 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CNN Filter DB: An Empirical Investigation of Trained Convolutional Filters
Apr 09, 2022
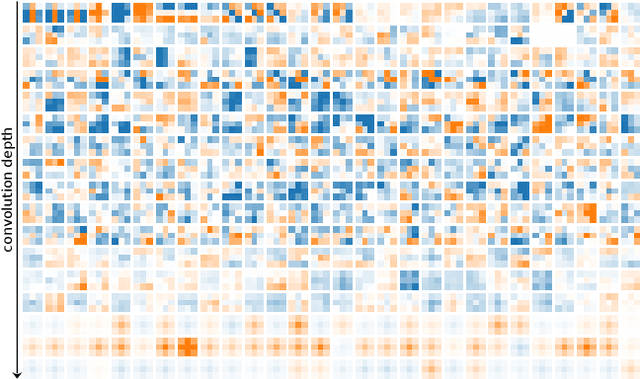

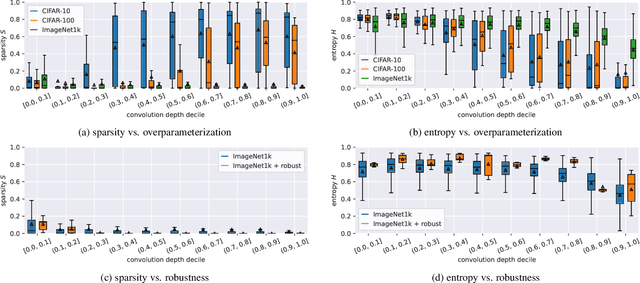
Currently, many theoretical as well as practically relevant questions towards the transferability and robustness of Convolutional Neural Networks (CNNs) remain unsolved. While ongoing research efforts are engaging these problems from various angles, in most computer vision related cases these approaches can be generalized to investigations of the effects of distribution shifts in image data. In this context, we propose to study the shifts in the learned weights of trained CNN models. Here we focus on the properties of the distributions of dominantly used 3x3 convolution filter kernels. We collected and publicly provide a dataset with over 1.4 billion filters from hundreds of trained CNNs, using a wide range of datasets, architectures, and vision tasks. In a first use case of the proposed dataset, we can show highly relevant properties of many publicly available pre-trained models for practical applications: I) We analyze distribution shifts (or the lack thereof) between trained filters along different axes of meta-parameters, like visual category of the dataset, task, architecture, or layer depth. Based on these results, we conclude that model pre-training can succeed on arbitrary datasets if they meet size and variance conditions. II) We show that many pre-trained models contain degenerated filters which make them less robust and less suitable for fine-tuning on target applications. Data & Project website: https://github.com/paulgavrikov/cnn-filter-db
MRI Reconstruction via Data Driven Markov Chain with Joint Uncertainty Estimation
Feb 03, 2022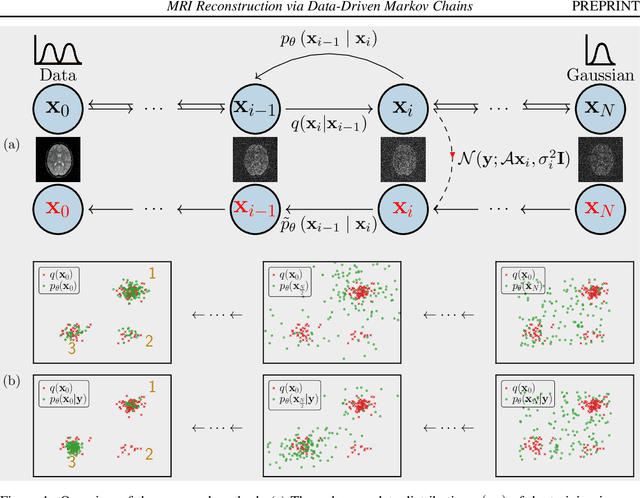
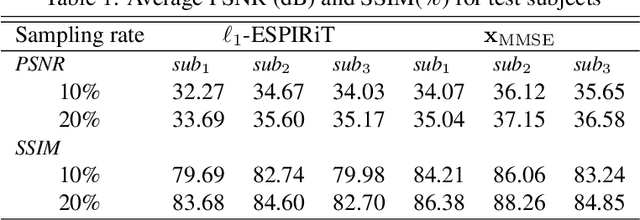
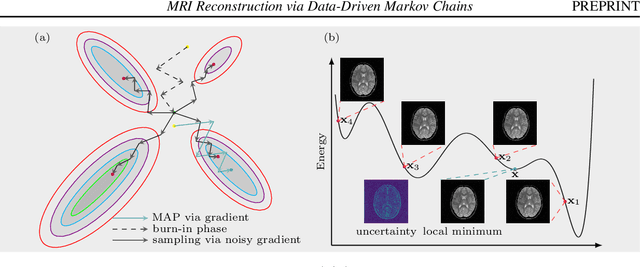

We introduce a framework that enables efficient sampling from learned probability distributions for MRI reconstruction. Different from conventional deep learning-based MRI reconstruction techniques, samples are drawn from the posterior distribution given the measured k-space using the Markov chain Monte Carlo (MCMC) method. In addition to the maximum a posteriori (MAP) estimate for the image, which can be obtained with conventional methods, the minimum mean square error (MMSE) estimate and uncertainty maps can also be computed. The data-driven Markov chains are constructed from the generative model learned from a given image database and are independent of the forward operator that is used to model the k-space measurement. This provides flexibility because the method can be applied to k-space acquired with different sampling schemes or receive coils using the same pre-trained models. Furthermore, we use a framework based on a reverse diffusion process to be able to utilize advanced generative models. The performance of the method is evaluated on an open dataset using 10-fold accelerated acquisition.
Real-time Rendering for Integral Imaging Light Field Displays Based on a Voxel-Pixel Lookup Table
Jan 26, 2022A real-time elemental image array (EIA) generation method which does not sacrifice accuracy nor rely on high-performance hardware is developed, through raytracing and pre-stored voxel-pixel lookup table (LUT). Benefiting from both offline and online working flow, experiments verified the effectiveness.
Survival Analysis for Idiopathic Pulmonary Fibrosis using CT Images and Incomplete Clinical Data
Mar 21, 2022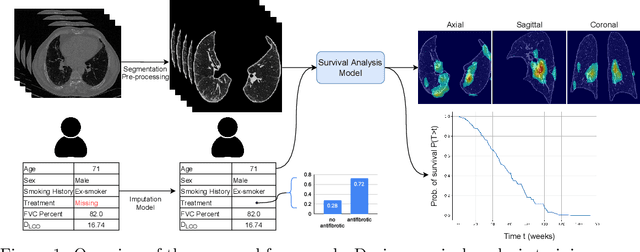
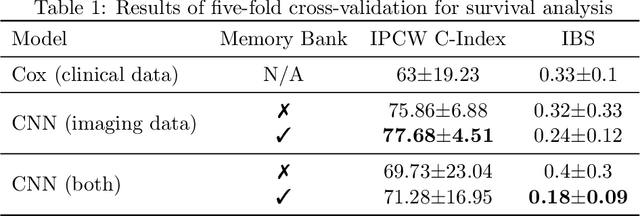
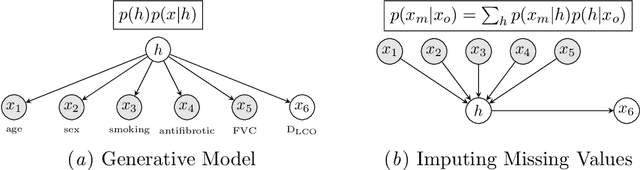

Idiopathic Pulmonary Fibrosis (IPF) is an inexorably progressive fibrotic lung disease with a variable and unpredictable rate of progression. CT scans of the lungs inform clinical assessment of IPF patients and contain pertinent information related to disease progression. In this work, we propose a multi-modal method that uses neural networks and memory banks to predict the survival of IPF patients using clinical and imaging data. The majority of clinical IPF patient records have missing data (e.g. missing lung function tests). To this end, we propose a probabilistic model that captures the dependencies between the observed clinical variables and imputes missing ones. This principled approach to missing data imputation can be naturally combined with a deep survival analysis model. We show that the proposed framework yields significantly better survival analysis results than baselines in terms of concordance index and integrated Brier score. Our work also provides insights into novel image-based biomarkers that are linked to mortality.
Fast Neural Architecture Search for Lightweight Dense Prediction Networks
Mar 09, 2022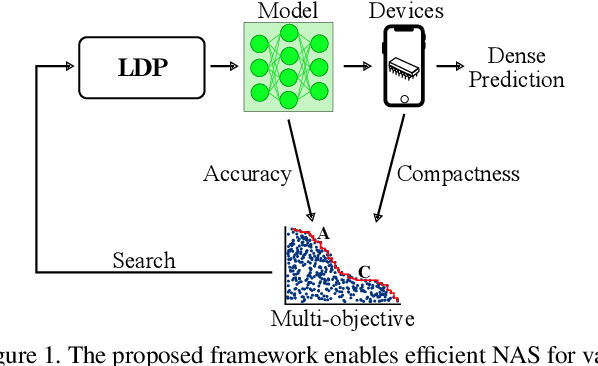
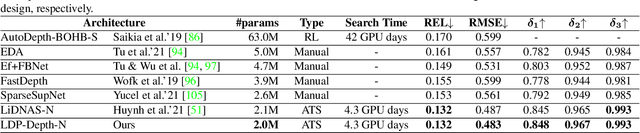
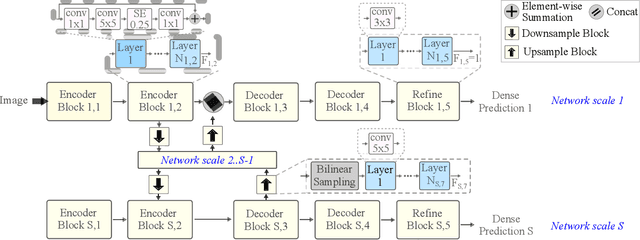
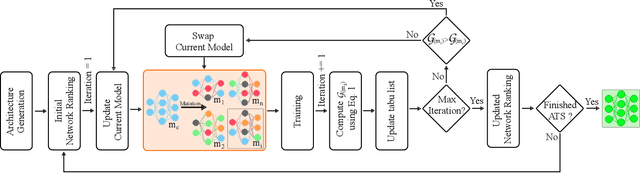
We present LDP, a lightweight dense prediction neural architecture search (NAS) framework. Starting from a pre-defined generic backbone, LDP applies the novel Assisted Tabu Search for efficient architecture exploration. LDP is fast and suitable for various dense estimation problems, unlike previous NAS methods that are either computational demanding or deployed only for a single subtask. The performance of LPD is evaluated on monocular depth estimation, semantic segmentation, and image super-resolution tasks on diverse datasets, including NYU-Depth-v2, KITTI, Cityscapes, COCO-stuff, DIV2K, Set5, Set14, BSD100, Urban100. Experiments show that the proposed framework yields consistent improvements on all tested dense prediction tasks, while being $5\%-315\%$ more compact in terms of the number of model parameters than prior arts.
Glance and Focus Networks for Dynamic Visual Recognition
Jan 09, 2022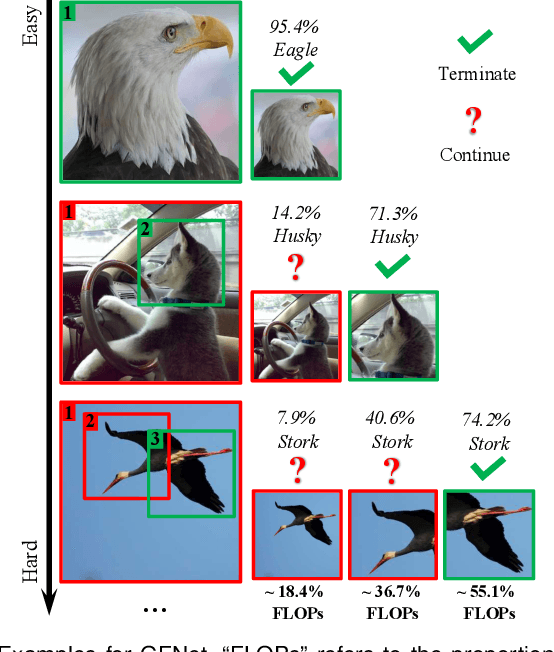
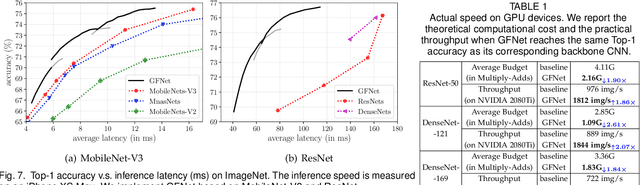
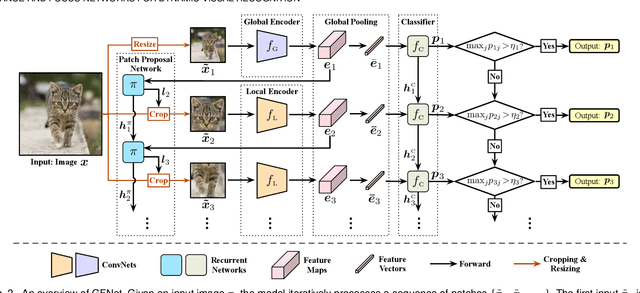
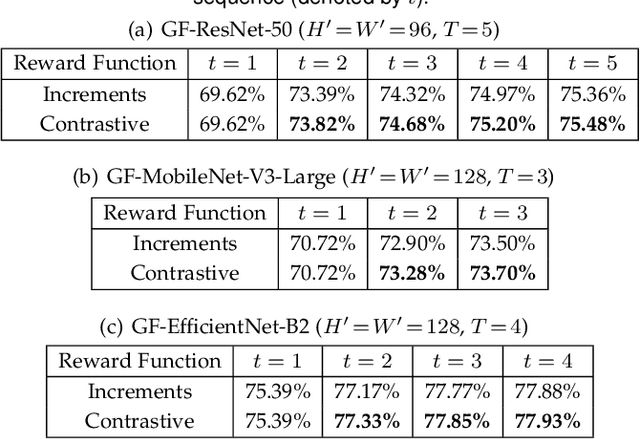
Spatial redundancy widely exists in visual recognition tasks, i.e., discriminative features in an image or video frame usually correspond to only a subset of pixels, while the remaining regions are irrelevant to the task at hand. Therefore, static models which process all the pixels with an equal amount of computation result in considerable redundancy in terms of time and space consumption. In this paper, we formulate the image recognition problem as a sequential coarse-to-fine feature learning process, mimicking the human visual system. Specifically, the proposed Glance and Focus Network (GFNet) first extracts a quick global representation of the input image at a low resolution scale, and then strategically attends to a series of salient (small) regions to learn finer features. The sequential process naturally facilitates adaptive inference at test time, as it can be terminated once the model is sufficiently confident about its prediction, avoiding further redundant computation. It is worth noting that the problem of locating discriminant regions in our model is formulated as a reinforcement learning task, thus requiring no additional manual annotations other than classification labels. GFNet is general and flexible as it is compatible with any off-the-shelf backbone models (such as MobileNets, EfficientNets and TSM), which can be conveniently deployed as the feature extractor. Extensive experiments on a variety of image classification and video recognition tasks and with various backbone models demonstrate the remarkable efficiency of our method. For example, it reduces the average latency of the highly efficient MobileNet-V3 on an iPhone XS Max by 1.3x without sacrificing accuracy. Code and pre-trained models are available at https://github.com/blackfeather-wang/GFNet-Pytorch.
A Survey on Intrinsic Images: Delving Deep Into Lambert and Beyond
Dec 07, 2021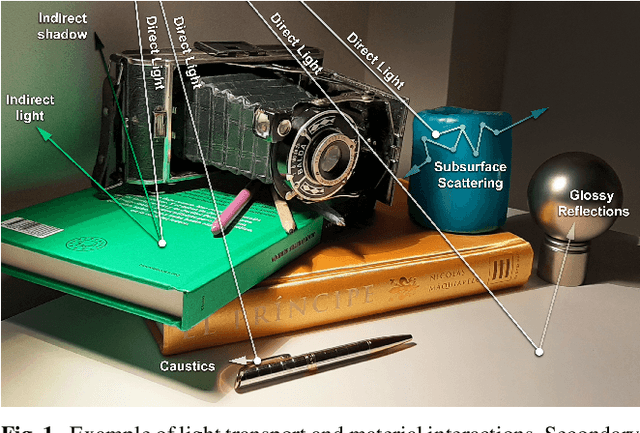
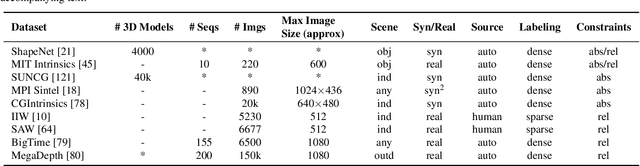
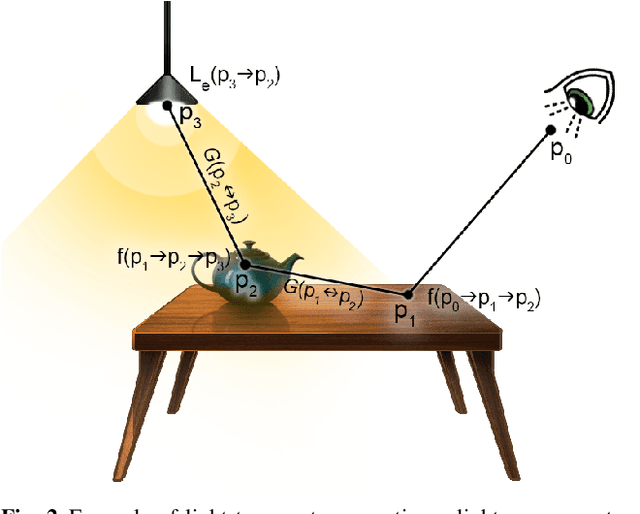
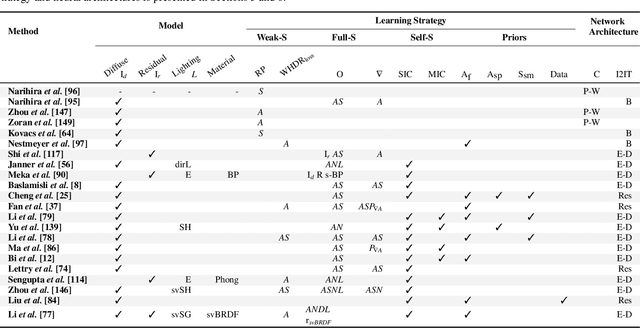
Intrinsic imaging or intrinsic image decomposition has traditionally been described as the problem of decomposing an image into two layers: a reflectance, the albedo invariant color of the material; and a shading, produced by the interaction between light and geometry. Deep learning techniques have been broadly applied in recent years to increase the accuracy of those separations. In this survey, we overview those results in context of well-known intrinsic image data sets and relevant metrics used in the literature, discussing their suitability to predict a desirable intrinsic image decomposition. Although the Lambertian assumption is still a foundational basis for many methods, we show that there is increasing awareness on the potential of more sophisticated physically-principled components of the image formation process, that is, optically accurate material models and geometry, and more complete inverse light transport estimations. We classify these methods in terms of the type of decomposition, considering the priors and models used, as well as the learning architecture and methodology driving the decomposition process. We also provide insights about future directions for research, given the recent advances in neural, inverse and differentiable rendering techniques.
CycleMorph: Cycle Consistent Unsupervised Deformable Image Registration
Aug 13, 2020
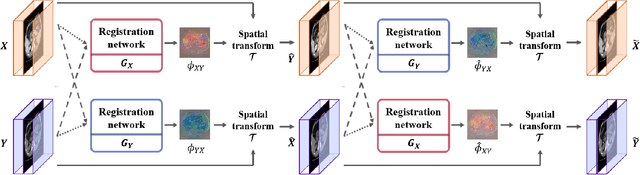
Image registration is a fundamental task in medical image analysis. Recently, deep learning based image registration methods have been extensively investigated due to their excellent performance despite the ultra-fast computational time. However, the existing deep learning methods still have limitation in the preservation of original topology during the deformation with registration vector fields. To address this issues, here we present a cycle-consistent deformable image registration. The cycle consistency enhances image registration performance by providing an implicit regularization to preserve topology during the deformation. The proposed method is so flexible that can be applied for both 2D and 3D registration problems for various applications, and can be easily extended to multi-scale implementation to deal with the memory issues in large volume registration. Experimental results on various datasets from medical and non-medical applications demonstrate that the proposed method provides effective and accurate registration on diverse image pairs within a few seconds. Qualitative and quantitative evaluations on deformation fields also verify the effectiveness of the cycle consistency of the proposed method.
Deconstruction and reconstruction of image-degrading effects in the human abdomen using Fullwave: phase aberration, multiple reverberation, and trailing reverberation
Jun 25, 2021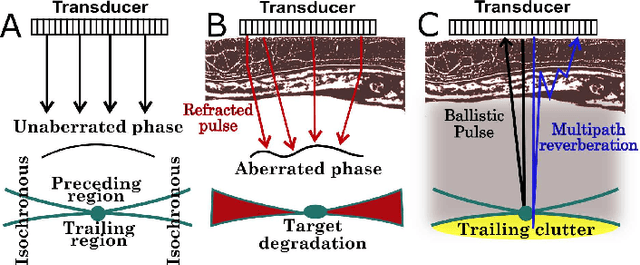
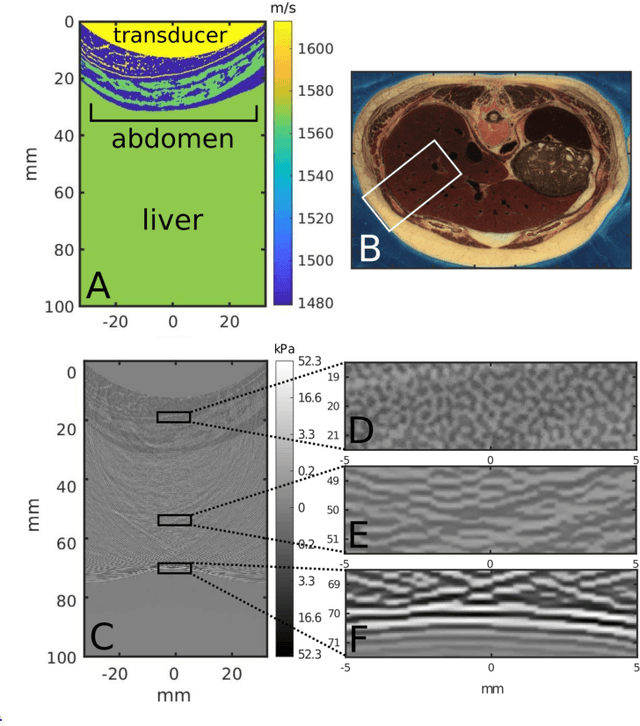
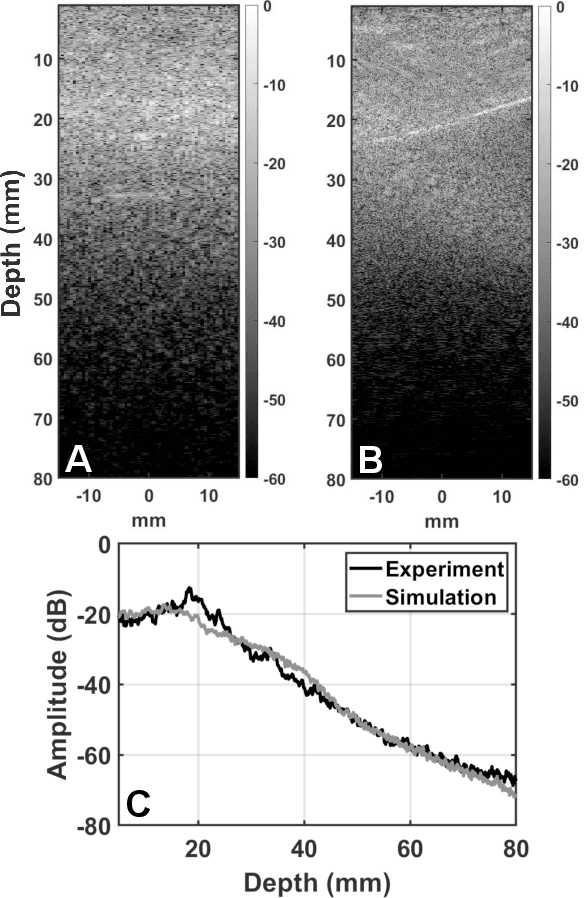
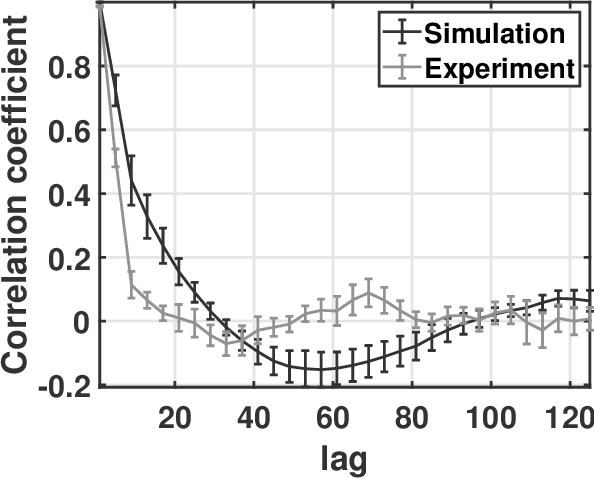
Ultrasound image degradation in the human body is complex and occurs due to the distortion of the wave as it propagates to and from the target. Here, we establish a simulation based framework that deconstructs the sources of image degradation into a separable parameter space that includes phase aberration from speed variation, multiple reverberations, and trailing reverberation. These separable parameters are then used to reconstruct images with known and independently modulable amounts of degradation using methods that depend on the additive or multiplicative nature of the degradation. Experimental measurements and Fullwave simulations in the human abdomen demonstrate this calibrated process in abdominal imaging by matching relevant imaging metrics such as phase aberration, reverberation strength, speckle brightness and coherence length. Applications of the reconstruction technique are illustrated for beamforming strategies (phase aberration correction, spatial coherence imaging), in a standard abdominal environment, as well as in impedance ranges much higher than those naturally occurring in the body.
Möbius Convolutions for Spherical CNNs
Jan 28, 2022
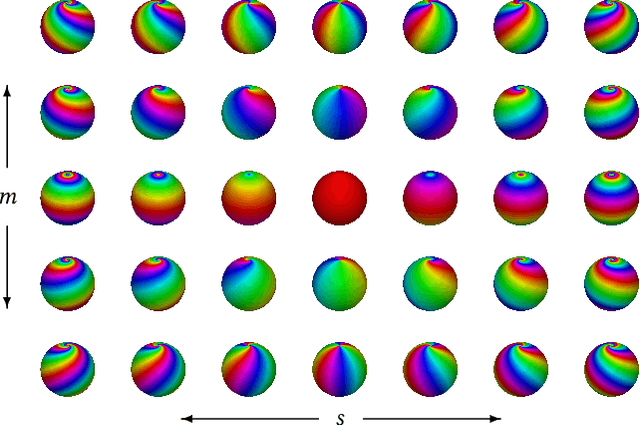
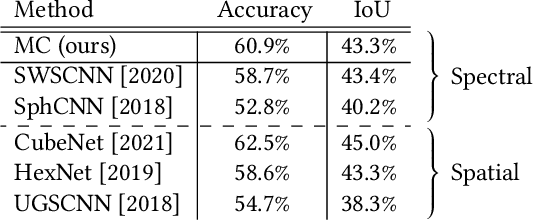
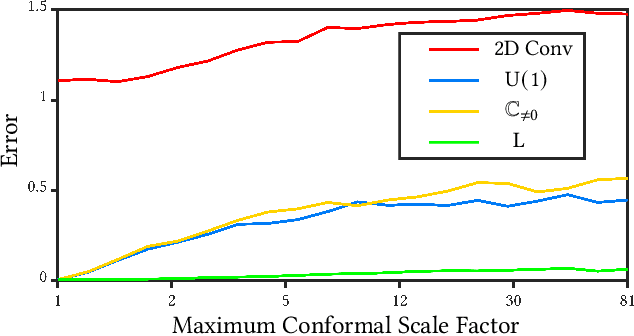
M\"{o}bius transformations play an important role in both geometry and spherical image processing -- they are the group of conformal automorphisms of 2D surfaces and the spherical equivalent of homographies. Here we present a novel, M\"{o}bius-equivariant spherical convolution operator which we call M\"{o}bius convolution, and with it, develop the foundations for M\"{o}bius-equivariant spherical CNNs. Our approach is based on a simple observation: to achieve equivariance, we only need to consider the lower-dimensional subgroup which transforms the positions of points as seen in the frames of their neighbors. To efficiently compute M\"{o}bius convolutions at scale we derive an approximation of the action of the transformations on spherical filters, allowing us to compute our convolutions in the spectral domain with the fast Spherical Harmonic Transform. The resulting framework is both flexible and descriptive, and we demonstrate its utility by achieving promising results in both shape classification and image segmentation tasks.