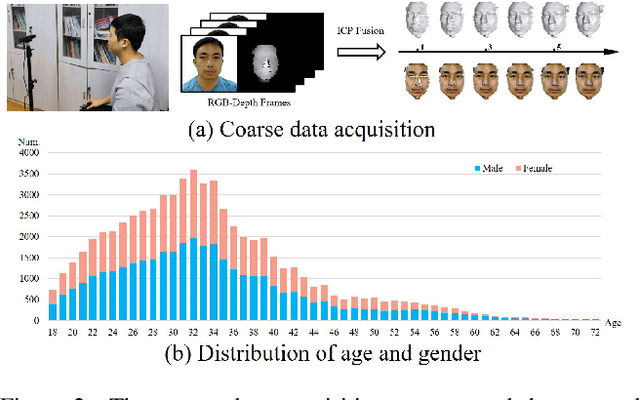
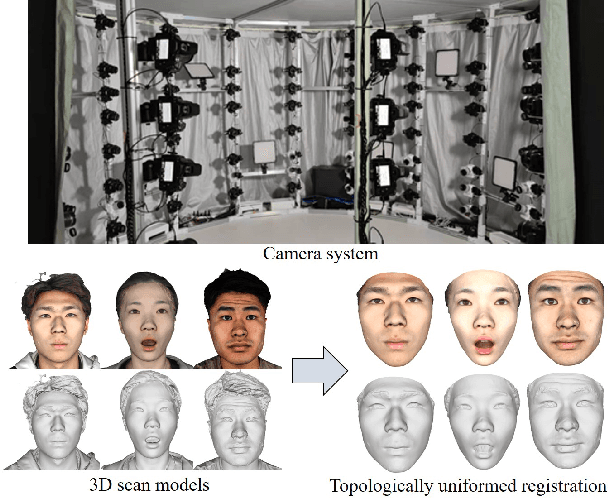
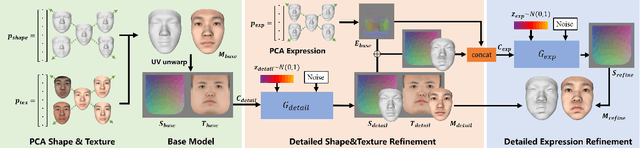
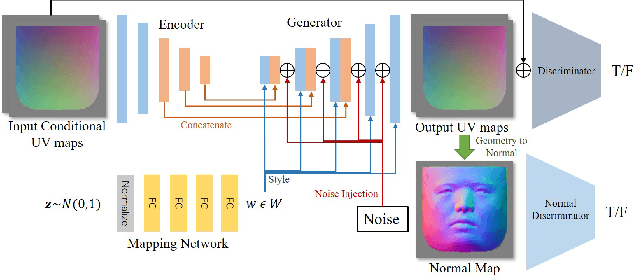
We present FaceVerse, a fine-grained 3D Neural Face Model, which is built from hybrid East Asian face datasets containing 60K fused RGB-D images and 2K high-fidelity 3D head scan models. A novel coarse-to-fine structure is proposed to take better advantage of our hybrid dataset. In the coarse module, we generate a base parametric model from large-scale RGB-D images, which is able to predict accurate rough 3D face models in different genders, ages, etc. Then in the fine module, a conditional StyleGAN architecture trained with high-fidelity scan models is introduced to enrich elaborate facial geometric and texture details. Note that different from previous methods, our base and detailed modules are both changeable, which enables an innovative application of adjusting both the basic attributes and the facial details of 3D face models. Furthermore, we propose a single-image fitting framework based on differentiable rendering. Rich experiments show that our method outperforms the state-of-the-art methods.
A Field of Experts Prior for Adapting Neural Networks at Test Time
Feb 10, 2022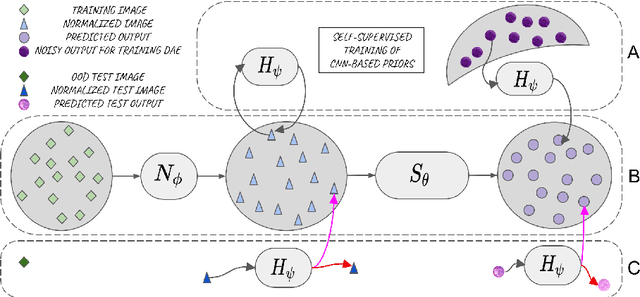
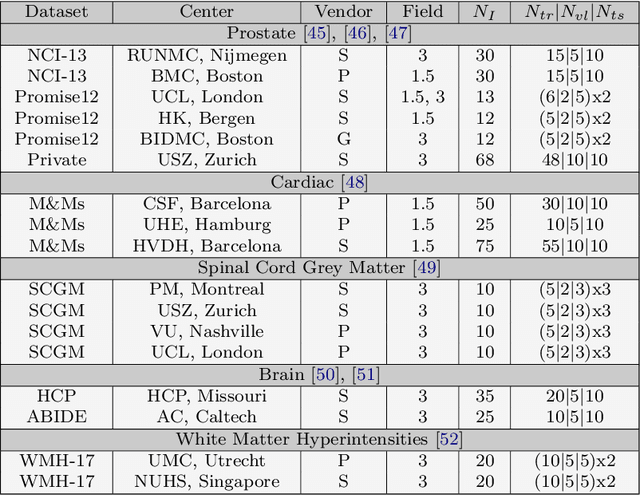
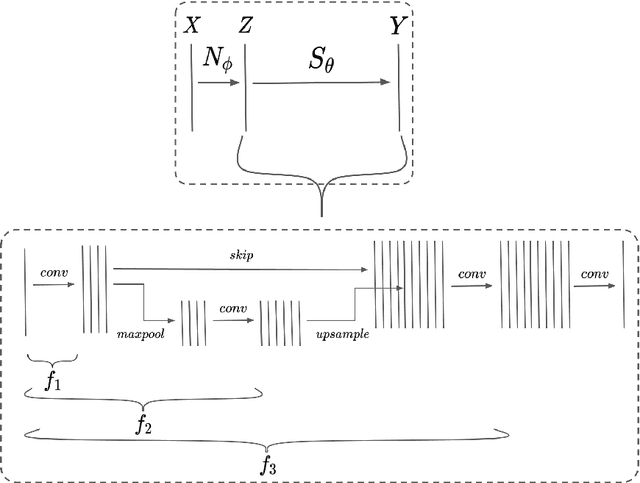
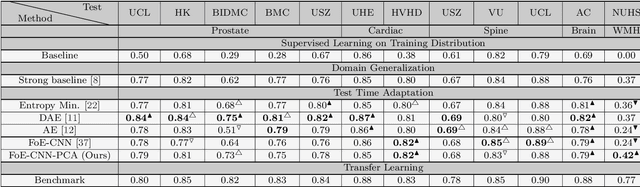
Performance of convolutional neural networks (CNNs) in image analysis tasks is often marred in the presence of acquisition-related distribution shifts between training and test images. Recently, it has been proposed to tackle this problem by fine-tuning trained CNNs for each test image. Such test-time-adaptation (TTA) is a promising and practical strategy for improving robustness to distribution shifts as it requires neither data sharing between institutions nor annotating additional data. Previous TTA methods use a helper model to increase similarity between outputs and/or features extracted from a test image with those of the training images. Such helpers, which are typically modeled using CNNs, can be task-specific and themselves vulnerable to distribution shifts in their inputs. To overcome these problems, we propose to carry out TTA by matching the feature distributions of test and training images, as modelled by a field-of-experts (FoE) prior. FoEs model complicated probability distributions as products of many simpler expert distributions. We use 1D marginal distributions of a trained task CNN's features as experts in the FoE model. Further, we compute principal components of patches of the task CNN's features, and consider the distributions of PCA loadings as additional experts. We validate the method on 5 MRI segmentation tasks (healthy tissues in 4 anatomical regions and lesions in 1 one anatomy), using data from 17 clinics, and on a MRI registration task, using data from 3 clinics. We find that the proposed FoE-based TTA is generically applicable in multiple tasks, and outperforms all previous TTA methods for lesion segmentation. For healthy tissue segmentation, the proposed method outperforms other task-agnostic methods, but a previous TTA method which is specifically designed for segmentation performs the best for most of the tested datasets. Our code is publicly available.
A new public Alsat-2B dataset for single-image super-resolution
Mar 21, 2021

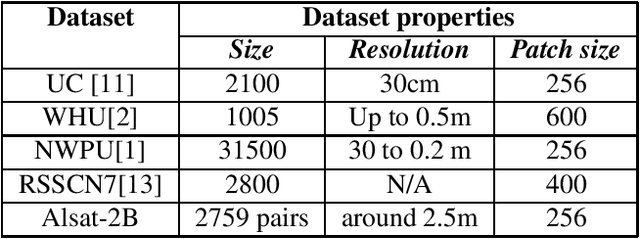
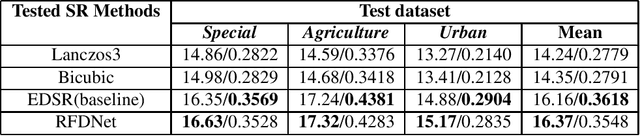
Currently, when reliable training datasets are available, deep learning methods dominate the proposed solutions for image super-resolution. However, for remote sensing benchmarks, it is very expensive to obtain high spatial resolution images. Most of the super-resolution methods use down-sampling techniques to simulate low and high spatial resolution pairs and construct the training samples. To solve this issue, the paper introduces a novel public remote sensing dataset (Alsat2B) of low and high spatial resolution images (10m and 2.5m respectively) for the single-image super-resolution task. The high-resolution images are obtained through pan-sharpening. Besides, the performance of some super-resolution methods on the dataset is assessed based on common criteria. The obtained results reveal that the proposed scheme is promising and highlight the challenges in the dataset which shows the need for advanced methods to grasp the relationship between the low and high-resolution patches.
Language-Driven Region Pointer Advancement for Controllable Image Captioning
Nov 30, 2020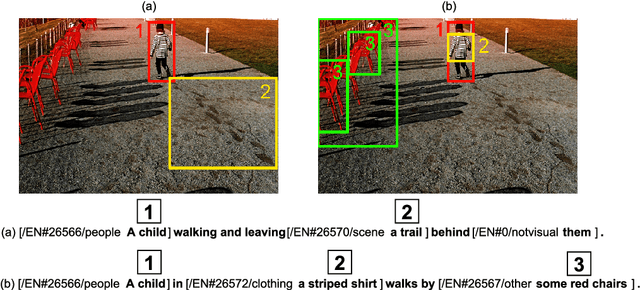
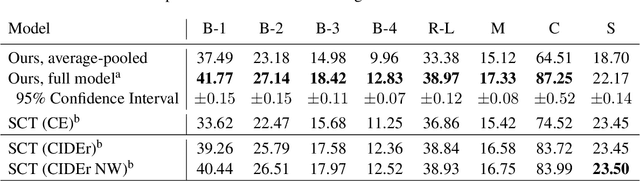
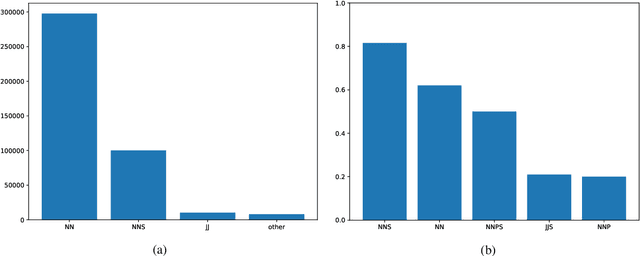
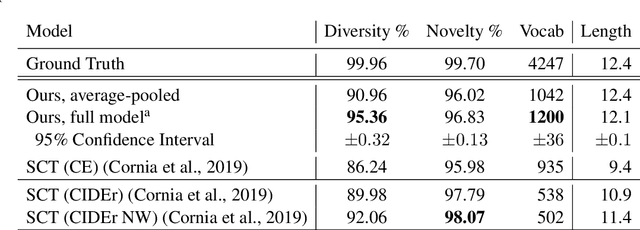
Controllable Image Captioning is a recent sub-field in the multi-modal task of Image Captioning wherein constraints are placed on which regions in an image should be described in the generated natural language caption. This puts a stronger focus on producing more detailed descriptions, and opens the door for more end-user control over results. A vital component of the Controllable Image Captioning architecture is the mechanism that decides the timing of attending to each region through the advancement of a region pointer. In this paper, we propose a novel method for predicting the timing of region pointer advancement by treating the advancement step as a natural part of the language structure via a NEXT-token, motivated by a strong correlation to the sentence structure in the training data. We find that our timing agrees with the ground-truth timing in the Flickr30k Entities test data with a precision of 86.55% and a recall of 97.92%. Our model implementing this technique improves the state-of-the-art on standard captioning metrics while additionally demonstrating a considerably larger effective vocabulary size.
Learning Omni-frequency Region-adaptive Representations for Real Image Super-Resolution
Jan 10, 2021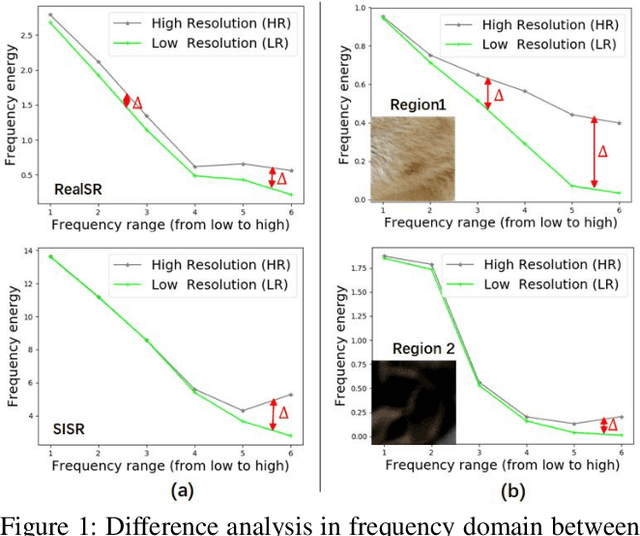
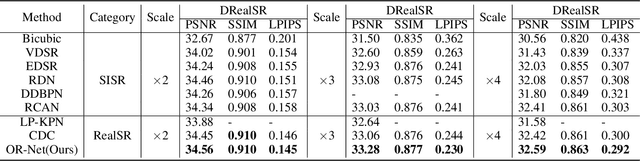
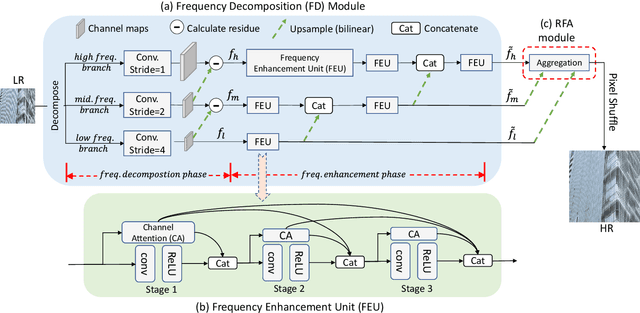
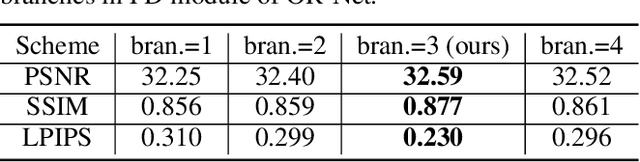
Traditional single image super-resolution (SISR) methods that focus on solving single and uniform degradation (i.e., bicubic down-sampling), typically suffer from poor performance when applied into real-world low-resolution (LR) images due to the complicated realistic degradations. The key to solving this more challenging real image super-resolution (RealSR) problem lies in learning feature representations that are both informative and content-aware. In this paper, we propose an Omni-frequency Region-adaptive Network (ORNet) to address both challenges, here we call features of all low, middle and high frequencies omni-frequency features. Specifically, we start from the frequency perspective and design a Frequency Decomposition (FD) module to separate different frequency components to comprehensively compensate the information lost for real LR image. Then, considering the different regions of real LR image have different frequency information lost, we further design a Region-adaptive Frequency Aggregation (RFA) module by leveraging dynamic convolution and spatial attention to adaptively restore frequency components for different regions. The extensive experiments endorse the effective, and scenario-agnostic nature of our OR-Net for RealSR.
Exploring Category-correlated Feature for Few-shot Image Classification
Dec 14, 2021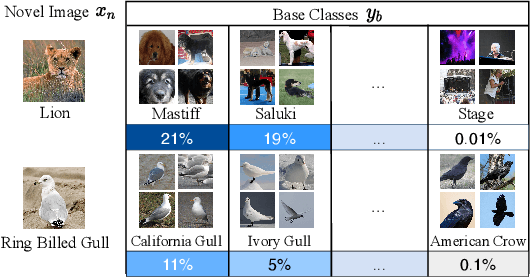
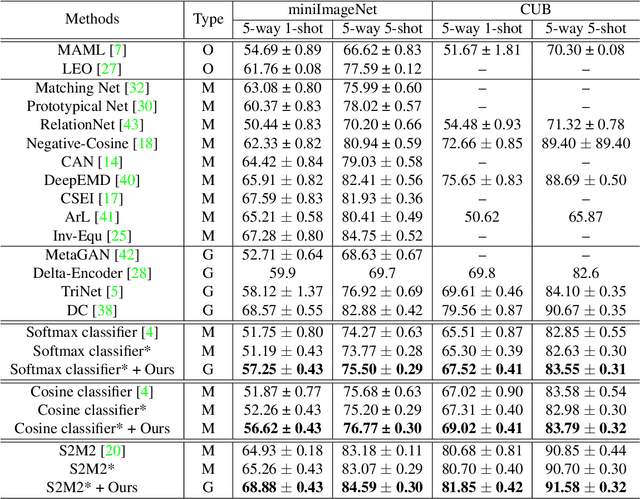

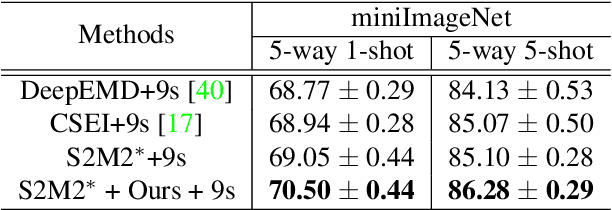
Few-shot classification aims to adapt classifiers to novel classes with a few training samples. However, the insufficiency of training data may cause a biased estimation of feature distribution in a certain class. To alleviate this problem, we present a simple yet effective feature rectification method by exploring the category correlation between novel and base classes as the prior knowledge. We explicitly capture such correlation by mapping features into a latent vector with dimension matching the number of base classes, treating it as the logarithm probability of the feature over base classes. Based on this latent vector, the rectified feature is directly constructed by a decoder, which we expect maintaining category-related information while removing other stochastic factors, and consequently being closer to its class centroid. Furthermore, by changing the temperature value in softmax, we can re-balance the feature rectification and reconstruction for better performance. Our method is generic, flexible and agnostic to any feature extractor and classifier, readily to be embedded into existing FSL approaches. Experiments verify that our method is capable of rectifying biased features, especially when the feature is far from the class centroid. The proposed approach consistently obtains considerable performance gains on three widely used benchmarks, evaluated with different backbones and classifiers. The code will be made public.
Muscle Vision: Real Time Keypoint Based Pose Classification of Physical Exercises
Mar 23, 2022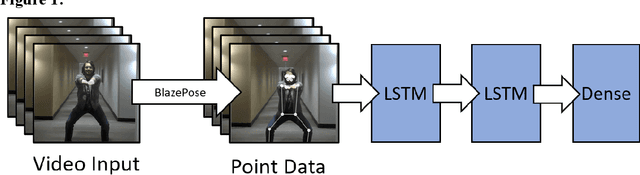
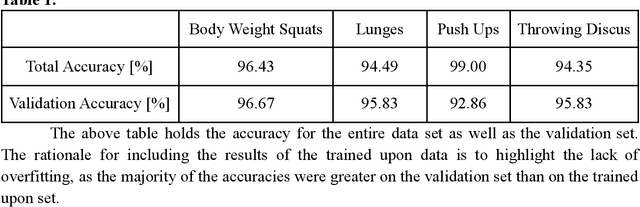
Recent advances in machine learning technology have enabled highly portable and performant models for many common tasks, especially in image recognition. One emerging field, 3D human pose recognition extrapolated from video, has now advanced to the point of enabling real-time software applications with robust enough output to support downstream machine learning tasks. In this work we propose a new machine learning pipeline and web interface that performs human pose recognition on a live video feed to detect when common exercises are performed and classify them accordingly. We present a model interface capable of webcam input with live display of classification results. Our main contributions include a keypoint and time series based lightweight approach for classifying a selected set of fitness exercises and a web-based software application for obtaining and visualizing the results in real time.
Denoising Diffusion Restoration Models
Feb 04, 2022
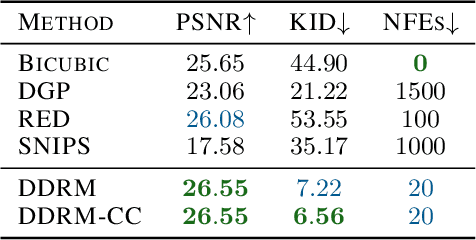
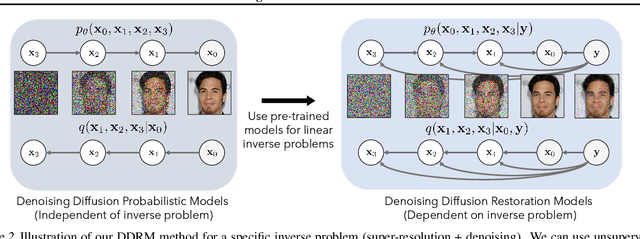
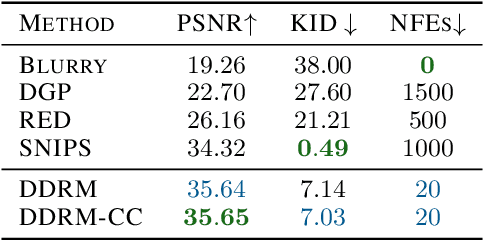
Many interesting tasks in image restoration can be cast as linear inverse problems. A recent family of approaches for solving these problems uses stochastic algorithms that sample from the posterior distribution of natural images given the measurements. However, efficient solutions often require problem-specific supervised training to model the posterior, whereas unsupervised methods that are not problem-specific typically rely on inefficient iterative methods. This work addresses these issues by introducing Denoising Diffusion Restoration Models (DDRM), an efficient, unsupervised posterior sampling method. Motivated by variational inference, DDRM takes advantage of a pre-trained denoising diffusion generative model for solving any linear inverse problem. We demonstrate DDRM's versatility on several image datasets for super-resolution, deblurring, inpainting, and colorization under various amounts of measurement noise. DDRM outperforms the current leading unsupervised methods on the diverse ImageNet dataset in reconstruction quality, perceptual quality, and runtime, being 5x faster than the nearest competitor. DDRM also generalizes well for natural images out of the distribution of the observed ImageNet training set.
A Generic Approach for Enhancing GANs by Regularized Latent Optimization
Dec 07, 2021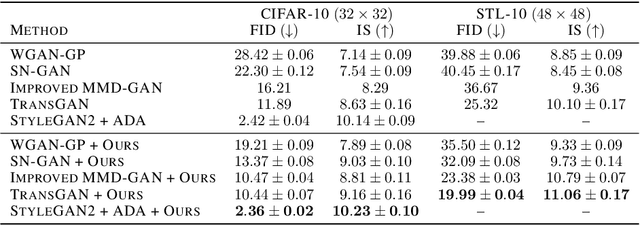

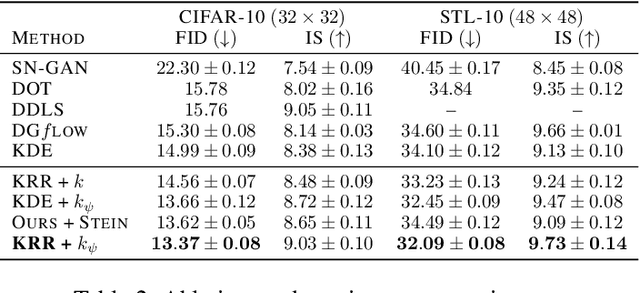

With the rapidly growing model complexity and data volume, training deep generative models (DGMs) for better performance has becoming an increasingly more important challenge. Previous research on this problem has mainly focused on improving DGMs by either introducing new objective functions or designing more expressive model architectures. However, such approaches often introduce significantly more computational and/or designing overhead. To resolve such issues, we introduce in this paper a generic framework called {\em generative-model inference} that is capable of enhancing pre-trained GANs effectively and seamlessly in a variety of application scenarios. Our basic idea is to efficiently infer the optimal latent distribution for the given requirements using Wasserstein gradient flow techniques, instead of re-training or fine-tuning pre-trained model parameters. Extensive experimental results on applications like image generation, image translation, text-to-image generation, image inpainting, and text-guided image editing suggest the effectiveness and superiority of our proposed framework.