 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Co-Teaching for Unsupervised Domain Adaptation and Expansion
Apr 04, 2022

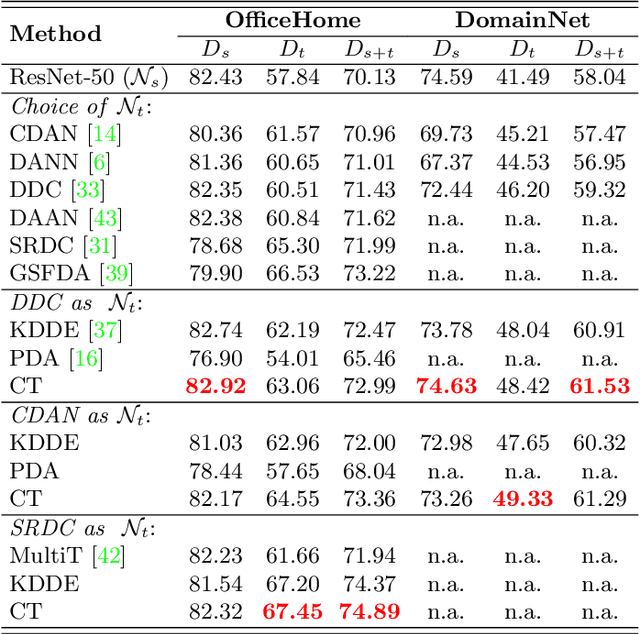
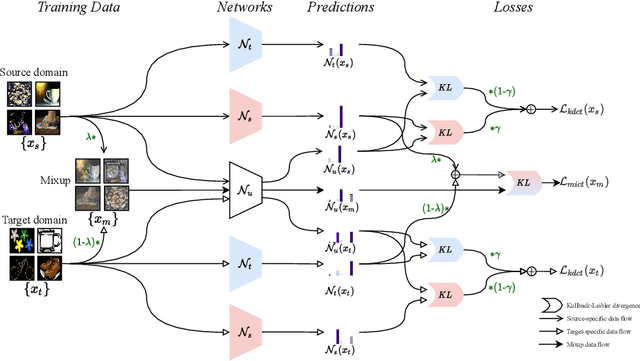
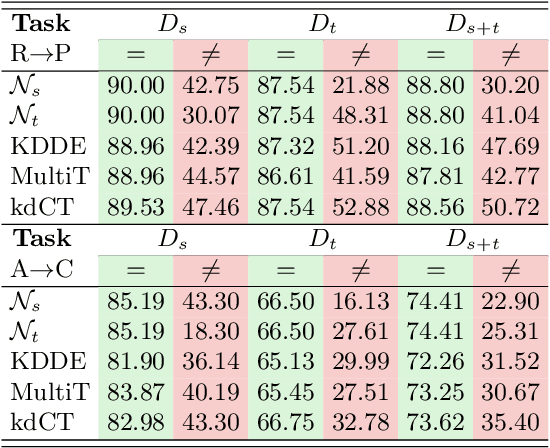
Unsupervised Domain Adaptation (UDA) is known to trade a model's performance on a source domain for improving its performance on a target domain. To resolve the issue, Unsupervised Domain Expansion (UDE) has been proposed recently to adapt the model for the target domain as UDA does, and in the meantime maintain its performance on the source domain. For both UDA and UDE, a model tailored to a given domain, let it be the source or the target domain, is assumed to well handle samples from the given domain. We question the assumption by reporting the existence of cross-domain visual ambiguity: Due to the lack of a crystally clear boundary between the two domains, samples from one domain can be visually close to the other domain. We exploit this finding and accordingly propose in this paper Co-Teaching (CT) that consists of knowledge distillation based CT (kdCT) and mixup based CT (miCT). Specifically, kdCT transfers knowledge from a leader-teacher network and an assistant-teacher network to a student network, so the cross-domain visual ambiguity will be better handled by the student. Meanwhile, miCT further enhances the generalization ability of the student. Comprehensive experiments on two image-classification benchmarks and two driving-scene-segmentation benchmarks justify the viability of the proposed method.
Learning Whole Heart Mesh Generation From Patient Images For Computational Simulations
Mar 20, 2022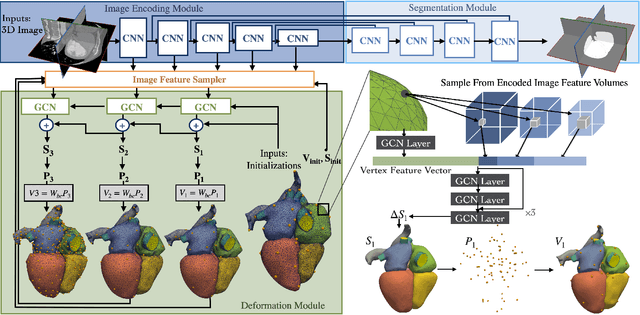
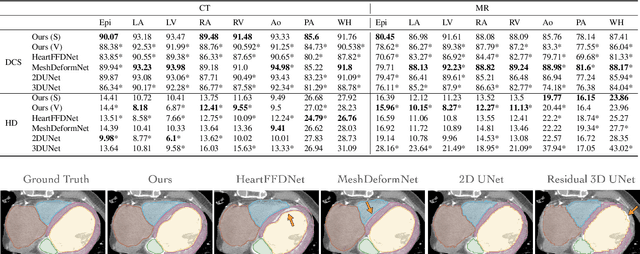
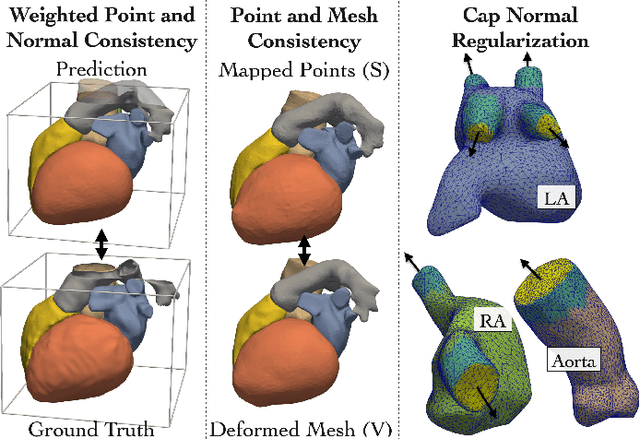
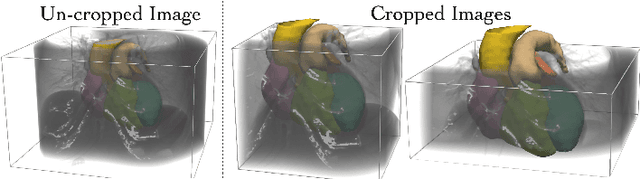
Patient-specific cardiac modeling combines geometries of the heart derived from medical images and biophysical simulations to predict various aspects of cardiac function. However, generating simulation-suitable models of the heart from patient image data often requires complicated procedures and significant human effort. We present a fast and automated deep-learning method to construct simulation-suitable models of the heart from medical images. The approach constructs meshes from 3D patient images by learning to deform a small set of deformation handles on a whole heart template. For both 3D CT and MR data, this method achieves promising accuracy for whole heart reconstruction, consistently outperforming prior methods in constructing simulation-suitable meshes of the heart. When evaluated on time-series CT data, this method produced more anatomically and temporally consistent geometries than prior methods, and was able to produce geometries that better satisfy modeling requirements for cardiac flow simulations. Our source code will be available on GitHub.
SeqTR: A Simple yet Universal Network for Visual Grounding
Mar 30, 2022
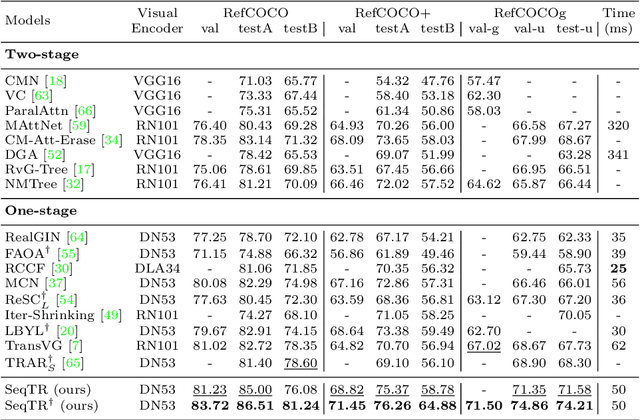
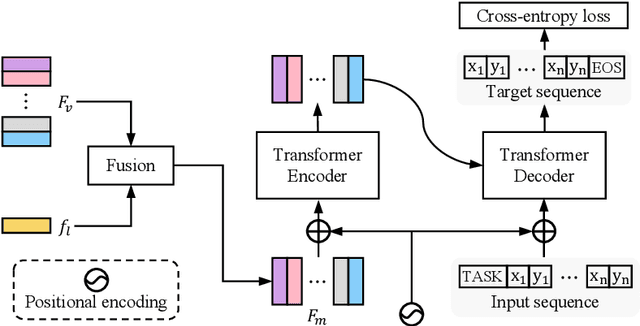
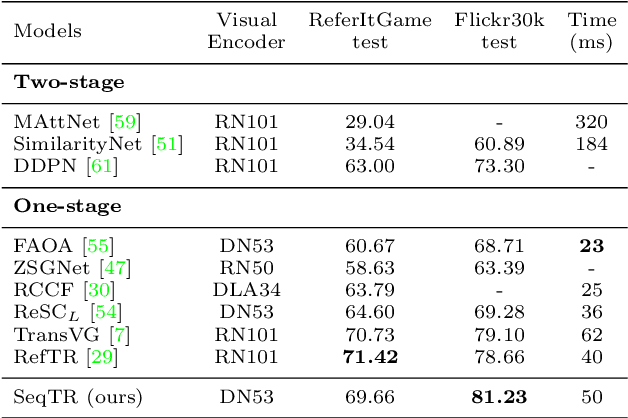
In this paper, we propose a simple yet universal network termed SeqTR for visual grounding tasks, e.g., phrase localization, referring expression comprehension (REC) and segmentation (RES). The canonical paradigms for visual grounding often require substantial expertise in designing network architectures and loss functions, making them hard to generalize across tasks. To simplify and unify the modeling, we cast visual grounding as a point prediction problem conditioned on image and text inputs, where either the bounding box or binary mask is represented as a sequence of discrete coordinate tokens. Under this paradigm, visual grounding tasks are unified in our SeqTR network without task-specific branches or heads, e.g., the convolutional mask decoder for RES, which greatly reduces the complexity of multi-task modeling. In addition, SeqTR also shares the same optimization objective for all tasks with a simple cross-entropy loss, further reducing the complexity of deploying hand-crafted loss functions. Experiments on five benchmark datasets demonstrate that the proposed SeqTR outperforms (or is on par with) the existing state-of-the-arts, proving that a simple yet universal approach for visual grounding is indeed feasible.
Lost Vibration Test Data Recovery Using Convolutional Neural Network: A Case Study
Apr 11, 2022

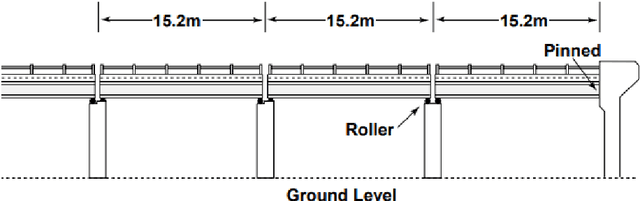

Data loss in Structural Health Monitoring (SHM) networks has recently become one of the main challenges for engineers. Therefore, a data recovery method for SHM, generally an expensive procedure, is essential. Lately, some techniques offered to recover this valuable raw data using Neural Network (NN) algorithms. Among them, the convolutional neural network (CNN) based on convolution, a mathematical operation, can be applied to non-image datasets such as signals to extract important features without human supervision. However, the effect of different parameters has not been studied and optimized for SHM applications. Therefore, this paper aims to propose different architectures and investigate the effects of different hyperparameters for one of the newest proposed methods, which is based on a CNN algorithm for the Alamosa Canyon Bridge as a real structure. For this purpose, three different CNN models were considered to predict one and two malfunctioned sensors by finding the correlation between other sensors, respectively. Then the CNN algorithm was trained by experimental data, and the results showed that the method had a reliable performance in predicting Alamosa Canyon Bridge's missed data. The accuracy of the model was increased by adding a convolutional layer. Also, a standard neural network with two hidden layers was trained with the same inputs and outputs of the CNN models. Based on the results, the CNN model had higher accuracy, lower computational cost, and was faster than the standard neural network.
Target-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection
Mar 30, 2022

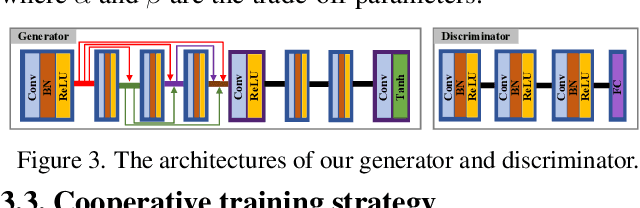

This study addresses the issue of fusing infrared and visible images that appear differently for object detection. Aiming at generating an image of high visual quality, previous approaches discover commons underlying the two modalities and fuse upon the common space either by iterative optimization or deep networks. These approaches neglect that modality differences implying the complementary information are extremely important for both fusion and subsequent detection task. This paper proposes a bilevel optimization formulation for the joint problem of fusion and detection, and then unrolls to a target-aware Dual Adversarial Learning (TarDAL) network for fusion and a commonly used detection network. The fusion network with one generator and dual discriminators seeks commons while learning from differences, which preserves structural information of targets from the infrared and textural details from the visible. Furthermore, we build a synchronized imaging system with calibrated infrared and optical sensors, and collect currently the most comprehensive benchmark covering a wide range of scenarios. Extensive experiments on several public datasets and our benchmark demonstrate that our method outputs not only visually appealing fusion but also higher detection mAP than the state-of-the-art approaches.
Depth-aware Neural Style Transfer using Instance Normalization
Mar 17, 2022



Neural Style Transfer (NST) is concerned with the artistic stylization of visual media. It can be described as the process of transferring the style of an artistic image onto an ordinary photograph. Recently, a number of studies have considered the enhancement of the depth-preserving capabilities of the NST algorithms to address the undesired effects that occur when the input content images include numerous objects at various depths. Our approach uses a deep residual convolutional network with instance normalization layers that utilizes an advanced depth prediction network to integrate depth preservation as an additional loss function to content and style. We demonstrate results that are effective in retaining the depth and global structure of content images. Three different evaluation processes show that our system is capable of preserving the structure of the stylized results while exhibiting style-capture capabilities and aesthetic qualities comparable or superior to state-of-the-art methods.
A review of deep-learning techniques for SAR image restoration
Jan 28, 2021

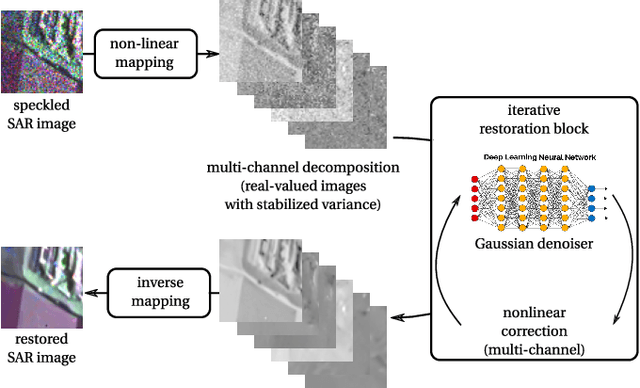
The speckle phenomenon remains a major hurdle for the analysis of SAR images. The development of speckle reduction methods closely follows methodological progress in the field of image restoration. The advent of deep neural networks has offered new ways to tackle this longstanding problem. Deep learning for speckle reduction is a very active research topic and already shows restoration performances that exceed that of the previous generations of methods based on the concepts of patches, sparsity, wavelet transform or total variation minimization. The objective of this paper is to give an overview of the most recent works and point the main research directions and current challenges of deep learning for SAR image restoration.
Fine-Grained Predicates Learning for Scene Graph Generation
Apr 08, 2022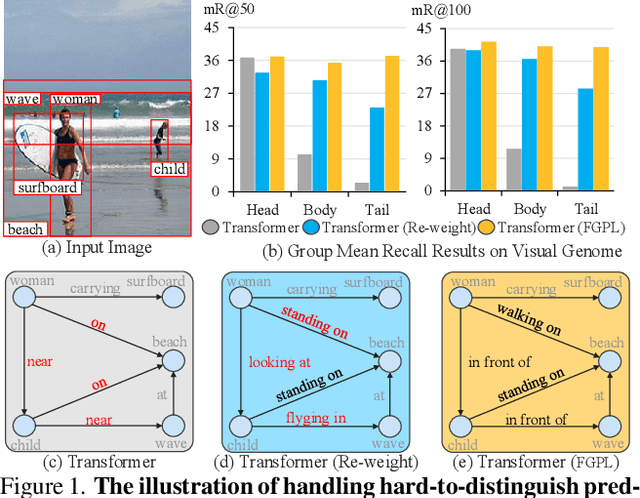
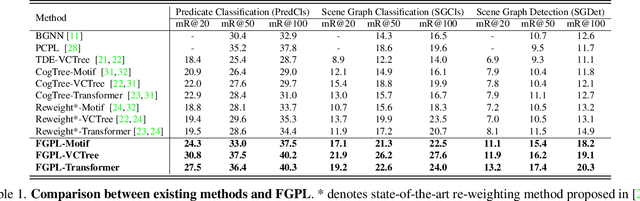
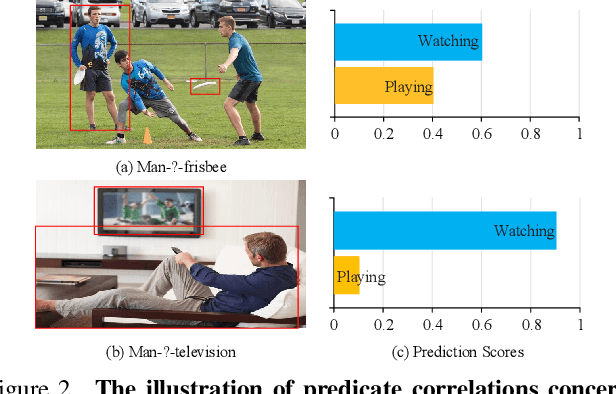
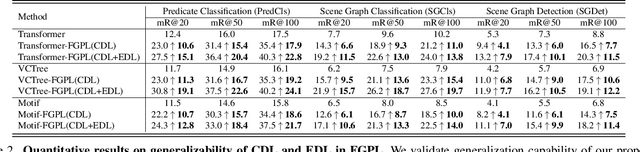
The performance of current Scene Graph Generation models is severely hampered by some hard-to-distinguish predicates, e.g., "woman-on/standing on/walking on-beach" or "woman-near/looking at/in front of-child". While general SGG models are prone to predict head predicates and existing re-balancing strategies prefer tail categories, none of them can appropriately handle these hard-to-distinguish predicates. To tackle this issue, inspired by fine-grained image classification, which focuses on differentiating among hard-to-distinguish object classes, we propose a method named Fine-Grained Predicates Learning (FGPL) which aims at differentiating among hard-to-distinguish predicates for Scene Graph Generation task. Specifically, we first introduce a Predicate Lattice that helps SGG models to figure out fine-grained predicate pairs. Then, utilizing the Predicate Lattice, we propose a Category Discriminating Loss and an Entity Discriminating Loss, which both contribute to distinguishing fine-grained predicates while maintaining learned discriminatory power over recognizable ones. The proposed model-agnostic strategy significantly boosts the performances of three benchmark models (Transformer, VCTree, and Motif) by 22.8\%, 24.1\% and 21.7\% of Mean Recall (mR@100) on the Predicate Classification sub-task, respectively. Our model also outperforms state-of-the-art methods by a large margin (i.e., 6.1\%, 4.6\%, and 3.2\% of Mean Recall (mR@100)) on the Visual Genome dataset.
Semantic Feature Extraction for Generalized Zero-shot Learning
Dec 29, 2021

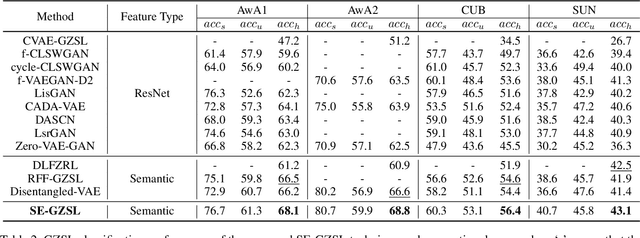
Generalized zero-shot learning (GZSL) is a technique to train a deep learning model to identify unseen classes using the attribute. In this paper, we put forth a new GZSL technique that improves the GZSL classification performance greatly. Key idea of the proposed approach, henceforth referred to as semantic feature extraction-based GZSL (SE-GZSL), is to use the semantic feature containing only attribute-related information in learning the relationship between the image and the attribute. In doing so, we can remove the interference, if any, caused by the attribute-irrelevant information contained in the image feature. To train a network extracting the semantic feature, we present two novel loss functions, 1) mutual information-based loss to capture all the attribute-related information in the image feature and 2) similarity-based loss to remove unwanted attribute-irrelevant information. From extensive experiments using various datasets, we show that the proposed SE-GZSL technique outperforms conventional GZSL approaches by a large margin.
Recommendation of Compatible Outfits Conditioned on Style
Mar 30, 2022

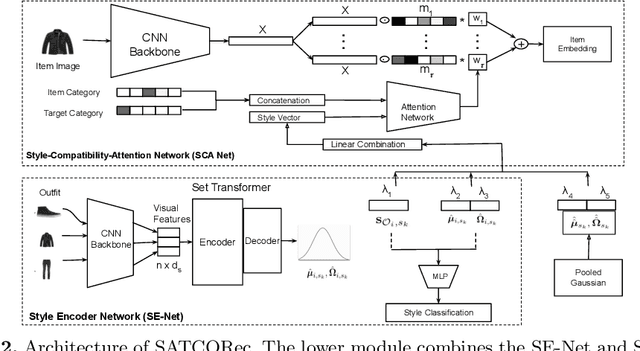

Recommendation in the fashion domain has seen a recent surge in research in various areas, for example, shop-the-look, context-aware outfit creation, personalizing outfit creation, etc. The majority of state of the art approaches in the domain of outfit recommendation pursue to improve compatibility among items so as to produce high quality outfits. Some recent works have realized that style is an important factor in fashion and have incorporated it in compatibility learning and outfit generation. These methods often depend on the availability of fine-grained product categories or the presence of rich item attributes (e.g., long-skirt, mini-skirt, etc.). In this work, we aim to generate outfits conditional on styles or themes as one would dress in real life, operating under the practical assumption that each item is mapped to a high level category as driven by the taxonomy of an online portal, like outdoor, formal etc and an image. We use a novel style encoder network that renders outfit styles in a smooth latent space. We present an extensive analysis of different aspects of our method and demonstrate its superiority over existing state of the art baselines through rigorous experiments.